2020.11.24
Interpretable Sequence Learning for COVID-19 Forecasting
Sercan O¨ . Arık et al.: Google Cloud AI
google はビッグデータを活用した人工知能の応用問題として、COVID-19 の感染予測を行っている。まあ、社会貢献という意味もあるだろう。最近日本の感染状況の解析と予測を公表した。
今後の新規陽性者数は直線的に増加するように予測されている。
指数関数的にならないのは、陽性者数の増加というニュースによって人々が接触を避けると予測しているからで、その傾向がAIで学習されているものと思われる。つまり感染パラメータが感染状況のフィードバックで変わるという非線形性が組み込まれている点が予測性に寄与している。
そのやり方を調べてみた。
この報告は journal に掲載されているものではなくて、google 自身が公表している AI の説明である。最初の方は一般的な事が書かれてあるので省略し、結果についても米国の結果だし、よく合って当り前なので、省略する。日本の予測も、このまま政府が何も対策しなければ、当たるだろうと思う。方法としては、区画モデル SEIR を拡張したモデルである。ただし、パラメータが様々なデータを使って日々変化していて、その関数形が AI で学習される、という処が AI たる所以である。ただ、予測が当たるとしても、モデル(因果関係)が正しいとは言えないことには注意する必要がある。モデルの構成は入手し易いビッグデータを活用できるように作られたものであって、COVID-19 の医学的特徴や検査の実態については、モデルが複雑になるので、あまり考慮されていない。医学的特徴とは、一次感染から二次感染までの時間分布とか、ウイルスを放出する期間とか、であり、検査の実態とは、発症から検査までの放置時間とか、である。確率過程モデルとか僕のモデル ではそれを考慮に入れている。予測を警告として受け取るのであれば何の問題も無いが、計算の中身から感染対策を立てるとすれば充分に注意する必要がある。
3 Proposed Compartmental Model for COVID-19
Fig.2 に全体図が示されている。
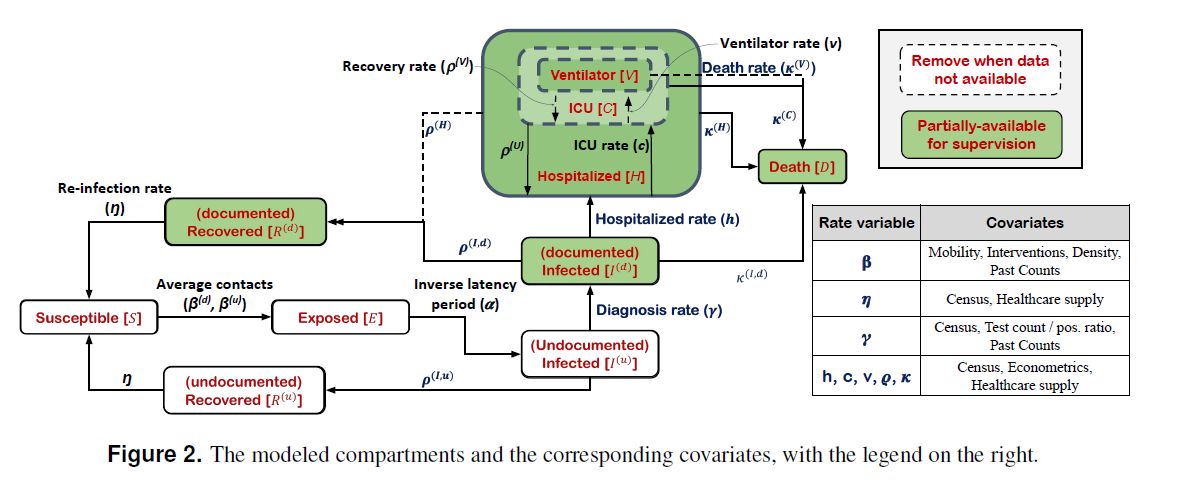
包含関係の無い区画は、S+E+I(u)+I(d)+H+R+D である。
SEIR との対応でいうと、I が I(u)+I(d)+H に区分されている。
また、R が R+D に区分されている。
S(未感染者)とE(待機)はそのままで変わらない。
Eは感染してから感染可能になるまでである。
I (感染者)は大きく二つに分ける
I(u) 未登録感染者 と I(d)+H:登録感染者である。
後者が PCR検査陽性者 Q に相当するから、SEIQR モデルの一種ともいえる。
更に その Q が区分される。
I(d)+H の H は入院者である。
H はその中に C:ICU隔離者を含む。
更に C はその中に V:人工呼吸器装着者を含む。
R は R:回復者 と D:死亡者 に区分されるが、
I(u)+Hからの回復とI(d)からの回復が区別されていて、
それぞれ R(u) と R(d) で表記されている。
次に、これら区画の間の遷移 rate を比率で与える。化学反応式や原子核種崩壊と同じやり方である。
つまり、増加分=比例係数×現在(あるいは一つ前の時刻での)関係する量 としている。
(例えば ΔI=β×I×S+・・・、ΔR=ρ×I+・・・)
こうすると、それ以上過去の履歴を考慮する必要が無くなる。
(注):全ての遷移についてはその開始の遅延は考慮されていない。
この点でやや現実乖離がある。医学的特徴が考慮されていない。
重要な遷移は S→I(u) である。これは感染源(spreader)に応じて二種ある。
I(u) が S に接触して感染させる場合の比例係数 がβ(u)で、
I(d) が S に接触して感染させる場合の比例係数 がβ(d)である。
後者は、自覚的 PCR検査陽性者が市中に徘徊して感染させる、という想定である。
(SEIQRモデルでは β(d)=0 と置いてしまう。)
入院した後は感染源とはならないという想定している。
(注):このモデルはPCR検査陽性者(RNA保持者)と感染源(ウイルス保持者)とを区別していないから、ここで推定される β は医学的な意味でのβよりも小さいと考えられる。
R:回復者から S:未感染者への遷移係数は η であり、R(u)もR(d)も区別されない。
医学的には獲得免疫の喪失を意味する。この為に R と D が区分された。
回復過程も rate で扱われる。これは PCR検査の陰性化として定義されている。
I(u) から R(u) への遷移は比例係数 ρ(I,u) で起こり、
I(d) から R(d) への遷移は比例係数 ρ(I,d) で起こり、
H から R(d) への遷移は比例係数 ρ(H) で起こる。
E から I(u) への遷移は比例係数 α で起きる。
(注):医学的には、遷移のタイミングについての幅広い分布が観測されているが、
rate で単純化するということは、その分布を指数関数的減衰と仮定することである。
I(u) から I(d) への遷移は比例係数 γ で起きる。
(注):これは正に通常の SEIQR モデルでの隔離率 q に相当するが、
このモデルでは、I(d) も多少は感染源となり得るので、やや異なる。
いずれにしても、実態としては検査の遅延が必ずあるので、
遷移するにはそのタイミングの分布があるのであるが、
rate で表現すると、その分布を指数関数的減衰と仮定したことになる。
登録感染者は更に I(d) と H に区分される。
これは実際にデータが入手可能だからである。
I(d) から H への遷移は比例係数 h で起こる。
この記述はそれほど実態と異なるとは思えないが、
時間経過すれば全ての感染者が入院する、ということになっている。
ある比率で分けるというやり方もあるだろうと思う。
入院者 H の中に C: 重症者(ICU隔離者)を考えて、
H−C から C への遷移係数 c とし、
C から H-C への遷移係数を ρ(U) とする。
更に C: 重症者の中に V: 人工呼吸者 を考えて、
C−V から V への遷移係数を v とし、
V から C−V への遷移係数を ρ(V) とする。
最後に 死亡 であるが、未登録者についてはデータが無いので考慮しない。
I(d) から D への遷移は係数を κ(I,d)
H−C から D への遷移は係数を κ(H)
C−V から D への遷移は係数を κ(C)
V から D への遷移は係数を κ(V)
これらの遷移係数は以下のようにしてその都度 covariates から決定される。これが AI による『学習』である。
(covariate は影響を与えるとされる因子である。下記:の右側。相関の場合もある。)
用語の意味合いがすっきりしない。η に医療が関係するのか???
β(感染率・接触頻度):移動度、介入、人口密度、過去の感染データ
η(免疫喪失):統計(census)、医療(medical care)
γ(登録率):統計、陽性率、過去の感染データ
h、c、v、ρ、κ:統計、経済状況、医療
感染症以外での死亡、および誕生は無視する。
実効再生産数は
Re={β(d)γ+β(u)(ρ(I,d)+κ(I,d)+h}/{(γ+ρ(I,u))(ρ(I,d)+κ(I,d)+h)}
β(d)=0 であれば、
Re=β(u)/{(γ+ρ(I,u)}
となり、これは SIQR モデルである。
しかし、SIQR モデルとは異なり、I(d) も感染源となる。
その β への寄与としては、β(d)γ/(ρ(I,d)+κ(I,d)+h) ということである。
分母×I(u) は I(d) が減少していく比例係数であり、γI(u) は I(d)が増加していく比例係数である。
4 Encoding Covariates
拡張されたSEIRモデルの各パラメータ(β、γ、等)を vi[t] とし、それを vi に対する影響因子 covariate cov(vi,t) (移動度、人口、等)の線形和で表現し、その係数行列 w を学習させる。ただ、このまま行うととんでもない解に収束してしまう場合(過剰適応)が多い。データそのものに誤差があり、その誤差までも再現しようとするからである。逆問題の困難性である。その過剰適応を避けるための工夫として、上限と下限を滑らかに切り捨てるようなシグモイド関数σ()を被せる。regulation である。
vi[t]=vi,L+(vi,U−vi,L)・σ(c+bi+wT cov(vi,t)) 式(2)
c は基準値、bi は地域に依存する定数。vi,L、vi,U は vi に設定された最小値と最大値。
現在時刻 T までのデータによって、最適値としての vi[t] を決める事が出来て、それを使って、差分方程式によって、T+1 における各区画の人数が計算できる。つまり予測である。しかし、τ>1日以降 T+τ での人数を予測するためには、vi[T+1]〜vi[T+τ-1] が必要となる。通例の区画モデルにおいては、これらを vi[T] として固定するから、τ が大きくなると予測がずれてくる。そこで、covariate f[T+τ-k : T+τ-1] を f[t<T+1] から推定する。時間軸だけを考えるので、自己回帰(autoregressive)モデルを使う。予測に使うのは過去14日分の covariates f である。これによって増減の傾向と週変動が捉えられる。この自己回帰モデルで予測された covariates f からモデルパラメータ(=変数 vi[T+1〜T+τ])を学習最適化し、その値を順次使って、実際の区画人数の予測を行う。
郡間の人の移動は感染の拡大に寄与するが、充分なデータが得られないので、隣接する郡の移動度データを統合して新たな covariate を作り出している。
最適化が郡レベルで行われてしまわないように regulation として bi の自乗和も最小化ターゲットの中に追加している。
重要な点であるが、このような感染モデルの比例係数(パラメータ)を学習するプロセスは過去の全ての履歴に依存している。該当する地域での感染対応策や住民の警戒心はその有効性も含めて学習されていくことになり、このことがモデルの予測性に寄与する。但し、対策への参考とする為には、中身の因果関係を知る必要があり、その解析は必ずしも容易ではない。
用語の説明
"inductive bias":
限られたデータから関数形を推定するときに、関数形に制限を与えることで推定を効率的に行える。
例:単純な増減の関係であれば線形依存性を仮定する。ここではそうしている。
google AI の場合、拡張した SEIR モデルという枠組みを与えたこともそれに相当する。
"regularization":
限られたデータから最適な関数形を推定しようとして、誤差を最小にすると、非常に複雑な関数形となり、現実性がなくなる。過剰適応である。こういう場合には、誤差+複雑さ を最小化する。様々な表現が提案されている。
"autoregressive" モデル:
この例に沿えば、
f(i)=c0+c1f(i-1)+c2f(i-2)+・・・+c14f(i-14)+noise
として、係数 c0〜c14 を決める。通例は最小二乗法を使う。
10 Datasets
Table 9 には、各 rate を決めるために使われたデータ(covariates)の種類が列挙されている。経済状況、人口動態、移動度、非医療的介入、医療体制、大気の清浄度 から影響すると考えられるデータを選択した、ということである。
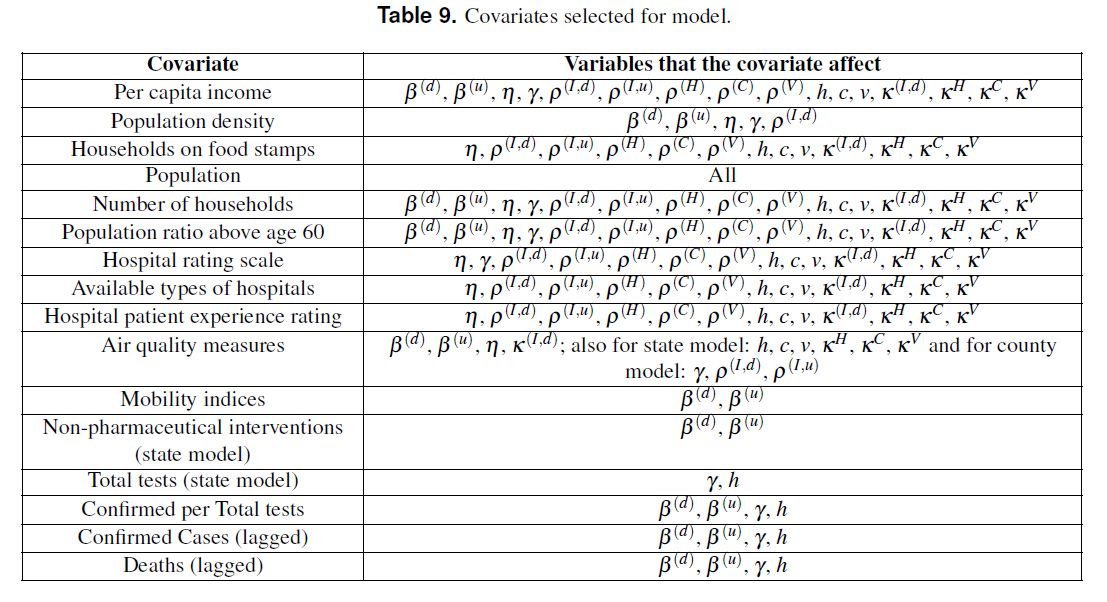
上から訳していくと、一人当たりの収入、人口密度、食事支援受給所帯数、人口、世帯数、60歳以上の比率、病院格付けスケール、利用できる病院の種類、入院経験者の評価、空気清浄度、人々の移動性、非医療的介入(州モデル)、全検査数(州モデル)、陽性率、陽性者数(時間遅れで使う)、死者数(時間遅れで使う)
・まずは基本的な感染状況は Johns Hopkins COVID-19 dataset、政府の Covid Tracking Project。
・移動度は Descartes labs のデータ。州レベルと郡レベル両方である。β(d)、β(u)に影響。
・非医療的介入は政府の政策である。学校の閉鎖、飲食店への制限、移動制限、集会の制限、必須業務宣言、緊急事態宣言。β(d)、β(u)に影響。
・人口動態はThe Kaiser Family Foundation より。
・空気清浄度はUS Environmental Protection Agency (EPA) から各地区データを得た。
・経済状況は個人だけでなく近隣の他者の経済状況を考慮した。国勢調査を使った。
・地域医療状況:Center for Medicare and Medicaid Services, a federal agency within the United States Department of Health and Human Services
・感染者数と死者数:過去のデータが影響してくる。β(d)、β(u)、γ、h に影響。
地方のデータをその地方だけに使うのではなく、近隣のデータを統合したもの(aggregation)も使う。
・・・これ以上詳しい内容は説明されていない。。。
(注)あまり変化しないデータは、人口動態、空気清浄度、経済状況、地域医療状況であり、これらは時間変動させない。地域間の差異を説明するのであろう。政府の介入、移動度は重なる部分もあるが、もっとも強力な影響だろう。直近の感染者数と死者数は人々の警戒感を呼び起こすことで影響を与えるだろう。検査発見の rate γ が SIQRモデルの 隔離率 q に相当するので、β、γ に影響するものを列挙すると、
・一人当たりの収入、人口密度、人口、世帯数、60歳以上の比率、
陽性率、陽性者数(時間遅れで使う)、死者数(時間遅れで使う)が β にも γ にも影響し、
・病院格付けスケール、全検査数(州モデル)が γ のみに影響し、
・空気清浄度、人々の移動性、非医療的介入(州モデル)が β のみに影響する。
ここから、長期的な因子(固定因子)を取り除くと、何を計算しているかが見えてくる。
・陽性率→ β・・相関関係(多分正相関)
・陽性者数(遅延)、死者数(遅延)→ β・・・心理的な影響(負効果)
・人々の移動性、非医療的介入→ β・・・直接的影響(それぞれ 正、負効果)
・陽性率→ γ・・・相関関係(多分負相関)
・陽性者数(遅延)、死者数(遅延)→ γ・・・心理的な影響(正効果)
・全検査数→ γ・・・検査体制整備の効果(正効果)
これらの概念の枠組みでしか因果関係が語られない、という本質的な限界がある。
ただ、その限界があっても感染予測は成功するであろう。
5 End-to-End Training
Algorithm 1 にAIでの学習方法が書いてあるが、これだけでは良く判らない。

一応その下の説明を読む。観測値 Y としては、現在時刻(日) T から T-M、つまり M日前までがあるとする。ここで Y というのは、Q(積算陽性者数)、H、C、V、D、R(d) である。非登録者や感染待機者 E 等は観測されない。Q だけは他の観測値から計算できる。ここから、次の τ 日間の Y を予測するというのが、最終目的である。
最小化すべき目的関数が式(5)で与えられている。これは観測量 Y の種類毎の誤差評価にそれぞれの重みを付けた和になっている。つまり Y の種類によって単位もサイズも異なるので、別々の重みが必要であり、これはまたどの観測量を重視するのか、という重みでもある。また過去の時間については、当然ながら現在に近い観測量の重みが大きくされている。exp(tz) という因子を掛けるが、この z を hyper parameter と呼ぶ。最終調整に使う。観測量 Y の計算予測値は当然感染パラメータを持った差分方程式の解として与えられ、その感染パラメータは種々の covatates の線形和として最適化されるが、その最適化のターゲットというのが、式(5) である。しかしこれだけだと、過剰適応することで非現実的な解が得られやすいので regularization を行う。一つのやり方は、この最適化ターゲットである式(5) に非現実性を評価する関数を追加することである。例えば遷移係数 が 1 を超えることはあり得ない(これは一日単位の差分方程式だから)。この表現が式(6) である。もう一つの regularization は実効再生産数であり、これがあり得ない値とならないように制限する。最終的な目的関数は式(7) である。
ということで、その学習アルゴリズム1の説明に入る。
まずは、得られている現在までのデータを最後の τ 日とそれ以前に分ける。後者が training data(varidates)であり、前者が再現すべき目標 varidation である。hyper parameter=z をいろいろ変えてみて、一番評価関数が小さくなるような z に固定し、joint training をするということなので、この段階で varidation に使っていた最近のデータも最適化に使う、ということだろう。RMSProp というアルゴリズムが経験的には一番良かったらしい。最後にコメントの感じで書いてあるのが、区画モデルは初期値に対して敏感な事があるので、その初期値についてもそれをいろいろ変えてみて最適化した、ということである。ここで初期値というのは観測される以前のデータである。確かに何もなければ感染が始まらない。特にこれだけ複雑な区画モデルの場合には初期値には注意すべきだろう。
用語
"RMSProp":最急降下法(目的関数が一番速く小さくなる方向にパラメータを変えていく方法)の振動を抑える為に、その変える単位を小さくしていくやり方。
(注)多変数空間で非線形の最小化であるから、グローバルな意味で最小になるかどうかは保証されない。局所最小値に陥りやすい。この方法はむしろ局所最小値へ安定して落ち着くための方法である。局所性というのは過剰適応であるから、それを避ける手立て regularization があらかじめ手当されていることが前提条件である。