2021.01.24乮01.30丗婰崋傪摑堦丄僔儈儏儗乕僔儑儞捛壛丄峫嶡捛壛丅02.07丗徚柵妋棪偺峫嶡捛壛乯
丒丒丒彉丒丒丒
Superspreader 偺榑暥乮Lloid-Smith乯丅SARS傪宱尡偟偰摼傜傟偨姶愼徢塽妛偺廳梫側惉壥偲尒側偝傟偰偍傝丄偦偺堄枴偱昁撉暥專偱偁傞丅惣塝巵偑擔杮偱偺COVID-19懳嶔偲偟偰僋儔僗僞乕懳嶔偵廤拞偟偨偲偒偺崻嫆偲側偭偨丅COVID-19偵偮偄偰偺妋棪儌僨儖偺榑暥乮Hellewell et al.乯偱堷梡偝傟偰偄偨榑暥偱偁傞丅"Superspreading and the effect of individual variation on disease emergence", J.O.Loid-Smith et al. doi:10.1038/Nature04153,vol.438(17)pp.355-359(2005)丅摨偠撪梕偺preprint偲偟偰丄壓婰傕偁偪偙偪偵尒偮偐傞丅"Superspreading and the impact of individual variation on disease emergence"丅
嬯楯偟偨丅supplemental information 傪撉傑側偄偲椙偔敾傜側偄丅嵞惗嶻悢偼尨棟揑偵偼慡偰偺姶愼帠徾傪娤嶡弌棃傟偽嬶懱揑偵媮傔傜傟傞丅捠忢偼屄乆偺堦師姶愼幰偑壗柤偵姶愼偝偣偨偐傪挷傋偰丄偦偺暯嬒傪嵦傟偽椙偄丅偙偺暯嬒偱偼側偔偙偺暘晍偵偮偄偰偺榑暥偱偁傞丅SARS偺棳峴帪偵栤戣偲側傝丄偦偺僨乕僞傪夝愅偟偰偄傞丅乮崱夞偺COVID-19偵偮偄偰偼傑偩僨乕僞偑懙偭偰偄側偄偲巚傢傟傞偑丄傎傏SARS偵嬤偄偺偱偼側偄偐偲尵傢傟偰偄傞丅乯屄乆偺擇師姶愼幰悢偼妋棪揑偵尰傟偨帠徾偱偁傞偲偡傞偲丄暯嬒偲偟偰偼偁傞嵞惗嶻悢偱偁傞傛偆側億儚僢僜儞暘晍偲尒側偝傟傞丅偙偺屄恖暯嬒偲偟偰偺嵞惗嶻悢偲偄偆僷儔儊乕僞乮兯丗僊儕僔儍暥帤僯儏乕乯偑偦偺堦師姶愼幰屌桳偺傕偺偩偲偡傞丅峏偵丄偙偺屄暿暯嬒嵞惗嶻悢乮兯乯偑偳傫側暘晍傪偟偰偄傞偐丄偵偮偄偰壖掕傪偍偄偰僨乕僞偲斾妑偡傞丅側偤偙偺傛偆偵妋棪暘晍傪擇廳偵峫偊傞偺偐丄偲偄偆偲丄乽姶愼偝偣傞乕偝偣側偄乿偲偄偆帠徾偼偳偆峫偊偰傕億儚僢僜儞暘晍側偺偵丄幚嵺偺僨乕僞偑偦偆側偭偰偄側偄偐傜偱偁傞丅
丒丒丒峫偊曽丒丒丒
儌僨儖乮侾乯
兯 偺暘晍偑柍偔偰扨堦偺抣丄偮傑傝慡暯嬒偲偟偰偺嵞惗嶻悢 R0 偱偁傞偲偡傞偲丄娤應偝傟傞擇師姶愼幰悢偺暘晍偼 z 乣億儚僢僜儞暘晍偵側傞丅偙偺応崌偵懄偟偰億儚僢僜儞暘晍傪掕媊偡傞偲丄z乣(r^z)exp(-r)/z!丗r= R0/姶愼壜擻婜娫丄偲偄偆偙偲偵側傞偑丄姶愼壜擻婜娫偼栤傢側偄偺偱 1 偲偡傟偽傛偄丅z 偺婜懸抣偼摉慠 R0偱偁傞丅
儌僨儖乮俀乯
兯 偺暘晍偑巜悢娭悢揑偱偁傞偲偡傞偲丄偦偺宍偼乮暯嬒偑 R0 偩偐傜乯兯 乣exp(-兯/R0) 偱偁傞丅偙偺帪偵偼擇師姶愼幰悢偺暘晍偼 z 乣婔壗暘晍乮z,1/(1+R0))偵側傞丅側偍丄婔壗暘晍(z,p)= p(1-p)^(z-1)偱偁傞丅兯 偺暘晍偑姶愼壜擻婜娫偺暘晍偲摨偠偱偁傞偲偡傟偽丄偙傟偼偪傚偆偳姶愼椡偑巜悢娭悢揑偵尭悐偡傞偲偄偆儌僨儖丄偮傑傝 S(E)I(Q)R 儌僨儖偱嵦梡偝傟偨姶愼椡僾儘僼傽僀儖乣exp(-兞t)偵憡摉偡傞丅偨偩偟丄S(E)I(Q)R 儌僨儖偦偺傕偺偼寛掕榑揑旝暘曽掱幃偱偁傞偐傜丄兯偺抁偄曽偐傜弴偵幚尰偡傞偺偵懳偟偰丄偙偙偱偼儔儞僟儉偵慖戰偝傟偰偄傞丅
儌僨儖乮俁乯
幚嵺偺暘晍偼偙傟傜偺拞娫偲巚傢傟傞丅偦偙偱丄挊幰偼 兯 偺暘晍偲偟偰僈儞儅暘晍傪憐掕偟偰偄傞丅婜懸抣偑 R0偱 堎曽惈偑 k 偱偁傞丅暘晍宍偼丄兯 乣僈儞儅暘晍(兯,k,k/R0)亖{(k/R0)^k/儭(k)}兯^(k-1)exp(-(k/R0)兯) 偱偁傞丅k= 1 偲偡傞偲乮俀乯偵側傝丄k=亣 偲偡傞偲乮侾乯偵側傞丅乮R0= 1.5偲偟偰丄偄傠偄傠側k 偵偮偄偰偺僈儞儅暘晍偼昞偺師偺恾a偵偁傞丅乯偙偺帪丄擇師姶愼幰偺暘晍偼 z 乣晧偺擇崁暘晍(z,k,1/(1+R0/k)) 偵側傞丅偙偺儌僨儖偩偗偑梋暘偵僷儔儊乕僞 k 傪帩偭偰偄傞偺偱丄幚懺偵崌傢偣偰寛傔傞偙偲偑偱偒傞丅側偍丄晧偺擇崁暘晍偼丄惉岟妋棪傪 p 偲偟偰丄k夞偺幐攕傪偡傞慜偵惉岟偟偨帋峴夞悢z 偺暘晍(z,k,p)= C(z+k-1;z)(p^k)(1-p)^z 偱丄k 傪旕惍悢傑偱奼挘偡傞偲丄{儭(z+k)/z!儭(k)}(p^k)(1-p)^z 丄z 偺婜懸抣亖k(1-p)/p亖R0偲偡傟偽丄p 偑寛傑傞丅k= 1偱偼婔壗暘晍丄k= 亣偱偼億儚僢僜儞暘晍丅晧偺擇崁暘晍偵偼偄傠偄傠側掕媊偑偁傞偺偱暣傜傢偟偄丅偙偙偱偼摑寁尵岅 R 偱偺掕媊傪巊偭偨丅z 偺暘嶶偼 k(1-p)/p^2 亖R0(1+R0/k) 偱偁傞丅晧偺擇崁暘晍偵偼嵞惗惈偑偁傞丅偮傑傝丄撈棫側妋棪曄悢偑偦傟偧傟晧偺擇崁暘晍偵廬偆偲偒偵偼偦傟傜偺榓傕堎曽惈僷儔儊乕僞傪壛偊偨擇崁暘晍偵廬偆丅廬偭偰丄n恖偺堦師姶愼幰偑惗傒弌偡擇師姶愼幰悢偺廬偆暘晍偼婜懸抣 nR0偱丄堎曽惈nk 偺晧偺擇崁暘晍偱偁傞丅n 偑憹偊傟偽偙傟偼億儚僢僜儞暘晍偵慟嬤偡傞丅側偍丄僈儞儅暘晍偲億儚僢僜儞暘晍偲晧偺擇崁暘晍偺娭學偵偮偄偰偼丄壓婰偵敾傝傗偡偄夝愢偑偁傞丅
壜帇壔偱棟夝偡傞乽晧偺擇崁暘晍乿 - 傎偔偦徫傓 (hatenablog.com)
丒丒丒榑暥偺寢壥丒丒丒
嵟栟朄偱堎曽惈僷儔儊乕僞 k 傪悇掕偡傞偲偒偵丄兛=1/k 偵偮偄偰嵟揔壔偡傞丅峏偵廳梫側偙偲偱偁傞偑丄k<1 偺椞堟傕挷傋傞丅偲偄偆偙偲偼乮俁乯偼乮侾乯偲乮俀乯偺拞娫偲偄偆偙偲偱偼側偔偰丄乮俀乯傛傝傕峏偵堎曽惈偺戝偒偄応崌傪娷傓偲偄偆偙偲偱偁傞丅幚嵺 SARS偺応崌偵偦偆側偭偰偄傞丅壓恾a偑偦偆偱偁傞丅仭偑乮侾乯丄▷偑乮俀乯丄仜偑乮俁乯偱偁傞丅
堎曽惈傪敾傝傗偡偔昞帵偡傞堊偵丄堦師姶愼幰偺偳傟埵偺妱崌偑擇師姶愼幰偺偳傟埵偺妱崌傪敪惗偝偣偰偄傞偐丄偲偄偆僌儔僼傪昤偄偰偄傞丅偙傟偼強摼奿嵎傪昞尰偡傞儘乕儗儞僣嬋慄偲摨偠偱丄乮侾乯偺帪偵捈慄偲側傝丄姶愼擻椡偺曃傝偑戝偒偄傎偳捈慄偐傜奜傟傞丅壓恾b丅
嬶懱揑偵奺働乕僗偱偺嵟揔僷儔儊乕僞偼Supplementary Table偵偁傞丅
SSE(Super spreading event) 偺掕媊傪採埬丅傑偢儌僨儖乮侾乯偵傛偭偰擇師姶愼幰悢偵偮偄偰偺億儚僢僜儞暘晍傪妋掕偡傞丅偦偺椺偊偽99%斖埻傪挻偊傞傛偆側擇師姶愼幰悢傪梌偊偨堦師姶愼幰傪 super spreader 偲掕媊偡傞丅
偙偺傛偆側姶愼擻椡偺曃嵼偑偁傞応崌偵丄姶愼忬嫷偵偳偺傛偆側塭嬁傪梌偊傞偱偁傠偆偐丠S(E)I(Q)R儌僨儖偺傛偆側寁嶼曽朄偲偳偙偑堘偭偰偔傞偩傠偆偐丠Branching Process Model 偲偄偆奣擮偑昁梫偱偁傞丅慡恖岥偺拞偵堦恖偺堦師姶愼幰傪擖傟偨帪乮偁傞偄偼巆偝傟偨帪乯傪弶婜忬懺偲偟偰憐掕偡傞丅S(E)I(Q)R儌僨儖偱偼丄暯嬒偲偟偰偺嵞惗嶻悢乮兝/(兞+q)乯偑侾傪挻偊傟偽姶愼偑奼戝偟丄侾傪壓夞傟偽廔懅偡傞丅廔懅偺応崌偼姶愼幰悢偑侾恖埲壓偲偄偆寁嶼偵側偭偰丄寛偟偰 0 偵偼側傜側偄偐傜丄傕偆偦偺曈偱柧傜偐側尷奅偱偁傞偑丄夝庍偲偟偰 0 偵側偭偨偲偡傞偟偐側偄偩傠偆丅壓恾a偺傛偆側堎曽惈傪憐掕偟偰丄億儚僢僜儞暘晍傪巊偭偰妋棪寁嶼傪偡傞偲丄嵞惗嶻悢偑侾傪挻偊偰偄偰傕姶愼幰悢偑 0 偵側傞妋棪乮徚柵妋棪乯q 偑僛儘偵偼側傜側偄丅偙傟偼堎曽惈偑戝偒偄乮k偑彫偝偄乯傎偳戝偒偄乮壓恾b乯丅媡偵丄姶愼偑奼戝偟偰偄偔応崌偵偮偄偰傕丄堎曽惈偺塭嬁偑尠挊偱偁傞丅堎曽惈偑戝偒偄応崌偵偼丄姶愼幰偑椺偊偽100攞偵側傞傑偱偺姶愼悽戙悢偑彮側偄乮壓恾c乯丅偮傑傝丄姶愼奼戝偑憗偄偑丄偦偺斾棪偼掅偄丅偮傑傝丄偨傑偨傑 super spreader 偱偁偭偨応崌偵偼媫寖偵奼戝偡傞偑丄偦偆偱側偄応崌偼徚柵偟偰偟傑偆丅偙偆偄偆偺傪 Overdispersion 岠壥偲偄偆傜偟偄丅R0 偼 1 傪挻偊偰偄偰傕偦偺暘晍偑峀偄偺偱丄戝晹暘偺働乕僗偱偼 侾埲壓偵側偭偰丄姶愼敋敪偵帄傜側偄偲偄偆偙偲偱偁傞丅乮儚僋僠儞偵傛傞廔懅岠壥傕崅偔側傞偲巚傢傟傞丅乯
姶愼懳嶔傪恖岥慡懱偵懳偟偰嬒堦偵幚峴偡傞応崌偲丄儔儞僟儉偵慖戰偟偨恖傪揙掙揑偵妘棧偡傞応崌傪斾妑偡傞丅偄偢傟傕暯嬒偲偟偰偺嵞惗嶻悢偺掅尭偼摨偠偱偁傞偲偡傞丅屻幰偺曽偑嵞惗嶻悢偺僶儔偮偒傪戝偒偔偡傞偐傜丄姶愼廔懅偵偼桳岠偱偁傞丅偟偐偟丄懠曽偱 super spreader 傪尒摝偡壜擻惈傕偁傞丅傕偟傕丄super spreader 傪偆傑偔尒偮偗偰妘棧偱偒傟偽嬌傔偰岠棪揑偱偁傞丅
丒丒丒棟夝偺堊偺僔儈儏儗乕僔儑儞丒丒丒
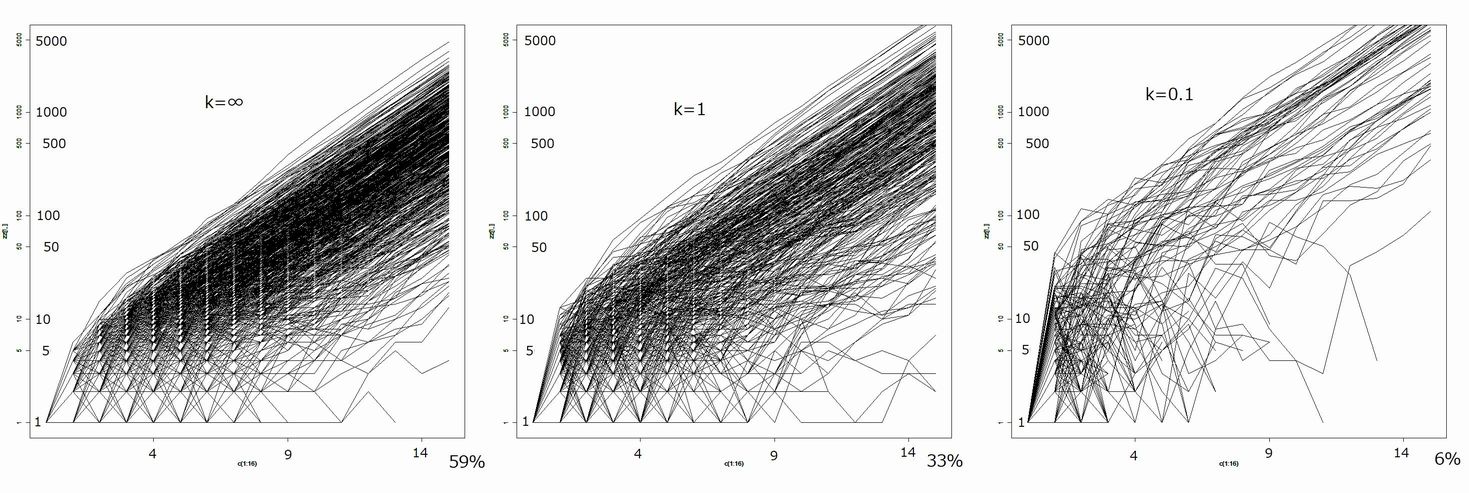
側偐側偐僀儊乕僕偑捦傔側偄偺偱丄寁嶼偟偰傒偨丅弶婜忦審偼姶愼幰堦恖偱偁傞丅R0=1.5 偲偟偰丄k亖亣丄k=1丄k亖0.1 偺応崌丄15悽戙偵榡偭偰姶愼幰悢偑偳偆曄壔偡傞偐傪寁嶼偟偨丅乮堦悽戙偲偄偆偺偼傎傏堦師姶愼幰偲擇師姶愼幰偺暯嬒揑側姶愼帪娫娫妘偱偁傝丄COVID-19偱偼俆乣俇擔埵偱偁傞丅乯妋棪揑側寁嶼側偺偱丄1000夞孞傝曉偟偨丅壓恾丄堦杮偺慄偑堦夞偺寁嶼偱偁傞丅奣偹姶愼幰偑10乣100恖傪挻偊傞偲捈慄偵側傞偺偱丄S(E)I(Q)R儌僨儖偺傛偆側寛掕榑揑側旝暘曽掱幃偑椙偄嬤帡夝朄偵側傞偲巚傢傟傞丅慄偑搑愗傟偰偄傞張偼姶愼幰偑嫃側偔側偭偨応崌偱偁傞丅%偲偄偆偺偼丄惗偒巆偭偨働乕僗偺妱崌偱偁傝丄幚嵺偵変乆偑姶愼敋敪偲偟偰栤戣偲偟偰偄傞偺偼偦偺惗偒巆偭偨応崌偩偗偱偁傞丅15夞栚偱偺姶愼幰悢偺懳悢暘晍僌儔僼傕帵偟偨丅暘晍宍偼帡偨傛偆側張偵棊偪拝偔偑丄k 偑彫偝偄応崌偵偼懳悢暯嬒偑戝偒偄丅乮k= 0.1偱擇偮僺乕僋偑偁傞傛偆偵尒偊傞偺偼妋棪揑側梙傜偓偱偁傞丅乯栜榑晛捠偺暯嬒偼偳傟傕摨偠偱丄栺R0亖1.5偺15忔偵側偭偰偄傞偺偱丄k偑彫偝偄応崌偵偼 0恖乮懳悢傪庢傞偲-亣乯偺妱崌偑懡偔偰丄偦傟傪捀揰偲偟偰側偩傜偐偵壓偑傞暘晍偺悶栰偑峀偄偲偄偆偙偲偱偁傞丅
COVID-19偺応崌偲偟偰丄k= 0.1 傪尒傞丅姶愼幰傪堦恖偯偮慡崙偵偽傜傑偄偨偲偡傞丅嵟弶偺姶愼偱23%偟偐巆傜側偄丅偟偐傕10恖埲忋偑懡偄丅偙傟偑僋儔僗僞乕偱偁傞丅偙偺傛偆側働乕僗傪揙掙揑偵捵偟偰偄偔丅擇師姶愼幰偑堦恖偺応崌偼偦偺師偺悽戙偱傑偨摨條側帠偑婲偒傞偑丄嵟弶偺1000恖偵斾傋傟偽10悢恖偲側偭偰偄傞偺偱丄偙傟傪孞傝曉偣偽姶愼敋敪偑梷偊崬傔傞丅偙傟偑僋儔僗僞乕懳嶔偺峫偊曽偱偁傞丅k= 亣偺応崌偼姶愼幰偑峀偔愺偔弌尰偡傞偺偱偙偺傛偆側懳嶔偑擄偟偄丅
丒丒丒巹揑峫嶡丒丒丒
Lloid-Smith 偺夝愅儌僨儖偼丄堦師姶愼幰屄恖偑壗恖偵姶愼偝偣傞擻椡偑偁傞偐丄偲偄偆屄恖揑嵞惗嶻悢 兯 傪帩偪丄偟偐傕偦傟偑幚尰偡傞偐偳偆偐偼儀儖僰乕僀僾儘僙僗丄偮傑傝偍恄廛傪堷偄偰媑偐嫢偐傪愯偆傛偆側傕偺偱偁傞丄偲偄偆帠偱偁傞丅偟偐偟丄偙傟傜擇偮偺帠徾偺尨場偲憐掕偝傟傞傕偺偼柧妋偱偼側偄丅傓偟傠憐掕壜擻側尨場慡偰傪屄恖揑嵞惗嶻悢 兯 偵妱傝摉偰偰丄偦傟埲奜偺嬼慠揑側僾儘僙僗傪儀儖僰乕僀僾儘僙僗偲偟偰儌僨儖壔偟偨丄偲偄偆帠偩傠偆丅尨場偲偟偰峫偊傜傟傞傕偺偱偁傞偑丄婎杮揑偵偼僂僀儖僗偺敪弌検偑偁傝丄偙傟偼昦懺偲偐帯椕偩偗偱側偔丄偦偺恖偑偍挐傝偐偳偆偐丄偲偐儅僗僋傪偟偰偄傞偐偲偐丄偲偄偭偨杮幙揑偵屄恖偺摿惈偱偁傞丅偟偐偟丄偦傟偩偗偱側偔丄枹姶愼幰偲偳傟埵偺愙怗偑偁偭偨偐丄偲偄偆姶愼幰乕旐姶愼幰偺椉曽偵棈傓尨場偲偐丄媡偵丄旐姶愼幰偑偳傟埵僂僀儖僗偵姶庴惈偑偁傞偐偲偐丄偳偺掱搙拲堄傪偟偰偄偨偐丄偲偄偆旐姶愼幰懁偺尨場傕 兯偺僶儔僣僉偵婑梌偟偰偍傝丄峏偵偙傟傜偼峴摦惂尷傗専嵏丒妘棧偲偄偭偨幮夛惌嶔偵傕塭嬁偝傟傞丅偙偆偄偭偨丄偁傝偲偁傜備傞尨場偵傛偭偰 兯 偲偦偺僶儔僣僉僷儔儊乕僞 k 偑寛傑偭偰偄偰丄偦傟偱傕姶愼偡傞偐偳偆偐偵偼嬼慠惈偑巆傞丅偦傕偦傕姶愼偟偨偐偳偆偐丄偲偄偆偺偼鑷抣尰徾偲偟偰濨枂偝偑柍偄偺偱偁傞偐傜丄偦傟偱傕巆傞嬼慠惈傪婰弎偡傞偺偼儀儖僰乕僀僾儘僙僗偩傠偆偲偄偆偙偲偱丄偦偺僷儔儊乕僞偑 兯 偲偝傟偨丅
堦師姶愼幰偑姶愼偝偣偨擇師姶愼幰偺悢偑懡悢偺堦師姶愼幰偵偮偄偰敾偭偰偄傞応崌偵偼丄偦傟傜偺悢偺暘晍偑摼傜傟傞丅傕偟傕擇師姶愼幰悢暘晍偑億儚僢僜儞暘晍偱偁傟偽丄兯 偵偼暘晍偑柍偔偰丄偦偺億儚僢僜儞暘晍偺僷儔儊乕僞偑嵞惗嶻悢 R 偲偟偰妋掕偡傞偑丄暘晍偑偁傟偽丄偦偺暯嬒抣偑嵞惗嶻悢偲偟偰寛傑傞丅兯 偺暘晍傪僈儞儅暘晍偲偡傟偽丄擇師姶愼幰悢偺暘晍偼晧偺擇崁暘晍偵側傞偺偱丄偙偺暘晍宍偱娤應偝傟偨擇師姶愼幰悢偺暘晍傪昞尰偱偒傟偽丄兯 偺暘晍偑摼傜傟傞丅偙偺儌僨儖偺傕偆堦偮偺摿挜偼丄擇師姶愼幰悢偺暘晍偑億儚僢僜儞暘晍傛傝傕嫹偔側傞偙偲偼尨棟揑偵偁傝摼側偄偲偄偆偙偲偱偁傞丅
億儚僢僜儞暘晍偲偄偆偺偼丄惗婲妋棪偺嬌傔偰掅偄帠徾傪堷偒婲偙偡帋傒偑懡悢夞峴傢傟偨帪偵丄偦偺帠徾偑壗夞婲偒傞偐丄偲偄偆妋棪暘晍偱偁傞丅僷儔儊乕僞偼偦偺惗婲妋棪亊帋峴夞悢=暯嬒偺惗婲帠徾悢偱偁傞丅廬偭偰丄偁傞忦審傪枮偨偡愙怗偑偁傟偽憡摉崅偄妋棪偱姶愼偝偣傞偲偄偆傛偆側姶愼徢偵偼摉偰偼傑傜側偄応崌偑懡偄敜偱偁傞丅偦偺傛偆側応崌偵偼愙怗夞悢偑偦偺傑傑屄恖揑嵞惗嶻悢偲側傞偑丄擇師姶愼幰悢偺暘晍偼偦偺暘晍偵嬤偄傕偺偲側傝丄嬌傔偰婯懃揑側惗妶傪嫮梫偝傟偰偄傞廤抍偵偍偄偰偼億儚僢僜儞暘晍傛傝傕嫹偔側傝摼傞丅偟偐偟丄幚嵺偵夁嫀偺姶愼徢傪挷傋傞偲偦偺傛偆側帠偵偼側偭偰偄側偄丄偲偄偆偺偑偙偺榑暥偺傕偆堦偮偺懁柺偱偁傞丅媡偵尵偊偽丄姶愼妋棪偑侾偵嬤偄傛偆側愙怗忬嫷傪摨掕偡傞偙偲偑偱偒側偄丄偲偄偆帠傕堄枴偟偰偄傞丅
傕偆堦偮丄偙偺峫偊偺柺敀偄張偼敪徢偲偼娭學柍偄偙偲偱偁傞丅偮傑傝丄敪徢偲偄偆偺偼昦懺偑偁傞鑷抣傪挻偊傞応崌傪巜偡偩偗偱偁偭偰丄偦偆偄偆堄枴偱偼丄晄尠惈姶愼幰偵懳偡傞儌僨儖傪峫偊傞忋偱嶲峫偵側傞偐傕偟傟側偄丅
乮捛壛忣曬乯 COVID-19偵偮偄偰偼丄師偺榑暥偑尒偮偐偭偨丅 F.Wong et al.,"Evidence that coronavirus superspreading is fat-tailed",PNAS,vol.117,no.47(November 24,2020),https://www.pnas.org/content/117/47/29416丅偳偆偄偆暘愅傪偟偨偺偐傑偩椙偔敾傜側偄偑丄COVID-19 偱偼晧偺擇崁暘晍傛傝傕暘晍偺悶偑挿偄偦偆偱偁傞丅晧偺擇崁暘晍偼丄k<1偱偼丄巜悢娭悢揑側悶偩偦偆偩偑丄幚嵺偺暘晍偼 傋偒忔揑側悶偩偦偆偱偁傞丅儀僉偼-1乣-2丅暘晍偦偺傕偺偼 僷儗乕僩暘晍偱嬤帡偱偒傞丅偙偺暘晍偺尦偲側傞偺偼 兯 偺暘晍偲偄偆傛傝傕丄姶愼娫妘乮generation time乯偺暘晍偩偦偆偱偁傞丅偦傟偑丄僈儞儅暘晍偱偁傞偙偲偐傜偔傞丅偙偺曈偺棟孅傕傑偩傛偔敾傜側偄丅堷梡暥專偵拞崙奜弶婜偲崄峘偱偺 SSE 帠椺偺曬崘偑偁偭偨丅
丒丒丒徚柵妋棪偵偮偄偰偺寁嶼丒丒丒
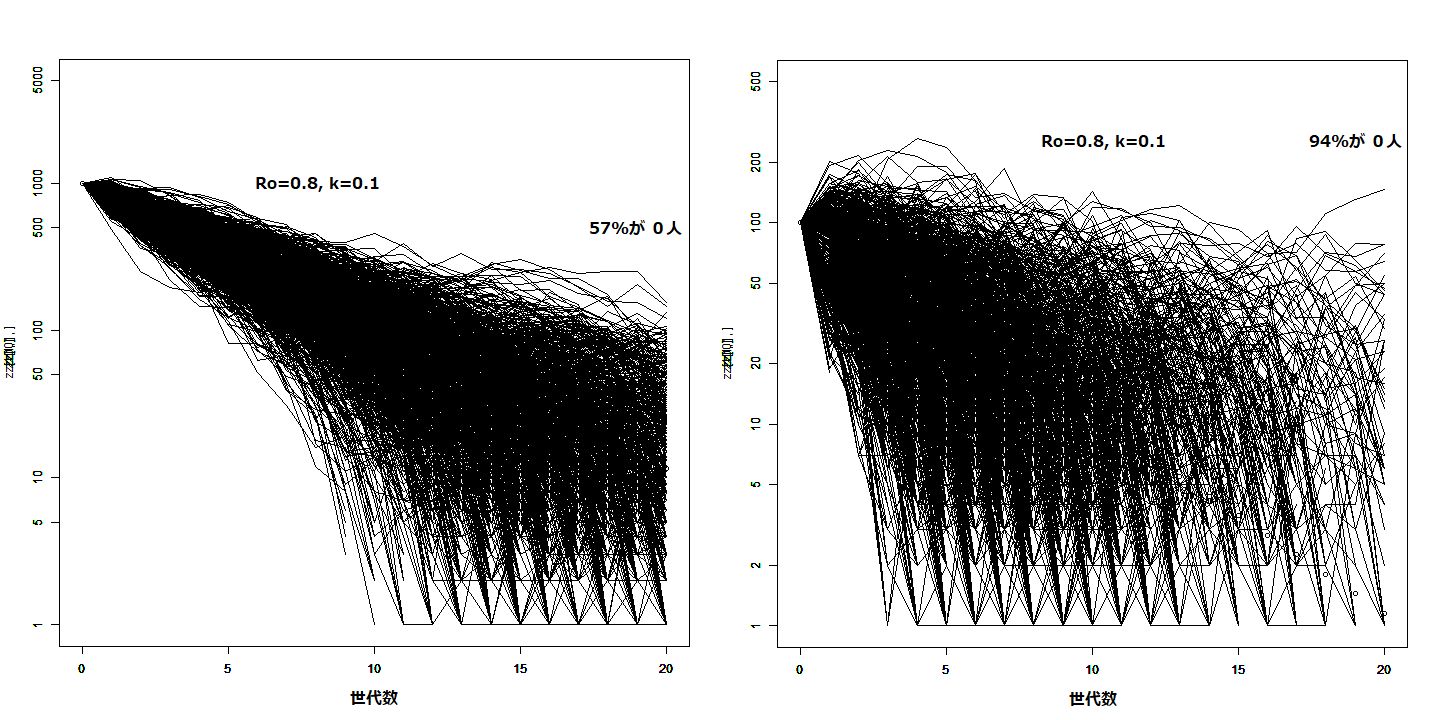
僔儈儏儗乕僔儑儞偵傛偭偰丄k=0.1 掱搙偺戝偒側嵞惗嶻悢偺暘嶶偑偁傞応崌偵傕 姶愼幰悢 100恖埲忋偱偁傟偽丄寛掕榑揑旝暘曽掱幃偱姶愼奼戝偑婰弎偱偒傞偙偲偑敾偭偨丅偦傟埲壓偺応崌偼妋棪揑偵庢傝埖偭偰寁嶼偟偨曽偑惓妋側攃埇偑弌棃傞丅偲傝傢偗廳梫側偺偼丄偳傟埵偺姶愼幰悢偵払偡傟偽姶愼偑姰慡偵廔懅乮姶愼幰 0 乯偡傞偺偐丄偲偄偆帠偱偁傞丅偙傟偼丄偦偙偐傜壗悽戙偐偺姶愼僾儘僙僗傪宱偨屻偵丄姶愼幰偑 0 偵側傞妋棪偑偳偆側傞偐丠偲偄偆宍幃偱偟偐摎偊傜傟側偄丅 悽戙悢傪柍尷戝偵偟偨応崌偺摎偊偼 Lloid-Smith 偺榑暥偺恾b 偵偁傞捠傝偱偁傞偑丄幚嵺偵偼桳尷偺悽戙悢偑栤戣偵側傞偺偱丄嵞惗嶻悢偑 1 埲壓偱傕姰慡徚柵傑偱偼峴偐側偄応崌偑惗偠傞丅偦偙偱丄5悽戙乮堦儢寧庛乯偲20悽戙偵偮偄偰寁嶼偟偰傒偨丅斾妑偲偟偰偼丄k亖柍尷戝乮嵞惗嶻悢偺暘嶶偑柍偄乯偺応崌偺懠偵丄寛掕榑揑旝暘曽掱幃偺応崌傕寁嶼偟偨丅偨偩偟丄偙偺応崌姶愼幰悢偑惍悢偵側傜側偄丅1 恖埲壓偵側傟偽丄徚柵偲偟偰夝庍偟偰傕傛偄偩傠偆偑丄偙偙偱偼 1 恖埲壓偺応崌偵偼侾偐傜偦偺悢傪堷偄偨妋棪偱徚柵偡傞偲夝庍偡傞丅偮傑傝 0.3 恖偵側傟偽丄徚柵妋棪傪 0.7 偲夝庍偡傞丅寢壥傪暘晍恾偱帵偟偨丅姶愼懳嶔傪尩偟偔偟偰姶愼幰悢傪彮側偔偟偰偄傞帪偵偼嵞惗嶻悢 Re 偼 1 埲壓偱偁傞偑丄偳偙偐偱懳嶔傪娚傔傟偽 1 傪挻偊傞丅Re亖侾傑偱娚傔偨忬懺傪堦儢寧懕偗偰丄姶愼幰偑嫃側偔側傞妋棪傪 0.9 偵偡傞偵偼丄2恖埲壓偵偟側偔偰偼側傜側偄丅係儢寧 Re亖侾傪堐帩偡傞偮傕傝側傜偽丄10恖埲壓偱戝忎晇偱偁傞丅
姶愼幰悢偑100恖埲壓偵側偭偰偔傞偲丄寛掕榑揑旝暘曽掱幃梊應偡傞偙偲偑擄偟偔側傞丅嵞惗嶻悢亖0.8丄暘嶶僷儔儊乕僞 k=0.1偺応崌偱偺丄弶婜姶愼幰悢亖1000恖偲丄100恖偺応崌偱丄20悽戙妋棪寁嶼乮1000夞寁嶼乯偟偨傕偺偱偁傞丅堦杮偺慄偑偦傟偧傟幚尰壜擻側姶愼幰悢偺悇堏傪昞偡丅100恖掱搙傑偱偱偁傟偽丄巜悢娭悢揑尭悐乮仜報乯偱嬤帡偱偒偦偆偱偁傞偑丄偦傟埲壓偵側傞偲丄梊應暆偑峀偔側傝偡偓傞丅