2023.12.26
『ディープラーニングAIはどのように学習し、どのように推論しているのか』 立山秀利(日経BP)
図書館で探して借りてきた。中学生でも判るように簡単な例を説明している。実に明解である。内容も重要なことだけに絞られていて、理路整然としている。4章までがニューラルネットワークの説明で、5章が学習方法の説明、6章が画像認識のやり方の説明で、ここでは Convolutional Neural Network (CNN)が主役となる。7章は Google Colab という Python ベースのネット上のアプリを使って、実際に画像分類のプログラムを構成して実験している。8章は自然言語処理のやり方の説明、9章は7章と同様に、実際にプログラムを構成して実験しているが、学習はやっていない。付録には必要最低限で Python の文法が説明してある。第8章:自然言語処理
自然言語処理の場合には、入力データとしての単語をどう表現するのか、がまず問題となる。word2vec というアルゴリズムで、その単語の周囲にどんな単語が来るかという確率で表現する。
具体的には図8-3-04のような3層のニューラルネットで学習させるというのだが、これはちょっと単純化しすぎていて理解に苦しむ。ネットで word2vec について調べてみたが、具体的にどうやっているのかについての説明が見当たらない。考え方と応用の説明しかない。ただ、ちょっと調べると、Skip-Gram法(Continuous Skip-Gram Model)といって、単語に対して周囲にどの単語が来るのかの確率を求める方法と、CBOW(Continuous Bag-of-Words Model)といって、周囲の単語から隠された単語を予測させる方法があるらしい。この本では後者が説明してあることになる。
良さそげな説明が見つかった。『Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力』
CBOWを例に採る。特定の単語(全単語の内 j 番)を含む文例を沢山集める。次にそこから特定の単語を除いたその近傍の単語だけ(全単語の内 k 番とする)を取り出して入力とする。形式は全ての単語数だけの次元 v のベクトルであり、個々の単語は自分の次元において 1 となり、他の次元は 0 という単純な v 次元ベクトルである。(one-hot ベクトルというらしい。)これに n 個(任意)のノードから成る隠れ層を対応させる。だから、その結合係数 W1 は v×n 個(行列)となる。なお、これは線形結合である。隠れ層からはやはり線形結合で v 次元のベクトルが出力される。従って、結合定数 W2 は n×v 個(行列)となる。
これ以上詳しくは書いていないし、元論文にも書いていない(更に元を辿ればよいのだが)ので、以下は僕の想像である。記述の都合で、W1 を W と表記し、W2 をW' と表記する。教師データは、特定の単語(ここでは j 番とする)を表す one-hot ベクトルである。一つの入力単語(k 番)からの隠れ層ベクトルへの寄与は、単に W の第 k 行の n 次元ベクトルであるが、 k は沢山あるし、その頻度も異なるので、特定の周辺単語 k の頻度分布を a[j,k] と表記すると、それらについての平均(continuous というのは単語 j からどれくらい離れているかについての事らしい)から、隠れ層ベクトルは j について、
Hj[i]=Σk W[k,i]a[j,k]
となる。Hj の次元は n で全単語数 v よりもかなり小さい(1000のオーダーらしい)。a[j,k] を j 番目の v 次元ベクトル Xj[k]=a[j,k] を v 個並べたものと見なせば、線形オードエンコーダ(主成分分析)によって、Xj[k] を小さい次元 n の空間(潜在ベクトル空間)に射影したものと見ることができる。これと W’ を掛けるのであるから、出力層は、
Oj[m]=Σi W'[i,m]Hj[i]
となるが、更に Oj[m] を X の空間に変換して、
Yj[p]=Σm a[p,m]Oj[m]
として、
B[p,i]=Σm a[p,m]W'[i,m]
と置き換えてみると、結局、
Yj[p]=Σi,k B[p,i]W[k,i]Xj[k]
となり、i については小さな次元数 n を設定して、この Yj を元の Xj に出来るだけ近づけるようにするわけだから、全ての j についての評価関数は、自乗和であれば、
L=Σjk {Oj[k]-δ(j,k)}^2
であるが、この代わりに、
L=Σjk {Yj[k]-Xj[k]}^2
ということにすれば、正に線形オートエンコーダ(主成分分析)である。また、元々の one-hot ベクトルから見れば、単語同士の近接性を取り出しているので、テキスト分析の共起分析と同じである。つまり、単語 j 近傍単語の頻度分布という v 次元ベクトルは単語同士の使われ方が似ていれば、近くに来るので、v 次元ベクトルと言えども、その一部の n 次元空間に射影すれば、単語同士の関係を表現できるような潜在空間を作ることが出来て、それが単語の分散表現なのである。なお、行列 a[j,k] が正則であれば、Skip-Gram法も同じ事になる。実際には多少違うようなので、これはおそらく評価関数の選択の差と思われる。 開発した本人も驚いたらしいのだが、この分散表現を使うと、単語の意味の足し算や引き算ができる。有名な例らしいが、「king」-「male」+「female」=「queen」という関係が非常に良い近似で成立するのである。線形演算だからだろう。
このサイトでの説明で気づいたのであるが、このやり方だと、正反対の意味を持つ単語同士が近くなってしまう。これを解決するためには、もっと広い文脈について Out[m] を決める必要がある。しかし、それでも論理的に逆の意味であることは完全には表現できていない。この辺が AI で言語処理をするときの限界の一つかもしれない。
実際にどんなものか?については例がある。
元の本に戻る。
word2vec では、単語の繋がりの前後関係が学べない。また文章の長さが変わると対応できない。これらを取り込むための仕組みが Recursive Neural Network (RNN)である。2つ目以降の単語については、その一つ前までの情報を使う。したがって、ノードにはその出力からのフィードバック入力が追加されている。これは元々あった入力とは別なので、重みも別である。
翻訳では、元文章からエンコーダーでも翻訳先文章生成のデコーダーでも使われる。これが sec2sec というアルゴリズムである。エンコーダでは、次々と送り込まれる単語(あらかじめ word2vec で分散表現になっている)に対して、それまでの単語列に対応する分散表現(これを「特徴」と呼ぶ)を出力していく。(結局この「特徴」というのは、「学習後には」次に来る単語の分散表現に近いものになっているということなのだろう。)なお、RNN のパラメータは「学習」後には固定されている。エンコーダで出力された最後の「特徴」、つまり文章全体の特徴がデコーダに入力されて、最初の単語が選ばれる。その後は次々と RNN に入力されてそれぞれが単語を生成する。勿論、この生成される単語というのは、翻訳先の言語における分散表現である。デコーダにおいても RNN のパラメータは学習後に固定されている。学習は勿論人間の作った原文と訳文を正解として使うのであるが、このスキームでは、翻訳の際に元文の単語を直接参照することはないから、非効率的だろうと思う。
これを改善したのが Attention 機構である。sec2sec ではデコーダはエンコーダが最後に出した文章の特徴だけを使うので学習にかなりな負担がかかるが、Attention ではエンコーダの途中経過の特徴全てを使う。その使い方というのは、これまで出力した翻訳先の文章の分散表現と翻訳元の途中段階での分散表現の内積を採って、類似性を判断し、もっとも類似性の高い段階での翻訳元単語に注目して、次の単語の候補とするのである。
この考え方は特徴抽出(エンコーダ)や文生成(デコーダ)それぞれの内部でも使われていて Self-attention と呼ばれる。自らの文の途中経過(単語)も類似度の判別に利用する。これは分散表現が近ければ次に来る確率が高いからである。なお、翻訳時のように他の文章の単語に注目する場合を Source-target 型 Attention と呼ぶ。
Transformer では RNN の代わりに、単語の位置情報の依存関係を把握するための機構を使う。したがって、Positional Encoding → Self-attention という流れになる。RNN を使う場合には順序だって計算する必要があるが、Transformer では時間的な順序を追う必要が無いので並列計算ができる、というのが大きなメリットである。
2018年に Google が開発した BERT は Transformer を 多く並べて繋いだ構造を持つ。更に、事前学習として、単語の穴埋め問題だけでなく、2つの文章の意味的な繋がりについても教師付き学習を行う。 つまり、文章全体を考慮に入れて、その場面での最適な分散表現(最後の単語の場合は次の単語予測)を出力するように学習されていることになる。BERT は他の機能(翻訳では翻訳文生成)を接ぎ木されて、全体としての再学習を受けて使われることになる。
ということで、結局の処、Transformer の具体的な仕組みは判らないままである。そこで、元論文もあるが、またネットを探して解説記事を見つけた。大変よく出来た解説なので、すこしだけ縮約して紹介させていただく。
【詳説】Attention機構の起源から学ぶTransformer
ウィケンズの情報処理モデルという認知モデルがあって、感覚入力から運動出力に至るまでのプロセスを、左から順番に、感覚処理、知覚、記憶・認知、反応選択、反応実行という段階に分け、各々に「注意資源」から何らかの処理を受ける構造をしている。つまり人間においても、注意機構が効率的な情報処理には必須となっている。
Attention は3つの分散表現ベクトルで記述できる。Query は関連性を探索する元の単語、Key と Value は探索対象の元データで、Key は用途、Value は本体の単語である。機械翻訳で説明すると、Source-target 型 Attention では、Query が翻訳側の現在の単語、Key と Value は翻訳元の全ての単語である。Self Attention では全て翻訳側の単語になる。
Attention(Q,K,V)=Softmax((QK)/√dk)V :dk は Key の次元である。
(QK) は Q、K それぞれを継起する単語数の次元で行列化(つまり単語の継起順に行毎に分散表現を並べた行列)としたとき、それらの行間の内積を採った行列である。内積が大きければ、それらのベクトルが似ているということだから、これは自然な考え方である。V は実際に候補となる個々の分散表現ベクトルを並べた行列であるから、ここでは K と同じであるが、概念としては区別される。結果として、Q の各単語に対して、関連性を考慮するように V の各単語から線形結合された新たな分散表現が割り当てられていることになる。「Query(=問い合わせ)の各トークンに対応する、Value(=値)の重要度をKey(=鍵)を使って内積と Softmax 関数で取り出し、Vの行ベクトルの線形結合として出力したもの」と解釈できる。
Transformer は、それ自身が Encoder→ Decoder というモデルであって、元文から縮約された次元の特徴ベクトル(隠れ層、潜在空間)を作り、それを使って、単語を予測する、という意味で、sec2sec とは勿論であるが、VAE 等とも同じ構造である。(とはいうものの、計算の殆どは縮約された分散表現の空間で行われている。)Attention 機構だけだと、文章中での単語の継起順序という情報が足りないために、RNN が使われてきたのであるが、Transformer ではこの単語の継起順序の情報を単語の分散表現の中に埋め込んでしまうことで、順序情報を考慮している。これを可能にするのが Positional Encoding で、正弦関数と余弦関数を用いて、(単語を分散表現に変える)Embedding 層からの行列に位置情報を埋め込んだ行列を足し合わせる。(注)足し合わせるだけで出来るというのは驚きであるが、勿論学習過程で最適化されるからであろう。
Transformerを構成する最も革新的な要素が Multi-Head Attention 機構であって、下記のように、多種類の Attention head を並列して計算した上で、それらを結合(Concat)している(実際上は平均)。
MultiHeadAttention(Q,K,V)=Concat(head1,head2,⋯,headh)Wo
where headi=ScaledDotProductAttention(QWQi,KWKi,VWVi)
Scaled Dot-Product Attentionは名前の通り、内積に基づく注意計算を行うが、それ単体では学習パラメータを持たず、学習によりチューニングできないため、直前に学習パラメータを持つ Linear 層を設けて多種多様な特徴部分空間における注意表現の学習を可能にしている。学習により獲得された注意表現を可視化すると、各ヘッドが異なる注意表現を獲得していることが確認されている。ヘッドを複数並列にすることでモデルの表現能力を高くしている。このように、文章全体にわたって複数の注意表現の獲得が可能な Attention 機構が、Multi-Head Attentionである。head の数は任意であるが、8個位が適当である。
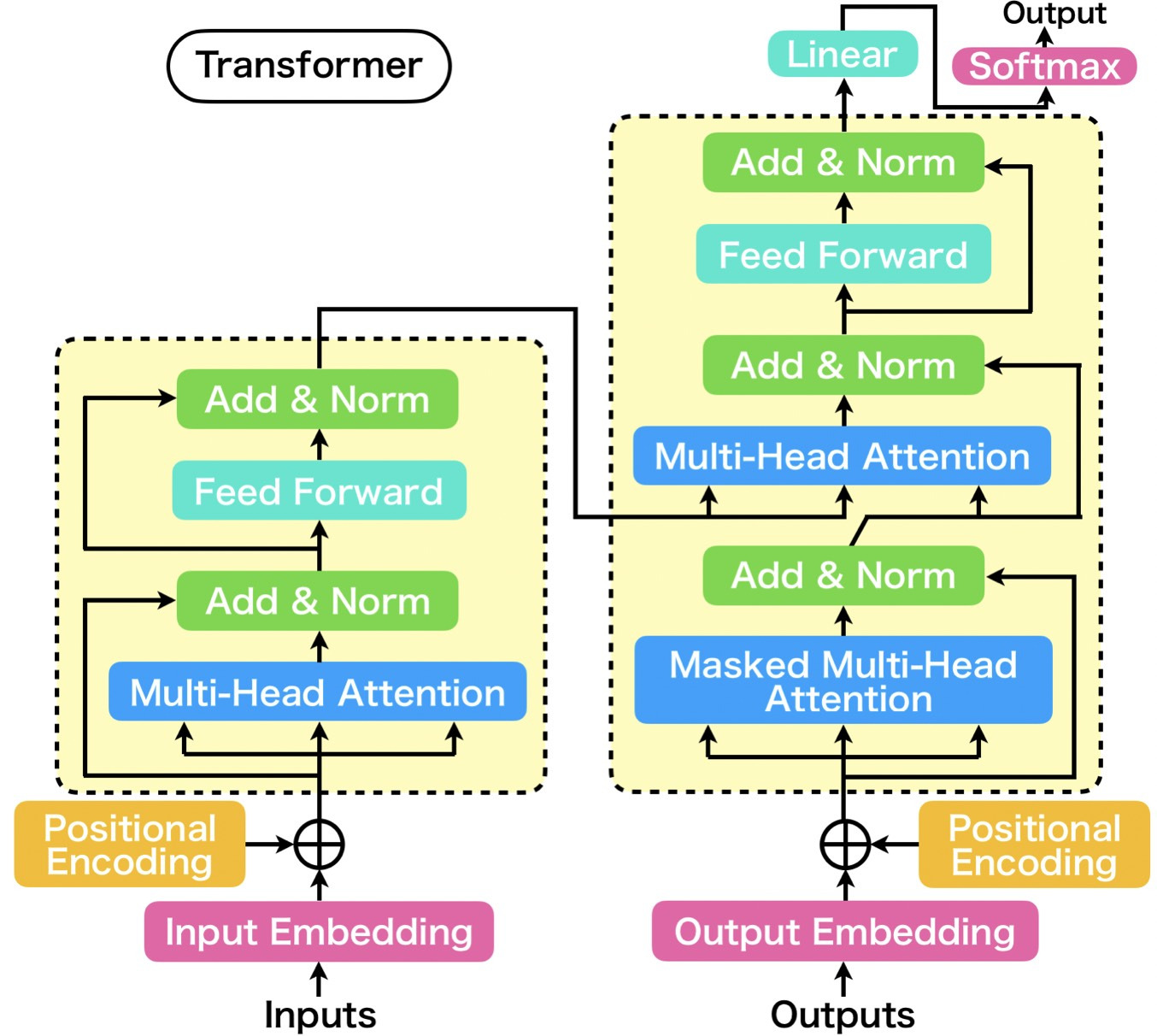
Transformer の説明には 元論文の図が使われている。新たな入力を処理する Encoder 部分(左側)と、自分の出した過去の出力と Encoder 出力を入力として分散表現を出力する Decoder 部分(右側)から成り立つのだから、見方によっては、RNN の構造を引き継いでいるようにも見える。多分、RNN として見たときの入力の単位が文章全体とか、大きいということなのだろう。
Transformer の Encoder 部分と Decoder の自己入力部分はほぼ同じで、最初の分散表現獲得→位置情報付与→Multi-Head Attention→後処理(総結合層)である。Decoder には途中から Encoder の出力が入って、自己入力処理の出力と合算されて、再度まとめて Multi-Head Attention→後処理(総結合層)という処理を受ける。なお、Multi-Head Attention→後処理(総結合層)は6回繰り返される。
なお、もうひとつ判りやすい説明があった。
Transformer は画像に対しても、一般的な CNN の代わりに使うことができる。画素を並べるのと単語を並べるのとの違いだけである。
{kind=link}