なぜこんなダイアグラムで2次微分までできてしまうのか、大多数の人は不思議に感じると思うので、できるだけ分かりやすく説明してみよう。Webに紹介されていた要旨は簡潔に書かれていて、式の一部にタイプミスがあるようだ。「科学計測のための波形処理」では原理と係数表しか書かれていない。したがって、自分なりの理解の上での説明なので間違っている可能性もあるので、気がつかれた方はご指摘をお願いしたい。
平滑化のためのデータ点数を2m+1とし、x座標は-mからmまでとする。生データの座標とn次の多項式による近似曲線を以下のように表す。
次に生データと近似関数の差の自乗和Sを作り、これが最小となるように近似曲線のパラメータを決定する。
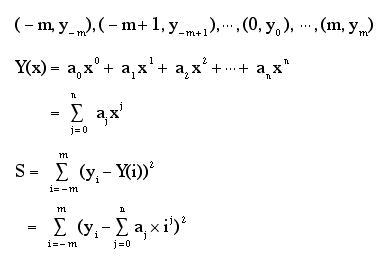


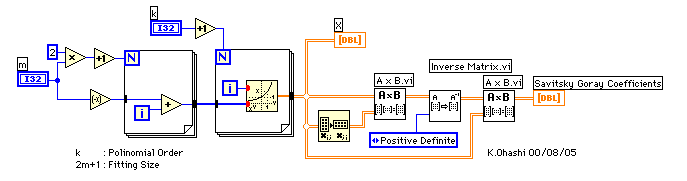
右辺を計算することにより、n次近似関数の係数a0からanを求めることができる。2m+1個のデータの中心では、近似関数のxは0であるからデータの近似点はa0となる。d次の微分はn次近似関数のd次導関数を求めてx=0を代入すれば良いので、d!・adが求めるd次微分値となる。紹介したダイアグラムでは2次微分までしか考慮していないが、3次微分の場合は4行目に係数として6(=1*2*3)をかけたものを使用すればよい。
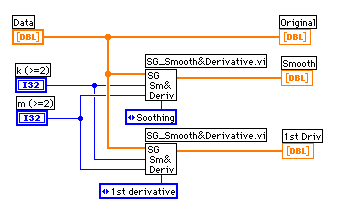
この方法の利点は、求めたい近似値やd次微分値に応じてマトリクスから行を取り出すことにより、フィルターとして生データに作用させることができる点である。
生データから2m+1個ずつ切り出して処理を行っても良いのだが、LabVIEWで用意されているコンボリューション関数を使用したほうが動作速度の点で有利だと思われる。LabVIEWに用意されているコンボリューション関数はX, Yの配列を入力するとコンボリューション配列X*Yを出力する。オンラインヘルプでは添え字にタイプミス(LV5では直っているかな?)があるが
nをXの要素数、mをYの要素数として
iは0 からn+m-2までの範囲で以下の式で表される。

コンボリューション配列X*Yの要素数はn+m-1個になるので、10個となる。
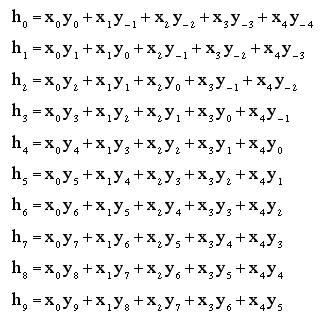
yに関し0から5の指標を持つもの以外は0であることに注意すると、h4, h5だけが端部の影響のない要素となっている。
不完全な部分がジャマな場合は、コンボリューション配列の前後n-1個は削除する必要がある。
また、h4, h5のx, yの指標を見るとxの指標が大きくなるとyの指標は小さくなっていることがわかる。この指標の順番は非対称なフィルターをかける場合に注意が必要となる。具体的な対応方法としてはXの配列を逆順にした後コンボリューションの入力に接続すれば良い。
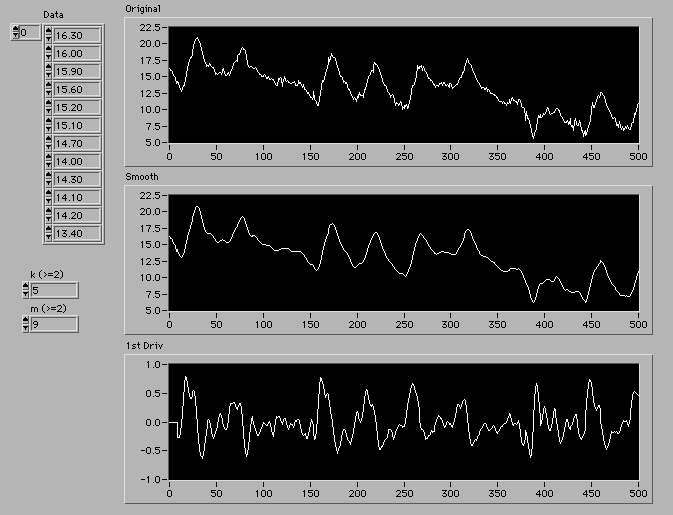
以上で説明を終わりにするが、実際に生データを処理した例を示しておこう。
鹿児島大学教育学部の気温連続測定・自動送信システム「CatRace」(http://www-rk.edu.kagoshima-u.ac.jp/catrace/)からいただいた鹿児島大学教育学部の戸外の気温データを例にとろう。このデータは30分おきの測定で1ヶ月ごとにファイルにまとめられているので、1日が48点、1ヶ月で1488点のデータとなっている。気温データのスムージングにどれほど意味があるかは不明だが、とりあえず、5次関数、19(9*2+1)点で平滑化と平滑化1次微分を行ってみた。平滑化のパラメータは現象に応じて各自で判断して使っていくしかないようだが、処理後のピーク値が生データとどの程度変化するかが一つの目安になるだろう。一般的に使われている移動平均に比べれば、原理的にピーク値の変化は少ないはずだ。