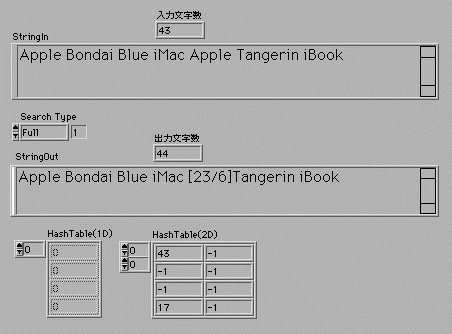
今回はハッシュ関数を使ってLZ77圧縮機能を作成しよう。
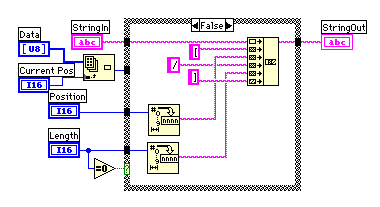
過去に出てきた文字列を[Position/Length]で置き換えて表示するプログラムだ。下のパネルの絵では2回目のApple
が[23/6]に置き換えられている。これは23文字前に6文字分の長さで以前に使われていた文字列であることを示している。
文字列検索はFullとQuickの2種類で、Fullでは最近の10個の発生カ所を記録するために256×10の2次元配列を使用しているのに対し、Quickでは最新の1個を256の長さの1次元配列に記録する。
配列の初期化を文字列検索の種類で変えているのでループの左側がやや込み入っている。ループの中では、ハッシュテーブルを使った検索と文字列の生成、ハッシュテーブルの更新が行われている。終了条件のためのカウンターは一番下のシフトレジスターで行なっているのだが、文字列が見つからない場合には+1で、文字列が見つかった場合には+3以上のカウントアップになるのでやや複雑になっている。
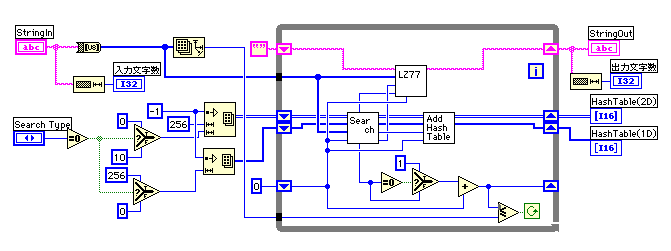
ハッシュテーブルの更新では、ハッシュテーブルからハッシュ値に対応する行を取り出して、最新のポジションをその配列の先頭に加えた1次元配列を作り、要素の置き換えを行なっている。1次元配列のハッシュテーブルでは単に要素の置換だけでOKなので特に説明はいらないだろう。
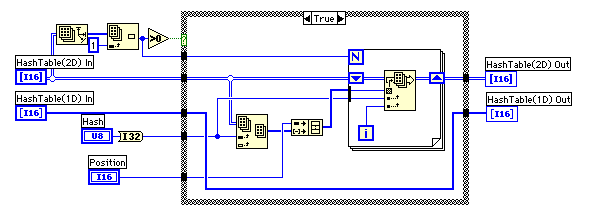
ループの左側では現在のポジションから3文字を取り出して、ハッシュ関数でハッシュ値を求めている。ハッシュテーブルは-1で初期化されているので2次元のハッシュテーブルを使うときには記録されているポジションが-1になるまで外側のループが動作を続け、最長の一致部分を探索する。1次元ハッシュテーブルの時はループは1度しか動作しないようになっている。一致部分の探索は、内側のループで一文字づつ比較を行うことにした。ハッシュ値が衝突してなければ、3文字は一致するはずなのだ。2次元のハッシュテーブルを使っているときには最も長い一致部分をシフトレジスタに残すことにした。このサブVIの出力はハッシュ値と、一致したポジションと長さの情報だ。
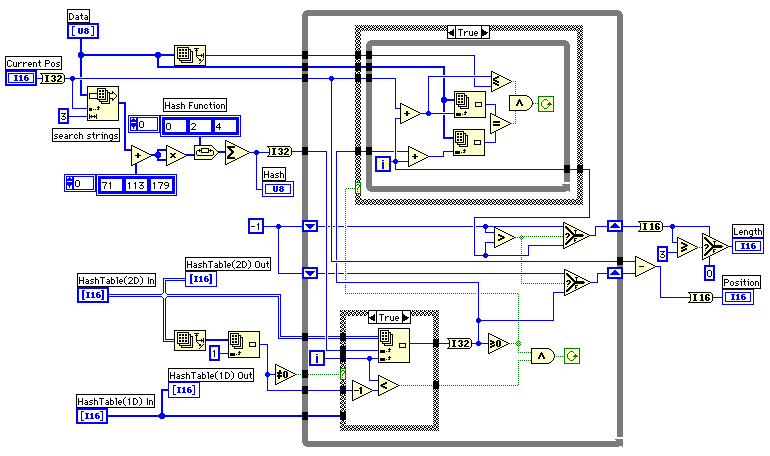
文字列の生成は一致長が0のときには現在の位置の文字を一文字追加し、一致した部分は分かりやすいように位置と一致長を文字列の中に埋め込むようにした。
動作時間が実用的な範囲に収まっているかどうかが問題なので、1万4千字の英文で動作させ、プロファイルをかけてみたところ、正直に言って、1次元配列で検索を手早くすませようとした方が遅かったのは驚きだった。2次元配列の方がヒット率が高いためサブVIの実行回数が半分近くになってサブVIの動作速度向上を相殺していた。文字列の生成のサブVIの動作時間は動作回数が少ないほうが短いので、全体としては2次元配列を使った計算の方が早くなっていたのだ。検索とテーブル作成は0.3秒(300MHzのPowerPC)で済んでいるので、次回以降のハフマン圧縮の速度次第では実用性も出てくるかもしれない。
次回は固定方式のハフマン圧縮を作り始めよう。