難解だった伸長プログラムが前回までで一応出来上がった。今回から圧縮プログラムをこつこつ作り上げていこう。LabVIEWでのプログラミングはブロックを組み立てる遊びに似ている。作り上げたいイメージにしたがって、用意された部品をこつこつ組み合わせていく。完成が近づくにつれて、あるいは、部品の都合に応じて完成のイメージが修正されていくところも似ているかもしれない。
ZIP圧縮ではLZ77アルゴリズムが使われている。伸長プログラムを作りながら見てきたように、圧縮処理済みの原文を辞書として使っていくのが特徴だ。x個前にy個続いている同じ文字列があるとき、その文字列の代わりにx,yで置き換えれば繰り返し同じ文字列を記録しておく必要はなくなる。対象とする文字列の長さは、3文字以上の長さに限定している。1文字では文字の出現頻度で圧縮するハフマン圧縮と同じレベルにしかならないので対象外となる。2文字の場合は、位置と長さと置き換えたことを示す記号を含めて2バイト未満にしないと圧縮のメリットが出ないので、対象とするのは難しい。3文字でも位置を示す数値が大きくなると1バイトでは表現できなくなるので不利になるが、位置の数値が小さくし長さの記号を短くしてようやくメリットが出てくる。
圧縮プログラムではこの文字列は前に出てきていたかなと頻繁に辞書を調べなくてはいけないので、"シオリ"の作り方がキーポイントになる。伸長プログラムでお世話になった仕様書にはハッシュを使えば良いという記述はあるのだが、詳細は書かれていない。Cのソースコードを調べようかとも思ったが、それも大変そうなので、まず、ハッシュについて調べてみた。(浪平博人著「データ構造」CQ出版社 ISBN4-7898-3673-8)
ハッシュは、プログラムの専門家にはなじみ深い言葉なのだろうが、私の場合はこれまで使ったことがない。Aというデータに対応させた(a)というデータを、Aから計算によって導いた場所に保存する。例えば、Hash( )という関数を決めておいて、Hash(A)で得られた場所に(a)を保存しておけば、知りたいときにHash(A)を計算して得られた場所を見にいくことにより(a)を得ることができる。
この方法は住所録のように人名と住所を記録して、検索を素早く行いたいときに用いられるらしい。関数計算だけで検索できるため、ソートした状態で記録する必要がない。このためデータの挿入や削除の時にデータ全体を移動・削除する必要もない。しかし、良いことだけではなくて面倒な面もしっかりある。全ての人名に一対一で記録エリアを用意することは膨大な無駄エリアを作ってしまうので、入力は幅広く対応し、出力値は限定された領域のみになるような関数をHash関数として選ばざるを得ない。このため、異なる人名で同じ関数値が得られてしまう事態に遭遇してしまう。これを教科書では衝突と言っているが、さまざまな対応の仕方がある。リストを使って衝突したものを次々につなげる方法や別な領域に衝突したデータを規則的に格納していく方法などが書かれている。
今回の用途は"シオリ"なので、衝突していたらマッチしない結果になるだけなので、気にしないことにした。
ハッシュ関数は、次のような性質を持っていることが望ましい。
1)計算が簡単なこと、2)均一な密度で出力されること、3)入力のわずかな変化に敏感に出力が変わること
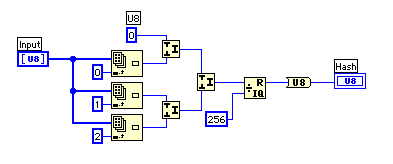
例として教科書に上げられている方法は、剰余演算の余りを使うという手だ。8ビット整数の配列に変換された3文字を32ビットの数値にして剰余演算を行う。下の例では出力を256個に圧縮したいので256で割っているが、この場合、結果として3番目の数値が直接出力されるだけなので良くない。"abc"でも"xyc"でも99という出力になる。
自前で考えることにして、次のような関数を作ってみた。3文字それぞれが異なる演算を受けるように加算と乗算を配置した。入力が0の時に出力が0になるのも美しくないので、適当な定数を加算している。
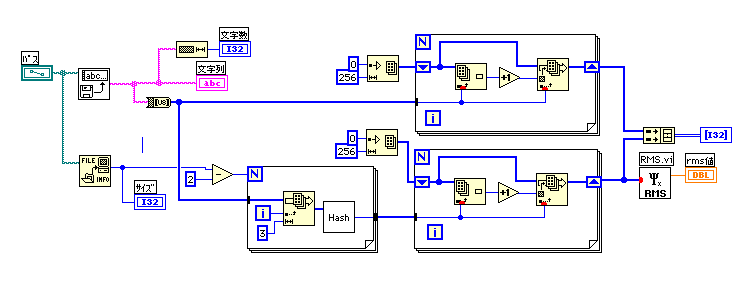
ハッシュ関数としての適性をテストするために、適当な文書を読み込んでハッシュした出力のヒストグラムでRMSを特性値にすることにした。このRMSが小さいほど良いハッシュ関数と考えることにする。
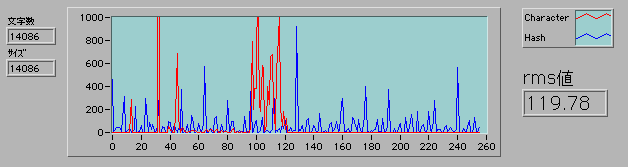
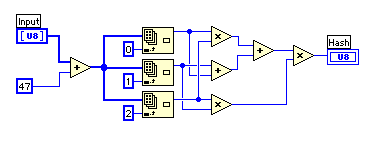
赤線が、読み込んだキャラクター1文字の頻度分布で、青線が3文字ハッシュ後の頻度分布になっている。たくさんピークがあるので、もう少しなんとかならないか工夫してみよう。動作速度のことも考えて配列のまま演算させるようにして、最終的に落ち着いたのが下のダイアグラムだ。
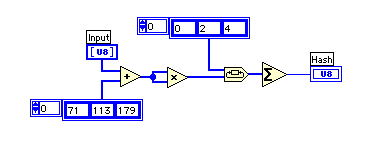
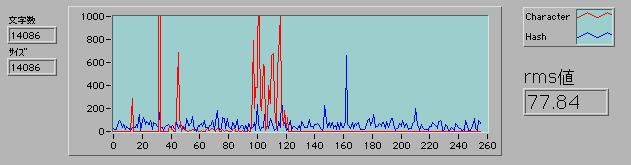
3文字の組み合わせの分布は見ていないのでrms値がどこまで下がるべきものなのか定かではないが、グラフを見ても改善している様子ははっきりわかる。動作速度も重要な関心事で、14084回の実行時間で、0.94秒だったものが0.84秒に下がった。
3文字それぞれに異なる数値を加算することで文字の順序を差別化し、自乗とビットローテーションで撹拌した後に総和をとっている。U8を使っているため桁あふれするが、ここではばらばらにすることが目的だから問題ない。ビットローテーションをなくしてしまうとrms値は84.99になるが、実行時間は短くなり0.78秒になる。速度を取ったほうが良いか、ランダム度を取ったほうが良いのかは完成してから考えても遅くないので、後でもう一度考えてみよう。
今回はハッシュ関数を検討した。次回はこれを使った"シオリ"の作り方を考えてみよう。