慜夞偼屌掕僴僼儅儞僐乕僪偱埑弅偝傟偨僨乕僞傪怢挿偡傞傾儖僑儕僘儉傪尒偰偒偨丅埑弅偵巊偆僴僼儅儞僐乕僪偑巇條彂偱帠慜偵寛傔傜傟偰偄傞偺偱丄僐乕僪偺忣曬傪埑弅僼傽僀儖偵婰弎偡傞昁梫偺側偄偺偑棙揰偩偑丄弌尰昿搙偺崅偄暥帤偵抁偄僐乕僪傪妱傝晅偗傞偲偄偆杮棃偺僴僼儅儞埑弅偺峫偊曽偐傜偡傟偽丄埑弅岠棪偼嵟揔壔偝傟偰偄側偄忬懺偩偲偄偊傞丅椺偊偽丄塸暥側偳偺1僶僀僩暥帤偲擔杮岅側偳偺俀僶僀僩暥帤偱偼8價僢僩扨埵偱尒偨偲偒偺弌尰昿搙偑傑偭偨偔堎側傞偺偱1-143傪8價僢僩丄144-255傪9價僢僩偱昞尰偡傞屌掕僴僼儅儞僐乕僪偼擔杮岅偺曽偑岠棪偑埆偄丅
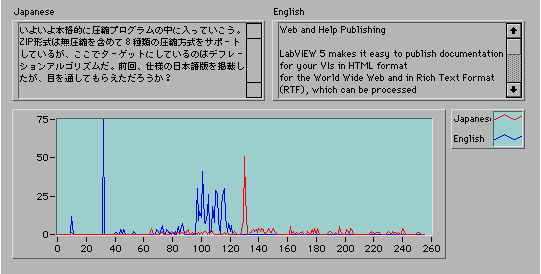
ZIP巇條彂偱彂偐傟偰偄傞傛偆偵僴僼儅儞僐乕僪偼僐乕僪挿傪巜掕偡傞偩偗偱堦堄偵寛掕偡傞偙偲偑偱偒傞丅暥帤丒挿偝僐乕僪偼287屄丄嫍棧僐乕僪偼32屄偁傞偺偱丄扨弮偵梾楍偡傞偲319僶僀僩昁梫偵側傝丄奺埑弅僽儘僢僋枅偵巜掕偡傞偙偲傪峫偊傞偲柍懯偑戝偒偄丅偦偙偱丄僟僀僫儈僢僋僴僼儅儞僐乕僪偱偼丄0偐傜18傑偱偺僐乕僪挿婰榐梡偺僴僼儅儞僐乕僪傪巊偭偰暥帤丒挿偝僐乕僪偲嫍棧僐乕僪傪婰榐偟偰偄傞丅崱擭偺壞偺傛偆偵娋傪偨偭傉傝媧偄崬傫偩T僔儍僣偑傑偩娋偺巆偭偨敡偵傑偲傢傝偮偔傛偆側丄幚偵擲拝幙偺傾儖僑儕僘儉偩丅
壞偺弸偝偵晧偗偢偵VI傪彂偄偰傒傞偲埲壓偺傛偆偵側偭偨丅3價僢僩偺屌掕挿偱巜掕屄悢偺僐乕僪挿傪撉傒庢偭偰丄僣儕乕傪嶌傟偽偄偄偺偩偑丄婰榐偝傟偰偄傞弴斣偑乽16, 17, 18, 0, 8, 丄丄丄乿偲巜掕偝傟偰偄傞偺偱丄偪傚偭偲傗偭偐偄偩丅傑偨丄巜掕屄悢偑4屄偺応崌偼丄愭摢偐傜4屄偺乽16, 17, 18, 0乿埲奜偺僐乕僪偺僐乕僪挿偼侽偱偁傞偲擣幆偟側偗傟偽側傜側偄丅巜掕偝傟偨弴斣偺code偲偄偆攝楍掕悢偲僐乕僪挿攝楍傪僋儔僗僞乕攝楍偵偟偰僜乕僩傪偐偗偰丄弴斣捠傝偺僐乕僪挿攝楍傪嶌傞丅偁偲偼慜夞嶌偭偨僣儕乕傪嶌傞僒僽VI "BuildTree.vi" 傪巊偊偽僐乕僪偑惗惉偝傟傞丅
僐乕僪挿僐乕僪傪巊偭偰暥帤丒挿偝僐乕僪偲嫍棧僐乕僪偺僐乕僪挿傪撉傒庢偭偰偄偔偺偼丄屌掕僴僼儅儞僐乕僪偱傾儖僼傽儀僢僩傪撉傒庢偭偰偄偔偺偲摨偠梫椞偩丅慜夞嶌偭偨VI偺堦晹傪撈棫偟偨僒僽VI偲偟丄偝傜偵僴僼儅儞僐乕僪偺嵟彫價僢僩挿偐傜僨乕僐乕僪傪奐巒偡傞傛偆偵曄峏偟偟偨丅傑偨丄崱夞偼僨僶僢僌偵庤娫庢偭偨偙偲傕偁傝丄嵟戝價僢僩挿傛傝傕戝偒偔側偭偨偲偒偵僄儔乕偱掆巭偡傞傛偆偵偟偨丅
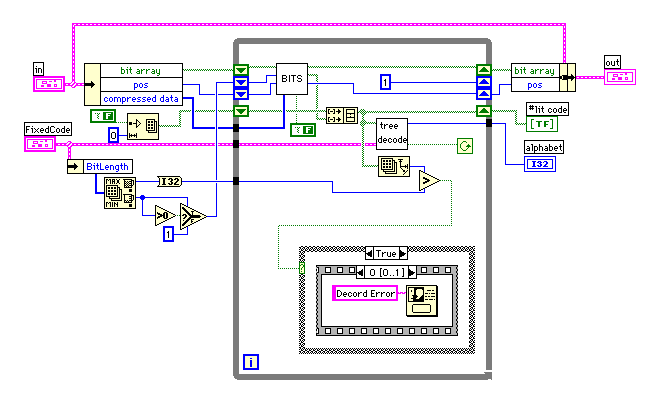
忋偺VI偺拞偱巊傢傟偰偄傞tree_decorder.vi偵偼僶僌偑偁傞偙偲偑暘偐偭偨偺偱丄壓偺傛偆偵曄峏偟偨丅True偺働乕僗偑廬棃偺傕偺偩偑丄#lit code傪悢抣偵偟偨偲偒偵抣偑0偵側傞応崌丄僐乕僪挿偑0偱抣偑0偵側偭偰偄傞傕偺偲僐乕僪挿偑1偱抣偑0偵側偭偰偄傞傕偺偲偺嬫暿偑偮偐側偄丅偙偺傛偆側応崌偵偼價僢僩挿偑奩摉偡傞梫慺傪専嶕偟偰僐乕僪偑堦抳偡傞偐挷傋傞偙偲偵偟偨丅
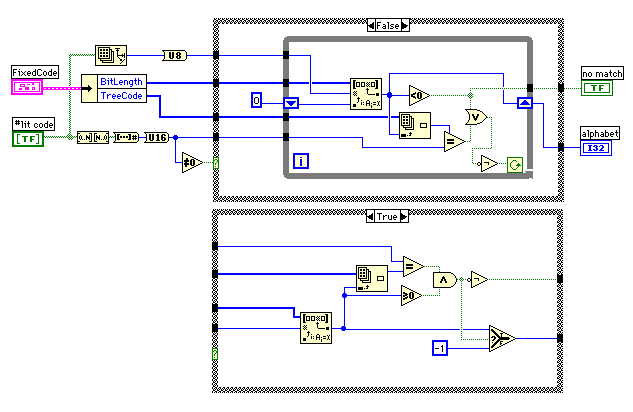
偙偺傎偐偵傕峫偊偑懌傝側偐偭偨VI偑偁傞偑丄師夞偵夞偡偙偲偵偟傛偆丅