いよいよ本格的に圧縮プログラムの中に入っていこう。ZIP形式は無圧縮を含めて8種類の圧縮方式をサポートしているが、ここでターゲットにしているのはデフレーションアルゴリズムだ。前回、仕様の日本語版を掲載したが、目を通してもらえただろうか?
デフレーションアルゴリズムでは、各ブロックごとに圧縮方法を指定することができる。ブロックヘッダーのBTYPEという2ビットで以下の3種類の方法を選択できる。
00 - 非圧縮
01 - 固定ハフマンコード圧縮
10 - ダイナミックハフマンコード圧縮
11 - 予約(エラー)
今回は手始めに、固定ハフマンコード圧縮で圧縮されたデータを伸長してみよう。あまり長いファイルだとわけがわからなくなるので次のような簡単な文字列にした。
Today is fine. Tomorrow will be fine too.
LZ77アルゴリズムでは先頭から文字列処理を進め、処理済みの文字列の中に重複するものが見つかったときには、その文字列を”長さと位置(距離)”で置き換えて圧縮を行う。デフレーションでは”長さと位置(距離)”への置き換えは3文字以上連続する文字列が見つかったときに行われる。今回の例文では、2回目の” fine”の5文字は処理済み文字列の中に重複する部分があるので圧縮がかかる。
デフレーションアルゴリズムでは、LZ77圧縮のあとハフマンコードで圧縮を行う。ハフマンコードがあらかじめ約束事として決められているのが固定ハフマンコード圧縮だ。圧縮しようとする文字列ごとに最適化されていないのでハフマンコードとしては圧縮率は低くなるが、ブロックごとにコードを記録しなくて済む大きなメリットがある。
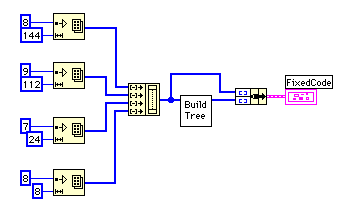
固定ハフマンコードのLiteral Valueの意味付けは、0-255が通常のアスキーコード、256はブロック終了記号、257-287は長さコードになっている。
| Literal Value | Bits | Code Min | Code Max |
| 0 - 143 | 8 | 00110000 | 10111111 |
| 144 - 255 | 9 | 110010000 | 111111111 |
| 256 - 279 | 7 | 0000000 | 0010111 |
| 280 - 287 | 8 | 11000000 | 11000111 |
左上でコード長毎の頻度を数えて、左下で各コード長の最小コードを求める。Literal Valueの順にコード長毎の最小コードから順番にコードを付けていく。
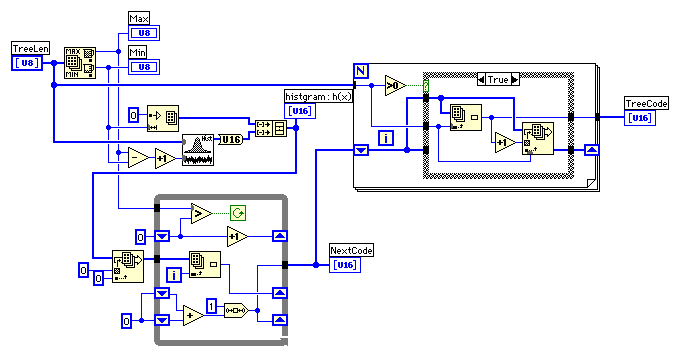
さて、固定ハフマンコードで圧縮されたデータを見てみよう。
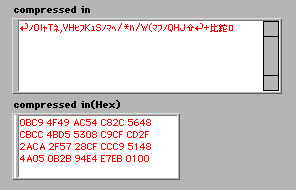
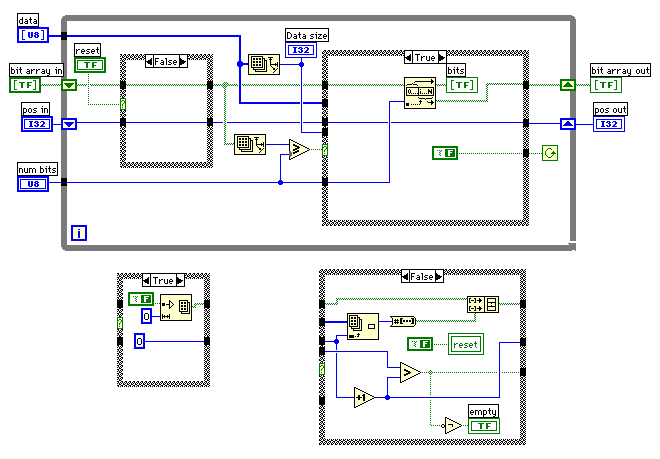
ビット列をバイト単位で表示しているだけなので、これだけ見ていても理解できない。従って、必要な長さのビット列を取り出してくるVIが必要になる。"bit array in"がバッファーの役割をはたし、必要なビット数よりも少ないときには"data"から1バイトづつ取り出して、必要なビット数分だけ"bits"に出力する。
ハフマンコードからのデコードは、先頭ビットからツリーを順にたどって一致するコードを探すものなのなのだが、うまい方法が思いつかなかった。そこでビット列を数値に変換したものでハフマンコード("TreeCode")の配列をサーチすることにした。ただし、デコードしようとする"#lit code"のビット数は事前には分からないため、例えば、9ビットのコードなのに7ビット部分だけを切り取って数値に置き換えると、ハフマンコードの配列の中ででたまたま一致してしまうことがある。これを避けるため、コードのビット長とデコードしようとする"#lit code"のビット数が一致するときのみマッチしたと判断させることにした。
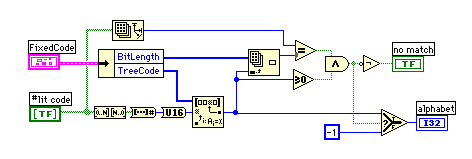
コードの最小ビット長から1ビットづつ追加して、一致するまでチェックを行う。
始めの方で書いたようにLiteral Valueの意味付けは、0-255が通常のアスキーコード、256はブロック終了記号、257-287は長さコードになっている。長さコードの場合、数値に応じて0から5ビット長までの追加ビットを持っているため、引き続きそれらのビットを読み取る必要がある。さらに、距離コードが5ビットの固定長で続き、その数値に応じて0から13ビット長までの追加ビットを持っている。
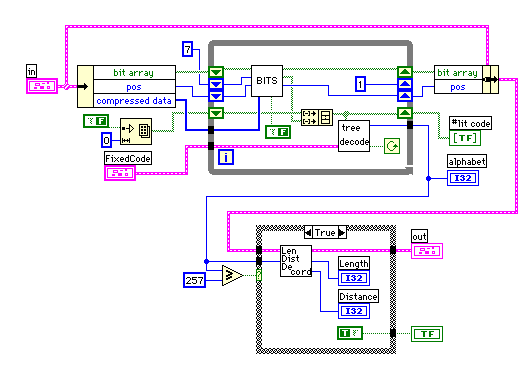
長さ、距離のデコードはビット長が指定されているので比較的簡単だ。(ここはまだ1例でしか確認していないので見落としが有るかもしれないが、気がついたら修正しよう。)ビット長やそのビット長での最小値は(一部しか表示されていないが、)固定の配列で与えたのでダイアグラムが醜くなっているのが残念だが、見通しは良くなっていると思う。
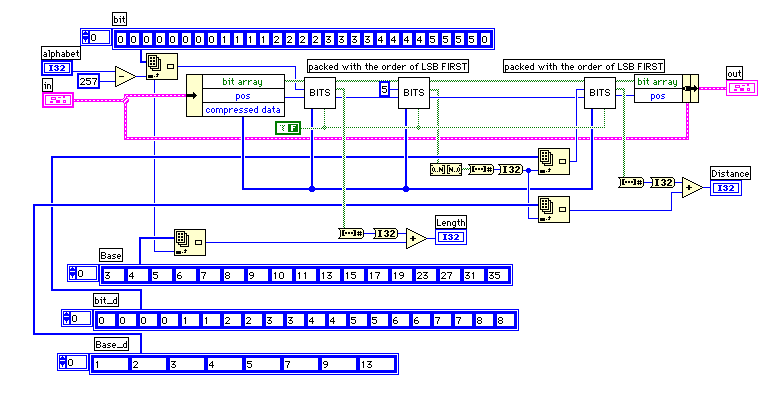
デコードした結果が文字の場合はそのまま文字列への書き出しを行う。長さ、距離コードの場合は文字列の指定位置から文字列をコピーして書き出しを行う。
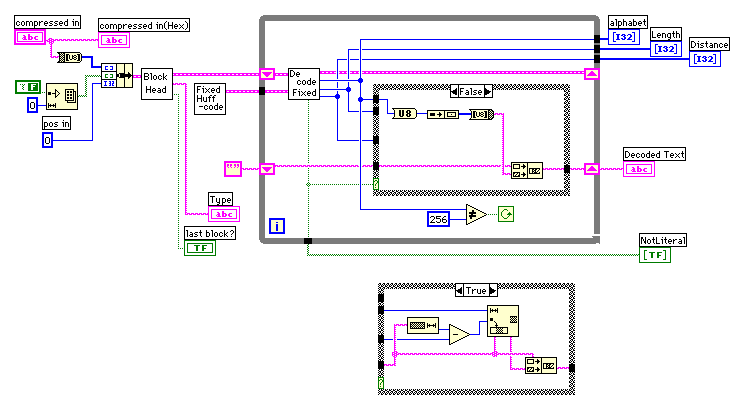
さて、今回は固定ハフマンコードで圧縮されたデータを伸長するアルゴリズムを見てきた。次回はダイナミックハフマンコードについて調べてみよう。