さて、現実の圧縮プログラムはどんな手法を使っているのだろう。もちろんハフマン圧縮でもそれなりに圧縮できるので、とりあえず簡単に実装したい場合は手軽ではある。しかし、記号の出現頻度が均等に近ければ原理的にそれ以上の圧縮は期待できない。
例えば"01010101、、、、、、"のように特定の記号の列が繰り返しあらわれる場合は、記号単位で置き換えるのではなく、"01"が50個というように表現したほうが圧縮率がかせげそうだ。このような方法は辞書ベース圧縮と呼ばれ、1977年にZivとLempelによって発表されたLZ77圧縮法がブレークスルーになった。圧縮技術はディスク容量の縮小だけではなく、通信時間/コストもセーブすることもできるので、それらに関連する企業の基盤技術として、辞書ベース圧縮に関する各種の圧縮アルゴリズムが開発され、特許が申請されている。
したがって、独自に新しいアルゴリズムを考えてプログラムに実装する場合は、特許を侵害していないかどうか注意する必要があると言われている。LZW圧縮と言われるアルゴリズムは、コンプサーブで使われ始めた画像フォーマットGIFで使われているが、特許権者との間で実際に問題をおこしたことで有名だ。特許の侵害問題は専門的な判断が要求されるので、アマチュアプログラマーには危険で手に負えない事態になってしまう。
複雑な世の中で困ったものだが、webで検索していくと、"deflation"というアルゴリズムは手かせ足かせの少ない圧縮方式があることが分かった。
Info-ZIPというホームページ(http://www.cdrom.com/pub/infozip/)では、Windowsプラットフォームで一般的に使われている".zip"形式のプログラムのソースコードや各種プラットフォームへ移植した実行形式プログラムを公開している。zipフォーマット(PKWARE Inc.が管理)はPaul Lindner氏が「Registration of a new MIME Content-Type / Subtype」というタイトルでMIMEに登録している。フォーマットにしたがったファイルであれば、どこの誰でも解凍できるというのは魅力的な話だ。
圧縮関連の特許の話は松阪大学 奥村晴彦氏のホームページ(http://www.matsusaka-u.ac.jp/~okumura/)が参考になった。zipに関しても特許が問題になっていて、スタック社が日本で出願した特許番号第2713369号はLZ77の辞書のアクセスにハッシュ関数を使うという内容だ。「こんなもので出願者に独占を許したら大部分のプログラマーは特許調査の合間にプログラムを書くようになってしまう」という声が聞こえてきそうだ。特許庁がウエブ上で特許を閲覧できるようにしているので興味のある人は一読してみるとよいだろう。Info-ZIPでは、スタック社の特許に抵触していないと主張しているのだが、私には今のところ分からない。
***************++++++++++++++++++++++***************
さて、現実的な問題は、プログラムが圧縮率を向上させるために工夫を凝らしているために分かりにくい事だ。仕様書やプログラムの注記などに配慮されているので、難解だが、時間をかければ理解できないこともないかもしれない。途中で投げてしまうかもしれないが、行けるところまでゆっくり進んでみよう。
zipをMIMEに登録した文書はzipというファイル名でInfo-ZIPに収められている。今回はこの資料を元にzipフォーマットの構造について確認していこう。日本語の「INTERNETファイル形式 A to Z完全解説」(ISBN4-88309-123-6/発行;ジャストシステム)にも11ページで解説されている。
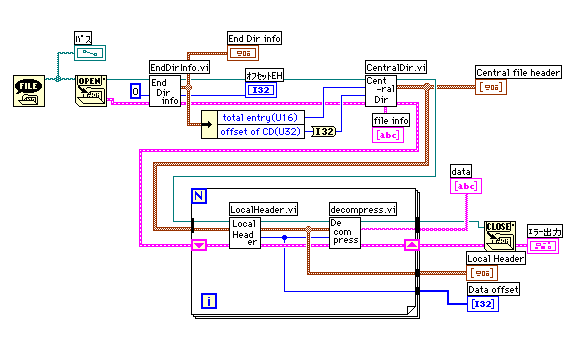
ファイル構造は比較的シンプルで、n個のファイルを圧縮したものは次のような構造になっている。
[ヘッダA1] 圧縮ファイル1、、[ヘッダAn] 圧縮ファイルn、[ヘッダB1] 、、[ヘッダBn]、[終了レコード]
[ヘッダB1]以降の部分は集中ディレクトリと呼ばれていてファイルの個数やそれぞれの圧縮情報、ヘッダAのある場所などの情報が記録されている。ヘッダA、ヘッダB、終了レコードはヘッダサインで区別している。それぞれ4バイトでPK34(あるいはPK78)、PK12、PK56のアスキー記号が割り振られている。
EndDirInfo.viでファイル数とヘッダB1のオフセットを調べて、CentralDir.viでヘッダBを取り込む。その情報をクラスター配列で出力してフォーループに渡し、ヘッダAの圧縮情報からファイルを復元する。このダイアグラムではdecompress.viがすでにできているように見えるが、中身はまだ無い。
zipがDOS生まれなので16bitや32bitのバイト順がインテル形式になっているのが気にくわないが、なんとかしよう。
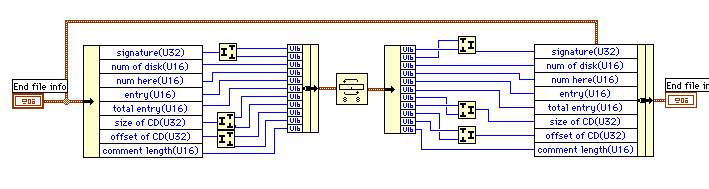
もっときれいなやり方を知っている人はぜひ教えて欲しい。
次回はまず、他のzipプログラムで圧縮したファイルがどのようになっているか調べて、ファイルへの伸張にトライしてみたい。これから中身を見ていかなければならないので時間がかかるかもしれない。