前回説明したハフマンツリーを作成するCプログラムをGに翻訳してみよう。「データ圧縮ハンドブック」(ISBN4-8101-8605-9)のプログラムを対比のために部分的に引用させてもらった。原文のプログラムは読みやすくインデントされているが、HTMLタグを工夫するのが面倒なので割愛した。
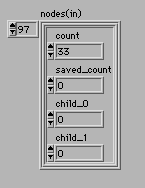
ツリーの情報はNODEという構造体に作られる。
*******quote*******
******unquote******
圧縮用の関数 CompressFile( input, output, argc, argv ) の中でnodesという名前でこの構造体を使った変数領域がつくられている。バイトサイズでの圧縮なので最大限256個の記号が出てくるので中間ノードを含めたツリーのサイズは512個で良いのだが、圧縮ファイルのエンドマークコードと要素の最小値探索のための初期値設定用として514個の領域が取られている。
nodes = (NODE *) calloc( 514, sizeof( NODE ) )
Gではクラスターアレーを使用しよう。
ツリーの構成用関数 build_tree( nodes ) が実行される前に、nodes には圧縮しようとするファイルの各バイトコードの出現頻度が最大値255で規格化されてセットされている。
*******quote*******
******unquote******
forループの前までの部分の翻訳はこんなところか。" nodes[ 513 ].count
= 0xffff; " がかなり面倒なことになってしまう。LabVIEWが好きになれない人はこんなところが気に入らないのかもしれない。nodesを2次元配列で扱うことにすれば、少し小さくなるが、、、
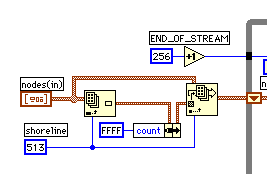
一番外側のループは、次のような構造になっている。
for ( next_free = END_OF_STREAM + 1 ; ; next_free++ ) {
**A**;
if ( min_2 == 513 )
break;
**B**;
}
停止条件が中間に入っていて、停止するときには" break; " 以降の"
**B**; " は実行しない。GではWhileループを使って" **B**; " はケース構造に入れてしまえば良いようだ。
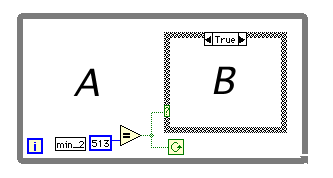
GのWhileループはdo { } while(condition); なので、一般的には使いにくい面がある。while(condition) { }が使いたいときには、上の図のAには何も入れないで、Bに実行したい内容を入れれば等価な制御構造を実行させることができる。これも煩わしさを感じる点かもしれない。なぜGではwhile(condition) { }を実装しなかったのだろう? データフローに馴染むデザインが思い浮かばなかったのか、データフローの場合には使用頻度が少ないと考えたのか?機会があればNIに聞いてみたいと思う。
ループの中の始めのforループについて見てみよう。ここではcountが0以外の最も小さい2個を選んでいる。努力して見やすくしたつもりだが、どうだろうか? アルゴリズムはさすがに洗練されている。
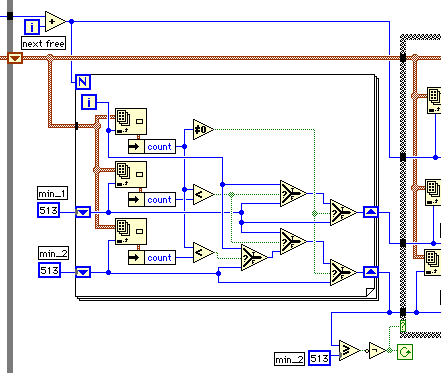
次に、最小の2個の要素を集めてノードを作成している。
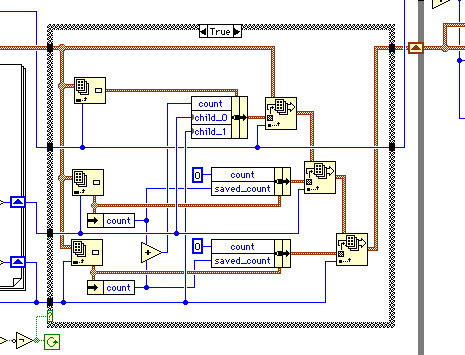
最後の3行はシンプルだ。
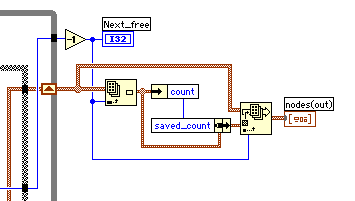
全体を通して、G特有の高レベル関数を使ってもっと簡単にできないかと考えてはみたが、良いアイデアは出てこない。int build_tree( nodes )はGとしても素直なプログラムに翻訳できたと思う。勉強になりました。(すぐ忘れてしまうのが残念!)
悩みの種になるのは、再帰的なプログラムだ。次回をお楽しみに。