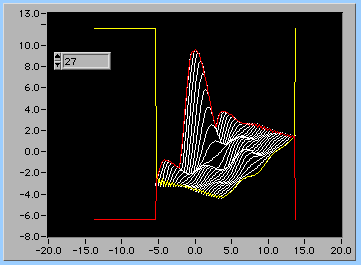
陰線処理は、ひとつ前のラインまでの最大値の配列と最小値の配列をもとに、最大値と最小値に挟まれない、"見える部分"を一区切りづつx-yグラフにしていくことだ。27番目のデータラインを書くときには26番目までの描画の最大値の配列/最小値の配列との比較を行う。その結果、下のグラフのように27番目のデータラインは白、水色、緑で描かれた3つの部分だけが描画される。
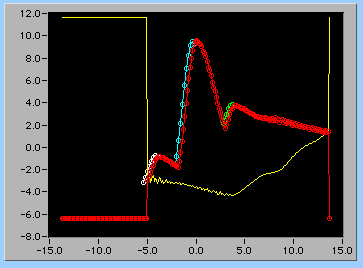
水色の部分を拡大するときれいに最大値データと交わっている。
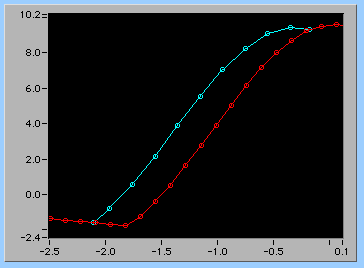
左側の交点部分をさらに拡大すると下のグラフになる。
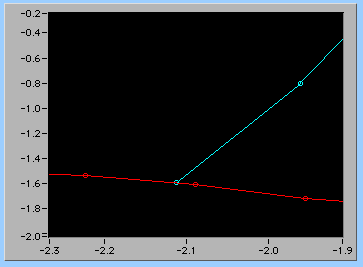
交点の計算自体は中学校で習う簡単なものだが、面倒なのは計算に使う2本の直線をどんな手順で決めていくか、ということなのだ。すっきりした頭で発想を転換すれば簡単になるかもしれないが、今のところかなり回りくどい手順になっている。
最大値の配列と最小値の配列のx座標は、描画幅を適当なピッチで分割して等間隔になっている。一方、回転後の描画データのx座標は、x軸に沿った線とy軸に沿った線とは間隔が異なるし、一本毎に開始点がずれていく。データ数や回転角度によってもさまざまな値となる。描画データを順次、最大値/最小値と比較するためにはx座標が揃っていると比較し易いのだがそうはうまくできていない。
例えば、最大値を超えたデータ点が見つかるとそのひとつ前のデータ点のとの間で交差することが分かる。その間に最大値の配列が何個入っているかは場合によって異なる。そのために、こんどは最大値の配列を順番に追いかけてデータの内挿値が最大値を超える点を見つけなければならない。これが見つかれば後はそれらの座標から交点を求めることは簡単だ。
そんな事情があって変化のおこったデータの番号とデータの配列のクラスターと最大値/最小値の配列のクラスターを渡してしまうことにした。
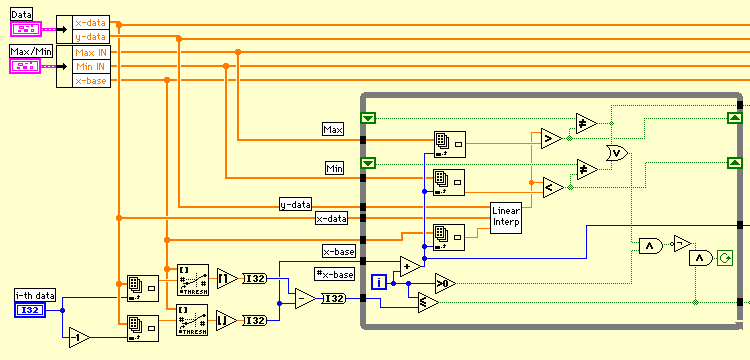
ダイアグラムはダラダラ長くなって1画面に収まらなくなった。普段はサブVIに分割したりシーケンスにしたりコンパクトにしようとじたばたするのだが、今回は疲れたのでデータの流れに任せてしまった。これはこれで流れが見やすいかな?
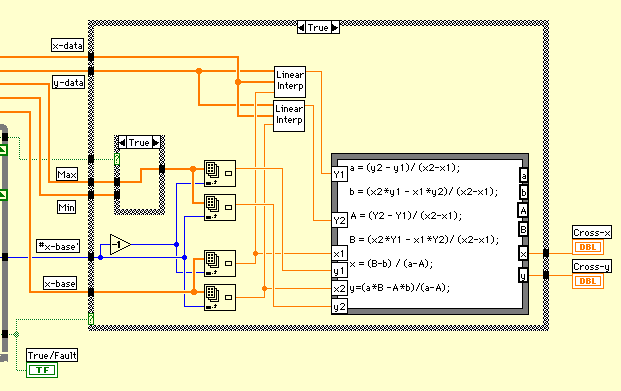
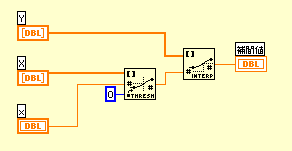
中にLinearInterpというアイコンが入っているが、内挿を行うサブVIだ。
今日はここまで、