2021.05.18
昨夜のBSTBS「報道1930」で鳥取県の感染対策を紹介していた。ウイルス排出量(Ct値が小さいほど多い)を目安にして徹底的な接触者検査を行っているという。合理的なやり方である。厚労省の定義する「濃厚接触」でない状況で二次感染が起きていて、Ct値を目安にして考えると辻褄が合いそうだということ。
出席者の元厚労大臣の長妻さんが、これを感染研に提案したところ、「Ct値と感染性の間の相関にはエビデンスが無いから政策提案すべきではない」という返事だったということで、驚いた。確かに感染性が Ct値だけで決まるものではないが、手元にある確実なデータは最大限活用すべきではないだろうか?そもそも「エビデンス」というのは研究して初めて明らかになるものであって、その努力をしないで、鳥取県に任せるというのは研究所の使命を理解していないということではないか?
Ct値と感染性の関係については、いろいろ議論されていて、確かに明確な結論が出ていない。最近興味深い Preprint が出たので要約してみた。
Quantifying the relationship between SARS-CoV-2 viral load and infectiousness
Aurelien Marc et al. https://doi.org/10.1101/2021.05.07.21256341
2020年4月、スペインにおいて、COVID-19の治療薬として期待されていたヒドロキシクロロキノンの大規模治験が行われて、詳細なデータが得られた。それを再度分析し直して、ウイルス排出量と感染性の関係を検討した。採り上げたのは、データの揃った 282 人の一次感染者の 753の濃厚接触事例である。
検査は感染が起きた後になってしまうので、感染時のウイルス排出量をモデルで推定する必要があった。これは、細胞レベルでのSIRモデルである。
家庭内感染の場合にはウイルス排出量の経時変化と二次感染確率との間の相関が非常に高かったが、家庭外感染の場合にはそれほどでもなかった。ウイルス排出量と二次感染確率との間の相関そのもの(時間因子を除く)については個人的バラつきが大きい。
●もう少し詳細に入る。
PCR検査は二次感染と異なる日(何日か後)の場合が殆どであって、陽性となる確率が高いのは発症日近辺の数日であるから、そのまま統計解析しても充分な相関が見えてこない。そこで、二次感染日でのウイルス排出量を推定するためにモデルを構成し、そのモデルの中に、個人差やワクチン効果等に依存するパラメータを入れておく。モデルで計算された二次感染日でのウイルス排出量で実際の感染確率を説明する為の比例係数 γ を家庭内感染と家庭外感染に区分して決める。これは基本的には「回帰分析」であるが、内部に構造を持つ「非線形混合モデル」となっている。ウイルス量が二次感染に関係しているかどうかの判断(有意性)は、求められた係数 γ に対する p 値で判断されることになる。家庭内感染の場合 p<0.01、家庭外感染の場合 p<0.05 であった。つまり、前者の方が有意性が高い。また相関係数も大きい。これは、後者においては、個人的バラつきに加えて感染の同定が不安定になっているということもあるからと思われる。回帰モデルとしてはいろいろな型を試しているが、M2(ロジット線形モデル) が一番良かったということで、表1の中に決定されたパラメータがまとめてある。感染した細胞が生み出す二次感染細胞数(基本再生産数)は16.2、感染細胞の寿命は、半減期で20時間、感染細胞が生み出すウイルスは、一日で 4.1×10^5個 となった。(但し再感染性のあるのはその一部である。)総排出ウイルス量は発症日がピークではあるが個人差が大きい。そのメディアンは10^9.8 個/mL(四分点=9.1,10.4)。なお、γ1 は家庭内、γ2 は家庭外。パラメータについてはモデルの説明を参照。( )内 RSE% の意味は良く判らない。パラメータの最適化誤差だろうが、%表示するものだろうか?
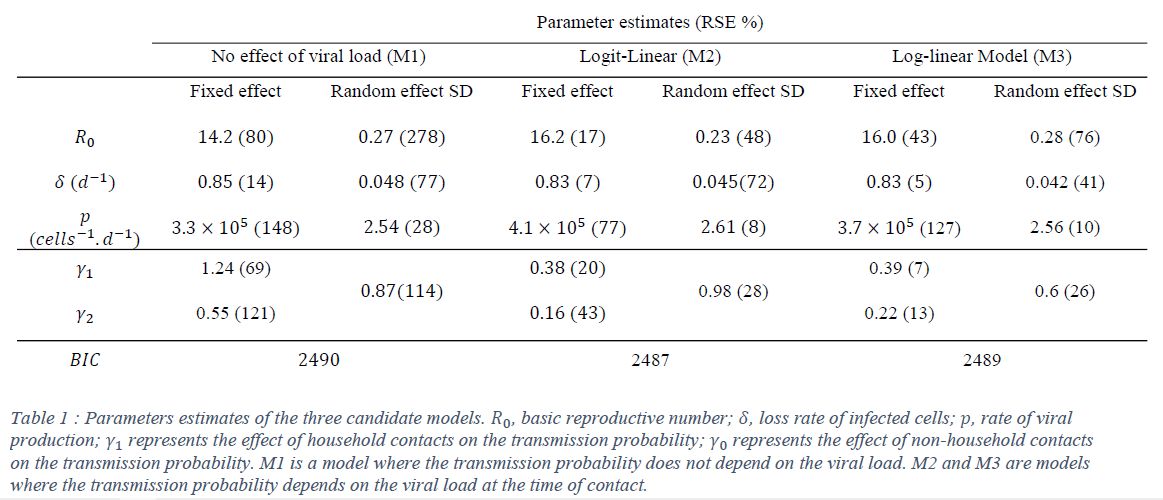
具体的には図1のようにして感染確率をその感染日でのウイルス排出量と関係づける。観測されたウイルス排出量は黒丸であるが、一次感染者と他者との接触日(四角)とは異なるために、ウイルス増殖モデルから、各曲線のように接触日における排出量を計算し、その値と接触における感染(赤)と非感染(白)の比率を説明するような回帰モデルを構成する。この増殖モデルと回帰モデルを一体化して、全体を最適化する。
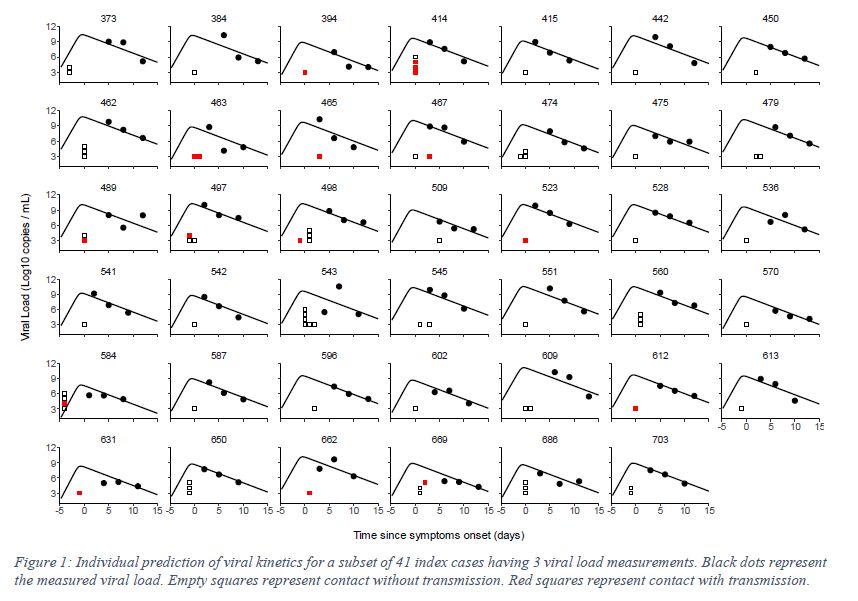
ウイルス排出量と感染確率の関係が1000例のシミュレーションによって計算されていて、図2の棒グラフとなっている。これに対して、実測は感染時のウイルス排出量はモデルで推定された値を使って、実際の感染確率を黒丸、95%信頼区間範囲を線分で示して、比較している。パラメータを実測に合うように最適化したのだから、まあ合って当り前であるが、実測の信頼区間を見ても彼らの主張は納得できそうである。
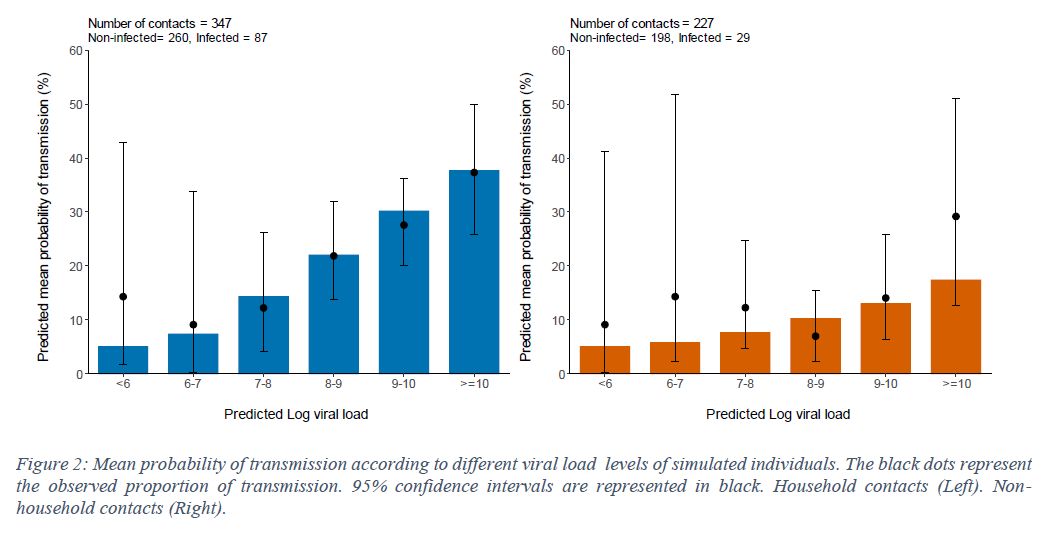
発症日から二次感染までの日数分布についても、同様に、図3で比較してある。ウイルス排出量に対して、二次感染確率の方は長時間側の裾が短い。これは良く知られていて、時間が経過すると検出されるRNAが必ずしも生きたウイルスではなくなるからである。ここでのモデルはその辺の区別はしていないが、二次感染には10^6個/mL という閾値を設けているから傾向がうまくでているのかもしれない。
このモデルから、ウイルスの感染能力、増殖能力、ワクチンによる制御等の細胞生物学的なパラメータが感染力に及ぼす影響が評価できる。
基準は、発症日における接触者への感染確率である。家庭内では 25%、家庭外では 11%。
増殖速度(下記の p を変える)の効果であるが、2倍で 27% と 12%、4倍で 29% と 12% になる。イギリス型に相当する。
逆にワクチン接種者においてはこれが小さくなる。1/4倍で 21% と 10%、1/100 倍で 12% と 7% になる。
●以下モデルの詳細である。
(1)Virial Kenetic Model
細胞側とウイルス側での Compartment モデルである。
細胞側は、正常細胞 T → 感染細胞 I1 → 産生細胞 I2 → 死亡、
ウイルス側は、感染ウイルス VI と 非感染ウイルス VNI に別れ、それぞれ 寿命を持つ。
T と VI が出会って、β×T×VI の rate で T が減り、I1 が増える。 I1 は k×I1 の rate で I2 に変わる。
I2 は δ×I2 の rate で死亡するが、その間 p×I2 の rate で新しいウイルスを生み出す。
新しいウイルスの内、μ の比率が VI で (1-μ) の比率が VNI である。
いずれのウイルスも c×VI、c×VNI の rate で死亡する。
感染初期にはウイルスの増加速度がウイルスの数に比例するから指数関数的に増大するが、やがて、正常細胞が消費されるので、減衰していく。SIRモデルと同じメカニズムである。実際には免疫作用が働くのだが、見かけだけ見れば同じ事なのだからまあ良いか、という感じ。
パラメータは、
c=10/days、μ=10^-4、T の初期値=1.33×10^5 cells/mL、
incubation period = 5days とあるから、k=0.2/days と思ったのだが、k=4/days となっている。
つまり、incubation period はこの Kinetic Model の中ではない。感染後5日経過してから、このモデルの初期条件に達するということにしているのか、それとも最大のウイルス排出の時点を感染日の5日後という風にしてあるのか。多分後者だろう。
I2 の初期値は 1/30 cells/mL
これらにはそれなりの根拠があるようだが、僕には判断できない。
残されたパラメータは β:ウイルスが細胞に感染する効率、p:感染された細胞がウイルスを排出する速度、δ :感染された細胞が死亡する効率。
これらが個人差であり、ワクチン効果としても考慮される。
感染された1つの細胞が死亡するまでに幾つの感染細胞を生み出すか、という基本再生産数は
R0=pβT0μ/cδ
と表現できるので、以下 β の替わりに R0 を使うから、ウイルス排出パラメータは R0、p、δ ということになる。
ちなみに、実際に標準的なパラメータで計算すると下図のようになる。×印が有効ウイルス排出量(感染力のあるウイルス量)である。PCR検査で観測されるのはこれの 1/μ 倍(10000倍)である。減衰期の振る舞いは δ だけで決まっている(∝ exp(-δt))。これで見ると潜伏期間も大体自然に出てくる感じではある。
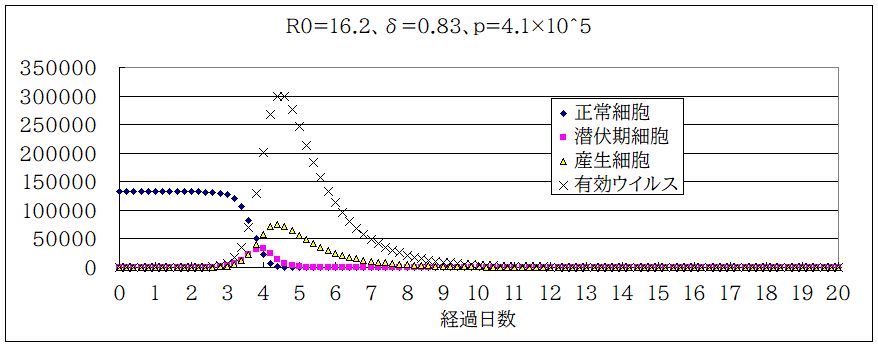
なお、元々モデルと実際とは違うので、これも蛇足ではあるが、有効ウイルス VI の方は細胞に侵入すると居なくなるので、β×T×VI の速度で減少する項が必要になる。この項がこの論文では抜け落ちている。これを入れると、上記グラフの有効ウイルス量のピークはほぼ5日の位置にずれる。Viral Dynamics モデルとして引用している2つの文献も調べて見ると、一つにはその項が入っていて、もう一つには入っていない。
(2)Statistical Model
ウイルス量の常用対数 yij=logV(tij, ΨVi) + εij
という統計モデルである。
i は一次感染者を区別する。j は時刻(他者との接触日)を区別する。εij はノイズ項(標準偏差 σ の正規分布)。
関数 V はViral Kinetic モデルによる経時変化の計算値 VI+VNI であるが、これは個人パラメータ ΨVi に依存する。
パラメータとは、具体的には、個人個人の R0 と p と δ と それらの分散であるが、一般的には R0,δ,p,ωR0,ωδ,ωp である。ここで、ω はそれぞれの標準偏差である。εij はウイルス排出パラメータの分散以外の攪乱要素として追加されているようであるが、具体的に σ がどうなったかについては記述が無い。考えてみると、ウイルス排出パラメータが決まれば、j 番目の日での排出量は決まるので、一人の一次感染者が何回も検査される以上、実際のデータとのずれが必ず生じる。それは最小化されるにしても、残るということだろう。ただし、どの程度の誤差が残っているのか(σ)については記述が無い。
(3)Probabilty of Transmission
一つの接触あたりの感染確率 を P として、その logit =ln(P/(1-P)) について線形モデルとする(ln は自然対数)。つまり、
logit(P)=α (if logV ≦6)
=α + βi × (logV - 6)
(V≦ 10^6 /mL 以下では感染が起きないということを取り入れている。)
βi は γexp(bi) と書いて、γ を家庭内、家庭外それぞれについて平均的な係数とする。
この係数はウイルス量 V を感染確率に結び付ける。(Virial Kinetic Model の β ではない。)
しかし、個人差が大きいので、ランダム効果として bi をモデルに入れる。
bi は分散を持ち、その分散がモデルパラメータである。
(4)Parameter Estimation
ウイルス放出についてのパラメータは R0、p、δ で、それぞれ個人差による分散がある。またウイルス排出量が決まった時でもそれによる感染確率係数 β とその分散がある。多分オーソドックスなやり方としては、階層化して、まずは一人一人の一次感染者の観測されたウイルス放出量にフィットするように R0、p、δ を決める。この時発症日でウイルつ放出量が最大となるようにするものと思われる。そのフィッティングの残渣の標準偏差が σ である。次の段階として、そのウイルス放出量の接触日での値と実際に感染が起きたかどうかのデータを関係づける。これは logit 回帰分析として行える。その時の係数が γ1 あるいは γ2 である。これら二つの段階を積み重ねるよりは、片方で多少妥協して片方でより合うようにする、といった調整をした方がフィッティングが良くなるだろう。そのような計算を一度にやってくれるプログラムが R では準備されているということらしい。ただ、第一段階においては微分方程式を解く必要が生じるので、ここに解析的な解を使わなくてはならないような気もする。