氏名の間の「空白」を見つけて、これを元に「名字(姓)」と「名前(名)」に分解するというものです。
かなり忙しい時に質問されたことなので...
頼まれてこちらで作業するならばマクロ(VBA)を用意して処理してしまうようなケースでもありますが、
今後のこともあって、各現場の(マクロの知識がない)担当者が、自分で作業できるようにと計算式(ワークシート関数)で実施できる文字列分解のサンプルを作成してみました。
今回の要件は、「氏名」から「名字(姓)」と「名前(名)」を分解するということで、元となる「氏名」は「名字(姓)」と「名前(名)」の間に空白はあるのですが、全角の場合と半角の場合が混在した一覧になっています。
また、このページの対応としては姓名間の空白がないケースの対応として、「名字(姓)」の側に寄せるように処置しています。
今回の要件は、「氏名」から「名字(姓)」と「名前(名)」を分解するということで、元となる「氏名」は「名字(姓)」と「名前(名)」の間に空白はあるのですが、全角の場合と半角の場合が混在した一覧になっています。
また、このページの対応としては姓名間の空白がないケースの対応として、「名字(姓)」の側に寄せるように処置しています。
- まず、「作業列」を使って、空白の文字位置を検出します。
-
(画像をクリックすると、このページのサンプルがダウンロードできます)
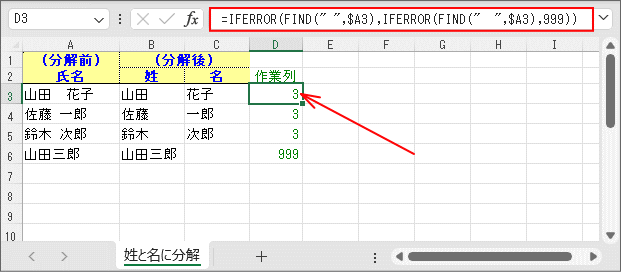
まずは、表の領域外の列を「作業列」として利用し、氏名間の空白の文字位置を算出します。
「作業列」とは、複雑な計算式の中間結果を一時的に保持させるセル(列)のことで、この例のように「作業列」で保持させた結果をさらに複数箇所で参照するようなケースでは、 単に計算式の複雑さを回避させるだけでなく、シート全体で効率改善的な効果も発揮させることができます。
ここでの「計算式」は、このようにしてみました。
=IFERROR(FIND(" ",$A3),IFERROR(FIND(" ",$A3),999))
まず、「氏名(分解前)」の文字列(A列)中に半角の空白があるか判断し、あればその文字位置を返します。 なければ同様のことを全角の空白で再度行ない、あればその文字位置を返します。それでもなければ「999」を返します。
空白の文字位置を探すのは「FIND関数」ですが、「あるかどうか」についてはこの「FIND関数」が失敗したかを「IFERROR関数」で判断しています。
このサンプルでは、テストケースとして「山田 花子」は姓名間が全角空白、「佐藤 一郎」「鈴木 次郎」は半角空白、「山田三郎」は空白なしとしてあります。
関数 概略説明 IFERROR関数 数式がエラーと評価される場合に指定した値を返します。それ以外の場合は、数式の結果が返されます。
引数は以下の通りです。
① エラーを検査する数式(または評価値)
② エラーの場合の値(または処置式)FIND関数 指定された検索文字(文字列)を対象文字数から検索して見つかった文字位置を返します。
引数は以下の通りです。
① 検索文字(文字列)
② 対象文字列
③ 開始位置(省略可、省略した場合は先頭から検索します)
※FIND関数では大文字と小文字が区別されます。 大文字と小文字を区別しない場合はSEARCH関数を使います。
- では、空白文字位置の左の「姓」を取り出します。
-
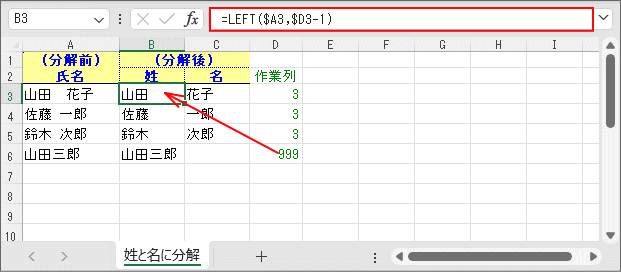
空白が全角であっても、半角であっても、その文字位置が見つかってしまえば、後は簡単です。
空白の文字位置の1文字手前までが「姓」ですから、
とすれば名字(姓)だけを取り出すことができます。=LEFT($A3,$D3-1)
関数 概略説明 LEFT関数 文字列の先頭から指定された数の文字を返します。引数は以下の通りです。
① 文字列
② 文字数
- さらに、空白文字位置の右の「名」を取り出します。
-
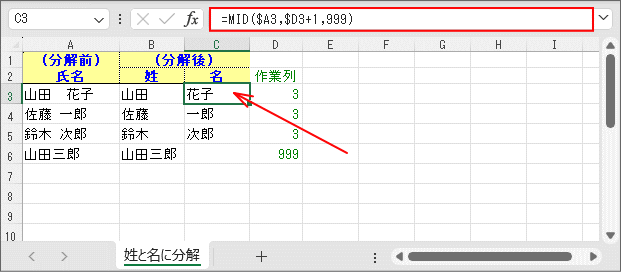
「名」の取り出しは「空白の右側の文字列」となりますから、右端から「文字列全体の文字数」-「空白までも文字数」の結果の文字数を取り出せば良いわけです。
=RIGHT($A3,LEN($A3)-$D3)
一見、これで良さそうなのですが、氏名間に空白がないデータが含まれていた場合は「#VALUE!」となってしまいます。
この対策としては「RIGHT関数」ではなく「MID関数」を使って、検出した空白文字の次の位置から右にある文字列を取り出すようにすれば良いようです。
「MID関数」では「取り出し開始文字位置」と「取り出し文字数」を指定しますが、「取り出し文字数」が不定なのであえて大きな数値として「999」を与えて取り出しています。 「RIGHT関数」の場合は「山田三郎」の名前のところで「#VALUE!」となってしまうのですが、「MID関数」ではこのようにブランクとして表示されます。=MID($A3,$D3+1,999)
関数 概略説明 MID関数 文字列の指定された位置から指定された文字数の文字を返します。引数は以下の通りです。
① 文字列
② 開始位置
③ 文字数
RIGHT関数 文字列の末尾(右端)から指定された文字数の文字を返します。引数は以下の通りです。
① 文字列
② 文字数
LEN関数 文字列の文字数を返します。引数は対象となる文字列です。
- Excel365ではTEXTBEFORE/TEXTAFTER関数が使えます。
-
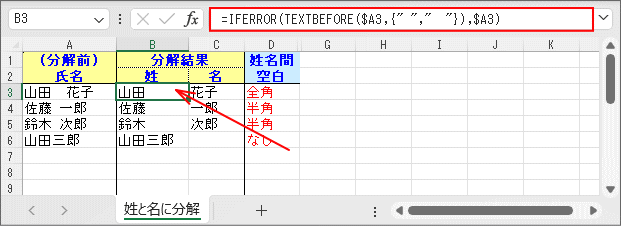
Excel365(Microsoft365のExcel)では、2022年のアップデートにより「TEXTBEFORE/TEXTAFTER関数」が加わりました。
これは文字列から「区切り文字(文字列でも良い)」を検出して、この「区切り文字」の左側(前)や右側(後)の文字列を取り出してくれる機能ですから、このページの要件にはピッタリです。 しかも、この「区切り文字」では配列定数として指定できるので、このサンプルのように半角空白と全角空白をOR条件のように指定することができます。
Excelのバージョンにより利用可否がありますが、可能なバージョンであれば数式も簡単になり、しかも「区切り文字」の位置を保持するための「作業列」も要らなくなるので、大変便利であり数式の理解も簡単です。
氏名の「姓」の方は、
となります。=IFERROR(TEXTBEFORE($A3,{" "," "}),$A3)
氏名の「名」の方は関数名が換わります。
=IFERROR(TEXTAFTER($A3,{" "," "}),"")
氏名間に空白がない場合の処置では、氏名全部を「姓」の方に寄せているので、「名」の方はブランクになるようにします。
関数 概略説明 TEXTBEFORE関数 指定した文字または文字列の前に出現するテキストを返します。
引数は以下の通りです。(③以降はオプション)
① 対象テキスト
② 検索指定文字または文字列
③ 検出位置(初期値=1:先頭、マイナス値はテキスト末尾から検索)
④ 大文字と小文字を区別(0=区別する:初期値、1=区別しない)
⑤ テキスト末尾の扱い(0=末尾は無視:初期値、1=末尾を区切り記号にする)
TEXTAFTER関数 指定された文字または文字列の後に出現するテキストを返します。
引数は以下の通りです。(③以降はオプション)
① 対象テキスト
② 検索指定文字または文字列
③ 検出位置(初期値=1:先頭、マイナス値はテキスト末尾から検索)
④ 大文字と小文字を区別(0=区別する:初期値、1=区別しない)
⑤ テキスト末尾の扱い(0=末尾は無視:初期値、1=末尾を区切り記号にする)