崱夞偼僒僂儞僪偺埑弅曽朄偺傂偲偮偱偁傞兪朄懃乮Mu-law)偵偮偄偰彂偄偰傒傛偆丅ITU-T Recommendations (CCITT) 偵掕傔傜傟偰偄傞傜偟偄偑丄巇條傪彂偄偨帒椏偼桳椏側偺偱庤尦偵偼側偄丅偝偄傢偄Computer-Music-Journal偵SUN偑ANSI-C偱彂偄偨reference implementations乮ccitt-adpcm.tar.Z偺拞偺g711.c乯偑偁偭偨偺偱丄偙傟傪嶲峫偵LabVIEW偱僾儘僌儔儈儞僌偟偰傒傛偆丅
偝偰丄Mu-law偼揹榖偱捠怣偱偒傞64kbps傪俉bit亊俉kHz偱幚尰偡傞偙偲傪擮摢偵峫偊傜傟偨僼僅乕儅僢僩偱丄恖娫偺挳妎偑壒偺戝偒偝偵懳偟偰懳悢揑偵斀墳偡傞偙偲傪棙梡偟偰壒幙楎壔傪墴偝偊側偑傜僨乕僞傪埑弅偡傞曽幃偩丅偙偺偁偨傝偺峫偊曽偼丄Mario Malcangi Fall 1995 IEEE Computer Society Press偵愢柧偝傟偰偄傞丅
Mu-law偼侾俇價僢僩偐傜俉價僢僩傊偺旕壜媡埑弅偱丄僨乕僞偑戝偒偔側傞偵偮傟偰戙昞抣傪庢傝弌偡娫妘傪懳悢揑偵峀偘偰偄偔丅懳悢揑偵偲尵偆偲擄偟偔峫偊偰偟傑偆偑俀恑悢偱峫偊偨偲偒偺悢抣偺嵟忋埵價僢僩偺埵抲傪傒傞偲懳悢揑側僗働乕儖偵偡傞偙偲偑偱偒傞丅
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
椺偊偽丄13偼俀恑悢偱1101偩偑丄嵍偵傂偲偮偯偮僔僼僩偟偰偄偔偲師偺傛偆偵側傞丅
| Dec | 價僢僩楍 | 僙僌儊儞僩 | 悢抣 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
埲忋偼Mario Malcangi巵偺愢柧偐傜棟夝偟偨Mu-law偺婎杮揑側峫偊曽偱偁傞丅
寢壥偲偟偰b0,b1偼柍帇偝傟傞偙偲偵側傞丅慜偵巊偭偨椺傪reference implementations曽幃偵偡傟偽埲壓偺傛偆偵側傞丅
| Dec | 0x84傪壛嶼屻偺價僢僩楍 | 僙僌儊儞僩 | 悢抣 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
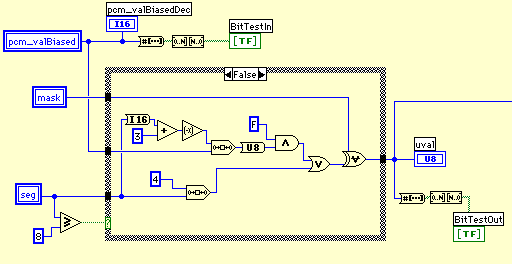
幚嵺偺VI偼斾妑揑僔儞僾儖偵彂偔偙偲偑偱偒傞丅C尵岅偱偺僾儘僌儔儉僐乕僪傪拃師LabVIEW偵堏偟姺偊傞偙偲傕偱偒傞偑丄岠棪偑偁傑傝椙偔側偄偙偲偑懡偄丅宱尡偱偼丄偱偒傞偩偗攝楍偺憖嶌偵帩偪崬傫偩曽偑摼偩偲巚偆丅
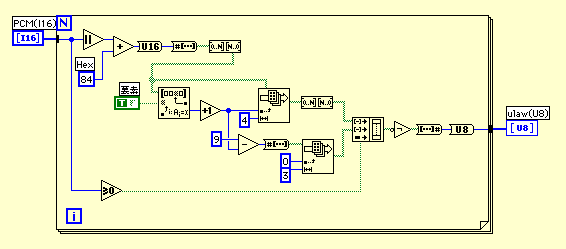
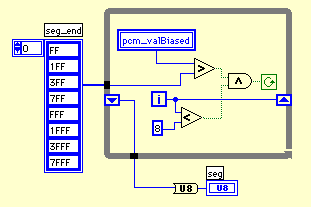 static short seg_end[8] = {0xFF, 0x1FF, 0x3FF, 0x7FF, 0xFFF, 0x1FFF,
0x3FFF, 0x7FFF};
static short seg_end[8] = {0xFF, 0x1FF, 0x3FF, 0x7FF, 0xFFF, 0x1FFF,
0x3FFF, 0x7FFF};
丂
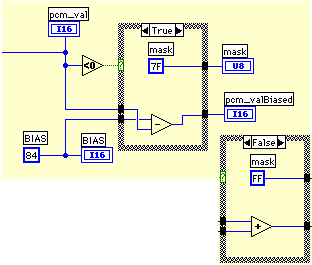 #define BIAS (0x84) /* Bias for linear code. */
#define BIAS (0x84) /* Bias for linear code. */
/* Convert the scaled magnitude to segment number. */
師夞偼偳傫側偙偲傪偟傛偆偐側丠
Nigel Yamaguchi
栠傞