![]()
【注意】 このドキュメントは、W3CのImage Annotation on the Semantic Web W3C Incubator Group Report 14 August 2007の和訳です。W3Cから新しいバージョンのドキュメントが発表された場合には、この和訳ドキュメント自体を変更または削除することがあります。
このドキュメントの正式版はW3Cのサイト上にある英語版であり、このドキュメントには翻訳に起因する誤りがありえます。誤訳、誤植などのご指摘は、訳者までお願い致します。
First Update: 2007年10月20日
Copyright © 2007 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
マルチメディア資産を処理する多くのアプリケーションは、そのマルチメディア・コンテンツに関して記述した何らかの形式のメタデータを使用しています。このドキュメントの目標は、画像メタデータの作成、蓄積、操作、交換、処理に対しセマンティック・ウェブの言語や技術を使用する利点について説明することです。さらに、ユースケースでの例示によって、セマンティック・ウェブベースの画像アノテーションのためのガイドラインを提供します。一般公開されているツールの簡潔な概要とともに、関連するRDFとOWLの語彙について論じます。
この項は、このドキュメントの公開時のステータスについて記述しています。他のドキュメントがこのドキュメントに取って代わることがありえます。最終インキュベータ・グループ報告のリストが入手可能です。http://www.w3.org/TR/のW3C技術報告索引もご覧ください。
このドキュメントはW3Cマルチメディア・セマンティクス・インキュベータ・グループ(W3C Multimedia Semantics Incubator Group)により作成されました。このドキュメントの前バージョンはW3Cセマンティック・ウェブ・ベスト・プラクティスおよび展開ワーキンググループ(W3C Semantic Web Best Practices & Deployment Working Group)のセマンティック・ウェブにおけるマルチメディア・アノテーション・タスクフォース(Multimedia Annotation on the Semantic Web Task Force)によって作成されました。このグループは、W3Cセマンティック・ウェブ・アクティビティの一部です。
W3Cインキュベータ・アクティビティの一部としてのW3Cによるこのドキュメントの公表は、W3Cによる当該コンテンツの承認を意味せず、W3Cはそれが扱う課題に対するかなる資源も所有しておらず、現在も将来も割り当てることはありません。W3Cサイトにおけるインキュベータ・グループへの参加とインキュベータ・グループ報告の公表はW3Cメンバーの利点です。
インキュベータ・グループは、W3C特許方針で定義されているように、無償利用ベースで実装可能な成果物を作成することを目標としています。当インキュベータ・グループの関係者は、後にW3C勧告に組み込まれるこのインキュベータ・グループ報告の一部に対し、W3C特許方針の使用許諾要件に従って使用許諾を提供するかどうかに関する声明を出していません。
読者は、このドキュメントを読んだ後に、個々のマルチメディア・アノテーションの語彙やその他の関連するツールおよび資源について論じた別の現行ドキュメントを参照することができます。画像アノテーションに対する現在のアプローチの大部分は、セマンティック・ウェブの言語に基づいていません。これらの技術と、RDFとOWLベースのアプローチの間の相互運用性はこのドキュメントでは取り扱いませんが、関心がある読者はマルチメディア・アノテーション相互運用性フレームワークのドキュメントを参照できます。
このドキュメントは、個人的なデジタル写真にアノテーションを付与している専門家ではないエンドユーザから、画像・映像バンクや視聴覚アーカイブ、博物館、図書館、メディア制作、放送業界においてデジタル画像を扱う仕事に従事している専門家に至るまで、画像アノテーションに関心を持っている全ての人々を対象としています。
このドキュメントに関する議論は、公開メーリングリストpublic-xg-mmsem@w3.org(公開アーカイブ)にお願いいたします。パブリック・コメントは件名接頭辞として「[MMSEM-Image]」含む必要があります。
デジタル画像データにアノテーションを付与する必要性は、画像データの専門家と個人の両方の利用をカバーする種々多様なアプリケーションにおいて認識されています。執筆時点では、この分野の作業のほとんどは、セマンティックに基づく技術をまだ使用せずに行われています。このドキュメントは、画像アノテーションにセマンティック・ウェブの言語や技術を利用する利点について説明し、それを実行するためのガイドラインを提供します。多くの代表的なユースケース、および、そのユースケースで言及した作業の達成に役立つセマンティック・ウェブの語彙やツールに関する記述などで構成されています。
ユースケースは、代表例として、個人用・業務用の両方、そして、公開・非公開領域の両方の例を提供しています。これらは、セマンティック・ウェブに基づく画像アノテーションに関連する語彙やツールについて論じるために後で用います。シナリオの例を5項で示しています。ユースケースは画像が表す主題またはそれを利用するコミュニティーによって異なります。アノテーションの過程で用いられるツールと語彙は、これらの基準によってしばしば決まります。
多くの個人の利用者は、休暇、パーティー、旅行、友人や家族、日常生活などの何千枚ものデジタル写真を持っています。写真は通常、パーソナルコンピュータのハード・ドライブに、メタデータを付けずに簡単なディレクトリ構造のもとに格納されています。利用者は一般的に、このコンテンツに簡単にアクセスしたり、それを見たり、自分のホームページに使用したり、プレゼンテーションを作成したり、他の人々がその一部を利用できるようにしたり、その一部を画像バンクに売ったりしたいとさえ考えます。しかし、このコンテンツにアクセスする唯一の方法がディレクトリを見ることであるということがあまりに多く、そのディレクトリの名前は通常、その写真に写されている元の出来事の日付や記述を、1つか2つの単語で表したものです。写真の数が増えるにつれてアクセスが困難になり、コンテンツはすぐに実際に使用されなくなることは明らかです。洗練された利用者は、キーワードとなるメタデータや簡単なカテゴリーの分類を提供してくれる簡単な写真管理ツールを活用します。これが、セマンティックに対応した解決策への第一歩です。5.1項では、セマンティック・ウェブの技術を用いたユースケースのシナリオの例を提供しています。
美術館が、コレクションの中で最も重要な芸術作品の高画質デジタル・スキャンを作成するように、それを専門とする企業に依頼したと想定しましょう。美術館が求める品質保証には、すべてのスキャンが、いつ、どこで、誰によって、どのような機材で行われたかなどを追跡できることが含まれます。T基盤となる画像データベースを維持している美術館内部のIT部門は、作成したすべての画像のサイズおよび解像度、形式を必要とします。また、原作の収納庫のIDを知る必要があります。美術館のウェブサイトを開発している会社は、著作権情報(これは、原作とそれが由来するコレクションの年代によってスキャンごとに異なる)も必要とします。また、絵画のタイトルやその画家の名前だけでなく、描かれている主題(「日沈」)、ジャンル(「自画像」)、形式(「ポスト印象派」)、時代(「世紀末」)、地域(「西ヨーロッパ」)によっても、利用者がウェブサイトでコレクションへアクセスできるようにしたいと考えます。5.2項では、これらのすべての要件がセマンティック・ウェブの技術を用いることでどのように実現できるかを示します。
視聴覚アーカイブ・センターは、非常に大規模なマルチメディア・データベースの管理に慣れています。例えば、INA(フランス国立視聴覚研究所、French Audiovisual National Institute)は、テレビ・ドキュメントを50年代から、ラジオ・ドキュメントを40年代からアーカイブしてきており、100万時間以上の放送番組を蓄積しています。彼らは最近、10,000時間以上のフランスのテレビ番組をオンライン上にアクセス・フリーで掲載しました。INAが保存している画像および録音アーカイブは、主に専門家の利用(フランスおよび世界中のジャーナリスト、映画監督、プロデューサー、視聴覚およびマルチメディアのプログラマーや出版社)に向けたものであるか、研究目的(学生や研究者、教師、作家といった公衆のための)でやりとりされるものですが、今ではますます一般の人々の利用が可能になっています。格納されたデータへの効率的なアクセスを可能にするために、これらのビデオ・ドキュメントの大部分は、その内容によって記述や索引付けが行われています。そして、グローバルなマルチメディア情報システムは、一部の非常に複雑で正確な検索要求に対応可能な、精密で詳細なものでなければなりません。例えば、ジャーナリストや映画監督は、ナショナル・チームのあるサッカー選手がヘディングで獲得した最初のゴールを見ることができる過去の放送番組の抜粋を求めるかもしれません。質問には、ゴール・シュートは前からのカメラ映像と逆アングルのカメラ映像の両方が入手できなければならないといった、いつくかの技術的な追加要件が含まれる可能性があります。最後に、クライアントは、日付、場所、最終得点のような、このサッカーの試合に関するいくつかの一般的な情報を覚えているかもしれませんし、いないかもしれません。5.3項では、このユースケースに対するセマンティック・ウェブの技術を用いた可能な解決策を提供します。
多くの組織が非常に大規模な画像コレクションを保持しています。例えば、アメリカ航空宇宙局(National Aeronautics and Space Administration、NASA)は、異なる形式、異なるレベルの可用性や解像度、様々なレベルの詳細や形式による関連記述情報を付与して格納された何十万もの画像を所有しています。また、このような組織は、収集・目録化した何千もの画像を継続的に作り出しています。したがって、様々な領域にまたがる多種多様なあらゆる画像コンテンツを目録化するための手段が必要です。画像自体(例えば、作成日、dpi、情報源)と、画像の特定の内容に関する情報の両方が必要です。さらに、関連するメタデータは、画像とデータの連関関係を累積的に構築できるように維持・拡張が可能でなければなりません。最後に、管理機能は、コンテンツ・タイプ、所有権、承認などに基づいて制限を付けることができるような柔軟なメカニズムを備えているべきです。5.4項では、このユースケースに対する解決策の例を提供します。
医療の提供者は、臨床アプリケーションや、教育、その他の目的の医療画像のアノテーション付与に関心があるかもしれません。患者治療に関わる診断画像は、異なる観点から適切にアノテーションを付与する必要があります。例えば、画像様式(レントゲン写真、MRIなど)、キャプチャー・パラメータ(時間を含む)、画像に描かれた患者の身体部位名、診療報告や電子カルテなどの関連する報告データなどです。このような画像を医療教育に用いる際には、承認のないユーザに個人情報が漏洩しないようにするために匿名化が必要です。教育用の画像には、様式の明確な記述、身体部位名、形態学上および診療上のコメントが必要です。このようなメタデータは、画像全体について記述していることもあれば、単に1つ以上のサブ領域について記述したものであることも多いため、何らかの方法で特定が必要です。教育用のメタデータは、ユーザに直接提示することも、自己学習技術を開発するために非公開にしておくことも可能です。5.5項では、これらの要件に対応した解決策の例を提供します。
ユースケースに対する解決策の例について論じる前に、この項では、最初の予想よりもずっと画像アノテーションを複雑にすることが多い問題に焦点を合わせ、一般的な画像アノテーションに関する概要を簡潔に提供します。さらに、後に提供する解決策を理解するために必要となる基本的なセマンティック・ウェブの概念について簡潔に論じます。
Flickrなどの人気のあるキーワード・ベースのタグ付けシステムの例のように、個人が利用する小規模な画像へのアノテーションの付与は、上記の最初のユースケースで述べたとおり、比較的簡単でありえます。残念ながら、より意欲的なアノテーション作業に対して、状況は急速に簡単でなくなります。より大規模な業務用として耐えうる画像アノテーションは複雑であることで有名です。規模の多様性に伴う背反性により、専門的なマルチメディアのアノテーションは困難になります。
作成時か作成後か
後からではなく先にアノテーションを付与するほうがはるかに簡単であるというのが通則です。通常は、アノテーションの作成に必要な情報の大部分は作成時に入手できます。例としては、大部分のデジタル・カメラが撮影時にJPEG画像に付与する、日時、レンズ設定やその他のEXIFメタデータ、科学や医学の画像における実験データ、創造産業界における脚本、ストーリー・ボード、編集リスト(EDL)の情報などが挙げられます。実際のところ、画像アノテーションにおけるおそらく「最も良い」唯一の慣行は一般的に、後の段階になって(デジタル・アーティファクトの自動分析や作成後に手入力するデータなどによって)メタデータを付与するよりも、作成過程でメタデータを付与するほうがはるかに安く、より高品質なアノテーションが作成できるということです。
一般的か作業特化か
明確なコンテキストや目標を考慮せずに画像にアノテーションを付与することは、しばしば費用効率がよくありません。新しい要件を十分にカバーしていない情報を使用して画像にアノテーションを付与していたということが、目標とするアプリケーションを開発した後に判明するかもしれません。アノテーションのやり直しは避けられませんが、高価な解決策です。他方では、目標とするアプリケーションのみを考慮したアノテーションも費用効率がよくないことがあります。アノテーションは、その1つのアプリケーションではうまく機能するかもしれませんが、同じメタデータを他のアプリケーションで再利用しようとすると、異なる状況での再使用には特定的過ぎて適当でないということが分かるかもしれません。ほとんどの場合、メタデータが将来的に使用されうるアプリケーションの範囲は、アノテーションの作成時には分かっていません。占いの水晶球でもなければ、アノテーターが実際にとることができる最善策は、不必要なアプリケーションに特化した想定をできるだけ避けながら、開発中のアプリケーションに十分特化した方法をとることです。
手入力か自動かと「セマンティック・ギャップ」
一般的に、手入力によるアノテーションは、正しいレベルの抽象化で画像の記述を提供できます。しかし、時間がかるため、高くつきます。さらに、非常に主観的なものになります。アノテーターが異なれば、同じ画像に対して別の「見方」をしがちです。他方で、自動的な特性抽出に基づくアノテーションは、比較的速く、安く、より体系的でありえます。しかし、多くのアプリケーションにとって画像記述のレベルが低過ぎるものになる傾向があります。画像解析ツールによって得られる低レベルの特性記述と、アプリケーションに必要な高レベルの内容記述の違いは、文献上ではしばしばセマンティック・ギャップと呼ばれています。残りの部分では、手入力と自動の両方における画像アノテーションに対するユースケースの解決策および語彙、ツールに関して論じます。
様々な種類のメタデータ
文献では様々な分類のメタデータに関して述べられていますが、アノテーターはみな、画像自体の特性について記述したアノテーションと、画像の内容すなわち画像によって表現された物や人、概念の特性について記述したもとの違いについて少なくとも意識しているべきです。最初の範疇の場合には、典型的なアノテーションとして、タイトル、作者、解像度、画像形式、画像サイズ、著作権、公表年などに関する情報を提供します。多くのアプリケーションは、このようなプロパティーを定義した、一般的で定義済みの比較的小さい語彙を使用します。例としては、ダブリン・コアとVRAコアの語彙が挙げられます。2番目の範疇は、画像によって何が表現されているかの記述であり、手元にある画像の種類によって大きく異なります。2番目の範疇は、画像によって何が表現されているかの記述であり、手元にある画像の種類によって大きく異なります。また、多くのアプリケーションでは、客観的な観察(「白いシャツを着た人が腕を左から右に動かしている」)と主観的な解釈(「人が武道をしているようだ」)を区別することも役に立ちます。その結果、この目的に使用される語彙には大きなばらつきがあります。典型的な例としては、領域固有の語彙(例えば、天文学の画像やスポーツの画像に非常に特化した用語の語彙)から領域非依存型の語彙(例えば、あらゆる報道写真について記述できるほど一般的な用語の語彙)まで様々です。さらに、語彙は、大きさ、粒度、形式などにおいて異なる傾向があります。
残りの部分では、上記のメタデータのカテゴリーについて論じます。最初の種類の場合、語彙はプロパティーを定義するだけであって、それらのプロパティーの値の定義は別の語彙に準拠するということは珍しくないことに注意してください。例えば、これは、ダブリン・コアとVRAコアの両方の場合に当てはまります。これは、通常、1つの画像にアノテーションを付与するために複数の語彙の用語が必要であることを意味します。
構文上およびセマンティック上の相互運用性の欠如
現在、様々な種類のファイル形式とツールが画像アノテーションに用いられています。相互運用性の欠如のために、別のツールで作成したメタデータを再利用できないことがしばしばあります。まず、あるツールはファイル形式ごとに異なる構文を使用するかもしれません。その結果、他のツールはこのツールが作成したアノテーションを読めなくなります。次に、特定のツールは同じアノテーションに異なる意味(セマンティクス)を割り当てるかもしれません。このような状況であれば、このツールは他のツールのアノテーションを読めるかもしれませんが、本来意図された方法でそれらを処理することはできないでしょう。
セマンティック・ウェブの技術を用いることによって、両方の問題を解決できます。まず、セマンティック・ウェブは、メタデータの構文とセマンティクスを明示的に定める手段を開発者に提供します。次に、開発者は、その用語が他のツールの用語にどのように関連するかを明示できるようになります。このドキュメントでは、両方の場合の例を提供します。
この項では、画像アノテーションにおけるセマンティック・ウェブ技術の役割について簡潔に説明します。セマンティック・ウェブの目的は、プログラム(または、「知的エージェント」)が資源(ウェブページや画像など)をより容易に解釈できるように既存のウェブを強化することです。ウェブ資源を、ウェブ資源のコンテンツおよび/または機能を表現したセマンティックなカテゴリーに関連付けようという構想です。
アノテーションのみではマークアップされている事物に関するセマンティクスを構築できません。アノテーションにセマンティクスを導入するために一般的にとられる1つの方法は、ある概念が何を意味し、それにどのような用語を使用しなければならないのかについてコミュニティーが合意を得ることです。

ダブリン・コアのメタデータ要素セット(Dublin Core Metadata Element Set)を用いてアノテーションを付与した画像に関する以下の例について考えてみてください。ダブリン・コアは「タイトル」、「作者」、「日付」などの15の「コアとなる」情報プロパティーを提供しています。以下のRDF/XMLのコードの例は、「Jeff Z. Panによって作成された画像であるGanesh.jpgがあり、そのタイトルはAn image of the Elephant Ganesh(ガネーシュ象の画像)である」というステートメントを表します。最初の4行は、この記述で使用するXML名前空間を定義しています。RDFに関する詳細な情報を得るための良い出発点はRDF入門です。
<rdf:RDF xml:base="http://example.org/"
xmlns="http://example.org/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="Ganesh.jpg">
<dc:title>An image of the Elephant Ganesh</dc:title>
<dc:creator>Jeff Z. Pan</dc:creator>
</rdf:Description>
</rdf:RDF>
上記の例の欠点は、すべてのメタデータの値の意味が文字列であるということで、自動的な手順で容易に解釈することができません。この意味に基づいて画像を処理する必要のあるアプリケーションは、この処理を自身のコードに組み込む必要があります。例えば、この画像が「動物に関するすべての画像を表示せよ」や「インドの神すべての画像を表示せよ」といったクエリと一致するかもしれないことをアプリケーションが発見するのは困難でしょう。
これを解決する方法は、その領域で使用される用語の意味に関する非形式的な合意を得ることから始め、これを形式的でマシン処理可能なバージョンに変えることです。このバージョンを通常、オントロジーと呼びます。これは、特定の領域に対し、重要な概念、そのプロパティー、相互関係、制約を含む、共有化された共通の語彙を提供します。この形式的な合意は、人間や異種の分散アプリケーション・システム間でやり取り可能です。オントロジー・ベースのアプローチは、開発が困難かもしれません。しかし、非形式的な合意のみに基づいたアプローチよりも強力です。例えば、マシンは、形式的な意味を推論に用いてアノテーションを完全で正当なものにできます。さらに、人間のユーザは、論理言語で表現された公理を使用して語彙をより完全に定義し、チェックできます。理想としては、オントロジーの概念とプロパティーは、人間とソフトウェア・アプリケーションが明確に使用できる形式的な定義と自然言語記述の両方を備えているべきです。
例えば、この写真に興味を持っているコミュニティーが、画像にアノテーションを付与するためにWordNetの語彙の概念を使用することに同意したと仮定してください。上記の例のdc:creator行の下に2行のRDFを簡単に追加できます。
<dc:subject rdf:resource="http://www.w3.org/2006/03/wn/wn20/instances/synset-Indian_elephant-noun-1"/> <dc:subject rdf:resource="http://www.w3.org/2006/03/wn/wn20/instances/synset-Ganesh-noun-1"/>
これで、WordNetの「インド象(Indian Elephant)」と「ガネーシュ(Ganesh)」の形式的に定義された概念を参照することにより、これらの概念を今まで一度も扱ったことがないアプリケーションであっても、WordNetの概念定義に関する詳細情報を要求し、例えば、「ガネーシュ」が「インドの神(Indian Deity)」という概念の下位概念語であり、「インド象」は動物界の「象科(Elephantidae)」族の「象類(Elephas)」属のメンバーであるということを知ることができます。
画像にアノテーションを付与するためにどの語彙を用いるかの選択は、アノテーション計画における重要な決定事項です。画像の様々な関連する側面をカバーするためには通常、複数の語彙が必要です。セマンティック・ウェブにおけるマルチメディア語彙(Multimedia Vocabularies on the Semantic Web)という名の別のドキュメントは、画像アノテーションに関連する個々の語彙とRDFやWOLへの変換について論じています。この項以外の部分では、より一般的な問題について論じています。
関連する語彙の多くがセマンティック・ウェブ以前に開発されています。この領域において最も有名で重要な国際標準で、MPEG-7として広く知られているマルチメディア・コンテンツ記述(Multimedia Content Description)は、XMLスキーマを用いて定義されています。執筆時点で、一般的に受け入れられている標準的なXMLスキーマ定義からRDFやOWLへのマッピング方法はありません。しかし、今までにいくつかの代替的なマッピング方法が開発されており、これらについてはMPEG-7およびセマンティック・ウェブのドキュメントで論じています。
その他の関連語彙は、VRAコアです。ダブリン・コア(DC)は、オンライン資源一般に対する小さな汎用語彙を定めており、一方で、VRAコアは視覚資源を特に対象とした同様の集合を定義しており、DC要素を特化しています。ダブリン・コアとVRAコアは、語彙の用語を要素として参照し、どちらも同じように要素を精緻化するための限定子を使用します。VRAコアのすべての要素は、ダブリン・コアの同等フィールドへの直接的なマッピングを有しているか、1つ以上のDC要素を特化したものとして定義されているかのどちらかです。さらに、両方の語彙は、実装の課題や基礎となるシリアル化言語から抜粋する方法で定義されています。しかし、大きな違いは、ダブリン・コアの場合は、一般的に受け入れられているRDFへのマッピング方法が、関連スキーマとともに存在しているということです。執筆時点では、これはVRAコアには当てはまらず、セマンティック・ウェブにおけるマルチメディア語彙のドキュメントでは代替のマッピング方法の是非について簡単に論じています。
セマンティック・ウェブに基づく多くのアノテーションは資源全体に関するものです。例えば、<dc:title>プロパティーは、ドキュメント全体に適用されます。画像やその他のマルチメディア・ドキュメントの場合、資源の特定の部分(例えば、画像のある領域)にアノテーションを付与する必要がしばしばあります。マルチメディア・コンテンツのある特定部分の位置指定を扱うメタデータを共有することは重要です。なぜならば、それにより同じコンテンツを参照する複数のアノテーション(複数のユーザによる可能性がある)を持つことができるからです。
画像の空間的に局在した領域にアノテーションを付与するには、少なくとも次の2つの可能性があります。
次の項では、画像用の既存アノテーション・ツールの一般的な特色について論じます。
画像のアーカイブ化や記述に用いられる多数のツールの中のいくつかをセマンティックなアノテーションに使用できるかもしれません。この項の目的は、適切な使用に向けたいくつかのガイドラインを提供するために、処理可能なコンテンツの種類や、精密なアノテーションが可能かどうかなどの、セマンティックな画像アノテーション・ツールの主な特性の一部を確認することです。これらのツールの利用者は、この特性を基準として用いることによって、特定のアプリケーションに最も適したツールを選択できます。
コンテンツの種類。ツールは、様々な種類のコンテンツにアノテーションを付与できます。通常、生のコンテンツは画像で、その形式は、jpg、png、tifなどでありえますが、映像にアノテーションを付与できるツールもあります。
メタデータの種類。アノテーションは、様々な利用目的を持つことができます。アメリカIIプロジェクトの作成が提供する分類に従うと、メタデータは、記述的(情報の記述および識別用)または構造的(ナビゲーションおよび提示用)、管理的(管理および処理用)でありえます。ほとんどのツールは、記述メタデータを提供するために使用することができ、そのうちの一部は、構造的および管理的な情報を提供してくれます。
メタデータの形式。アノテーションは、様々な形式で表現できます。他の(セマンティック・ウェブ)アプリケーションとの相互運用性を確保する必要があるため、この形式は重要です。セマンティック・ウェブの世界ではOWLとRDFのほうが適切ですが、自動分析結果を交換するためのメタデータ形式としてはMPEG-7がしばしば使用されています。
アノテーションのレベル。語彙を用いて画像にアノテーションを付与する機会を提供してくれるツールもあれば、フリー・テキストでのアノテーションのみが可能なものもあります。オントロジーを(RDFか、SKOS、OWL形式で)使用すると、一般的に、より形式的な方法でセマンティクスが提供されるため、アノテーションのレベルは統制されていると考えられますが、そうでない場合は、アノテーションのレベルはフリー形式であると考えられます。
クライアント・サイド要件。この特性は、サービスにアクセスするためにウェブ・ブラウザを使用できるのか、スタンドアロンのアプリケーションをインストールする必要があるのかを意味します。
ライセンス条件。オープンソースのものもあれば、そうでないものもあります。マルチメディア・アノテーションの分野の利用者および潜在的な研究者や開発者にとって、特定ツールを選択する前にこの課題について承知していることは重要です。
共同か個別か。この特性は、ウェブで共有可能な映像データベースのアノテーションの枠組みとしてツールを利用できるのか、個別利用者のマルチメディア・コンテンツ・アノテーション・ツールとして利用できるのかを意味します。
粒度。粒度は、アノテーションがセグメント・ベースなのか、ファイル・ベースなのかを定めています。使用目的によっては、画像の構造を示すことが重要でありえるため、これは重要な特性です。例えば、情報に関するいくつかの手がかり(テキスト部分や画像の部分のような)を記述したり、画像に描写されている異なる物体(例えば、人)を定義・記述したりと、画像の特異な部分に関するアノテーションを提供することは有益です。
スレッド式か非スレッド式か。この特性は、前のアノテーションに対応または追加し、これを反映するためにアノテーションの表示をずらして配置/構造化するツールの機能を意味します。
アクセス・コントロール。これは、利用者別に提供されるメタデータへのアクセスを意味します。例えば、簡単なアクセス権限(閲覧のみ)を有する利用者と完全なアクセス権限(閲覧や変更)を有する利用者を区別することは重要です。
最後に、ツールの適切さは利用者が必要とするアノテーションの性質に依存するため、あらかじめ判断することはできません。マルチメディア・セマンティクス・ツールおよび資源(Multimedia Semantics Tools and Resources)というウィキ・ページが別途維持されており、ウェブ上にある大部分のアノテーション・ツールが、上記の特性に従って分類されています。この別ドキュメントには、コメント、提案、新しいツールのお知らせが追加されるでしょう。以下の項で示しているように、ツールは、ユースケースに応じて、様々な種類のアノテーションに使用できます。
この項では、1項で示したユースケースを裏付けるために、セマンティック・ウェブの技術をいかに使用できるかに関する実現可能なシナリオを記述しています。これらのシナリオは、単に説明に役立つ実例として提供するものであり、W3Cメンバーやセマンティック・ウェブ・ベスト・プラクティスおよび開発ワーキンググループまたは、W3Cマルチメディア・セマンティクス・インキュベータ・グループによる承認を意味するものではありません。

1.1項で示した個人デジタル写真コレクションの管理に関するユースケースに対して提案したシナリオは、写真のアノテーションが、複数の語彙を用いてそのプロパティーとその内容を記述することを想定しています。作者、解像度、取り込み日付などの、画像自体のプロパティーは、DCおよびVRA語彙の用語で記述します。個人のデジタル・コレクションの写真の対象は潜在的に非常に広く、休暇、個人の過去の特別な出来事、風景、位置、人々、物などの概念を含むことがあるため、画像の内容の記述には、さまざまな既存の語彙を用い、領域固有のオントロジーはほとんど作成されません。
個人のデジタル写真コレクションの例として、タイのKaterina Tzouvaraという人物の休暇を表した写真を選びました。そして、画像に写っている人物について説明するためにFOAF語彙を使用しています。3つの領域固有のオントロジー「位置」、「風景」、「出来事」を使用しています。すべての語彙、オントロジー、アノテーション・ファイルに最も適したものとして、RDF形式が選ばれています。オントロジーとアノテーション・ファイルの編集には、あらゆる既存のエディタを使用できます(作成したRDFファイルを参照してください)。
最初に、アノテーション・ファイルの形式に関する決定をしなければなりません。相互運用性を得るためにRDFのRDF/XML構文を選択します。RDFのRDF/XML構文は、制約のオーバレイを持つ整形式のXMLであり、XMLの技術を用いて解析可能です。
アノテーション・ファイルの最初の行は、XML宣言の行です。その次の要素は、RDFベースのコンテンツを囲み込んだRDF要素です。RDF要素内では、ファイル内の各要素に関連している様々な名前空間が属性として宣言されます。これらの名前空間は、対象画像にアノテーションを付与するために特定の要素を用いてきた既存のRDFスキーマとオントロジーを参照します。特に、以下のスキーマが使用されています。
<!-- Declaration of the namespaces of the schemas and ontologies being used -->
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:event="http://www.example.org/ontologies/event#"
xmlns:locat="http://www.example.org/ontologies/location#"
xmlns:lsc="http://www.example.org/ontologies/landscape#"
xmlns:vra="http://e-culture.multimedian.nl/ns/vracore3.rdfs#>
(rdf:Description)に続く内部要素は、主語-述語-目的語のトリプルを囲い込みます。rdf:about属性で宣言されている主語は、アノテーションが付与される画像(URIで識別される)で、述語は画像のプロパティー、目的語はそのプロパティーの値です。
<rdf:Description rdf:about="http://www.w3.org/2005/Incubator/mmsem/XGR-image-annotation/Personal.jpg">
次のトリプルのブロックは、写真全体に関する一般的な情報を提供しています。ダブリン・コアの用語は、十分に一般化されており、メタデータ・コミュニティーに広く受け入れられているため、主にこのような情報を提供するために使用されています。最初の述語-目的語の対(pair)は、DC term-propertyの資源タイプ(dc:type)を述語として、DCMI Type term-conceptの画像(Image)を目的語として用いて、アノテーション・ファイルの対象が画像であると述べます。
次行のDC term-propertyの内容記述(dc:description)は、画像の主題に関する、簡潔な言語による人間が理解できる記述を提供します。
そして、画像の作者を指定するためにDC term-propertyの作者(dc:creator)が使用されています。作者が人である(そして、例えば、組織や会社ではない)と定義するために、FOAF term-classの人(foaf:Person)が使用されています。人の名前は、FOAF term-propertiesの姓(foaf:familyname)と名(foaf:firstname)を用いて定義されます。これらのプロパティーの値は、RDFリテラルです。広範的なfoaf:nameよりもこれらの2つのプロパティーの方が好ましいことに注意してください。なぜならば、個々の名前の構築に対する詳細な規則や標準がないため、姓と名は区別できないと推理エンジンが誤った判断をするかもしれないからです。
写真をキャプチャーした日をDCプロパティーの日付(dc:date)で記述し、これで記述は終わりです。このプロパティーのRDFリテラル値は、日付および時間を表現するためのISO 8601の仕様に準拠しています。
<!-- Description and general information about the entire photo, e.g. description, creator, date -->
<!-- using Dublin Core and FOAF -->
<dc:type rdf:resource="http://purl.org/dc/dcmitype/Image"/>
<dc:description>Photo of Katerina Tzouvara during Vacations in Thailand</dc:description>
<dc:creator>
<foaf:Person>
<foaf:familyname>Stabenaou</foaf:familyname>
<foaf:firstname>Arne</foaf:firstname>
</foaf:Person>
</dc:creator>
<dc:date>2002-12-04</dc:date>
写真のフォーマットと解像度に関するそれ以上の技術情報は、DCプロパティーのフォーマット(dc:format)、MIME語彙のJPEGという用語、およびVRA propertyのmeasurements.resolution(vra:measurements.resolution)を用いてアノテーション・ファイルに含まれています。この特定のユースケースではこれらはそれほど重要に思えないかもしれませんが、異なる性能のハードウェアやソフトウェアを持っているユーザ間で個人のデジタル写真を交換するためには、これらのプロパティーの存在が必要となります。
<!-- Technical information, e.g. format, resolution, using DC, VRA, MIME -->
<dc:format>JPEG</dc:format>
<vra:measurements.resolution>300 x 225px</vra:measurements.resolution>
残りのアノテーション・ファイルは、もっぱら画像の内容記述に関するものです。完全な内容記述を提供するためには、「いつ」「どこで」「なぜ」写真が撮影され、「だれ」と「何」が写真に描かれているかという質問に答えようとすることがしばしば役に立ちます。なぜなら、これらはエンドユーザが検索処理中に問い合せて欲しいと考える可能性が最も高い質問であるからです。
最初に、写真に描かれている位置と風景を記述します。そのために、この画像のアノテーションに求められるのと同程度の簡便さで、接頭辞がlocatの位置オントロジーと、接頭辞がlscの風景オントロジー、という2つの領域オントロジーが構築されます。位置オントロジーは、大陸(locat:Continent))、国(locat:Country)、都市(locat:City)などの概念や、特定の大陸(locat:located_in_Continent)、国(locat:located_in_Country)、都市(locat:located_in_City)で画像が撮影されたという事実を表すためのプロパティーを提供します。風景オントロジーのクラスは、山(lsc:Mountain)、ビーチ(lsc:Beach)、砂(lsc:Sand)、木(lsc:Tree)などの概念を表します。
FOAFプロパティーの描写(foaf:depicts)は、画像が描写する物や人の関係を表します。FOAFプロパティーの名前(foaf:name)は、どのよな種類の位置や風景にも特定の名前があるということを示します。TGN語彙は、例えばタイ(Thailand)のような位置や風景の名前に用いられ、AGROVOCシソーラスは、例えばPhoenix Dactylipheraのような農業に関連する名前に用いられます。ある都市が特定の国に属するという関係を表現するために、プロパティーlocat:belongs_to_Countryを使用します。
<!-- Information about the location and the objects depicted using a landscape ontology -->
<!-- and the TGN and AGROVOC thesaurus -->
<locat:located_in_Continent>
<locat:Continent>Asia</locat:Continent>
</locat:located_in_Continent>
<locat:located_in_Country>
<locat:Country>Thailand</locat:Country>
</locat:located_in_Country>
<locat:located_in_City>
<locat:City>
<foaf:name>Phi Phi</foaf:name>
<locat:belongs_to_Country>
<locat:Country>Thailand</locat:Country>
</locat:belongs_to_Country>
</locat:City>
</locat:located_in_City>
<foaf:depicts>
<lsc:Beach/>
</foaf:depicts>
<foaf:depicts>
<lsc:Palm_Tree>Phoenix Dactyliphera</lsc:Palm_Tree>
</foaf:depicts>
<foaf:depicts rdf:resource="http://www.example.org/ontologies/landscape#Sand"/>
このユースケースにセマンティック・ウェブの技術を用いる利点は、もうこの段階で示すことができます。アノテーション・ファイルには、どの国で写真が撮影されたかを完全に明示的に宣言する行は含まれていないけれども、タイに属する都市ピピ(Phi Phi)で撮影されたと記述した行のみが含まれていたと仮定してください。タイが描かれた写真を検索する問い合わせをエンドユーザが行った時には、推論技術を用いたデジタル写真コレクション管理用アプリケーションは、タイを表示するように明確に宣言された全ての写真を結果として返すべきですが、例えば、タイに属する都市で撮影されたと明確に宣言することでタイが描かれていると暗に宣言している全ての写真も返すべきです。
画像に写っている出来事を記述するためには、重要な出来事を表す簡単なオントロジーが人間のために作成されます。このオントロジーは、ビジネス旅行(event:Business_Travelingやevent:Conference)、休暇(event:Vacations)、スポーツ活動(event:Sports_Activity))、祝典(event:Celebrationやevent:Birthday_Party)などのような出来事を概念化します。
<!-- Information about the kind of event depicted by the image -->
<foaf:depicts rdf:resource="http://www.example.org/ontologies/event#Vacations"/>
最後に、画像上の人間を識別するためにfoaf:depictsプロパティーとfoaf:Personの概念が用いられます。
<!-- Information about the persons depicted by the image -->
<foaf:depicts>
<foaf:Person>
<foaf:familyname>Tzouvara</foaf:familyname>
<foaf:firstname>Katerina</foaf:firstname>
</foaf:Person>
</foaf:depicts>
</rdf:Description>
</rdf:RDF>
アノテーション処理に関するこの分析から、セマンティック・ウェブ技術の効率を高めるために、多くの重要課題について検討されていることが明らかです。まず最初に、FOAF、VRA、TGNのような様々な語彙には、OWLやRDFなどの標準化されたオントロジー言語における標準化された表現がまだありません。次に、画像資料の内容記述に関する領域固有の語彙はあまり存在していません。例えば、風景や個人的な過去の出来事に関する語彙もなければ、画像に描かれ得る事物に関する語彙もありません。このアノテーション標準の欠如は、管理と検索の処理において、異なる種類のアノテーションを付与されたコンテンツの間で相互運用性の問題を引き起こします。最後に、別の重要な懸案事項は、どの深さまでアノテーションの処理を進めるべきかということです。上記の例では、人の衣服にもアノテーションを付与することが重要だと思う人がいるかも知れませんし、ビーチにある物などについてアノテーションを付与する方が重要だと考える人もいるかもしれません。これは、エンドユーザのニーズに従って定義されるべきアノテーションの方法に関する問題です。
結論として、マルチメディア素材の記述に対するセマンティック・ウェブ技術の使用には、まだ改良の余地が多くあります。しかし、このユースケースの分析で示されているように、パーソナル・コンピュータのアプリケーションにオントロジー・ベースのアノテーションを利用できるようにすると、はるかに集中的かつ統合的なコンテンツ管理が可能になり、個人の写真の交換が容易になるでしょう。
1.2項で記述したユースケースの要件の多くは、VRAで開発された語彙をGettyのAATやULANなどの領域固有の語彙と組み合わせて用いることで満たすことができます。この項では、例として英語では「Garden at Sainte-Adresse」として知られている、クロード・モネの絵画のRDFアノテーションを提供しています。これはニューヨークのメトロポリタン美術館のコレクションのひとつです。対応するRDFファイルは、別の文書として入手できます。アノテーションを作成するために特別なアノテーション・ツールは使用していません。同様のメタデータを作成する必要がある文化遺産機関は、自分達のコレクションのデータベースの既存の情報をRDFにエクスポートすることによって、それを実現するでしょう。以下では、このファイルで使用されている様々なアノテーションについて論じています。
ファイルは、XMLバージョンの定義、後に使用するRDFとVRAの名前空間に対するエンティティーのエンコードおよび定義によって、典型的なRDF/XMLファイルとして始まります。Mark van Assemが開発したVRAコアのRDF/OWLスキーマを使用していることに注目してください。
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY vra "http://e-culture.multimedian.nl/ns/vracore3.rdfs#">
例には同じ絵画の2つの異なる画像に関するアノテーションが含まれています。VRA語彙が実行する重要な区別は、美術作品自体について記述したアノテーションと、その作品の(デジタル)画像について記述したアノテーションとの区別です。この例でもこの区別を使用します。RDFでは、資源に関して何かを述べるためには、その資源がURI を持っている必要があります。したがって、2つの画像のURIだけではなく、絵画自体のURIも必要となるでしょう。
<!ENTITY image1 "http://www.metmuseum.org/Works_Of_Art/images/ep/images/ep67.241.L.jpg"> <!ENTITY image2 "http://www.artchive.com/artchive/m/monet/adresse.jpg"> <!ENTITY painting "http://thing-described-by.org/?http://www.metmuseum.org/Works_Of_Art/images/ep/images/ep67.241.L.jpg"> ]>
VRAコアは、作品、画像、アノテーションの記録をどう識別すべきかを定めていません。この2つの画像の場合、我々は、識別用のURIとして画像のURIを使用するという最も簡単な解決策を選ぶことにしました。しかし、絵画自体を識別する似たようなURIがありませんでした。我々は、複数の画像のうちの1つのURI を再利用できませんでした。これは、概念的に間違っているだけではなく、技術的なエラーにもつながりえます。これは、vra:Imageという既存のインスタンスやvra:Workクラスのインスタンス作成するでしょう。しかし、これはスキーマでは許されていません。
例では、画像のうちの1つのURIを任意に選択し、その前にhttp://thing-described-by.org/?を置くことにより、絵画のURIを「作り出す」ことにしました。これにより、画像自体とは異なる新しいURIが作成されますが、ブラウザがこれを解決する際には、ウェブ・サーバであるthing-described-by.orgが画像のURIにリダイレクトするでしょう(httpに基づくURIの使用がこの場合に本当に適切であるかどうかが議論になりえます。この議論に関する詳細は、HTTPのURIが何を識別するのか?および[httpRange-14]を参照してください)。
警告: 以下に記述しているアノテーションには、vra:idNumber.currentRepository要素も含まれており、これは美術館の収納庫でローカルに使用されている識別子を定義します。これらのローカルな識別子を、URIで提供されるグローバルに一意な識別子と混同しないでください。
次の行でRDFブロックが始まり、上記で定義したXMLエンティティーを用いて名前空間を宣言します。利便性のため、使用されているVRAスキーマをエージェントが発見しやすいようにrdf:seeAlsoを使用します。
<rdf:RDF xmlns:rdf="&rdf;" xmlns:vra="&vra;" rdf:seeAlso="http://www.w3.org/2001/sw/BestPractices/MM/vracore3.rdfs" >
以下の行は、絵画自体のプロパティーについて記述しています。2つの画像のプロパティーは、後ほど扱うつもりです。最初に、タイトル、作者や作成日などの絵画に関する一般的な情報を提供しています。これらのプロパティーに関しては、VRAはダブリン・コアの規定に厳密に従います。
<!-- Description of the painting -->
<vra:Work rdf:about="&painting;">
<!-- General information -->
<vra.title>Jardin à; Sainte-Adresse</vra.title>
<vra:title.translation>Garden at Sainte-Adresse</vra:title.translation>
<vra:creator>Monet, Claude</vra:creator> <!-- ULAN ID:500019484 -->
<vra:creator.role>artist</vra:creator.role> <!-- ULAN ID:31100 -->
<vra:date.creation>1867</vra:date.creation>
多くの値はRDFリテラルで埋められており、スキーマによる値の制約はしていません。しかし、これらの値の多くは実際には、GettyのAATやULAN、MIMEで定義されている画像タイプなどの、別の統制語彙の用語です。統制語彙を使用すると、フリー・テキストのアノテーションに伴う多くの問題を解決できます。例えば、 ULANは、芸術家の名前を索引付けする際には、1つの綴りを用いることを推奨しているため、我々はその綴り(「Monet, Claude」)をvra:creatorフィールドに使用しました。クロード・モネおよび「芸術家」(artist)というクラスを記述した、データ内のULAN識別子のクラスを上記のXMLコメントで示しています。統制語彙を使用することにより、後になって、異なる綴りの同じ名前を混同したり、「統合」が必要になったりすることを避けることができます。
しかし、統制語彙を使用しても不明確な用語の問題は解決されません。以下のアノテーションでは、「oil paint」(油絵の具)、「oil paintings」(油絵)、「oil painting (technique)」(油絵(技法))に対し、3つの異なる意味を使用しています。1番目はキャンバス上で用いられる絵の具の種類、2番目は作品の種類(例えば、作品は油絵でありエッチングではない)、最後は芸術家が使用した絵画技法を意味します。3つの用語はすべて、AAT用語階層構造の異なる枝に属する異なる概念を指し示します(これらの概念のAAT識別子はXMLコメントで記述します)。しかし、異なる概念に非常に似た用語を使用すると混乱は必至でしょう。そうではなく、owl:datatypePropertiesの使用からowl:objectPropertiesの使用に切り替え、リテラルのテキストを、使用している概念のURIへの参照に置き換えることができます。例えば、
<vra:material.medium>oil paint</vra:material.medium>
を
<vra:material.medium rdf:resource="http://e-culture.multimedian.nl/ns/getty/aat#300015050"/>
に変更できます。
しかし、この方法には、対象語彙のすべての用語に対して一意なURIに基づく命名スキームが定義されている必要があります(そして、この場合、そのようなURIに基づく命名スキームはAAT用語にはまだ存在していません)。追加的なセマンティック・ウェブに基づく処理も、一旦これらの語彙がRDFやOWLで利用できるようになったときのみに可能となります。
<!-- Technical information -->
<vra:measurements.dimensions>98.1 x 129.9 cm</vra:measurements.dimensions>
<vra:material.support>unprimed canvas</vra:material.support> <!-- AAT ID:300238097 -->
<vra:material.medium>oil paint</vra:material.medium> <!-- AAT ID:300015050 -->
<vra:type>oil paintings</vra:type> <!-- AAT ID:300033799 -->
<vra.technique>oil painting (technique)</vra.technique> <!-- AAT ID:300178684 -->
<!-- Associated style, etc. -->
<vra:stylePeriod>Impressionist</vra:stylePeriod> <!-- AAT ID:300021503 -->
<vra:culture>French</vra:culture> <!-- AAT ID:300111188 -->
多くのアプリケーションにとって、絵画に何が実際に描かれているかを知るのは役に立ちます。この形式のアノテーションを任意のレベルの詳細情報に追加できます。例を簡潔なものにしておくために、絵画に描かれている人々の名前のみをvra:subjectフィールドを用いて記録することにしました。同じく簡潔さのために、絵画の特定の部分や領域にアノテーションを付与しないことにしました。これは、例えば絵画内の様々な人物が描かれている関連領域の識別などに適していたかもしれません。
<!-- Subject matter: (who/what is depicted by this work -->
<vra:subject>Jeanne-Marguerite Lecadre (artist's cousin)</vra:subject>
<vra:subject>Madame Lecadre (artist's aunt)</vra:subject>
<vra:subject>Adolphe Monet (artist's father)</vra:subject>
以下のフィールドの多くは、絵画の現在の状況に関する情報ではなく、絵画が過去に属していた場所やコレクションに関する情報を含んでいます。これは、この領域において重要な来歴情報を提供しています。
<!-- Provenance -->
<vra:location.currentSite>Metropolitan Museum of Art, New York</vra:location.currentSite>
<vra:location.formerSite>Montpellier</vra:location.formerSite>
<vra:location.formerSite>Paris</vra:location.formerSite>
<vra:location.formerSite>New York</vra:location.formerSite>
<vra:location.formerSite>Bryn Athyn, Pa.</vra:location.formerSite>
<vra:location.formerSite>London</vra:location.formerSite>
<vra:location.formerRepository>
Victor Frat, Montpellier (probably before 1870 at least 1879;
bought from the artist); his widow, Mme Frat, Montpellier (until 1913)
</vra:location.formerRepository>
<vra:location.formerRepository>Durand-Ruel, Paris, 1913</vra:location.formerRepository>
<vra:location.formerRepository>Durand-Ruel, New York, 1913</vra:location.formerRepository>
<vra:location.formerRepository>
Reverend Theodore Pitcairn and the Beneficia Foundation, Bryn Athyn, Pa. (1926-1967),
sale, Christie's, London, December 1, 1967, no. 26 to MMA
</vra:location.formerRepository>
<vra:idNumber.currentRepository>67.241</vra:idNumber.currentRepository> <!-- MMA ID number -->
残りのプロパティーは、メタデータと権利管理ステートメントを作成するために用いた資源の起源を記述しています。vra:description要素を用いて、ウェブページへのリンクに追加記述情報を提供しています。
<!-- extra information, source of this information and copyright issues -->
<vra:description>For more information, see
http://www.metmuseum.org/Works_Of_Art/viewOne.asp?dep=11&viewmode=1&item=67%2E241§ion=description#a</vra:description>
<vra:source>Metropolitan Museum of Art, New York</vra:source>
<vra:rights>Metropolitan Museum of Art, New York</vra:rights>
最後に、解像度、著作権などが異なる2つの絵画の画像に特有のプロパティーを定義しています。最初のアノテーションはメトロポリタン自身のウェブサイトにある500×300ピクセルの画像について記述しており、2番目のものはMark Hardenのアーカイブのウェブサイトにあるより大きな解像度(1075×778ピクセル)の画像のプロパティーを記述しています。VRAコアは作品とその関連画像がどのように関連付けられるべきかを指定しないことに注意してください。例では、Van Assemの提案に従い、vra.relation.depictsを用いて、画像を、画像に描写されている作品に明示的にリンクしています。
<!-- Description of the first online image of the painting -->
<vra:Image rdf:about="&image1;">
<vra:type>digital images</vra:type>
<!-- AAT ID: 300215302 -->
<vra:relation.depicts rdf:resource="&painting;"/>
<vra.measurements.format>image/jpeg</vra.measurements.format>
<!-- MIME -->
<vra.measurements.resolution>500 x 380px</vra.measurements.resolution>
<vra.technique>Scanning</vra.technique>
<vra:creator>Anonymous employee of the museum</vra:creator>
<vra:idNumber.currentRepository>ep67.241.L.jpg</vra:idNumber.currentRepository>
<vra:rights>Metropolitan Museum of Art, New York</vra:rights>
</vra:Image>
<!-- Description of the second online image of the painting -->
<vra:Image rdf:about="&image2;">
<vra:type>digital images</vra:type>
<!-- AAT ID: 300215302 -->
<vra:relation.depicts rdf:resource="&painting;"/>
<vra:creator>Mark Harden</vra:creator>
<vra.technique>Scanning</vra.technique>
<vra.measurements.format>image/jpeg</vra.measurements.format>
<!-- MIME -->
<vra.measurements.resolution>1075 x 778px</vra.measurements.resolution>
<vra:idNumber.currentRepository>adresse.jpg</vra:idNumber.currentRepository>
<vra:rights>Mark Harden, The Artchive, http://www.artchive.com/</vra:rights>
</vra:Image>
</vra:Work>
</rdf:RDF>
上例は、いくつかの未確定の技術的な課題を露呈しています。例えば、絵画のURIの作り出し方はかなり恣意的です。望ましくは、一般に受け入れられている絵画のURIスキームが存在していたでしょう(c.f.:生命科学の概念を識別するために用いられるLSIDスキーム)。執筆時点では、ここで使用したVRAおよびAAT、ULAN語彙には現在、一般に認められているRDFやOWLの表現がないため、選択しだアプローチの相互運用性が低くなります。別の課題は、ツールのサポートです。既にRDFをサポートし始めている大手のデータベース業者もありますが、既存コレクションのデータベースからここで示しているような種類のRDFを生成するには、多くの場合、大きなカスタム変換ソフトウェアが必要でしょう。
モデリングの観点から、主題のアノテーションは常に大変です。上で述べたように、これは非常にアプリケーションに依存したものでありえるため、何にどの深さまでアノテーションを付与すべきかに関する一般的なガイドラインを示すことは困難です。この例では、絵画に登場する人々にアノテーションを付与し、2つの画像のURIではなく、絵画のURIのプロパティーとしてこの情報をモデル化したことに注意してください。しかし、ユースケースをわずかに変更し、1つの通常の画像とその下にある古い絵画を示した1つのX線画像にすれば、より特定的な主題アノテーションを特定の画像のプロパティーとしてモデル化する意味をより理解できたかもしれません。
それにもかかわらず、例では、ユースケースで記述した課題の大部分が、現在のセマンティック・ウェブの技術を用いて解決できるということを示しています。これは、絵画の様々な側面とそれを描写している画像にアノテーションを付与するために、どのようにRDFを既存の語彙と共に用いることができるかを示しています。
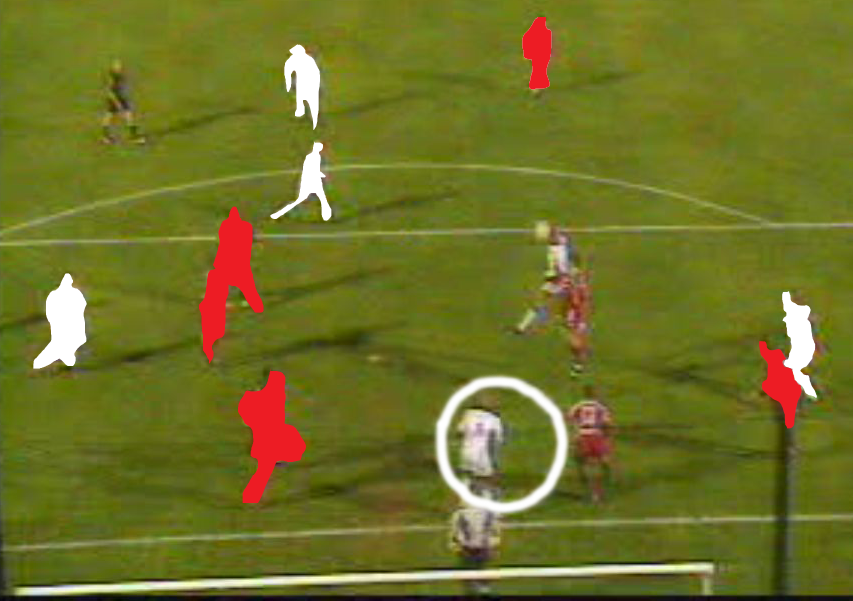 パートナーがゲーム中にヘティングで得点している時のサッカー選手のオフサイド位置を表す図。
パートナーがゲーム中にヘティングで得点している時のサッカー選手のオフサイド位置を表す図。1.3項で記述したユースケースは、複数の語彙を使用する必要がある典型的なものです。記述する画像が、特定の試合中(例えば、2002年3月16日に試合をしたオセール対メッツ)にオフサイド・ポジションのために無効になったあるサッカー選手(例えば、J.A Boumsong)のゴールに関するものであると仮定します。まず、テレビで放送された週刊スポーツ・マガジンから画像を抽出できます。この番組は、[TV Anytime forum]が開発した語彙を用いて完全に記述できます。次に、この画像は、オセール対メッツ戦においてJean-Alain Boumsong選手がヘティングで得点した様子を示しています。このサッカーの試合に関するコンテキストは[MPEG-7]の語彙を用いて記述でき、一方で、この動作自体は[Tsinaraki]が開発したような サッカー(または、フットボール)オントロジーで記述できるかもしれません。最後に、サッカー・ファンは、このゴールが実際には別選手のオフサイド・ポジションによって無効になったことに気付くかもしれません。画像では、良くない位置にいたこの選手を円で強調できます。再び、該当する画像の範囲を定めるためのMPEG-7の語彙と、動作自体を記述するための領域固有のオントロジーを組み合わせて記述できます。
以下では、例として、これらの3つのレベルの記述に加え、関連する語彙を示したRDFアノテーションを提供しています。
フランスの公共チャンネルであるFrance 2で2002年3月17日に放送されたStade 2という名の週刊スポーツ・マガジンの画像があると想定しましょう。このコンテキストは、テレビ(または、ラジオ)のアナウンサーがウェブや電子番組ガイドで番組のリストを作成するために用いているTV Anytimeの語彙を使用して表すことができます。したがって、この語彙は、番組を目録化するために必要な概念と関係性を提供し、対象者に、形式やジャンル、何らかの保護者同伴指定の情報を提供します。語彙には、広告料に適応させるために極めて重要な、実際の対象者や最高視聴時間を後になってアナウンサーが記述するための語彙も含まれています。
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
]>
<rdf:RDF
xmlns:rdf="&rdf;"
xmlns:xsd="&xsd;"
xmlns:tva="urn:tva:metadata:2002">
<tva:Program rdf:about="program1">
<tva:hasTitle>Stade 2</tva:hasTitle>
<tva:hasSynopsis>Weekly Sports Magazine broadcasted every Sunday</tva:hasSynopsis>
<tva:Genre rdf:resource="urn:tva:metadata:cs:IntentionCS:2002:Entertainment"/>
<tva:Genre rdf:resource="urn:tva:metadata:cs:FormatCS:2002:Magazine"/>
<tva:Genre rdf:resource="urn:tva:metadata:cs:ContentCS:2002:Sports"/>
<tva:ReleaseInformation>
<rdf:Description>
<tva:ReleaseDate xsd:date="2002-03-17"/>
<tva:ReleaseLocation>fr</tva:ReleaseLocation>
</rdf:Description>
</tva:ReleaseInformation>
</tva:Program>
</rdf:RDF>
1.4項のユースケースで示した要件に対する1つの可能な解決策は、オントロジー(OWL、そして/または、RDFS)の概念を用いて、画像、そして/または、その範囲に関する情報に利用者がアノテーションを付与できるようなアノテーションの環境です。より明確に言えば、主題の専門家ならば、画像やその特定の内容に関するメタデータ要素を言明できるでしょう。マルチメディア関連のオントロジーを用いて、特定の画像内の範囲を特定し、表現できます。そして、描写(または、アノテーション)プロパティーによって、この範囲と画像を関連付けることができます。例えば、MINDSWAPデジタル・メディア・オントロジー,を、(画像の描写を言明するために)FOAFと併用することにより(画像や画像の範囲などを表現するために)この機能を提供できます。さらに、範囲に関する低いレベルの画像特性を表現するためには、aceMediaビジュアル記述子オントロジー(aceMedia Visual Descriptor Ontology)を使用できます。
このような画像の内容を記述するためには、画像内に描写されている、領域固有の内容を表す仕組みが必要です。このユースケースの場合、空間特化の概念と関係性を定義する領域オントロジーを使用できます。このようなオントロジーは、自由に入手でき、以下のものが含まれています(しかし、これらに限られていません)。
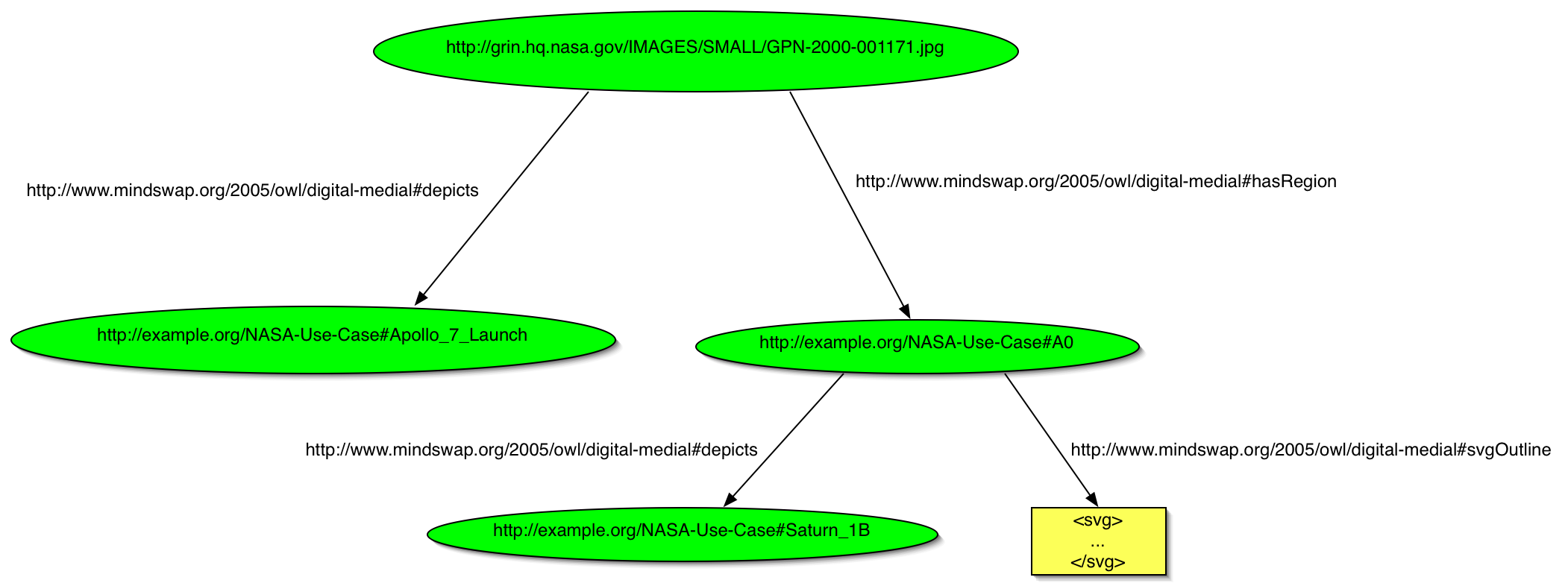
上で論じたように、このシナリオには、画像(そして、できればその範囲)がある事物を描写していると述べる能力が必要です。例えば、アポロ7号土星ロケットの発射の写真を考えてみてください。画像がアポロ7号の発射を描写しており、ロケットの周りの長方形の範囲内にアポロ7号土星IB宇宙船が描かれていて、画像の作者はNASAであるなどということを含む言明を行いたいと考えるでしょう。これを達成できる1つの方法は、FOAFやMINDSWAPデジタル・メディア・オントロジーを含む、様々なマルチメディア関連のオントロジーを組み合わせて使用することです。より明確に言えば、画像描写は、MINDSWAPデジタル・メディア・オントロジーで定義されている描写プロパティー(foaf:depictionのサブプロパティー)で言明できます。したがって、ウェブで定義されたインスタンスに画像をセマンティックにリンクできます。画像の範囲は、ImagePartの概念(MINDSWAPデジタル・メディア・オントロジーでも定義されている)で定義できます。さらに、svgOutlineというプロパティーを用いて、範囲にバウンディング・ボックスを加えることができ、これによって画像の部分の位置指定が可能になります。基本的に、範囲のSVG輪郭(SVG XMLリテラル)は、このプロパティーを用いて指定できます。ダブリン・コアやEXIFスキーマを用いて、作者、大きさなどを含む、画像に関するより一般的なアノテーションも言明できます。以下のRDFグラフでは、これらのサンプル・アノテーションのサブセットを示しています。
このRDFグラフは、このアプローチでどのようにメタデータを画像にリンクするかを示しています。
http://www.mindswap.org/2005/owl/digital-media#depictsで識別されます。http://www.mindswap.org/2005/owl/digital-media#hasRegionで識別されます。http://www.mindswap.org/2005/owl/digital-media#svgOutlineおよびSVG断片を用いて位置指定されます。さらに、アポロ7号発射の全体的なアノテーションは、このRDF/XMLファイルにあり、以下に再作成しています。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:svg="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink/"
xmlns:j.0="http://www.w3.org/2003/12/exif/ns#"
xmlns:j.1="http://www.mindswap.org/2005/owl/digital-media#"
xmlns:j.2="http://semspace.mindswap.org/2004/ontologies/System-ont.owl#"
xmlns:j.3="http://semspace.mindswap.org/2004/ontologies/ShuttleMission-ont.owl#"
xml:base="http://example.org/NASA-Use-Case">
<!-- Description of the whole image that contains the A0 region -->
<rdf:Description rdf:about="http://grin.hq.nasa.gov/IMAGES/SMALL/GPN-2000-001171.jpg">
<j.0:imageLength>640</j.0:imageLength>
<dc:date>10/11/1968</dc:date>
<dc:description>Taken at Kennedy Space Center in Florida</dc:description>
<j.1:depicts rdf:resource="#Apollo_7_Launch"/>
<j.1:hasRegion rdf:nodeID="A0"/>
<dc:creator>NASA</dc:creator>
<rdf:type rdf:resource="http://www.mindswap.org/~glapizco/technical.owl#Image"/>
<j.0:imageWidth>451</j.0:imageWidth>
</rdf:Description>
<!-- Description of what depicts the whole image -->
<rdf:Description rdf:about="#Apollo_7_Launch">
<j.3:launchDate>10/11/1968</j.3:launchDate>
<j.3:codeName>Apollo 7 Launch</j.3:codeName>
<j.3:has_shuttle rdf:resource="#Saturn_1B"/>
<rdfs:label>Apollo 7 Launch</rdfs:label>
<j.1:depiction rdf:resource="http://grin.hq.nasa.gov/IMAGES/SMALL/GPN-2000-001171.jpg"/>
<rdf:type rdf:resource="http://semspace.mindswap.org/2004/ontologies/ShuttleMission-ont.owl#Launch"/>
</rdf:Description>
<!-- Description of the A0 region -->
<rdf:Description rdf:about="A0">
<j.1:depicts rdf:resource="#Saturn_1B"/>
<rdf:type rdf:resource="http://www.mindswap.org/~glapizco/technical.owl#ImagePart"/>
<rdfs:label>region2407</rdfs:label>
<j.1:regionOf rdf:resource="http://grin.hq.nasa.gov/IMAGES/SMALL/GPN-2000-001171.jpg"/>
<j.1:svgOutline>
<svg:svg xml:space="preserve" width="451" heigth="640" viewBox="0 0 451 640">
<image xlink:href="http://grin.hq.nasa.gov/IMAGES/SMALL/GPN-2000-001171.jpg" x="0" y="0" width="451" height="640" />
<rect x="242.0" y="79.0" width="46.0" height="236.0" style="fill:none; stroke:yellow; stroke-width:1pt;"/>
</svg:svg>
</j.1:svgOutline>
</rdf:Description>
<!-- Description of what depicts the A0 region -->
<rdf:Description rdf:about="#Saturn_1B">
<rdfs:label>Saturn 1B</rdfs:label>
<rdf:type rdf:resource="http://semspace.mindswap.org/2004/ontologies/System-ont.owl#ShuttleName"/>
<j.1:depiction rdf:nodeID="A0"/>
</rdf:Description>
</rdf:RDF>
画像の低いレベルの特性を表すためには、aceMediaビジュアル記述子オントロジーを使用できます。このオントロジーにはMPEG-7ビジュアル記述子の表現が含まれており、物体の視覚特性を記述する概念とプロパティーをモデル化します。例えば、ドミナント・カラー記述子を用いて、関心領域内に存在するドミナント・カラーの数と値、および、各関連色の値が持つピクセルの割合を記述できます。
PhotoStuffやM-OntoMat-Annotizerのような既存のツールキットは現在、グラフィカルな環境を用いて、上記のアノテーション作業を実行できます。利用者は、このようなツールを用いて、画像を読み込み、画像の部分の周辺に範囲を指定し、選択範囲における低いレベルの特性を自動的に抽出し(M- OntoMat-Annotizerによって)、選択範囲に関するステートメントを出す、などを行うことができます。さらに、その結果として作成されたアノテーションをRDF/XMLとしてエクスポートすることができ(上で示したように)、したがって、それを共有、索引付けし、アノテーションに基づく高度な閲覧(および検索可能な)環境で使用できます。
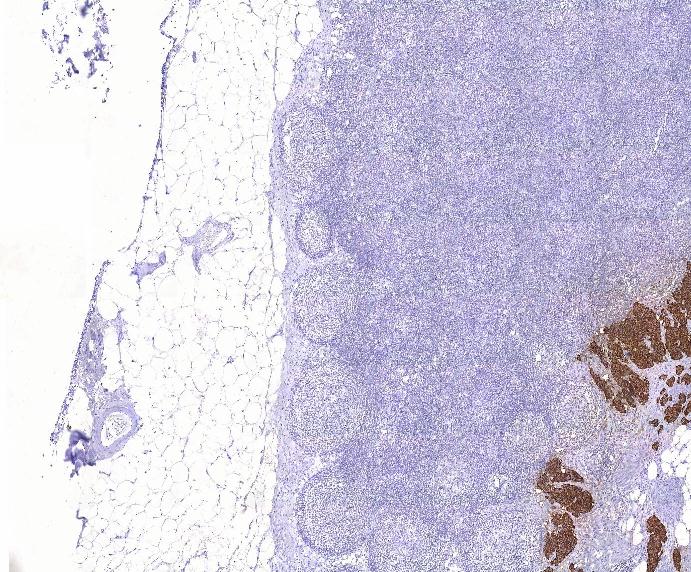 リンパ組織の顕微鏡画像。
リンパ組織の顕微鏡画像。1.5項で記述したユースケースで示した要件に対する解決策には、画像とその領域に関する情報のアノテーションに対するサポートが含まれています。
生物医学の領域で既に用いられている数多くの統制語彙(ICD9、MeSH、SNOMEDなどのシソーラスやオントロジーを含む)から考えると、アノテーションは、自由な形式のテキストやキーワードのみではなく、これら統制語彙の概念を使用できるべきです。そして、既に大量のデータの蓄積(電子カルテを含む)を利用できることから考えると、完全手動でアノテーションを処理すべきではありません。そのかわり、メタデータをこれらの既存の情報源に(半)自動的にリンクするか、これらから抽出すべきです。医療画像処理では、放射線学用のDICOMのように、メタデータを記録できる画像形式によって、既に画像アノテーションは行われています。できれば、このような組み込み型のメタデータ画像形式でセマンティック・ウェブの解決策を相互運用できるようにすべきです。
このような画像の内容を記述するためには、画像内に描写された、領域固有の内容を表現する仕組みが必要です。生物医学の概念に対しては、以下を含む多くの語彙を利用できますが、これらに限定されているわけではありません。
また、国立医学図書館は、さまざまな言語で書かれた60以上の生物医学用語を基にした用語をセマンティックなネットワークで接続したメタシソーラス(meta-thesaurus)を含んでいるUMLS(Unified Medical Language System)を開発しました。これらのオントロジーの元の形式はすべて、RDFやOWLではありません。しかし、これらの言語に変換可能です(または、既に変換済みです)。上記のすべてのメタデータは、これらのうちの1つ以上の語彙がカバーしています。さらに、UMLSのおかげで、メタシソーラスを架け橋として用いることで、1つの語彙から別の語彙へと移行することも可能です。
例として、D005753という一意のIDを持つ胃粘膜をMeSHから取り込むことができ、胃の一部として消化器系のサブツリーや、細胞膜の中の組織のサブツリーに置かれます。
この種のメタデータは、通常よりも高い再現率で画像を検索するのに役立つかもしれません。実際に、学生は胃の画像を検索するかもしれません。推奨通りにアノテーションが付与されていれば、MeSHオントロジーでは胃粘膜は胃の一部であるため、学生はこの胃粘膜の画像を発見できるでしょう。その一方で、画像が特定の種類の膜を描写しているため、膜のサンプルを探すときにもこの画像を発見するでしょう。皮膜に関するクエリにも、画像の主題ではないけれども一部ではあるという、同じことが言えます。
1つのシナリオとして、組織の微視的構造について研究している分野である、組織学の医学的分野の画像について考えてみましょう。顕微鏡を用いて画像を取得し、教育の目的で蓄積します。この特定の目的では、実用的な患者データを用いて画像にアノテーションを付与する必要は全くありません。しかし、画像の意味を解釈するためにはいくつかの個人データが必要です。例えば、年齢と性別の意味は、患者の個人および家族の履歴と同様に、役に立つことがある変数です。また、これらは画像のアノテーションになりえ、ゆくゆくは、同じツールまたは他の様式で得られる、同じ患者の他の画像のアノテーションにもなりえます。これは、以下のRDFコード(この場合、image1.jpgとimage2.jpg)に相当し、その場合、同じ患者に多くの画像を関連付けられるとも考えられます。
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://www.telemed.uniud.it/cases/case1/">
<dc:creator>Beltrami, Carlo Alberto</dc:creator>
<dc:contributor>Della Mea, Vincenzo</dc:contributor>
<dc:title>Sample annotated image</dc:title>
<dc:subject>
<dcterms:MESH>
<rdf:value>A10.549.400</rdf:value>
<rdfs:label>lymph nodes</rdfs:label>
</dcterms:MESH>
</dc:subject>
<dc:subject>
<dcterms:MESH>
<rdf:value>C04.697.650.560</rdf:value>
<rdfs:label>lymphatic metastasis</rdfs:label>
</dcterms:MESH>
</dc:subject>
<dc:subject>
<dcterms:MESH>
<rdf:value>C04.557.470.200.025.200</rdf:value>
<rdfs:label>carcinoid tumor</rdfs:label>
</dcterms:MESH>
</dc:subject>
<dc:date>2006-05-30</dc:date>
<dc:language>EN</dc:language>
<dc:description>Female, 86 yrs. Some clinical history. This field might be further structured.</dc:description>
<dc:identifier>http://www.telemed.uniud.it/cases/case1/</dc:identifier>
<dc:relation.hasPart rdf:resource="http://www.telemed.uniud.it/cases/case1/image1.jpg"/>
<dc:relation.hasPart rdf:resource="http://www.telemed.uniud.it/cases/case1/image2.jpg"/>
</rdf:Description>
</rdf:RDF>
主題(subject)は、MeSHの用語を用いて記述しています。別レベルの記述は、生体サンプルと顕微鏡の準備に関係しています。生体サンプルは体の器官のものです。ある特定の化学製品を使用して、薄片化および染色してあります。サンプルに関連して、患者データと画像(または、複数の画像)の内容の両方から抽出した、1つ以上の兆候に関する仮説があります。クロモグラニン染色を施したリンパ節の部位があり、カルチノイド腫瘍からの転移の兆候を示していると考えてみましょう(クロモグラニンは免疫組織化学的抗体です)。最終段階の記述は、特定の光学特性(中でも最も重要なのは客観的な倍率と開口数で、これは分解能に影響を与え、したがって、視覚的な精細度に影響します)を持つ顕微鏡およびカメラで構成される入力装置を、画素解像度と色性能で考察しています。このシナリオでは、対物10倍、開口数0.20、解像度1600x1200画素で画像を入力したかもしれません。
<rdf:Description rdf:about="http://www.telemed.uniud.it/cases/case1/image1.jpg">
<dp:image dp:staining="chromogranin" dp:magnification="10" dp:na="0.20"
dp:xsize="1600" dp:ysize="1200" dp:depth="24" dp:xres="1.2" dp:yres="1.2"/>
<dc:Description>chromogranin-stained section of lymph node</dc:Description>
<dc:subject>
<dcterms:MESH>
<rdf:value>C030075</rdf:value>
<rdfs:label>chromogranin A</rdfs:label>
</dcterms:MESH>
</dc:subject>
<dc:subject>
<dcterms:MESH>
<rdf:value>E05.200.750.551.512</rdf:value>
<rdfs:label>immunohistochemistry</rdfs:label>
</dcterms:MESH>
</dc:subject>
<dc:subject>
<dcterms:MESH>
<rdf:value>E05.595</rdf:value>
<rdfs:label>microscopy</rdfs:label>
</dcterms:MESH>
</dc:subject>
</rdf:Description>
画像全体について記述した全体的なメタデータに加え、マルチメディア関連のオントロジーを用いて、特定の画像内の範囲を指定し、表現できます。アノテーションは、描写されている解剖に関する詳細の記述、異常細胞の存在と種類、そして一般的には、上記の兆候に関する仮説を支える特徴を含む、具体的な形態学上の特徴に関する記述を提供できます。このような画像では、転移細胞を着色によって茶色で明示し、セマンティックにアノテーションを付与できます。このケースでは、MeSHの用語では十分な詳細が得られないため、別の情報源の用語を選ばなくてはならず、NCIシソーラスはその1つの候補です。
<rdf:Description id="area1"> <dp:rectangle>some rectangle definition</dp:rectangle> </rdf:Description>
<rdf:Description about="#area1">
<dc:Description>metastatic cells</dc:Description>
<dc:subject>
<dcterms:NCI>
<rdf:value>C4904</rdf:value>
<rdfs:label>Metastatic_Neoplasm_to_Lymph_Nodes</rdfs:label>
</dcterms:NCI>
</dc:subject>
<dc:subject>
<dcterms:NCI>
<rdf:value>C12917</rdf:value>
<rdfs:label>Malignant_Cell</rdfs:label>
</dcterms:NCI>
</dc:subject>
</rdf:Description>
現在のセマンティック・ウェブ技術は、画像資源を含む多種多様なウェブ資源のアノテーションをサポートできる程度に一般的なものになっています。このドキュメントは、多種多様な領域のユースケースに基づいて、画像アノテーションに対するセマンティック・ウェブの言語やツールの使用例を紹介しています。マシンがよりうまく処理できるように画像にセマンティックにアノテーションを付与するために使用できる、現在利用可能ないくつかの語彙やツールについて簡潔に概観しています。セマンティック・ウェブ技術の使用は、異なるメタデータの相互運用性が重要なアプリケーションの領域や、推理タスクを実行するために明確に定義された形式的なセマンティクスに基づくメタデータを要する領域において、大きな利点があります。
それでも、改良すべきことが多くあります。一般的に受け入れられ、広く使用されている画像アノテーションの語彙はまだありません。このような語彙があれば、アプリケーション間や、複数の領域間にわたるメタデータの共有に有益でしょう。特に、画像内の部分領域を指定する標準的な方法がまだありません。さらに、セマンティック・ウェブに基づく画像アノテーションが産業的な規模で適用されるようになる前に、ツールのサポートを劇的に向上させる必要があり、そのサポートは全体の生産・流通網において統合的なものである必要があります。最後に、画像メタデータに対する多くの既存のアプローチは、セマンティック・ウェブの技術に基づいておらず、これらのアプローチをセマンティック・ウェブと相互運用可能にするためには労力を要します。
生物医学画像ユースケースの提供に関し、Vincenzo Della Mea(ウディーネ大学)に感謝申し上げます。編集者は、Chris Catton(オックスフォード大学)、Karl Dubost(W3C)、John Smith(IBM T.J.ワトソン研究所)および、このドキュメントの以前のバージョンにおけるフィードバックに対し、次のW3Cセマンティック・ウェブ・ベスト・プラクティスおよび開発ワーキンググループとW3Cマルチメディア・セマンティクス・インキュベータ・グループのメンバーにも感謝申し上げます: Georges Anadiotis、Patrizia Asirelli、Mark van Assem、Jeremy Caroll、Stamatia Dasiopoulou、Jane Hunter、Suzanne Little、Massimo Martinelli、Libby Miller、Ovidio Salvetti、Guus Schreiber 、およびMichael Uschold。
以下のリストには、前の公開バージョン(2006年3月22日)以後にこのドキュメントに行われた変更を記述しました。旧バージョンに関するコメントへの編集者のすべての回答も記述しています。
$Id: overview.html,v 1.11 2007/08/24 11:45:10 rtroncy Exp $


{kind=link}