![]()
【注意】 このドキュメントは、W3CのWeb Annotation Data Model W3C Recommendation 23 February 2017の和訳です。
このドキュメントの正式版はW3Cのサイト上にある英語版であり、このドキュメントには翻訳に起因する誤りがありえます。誤訳、誤植などのご指摘は、訳者までお願い致します。
訳注: Annotation、Body、Target等、頭文字が大文字になっている語句(クラスを表すと思われる)が本文中に多く出現しますが、それらは大文字・小文字を区別せずに訳しました。
First Update: 2017年3月6日
公開以後に報告されたエラーや問題がないか正誤表を確認してください。
このドキュメントは、規範以外の形式でも入手できます: ePub
この仕様の英語版が唯一の規範のバージョンです。非規範の翻訳版も入手可能かもしれません。
Copyright © 2017 W3C® (MIT, ERCIM, Keio, Beihang). W3C liability, trademark and document use rules apply.
アノテーションは、一般的に、資源または資源間の関連性に関する情報を伝えるために用いられます。簡単な例には、1つのウェブ・ページや画像に関するコメントやタグ、ニュース記事に関するブログの投稿が含まれます。
ウェブ・アノテーション・データ・モデル仕様は、様々なハードウェアおよびソフトウェアのプラットフォームにまたがってアノテーションを共有、再利用できるようにするための構造化モデルと形式について記述しています。一般的なユースケースにより、シンプルかつ便利な方法でモデル化できると同時に、任意のコンテンツを特定のデータ・ポイントやタイムド・マルチメディア資源の断片にリンクさせるなどの、複雑な要件も可能となります。
この仕様では、このユースケースに対応した概念モデルに基づくアノテーションの作成と利用が容易になるように、特定のJSON形式とそれを表す用語の語彙を提供します。
この項は、このドキュメントの公開時のステータスについて記述しています。他のドキュメントがこのドキュメントに取って代わることがありえます。現行のW3Cの刊行物およびこの技術報告の最新の改訂版のリストは、http://www.w3.org/TR/のW3C技術報告インデックスにあります。
この仕様は、オープン・アノテーション・コミュニティ・グループの成果から得られたものであり、両者の違いに関する詳細は付録の謝辞に記録されています。
このドキュメントは、ウェブ・アノテーション・ワーキンググループによって勧告として発表されました。このドキュメントに関してコメントを行いたい場合には、public-annotation@w3.org(購読、アーカイブ)にお送りください。どのようなコメントでも歓迎します。
ワーキンググループの実装報告書を参照してください。
このドキュメントは、W3Cメンバー、ソフトウェア開発者、他のW3Cグループ、および他の利害関係者によりレビューされ、W3C勧告として管理者の協賛を得ました。これは確定済みドキュメントであり、参考資料として用いたり、別のドキュメントで引用したりすることができます。勧告の作成におけるW3Cの役割は、仕様に注意を引き付け、広範囲な開発を促進することです。これによってウェブの機能性および相互運用性が増強されます。
このドキュメントは、2004年2月5日のW3C特許方針の下で活動しているグループによって作成されました。W3Cは、このグループの成果物に関連するあらゆる特許の開示の公開リストを維持し、このページには特許の開示に関する指示も含まれています。不可欠な請求権(Essential Claim(s))を含んでいると思われる特許に関して実際に知っている人は、W3C特許方針の6項に従って情報を開示しなければなりません。
このドキュメントは、2015年9月1日のW3Cプロセス・ドキュメントによって管理されています。
この項は非規範的です。
アノテーションの付与という、別個の情報間を関係付ける行為は、様々な形でオンライン上において普及している活動です。ウェブの利用者は、提供元のウェブ・サイトに組み込まれているツール、外部のウェブ・サービス、またはアノテーション・クライアントの機能を用いてオンライン資源にコメントを付与します。共有されている写真や動画に関するコメント、製品レビュー、ウェブ資源に関するソーシャル・ネットワークの言及ですら、すべてアノテーションとみなすことができます。さらに、「付箋」システムやスタンドアロンのマルチメディア・アノテーション・システムが多数存在しています。この仕様では、これらのアノテーションを表現する一般的なアプローチなどを記述しています。
ウェブ・アノテーション・データ・モデルは、1つのウェブ資源にテキストの断片を貼り付けるなどの、最も一般的なユースケースにも対応できる十分な簡潔さを確保しつつ、複雑な要件を満たす豊かな表現力を持ち、プラットフォーム間で容易に共有できる、アノテーション表現に対する拡張可能かつ相互運用可能なフレームワークを提供します。
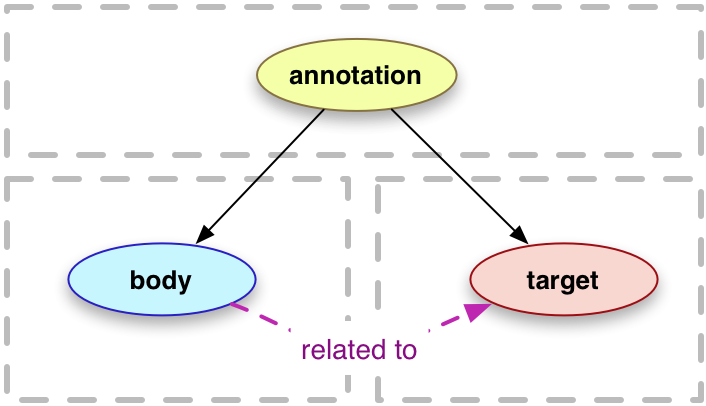
アノテーション(annotation)は、接続された資源の集合であると考えられ、一般的に本体(body)とターゲット(target)が含まれており、本体がターゲットに関係付けられている(related to)ということを伝えます。この関係の正確な性質はアノテーションの意図によって変わりますが、本体は、何らかのターゲットに「関する」ものであることが最も多いです。この観点から、下記に示す3つの部分からなる基本モデルが得られます。完全なモデルは、追加機能をサポートし、アノテーション内へのコンテンツの組み込み、資源の任意の断片の選択、資源の適切な表現の選択、クライアントがアノテーションを適切に表示できるようなヒントの提供が可能です。機械によって作成された、または、機械をターゲットとしたアノテーションも可能で、人間向きのドキュメントのウェブのみが考慮され、データのウェブが無視されないことが保証されます。
ウェブ・アノテーション・データ・モデルは、アノテーションの作成、管理、検索に対する転送プロトコルを規定していません。その代わりに、多くの様々なプロトコルで受け渡される資源指向の構造およびその構造のシリアル化について記述しています。関連する[annotation-protocol]仕様では、推奨されるトランスポート層について記述しており、それは別途採用することができます。
ウェブ・アノテーション・データ・モデルの主な目的は、アノテーションをシステム間で共有できるようにするための標準的な記述モデルと形式を提供することです。この相互運用性は、他者との共有のため、または機器やプラットフォームの間の私的なアノテーションの移行のためのどちらかでありえます。共有されたアノテーションは、既存のコレクションに統合され、重要な情報を失うことなく再利用できなければなりません。このモデルは、シンプルなアノテーションが容易である状態を保ちつつ、複雑な利用が可能となるようにそのベースラインから拡張して、できる限り多くのアノテーションのユースケースをカバーすべきです。
ウェブ・アノテーション・データ・モデルは、あらゆる利害関係者が利用できる、1つの整合性のあるモデルです。作成者と利用者の両方の実装コストを最小限に抑えるためにあらゆる努力が行われました。既存の標準に適応する必要がある場合や、1つの方法のみを採用すると重大なコストが伴う場合を除き、ユースケースを満たすには、複数の方法よりも、1つの方法の方が強く推奨されます。このデータ・モデルはリンクト・データの基礎を用いて構築されていますが、豊かで高性能な非グラフ・ベースの実装を可能とすることを目指して設計されています。そのため、このモデルの設計の最適化においては、推論やその他のグラフ・ベースのクエリは、明らかに優先事項ではありません。
ドキュメント内のすべての例は、アノテーション語彙[annotation-vocab]の付録Aで示しているコンテキストを用いて[JSON-LD]としてシリアル化されており、これは、望ましいシリアル化の形式です。この形式のメディア・タイプは、アノテーション・プロトコル[annotation-protocol]の3項でapplication/ld+json;profile="http://www.w3.org/ns/anno.jsonld"と定義されています。
アノテーションに記録される唯一の情報が資源のIRIである場合、そのIRIは、例1のように、関係の値として用いられます。資源に関してより多くの情報がある場合、IRIは、例2のように、関係の値であるオブジェクトのidプロパティーの値です。
非規範的と記している項と同じく、この仕様のすべての作成ガイドライン、図、例、注は、非規範的です。この仕様のその他の部分はすべて規範的です。
「することができる/してもよい(MAY)」、「しなければならない(MUST)」、「してはならない(MUST NOT)」、「推奨されない(NOT RECOMMENDED)」、「推奨される(RECOMMENDED)」、「すべきである/する必要がある(SHOULD)」、「すべきでない/する必要がない(SHOULD NOT)」というキーワードは、[RFC2119]で記述されているように解釈されるべきです。
ウェブ・アノテーション・データ・モデルは、次の基本原則を用いて定義されています。
下記の原則は、ターゲットと本体の正確な性質に関する区別について補足したものです。
アノテーション・ドキュメントに含まれている、本体やターゲットなどの外部資源のプロパティーは、クライアントへのヒントとして意図されているものであり、信頼できる情報とはみなされません。これには、外部資源の作成された時間、作成エージェント、修正時刻、権利表明、形式、言語、文字方向などのプロパティーも含まれます。
アノテーションはウェブ資源です。通常、アノテーションには、コメントやその他の記述資源である1つの本体と、何らかの形で本体がそれに「関する」ものである1つのターゲットが含まれています。アノテーションには、追加の記述プロパティーが含まれている可能性も高いです。
ユースケースの例: Aliceは、特定のウェブ・ページに関するコメントを投稿しました。彼女のクライアントは、その投稿を本体資源とし、そのウェブ・ページをターゲット資源としたアノテーションを作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| @context | プロパティー | アノテーションとしてのJSONの意味を決定するコンテキスト。 アノテーションは、 @contextの値を1つ以上持っていなければならず(MUST)、http://www.w3.org/ns/anno.jsonldはそのうちの1つでなければなりません(MUST)。値が1つだけの場合は、文字列で提供されなければなりません(MUST)。 |
| id | プロパティー | アノテーションのID。 アノテーションは、それを識別するIRIを1つだけ持っていなければなりません(MUST)。 |
| type | 関係 | アノテーションのタイプ。 アノテーションは、タイプを1つ以上持っていなければならず(MUST)、 Annotationクラスはそのうちの1つでなければなりません(MUST)。 |
| Annotation | クラス | ウェブ・アノテーションに対するクラス。Annotationクラスは、typeを用いてアノテーションに関連付けられなければなりません(MUST)。 |
| body | 関係 | アノテーションとその本体との関係。 アノテーションに関連付けられている body関係が1つ以上あるべきですが(SHOULD)、0であることもできます(MAY)。 |
| target | 関係 | アノテーションとそのターゲットとの関係。 アノテーションに関連付けられている target関係が1つ以上なければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno1",
"type": "Annotation",
"body": "http://example.org/post1",
"target": "http://example.com/page1"
}
ウェブ資源はIRIで識別され、様々なプロパティーを持ち、多くの場合、資源のコンテンツの形式や言語が含まれます。この情報は、資源表現をウェブから検索しなければならない場合でも、アノテーションの一部として記述できます。
ユースケースの例: Beatriceは、特許に関する長い分析を記録し、彼女のウェブ・サイトで音声をmp3で公開します。その後、彼女は、mp3を本体とし、特許のPDFをターゲットとしたアノテーションを作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 本体またはターゲットの資源を識別するIRI。 外部ウェブ資源である本体またはターゲットは、資源のIRIを値として持つ idを1つだけ持っていなければなりません(MUST)。 |
| format | プロパティー | ウェブ資源のコンテンツの形式。 本体またはターゲットは、それに関連付けられた形式を1つだけ持っているべきですが(SHOULD)、0以上持つこともできます(MAY)。プロパティーの値は、 [rfc6838]の仕様に従った形式のメディア・タイプであるべきです(SHOULD)。 |
| language | プロパティー | ウェブ資源のコンテンツの言語。 本体またはターゲットは、それに関連付けられた言語を1つだけ持っているべきですが(SHOULD)、例えば、言語が識別できなかったり、資源に言語の組み合わせが含まれていたりする場合は、0以上持つこともできます(MAY)。プロパティーの値は、[bcp47]の仕様に従った言語コードであるべきです(SHOULD)。 |
| processingLanguage | プロパティー | 改行、ハイフネーション、使用するフォントなどのテキスト処理アルゴリズムに用いる言語。 本体とターゲットはそれぞれ、 processingLanguageを1つだけ持つことができます(MAY)。プロパティーの値は、[bcp47]の仕様に従った言語コードであるべきです(SHOULD)。このプロパティーが存在せず、1つの値を持つlanguageプロパティーが存在している場合は、クライアントはその言語を要件の処理に用いるべきです(SHOULD)。 |
| textDirection | 関係 | 資源内のテキストの全体的な基本書字方向。 本体またはターゲットは、それに関連付けられたtextDirectionを1つだけ持つことができます(MAY)。プロパティーの値は、下記で定義している方向( ltr、rtl、またはauto)のうちの1つでなければなりません(MUST)。 |
| ltr | インスタンス | 資源の値を示す方向は、方向が明示的に分離されている左から右のテキストです。 |
| rtl | インスタンス | 資源の値を示す方向は、方向が明示的に分離されている右から左のテキストです。 |
| auto | インスタンス | 資源の値を示す方向は、方向が明示的に分離されているテキストであり、方向は、値を用いてプログラムが決定します。 |
formatプロパティーで使用できる公式なメディア・タイプのレジストリを示しています。[w3c-language-tags]という記事は、実装者が、languageプロパティーで遭遇すると予想される値を適切に概説しています。テキスト方向の観念とauto、ltr、rtlの値の定義は、明らかにHTML5[html5]のdir属性から取り入れたものです。外部資源から提供される情報と、それに関してアノテーションから提供される情報とが矛盾する場合は、外部資源の方が信頼でき、アノテーションの情報は無視すべきであることにも注意してください。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno2",
"type": "Annotation",
"body": {
"id": "http://example.org/analysis1.mp3",
"format": "audio/mpeg",
"language": "fr"
},
"target": {
"id": "http://example.gov/patent1.pdf",
"format": "application/pdf",
"language": ["en", "ar"],
"textDirection": "ltr",
"processingLanguage": "en"
}
}
クライアントがウェブ資源の一般的なタイプを事前に知っていると有用です。クライアントが動画を表示できない場合には、本体が動画であることが分かっていると、大きい可能性のあるコンテンツ・ストリームを不必要にダウンロードすることを回避できます。多くのデータ形式のように、明確なメディア・タイプがない資源の場合は、text/csvという形式の資源は、そのメディア・タイプの最初の部分に反して、単なるプレーン・テキストとして表示すべきではないけれども、application/pdfは、主なタイプが「application」であるにもかかわらずユーザー・エージェントが表示できる可能性があることをクライアントが知っていることも有用です。
ユースケースの例: Corinaは、あるウェブ・サイトに関するコメント動画を彼女の電話で撮影し、それをアップロードします。彼女はアノテーションで動画をウェブ・サイトに関連付け、彼女のクライアントは利用システムへのヒントとしてタイプを追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | 本体またはターゲットの資源のタイプ。 本体またはターゲットは、 typeを1つ以上持つことができ(MAY)、その場合、値は下記のクラスのリストから選ぶべきです(SHOULD)が、その他の語彙から持ってくることもできます(MAY)。 |
| Dataset | クラス | 定義されている構造内のデータをエンコードする資源のクラス。 |
| Image | クラス | 主に見ることを意図した画像資源のクラス。 |
| Video | クラス | 音声の有無にかかわらず、動画資源のクラス。 |
| Sound | クラス | 主に聞くことを意図した資源のクラス。 |
| Text | クラス | 主に読むことを意図した資源のクラス。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno3",
"type": "Annotation",
"body": {
"id": "http://example.org/video1",
"type": "Video"
},
"target": {
"id": "http://example.org/website1",
"type": "Text"
}
}
アノテーションの多くは、外部ウェブ資源の全体ではなく一部に関するものです。ウェブ[webarch]では、資源の断片は、フラグメント要素付きIRIを用いて識別され、それは、関心のある断片を資源から抽出する方法を記述すると同時に、抽出されたコンテンツを識別します。シンプルなアノテーションでは、本体またはターゲットの識別子としてこのフラグメント要素付きIRIを使用できれば有益です。
ユースケースの例: Dawnは、画像の特定領域について説明したいと考えています。彼女は彼女のクライアントでその領域をハイライト表示させ、説明を入力します。そして、彼女のクライアントは、適切なフラグメント要素付きIRIをターゲットとして作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 本体またはターゲットの資源を識別するIRI。 外部ウェブ資源である本体またはターゲットは、値が資源のIRIである idを1つだけ持っていなければならず(MUST)、そのIRIはフラグメント要素を持つことができます(MAY)。 |
type、format、languageなどの他の資源のプロパティーに加え、下記のその他のプロパティーの項で記述しているプロパティーを、資源全体に対するものと同様に、資源の断片に適用できることに注意してください。フラグメント要素付きIRIを用いたときの結果と、それを用いることで実装に課される制限について知っていることが重要です。
http://example.com/image.jpg#xywh=1,1,1,1というターゲットを持つアノテーションは、http://example.com/image.jpgを単に検索しても、後者が前者の一部であるにも関わらず、発見されないでしょう。{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno4",
"type": "Annotation",
"body": "http://example.org/description1",
"target": {
"id": "http://example.com/image1#xywh=100,100,300,300",
"type": "Image",
"format": "image/jpeg"
}
}
多くの場合、アノテーションの本体はテキスト形式であり、別のIRIのないアノテーションと同時に作成されます。この場合、複数のシステムとの相互作用を行う必要性を避けるために、本体のテキストをアノテーションの一部として含むことができます。本体は、特に、伝達されるテキストの言語や形式などの、外部ウェブ資源の特性を持つこともできます。
ユースケースの例: Emilyは、彼女が写真共有ウェブ・サイトの画像がいかに好きなのかに関するコメントを書きます。彼女のクライアントは、コメントが組み込まれたアノテーションを作成し、それが、フランス語であり、HTML形式で書かれていることを付け加えます。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | テキスト形式の本体を識別するIRI。 本体は、それを識別するIRIを1つだけ持つことができます(MAY)。 |
| type | 関係 | テキスト形式の本体資源のタイプ。 本体は、 TextualBodyクラス持っているべきであり(SHOULD)、その他のクラスを持つことができます(MAY)。 |
| TextualBody | クラス | アノテーション内のテキスト形式の資源を組み込むために本体に割り当てられるクラス。 本体は、 TextualBodyクラスを持っているべきです(SHOULD)。 |
| value | プロパティー | テキスト形式の本体のコンテンツの文字列。 TextualBodyに関連付けられた valueプロパティーが1つだけなければなりません(MUST)。 |
システムは、たとえtypeプロパティーに明示的に含まれていなくても、テキスト形式の本体には、上記のクラスで説明したTextクラスがあると想定すべきです(SHOULD)。
languageやformatなどの外部ウェブ資源のプロパティーも、組み込まれたテキスト形式の本体資源に適用されます。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno5",
"type": "Annotation",
"body": {
"type" : "TextualBody",
"value" : "<p>j'adore !</p>",
"format" : "text/html",
"language" : "fr"
},
"target": "http://example.org/photo1"
}
最もシンプルなタイプの本体は、追加の情報やプロパティーがないプレーン・テキストの文字列です。このタイプの本体は、最もシンプルなアノテーションにのみ有用であり、本体をアノテーションの外から参照する必要がある場合の使用には推奨されません(NOT RECOMMENDED)。
ユースケースの例: Franceskaは、シンプルなコマンド・ラインのクライアントから手っ取り早くアノテーションを作成したいと考えています。彼女は、テキスト・ファイルでJSONシリアル化を作成し、それを自体のアノテーション・サーバーに送信して維持します。
| 用語 | タイプ | 説明 |
|---|---|---|
| bodyValue | プロパティー | アノテーションの本体の文字列の値。 アノテーションには bodyValueが1つだけ存在でき(MAY)、その値は次の要件に従っていなければなりません(MUST)。bodyValueプロパティーが存在している場合は、body関係も存在していてはなりません(MUST NOT)。 |
この形式を使用できる場合と、それを解釈する方法には、いくつかの制限があります。
文字列の本体は、
xsd:stringでなければならず(MUST)、データ型をシリアル化で表現してはなりません(MUST NOT)。valueプロパティーの値であるかのように解釈しなければなりません(>MUST)。text/plainという値のformatプロパティーを持っているかのように解釈しなければなりません(MUST)。上記の解釈のいずれかが正しくない場合は、代わりにTextualBody構築子を用いなければなりません(MUST)。
bodyValueという形式を維持するのではなく、TextualBody構築子を用いるようにアノテーションを書き換えることができます(MAY)。アノテーションを処理しているクライアントにとって、言語と形式の情報は重要であるため、TextualBody構築子の方が望ましいです。{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno6",
"type": "Annotation",
"bodyValue": "Comment text",
"target": "http://example.org/target1"
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno7",
"type": "Annotation",
"body": {
"type": "TextualBody",
"value": "Comment text",
"format": "text/plain"
},
"target": "http://example.org/target1"
}
一部のアノテーションは、テキストが付随していないシンプルなハイライト表示やブックマークなど、全く本体がない場合があります。アノテーションは複数の本体および/またはターゲットを持つこともできます。その場合、個々の本体は、すべてのターゲットの集合にではなく、各ターゲットにそれぞれ等しく関連しているとみなされます。
ユースケースの例: Gretchenは、彼女の電子書籍の特定領域を緑色でハイライト表示し、そのハイライト表示が何を意味するのかを知っているため、彼女はコメントを行いません。彼女のクライアントはスタイルシートをアノテーションに関連付けますが、本体は全く作成しません。
ユースケースの例: Hannahは、1つのアノテーションを用いてタグと記述を、2つの画像に関連付けます。
アノテーションに本体が全くない場合は、body関係は省略されます。
アノテーションのbodyおよび/またはtarget関係は、1つのオブジェクトではなく配列でありえます。値は、資源のIRIが含まれている文字列またはオブジェクトでありえます。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno8",
"type": "Annotation",
"target": "http://example.org/ebook1"
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno9",
"type": "Annotation",
"body": [
"http://example.org/description1",
{
"type": "TextualBody",
"value": "tag1"
}
],
"target": [
"http://example.org/image1",
"http://example.org/image2"
]
}
選択には、アプリケーションが処理または表示を行うために1つだけ選択すべき資源の順序付きリストがあります。順序は、アノテーションの作成者または公開者が、最も望ましいものから、最も望ましくないものへの順で指定します。
ユースケースの例: Irinaは、特定のウェブ・サイトに関する彼女の意見をフランス語と英語の両方で書きます。2つの投稿は同等であるため、両方を表示する必要はなく、代わりに、彼女はフランス語の話者にフランス語のコメントを表示し、他の人には英語のバージョンを表示したいと考えます。彼女のクライアントは、英語のコメントを最初に掲載した選択として作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 選択を識別するIRI。 選択は、それを識別するIRIを1つだけ持つことができます(MAY)。 |
| type | 関係 | 資源のタイプ。 選択は、 typeを1つだけ持っていなければならず(MUST)、それはCHOICEクラスでなければなりません(MUST)。 |
| Choice | クラス | 列挙されている資源をすべて表示するのではなく、そのうちの1つを選択してユーザーに表示すべきである(SHOULD)と、利用アプリケーションに伝える構築子。 |
| items | 関係 | 選択すべき資源のリストで、デフォルトの選択肢が最初に掲載されます。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno10",
"type": "Annotation",
"body": {
"type": "Choice",
"items": [
{
"id": "http://example.org/note1",
"language": "en"
},
{
"id": "http://example.org/note2",
"language": "fr"
}
]
},
"target": "http://example.org/website1"
}
アノテーションや参照されている資源に責任がある人、組織または機械は、その寄与に対する称賛に値し、資源の作成時間は、順序付けの表示や、フィルタリングによる古くて無関係な可能性のあるコンテンツの除去に有用です。アノテーションの作成者は、アノテーションの信頼性を判断するためにも有用です。アノテーションの作成とシリアル化に用いたソフトウェアは、その作業がいつ実施されたかに加え、問題の通知やデバッグにも有用です。
ユースケースの例: Janeは、オンラインでレストランのレビューを書き、彼女の友人が、それが彼女のレビューであり、信頼できるということを知らせるために、そのレビューに関連付けたいと考えています。彼女のクライアントは、アノテーションに彼女のアカウントのIDとそれ自体のIDを、また、資源の作成時の適切なタイム・スタンプを追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| creator | 関係 | 資源の作成に責任があるエージェント。これは、人間、組織またはソフトウェア・エージェントのいずれかでありえます。 アノテーションと本体に creator関係が1つだけ存在しているべきですが(SHOULD)、資源の作成者関係が匿名のままとしたかったり、複数のエージェントが共同作業を行っていたりする可能性があるため、 0または2つ以上存在することもできます(MAY)。関係は、他の資源に関係付けることができます(MAY)。 |
| created | プロパティー | 資源が作成された時間。 アノテーションと本体に createdプロパティーが1つだけあるべきで(SHOULD)、2つ以上であってはなりません(MUST NOT)。プロパティーは、他の資源に関連付けることができます(MAY)。日付は、UTCタイムゾーンを「Z」で表したxsd:dateTimeでなければなりません(MUST)。 |
| generator | 関係 | アノテーションのシリアル化の生成に責任があるエージェント。 アノテーションごとに generator関係が0以上存在できます(MAY)。 |
| generated | プロパティー | アノテーションのシリアル化が生成された時間。 アノテーションごとに generatedプロパティーが1つだけ存在でき(MAY)、2つ以上であってはなりません(MUST NOT)。日付は、UTCタイムゾーンを「Z」で表したxsd:dateTimeでなければなりません(MUST)。 |
| modified | プロパティー | 作成後に資源が変更された時間。 アノテーションと本体に modifiedプロパティーが1つだけ存在することができ(MAY)、2つ以上であってはなりません(MUST NOT)。プロパティーは、他の資源に関連付けることができます(MAY)。日付は、UTCタイムゾーンを「Z」で表したxsd:dateTimeでなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno11",
"type": "Annotation",
"creator": "http://example.org/user1",
"created": "2015-01-28T12:00:00Z",
"modified": "2015-01-29T09:00:00Z",
"generator": "http://example.org/client1",
"generated": "2015-02-04T12:00:00Z",
"body": {
"id": "http://example.net/review1",
"creator": "http://example.net/user2",
"created": "2014-06-02T17:00:00Z"
},
"target": "http://example.com/restaurant1"
}
エージェントを識別するIRI以上の、アノテーションの作成に関与したエージェントに関するより多くの情報が通常必要です。これには、それらが、個人なのか、グループなのか、それとも、本名、アカウント名、電子メール・アドレスなどのソフトウェアやプロパティーの断片なのかが含まれます。
ユースケースの例: Kellyは、彼女のIDを管理していないシステムにアノテーションを送信したいと考えており、ペンネームの表示を望んでいます。彼女のクライアントは、この情報をアノテーションに追加してサービスに送信します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | エージェントを識別するIRI。 エージェントは、それを識別するIRIを1つだけ持っているべきで(SHOULD)、2つ以上持ってはなりません(MUST NOT)。 |
| type | 関係 | エージェントのタイプ。 エージェントは、下記に列挙しているものから、クラスを1つ以上持っているべきです(SHOULD)。 |
| Person | クラス | 人間であるエージェントのクラス。 |
| Organization | クラス | 個人とは対照的に、組織のクラス。 |
| Software | クラス | アノテーションを作成するユーザーのクライアントや機械学習システムなどのソフトウェア・エージェントのクラス。 |
| name | プロパティー | エージェントの名前。 個々のエージェントは、 nameプロパティーを1つだけ持っているべきで(SHOULD)、0以上持つこともできます(MAY)。 |
| nickname | プロパティー | エージェントのニックネーム。 個々のエージェントは、 nicknameプロパティーを1つだけ持っているべきで(SHOULD)、0を持つこともできます(MAY)。 |
| 関係 | mailto:のIRIスキーム[rfc6086]を用いてエージェントに関連付けられている電子メール・アドレス。 個々のエージェントは、 emailアドレスを1つ以上持つことができます(MAY)。 |
|
| email_sha1 | プロパティー | sha1アルゴリズムを、エージェントの電子メールのIRIに適用した結果のテキスト表現で、「mailto:」という接頭辞を含み、空白は含まれません。これにより、アドレスを公開せずにメール・アドレスを識別子として利用できるようになります。 個々のエージェントは、 email_sha1プロパティーに値を1つ以上持つことができます(MAY)。 |
| homepage | 関係 | エージェントのホームページ。 個々のエージェントは、ホームページを1つ以上持つことができます(MAY)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno12",
"type": "Annotation",
"creator": {
"id": "http://example.org/user1",
"type": "Person",
"name": "My Pseudonym",
"nickname": "pseudo",
"email_sha1": "58bad08927902ff9307b621c54716dcc5083e339"
},
"generator": {
"id": "http://example.org/client1",
"type": "Software",
"name": "Code v2.1",
"homepage": "http://example.org/client1/homepage1"
},
"body": "http://example.net/review1",
"target": "http://example.com/restaurant1"
}
アノテーションやその他の資源の作成と管理に関連するエージェント以外に、資源が意図する利用エージェントの対象者またはクラスを知っていることも有用です。これによって、意図する対象者の役割(先生か学生かなど)またはクラスのプロパティー(推奨年齢の範囲など)を記録することが可能になります。
ユースケースの例: Lyndaは、授業を行うために特定の教科書の使用に関する注意をいくつか書いています。彼女は、意図するアノテーションの対象者が先生(教科書を利用する人)であると付け加え、学生が対象者(同じく教科書を利用するが、学習用である)でありえる他のアノテーションと区別します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 対象者を識別するIRI。 対象者を識別するIRIが1つだけ存在できます(MAY)。 |
| type | 関係 | schema.orgクラス構造の利用者のタイプ。 対象者は、 typeを1つ以上持っているべきで(SHOULD)、それはschema.orgクラス構造から得たものであるべきです(SHOULD)。 |
| audience | 関係 | アノテーションとその意図する対象者との関係。 アノテーションごとに対象者が0以上存在できます(MAY)。 |
対象者を記述するさらなるプロパティーは、schema.orgの対象者クラスのものを用います。そのプロパティーとクラスの名前には、他のプロパティーやクラスと一意に区別できるように、schema:というJSONの接頭辞を置かなければなりません(MUST)。
audienceの使用は、アノテーションが表示されないようにするアクセス制限を暗示または有効にするものではありません。システムは、ユーザーに関する知識に基づいてアノテーションの表示をフィルタリングするために情報を用いるべきであり(SHOULD)、アノテーションやその他の資源が認証や認可を要求することを想定すべきではありません。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno13",
"type": "Annotation",
"audience": {
"id": "http://example.edu/roles/teacher",
"type": "schema:EducationalAudience",
"schema:educationalRole": "teacher"
},
"body": "http://example.net/classnotes1",
"target": "http://example.com/textbook1"
}
情報へのアクセスは国際連合によって基本的人権として認められています。ウェブは、身体的障害の種類の違いにかかわらず、通信と相互作用に対する障害を取り除くことができます。これは、社会的包摂をサポートしますが、情報の潜在的な対象者も増大させます。アノテーションの本体またはターゲットとして用いられる資源に関し、多様な範囲の能力を有するユーザーにより容易なアクセスを提供するために、その資源の特性を記録することは有益です。
ユースケースの例: Meganは、音を聞く能力が非常に限られており、動画と相互作用を行う時には字幕を読むことを好みます。彼女は、彼女のアノテーションクライアントを用いてそのような動画にコメントを付け、クライアントは、同じ状況の人の役に立つように、動画にそのアクセシビリティ機能があることを記述します。
| 用語 | タイプ | 説明 |
|---|---|---|
| accessibility | プロパティー | 値を列挙したリストに基づく1つ以上の文字列で、個々に資源が持つアクセシビリティ機能が記述されています。 本体またはターゲットの資源ごとに列挙されたアクセシビリティ機能が0以上存在できます(MAY)。 |
現在の値のリストは、schema.orgの記述のaccessibilityFeatureプロパティーで参照できます。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno14",
"type": "Annotation",
"motivation": "commenting",
"body": "http://example.net/comment1",
"target": {
"id": "http://example.com/video1",
"type": "Video",
"accessibility": "captions"
}
}
多くの場合、アノテーションに関係する時間やエージェントのみでなく、アノテーションが作成された理由やテキスト形式の本体をアノテーションに含めた理由を理解することが重要です。これらの理由は、アノテーションを作成した動機、またはテキスト形式の本体をアノテーションに含めた目的を宣言することで提供され、これは、前項で説明した「誰」 や「いつ」ではなく、「なぜ」です。
ユースケースの例: Noelleは、後で参照するためにブックマークすることを目的として資源にアノテーションを付与し、より容易に再検索できるように記述とタグを提供します。彼女のクライアントは、それを取り込むために、アノテーションとテキスト形式の本体の資源に適切な動機を付け加えます。
| 用語 | タイプ | 説明 |
|---|---|---|
| motivation | 関係 | アノテーションと動機との関係。 アノテーションごとに、 motivationが1つだけ存在しているべきで(SHOULD)、0または2つ以上存在することもできます(MAY)。 |
| purpose | 関係 | アノテーション内にテキスト形式の本体を含めた理由。TextualBodyに関連付けされたpurposeが0以上存在できます(MAY)。 |
| Motivation | クラス | アノテーションの動機は作成した理由であり、別のアノテーションに対する応答、資源に関するコメント、または関連する資源に対するリンクなどが含まれる可能性があります。 |
| 動機 | ||
| assessing | インスタンス | ユーザーが、ターゲット資源に関して単にコメントするのではなく、何らかの方法でそれを評価しようとする時の動機。例えば、本のレビューや評価を書いたり、データセットの品質を評価したり、学生の勉強を評価するなど。 |
| bookmarking | インスタンス | ユーザーが、ターゲットまたはその部分にブックマークを作成しようとする時の動機。例えば、読者が読み終えた文の位置をブックマークするなどのアノテーション。 |
| classifying | インスタンス | ユーザーが、ターゲットを何かに分類しようとする時の動機。例えば、画像を肖像として分類するなど。 |
| commenting | インスタンス | ユーザーがターゲットに関してコメントしようとする時の動機。例えば、特定のPDFドキュメントに関するコメントを提供するなど。 |
| describing | インスタンス | ユーザーが、(例えば)ターゲットに関してコメントするのではなく、ターゲットを記述しようとする時の動機。例えば、上記のPDFのコンテンツの正確さに関してコメントするのではなく、コンテンツを記述するなど。 |
| editing | インスタンス | ユーザーが、ターゲット資源に変更や編集を要求しようとする時の動機。例えば、誤植を訂正するように要求するアノテーションなど。 |
| highlighting | インスタンス | ユーザーが、ターゲット資源またはその断片をハイライト表示しようとする時の動機。例えば、アノテーターが同意していない部分のテキストに注意を引くためになど。 |
| identifying | インスタンス | ユーザーが、ターゲットにIDを割り当てようとする時の動機。例えば、都市を識別するIRIを、ウェブ・ページのその都市に関する言及に関連付けるために。 |
| linking | インスタンス | ユーザーが、ターゲットに関連する資源にリンクしようとする時の動機。 |
| moderating | インスタンス | ユーザーが、ターゲットに何からの価値または品質を割り当てようとする時の動機。例えば、信頼ネットワークまたはスレッド化した議論をモデレートするためにアノテーションにアノテーションを付与するなど。 |
| questioning | インスタンス | ユーザーが、ターゲットに関して質問をしようとする時の動機。例えば、テキストの特定部分についての支援を求める、またはその正確さについて疑問を呈するなど。 |
| replying | インスタンス | ユーザーが、前のステートメント(アノテーションか別の資源かのいずれか)に回答しようとする時の動機。例えば、上記で求められた支援を提供するなど。 |
| tagging | インスタンス | ユーザーが、ターゲットにタグを関連付けようとする時の動機。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno15",
"type": "Annotation",
"motivation": "bookmarking",
"body": [
{
"type": "TextualBody",
"value": "readme",
"purpose": "tagging"
},
{
"type": "TextualBody",
"value": "A good description of the topic that bears further investigation",
"purpose": "describing"
}
],
"target": "http://example.com/page1"
}
使用条件を記述するためにライセンスまたは権利ステートメントを資源に関連付けることは、一般的な慣習です。これにより、ユーザーが資源を適切に利用することができると同時に、一部の自動化されたシステムは利用が許可されていることを確認できます。アノテーション、本体、ターゲットは、様々なライセンスや権利で作成される可能性があるため、それぞれ別々に記述できます。アノテーション自体以外の資源の権利は、利用クライアント・アプリケーションにとって有益なヒントとみなされます。
ユースケースの例: Opheliaは、製品のレビューを書き、そのレビューの著者であることを知られたいと考えますが、レビューと製品を関連付けているアノテーションがどのように用いられるかは気にしません。彼女は、これらの2つの別個の権利ステートメントをアノテーションと本体で個々に言明します。彼女は、ターゲット資源上で表明されている権利については知らないため、何も指定しません。
| 用語 | タイプ | 説明 |
|---|---|---|
| rights | 関係 | アノテーション、本体またはターゲットと、資源を利用できる権利ステートメントまたはライセンスが含まれているウェブ資源との関係。 個々の資源からリンクされた rightsステートメントまたはライセンスが0以上存在することができ(MAY)、その値はIRIでなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno16",
"type": "Annotation",
"rights": "https://creativecommons.org/publicdomain/zero/1.0/",
"body": {
"id": "http://example.net/review1",
"rights": "http://creativecommons.org/licenses/by-nc/4.0/"
},
"target": "http://example.com/product1"
}
ウェブなどの大規模な分散型のシステムでは、情報はしばしばコピーされます。アノテーションやその他の関連する資源の来歴を追跡するために、資源を識別する追加のIRIを記録することができます。これは逆参照可能な「パーマリンク」、ウェブの知識なしにクライアントがオフラインで割り当てたID、または、単に現在の収集システムが資源を発見した場所でありえます。
ユースケースの例: Petraは、アノテーションを作成し、それを複数のシステムに送信して維持します(1つは私的、1つは公的)。彼女は、コピーを連携できるようにしたいと考え、UUIDを正規のIRIとして設定し、サービスがそれにHTTP IRIを割り当てることができるようにします。そして、後続のシステムは、公的なコピーを収集し、発見したものとして正規のUUIDを維持し、元のHTTP IRIをviaに移行させ、それをその管理下にあるIRIと置き換えます。
| 用語 | タイプ | 説明 |
|---|---|---|
| canonical | 関係 | アノテーション、本体またはターゲットと、そのIDを追跡するために用いるべき(SHOULD)IRIとの関係(それがどこでアクセスできるようになるかを問わない)。このプロパティーが設定されている場合は、システムはそれを変更または削除してはなりません(MUST NOT)。アノテーションがすでに他の場所で正規のIRIを持っている可能性があるため、システムは、正規のIRIが存在していない時に、事前の同意なく正規のIRIを割り当てるべきではありません(SHOULD NOT)。 資源ごとに canonical IRIが1つだけ存在できます(MAY)。 |
| via | 関係 | アノテーション、本体またはターゲットと、資源を利用できるようにしているシステムによって資源が取得された場所のIRIとの関係。 資源ごとに viaで提供されるIRIが0以上存在できます(MAY)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno17",
"type": "Annotation",
"canonical": "urn:uuid:dbfb1861-0ecf-41ad-be94-a584e5c4f1df",
"via": "http://other.example.org/anno1",
"body": {
"id": "http://example.net/review1",
"rights": "http://creativecommons.org/licenses/by/4.0/"
},
"target": "http://example.com/product1"
}
上記の構築子のみを用いれば、フラグメント要素付きIRIで資源の一部を参照するアノテーションを作成できますが、それでは十分でない場合も多くあります。例えば、画像のシンプルな円形領域、またはそれを横切る対角線さえも可能ではありません。HTMLページ内のテキストの任意の範囲を選択することは、恐らく最もシンプルなアノテーションの概念ですが、それもフラグメントではサポートされません。さらに、資源の特定の状態や表現を検索したり、特別な方法でスタイルを指定したり、アノテーションの使用に特化した資源に役割を関連付けたり、資源が特定のコンテキストで用いられる時にのみアノテーションを適用したりすることをクライアントに要求する、非断片的なユースケースがあります。
ウェブ・アノテーション・データ・モデルは、SpecificResourceという新しい資源のタイプを用いて、これらのアノテーション固有の要件を取り込みます。SpecificResourceは、アノテーションでの利用方法に関する追加情報を捕捉するために、必要に応じて、アノテーションと本体またはターゲットの間で用います。記述は一般的に、別個のエンティティーとしてSpecificResourceから参照され、様々な要件を取り込むために様々なタイプのものでありえます。例えば、アノテーションのターゲットが画像の円形領域である場合、SpecificResourceはその円形領域であり、それをセレクタで記述し、情報源の画像資源との関連付けも行います。
セレクタ構築子の例のように、特定資源と指定子は、独自のIRIを持つ外部ウェブ資源でありえますが(MAY)、アノテーションの処理に必要なすべての情報を検索するために不必要なネットワーク上の相互作用が必要となることを避けるために、アノテーション表現に含めることを推奨します(RECOMMENDED)。
このドキュメントで定義している追加の特異性のタイプは次のとおりです。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 特定資源のID。 特定資源は、それを識別するIRIを1つだけ持つことができます(MAY)。 |
| type | 関係 | 特定資源のクラス。 特定資源は、 SpecificResourceというクラスを持っているべきです(SHOULD)。 |
| SpecificResource | クラス | 特定資源のクラス。SpecificResourceクラスは、別の資源のより特定の領域または状態としての役割が明確となるように、特定資源に関連付けられているべきです(SHOULD)。 |
| source | 関係 | 特定資源とより特定的な表現である資源との関係。 特定資源に関連付けられた source関係が1つだけ存在していなければなりません(MUST)。情報源資源は、上記で定義しているとおり、詳細に記述できる、または単なる資源のIRIであることができます(MAY)。 |
同じ特定資源と指定子のクラスをターゲットと本体の両方に用います。この項の例では、これらのうちの1つだけを用いていますが、両方に同じモデルを適用できます。
テキスト形式の本体と同様に、外部ウェブ資源にも、アノテーション内に含めた動機を付与することができます。これは、目的は資源がアノテーションのコンテキストで用いられる方法を規定するため、セレクタが断片を記述したり状態が表現を記述したりするのと同じ方法で、特定資源パターンを用いて行われます。
ユースケースの例: Qitaraは、曖昧でありえる都市の名前を入力するだけでなく、写真に都市の識別子をタグ付けしたいと考えます。彼女のクライアントは、その都市の有名なIRIを検索して用い、その目的の割り当てを管理するために特定資源を作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| purpose | 関係 | ウェブ資源をアノテーションに含めた理由。purposeを用いてSpecificResourceに関連付けた動機が0以上存在できます(MAY)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno18",
"type": "Annotation",
"body": {
"type": "SpecificResource",
"purpose": "tagging",
"source": "http://example.org/city1"
},
"target": {
"id": "http://example.org/photo1",
"type": "Image"
}
}
多くのアノテーションは、資源のすべてではなく、一部をターゲットとして参照します。資源のその部分を(関心のある)断片と呼びます。セレクタは、情報源資源内の断片を決定する方法を記述するために用います。様々なメディア・タイプの断片を記述する方法は一様ではないため、セレクタの性質は資源のタイプに依存します。複数のセレクタを付与して同じ断片を様々な方法で記述することで、それを後で発見し、利用ユーザー・エージェントが少なくとも1つのセレクタを使用できる可能性を最大化できます。
ユースケースの例: Ramonaは、ウェブ・ページ内のテキストの選択をデータセットのスライスに関連付けたいと考えます。彼女は、クライアントで両方を選択し、本体とターゲットごとにセレクタを持つSpecificResourceでアノテーションを作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| selector | 関係 | 特定資源とセレクタとの関係。 特定資源に関連付けられた selector関係が0以上存在できます(MAY)。複数のセレクタは、同じコンテンツを選択すべきですが(SHOULD)、一部のセレクタには他と同じ正確さがないでしょう。利用ユーザー・エージェントは、記述されている断片が多様である場合は、そのうちの1つを選択しなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno19",
"type": "Annotation",
"body": {
"source": "http://example.org/page1",
"selector": "http://example.org/paraselector1"
},
"target": {
"source": "http://example.com/dataset1",
"selector": "http://example.org/dataselector1"
}
}
断片を選択するための最もよく理解されているメカニズムは、表現のメディア・タイプで定義されているIRIのフラグメント部分を用いることであるため、これをセレクタによる記述メカニズムとして可能にすると便利です。これにより、既存および将来のフラグメント仕様を整合性のある形で特定資源に利用できるようになります。どのフラグメント・タイプが用いられているかを明確にするために、セレクタは、それを定義している仕様を参照できます。
ユースケースの例: Sallyは、動画の一部を画像に関する記述として関連付けたいと考えます。彼女は動画内の時間範囲を選択し、それがターゲットを記述していることに気づきます。そして、彼女のクライアントは、FragmentSelectorを持つSpecificResourceとdescribing動機を用いてアノテーションを作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 FragmentSelectorsは、 typeを1つだけ持っていなければならず(MUST)、値はFragmentSelectorでなければなりません(MUST)。 |
| FragmentSelector | クラス | IRIのフラグメント要素を用いて断片を記述する資源。 |
| value | プロパティー | 断片を記述したIRIのフラグメント要素のコンテンツ。 FragmentSelectorは、 valueプロパティーを1つだけ持っていなければなりません(MUST)。 |
| conformsTo | 関係 | FragmentSelectorとvalueプロパティーのIRIフラグメントの構文を定義している仕様との関係。フラグメント・セレクタは、フラグメントの構文を定義している仕様に対する conformsToリンクを1つだけ持っているべきで(SHOULD)、2つ以上持つべきではありません(MUST NOT)。 |
フラグメント付きIRIを直接用いるのではなく、SpecificResourcesを記述する他の手段と互換性がある整合的なメソッドとしてFragmentSelectorを用いることを推奨します(RECOMMENDED)。利用アプリケーションは、両方を知っているべきです(SHOULD)。
以下のIRIは、フラグメントのセマンティクスを定義している仕様の一部であり、そのため、conformsTo関係で用いることができます。その他のIRIも使用できます(MAY)。
| 名称 | フラグメント仕様 | 説明 |
|---|---|---|
| HTML | http://tools.ietf.org/rfc/rfc3236 | [rfc3236] 例: namedSection |
| http://tools.ietf.org/rfc/rfc3778 | [rfc3778] 例: page=10&viewrect=50,50,640,480 |
|
| Plain Text | http://tools.ietf.org/rfc/rfc5147 | [rfc5147] 例: char=0,10 |
| XML | http://tools.ietf.org/rfc/rfc3023 | [rfc3023] 例: xpointer(/a/b/c) |
| RDF/XML | http://tools.ietf.org/rfc/rfc3870 | [rfc3870] 例: namedResource |
| CSV | http://tools.ietf.org/rfc/rfc7111 | [rfc7111] 例: row=5-7 |
| Media | http://www.w3.org/TR/media-frags/ | [media-frags] 例: xywh=50,50,640,480 |
| SVG | http://www.w3.org/TR/SVG/ | [SVG11] 例: svgView(viewBox(50,50,640,480)) |
| EPUB3 | http://www.idpf.org/epub/linking/cfi/epub-cfi.html | [cfi] 例: epubcfi(/6/4[chap01ref]!/4[body01]/10[para05]/3:10) |
source、#、valueを連結させることで再構築できます。例えば、下記の例のIRIはhttp://example.org/video1#t=30,60です。{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno20",
"type": "Annotation",
"body": {
"source": "http://example.org/video1",
"purpose": "describing",
"selector": {
"type": "FragmentSelector",
"conformsTo": "http://www.w3.org/TR/media-frags/",
"value": "t=30,60"
}
},
"target": "http://example.org/image1"
}
HTMLのドキュメント・オブジェクト・モデルの要素を選択するための最も一般的な方法の1つは、CSSセレクタ[CSS3-selectors]を用いることです。CSSセレクタによって、ウェブ・ページの要素へのパスを記述するための多種多様で十分にサポートされた方法が可能となり、したがって、ウェブ・アノテーションの基本的なユースケースの多くがカバーされます。CSSセレクタがドキュメント・オブジェクト・モデルに準拠していない表現に適用された場合の結果は定義していません。
アノテーション内の資源をスタイル指定するためにもCSSを使用できることに注意してください。このクラスは、特に、CSSセレクタのメカニズムを再利用してドキュメント・オブジェクト・モデルに準拠した資源の断片を選択するためのものです。
ユースケースの例: Teynikaは、メモを書きたいウェブ・ページの段落を選択します。彼女のクライアントは、その要素を明確に識別するCSSパスを算出し、それをアノテーションに追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 CssSelectorsは、 typeを1つだけ持っていなければならず(MUST)、その値はCssSelectorでなければなりません(MUST)。 |
| CssSelector | クラス | CSSセレクタ資源のタイプ。 CSSセレクタは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| value | プロパティー | 断片に対するCSS選択のパス。 CSSセレクタに関連付けられた valueが1つだけ存在してなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno21",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/page1.html",
"selector": {
"type": "CssSelector",
"value": "#elemid > .elemclass + p"
}
}
}
XMLやHTMLのドキュメントなどのドキュメント・オブジェクト・モデル(DOM)をサポートする資源内の要素とコンテンツを選択する別の一般的な方法は、XPath選択[DOM-Level-3-XPath]を用いることです。XPathは、構造内の選択されたコンテンツへのパスの記述に、大きな柔軟性を認めています。DOMに準拠していない表現にXPathセレクタが適用された場合の結果は定義していません。
ユースケースの例: Ulrikaは、HTMLページの表の中の範囲を選択し、内容に関してメモを書きます。この要素を明示的に参照するために、彼女のクライアントは、XPathを慎重に構築し、それをアノテーションのターゲットとして識別します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 XPathセレクタは、 typeを1つだけ持っていなければならず(MUST)、その値はXPathSelectorでなければなりません(MUST)。 |
| XPathSelector | クラス | XPathセレクタ資源のタイプ。 XPathセレクタは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| value | プロパティー | 選択された断片へのxpath。 XPathセレクタに関連付けられた valueが1つだけ存在していなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno22",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/page1.html",
"selector": {
"type": "XPathSelector",
"value": "/html/body/p[2]/table/tr[2]/td[3]/span"
}
}
}
このセレクタは、コピーすることによってある範囲のテキストを記述し、その直前(接頭辞)・直後(接尾辞)のテキストの一部を含めることで、同じ文字列の複数のコピーを区別します。
例えば、再びドキュメントが「abcdefghijklmnopqrstuvwxyz」であるとした場合、「abcd」という接頭辞、一致する「efg」、「hijk」という接尾辞により「efg」を選択できます。
ユースケースの例: Valeriaは、ウェブ・ページの誤植(「anotation」)を選択し、正しいスペル(「annotation」)に置き換えるべきであるというコメントを追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 テキスト引用セレクタは、 typeを1つだけ持っていなければならず(MUST)、その値はTextQuoteSelectorでなければなりません(MUST)。 |
| TextQuoteSelector | クラス | 引用という方法でテキストの断片(加えて、その前後の一節)を記述するセレクタのクラス。 TextQuoteSelectorは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| exact | プロパティー | 選択されているテキスト(正規化後)のコピー。 個々のTextQuoteSelectorは、 exactプロパティーを1つだけ持っていなければなりません(MUST)。 |
| prefix | プロパティー | 選択されているテキストの直前にあるテキストの断片。 個々のTextQuoteSelectorは、 prefixプロパティーを1つだけ持っているべきで(SHOULD)、2つ以上持ってはなりません(MUST NOT)。 |
| suffix | プロパティー | 選択されているテキストの直後にあるテキストの断片。 個々のTextQuoteSelectorは、 suffixプロパティーを1つだけ持っているべきで(SHOULD)、2つ以上持ってはなりません(MUST NOT)。 |
テキストの選択は、コード単位(選択されたデータ型を用いて表現される数)ではなく、Unicodeコード・ポイント(「文字番号」)でなければなりません(MUST)。選択は、書記素クラスタの真ん中で開始または終了すべきではありません(SHOULD NOT)。選択は、特に、双方向テキストでは、テキストの表示上の順序ではなく、論理的な順序に基づいていなければなりません(MUST)。ウェブで用いられるテキストの文字モデルの詳細については、[charmod]を参照してください。
テキストは、アノテーションに記録する前に正規化をしなければなりません(MUST)。したがって、HTML/XMLのタグは削除すべきで(SHOULD)、文字エンティティーは、エンコードする文字に置き換えられるべきです(SHOULD)。これが、アノテーションを付与されているドキュメントのコンテンツの状態には影響を与えず、コンテンツがアノテーション・ドキュメントに記録される方法にのみ影響を与えることに注意してください。
接頭辞(prefix)、完全(exact)、接尾辞(suffix)を処理した後に、ユーザー・エージェントが一致するテキスト・シーケンスを複数発見した場合、選択は、すべてのマッチと一致したものとして扱われるべきです(SHOULD)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno23",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/page1",
"selector": {
"type": "TextQuoteSelector",
"exact": "anotation",
"prefix": "this is an ",
"suffix": " that has some"
}
}
}
このセレクタは、連続するデータ内の選択の開始・終了位置を記録することでテキストの範囲を記述します。0という位置は最初の文字の直前であり、1という位置は2番目の文字の直前であるなどです。したがって、開始文字はリストに含まれますが、終了文字は含まれません。
例えば、ドキュメントが「abcdefghijklmnopqrstuvwxyz」であり、開始が4、終了が7であれば、選択範囲は「efg」でしょう。
ユースケースの例: Wendyは、コンテンツの抽出とコピーが許可されていない電子書籍のレビューを書きます。彼女のクライアントは、コンテンツ内の開始・終了位置を用いて選択範囲を記述します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 テキスト位置セレクタは、 typeを1つだけ持っていなければならず(MUST)、その値はTextPositionSelectorでなければなりません(MUST)。 |
| TextPositionSelector | クラス | 開始・終了位置に基づき、テキストの範囲を記述するセレクタのクラス。 TextPositionSelectorは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| start | プロパティー | テキストの断片の開始位置。フルテキストの最初の文字は文字位置が0であり、その文字は断片内に含まれています。 個々のTextPositionSelectorは、 startプロパティーを1つだけ持っていなければならず(MUST)、その値は負でない整数でなければなりません(MUST)。 |
| end | プロパティー | テキストの断片の終了位置。その文字は断片内に含まれていません。 個々のTextPositionSelectorは、 endプロパティーを1つだけ持っていなければならず(MUST)、その値は負でない整数でなければなりません(MUST)。 |
開始・終了位置を決定するためには、文字を数える前にテキスト引用セレクタと同じ方法でテキストを選択して正規化をしなければなりません(MUST)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno24",
"type": "Annotation",
"body": "http://example.org/review1",
"target": {
"source": "http://example.org/ebook1",
"selector": {
"type": "TextPositionSelector",
"start": 412,
"end": 795
}
}
}
テキスト位置セレクタと同様に、データ位置セレクタは、同じプロパティーを用いますが、テキスト・レベルの文字ではなくビット・ストリーム・レベルのバイト(byte)で機能します。
ユースケースの例: Xenaは、フォレンジック目的とエミュレーション要件記述のために、オンラインのディスク・イメージ領域に関してコメントを書きます。彼女のクライアントは、彼女が用いている人間が読みやすい表示ではなく、バイナリ・ストリーム内の開始・終了位置を生成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 データ位置セレクタは、 typeを1つだけ持っていなければならず(MUST)、その値は、DataPositionSelectorでなければなりません(MUST)。 |
| DataPositionSelector | クラス | バイト・ストリーム内のその開始・終了位置に基づき、データの範囲を記述するセレクタのクラス。 DataPositionSelectorは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| start | プロパティー | データの断片の開始位置。最初のバイトは、文字位置が0です。 個々のDataPositionSelectorは、 startプロパティーを1つだけ持っていなければなりません(MUST)。 |
| end | プロパティー | データの断片の終了位置。最後の文字は断片内に含まれません。 個々のDataPositionSelectorは、 endプロパティーを1つだけ持っていなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno25",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/diskimg1",
"selector": {
"type": "DataPositionSelector",
"start": 4096,
"end": 4104
}
}
}
SvgSelectorは、SVG(Scalable Vector Graphics)[SVG11]標準を用いて領域を定義します。これにより、ユーザーは、SVGで領域を記述することにより、円や多角形などの、矩形ではないコンテンツ領域を選択できるようになります。SVGは、アノテーション内に組み込むか、外部ウェブ資源として参照することができます。
資源の領域を選択するためにSvgSelectorがSVGを用いることに注意してください。SVG表現の断片は、セレクタを用いて選択することもでき、それにはFragmentSelectorやSvgSelectorが含まれます。
ユースケースの例: Yadiraは、歴史的な道路の対角線領域をオンラインで古い地図にタグ付けしています。彼女のクライアントは、SVGポリゴンを作成し、画像コンテンツと相対的に領域を記述します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 SVGセレクタは、 typeを1つだけ持っていなければならず(MUST)、その値にはSvgSelectorが含まれていなければなりません(MUST)。 |
| SvgSelector | クラス | SVG標準を用いて選択された領域の形を定義するセレクタのクラス。 セレクタは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| value | プロパティー | SVGコンテンツの文字列。 セレクタに関連付けられた valueプロパティーが1つだけ存在でき(MAY)、その場合、そのプロパティーの値は、整形式のSVG XMLでなければなりません(MUST)。 |
SVGの形またはキャンバスの大きさは、その形のサイズを画像のフル・サイズに拡大・縮小し、希望する領域が正しく表現されるようにして、情報源資源の大きさと相対的でなければなりません(MUST)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno26",
"type": "Annotation",
"body": "http://example.org/road1",
"target": {
"source": "http://example.org/map1",
"selector": {
"id": "http://example.org/svg1",
"type": "SvgSelector"
}
}
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno27",
"type": "Annotation",
"body": "http://example.org/road1",
"target": {
"source": "http://example.org/map1",
"selector": {
"type": "SvgSelector",
"value": "<svg:svg> ... </svg:svg>"
}
}
}
ユーザーが行う選択は、広範囲である可能性および/または表現の内部境界を越える可能性があるため、正しいコンテンツを確実に記述する1つのセレクタを構築することは困難です。範囲セレクタを用いれば、他のセレクタを用いて、選択の最初と最後を識別することができます。この方法では、最も適切な選択メカニズムで2つの位置を正確に識別し、その後でリンクさせて選択範囲を形成することができます。選択は、開始セレクタの最初から終了セレクタの最初(しかし、これは含まない)までのすべてで構成されます。
ユースケースの例: Zaraは、ウェブ・ページの一部である表内の隣接する2つのセルに関してコメントしたいと考えます。彼女は2つのセルを選択し、彼女のクライアントは最初のセルと、2番目の直後のセルにXPathを構築します。そして、彼女のクライアントは、最初のXPathセレクタを開始として、2番目のXPathセレクタを終了として用いて範囲セレクタを作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | セレクタのクラス。 範囲セレクタは、 typeを1つだけ持っていなければならず(MUST)、その値はRangeSelectorでなければなりません(MUST)。 |
| RangeSelector | クラス | 範囲セレクタ資源のタイプ。 範囲セレクタは、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| startSelector | 関係 | 範囲の包括的な開始位置を記述するセレクタ。 範囲セレクタに関連付けられた startSelectorが1つだけ存在していなければなりません(MUST)。 |
| endSelector | 関係 | 範囲の排他的な終了位置を記述するセレクタ。 範囲セレクタに関連付けられた endSelectorが1つだけ存在していなければなりません(MUST)。startSelectorとendSelectorは両方とも同じクラスに属しているべきです(SHOULD)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno28",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/page1.html",
"selector": {
"type": "RangeSelector",
"startSelector": {
"type": "XPathSelector",
"value": "//table[1]/tr[1]/td[2]"
},
"endSelector": {
"type": "XPathSelector",
"value": "//table[1]/tr[1]/td[4]"
}
}
}
}
完全な資源の選択ではなく、選択の選択として資源の関心のある断片を指定する方が、より簡単で、より信頼でき、より正確でありえます。特に、様々なパッケージ化形式などの、他の資源が含まれている資源では、要素に一意の識別子がない場合に、これによって選択メカニズムを分解することもできます。これは、セレクタを連鎖的につなげ、それぞれが前のセレクタの結果を精緻化することで実現できます。
ユースケースの例: Alexandraは、テキストの段落を選択した後にその中の短いフレーズを選択し、コメントを付与します。彼女のクライアントは、そのフレーズが含まれている段落を識別するために用いるFragmentSelectorをさらに変更するTextQuoteSelectorとしてフレーズを記録します。
| 用語 | タイプ | 説明 |
|---|---|---|
| refinedBy | 関係 | 最初の結果に適用すべき(SHOULD)より広いセレクタとより特定的なセレクタとの関係。 セレクタは、1つ以上の他のセレクタにより refinedBy(精緻化)できます(MAY)。2つ以上ある場合、それらは同じ選択を生む選択肢であるとみなされます。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno29",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/page1",
"selector": {
"type": "FragmentSelector",
"value": "para5",
"refinedBy": {
"type": "TextQuoteSelector",
"exact": "Selected Text",
"prefix": "text before the ",
"suffix": " and text after it"
}
}
}
}
状態は、特定のアノテーションに適用される資源の意図する状態を記述し、したがって、その資源の正しい表現を得るために必要な情報を提供します。ウェブ資源は、時間の経過とともに変化しますが、状態は、意図されている以前のバージョンに戻す方法を記述するために使用できます。また、ウェブ資源には複数の形式があり、状態を等しく用いて特定の形式を検索する方法を記述することもできます。利用ユーザー・エージェントが表現を検索できる可能性を最大にするために、複数の状態を付与して、同じ表現を記述することができます。
ユースケースの例: Britneyは、頻繁に更新されるウェブ・ページに関してコメントします。彼女のクライアントは、他のクライアントがアノテーションの元のターゲットをうまく再構築できるようにするための情報を記録します。
| 用語 | タイプ | 説明 |
|---|---|---|
| state | 関係 | SpecificResourceと状態との関係。 SpecificResourceごとに0以上の stateの関係が存在できます(MAY)。複数の状態は、同じ表現を記述すべきですが(SHOULD)、他と同じ精度を持たない状態もあるでしょう。利用ユーザー・エージェントは、記述されている表現が多様である場合は、そのうちの1つを選択しなければなりません(MUST)。 |
状態は、セレクタやスタイル情報を処理する前に処理しなければなりません(MUST)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno30",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/page1",
"state": {
"id": "http://example.org/state1"
}
}
}
時間状態資源は、資源がアノテーションに適している時間を記録するもので、一般的には、アノテーションが作成された時間および/または現在のバージョンの永続的なコピーへのリンクです。資源のタイム・スタンプは、RFC7089[rfc7089]で記述されているとおり、メメント(Memento)プロトコルで解決できます。
ユースケースの例: Carlaは、ニュース・ウェブサイトのトップ・ページの現在の状態についてメモを作成し、そのページは頻繁に変更される可能性が高いとフラグを立てます。彼女のクライアントは、アノテーションを付与したページのバージョンを記述するために現在の時間を状態に追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | 状態のクラス。 時間状態は、 typeを1つだけ持っていなければならず(MUST)、その値はTimeStateでなければなりません(MUST)。 |
| TimeState | クラス | アノテーションに時間的に適している情報源資源の表現を検索する方法の記述。 状態は、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| sourceDate | プロパティー | 情報源資源がアノテーションに対して解釈されるべき(SHOULD)タイム・スタンプ。 TimeStateごとに sourceDateプロパティーが0以上存在できます(MAY)。2つ以上ある場合は、それぞれは情報源を解釈できる代替のタイム・スタンプを示します。タイム・スタンプは、xsd:dateTime形式で表現しなければならず(MUST)、「Z」で表したUTCタイムゾーンを用いなければなりません(MUST)。sourceDateが提供されている場合は、sourceDateStartとsourceDateEndは提供されてはなりません(MUST NOT)。 |
| sourceDateStart | プロパティー | 情報源資源がアノテーションに対して解釈されるべき(SHOULD)インタバルが始まるタイム・スタンプ。 TimeStateごとに sourceDateStartプロパティーが1つだけ存在できます(MAY)。タイム・スタンプは、xsd:dateTime形式で表現しなければならず(MUST)、「Z」で表したUTCタイムゾーンを用いなければなりません(MUST)。sourceDateStartが提供されている場合は、sourceDateEndも提供されていなければなりません(MUST)。 |
| sourceDateEnd | プロパティー | 情報源資源がアノテーションに対して解釈されるべき(SHOULD)インタバルが終わるタイム・スタンプ。 TimeStateごとに sourceDateEndプロパティーが1つだけ存在できます(MAY)。タイム・スタンプは、xsd:dateTime形式で表現しなければならず(MUST)、「Z」で表したUTCタイムゾーンを用いなければなりません(MUST)。sourceDateEndが提供されている場合は、sourceDateStartも提供されていなければなりません(MUST)。 |
| cached | 関係 | アノテーションに適している、情報源資源の表現のコピーへのリンク。 TimeStateごとに0以上の cached関係が存在できます(MAY)。2つ以上ある場合は、それぞれは表現の代替のコピーを示します。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno31",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/page1",
"state": {
"type": "TimeState",
"cached": "http://archive.example.org/copy1",
"sourceDate": "2015-07-20T13:30:00Z"
}
}
}
1つのIRIで資源から配信できる表現は潜在的に多く存在しており、特定資源はそのうちの1つにしか適用できないため、正しい表現を検索するために送信する必要があるHTTPリクエスト・ヘッダーを記録できることが重要です。HttpRequestState資源は、表現を取得した時に再生すべきヘッダーのコピーを保持します。
ユースケースの例: Devinaは、HTML、PDFまたはプレーン・テキストを配信できるウェブ資源のPDF表現を検索した後に、それに関して説明を書きます。彼女は、彼女の説明がPDF表現に関するもののみであることを示唆します。そして、彼女のクライアントは、そのターゲット表現を検索する方法を記述するために、状態を含めます。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | 状態のクラス。 リクエスト・ヘッダー状態は、 typeを1つだけなければならず(MUST)、その値はHttpRequestStateでなければなりません(MUST)。 |
| HttpRequestState | クラス | リクエストを転送するHTTPリクエスト・ヘッダーに基づく、アノテーションに対する情報源資源の適切な表現を検索する方法の説明。 状態は、それに関連付けられたこのクラスを持っていなければなりません(MUST)。 |
| value | プロパティー | 1つの、完全な文字列として送信するHTTPリクエスト・ヘッダー。 HttpRequestStateは、 valueプロパティーを1つだけ持っていなければなりません(MUST)。 |
Content-Locationヘッダーを返す場合、クライアントは、リクエストされたIRIではなく、それをアノテーションのtargetとして用いる可能性があります。{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno32",
"type": "Annotation",
"body": "http://example.org/description1",
"target": {
"source": "http://example.org/resource1",
"state": {
"type": "HttpRequestState",
"value": "Accept: application/pdf"
}
}
}
選択の精緻化と同様に、資源の適切な状態をアトミックな状態資源の階層として指定する方が、より簡単で、より信頼でき、より正確でありえます。これは、内部変換を反映した状態と外部リクエストを記述した状態の結果との組み合わせを表すのに特に適しています。この分解は、セレクタと同じ方法で状態を連鎖的につなげることで実現できます。
さらに、状態によって特定の表現が生じる可能性が高いことを考えると、その表現の断片を記述するのに適した特定のセレクタが存在する可能性があります。これに対応するために、状態をセレクタで精緻化することもできます。
ユースケースの例: Erinは、時間の経過とともに多くのバージョンがあり、様々な形式で利用できる旅行の電子書籍に関してコメントを書きます。彼女は、特定のバージョンと形式に関して特にコメントしているため、彼女のクライアントは、時間を捕捉するTimeStateと形式を捕捉するHttpRequestStateの両方を追加した後に、その形式に適した特定のFragmentSelectorを追加します。
| 用語 | タイプ | 説明 |
|---|---|---|
| refinedBy | 関係 | 最初の結果に適用すべき(SHOULD)より広い状態とより特定的な状態またはセレクタとの関係。 個々の状態は、1つ以上の他の状態またはセレクタにより refinedBy(精緻化)できます(MAY)。2つ以上ある場合、それらは同じ結果を生む選択肢であるとみなされます。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno33",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/ebook1",
"state": {
"type": "TimeState",
"sourceDate": "2016-02-01T12:05:23Z",
"refinedBy": {
"type": "HttpRequestState",
"value": "Accept: application/pdf",
"refinedBy": {
"type": "FragmentSelector",
"value": "page=10",
"conformsTo": "http://tools.ietf.org/rfc/rfc3778"
}
}
}
}
}
特定のアノテーションまたはアノテーションの本体の解釈は、実装全体で統一されているアノテーションの表示スタイルに依存する可能性があります。画像や動画などのバイナリ・コンテンツのアノテーションでは、アノテーション・クライアントはターゲットの背景色にアクセスできない可能性があり、夜空の画像のターゲット領域として黒い長方形が表示されているなど、デフォルトの色は認識しにくいかもしれません。表示情報は、CSSスタイルシートとそのスタイルシートで定義されているクラスへの参照を用いて記録されます。
ユースケースの例: Felicityは、ドキュメント内の2つの段落をハイライト表示し、一方は赤色、もう一方は黄色でハイライト表示するようにクライアントで選択します。そして、黄色い部分と赤い部分は矛盾しているとコメントします。彼女のクライアントは、彼女がターゲットの赤色と黄色の彩色を選択したことを記録します。
| 用語 | タイプ | 説明 |
|---|---|---|
| type | 関係 | スタイルのクラス CSSスタイルシートは、 typeを持つことができ(MAY)、それが含まれている場合は、その値はCssStylesheetでなければなりません(MUST)。 |
| CssStylesheet | クラス | CSSを用いてアノテーションに関与している資源のスタイルを記述する資源。 クラスは、スタイルシート資源と関連付けることができます(MAY)。 |
| stylesheet | 関係 | アノテーションとスタイルとの関係。 アノテーションごとに stylesheet関係が0または1つ存在できます(MAY)。 |
| styleClass | プロパティー | 特定資源に適用されるべき(SHOULD)CSS記述で用いるクラス名。 特定資源には styleClassプロパティーが0以上存在できます(MAY)。 |
CSSスタイルシートは、アノテーション自体に関連付けられ、そのコンテンツはアノテーションの構成資源に関する表示のヒントを提供します。これは、その情報を提供する独自の逆参照可能なIRIを持つか、アノテーション内に組み込むことができます(MAY)。これは、異なる資源ごとに1行のスタイルシートが関連付けられることを避け、特定の実装の全てのスタイルを統括した1つのIRIへの参照を可能とするためです。
公開用システムは、これが処理されることを想定してはなりません(MUST NOT)。それは要件ではなく、ヒントとして提供されているだけです。
特定資源を表示する際に、利用アプリケーションは、それにstyleClassプロパティーがあるかどうかを確認すべきです(SHOULD)。それがあった場合、アプリケーションは、CSSドキュメント内の適切なセレクタを探してみて、その後にcss-値ブロックを適用すべきです(SHOULD)。特定資源がstyleClassの値を持っていても、そのようなクラスが、アノテーションに付けられたstylesheetで記述されていない場合は、styleClassを無視しなければなりません(MUST)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno34",
"type": "Annotation",
"stylesheet": "http://example.org/style1",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/document1",
"styleClass": "red"
}
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno35",
"type": "Annotation",
"stylesheet": {
"type": "CssStylesheet",
"value": ".red { color: red }"
},
"body": "http://example.org/body1",
"target": {
"source": "http://example.org/target1",
"styleClass": "red"
}
}
アノテーションが作成された時にターゲット資源を処理および/または表示するために用いられたソフトウェアを知っていることは有益でありえます。この情報は、将来のシステムが環境を潜在的に再現するために用いることができ、アノテーションがターゲットの表現の適切な部分により簡単かつ正確に再接続できるようにします。このライフサイクル情報は、同じターゲットのアノテーションの間で変わる可能性が非常に高く、ターゲット資源に直接関連付けることができないため、特定資源に関連付けます。
ユースケースの例: Gabrielleは、ブラウザ・ベースのクライアントを用いて学術論文のPDFを表示します。彼女のブラウザは、PDFをHTMLで表示するために、特定のライブラリを用います。彼女は、利用しているビューで段落にアノテーションを付与し、HTMLのレンダリングと彼女のクライアントは、アノテーションでの表示に用いたライブラリを、彼女のコメントやターゲットのPDFとともに記録します。
| 用語 | タイプ | 説明 |
|---|---|---|
| renderedVia | 関係 | アノテーションのターゲットを表している特定資源と、アノテーションが作成された時にターゲットを表示するために用いられたソフトウェアや他のシステムとの関係。 特定資源ごとに renderedVia関係が0以上存在できます(MAY)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno36",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.edu/article.pdf",
"selector": "http://example.org/selectors/html-selector1",
"renderedVia": {
"id": "http://example.com/pdf-to-html-library",
"type": "Software",
"schema:softwareVersion": "2.5"
}
}
}
アノテーターがその時に表示または利用していた資源という点で、アノテーションが作成されたコンテキストを捕捉することが重要であることがたまにあります。これは、アノテーションがそのページのコンテキストにおいて画像にのみ有効であるという言明を暗示するものではなく、単にそのページが閲覧されたということを記録するものです。
ユースケースの例: Heatherは、特定のウェブ・ページの画像に関して、組織の正しいロゴではないというコメントを行います。彼女のクライアントは、画像が表示されているページを含めますが、アノテーションは画像資源自体に関連付けられます。
| 用語 | タイプ | 説明 |
|---|---|---|
| scope | 関係 | 特定資源と、このアノテーションにおいてその資源の範囲またはコンテキストを提供する資源との関係。 特定資源ごとに scope関係が0以上存在できます(MAY)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno37",
"type": "Annotation",
"body": "http://example.org/note1",
"target": {
"source": "http://example.org/image1",
"scope": "http://example.org/page1"
}
}
アノテーションをリストとして集約できることが有用であることが多く、それをアノテーション・コレクションと呼びます。このリストは、常に順序付けされており、その中に含まれているアノテーションを参照し、コレクション自体に関する情報を維持する手段として機能します。
コレクションのモデルは、リストのIDおよびその記述を管理するアノテーション・コレクションと、コレクションのメンバーであるアノテーションを列挙したアノテーション・ページの2つの部分に分かれます。
ユースケースの例: Ingeborgは、出版社に勤務しており、スチームパンク小説の著者のコメントを販売用のアノテーションに変換しました。その会社は、すでに小説を購入している顧客のためのアドオンとして、また、新たなまとめ売りでも利用できるようにしたいと考えています。
アノテーション・コレクションは非常に大きなものになる可能性があるため、モデルでは、コレクション自体と、アノテーションを順番に列挙する要素ページのシーケンスとを区別します。 コレクションは自体に関する情報を維持し、それには、コレクションの発見と理解に役立つ作成情報や記述情報、そして少なくともアノテーションの最初のページへの参照が含まれます。最初のページの最初のアノテーションから始め、最後のページの最後のアノテーションまでページを移動すれば、コレクションのすべてのアノテーションが発見されるでしょう。
アノテーションは、複数のコレクション内に同時に存在でき(MAY)、コレクションは、含まれているアノテーションを作成または維持するエージェント以外のエージェントにより作成または維持できます(MAY)。
| 用語 | タイプ | 説明 |
|---|---|---|
| @context | プロパティー | アノテーション・コレクションとしてJSONの意味を決定するコンテキスト。 コレクションは、 @contextという値を1つ以上持っていなければならず(MUST)、http://www.w3.org/ns/anno.jsonldがそのうちの1つでなければなりません(MUST)。 |
| id | プロパティー | コレクションのID。 コレクションは、それを識別するIRIを1つだけ持っていなければなりません(MUST)。 |
| type | プロパティー | コレクションのタイプ。 コレクションは、タイプを1つ以上持っていなければならず(MUST)、 AnnotationCollectionがそのうちの1つでなければなりません(MUST)。 |
| AnnotationCollection | クラス | アノテーションの順序付きコレクションのクラス。 このクラスは、 typeを用いてコレクションに関連付けられていなければなりません(MUST)。 |
| label | プロパティー | コレクションの名前として意図されている人間が読めるラベル。 コレクションは、 labelを1つ以上持っているべきで(SHOULD)、その値は文字列でなければなりません(MUST)。 |
| total | プロパティー | コレクションのアノテーションの合計数。 コレクションは、 totalを1つだけ持っているべきで(SHOULD)、存在している場合は、それはxsd:nonNegativeIntegerでなければなりません(MUST)。 |
| first | 関係 | コレクション内に含まれているアノテーションの最初のページ。 アノテーションの合計数が1つ以上であるコレクションは、アノテーションの firstページを1つだけ持っていなければなりません(MUST)。最初のページは、コレクションの表現の中に組み込むことができるか(MAY)、IRIとして付与できます(MAY)。 |
| last | 関係 | コレクション内に含まれているアノテーションの最後のページ。 アノテーションの合計数が1つ以上であるコレクションは、アノテーションの lastページのIRIへの参照を持っているべきです(SHOULD)。 |
利用方法、知的所有権、来歴、および有用であると考えられるその他の特性を記述するために、その他のプロパティーをコレクションに追加できます(MAY)。これらのプロパティーは、可能であれば、この仕様で記述しているものであるべきですが(SHOULD)、適切な語彙であればどのようなものでも利用できます(MAY)。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/collection1",
"type": "AnnotationCollection",
"label": "Steampunk Annotations",
"creator": "http://example.com/publisher",
"total": 42023,
"first": "http://example.org/page1",
"last": "http://example.org/page42"
}
アノテーション・ページはアノテーション・コレクションの一部であり、コレクション内にあるアノテーションの一部またはすべての順序付きリストを持っています。個々のコレクションはページを複数持つことができ、これらは、ページ間のnextとprevのリンクをたどって移動できます。
| 用語 | タイプ | 説明 |
|---|---|---|
| @context | プロパティー | アノテーション・コレクション・ページとしてJSONの意味を決定するコンテキスト。 ページがコレクション内に組み込まれていない場合、それは、 @contextという値を1つ以上持っていなければならず(MUST)、http://www.w3.org/ns/anno.jsonldがそのうちの1つでなければなりません(MUST)。組み込まれている場合は、@contextプロパティーを持っているべきではありません(SHOULD NOT)。 |
| id | プロパティー | ページのID。 ページは、そのIDを提供するIRIを1つだけ持っていなければなりません(MUST)。 |
| type | プロパティー | ページのタイプ。 ページは、タイプを1つ以上持っていなければならず(MUST)、 AnnotationPageというクラスがそのうちの1つでなければなりません(MUST)。 |
| AnnotationPage | クラス | アノテーション・ページのクラス。 このクラスは、 typeを用いてページに関連付けられていなければなりません(MUST)。 |
| partOf | 関係 | ページとその部分であるアノテーション・コレクションとの関係。 個々のページは、 partOf関係を1つだけ持っているべきで(SHOULD)、その値は、コレクションのIRI、またはコレクションのプロパティーの一部またはすべてを持つオブジェクトのいずれかです(少なくともそのidを含む)。 |
| items | 関係 | ページのメンバーであるアノテーションのリスト。 個々のページは、アノテーションの配列を itemsの値として1つ以上持っていなければなりません(MUST)。 |
| next | 関係 | コレクションを構成する一連のページの次のページへの参照。 現在のページがコレクションの最後のページでない場合は、それに続くページのIRIへの参照がなければなりません(MUST)。 |
| prev | 関係 | コレクションを構成する一連のページの前のページへの参照。 現在のページがコレクションの最初のページでない場合は、それが続いているページのIRIへの参照があるべきです(SHOULD)。 |
| startIndex | プロパティー | アノテーション・コレクションを基準にした、itemsリストの最初のアノテーションの相対的な位置。最初のページの最初のエントリーは、エントリー0であるとみなされます。個々のページは、 startIndexを1つだけ持っているべきで(SHOULD)、2つ以上持っていてはなりません(MUST NOT)。その値はxsd:nonNegativeIntegerでなければなりません(MUST)。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/page1",
"type": "AnnotationPage",
"partOf": {
"id": "http://example.org/collection1",
"label": "Steampunk Annotations",
"total": 42023
},
"next": "http://example.org/page2",
"startIndex": 0,
"items": [
{
"id": "http://example.org/anno1",
"type": "Annotation",
"body": "http://example.net/comment1",
"target": "http://example.com/book/chapter1"
},
{
"id": "http://example.org/anno2",
"type": "Annotation",
"body": "http://example.net/comment2",
"target": "http://example.com/book/chapter2"
}
]
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/collection1",
"type": "AnnotationCollection",
"label": "Two Annotations",
"total": 2,
"first": {
"id": "http://example.org/page1",
"type": "AnnotationPage",
"startIndex": 0,
"items": [
{
"id": "http://example.org/anno1",
"type": "Annotation",
"body": "http://example.net/comment1",
"target": "http://example.com/book/chapter1"
},
{
"id": "http://example.org/anno2",
"type": "Annotation",
"body": "http://example.net/comment2",
"target": "http://example.com/book/chapter2"
}
]
}
}
次の表は、主なメディア・タイプとセレクタ・タイプとの関係を示しています。このドキュメントの1.3 適合性の項と関連があります。
| フラグメント | CSS | XPath | テキスト引用 | テキスト位置 | データ位置 | Svg | |
|---|---|---|---|---|---|---|---|
| HTML (text/html) | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✘ | ✘ |
| CSV (text/csv) | ✔︎ | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| プレーン・テキスト (text/plain) | ✔︎ | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| その他のテキスト・ファイル (text/*) | ? | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| EPUB2、EPUB3 (application/epub+zip) | ✔︎ | ✘ | ✘ | ✔︎ | ✘ | ✘ | ✘ |
| PDF (application/pdf) | ✔︎ | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| XML (application/xml, application/*+xml) | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✘ | ✘ |
| SVG (image/svg+xml) | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✘ | ✔︎ |
| SVG以外の画像 (image/gif, image/jpeg, image/png, image/tiff) | ✔︎ | ✘ | ✘ | ✘ | ✘ | ? | ✔︎ |
| 動画 (video/*) | ✔︎ | ✘ | ✘ | ✘ | ✘ | ? | ✔︎ |
| バイナリ・データ・ファイル | ? | ✘ | ✘ | ✘ | ✘ | ✔︎ | ✘ |
この項は非規範的です。
次の表には、メディア・タイプとセレクタ・タイプとの、その他の可能な組み合わせがいくつか含まれており、それを実装することはできますが(MAY)、この仕様では必須ではありません。これらの組み合わせの一部は、新しい実装固有のセレクタ拡張を定義するための基礎となりえます。
| フラグメント | CSS | XPath | テキスト引用 | テキスト位置 | データ位置 | Svg | |
|---|---|---|---|---|---|---|---|
| CSS (text/css) | ✘ | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| TSV (text/tab-separated-values) | ✔︎✝ | ✘ | ✘ | ✔︎ | ✔︎ | ✘ | ✘ |
| RDF/Turtle (text/turtle) | ✔︎✝ | ✘ | ✘ | ? | ? | ✘ | ✘ |
| JSON (application/json, application/*+json) | ✘ | ✘ | ✘ | ✔︎ | ? | ✘ | ✘ |
| プログラミング言語 (application/javascript, python files, etc.) | ✘ | ✘ | ✘ | ✔︎ | ? | ✘ | ✘ |
| ✝既存のフラグメントや慣習には有名な接続子がありますが、フラグメントはIETFで正式に定義されていません。 | |||||||
この項は非規範的です。
全体的に不自然なユースケースの例: Julietは、彼女がアノテーション内に英語で書いたコメントや、他の誰かによるドイツ語の同じ内容の外部mp3とタグを、それが特定の時点であったため、また、それが特別な方法で表示されるように、ドキュメントのXML表現の特定要素の文字の範囲に関連付けたいと考えます。
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno38",
"type": "Annotation",
"motivation": "commenting",
"creator": {
"id": "http://example.org/user1",
"type": "Person",
"name": "A. Person",
"nickname": "user1"
},
"created": "2015-10-13T13:00:00Z",
"generator": {
"id": "http://example.org/client1",
"type": "Software",
"name": "Code v2.1",
"homepage": "http://example.org/homepage1"
},
"generated": "2015-10-14T15:13:28Z",
"stylesheet": {
"id": "http://example.org/stylesheet1",
"type": "CssStylesheet"
},
"body": [
{
"type": "TextualBody",
"purpose": "tagging",
"value": "love"
},
{
"type": "Choice",
"items": [
{
"type": "TextualBody",
"purpose": "describing",
"value": "I really love this particular bit of text in this XML. No really.",
"format": "text/plain",
"language": "en",
"creator": "http://example.org/user1"
},
{
"type": "SpecificResource",
"purpose": "describing",
"source": {
"id": "http://example.org/comment1",
"type": "Audio",
"format": "audio/mpeg",
"language": "de",
"creator": {
"id": "http://example.org/user2",
"type": "Person"
}
}
}
]
}
],
"target": {
"type": "SpecificResource",
"styleClass": "mystyle",
"source": "http://example.com/document1",
"state": [
{
"type": "HttpRequestState",
"value": "Accept: application/xml",
"refinedBy": {
"type": "TimeState",
"sourceDate": "2015-09-25T12:00:00Z"
}
}
],
"selector": {
"type": "FragmentSelector",
"value": "xpointer(/doc/body/section[2]/para[1])",
"refinedBy": {
"type": "TextPositionSelector",
"start": 6,
"end": 27
}
}
}
}
この項は非規範的です。
この項は非規範的です。
複数のターゲットにアノテーションを付与することはできますが、そのアノテーションの意味は、個々の本体が個々のターゲットに独立して適用されるというものになります。これは、アノテーションを正しく理解するためにすべてのターゲットが必要となるなど、アノテーターの意図するところではないかもしれません。アノテーターがこれらの要件を捕捉できるようになるためには、複合(Composite)(順序付けなし)やリスト(List)(順序付けあり)など、選択と似た資源を利用できます。
このパターンを技術的に実装することは、選択と実用的に同じであるため、困難ではありませんが、クライアントがその区別を認識できるように人間のユーザーの相互作用を管理できるユーザ・インターフェースの実装は非常に難しいことが判明しています。そのため、この付録では、将来の検討のためにパターンをメモしています。
ユースケースの例: Karinは、一連のウェブ・ページは、まとめて、彼女の研究上の仮説に対する証拠を示しているとコメントします。彼女のクライアントは、一連のウェブ・ページに固有の順序がないため、複合を作成します。
ユースケースの例: Lanaは、本の中のページのリストを重要であるとタグ付けします。本の中のページには順序があるため、彼女のクライアントは、その順序を維持するためにリストを作成します。
ユースケースの例: Melanieは、一連の画像をポートレートとして分類するためにアノテーションを付与します。分類は個々の画像に独立して適用されるため、彼女のクライアントは、それらをグループ化するために、独立(Independents)資源を作成します。
| 用語 | タイプ | 説明 |
|---|---|---|
| id | プロパティー | 集合を識別するIRI。 集合資源は、それを識別するIRIを1つだけ持つことができます(MAY)。 |
| type | 関係 | 資源のタイプ。 集合は、下記の選択肢に含まれている typeクラスを1つだけ持っていなければなりません(MUST)。 |
| Composite | クラス | 資源の集合。すべての資源は、アノテーションを正しく解釈するために必要です。 |
| List | クラス | 資源の順序付きリスト。すべての資源は、アノテーションを正しく解釈するために順番付きで必要です。 |
| Independents | クラス | 資源の集合。各資源は、アノテーションに直接関連付けられている複数の本体またはターゲットを持っているのと同じ解釈で別々にアノテーションが付与されています。 |
| items | 関係 | Composite、List、またはIndependentsの資源のリスト。 |
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno39",
"type": "Annotation",
"motivation": "commenting",
"body": {
"type": "TextualBody",
"value": "These pages together provide evidence of the conspiracy"
},
"target": {
"type": "Composite",
"items": [
"http://example.com/page1",
"http://example.org/page6",
"http://example.net/page4"
]
}
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno40",
"type": "Annotation",
"motivation": "tagging",
"body": {
"type": "TextualBody",
"value": "important"
},
"target": {
"type": "List",
"items": [
"http://example.com/book/page1",
"http://example.com/book/page2",
"http://example.com/book/page3",
"http://example.com/book/page4"
]
}
}
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno41",
"type": "Annotation",
"motivation": "classifying",
"body": "http://example.org/vocab/art/portrait",
"target": {
"type": "Independents",
"items": [
"http://example.com/image1",
"http://example.net/image2",
"http://example.com/image4",
"http://example.org/image9"
]
}
}
この項は非規範的です。
ウェブ・アノテーション・ワーキンググループは、オープン・アノテーション・コミュニティ・グループの貢献に謝意を表します。コミュニティ・グループの成果が現在のデータ・モデルの基礎となりました。特に、編集者は、コミュニティ・グループの過程全体にわたる編集上の貢献に対し、ロスアラモス国立研究所のHerbert Van de Sompelに謝意を表します。
この仕様の作成において、次の方々に、アイデア、フィードバック、レビュー、コンテンツ、批評およびインプットの提供でご協力いただきました。
この項は非規範的です。
この仕様を勧告案に進めるためには、下記の各機能の少なくとも2つの独立した実装がなければなりません。各機能は、異なる製品に実装でき、1つの製品がすべての機能を実装するという要件はありません。
機能終了基準を評価する目的で、下記を機能とみまします。
特定の機能の有無によってその動作を変更しないソフトウェアは、勧告候補段階を終了する目的でその機能を実装しているとはみなされません。
この項は非規範的です。
重要な変更はない。
2016年3月31日の草案公開からのこの仕様の重要な技術的変更は、下記のとおりです。
textプロパティーの代わりにvalueを再利用textプロパティーの削除から起因して、bodyTextからbodyValueに名前を変更Contentの削除から起因して、SvgSelectorとCssStylesheetを単純化textDirectionとprocesingLanguageのプロパティーを追加foaf:nickに対するaccountの代わりに曖昧さが少ないnicknameを使用bodyValueの解釈の役割要件を削除オープン・アノテーション・コミュニティ・グループの草案からのこの仕様の重要な技術的変更は、下記のとおりです。