今回はZip形式の書き出しプログラムの変更について書いてみよう。第67話で書いたZip形式の書き出しプログラムはバラックの域を出ないものだった。今回は大きなファイルでもきちんと書き込めるようにすることと、複数のパスで指定されたファイルを一つの圧縮ファイルにまとめることができるようにしよう。
第67話で圧縮について書いた頃は、圧縮関数がうまく動いているかどうかを知りたかったし、とりあえず動いていたのでファイルサイズが大きい場合の事は考えなかった。ZIPの仕様上は非圧縮ブロックでは32K以下の制限があるが、それ以外ではブロックサイズに制限がない事になっている。大きなファイルを圧縮する場合、データの読み込みを一度に済ませておいて圧縮するという手もあるのだが、配列データが重くなりそうなので、32K毎にブロック処理することにした。もちろんブロックサイズは32K以下でもOKなので不都合が見つかれば再検討することにしよう。
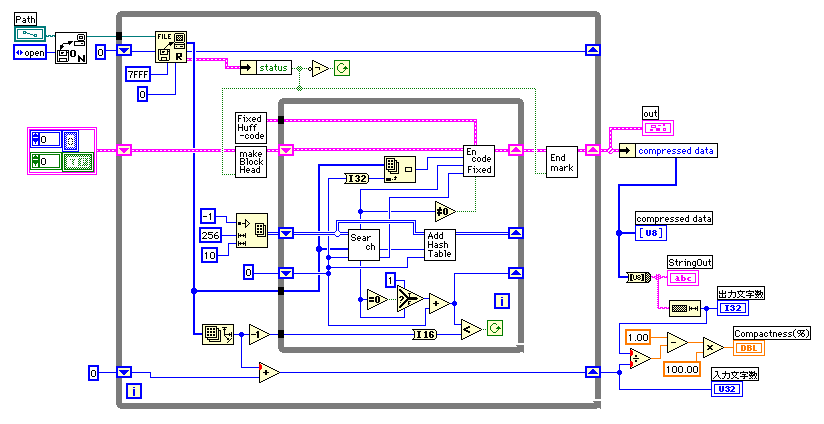
下のダイアグラムはLZ77圧縮のVIだ。圧縮するファイルのパスが指定されると、ファイルを開きfile refnumをホワイルループの中のread fileに伝える。ホワイルループでは7FFFH(32767)個毎に8ビットデータをファイルから読み出してブロック処理を行っている。ファイルが全て読み込まれるとread fileのエラー出力クラスターのstatusがTrue(エラーあり)になるのでこれを合図に最後のループを実行してホワイルループを終了する。エラーでホワイルループを終了させるのは少し気持ちが悪いので後でread fileのエラー時の動作を確認しよう。
LZ77圧縮は内側のホワイルループで実行され、ブロックヘッダーとエンドマークがその前後で追加される。最終ブロックではブロックヘッダーとエンドマークが特別の処理を行うのでエラー出力クラスターのstatusが接続されている。圧縮方式は単純な固定ハフマン方式だけを使うことにした。
read file関数は、ファイルサイズより大きなデータを読み込む設定(カウント数)にしておいても、ファイルの最後まで読んでエラーを表示してくれるので、けっこう気軽に使うことができる。
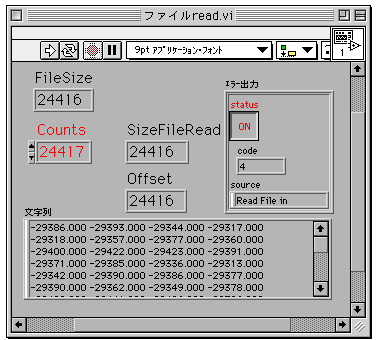
とはいえ、実際にread file関数のエラー出力時の様子を確認してみないと心配なのでVIを作ってみた。下のダイアグラムは21416バイトのファイル読み込むときに、1バイトデータ(U8)を24417個読み取る、という設定で実行した場合の動作を示している。
実際に読み取られたデータ数は21416個でオフセットも21416になっている。エラー出力はステータスが、Trueでエラーがあることを示している。実際のプログラミングではデバッグの時などに疑わなくて済むので、読み取り個数を計算して丁寧にインプットをしておいたほうが良いだろう。
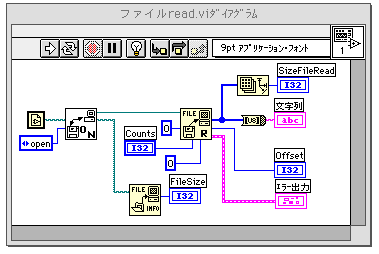

VIの中をのぞいてもらえば分かるが、CRC32の部分は直していないのでファイルヘッダーにはいいかげんな値が入っている。厳密なZipリーダーはエラーを出力すると思うので、そのうち変更しないといけない。ダイナミックハフマン方式も、圧縮率向上のためにそろそろ考えてみる時期かもしれない。
LVZIP.llbは2メガを越えるサイズになってしまったが、圧縮と伸長を別々のサブVIとして取り出して各自の計測VI、解析VIに組み込めば、それなりに収まってくれるのではないだろうか?