前回はNIのサンプルを改造してファイルアクセスをするVIを作成した。今回はそのVIを活用してZIPファイルを伸長するところまで行ってみよう。
伸長プログラムは第62話で作ったLVZIP_R.llbのインターフェースを改造して使うつもりだ。但し、LVZIP_R.llbの中心的VIであるdecompress.viは62話で書いたように「ローカルヘッダーに書かれているファイルサイズ分だけ一気に読取を行い、ブロックヘッダーをもとに圧縮方式を選んで伸長を行っている」ため、大きなファイルを扱うのはつらいプログラムだった。また、ファイルへの書き出し機能を作らなかったので本当に正しく伸長しているのかチェックしづらいため、プログラムとして不安な面があった。不安な部分は大体においてバグが残っているもので、今回はこのバグ取りも同時に進めよう。
下のダイアグラムはファイル選択のためのVIの一部分だ。ファイルリストで選択されている項目がシフトレジスターの整数の配列(青い太線)に保管されているので、ファイルリストのファイル名の文字配列(ピンクの太線)からファイル名を調べてプログラムに渡している。実は、つい先ほどまでは、整数配列を渡すだけのつもりだったが、ファイルリストに表示されている順番は必ずしもzipファイルに保存されている順番と異なっている事に気がついたので急きょ変更したのでした。
Etractボタンが押されたときに、ファイルリストでファイルが選択されていることと、パス名に.zipが含まれていることを条件にしている。

伸長プログラムの大きな流れに変更は無い。ZIPファイルの最後尾についているヘッダーを読み取り、各ファイルのヘッダーが圧縮されている場所を調べ、圧縮形式に応じて伸長を行う。
伸長したファイルを格納するディレクトリとして、zipファイルのあったディレクトリに.zipを取り去った名前で新しいディレクトリを作成し、そのパスを伸長プログラムに渡している。
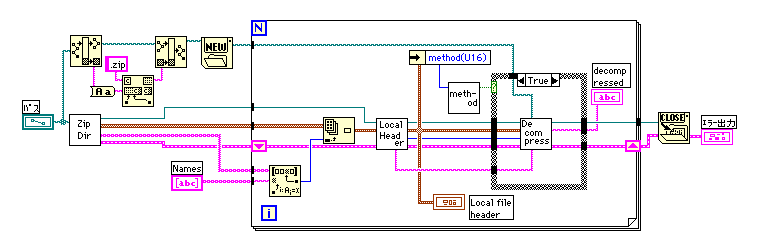
大きな変更が必要だったのは、伸長プログラムだ。ブロックごとにループ処理をし、最終ブロックを検出するとループを終了するのは以前と変わりないが、zipファイルからのデータの読み出しと、伸長結果の書き出しをブロックごとに行うことにした。これは、大きなファイルでも過大なメモリがいらないようにするために必要な変更だ。
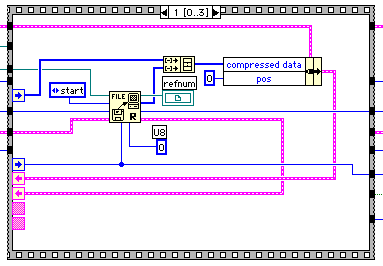
zipファイルのブロックサイズは32kBに限定されているので、各ブロックの伸長開始時に7FFFH個のデータが読み込まれていれば十分だと考え8000Hを上限に読み込むことにした。読み込みデータ(compress data)と処理位置(pos)がクラスターで伝達されるので、処理済みのデータは捨ててしまおう。もちろん、1個目のブロックを処理するときには、pos=0でデータも要素数が0になっているので0個捨てることになる。もともとデータ数が8000H以下の時もあるので、その場合は全て読み込んでしまうことになる。フレーム0ではこのようにしてzipファイルから読み込んでくるバイト数を決定している。ヘッダーに書かれている読み込むべきバイト数から、今回読み込むバイト数を引き算して、残っているバイト数をシフトレジスターに保管しておこう。

フレーム1はフレーム0で計算したバイト数だけ読み込みを行って、compress dataにマージし、pos=0にセットしておく。
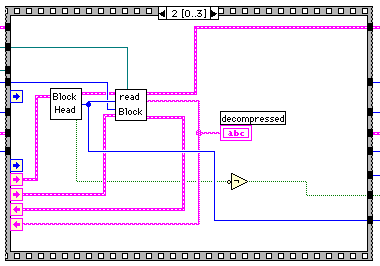
フレーム2は実際の伸長ルーチンになっている。最終ブロックの場合はここで、ループの条件をFalseにし、最後のフレームまで実行後ループから抜けることになる。
フレーム3は伸長したデータをファイルに記録する。
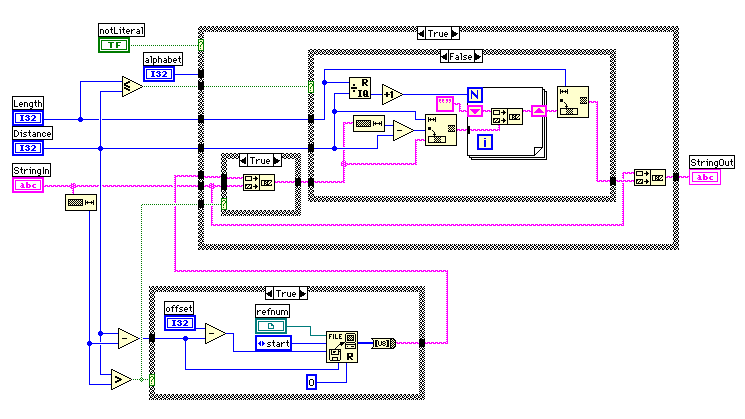
ここで悩んだのは重複文字列の参照はブロックをまたがって行われる点だ。結局、フレーム2でのread Blockでは必要なときに記録したファイルを読み込むことにした。以前は、過去のブロックを参照することを考慮していなかったので復数ブロックになる大きな圧縮ファイルでは途中からでたらめになっていたのだった。半年ぶりぐらいに仕様を読み返してしまった。

さて、今回のプログラムは実用的な速度を持っているだろうか?
答えはNoで、圧縮前で150kBのテキストファイルの伸長にたぼこ一服の時間以上かかっている。まあ、こんなものかなとも思うが、ビット操作のgetBits.viが繰り返し使われているため、手を入れてみてもいいだろう。