ZIPのファイルヘッダーについては第57話や第62話で触れたが、第62話に載せたLVZIP_R.llbのフロントパネルの絵のLocal File Headderのクラスターの7番目にCRC(U32)という項目がある。LVZIP_R.llbでは読み飛ばしていたのだが、他の伸長プログラムで読めるようにするには正しく書き込まないといけないのだろう。
このCRCがチェックサムと呼ばれるもので、伸長した後でチェックしてヘッダーに書かれている値と同じになれば正しく伸長できたと判断する。もともとはデータを単純に合計して下位の数バイトの値を確認用に使っていたのでチェックサムという名前になったのだが、いまでは合計値以外の方法で作成した数値でも広義にチェックサムと呼ばれるようだ。CRCはCyclic Redundancy Checkの略で日本語では巡回冗長度チェックと訳されているが、手元にある本では詳細が書かれていない。
お世話になっているInfo-ZIP(http://www.cdrom.com/pub/infozip/)にはソースコードが公開されているので,CRCを作成するコードを読んでみたのだが、意味がまったく分からなかった。短いコードなのだけれど、何をしようとしているのだろう。
すでにVIが作られているかどうかInfo-lv archiveに登録されているVIを
http://vaneg1.ecs.umass.edu/Socratis/LabVIEW/Index.htm
で調べてみたら16ビット版のCRCプログラムがccitt_crc.llbという名前で登録されていた。(これをダウンロードした後で32ビット版も登録されていることに気がついたのだが、最近ftpサーバーがダウンしているようなので残念ながら確認できない。)ccitt_crc.llbのダイアグラムを見ても、CのソースコードからLabVIEWに翻訳しているだけのようなので、あいかわらず何をしているのかよく分からない。
参考文献としてcrc_v3.txtがあるということなので、以下のサイトから取り出してみた。
ftp://ftp.rocksoft.com/clients/rocksoft/papers/crc_v3.txt
これは詳しく書かれていて得をした気分になった。タイトルには"A PAINLESS GUIDE TO CRC ERROR DETECTION ALGORITHMS"と書いてあるが、どうなのだろうか? 少なくとも私の場合は数週間、苦痛を覚えた。
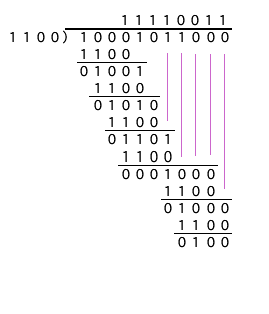
CRCでは桁上がりが無い特殊な演算を定義している。例えばオリジナルデータ10001011を、適当に考えた1100のような数で割ってその余りをチェックサムにする。被除数の最下位ビットへの演算が可能になるように0を追加して桁数を上げておいて、普通の十進の割り算のように計算を進める。このとき、引き算は桁上がりが無いためXOR演算と同じになる。
CRCの話の中ではこの除数として使う数値をポリノミアル(Polynomial-多項式)と呼んでいる。係数をMod 2に限定した多項式では桁上がりが無くなり、さきほど書いた特殊な演算が成り立つ。たとえば、1100はX^3+X^2となり、10001011はX^7+X^3+X+1と考えることができる。
懐かしい雰囲気で手計算した結果は4ビットの数値"0100"であった。"10001011"を"1000"と"1011"の2個の4ビットと考えて、単なる4ビットのチェックサムでそれらを加算して得られた数値"0011"と比べて特徴があるわけではないが、先頭ビットによってスキップする場合も含めると計算量が8倍多くかかっている。
除数の選び方でノイズへの検出力が変化するため32ビット用の除数として"04C11DB7"が使われている。この値を使って、また手計算をやってみよう。大きなデータではスペース上大変なので、"T"という1文字で計算を行ってみよう。被除数"T"は54Hなので、01010100だが、32個の0が後ろに追加されている。除数は"04C11DB7"を使うのだが、33ビット目に1が追加されていることに注意しよう。

長くなっているので大変だが、計算方法は前回の例と同じだ。CRCとなる剰余は、6B93DDDBになった。このような計算を行うVIを作ってみよう。
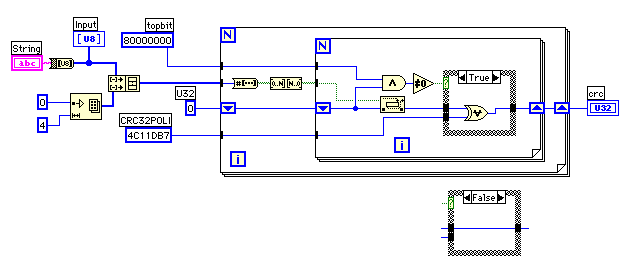
XOR演算を行うタイミングは、Rotate Left With Carryで次のビットを詰め込む前に、先頭ビットが1になっているときに行う。33ビットの演算を32ビットで行うための工夫と言えるかもしれない。ループごとに再計算されたCRCはシフトレジスタに蓄えられている。
このアルゴリズムは分かりやすいが、ビットごとにループを回さなくてははらないので動作速度の観点からは使い物にならない。この点を改良しているのが事前に計算されたテーブルを参照するアルゴリズムで、実用的なソフトに組み込まれている。
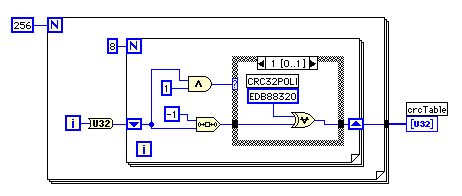
手計算の手順を、先頭の8ビットの役割に注目して、もう一度見直してみると、なぜ事前にテーブルを計算しておくことができるのかなんとなく分かってくる。先頭の8ビットはXOR演算を行うタイミング決めているだけで、CRCのレジスターは8回の操作が終わったときに下位側に移動してしまっているのだ。XOR演算は交換則も結合法則もなりたつので、手計算で"T"あるいは54Hについて行ったように256個ある全ての8ビットの数値に対してあらかじめ計算したテーブルを用意しておいて、CRCのレジスターの下位の24ビットとのXOR演算を後で行っても同じ結果を得ることができる。
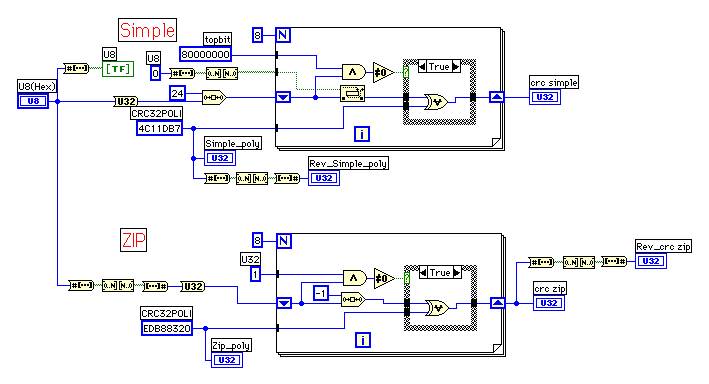
テーブルを作成するVIは、先ほどのVIの内側のループをそのまま使うことができる。このような方法を"Simple"と呼ぶことにしよう。"Simple"では4バイトの0をデータの最後に追加しなければならないため、一括で処理する場合は問題が少ないが、逐次処理を実行するときには全てのデータを処理し終わった後で4バイトの0を追加して最終的なCRCを求めなければならない。
ZIPプログラムでは、これを避けるため、32ビットを逆のビット順で並んでいるように処理していく工夫がなされている。これら2つの方式を比較するために次のVIを作ってみた。
"ZIP"での違いを書き出してみよう。(1)U8(Hex)から来るデータのビット順を反転させている。(2)ポリノミアルもビット順が反転されている。(3)ケース構造の判定をしているビット位置が0ビット目に変更されている。(4)CRCもビット順が反転している。
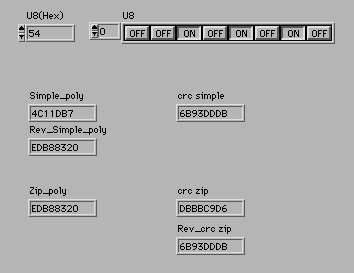
次のフロントパネルは54Hで計算した例だ。"ZIP"のポリノミアルは"Simple"のポリノミアルのビット順を反転したものと同じであることや、"ZIP"のCRCのビット順を反転すると"Simple"と同じになることが確認できる。
さて、ここまで書いてきたように紆余曲折のある難解なアルゴリズムだが、プログラム自体は簡単だ。ZlibにあるCのソースコードの一部を参照のために引用させてもらった。
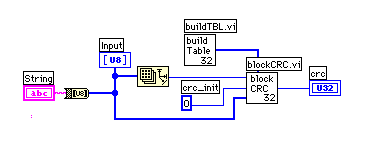
BuildTBL.viはさっき紹介したものと内容的には同じものだ。
テーブルを参照しながら実際の処理を進めるのが、blockCRC.viだ。インプットデータとその時点のCRC値のXORでテーブルを参照し、CRC値を8ビット右シフトしたものとテーブルからの読み値をXORしている。VIの始めと終わりでFFFFFFFFとXORしているのは、データの出だしが0というのは良くあることなので、その場合でもCRC値に反映させるために行っている。FFFFFFFFでスタートするデータには対処できないが、そのようなケースは0に比べれば少ないという判断だろう。
crc = crc_table[((int)crc ^ (*buf++)) & 0xff] ^ (crc >> 8);
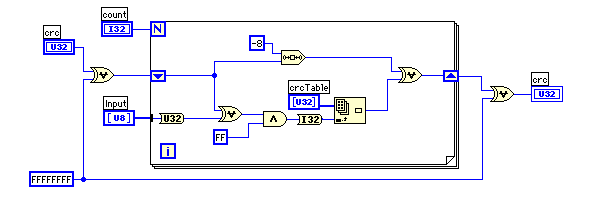
ZIPファイルのヘッダーに書かれている結果と同じ結果が得られるようになったので、このVIはきちんと動作しているようだ。
いずれにしても、興味を持った人にはcrc_v3.txtを一読してもらいたい。