気分を変えてデータ圧縮について考えてみよう。info-lvでの話題を調べてみると、最近は、静止画や動画の圧縮について困っている人が多いようで、LabVIEWの使われ方が広がってきていることを感じる。次のような収集データ量に関する一般的な議論もあった。
*********ポールからの相談**********
読者の皆さん、
60-75チャンネルを最高1kHz (通常100 Hz)で2週間分、一度にサンプリングできるデータ収集システムを作っているところです。DAQの部分よりも、記録と解析の部分が問題だと思っています。75チャンネルを100Hzで2週間取り込むと単精度浮動小数点では35.9GBになってしまう。
*********ポールへのコメント**********
ポール、
まず、単精度フォーマットでなく16ビットバイナリで保存するようにすれば半分のスペースに収めることができる。
次のステップは圧縮アルゴリズムを検討することだ。データに規則性があるのならば、かなり圧縮できる。(ところで、LabVIEWで使えるpkzip圧縮形式の(ActiveXとかその他の)良いプラグイン知らない?)もしも、圧縮を使うのなら16ビットバイナリに変えるのはあまり意味がない、同じ情報なら同レベルのサイズまで圧縮できるはずだから。
別の考え方でも圧縮することができる。例えば、最小値、最大値と周波数スペクトルを1分毎に記録しておいて、あるパラメータが通常値を越えたときに生データを記録するようにもできる。
最後に言いたいことは、データの必要性についても十分考えたほうが良いということだ。維持管理が大変なほどの膨大なデータだよ。適切な測定や検討をするために36GBのデータが必要な物理的なシステムは考えづらい。たとえ、コストがかからずに簡単に沢山の生データを保存しておけたとしても、たぶん害にはならないだろうけど、データを管理するのが高価で、非生産的だと気がつくと思うよ。
**********************************
回答した人はやさしい人だね。
さて、先が見えないのはいつものことながら、FaxやJPEGやzipにも使われているハフマン(Huffman)圧縮から調べ始めてみよう。ハフマン圧縮は出現頻度の高いデータに少ないビット数のコードを割り付け、出現頻度の低いものには多くのビット数からなるコードを割り付けることによって圧縮する方法だ。他にも同様なアルゴリズムが考えられているが、その中で最も効率のよいアルゴリズムであることが証明されている。
参考書は、「データ圧縮ハンドブック」(プレンティスホール/トッパン)ISBN4-8101-8605-9で、C言語でアルゴリズムを説明してくれている。CからLabVIEWへの翻訳も興味があるし、ツリー構造の作り方も興味がある。
次にハフマン圧縮の手順をまとめてみよう。
(1)対象となるファイルを0-255の記号の並びと考えて出現頻度を求める。出現頻度をその記号に対する重みとみなす。
(2)最も重みの低いものを右側のノードに、次に低いものを左側のノードに割り付ける。これらのノードの重みを加えて中間ノードの重みとする。
(3)残っている記号と(2)で作られた中間ノードを対象として残っている記号が一つになるまで(2)のノード割り付けを続ける。
(4)最後まで残っていた記号を左に、最後にできた中間ノードを右に割り付けてツリーが完成した。
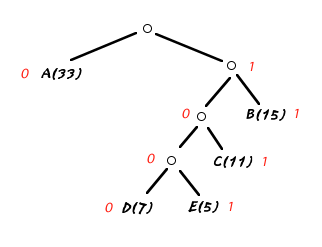
たとえば、A(33), B(15), C(11), D(7), E(5)という重みの時は、下のようなツリーになる。
それぞれの記号はツリーにしたがってたどっていくと次のようなコードで表現されることが分かる。
A;0、B;11、C;101、D;1000、E;1001、
頻度の高いAは1ビットで、頻度の少ないEは4ビットで表現されている。例えば、0100010100はADCAAを圧縮したもので、10ビットで5文字(40ビット)をあらわしている。
ハフマンツリーの特徴をまとめると、
(1)コードの長さが違うのに区切り記号がなくても、これ以外の読み方は無い。
(2)出現頻度(Wi)を考慮した平均検索経路長(L=ΣWi×Li)がほぼ一定。
ということがあげられる。これらの特徴を生かして高い圧縮効率を実現している。
次回から、データ圧縮ハンドブックのCプログラムを参考にワイヤリングしていこう。