
東北大の大学院のMさんから測定データをガウス関数で表現したいとのメールをいただきました。LabVIEWにはいろんな種類の回帰用VIが用意されていますが、自分の回帰したい関数がないときにはどうすれば良いのでしょうか?
自分の対象に合わせて自分で作ってしまうのが一番です。LabVIEWはそれだけの自由度と実行速度を持っています。データの取り込みはLabVIEWで行って、後処理はエクセルで済ませるパターンを私の周りで良く見かけますが、繰り返し行うような測定はできるかぎりLabVIEWに持ってきたほうが時間と信頼性の観点で有利です。他の人に測定を頼んでも、きちんとしたデータを手に入れることができるのも大きなメリットです。LabVIEWを手に馴染んだツールに変えていきましょう。
さて、Mさんにお願いしてサンプルのデータをいただきました。測定対象などの詳細はお聞きしませんでしたが、ソニー・テクトロニクスのリアルタイム・スペクトラム・アナライザ3026型を使って100回アベレージングを施した後に出力されたデータだそうです。サンプルデータはLogスケールでデータ収集したものなので、線形データに変換するには以下の関係で逆変換します。
X(dBm)=20*log(P/P0) [ P:入力された強度 P0:1(mW) ]
データはx座標、y座標の2列のアスキーファイルでいただきましたので、readData.viの中でRead From Spreadsheet File.viを使って2次元配列で読み込みます。y座標はフォーミュラノードを使って線形データに変換しました。
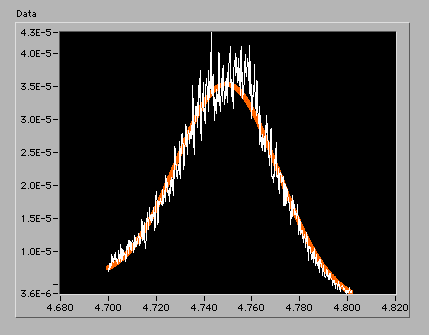
線形データに変換したグラフは次のようなものです。

たしかに、釣鐘状ですが右に傾いているような気もします。ゆっくり低下してくる成分の上に着目している現象が重なっているような場合はよくあるのですが、このデータも横軸を広い範囲で測定すればそういう状況なのかもしれません。そこで、回帰関数はガウス関数と1次関数の和とすることに勝手に決めてしまいました。
y=a * exp ( - b * (x - c) ^2) + d * x + e (1)
あとで考えると
y=a * exp ( - {(x - c) / b }^2) + d * x + e (2)
の方が良かったかもしれませんが、たいした違いではありませんので(1)のままにしました。
ところで、私は統計のプロではありませんから、「データと回帰関数の差の自乗和が最小になれば良いんだよね」と回帰に関する認識はアバウトです。最小といってもきりがないので、経済的などこかで打ち切ることにします。aからeまでの5個の係数を決めていく手順は思案のしどころです。全てを最適状態に持っていかないといけないのですが、後で考えましょう。
どんな方法で5個の係数を決めるにしても、スタートがゴールに近ければより早くゴールに到達することができます。5個の初期値をできるかぎり精度良く決める方法を考えてみましょう。これは関数の性質をうまく使えるかどうかにかかってきます。ガウス関数はピークが一つあり、左右対称な関数で、ピークから離れるほど0に近づいていきます。
[ a ] は関数の高さを表すので、Max - Min、[ c ] はピークのx座標でいいでしょう。[ b ] は高さが1/eになる関数の幅に関係しています。b * (x - c) ^2 = 1のときピークの1/eになるので、xは[ c ] から1/√b離れたところになります。傾いているときは左右で幅が変わってきますから、平均値を使います。[ d ]、[ e ] は傾きとシフト分なので、[ c ] から左右に1/√b離れたx座標の値からそれぞれ高さの1/eだけ下の2点を結んだ直線から求めます。けっして正しい値ではないのですが、これをスタートポイントとすることにしましょう。
さて、データを眺めてみるとずいぶんノイズが入り込んでいますので、スムージングしないとスタートポイントの計算が大変です。移動平均をかけようかなとも思いましたが、General Polynomial Fit.viを使うことにしました。ガウス回帰をするために、備え付けの回帰プログラムを使う。なかなかよい発想だと思いませんか?
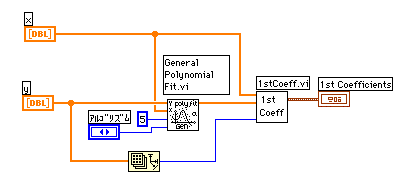
回帰パラメータは5次の近似でアルゴリズムはGivensにしました。アルゴリズムの違いは良くわかりませんが、グラフに表示してチェックしました。白が生データで、タンジェリン色が5次近似の関数です。
1stCoeff.viは5個の初期値を求めるviです。かなり手間がかかっていますが、ゴールに近いスタートポイントが得られます。

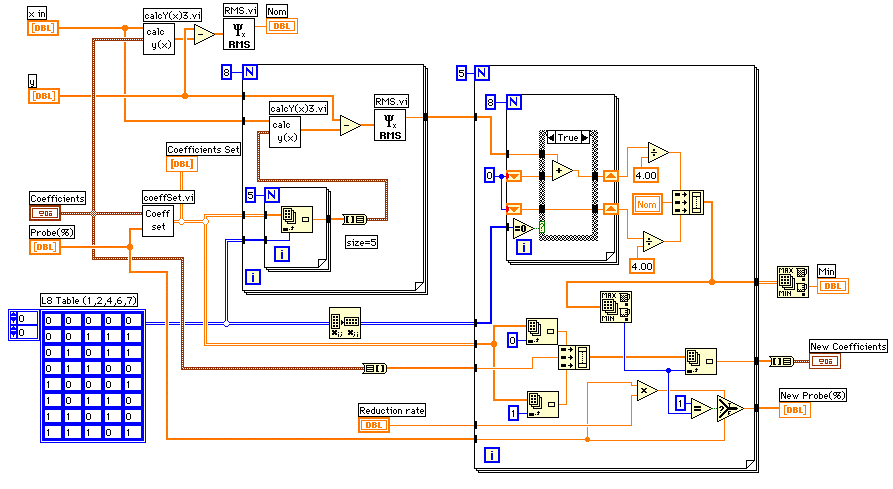
データと回帰関数の差の自乗和が最小になるように5個の係数を最適化しましょう。影響の大きいものから順次係数を決めていく手もありますが、今回は実験計画法と呼ばれる手法でまとめて最適化することにしました。
5個のスタートポイントからそれぞれ適当な量を増減してRMS(自乗和のルート)を求めます。まともに組み合わせを考えると2の5乗の32通りの組み合わせがありますから32回計算を行わなければなりません。直交配列表と呼ばれる組み合わせに従って係数を選んで計算させると、8回の計算で済んでしまいます。これは、5個の係数を単独で増減させて計算するときの10回に比べても少ない計算回数になっています。
下のダイアグラムの左下の配列定数が直交配列表になっています。"0"はマイナス側、"1"はプラス側に変化させた係数を意味し、横の行が一組の係数セットになっていて、全部で8行あります。縦の列がそれぞれの係数で、4個は"0"、4個は"1"になっています。例えば、1列目は上から4個が"0"、その下から4個が"1"になっています。上から4行の他の係数は"0"と"1"が半々になっています。従って、上から4個の平均値はb,c,d,eが変化している中でaをマイナス側にしたときの効果としてとらえることができます。その下から4個の平均値はaをプラス側にしたときの効果になります。
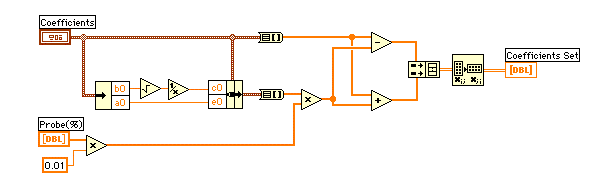
左端中央にあるCoeffSet.viは、初期の係数("Coefficients")と指定された変化幅("Probe(%)")から増減した係数を2次元配列("Coefficients Set")で出力します。8個の計算はフォーループの中で行います。L8 Tableに従って係数を選んでcalcY(x)3.viで"x in"配列に対応するyを出力します。オリジナルデータとの差分をとってRMSを求めます。右端のフォーループでは係数ごとに減少させた場合、増加させた場合の平均を求め、中央値を含め、3要素の配列を作ります。中央値が最小の場合は"Reduction rate"で変化幅("Probe(%)")を小さくします。それ以外の場合は最小値を新しい係数とします。
coeffSet.viでは適当なスケールで係数を増減させたいので、a, b, d はその値の指定比率("Probe(%)")で直接行いますが、c とe は原点( 0, 0 )基準となってしまうので、関数の幅と高さを基に指定比率("Probe(%)")で増減量を与えました。
calcY(x)3.viは単に与えられた係数でy 配列を求めるだけですが、繰り返し使用されるため計算速度に大きく影響するviです。プロフィールウインドウで確認したところでは、フォーミュラノードで計算させるより格段に早くなっています。配列で直接計算させていますが、この方がフォーループに入れるより早くなっています。
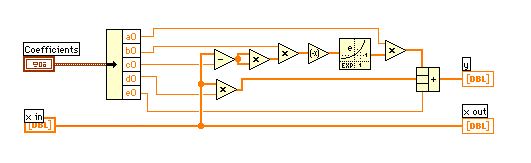
全体をまとめると下のダイアグラムになりました。計算停止の条件は全ての係数が0.01%以内の変化になったときにしています。
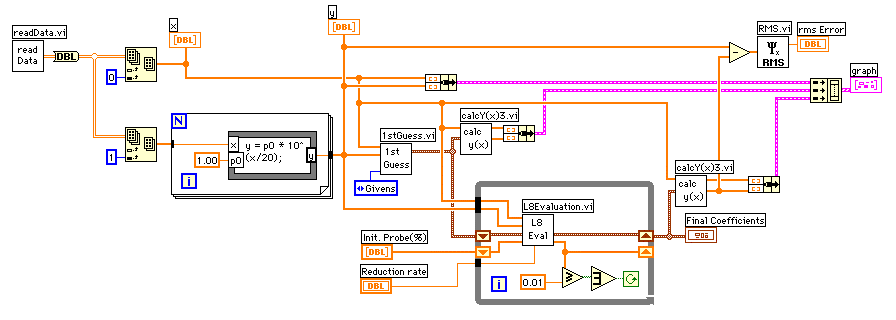
最終的な回帰関数(赤)は初期値の関数(黄色)から大きく離れてはいない。
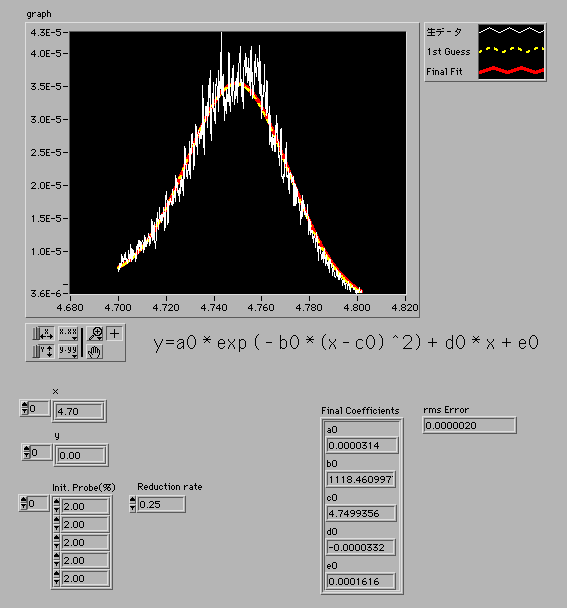
今回は2個の生データで確認しただけですから実際に色々な状況で使うためには修正が必要かもしれません。参考までに紹介させていただきました。
99.09.25 大橋 康司
ohashi@mac.email.ne.jp