
1.初心者にとって取っつきにくい。
2.プロでもよく間違える。
まず、1の方から話しましょう。前回の説明ですっきりする人はほとんどいないと思うのです。もっと詳しい教科書を見ると、さらに「難しい説明」や「実例」があって、初心者はとまどうでしょう。(私がそうでした。)私自身の経験から言うと、「何の役に立つのだろう」などと、気をもむより、実際に使われている例を見てゆっくり馴染んでいけばよいのだと思うのです。
変な話ですが、外国語を覚えるのとプログラミング言語を覚えるのはとてもよく似ています。(これは学生時代のとても優秀な友人たちの言葉です。、、、もしかすると孫引きかもしれませんが。)英語の文法書を読んで、英語が話せるようになる人がほとんどいないように、プログラミング言語の規則を学んでプログラムができるようになる人はまれだと思います。プログラミング言語のよい習得方法は、自分で書いてみることと、上手な人のお手本を調べることです。
ポインタに関しては、特にそうでした。自分であれこれ悩むより、実際の使われ方を見て、学ぶことが多かったようです。
ただ、「よいお手本」はどこにあるのかが問題ですね。もし、ご近所に立派なC/C++プログラマがいたら是非コードを見せてもらってください。(^^;)あとは、やはり具体例のある本を買って読むことだと思います。もうすぐ、入門が終わった頃には、そういう本も少しづつ読めるようになっていると思います。
さて、理由2の方(私の入門ではほとんど扱いません)ですが、ポインタというものは実はとても危険なものです。ポインタはメモリ上のオブジェクトなどのアドレスを指定する変数であり、その変数を使えば、たとえば、そのデータを直接書き換えることもできるからです。(前回の*pなんかです。)これは、うっかりミスで重要なデータを消してしまうことを意味しています。私がそうであったように、初心者のうちにはそんな危険なんか目にはいらないと思います。「重要なデータをうっかり消してしまう?ふ〜ん。でも、そんなことしないよ〜。」ってな感じでした。しかし、実際はポインタを使うプログラムが長くなるにつれ、危険はどんどん増していきます。
教科書を書いている人たちは、当然その危険性を熟知しているので、大抵は、しつこく解説があるようです。しかし、この説明がかえって初心者の気持ちをめげさせているようにも思うのです。ときに無味乾燥な「べからず集」に見えるからです。
こういう教科書が悪いといっているのではありません。むしろとても良い教科書なのです。ただ、まだ、そのレベルに行く前に、ぶつかってしまうと嫌な気持ちになるかな、と思ったので書きました。
ポインタが危険だという事は知っておいてください。しかし、はじめから全ての危険なケースとその対策を学ぶことはできません。要するに、具体例(自分の失敗も含めて)から、ゆっくり学んでくださいということです。繰り返しますが、一部の人がおどしまくっているように、とてつもなく難しいものでもありません。慣れです。
クラス名 インスタンス名;
のように作ってきました。たとえば、
Neko dora("ボス");
なんかです。ここで、Nekoがクラス名、Doraがインスタンス名でした。
この方法はお手軽ですが、必要なときだけ、オブジェクトを作る方法もあります。そのために、使われるがnewです。以下に具体例を見せますが、ちょっと簡単に説明します。newを使うと、オブジェクトが生成されるのですが、ほっておけばできあがったオブジェクトは迷子になってしまいます。それで、できあがったオブジェクトのアドレスをしっかり捕まえておくような仕組みにポインタが使われるのです。
もう一言、newに対になっているのがdeleteで、これはできたオブジェクトをプログラマが消したいときに使うのです。
それでは、具体例を見せます。生成するオブジェクトの型はなんでもよいのですが、簡単のため、「入門18」で作ったNanikaを使いましょう。
//nd_sample.cpp
#include <iostream>
using namespace std;
//英語の教科書によくあるThingをまねてNanikaとしたのですが、なんか不気味ですね。
class Nanika
{
int datum;
public:
//引数を取らないコンストラクタ
Nanika() : datum(0){
cout << "Nanikaのインスタンス"
<< datum << "が生成されました。" << endl;
}
//引数を取るコンストラクタ
Nanika(int x) : datum(x){
cout << "Nanikaのインスタンス" << datum << "が生成されました。" << endl;
}
void func() const{
cout << "Nanikaのインスタンス" << datum << "のfuncが呼ばれました。" <<endl;
}
//デストラクタ
~Nanika(){
cout << "Nanikaのインスタンス" << datum << "が消滅しました。" << endl;
}
};
int main()
{
//Nanikaのポインタをまず用意。これはポインタであってオブジェクトはまだない。
Nanika *p;
cout << "Nanikaのオブジェクトを生成"
<< endl;
p = new Nanika(1);
//上ではNanikaのコンストラクタに「1」が渡され、オブジェクトが生成される。
//引数に「1」を選んだのに意味はない。
//pはポインタなので、メンバ関数を呼び出すのに、「.」ではなく「->」を使う。
p->func();
//ポインタpで示されているインスタンスを消滅させる。
delete p;
}
ポインタ = new コンストラクタ(引数);
などという格好にします。これによってオブジェクトが生成され、そのアドレスがポインタに代入されるのです。newはそのように作られているのです。「pにオブジェクトのアドレスが格納される」ということは、「pがそのオブジェクトを指し示している」ということです。
コンストラクタに引数がない場合、あるいは引数のないコンストラクタを使いたい場合は、「(引数)」はいりません。上の例では、
p = new Nanika(1);
を単に
p = new Nanika;
と書き換えればよいだけです。(上のNanikaには引数を取らないコンストラクタを追加してあります。これがなければ当然エラーになりますので、注意してください。)
そして、newでつくったオブジェクトは基本的にはdeleteで消さなければなりません。それが、最後の
delete p;
です。注意してほしいのですが、pという変数を消しているのでなく、pの指しているオブジェクトを消しているのです。
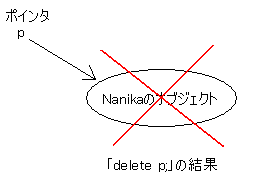
したがって、このあとにプログラムを続ける場合、はじめにつくったNanikaのオブジェクトはもう使えませんが、pはプログラムの最後まで使えます。
deleteをいつ使うか、つまり、いつオブジェクトを消すかはプログラマの自由です。上のサンプル・プログラムは短すぎるので、かえってわかりづらいかもしれませんが、長いプログラムでは、プログラマがよく考えて、オブジェクトを消したい場所でdeleteを使うのです。
その際、一度deleteしたオブジェクトをもう一度deleteしてはいけません。そんなこと普通ならしそうもないですが、長いプログラムで、複雑なことをやっていると、知らずに2度deleteをやってしまうのです。気をつけましょう。(これこそ、上に書いたプロがやるミスのひとつなんです。)
まだ、これらが何の役に立つかわかりづらいですね。私が学校などでC++を教えていて、一番良くある質問は、「どうして今までのやり方ではいけないんですか?なぜnewの方法があるんですか?」というものでした。たとえば、このような仕組みを使えば、「メモリを必要なときに必要なだけ使う」という細かい操作が可能なわけです。最近はメモリが十分あるのであまり気にしないかもしれませんが、「極限に挑戦するプログラム」では重要なわけです。
また、何も「極限に挑戦するプログラム」でなくても、慣れてくれば、いろいろ使い道が見えてくると思います。とりあえず、最初は、こんなのものあるのかと思っておきましょう。
実は、newは配列とからんでもよく使われます。
配列は「入門19」でやりました。配列はとても便利なものですから、思い出しておいてくださいね。ただ、一つだけ、不満な点があります。それは、要素の数がはじめから決まっているということです。入門19の例gakusei_sample.cppでは、算数を受講している学生の点数を処理するプログラムを考えました。その際、学生数ははじめに、10とか100とか決めなければなりませんでした。(Gakusei mine[10];のところです。ここでmine[10]は10個のGakusei(のオブジェクト)の配列を表します。)
しかし、学生数は毎年普通変動しますから、これは不便です。ここで、newが使えるのです。この場合は、配列をつくるので、先ほどと書式が少し違って、
ポインタ = new Gakusei[学生数];
と書くようになります。Gakuseiの後の[ ]は丸かっこではないですね。「これだけの数のオブジェクトをつくれ」というときにはこのように書くのです。
そして、これによって、これらのGakuseiの配列ができあがるのです。
また、deleteも、今は配列のdeleteなので、少し違って、
delete [] ポインタ;
Gakusei *pm;
...
pm = new Gakusei[ninzu];
とやっていますが、これで、ninzu個のGakuseiの配列ができたのです。要素は具体的にはpm[0]、pm[1]、、、pm[9]で表されます。
//gakusei_sample2.cpp
#include <iostream>
using namespace std;
class Gakusei
{
int sansu; //算数の点
public:
//引数なしのコンストラクタ(これがないとプログラムはエラー)
Gakusei(){} //何もしないので、中カッコ内は空
//引数ありのコンストラクタ
Gakusei(int x){ set_sansu(x); }
void set_sansu(int x);
int get_sansu() const{ return sansu; }
void input(); //入力のために新しく付けた
};
void Gakusei::set_sansu(int x){
if(x >= 100){
//xが100以上の時は、100を代入してしまう。
x = 100;
}
sansu = x;
}
void Gakusei::input()
{
int temp;
cout << "算数の点を入力してください:";
cin >> temp;
set_sansu(temp);
}
int main()
{
int ninzu, sum = 0;
Gakusei *pm;
cout << "学生の人数を入力してください。"
<< endl;
cin >> ninzu;
pm = new Gakusei[ninzu];
//引数を取らないコンストラクタが使われる
cout << ninzu << "人の学生の点数を入力してください。"
<< endl;
for(int i = 0; i < ninzu; i++){
pm[i].input();
}
cout << "それでは平均を計算します。"
<< endl;
for(int i = 0; i < ninzu; i++){
sum += pm[i].get_sansu();
}
cout << "平均点は" << sum/ninzu << "です。" <<
endl;
delete [] pm;
}
入門19でも書きましたが、平均の計算sum/ninzuは、整数で行っているので、小数点以下はまるめられてしまいます。(小数点つきの数(つまり、実数)にしたい人は、int
sum = 0; を float sum = 0.0; にしてください。)
引数を取らないコンストラクタがないと配列を作れないのは、newを使う場合も、使わない場合も同様です。

ところで、ここで、
pm[i].input();
などは、
pm[i]->input();
ではないかと悩む人がとても多いようです。上の方の例から類推すると、そんな気がするかもしれません。しかし、(pmはポインタですが、)pm[i]はポインタではなくオブジェクトなのです。なぜか、、、というと、配列の生成は、そうなっているからと考えてください。もしかすると、「Cにおけるポインタと配列要素の関係」を知っている人には、納得しやすいかもしれません。しかし、結局、何がどうあれ、そうなっているわけです。Cを知らない人は、とりあえず、そんなもんかと思ってもらえればよいと思います。(最近はC入門も書きましたので、興味のある人はのぞいてみてください。)