Network Working Group P. Deutsch
Request for Comments: 1951 Aladdin Enterprises
Category: Informational May 1996
デフレート圧縮データ形式仕様書 バージョン1.3
(DEFLATE Compressed Data Format Specification version 1.3)
<<邦訳; 大橋 康司 ohashi@mac.email.ne.jp>>
このメモのステータス
このメモはインターネットコミュニティのための情報を提供する。このメモは、いかなる種類のインターネット標準を規定するものではない。このメモの配付に関する制限はない。
IESGのノート:
IESGはこの文書に含まれる知的所有権の記載が正しいものであるかどうか一切関知しない。
告知事項
Copyright (c) 1996 L. Peter Deutsch
この文書の複写と配付および他の言語への翻訳や編集物への編入は著作権表示と本告知が保持されていて、本質的な変更や削除が明確に表示されているかぎり、目的を問わず無料である。
<<権利、義務に関しては文書の最後に添付した原文を参照のこと[訳者]>>
HTMLフォーマットの本文書および関連する文書の最新版については以下のURLを参照できる。
<ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html>
要約
この仕様書はLZ77アルゴリズムとHuffman 符号化の併用により、現在利用されている最高の汎用圧縮方法と同程度の効率でデータを圧縮できる可逆圧縮フォーマットについて規定する。任意の長さで順次受け取られるデータストリームに対しても容量が制限された中程度の容量の記憶装置を使用してデータを生成したり利用することができる。このフォーマットは特許に制限されることなく容易にプログラムすることができる。
目次
1. 初めに
1.1. 目的
1.2. 想定している読者
1.3. 範囲
1.4. 準拠
1.5. 用語の定義と慣用
1.6. 以前のバージョンからの変更点
2. 圧縮表現概観
3. 詳細仕様
3.1. 記法
3.1.1. バイトへのパッキング
3.2. 圧縮ブロックフォーマット
3.2.1. プレフィックス符号化とハフマン符号化の概要
3.2.2. デフレートフォーマットでのハフマン符号化の使い方
3.2.3. ブロックフォーマットの詳細
3.2.4. 非圧縮ブロック(BTYPE=00)
3.2.5. 圧縮ブロック(長さと距離のコード)
3.2.6. 固定ハフマンコードによる圧縮(BTYPE=01)
3.2.7. ダイナミックハフマンコードによる圧縮(BTYPE=10)
3.3. 準拠
4. 圧縮アルゴリズムの詳細
5. References
6. Security Considerations
7. Source code
8. Acknowledgements
9. Author's Address
1. 初めに
1.1. 目的
この仕様書の目的は以下の特徴を持つ可逆データ圧縮フォーマットを規定することである。
*CPUタイプ、オペレーティングシステム、ファイルシステム、キャラクターセットに依存しない。したがって、相互交換のために使用できる。
*任意の長さで順次受け取られるデータストリームに対しても容量が制限された中程度の容量の記憶装置を使用してデータを生成したり利用することができる。したがって、データ通信やUnixで用いられるフィルターと似た機構で用いることができる。
*現在利用されている最高の汎用圧縮方法と同程度の効率でデータを圧縮でき、特に"compress"プログラムよりもかなり効率が良い。
*このフォーマットは特許に制限されることなく容易にプログラムすることができる。したがって自由に試すことができる。
*現在広く使われているgzipユーティリティで作られるフォーマットと互換性があるため、仕様にしたがった伸長プログラムはgzip圧縮プログラムで作られたデータを伸長することができる。
この仕様に規定されているデータフォーマットは以下の用途には適さない。
*圧縮されたデータへのランダムアクセスを行う。
*特別なデータ(ラスターグラフィックスなど)を対象にしたり、最高水準の特定アルゴリズムで圧縮する。
簡単な議論によって分かることだが、どんな入力データに対してもファイルサイズを小さくできる可逆圧縮アルゴリズムというものは存在しない。ここで規定したフォーマットの場合、最悪のケースで32Kバイトにつき5バイト増加する。すなわち、大きなデータの場合、ファイルサイズは0.015%増加してしまう。英文の場合通常1/2.5から1/3程度に、実行ファイルではやや圧縮率が悪くなり、ラスター画像のような画像データではもっと圧縮率が良くなる。
1.2. 想定する読者
この仕様書はデフレート("deflate")フォーマットでデータを圧縮したり、デフレートフォーマットからデータを伸長するプログラムを作成しようとする人に使ってもらうことを意図している。
この仕様書の文章はビットやその他の基本的データ表現レベルのプログラミングに関する基礎的な知識があることを前提に書かれている。ハフマン(Huffman)符号化に関する技術を理解していれば役に立つが、必須ではない。
1.3. 範囲
この仕様書はバイトの列を(通常は短い)ビットの列に変換する方法とビット列をバイト列にパッキングする方法について規定している。
1.4. 準拠
以下に明記されること以外、この仕様に準拠する伸長器は仕様にある全ての方法にしたがったデータセットを受け取り伸長できなければならない。この仕様に準拠する圧縮器は仕様にある全ての方法にしたがってデータセットを生成できなければならない。
1.5. 用語の定義と慣用
バイト(Byte):一つの塊として保管されたり、転送されたりする8ビット。この仕様の中ではたとえ文字を8とは異なるビット数で保存する機械で使われる場合でも1バイトは厳密に8ビットである。1バイトの中でのビット順については以下の説明を見ること。
ストリング(String):任意の長さのバイト列
1.6. 以前のバージョンからの変更点
バージョン1.1の仕様書からデフレートフォーマットに関する技術的な変更はない。バージョン1.2では用語の変更があった。バージョン1.3ではRFC様式に仕様書を変更した。
2. 圧縮表現概観
圧縮されたデータセットは入力データの連続するブロックに対応して、一連のブロックからできている。ブロックは、非圧縮ブロックが65,535バイト以下に制限されている以外は任意の大きさになっている。
それぞれのブロックは、LZ77アルゴリズムとハフマン 符号化の結合により圧縮される。それぞれのブロックのハフマンツリーは前後のブロックに対して独立したものが用いられる。LZ77アルゴリズムでは前のブロックで処理した入力データに対しても最大32Kバイト前であれば、重複した文字列への参照を行うことができる。
それぞれのブロックは二つの部分、圧縮データ部分の表現を記述した一対のハフマンツリーと圧縮データからできている。(ハフマンツリー自体もハフマン 符号化で圧縮されている。)圧縮されたデータは2種類の要素からなっている。2種類の要素とは、文字列のアスキー表記そのもの(それ以前の32Kバイトの入力文字列に現れていない文字列)と重複している文字列への参照記号である。参照記号は重複文字列の長さ(これ以降は"長さ"と表記する)と重複部分の開始位置(これ以降は"距離"と表記する)の一対で示される。デフレートフォーマットで用いられている表現は長さが258以内で、距離が32Kバイトに制限されているが、前に述べた非圧縮ブロックは除いてブロックの長さに制限はない。
圧縮データ部分の文字、距離、長さというそれぞれのタイプの値は、文字と長さのためのツリーと距離のツリーを使ってハフマン 符号で表現されている。ブロック毎のツリーはコンパクトにまとめられた形式でそのブロックの圧縮データ部分の前に書かれている。
3. 詳細仕様
3.1. 記法
次のボックスは1バイトを表す。
+---+
| | <-- 縦線は書かれない場合がある
+---+
次のボックスは数バイトを表す。
+==============+
| |
+==============+
コンピュータの中で保存されるときバイトは常に一つの単位として扱われるためビットオーダーを持たない。しかしながら、1バイトを0から255の整数と考えたとき最上位ビット(MSB)や最下位ビット(LSB)を考えることができる。数字を書くときに位の高い数字を左に書くのと同様に、ここでは最上位ビットを左端に書くことにする。最上位ビットを7、最下位ビットを0として下の絵のように書き表すことにする。
+--------+
|76543210|
+--------+
コンピュータの内部では、複数のバイトで数値を表すことがある。ここでは複数バイトの数値は、最下位バイトを先頭(メモリアドレスの低いほう)に保存されているとする。例えば、10進数で520は以下のように保存される。
0 1
+--------+--------+
|00001000|00000010|
+--------+--------+
^ ^
| |
| + 上位バイト= 2 x 256
+ 下位バイト= 8
3.1.1. バイトへのパッキング
最終的なデータフォーマットではビット単位の順番ではなくバイト単位の順番が基本となっているため、この文書ではビット単位の順番が基本となるメディアにバイトの中のビットがどういう順番で転送されるかについては扱わない。しかしながら、以下に述べる圧縮ブロックのフォーマットではバイトの並びではなく、色々なビット長のデータ要素の並びについて述べる。したがって、我々は、バイト順に並んでいる最終的な圧縮データを得るために、データ要素をどのようにしてバイトに詰め込むかについて明確にする必要がある。
*データ要素のバイトへのパッキングは、バイトの中でビット番号が大きくなる方向に行う。すなわち、バイトの最下位ビットからスタートする。
*ハフマンコード以外のデータ要素は、データ要素の最下位ビットから詰める。
*ハフマンコードはコードの最上位ビットから詰める。
言い変えれば、バイト列としての圧縮データをプリントアウトする際に、最上位ビットは通常通り左端にして、1番目のバイトを右マージンで左に向かって処理を続ける。すると、右から左へと固定幅の要素が正しいMSBからLSBへの順番となって結果を追うことができる。ハフマンコードはビットが通常と逆の順番(コードの第1ビットが相対的に最下位ビット側に来るように)となる。
3.2. 圧縮ブロックフォーマット
3.2.1. プレフィックス符号化とハフマン符号化の概要
プレフィックス 符号化はアルファベットからの記号をビット列でできたコードであらわす。一つの記号に一つのコードが対応し、異なる記号は異なる長さのビット列であらわされるかもしれない。しかし、コード化された記号を間違いなく理解することができる。
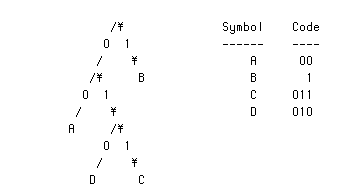
我々の定義するプレフィックスコードは2分木の用語で言えば、ノードから分岐した二つの枝は0と1にラベル付けされる、葉ノードはアルファベットの記号に対応する。そして、記号に対するコードはルートノード(最上位にあるノード)から記号のある葉ノードまでの0と1の数字の並びで与えられる。例えば、以下のように表示される。
復号はコードのビット列(0と1の数字の並び)に従ってルートノードから枝を選んで記号のある葉ノードの記号を知ることができる。
記号の出現頻度がわかっている場合、ハフマンアルゴリズムは出現頻度が高い記号にビット数が少ないプレフィックスコードを使うため最適化されたプレフィックスコードを生成することができる。そのようなコードをハフマンコードという。(ハフマンコードについての詳しく知りたい場合は、参考文献1の5章を見ること。)
デフレートフォーマットではアルファベット記号に与えるハフマンコードはあるビット長よりも長くなってはならない。この制約が記号の出現頻度からコードの長さを計算するアルゴリズムを複雑なものにしている。詳しくは、参考文献1の5章を見ること。
3.2.2. デフレートフォーマットでのハフマン符号化の使い方
デフレートフォーマットではアルファベット記号へのハフマンコードの与え方に二つのルールを追加した。
*ビット長が与えられたとき記号が辞書の順番になるようにコードを割り付ける。
*ビット長が短いコードは辞書的にビット長が長いコードに先行する。
アルファベットがABCDの順であるとき、これらのルールにしたがってコードを割り付けると以下のようになる。
記号 コード
------ ----
A 10
B 0
C 110
D 111
すなわち、(ビット数の短い)0は10の前になっていて、10は110,111の前にある。110と111は記号の辞書順に割り付けられている。
このルールに従えば、記号の辞書的順番に記号毎のコードのビット長与えるだけでハフマンコードを知ることができる。先の例ではビット長の並びは(2, 1, 3, 3)となる。以下のアルゴリズムは整数(上位ビットから下位ビットに向かって読む)としてコードを生成する。コード長はtree[I].Lenで与えられ、コードはtree[I].Codeに作られる。
1)コード長毎にコードの数をカウントする。N>=1の時、bl_count[N]をコード長Nのコード数とする。
2)コード長毎に最小のコードの数値を見つける。
code = 0;
bl_count[0] = 0;
for (bits = 1; bits <= MAX_BITS; bits++) {
code = (code + bl_count[bits-1]) << 1;
next_code[bits] = code;
}
3)同じビット長のコードにはステップ2で決めた最小のコード値から通し番号を付けることにより、全てのコードに数値を割り付ける。一度も現れない記号(ビット長0)には数値を割り付けてはならない。
for (n = 0; n <= max_code; n++) {
len = tree[n].Len;
if (len != 0) {
tree[n].Code = next_code[len];
next_code[len]++;
}
}
例:
アルファベットABCDEFGHがビット長(3, 3, 3, 3, 3, 2, 4, 4)の場合を考える。ステップ1が終わると以下のようになる。
N bl_count[N]
- -----------
2 1
3 5
4 2
ステップ2では次のnext_code値が得られる。
N next_code[N]
- ------------
1 0
2 0
3 2
4 14
ステップ3では以下のコード値が得られる。
Symbol Length Code
------ ------ ----
A 3 010
B 3 011
C 3 100
D 3 101
E 3 110
F 2 00
G 4 1110
H 4 1111
3.2.3. ブロックフォーマットの詳細
圧縮データのそれぞれのブロックは以下のデータからなる3ビットのヘッダーから始まる。
第1ビット BFINAL
次の2ビット BTYPE
ブロックは整数バイトであるとは限らないため、ヘッダービットは必ずしもバイトの先頭から始まらないことに注意しなければならない。
BFINALは最終ブロックであるときだけセットされる。
BTYPEは以下のように圧縮方法を示している。
00 - 非圧縮
01 - 固定ハフマンコード圧縮
10 - ダイナミックハフマンコード圧縮
11 - 予約(エラー)
2種類の圧縮方法の違いは、文字/長さ用と距離用のハフマンコードの定義の仕方によるものである。
全てのケースに対して実際のデータの伸長アルゴリズムは以下のようなものである。
do
read block header from input stream.
if stored with no compression
skip any remaining bits in current partially
processed byte
read LEN and NLEN (see next section)
copy LEN bytes of data to output
otherwise
if compressed with dynamic Huffman codes
read representation of code trees (see
subsection below)
loop (until end of block code recognized)
decode literal/length value from input stream
if value < 256
copy value (literal byte) to output stream
otherwise
if value = end of block (256)
break from loop
otherwise (value = 257..285)
decode distance from input stream
move backwards distance bytes in the output
stream, and copy length bytes from this
position to the output stream.
end loop
while not last block
重複した文字列への参照は前のブロックにも及ぶことに注意が必要である。すなわち、伸長済みの文字列への距離は数ブロック前のものになることもある。しかしながら、距離は、出力文字列の開始点よりも遠くになることはない。(固定辞書を使っているアプリケーションは出力文字列の一部を破棄することがある。それによらず、距離はしゅつりょくもじれつの破棄された部分を参照することができる。)さらに、注意が必要なことだが、参照される文字列は現在の場所に部分的に重なるように参照されるかもしれない。例えば、伸長済みの最後の2文字がxとyであったとき、<length = 5, distance = 2>で文字列が参照されれば、XYXYXを出力する。
さて、個々の圧縮方法を順番に説明する。
3.2.4. 非圧縮ブロック(BTYPE=00)
次のバイト境界まで全てのビットを無視する。
残りのブロックは次のような情報からなっている。
0 1 2 3 4...
+---+---+---+---+================================+
| LEN | NLEN |... LEN bytes of literal data...|
+---+---+---+---+================================+
LENはブロックに入っているデータのバイト数。NLENはLENの1の補数。
3.2.5. 圧縮ブロック(長さと距離のコード)
これまでに述べてきたように、デフレートフォーマットのコード化されたデータのブロックは3種類の概念が異なるアルファベットから引かれた記号の列からできている。
3種類の概念が異なるアルファベットとは、(0..255)のバイト値を持つ文字、あるいは、長さと戻り方向の距離からなる一対の記号のことである。長さは(3..258)の中から選ばれ、距離は(1..32,768)から選ばれる。実際は文字と長さは(0..285)の一つのアルファベットに合成され、0..255は文字を、256はブロックの終端、257..285は場合により引き続く追加ビットを持って長さの記号を意味する。
Extra Extra Extra
Code Bits Length(s) Code Bits Lengths Code Bits Length(s)
---- ---- ------ ---- ---- ------- ---- ---- -------
257 0 3 267 1 15,16 277 4 67-82
258 0 4 268 1 17,18 278 4 83-98
259 0 5 269 2 19-22 279 4 99-114
260 0 6 270 2 23-26 280 4 115-130
261 0 7 271 2 27-30 281 5 131-162
262 0 8 272 2 31-34 282 5 163-194
263 0 9 273 3 35-42 283 5 195-226
264 0 10 274 3 43-50 284 5 227-257
265 1 11,12 275 3 51-58 285 0 258
266 1 13,14 276 3 59-66
追加ビットは最上位ビットが先頭になる順番で記録された整数であり、例えば1110は14という値となる。
Extra Extra Extra
Code Bits Dist Code Bits Dist Code Bits Distance
---- ---- ---- ---- ---- ------ ---- ---- --------
0 0 1 10 4 33-48 20 9 1025-1536
1 0 2 11 4 49-64 21 9 1537-2048
2 0 3 12 5 65-96 22 10 2049-3072
3 0 4 13 5 97-128 23 10 3073-4096
4 1 5,6 14 6 129-192 24 11 4097-6144
5 1 7,8 15 6 193-256 25 11 6145-8192
6 2 9-12 16 7 257-384 26 12 8193-12288
7 2 13-16 17 7 385-512 27 12 12289-16384
8 3 17-24 18 8 513-768 28 13 16385-24576
9 3 25-32 19 8 769-1024 29 13 24577-32768
3.2.6. 固定ハフマンコードによる圧縮(BTYPE=01)
2種類のアルファベットに対するハフマンコードは固定されていて、データの中には示されていない。文字・長さのアルファベットに対するコード長は以下の通り。
Lit Value Bits Codes
--------- ---- -----
0 - 143 8 00110000 through
10111111
144 - 255 9 110010000 through
111111111
256 - 279 7 0000000 through
0010111
280 - 287 8 11000000 through
11000111
コード長は実際のコードを生成するのに十分な長さを持っている。分かりやすいように上のテーブルではコードも示しておいた。文字・長さの値で286-287は実際には決して圧縮データの中に現れないのだが、コードの構成に必要となっている。
距離コード0-31は固定長の5ビットで、3.2.5の表で示したように必要に応じて追加ビットを持つ。距離コード30-31は実際には決して圧縮データの中に現れない。
3.2.7. ダイナミックハフマンコードによる圧縮(BTYPE=10)
2種類のアルファベットに対するハフマンコードはヘッダービットの直後で圧縮データ部分の前に文字・長さコード、距離コードの順で書かれている。それぞれのコードは3.2.2で書いたようにコード長を並べたものになっている。さらに圧縮率を上げるために、コード長の並び自体がハフマンコードが使われている。コード長へのアルファベットは以下のようになっている。
0 - 15: Represent code lengths of 0 - 15
16: Copy the previous code length 3 - 6 times.
The next 2 bits indicate repeat length
(0 = 3, ... , 3 = 6)
Example: Codes 8, 16 (+2 bits 11),
16 (+2 bits 10) will expand to
12 code lengths of 8 (1 + 6 + 5)
17: Repeat a code length of 0 for 3 - 10 times.
(3 bits of length)
18: Repeat a code length of 0 for 11 - 138 times
(7 bits of length)
コード長0は対応する文字・長さと、距離のアルファベットがそのブロックには存在しないことを示している。そしてそのコードは始めに示したハフマンコードの構成アルゴリズムにかかわってはならない。もしも、ただ一つの距離コードしか使われていないときには、0ビットではなく、1ビットで記号化しなければならない。この場合コード長1の一つのコードと、使われていないコードで構成される。0ビットの1個の距離コードはまったく距離コードが使われていないことを示す。(つまり、データは全て文字コードからなる。)
われはれは、ブロックのフォーマットを示せる段階にきた。
5 Bits: HLIT, # of Literal/Length codes - 257 (257 - 286)
5 Bits: HDIST, # of Distance codes - 1 (1 - 32)
4 Bits: HCLEN, # of Code Length codes - 4 (4 - 19)
(HCLEN + 4) x 3 bits: コード長を示すアルファベットのためのコード長は以下の順番で与えられる: 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1,15
これらのコード長は3ビット整数であると解釈される。コード長0は対応するシンボル(文字・長さコード、距離コード)が使われていないことを示す。
HLIT + 257 文字・長さアルファベット用のコード長でコード長用ハフマンコードで記号化されている
HDIST + 1 距離アルファベット用のコード長でコード長用ハフマンコードで記号化されている
文字・長さ、距離ハフマンコードで記号化された、ブロックの実際の圧縮データ
文字・長さハフマンコードで記号化された、文字・長さ値256(ブロックの終端)
コード長繰り返しコードは HLIT + 257 からHDIST + 1 まで。言い変えれば、全てのコード長は単一のHLIT + HDIST + 258のシーケンスをかたちづくる。
3.3. 準拠
圧縮ソフトは前のセクションで規定された値の範囲をさらに限定を加えることができ、それでも互換性が維持できる。例えば、後ろ方向へのポインターの距離として32Kより少ない値に限定することができる。同様に、ブロックサイズを制限してメモリ容量に合った圧縮ブロックにすることができる。
伸長ソフトは規定される全ての値に対応し、任意のブロックサイズに対応しなければならない。
4. 圧縮アルゴリズムの詳細
特定の圧縮アルゴリズムによらずデフレートフォーマットを規定することが本文書の狙いであるが、このフォーマットはLZ77(Lempel-Ziv 1977, 文献[2]参照)によって作られた圧縮フォーマットに関連している。LZ77の多くの変形版が特許となっているので、圧縮プログラムの作成はここで紹介する特許に縛られないアルゴリズムに従うことを強く勧める。この章は仕様ではないので、互換性の観点からは圧縮ソフトはこれらに従う必要はない。
圧縮器は新しいハフマン木を作った方が良いと判断したとき、あるいは、ブロックサイズがブロックバッファーを越えそうになったときにブロックを終了させる。
圧縮器は重複している文字列を見つけるために3バイト文字列に対する連結されたハッシュテーブルを使用する。圧縮過程のどの時点でもかまわないが、xyzが次に圧縮しようとしている文字列だったとしよう。もちろんxyzが全て異なる文字である必要はない。圧縮器は第1にxyzに対するハッシュチェーンを調べる。もしも、そのチェーンが空であったときには圧縮器はxを書き出して入力を一つ先に進める。もしも、チェーンが空でなかったときには、xyz(あるいは、不幸にして、同じハッシュ値を持つ別の3バイト文字列かもしれないが、)の文字列は過去にあったことになり、圧縮器は現時点のポインターから始まる入力文字列とxyzハッシュチェーンにある全ての文字列を比較し、最も長く一致している文字列を選択する。
圧縮器は距離が小さいほどハフマンコードが短くなるので、最近の文字列からハッシュチェーンを探し始める。ハッシュチェーンは単一のリンクである。ハッシュチェーンからの削除は行わない。アルゴリズムは距離が長いマッチは捨て去る。最悪の状況を避けるために、非常に長いハッシュチェーンは実行時のパラメータによりある長さに任意に縮められる。
全体の圧縮性能を向上させるために、圧縮器はオプションで一致の決定を先に延ばす("lazy matching")ことができる。長さNの一致があったとき圧縮器は次の入力バイトから始まるさらに長い一致があるか調べる。さらに長い一致が見つかったときには、前に見つけた一致文字列は1文字に減し(したがって、一個の文字を出力する)、あとで見つけたより長い一致文字列を採用する。さらに長い文字列が見つからなかった場合は、初めの一致文字列を採用する。そして、前に述べたようにNバイト分先に進める。
実行時のパラメータで"lazy match"の条件を設定できる。もしも、圧縮率が最も重要な場合、圧縮器は初めの一致文字列の長さにかかわらず、第2の一致を探す。通常の設定のでは、一致した文字列が十分長いとき、圧縮器はさらに長い一致を探さず、処理を高速化する。処理スピードが最も重要なときには、一致しない文字列の場合か、一致が短いときだけ新しい文字列をハッシュテーブルに挿入する。これにより、圧縮比は低下するが、挿入と検索の両方を減らすため、時間を短くすることができる。
5. References
[1] Huffman, D. A., "A Method for the Construction of Minimum
Redundancy Codes", Proceedings of the Institute of Radio
Engineers, September 1952, Volume 40, Number 9, pp. 1098-1101.
[2] Ziv J., Lempel A., "A Universal Algorithm for Sequential Data
Compression", IEEE Transactions on Information Theory, Vol. 23,
No. 3, pp. 337-343.
[3] Gailly, J.-L., and Adler, M., ZLIB documentation and sources,
available in ftp://ftp.uu.net/pub/archiving/zip/doc/
[4] Gailly, J.-L., and Adler, M., GZIP documentation and sources,
available as gzip-*.tar in ftp://prep.ai.mit.edu/pub/gnu/
[5] Schwartz, E. S., and Kallick, B. "Generating a canonical prefix
encoding." Comm. ACM, 7,3 (Mar. 1964), pp. 166-169.
[6] Hirschberg and Lelewer, "Efficient decoding of prefix codes,"
Comm. ACM, 33,4, April 1990, pp. 449-459.
6. Security Considerations
Any data compression method involves the reduction of redundancy in
the data. Consequently, any corruption of the data is likely to have
severe effects and be difficult to correct. Uncompressed text, on
the other hand, will probably still be readable despite the presence
of some corrupted bytes.
It is recommended that systems using this data format provide some
means of validating the integrity of the compressed data. See
reference [3], for example.
7. Source code
Source code for a C language implementation of a "deflate" compliant
compressor and decompressor is available within the zlib package at
ftp://ftp.uu.net/pub/archiving/zip/zlib/.
8. Acknowledgements
Trademarks cited in this document are the property of their
respective owners.
Phil Katz designed the deflate format. Jean-Loup Gailly and Mark
Adler wrote the related software described in this specification.
Glenn Randers-Pehrson converted this document to RFC and HTML format.
9. Author's Address
L. Peter Deutsch
Aladdin Enterprises
203 Santa Margarita Ave.
Menlo Park, CA 94025
Phone: (415) 322-0103 (AM only)
FAX: (415) 322-1734
EMail: <ghost@aladdin.com>
Questions about the technical content of this specification can be
sent by email to:
Jean-Loup Gailly <gzip@prep.ai.mit.edu> and
Mark Adler <madler@alumni.caltech.edu>
Editorial comments on this specification can be sent by email to:
L. Peter Deutsch <ghost@aladdin.com> and
Glenn Randers-Pehrson <randeg@alumni.rpi.edu>
このメモのステータス、IESGのノート、告知事項の原文
Status of This Memo
This memo provides information for the Internet community. This memo
does not specify an Internet standard of any kind. Distribution of
this memo is unlimited.
IESG Note:
The IESG takes no position on the validity of any Intellectual
Property Rights statements contained in this document.
Notices
Copyright (c) 1996 L. Peter Deutsch
Permission is granted to copy and distribute this document for any
purpose and without charge, including translations into other
languages and incorporation into compilations, provided that the
copyright notice and this notice are preserved, and that any
substantive changes or deletions from the original are clearly
marked.