質問は「英字が含まれているか」だったのですが....
そもそもコード設計の問題ですが....
こんな質問をしてくる場面は同じ「商品コード」であっても桁数もバラバラ、数字だけだったり英字が含まれていたりで、何かその文字列中の文字に「意味」があるようなケースだろうと思います。
もしかしたら「数字だけで構成されているか」ではないのか、とか「商品コード等ならマスタで存在チェックすれば済む」とかご意見もあろうかと思います。 まあ、場面はさておき、「英字が含まれているか」などを判定してみます。
何種類かの方法を提示していますが、実情にあった方法を考えて下さい。
もしかしたら「数字だけで構成されているか」ではないのか、とか「商品コード等ならマスタで存在チェックすれば済む」とかご意見もあろうかと思います。 まあ、場面はさておき、「英字が含まれているか」などを判定してみます。
何種類かの方法を提示していますが、実情にあった方法を考えて下さい。
- サンプルを用意しました。
-
(画像をクリックすると、このページのサンプルがダウンロードできます)
このようなサンプルを用意しました。
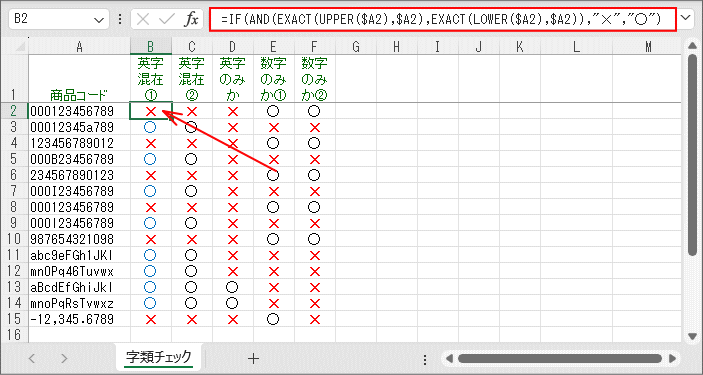
A列に「商品コード」があり、B~F列でその評価を行なっています。
以降に各評価列の目的や数式説明を行ないます。
- [B列]英字が含まれているか①
-
半角英字が1文字でも含まれていれば「○」とする例です。簡易的な方法です。
半角英字は「大文字変換(UPPER関数)」「小文字変換(LOWER関数)」ができるので、 両方それぞれを変換させた文字列と元の文字列が同じなら「半角英字は含まれない」と判断できるという方法です。=IF(AND(EXACT(UPPER($A2),$A2),EXACT(LOWER($A2),$A2)),"×","○")
一致を判断する「EXACT関数」は大文字/小文字を含めての完全一致かどうかが判定できます。
関数 概略説明 IF関数 比較判断を行ない、肯定時と否定時に分けます。引数は以下の通りです。
① 比較判断式
② 肯定時の値(または処置式)
③ 否定時の値(または処置式)EXACT関数 2つの文字列を比較して、まったく同じである場合は TRUEを、そうでない場合は FALSEを返します。
EXACT関数では大文字と小文字は区別されますが、書式の違いは無視されます。
引数は2つの文字列を第1引数、第2引数で指定します。
UPPER関数 文字列を大文字に変換します。 引数は変換元の文字列です。
LOWER関数 文字列を小文字に変換します。 引数は変換元の文字列です。
- [C列]英字が含まれているか②
-
半角英字が1文字でも含まれていれば「○」とする例です。質問を字面の通り「まじめ」に取り組んだ方法です。
半角英字26文字種を1文字ずつ判定する方法ですが、「COUNTIF関数」をワイルドカードで文字検索させています。=IF(SUM(COUNTIF($A2,"*A*") ,COUNTIF($A2,"*B*") ,COUNTIF($A2,"*C*") ,COUNTIF($A2,"*D*") ,COUNTIF($A2,"*E*") ,COUNTIF($A2,"*F*") ,COUNTIF($A2,"*G*") ,COUNTIF($A2,"*H*") ,COUNTIF($A2,"*I*") ,COUNTIF($A2,"*J*") ,COUNTIF($A2,"*K*") ,COUNTIF($A2,"*L*") ,COUNTIF($A2,"*M*") ,COUNTIF($A2,"*N*") ,COUNTIF($A2,"*O*") ,COUNTIF($A2,"*P*") ,COUNTIF($A2,"*Q*") ,COUNTIF($A2,"*R*") ,COUNTIF($A2,"*S*") ,COUNTIF($A2,"*T*") ,COUNTIF($A2,"*U*") ,COUNTIF($A2,"*V*") ,COUNTIF($A2,"*W*") ,COUNTIF($A2,"*X*") ,COUNTIF($A2,"*Y*") ,COUNTIF($A2,"*Z*"))>0,"○","×")
「COUNTIF関数」の第1引数は「検索するセル範囲」であり、結果は「該当するセルの個数」で返されるものですが、 ここでは単一セルで行なうため「1」か「0」しか返りません。
これを26文字種についてそれぞれ行ない、戻り値の合計を「SUM関数」で集計させています。
結果がゼロでなければ「半角英字は含まれる」と判断できるという方法です。
なお、「COUNTIF関数」では半角英字の大文字/小文字は区別されないので、大文字のみで検査しています。
関数 概略説明 COUNTIF関数 指定範囲から検索条件に一致するセルの個数を返します。引数は以下の通りです。
① セル範囲
② 検索条件
SUM関数 引数に指定した個々の値、セル参照、セル範囲、またはこれらの組み合わせを加算合計します。
- [D列]英字だけで構成されているか
-
「英字が含まれているか」ではなく「英字だけで構成されているか」なので難しくなりました。
なぜ「難しい」かというと、Excelには「文字列中に特定文字が何個あるか」を単純に算出する適当な関数がないのです。=IF(SUM((LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"A",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"B",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"C",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"D",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"E",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"F",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"G",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"H",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"I",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"J",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"K",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"L",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"M",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"N",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"O",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"P",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"Q",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"R",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"S",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"T",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"U",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"V",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"W",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"X",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"Y",""))) ,(LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"Z",""))))=LEN($A2),"○","×")
やり方としては、半角英字26文字種を1文字ずつ判定する方法なのですが、各半角英字を文字列中から一旦「無いもの」として変換し、 その変換後の文字列長と元の文字列長の「差」を求めれば該当の半角英字の文字数になる、という方法を採ります。
これを26文字種全てについて行ない、結果の文字数の合計が元々の文字数と一致すれば「半角英字のみ」と判断できるわけです。
なお、半角英字は大文字/小文字の問題があるので「大文字変換(UPPER関数)」で大文字にした上で判定します。
半角英字26文字種の1文字分の判定は、
となります。LEN($A2)-LEN(SUBSTITUTE(UPPER($A2),"A",""))
まず、「LEN($A2)」は元の文字列の文字数です。
「SUBSTITUTE(UPPER($A2),"A","")」が「大文字変換した元の文字列の中の"A"を""(空文字)に置き換える」という動作になります。
空文字は文字数にカウントされないので、"A"の分が差し引かれたカウントになり、それを元の文字列長から差し引くので実質"A"の文字数になるわけです。 (引数の範囲区別を明確にするため、この単位でカッコを付けています)
実際問題として、「LEN($A2)」はこの数式の中で27箇所で発生しているわけで「無駄な動き」にも見えます。
現在のPCでは何の問題もなく動作しているようですが、この分を一旦使わない列に収容して、この数式ではそのセルの参照にする方が効率的なのかも知れません。
関数 概略説明 SUBSTITUTE関数 対象文字列内の検索文字(文字列)を置換文字(文字列)に置き換えます。
引数は以下の通りです。
① 対象文字列
② 検索文字(文字列)
③ 置換文字(文字列)
④ 置換対象(省略可、省略した場合はすべての文字列が対象になります)
LEN関数 文字列の文字数を返します。引数は対象となる文字列です。
- [E列]数字だけで構成されているか①
-
簡易的な方法として「数字だけの文字列なら数値に変換できる」ということを利用する方法です。完全な方法ではありません。
対象文字列を「VALUE関数」で数値変換し、失敗しなければ「数字だけの文字列」だと判断する方法です。 「失敗」の判定は「ISERROR関数」で行ないます。 (桁数オーバーは指数処理されるのか30桁位でもエラーにはなりません)=IF(ISERROR(VALUE($A2)),"×","○")
但し、サンプル画面の15行目のように符号、小数点、カンマ(位取り)が適切な位置にあると、 「○」になってしまうという問題点があります。
関数 概略説明 ISERROR関数 指定された値(数式)のエラー有無をチェックして、その結果によりTRUEまたはFALSEを返します。
引数はエラーを検査する数式(または評価値)です。
VALUE関数 「数値を表す文字列」を「数値」に変換します。引数は「数値を表す文字列」です。
- [F列]数字だけで構成されているか②
-
これはD列の「英字だけで構成されているか」と同じ考え方の方法です。
数字なので10種類となり、大文字/小文字の問題がなくなるので、D列より簡単な数式になりました。=IF(SUM((LEN($A2)-LEN(SUBSTITUTE($A2,"0",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"1",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"2",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"3",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"4",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"5",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"6",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"7",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"8",""))) ,(LEN($A2)-LEN(SUBSTITUTE($A2,"9",""))))=LEN($A2),"○","×")
説明はD列と同じになるので割愛します。