要約
このドキュメントは、RDF 1.1[RDF11-CONCEPTS]とRDFスキーマ[RDF11-SCHEMA]の厳密なセマンティクスを記述しています。多くの様々な含意レジームと、対応する含意のパターンを定義しています。これは、RDF 1.1のフル仕様を含む一連のドキュメントの一部です。
このドキュメントのステータス
この項は、このドキュメントの公開時のステータスについて記述しています。他のドキュメントがこのドキュメントに取って代わることがありえます。現行のW3Cの刊行物およびこの技術報告の最新の改訂版のリストは、http://www.w3.org/TR/のW3C技術報告インデックスにあります。
このドキュメントは、RDF 1.1ドキュメント群の一部です。これは、2004年のRDF[RDF-MT]のセマンティクス仕様の改訂版で、そのドキュメントに取って代わります。その時以後の本質的な(編集上のものではない)変更に関する非形式的な要約については、含意の変更を参照してください。
このドキュメントは、RDFワーキンググループによって勧告として公開されました。このドキュメントに関してコメントを行いたい場合には、public-rdf-comments@w3.org(購読、アーカイブ)にお送りください。どのようなコメントでも歓迎します。
ワーキンググループの実装報告書を参照してください。
このドキュメントは、W3Cメンバー、ソフトウェア開発者、他のW3Cグループ、および他の利害関係者によりレビューされ、W3C勧告として管理者の協賛を得ました。これは確定済みドキュメントであり、参考資料として用いたり、別のドキュメントで引用することができます。勧告の作成におけるW3Cの役割は、仕様に注意を引き付け、広範囲な開発を促進することです。これによってウェブの機能性および相互運用性が増強されます。
このドキュメントは、2004年2月5日のW3C特許方針の下で活動しているグループによって作成されました。W3Cは、このグループの成果物に関連するあらゆる特許の開示の公開リストを維持し、このページには特許の開示に関する指示も含まれています。不可欠な請求権(Essential Claim(s))を含んでいると思われる特許に関して実際に知っている人は、W3C特許方針の6項に従って情報を開示しなければなりません。
Notes
この形式の注記は、2004年のRDF 1.0セマンティクスからの変更を示します。
この形式の注記は、不明確または難解な問題に関する技術的なトピックです。
1. はじめに
このドキュメントは、RDFグラフおよびRDFとRDFSの語彙のモデル理論セマンティクスを定義しており、RDFの変換や他のRDFからRDFコンテンツを導き出すオペレーションによって真偽がいつ保持されるかに関する正確な形式的仕様を提供しています。
3. セマンティックの拡張と含意レジーム
RDFは、OWL[OWL2-OVERVIEW]、RIF[RIF-OVERVIEW]などの様々な拡張表記に対する基礎的な表記法として用いることを目指しており、特別に定義された意味を有する特別な語彙を用いたRDFグラフとしてその表現をエンコードできます。さらに、他の仕様や規定によって特定のIRIの語彙に意味を与えることができます。そのような追加の意味が仮定される場合、RDFグラフは、基礎的なRDFセマンティクスによって認められているよりも広い範囲の含意をサポートできます。一般的に、RDFグラフでIRIの意味に関して仮定が行われれば行われるほど、それらの仮定からより多くの含意が得られます。
そのような特定のセマンティックの仮定を、セマンティックの拡張と呼びます。個々のセマンティックの拡張は、その拡張の下で有効な含意の含意レジーム(ここでは、SPARQL 1.1含意レジーム勧告[SPARQL11-ENTAILMENT]と同じ意味で用いられている)を定義します。このドキュメントで後ほど述べるRDFSは、このようなセマンティックの拡張の1つです。このドキュメントでは、含意レジームを、RDFS含意、D-含意などの名前で呼びます。
セマンティックの拡張は、あるトリプルが存在することを要求したり、トリプルにおける特定のIRIの結合を禁止するなど、RDFグラフに特別な構文条件や制限を課すことができ(MAY)、これらの条件に一致しないRDFグラフをエラーとみなすことができます(MAY)。例えば、
ex:a rdfs:subClassOf "Thing"^^xsd:string .
という形式のRDFステートメントは、記述論理[OWL2-SYNTAX]に基づくOWLのセマンティックの拡張では禁止されています。そのような場合には、トリプルのサブセットをとるなどの基礎的なRDFオペレーションや、RDFグラフの結合により、拡張条件を認識するパーサにおいて構文エラーが生じるかもしれません。このドキュメントでは規範的に定義しているセマンティックの拡張は、そのような構文上の制限をRDFグラフに課しません。
拡張の構文条件が満たされている場合には、AがBを単純含意していれば、含意の拡張概念下ではAはBも含意するという意味で、すべての含意レジームは、このドキュメントで記述している単純含意レジームを単調に拡張したものでなければなりません(MUST)。言い換えれば、セマンティックの拡張は、結果を構文エラーとして扱うことはできますが、より弱い含意レジームによって作られた含意を「取り消す」ことはできません。
4. 表記法と用語
このドキュメントは、すべて関連するRDF概念仕様で定義されているとおりに[RDF11-CONCEPTS]RDFグラフ構文の記述に、IRI、RDFトリプル、RDFグラフ、主語、述語、目的語、RDF情報源、ノード、空白ノード、リテラル、同形、RDFデータセットという用語を用います。このドキュメントのすべての定義は、そのまま一般化RDFトリプル、グラフおよびデータセットに当てはまります。
解釈は、IRIとリテラルから集合へのマッピングで、集合とマッピングに対するいくつかの制約が伴います。このドキュメントは、解釈の様々な概念を定義しており、そのそれぞれが標準的な方法で含意レジームに対応しています。これらは、単純解釈などの接頭辞で識別され、それらは後の項で定義しています。解釈という修飾のない用語は、一般的に、何らかの互換性を有する類の解釈を意味するために通常用いられますが、コンテキストから明確な場合には、特定の種類の解釈を意味することもあります。
表すおよび参照するという言葉は、IRIまたはリテラルと、それがある解釈において参照するもとの関係の同意語として交換できる形で用いられ、それ自身は指示や指示対象と呼ばれます。IRIの意味は、RDFセマンティクスの外部にある他の制約によっても決定できます。そのような外部で定義された指定の関係を参照したい場合には、識別するという単語とその同語源語を用います。例えば、http://www.w3.org/2001/XMLSchema#decimalというIRIを、XMLスキーマ・ドキュメント[XMLSCHEMA11-2]のデータ型名として広く用いるという事実を、IRIがそのデータ型を識別すると述べることで記述するかもしれません。IRIは、それが何かを識別している場合、セマンティクスの規定方法次第で、ある解釈においてそれを参照していることも参照していないこともありえます。例えば、RDFデータセット内の名前付きグラフを識別するグラフ名として用いられているIRIは、それが識別するグラフとは違うものを参照することがありえます。
このドキュメントの全体にわたり、等号(=)は、厳密な同一性を示します。「A = B」というステートメントは、「A」と「B」の両方の表現が参照する1つのエンティティーが存在することを意味します。山括弧(< x, y >)は、x、yの順序の対を示すために用いられます。
このドキュメントの全体にわたり、RDFグラフとその他のRDF抽象構文のフラグメントは、Turtle構文[TURTLE]の表記法の規定を用いて記述しています。[RDF11-CONCEPTS]の1.4項と同様に、rdf:、rdfs:、xsd:という名前空間接頭辞を用いています。正確なIRIが重要でない場合には、ex:という接頭辞を用います。一般的な規則や条件について述べる時には、aaa、xxx、sssなどの3文字の変数を用いて任意のIRI、リテラルまたはRDF構文のその他の構成要素を表します。グラフ構造を直接表したノード―アークの図によって表す場合もあります。
名前は、IRIまたはリテラルです。型付きリテラルには、自身とその内部の型のIRIの2つの名前が含まれます。語彙は、名前の集合です。
空のグラフは、トリプルの空集合です。
RDFグラフのサブグラフは、グラフ内のトリプルのサブセットです。トリプルは、それを含んでいるシングルトンの集合とみなされるため、グラフ内の個々のトリプルはサブグラフであるとみなされます。真部分グラフは、グラフ内のトリプルの真部分集合です。
基底RDFグラフは、空白ノードが含まれていないグラフです。
Mが空白ノードの集合から、リテラル、空白ノードおよびIRIのある集合への機能的なマッピングであると仮定してください。グラフG内の空白ノードNの一部またはすべてをM(N)に置き換えることによりグラフGから得られるグラフはGのインスタンスです。あらゆるグラフは自身のインスタンスであり、GのインスタンスのインスタンスはGのインスタンスであり、HがGのインスタンスであれば、H内のすべてのトリプルは、Gの少なくとも1つのトリプルのインスタンスです。
語彙Vに関するインスタンスとは、元の空白ノードの代わりに用いられたインスタンスのすべての名前がVからの名前であるインスタンスです。
グラフの真のインスタンスとは、空白ノードが名前で置き換えられた、あるいは、グラフの2つの空白ノードがインスタンスの同じノードにマッピングされたインスタンスです。
2つのグラフは、それぞれが空白ノードにおいて1:1のマッピングでもう一方にマッピングされていれば、同型です。同型のグラフは、可逆のインスタンス・マッピングを有する相互に同等なインスタンスです。空白ノードはグラフ内のその位置以外では特定のアイデンティティーを持たないため、しばしば同型のグラフは同一のものとして扱われます。
RDFグラフが、自身の真部分グラフであるインスタンスを持っていなければ、それは簡潔(lean)です。簡潔でないグラフには内部余剰があり、簡潔なサブグラフと同じ内容を表します。例えば、次のグラフ
ex:a ex:p _:x .
_:y ex:p _:x .
は、簡潔ではありませんが、
ex:a ex:p _:x .
_:x ex:p _:x .
は簡潔です。基底グラフは簡潔です。
4.1 共通の空白ノード、和集合と併合
グラフは、異なるRDFグラフ間の空白ノードの共有を明示したドキュメントやその他の構造(RDFデータセットなど)で記述されているグラフからそのグラフが得られる場合にのみ、空白ノードを共有します。ウェブ・ドキュメントをダウンロードするだけでは、その結果得られるRDFグラフの空白ノードが、同じドキュメントを別途ダウンロードしたり、同じRDF情報源から得られた空白ノードと同じであることにはなりません。
空白ノード識別子を用いたRDF具象構文を扱うRDFアプリケーションは、それが識別する空白ノードのアイデンティティーの状況を注意して把握すべきです。空白ノード識別子は、ローカルな範囲を持っていることが多いため、異なる情報源のRDFを組み合わせる時に、別々の空白ノードが誤ってまとめられてしまうことを避けるために識別子を変更しなければならないかもしれません。
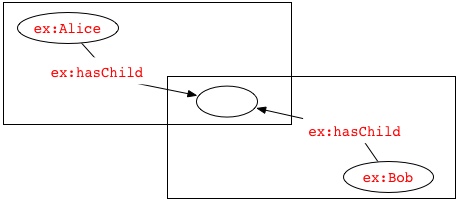
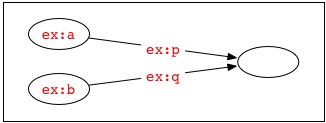
例えば、1つの空白ノードを識別するために、2つのドキュメントが両方とも「_:x」という空白ノード識別子を用いることがありますが、これらのドキュメントが、共通の識別子の範囲になかったり、共通の情報源に由来するものでない場合には、1つのドキュメント内の「_:x」の存在は、もう一方のドキュメントで記述されているグラフのものとは異なる空白ノードを識別するでしょう。複数の情報源のRDFを組み合わせてグラフが作られている場合、別のドキュメントにはない他の識別子に置き換えて、空白ノード識別子を別々に標準化する必要があるかもしれません。例えば、次の文で表される2つのグラフ
ex:a ex:p _:x .
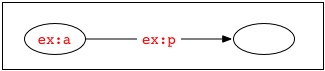
ex:b ex:q _:x .
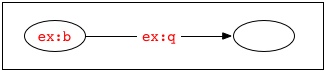
には、4つのノードが含まれています。したがって、これらの和集合には、さらに4つのノードが含まれます。
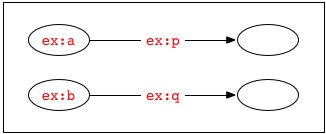
しかし、これらの文の表面的な表現を単純に連結して作成された次のドキュメント
ex:a ex:p _:x .
ex:b ex:q _:x .
は、次の3つのノードが含まれるグラフを表します。
これは、共通する識別子の範囲にある「_:x」という2つの空白ノード識別子が同じ空白ノードを識別するためです。これらの2つのグラフの4つのノードの和集合は、下記のような表層形式でより適切に記述できます。
ex:a ex:p _:x1 .
ex:b ex:q _:x2 .
ここでは、別々の空白ノードがまとめられることを避けるために、空白ノード識別子を別々に標準化しています。(使用している特定の空白ノード識別子は重要ではなく、別個なだけです。)
2つ以上のグラフは、例えば、それらが1つのより大きなグラフのサブグラフであったり、共通の情報源に由来していれば、1つの空白ノードを共有できます。そのとき、1組のグラフの和集合は、グラフ間で共有されていた空白ノードのアイデンティティーを保持しています。一般的に、それらが空白ノードを共有していてもいなくても、1組のRDFグラフの和集合は、グラフ自身と同じセマンティックの内容を正確に表します。
併合(merging)と呼ばれる関連するオペレーションは、共通の空白ノード(それらは2つ以上のグラフに出現する)が個々のグラフにおいて別のものであることを強制した後に和集合を作成します。その結果作成されるグラフを併合(merge)と呼びます。グラフのサブグラフの併合は、元のグラフより大きくなりえます。例えば、次のような、3つのノードのグラフの2つのシングルトンのサブグラフ
を併合した結果は、4つのノードのグラフになります。
和集合は常に併合のインスタンスです。共通する空白ノードがグラフになければ、その併合と和集合は同一です。
5. 単純解釈
この項では、RDFグラフの単純解釈と真偽に関する基礎概念を定義します。RDFでエンコードされる語彙や高レベルの表記法のすべてのセマンティックの拡張は、この最小限の真偽条件に従わなければなりません(MUST)。他のセマンティックの拡張では、これを拡張したり追加したりできますが、修正したり無効にしてはなりません(MUST NOT)。例えば、単純解釈はIRIに適用されるマッピングであるため、セマンティックの拡張は、1つのIRIの異なる存在を異なるものとして解釈することはできません。
すべてのセマンティクスはRDF情報源ではなくRDFグラフに適用されます。RDF情報源は、ある時間や状況においてその値であるグラフによってのみセマンティックな意味を持っています。グラフは、時間によってそのセマンティクスを変えることはできません。
単純解釈Iは、次のもので構成される構造です。
単純解釈の定義
| 1. Iの定義域(domain)や論議領域(universe)と呼ばれる、資源の空でない集合IR
2. Iのプロパティーの集合と呼ばれる、集合IP
3. IPからIR x IRのべき集合(つまり、IRにおけるxとyとの対< x, y >の集合の集合)へのマッピングIEXT
4. IRIから(IR union IP)へのマッピングIS
5. リテラルからIRへの部分的なマッピングIL |
2004年のRDF 1.0セマンティクスでは、語彙に対する単純解釈を定義しました。
2004年のRDF 1.0セマンティクスでは、ILは、部分的ではなく全体的なマッピングでした。
2004年のRDF 1.0仕様では、リテラルを、型やオプションの言語タグのない「プレーンな」リテラルと型付きリテラルとに分けていました。利用してみると、すべてのリテラルに型があることが重要であると判明しました。RDF 1.1では、言語タグのないプレーン・リテラルを、XMLスキーマのstringデータ型を付与したリテラルに置き換え、rdf:langStringという特別な型を言語タグ付き文字列に導入しました。型付きリテラルに対する完全なセマンティクスについては、次の項で示しています。
単純解釈では、すべての名前を解釈する必要があり、したがって、無限です。これにより、表示が単純化されます。しかし、RDFは有限の構造を用いて解釈でき、決定可能なアルゴリズムをサポートします。詳細については付録Bで示します。
IEXT(x)は、xの外延(extension)と呼ばれ、プロパティーが真である引数を識別する1組の対、すなわち2項関係の外延です。
下記のように、データ型のセマンティクスが定義されている時にはIRとILの違いが重要になるでしょう。一部のリテラルは指示対象を持たないことができるため、ILは、部分的であることが認められています。
関係名を関係の外延に直接マッピングする規定になっています。しかし、これは、語彙が関係名と個体名に分離されていることを前提しており、RDFはそのような仮定をおこないません。さらに、RDFでは、IRIを自身に引数として適用した関係名として用いることが認められています。例えば、そのような自己適用構造は、RDFSで用いられます。目的語としての関係と、その関係の外延とを区別するためにIEXTマッピングを用いると、これらの両方の要件に適合します。さらに、それによって、その集合論の拡張を区別できるRDFS「クラス」の概念も提供されます。同様の技術がISO/IECの共通ロジック標準[ISO24707]で用いられています。
そして、単純解釈Iでの基底RDFグラフの指示は、次の規則に基づいて与えられ、そのとき、その解釈は表現(名前、トリプル、グラフ)から論議領域の要素と真偽値への関数としても扱われます。
基底グラフのセマンティック条件
| Eがリテラルであれば、I(E) = IL(E)である |
| EがIRIであれば、I(E) = IS(E)である |
Eが基底トリプルs p o.であり、
I(p)がIPにあり、対<I(s),I(o)>がIEXT(I(p))にあれば、I(E) = 真であり、
さもなければI(E) = 偽である |
| Eが基底RDFグラフであり、EのあるトリプルE'に対してI(E') = 偽であれば、I(E) = 偽であり、さもなければI(E) = 真である |
IL(E)が、あるリテラルEに対して定義されていなければ、Eはセマンティックな値を持っていないため、それを含んでいるトリプルは偽(false)となり、したがって、そのトリプルを含んでいる任意のグラフも偽になります。
最後の条件は、空のグラフ(トリプルの空の集合)が常に真であることを示します。
集合IPとIRは重複可能で、実際にIPはIRのサブセットになりえます。IEXTの定義域の条件のため、真のトリプルの主語と目的語の表示はIRに含まれるでしょう。そのため、グラフに述語としても、主語または目的語としても出現するIRIは、IPとIRの積集合内の何かを示すでしょう。
セマンティックの拡張は、一部のIRIが特定の方法で参照することを要求することにより、解釈マッピングに追加の制約を課するかもしれません。例えば、下記で述べているD-解釈は、一部のIRI(データ型を識別し参照すると理解されている)が、固定の指示を持つことを必須としています。
5.1 空白ノード
空白ノードは、特定の事物を識別するためにIRIを用いず、事物の存在をシンプルに示すものとして扱われます。これは、空白ノードが「未知の」IRIを示すと想定することと同じではありません。
Iが単純解釈であり、Aが空白ノードの集合からIの領域IRへのマッピングであると仮定します。マッピング[I+A]を、名前ではI、その集合の空白ノードではAと定義します。xが名前である場合には[I+A](x)=I(x)で、xが空白ノードである場合には[I+A](x)=A(x)であり、このマッピングを、基底グラフに対し上記で示した規則を用いて、トリプルとRDFのグラフに拡張してください。そうすると、RDFグラフのセマンティック条件は次のとおりです。
空白ノードのセマンティック条件
| EがRDFグラフであり、Eの空白ノードの集合からIRへのあるマッピングAに対して[I+A](E) = 真であれば、I(E) = 真であり、さもなければ、I(E)=偽である |
真偽条件は、何らかのそのようなマッピングのみしか参照しないため、空白ノードから指示対象へのマッピングは単純解釈の定義の一部ではありません。空白ノードは、単純解釈による指示を割り当てられないという点で他のノードとは異なっており、それは、それ自身が「グローバルな」意味を持っていないということを直観的に表します。
5.2 単純含意
標準的な用語に従い、I(E)=真である場合、IはEを(単純に)満足すると述べ、それを満足する単純解釈が存在する場合、Eは(単純に)満足でき、そうでなければ(単純に)満足できないと述べ、Gを満足するすべての解釈がEをも満足する場合、グラフGはグラフEを単純含意すると述べることができます。2つのグラフEとFが、それぞれにもう一方を含意する場合、それらは論理的に同等です。
後の項で、これらの概念を他のクラスの解釈に適用しますが、この項では、全体的に「含意」は単純含意を意味すると解釈すべきです。
このドキュメントでは、グラフの集合間の含意の概念は定義していません。グラフの集合がグラフを含意するかどうかを判断するためには、そのグラフの和集合または併合をとることにより、最初にその集合のグラフを1つのグラフに結合させなければなりません。併合は空白ノードの共有を事実上無視しますが、和集合は、共有されている空白ノードの共通する意味を保持します。グラフの集合を併合すると、2004年のRDF 1.0仕様で定義されていた集合に基づく含意と同じ定義が生成されます。
他のあるグラフSからグラフEを構築するプロセスは、どのような場合でもSがEを単純含意する場合には(単純に)有効で、そうでない場合には無効です。
推論が有効であるという事実は、RDFアプリケーションが推論を行うことを義務付けられたり要求されることを意味すると理解すべきではありません。同様に、あるRDFの変換や処理の論理的な無効性は、プロセスが不正であることや禁止されていることを意味しません。この仕様では、RDFグラフや情報源に特定のオペレーションを要求したり禁止したりすることはありません。含意と有効性は、真偽の保持を保証するようなオペレーションの条件の確立にもっぱら関係があります。論理的に無効なプロセス(有効な含意に従っていない)は禁止されていませんが、真であるRDFデータに偽りを導入してしまう危険性がありえることを知っているべきです。しかし、論理的に無効なプロセスの特定の使用は正当化され、他の手段によって真偽が保証される状況下のデータ処理に適しているもしれません。
含意は、RDFグラフの真偽のみを示すものであり、その他の目的の適応性を示すものではありません。RDFグラフは、定められた目的に適合していながらも、同じ目的に適していない別のグラフを有効的に含意することができます。ひとつの例は、ユーザの利便性のためにRDFドキュメントとして提供されているRDFテスト・ケース・マニフェスト[RDF-TESTCASES]です。このドキュメントは、前提と結論を記述することにより、正しい含意の例を掲載しています。マニフェストは、RDFグラフであると見なされ、前提を省略したサブグラフを単純含意するため、テスト・ケース・マニフェストとして用いるのは正しくないでしょう。これはRDFのセマンティックな規則に違反するものではなく、「正しいRDFテスト・ケース・マニフェストである」プロパティーがRDF含意下では保持されず、したがって、RDFのセマンティックの拡張として記述できないことを示します。このような、含意にリスクを伴うRDFの使用は、ウェブでのオープンなデータの公開にRDFを用いるという、より一般的なケースとは異なり、ここで示しているような、含意に対して意図されている特別な制限がどんなものであるかがすべての関係者に明らかであるようなケースに制限されるべきです。
7. リテラルとデータ型
2004年のRDF 1.0仕様では、データ型D-含意は、RDFS-含意のセマンティックの拡張と定義されていました。ここではそれを、基礎的なRDFに対する直接的な拡張と定義しています。これは実際の利用とより一致しており、データ型を有するRDFは、RDFS語彙なしに広く用いられています。2004年のRDF 1.0の用語とこれを区別する必要がある場合、「D含意」ではなく、「単純D-含意」や「単純データ型含意」というより長い表現を用いるべきです。
データ型はIRIで識別されます。解釈は、どのIRIがデータ型を示していると認識されるかによって変わるでしょう。これは単純解釈でパラメータDを用いて記述され、そのとき、Dは認識されたデータ型IRIの集合です。
この仕様の前バージョンでは、パラメータDを、IRIからデータ型へのデータ型マップとして、つまり、制限のある解釈マッピングの一種として定義していました。現在のセマンティクスは、認識されたIRIは一意のデータ型を識別すると仮定するため、IRIからデータ型へのこのマッピングは、グローバルに一意で、外部で指定されます。したがって、Dを、IRIの集合か固定のデータ型マップのどちらかと見なすことができます。形式的には、集合Dに対応するデータ型マップは、集合Dに対するD解釈の制限です。データ型マップの条件に関して述べられているセマンティックの拡張は、このマッピングに当てはまると解釈できます。
IRIがデータ型を識別する正確なメカニズムは、セマンティクスの外部にあると考えられますが、セマンティクスは、認識されたIRIはそれがどこで出現しようとも一意のデータ型を識別すると考えます。どのデータ型がIRIで識別されているかを決定できないRDFプロセッサはそのIRIを認識できず、そのIRIをそれらのデータ型IRIとして持つリテラルを未知の名前として扱うべきです。
RDFリテラルとデータ型については、[RDF11-CONCEPTS]の5項で完全に記述しています。それを要約すると、1つの例外を除いて、RDFリテラルは文字列とデータ型を識別するIRIとを組み合わせます。その例外とは、言語タグ付き文字列で、これには文字列と言語タグという2つの構文要素があり、rdf:langStringという型が割り当てられています。データ型は、字句から値へのマッピングと呼ばれる、字句空間(文字列の集合)から値への部分的なマッピングを定義すると理解されます。関数L2Vは、データ型をその字句から値へのマッピングにマッピングします。データ型dを持つリテラルは、このマッピングを文字列sssに適用することにより得られた値を表します: L2V(d)(sss)。リテラルの文字列が字句空間にない場合には、字句から値へのマッピングはリテラルの文字列に値を提供せず、そのリテラルには指示対象がありません。データ型の値空間は、字句から値へのマッピングの範囲です。その型を有するすべてのリテラルは、型の値空間にある値を参照するか、まったく参照できないかのどちらかです。不正な型のリテラルとは、そのデータ型IRIは認識されているけれども、そのデータ型に対する字句から値へのマッピングにより、その文字列に値が割り当てられないものです。
RDFプロセッサは、rdf:langStringとxsd:string以外のデータ型IRIを認識することを求められませんが、[RDF11-CONCEPTS]の5項に掲載されているIRIが認識されたものであれば、それらは、そこで記述されているとおりに解釈されなければならず(MUST)、rdf:PlainLiteralというIRIが認識されたものであれば、[RDF-PLAIN-LITERAL]で定義されているデータ型を参照すると解釈されなければなりません(MUST)。RDFプロセッサは、他のデータ型IRIを認識できます(MAY)が、他のデータ型IRIが認識されたものであれば、それが参照するデータ型IRIとデータ型の間のマッピングは、明確に指定されなければならず(MUST)、すべてのRDFの変換や操作の間に固定されなければなりません(MUST)。実際には、これはデータ型自身のコンポーネントと、IRIがデータ型を識別するという事実の両方を記述したデータ型の外部仕様にIRIをリンクすることにより達成でき、それによって、このIRIのデータ型マップの値が固定されます。
rdf:langStringをデータ型として持つリテラルは、特別な対応がとられる例外的なケースです。rdf:langStringというIRIは、データ型IRIと分類され、それに対してL2Vマッピングが定義されなくても、データ型を参照すると解釈されます。rdf:langStringの値空間は、言語タグを持つすべての対の文字列の集合です。これを型として持つリテラルのセマンティクスを下記で示しています。
RDFリテラルの構文では、データ型の参照として認識されていない場合でも、型付きリテラルに任意のIRIを用いることが許されています。そのような「未知の」データ型IRIを持つリテラルは、認識されたデータ型の集合には含まれておらず、RDFアプリケーションは警告を出すことができます(MAY)が、エラーとして扱うべきではありません(SHOULD NOT)。そのようなリテラルは、IRIのように扱い、領域IR内の事物を表すと考えるべきです(SHOULD)。データ型IRIを認識しないRDFプロセッサは、それを認識するプロセッサには見える一部の含意を検知できないでしょう。例えば、
ex:a ex:p "20.0000"^^xsd:decimal .
が
ex:a ex:p "20.0"^^xsd:decimal .
を含意するという事実は、xsd:decimalというデータ型IRIを認識しないプロセッサには見えないでしょう。
7.1 D-解釈
Dを、データ型を識別するIRIの集合とします。(単純)D-解釈は、次の条件を満足する単純解釈です。
テータ型付きリテラルのセマンティック条件
rdf:langStringがDにあれば、字句形式sssと言語タグtttを持つすべての言語タグ付き文字列Eに対しIL(E)= < sss>であり、そのとき、ttt'はUS-ASCIIの規則を用いて小文字に変換されたtttである。 |
| Dの他のすべてのaaaというIRIに対し、I(aaa)は、aaaで識別されるデータ型で、すべての"sss"^^aaaというリテラルに対し、IL("sss"^^aaa) = L2V(I(aaa))(sss)である。 |
リテラルが不正な型であれば、L2V(I(aaa))マッピングには値がありません。その結果、リテラルは何も表すことができません。この場合、そのリテラルを含んでいるトリプルは偽でなければなりません。したがって、不正な型のリテラルを含んでいるトリプル(したがって、グラフ)は、D-不満足、つまり、すべてのD-解釈において偽でしょう。これは、Dにおいて認識されたデータ型IRIで型付けされたリテラルにのみ当てはまり、認識されていない型のIRIを持つリテラルは不正な型ではなく、D-不満足なグラフを生成することはできません。
特別なデータ型rdf:langStringには不正な型のリテラルはありません。この型を持つ正当な構文のリテラルは、Dにrdf:langStringが含まれているすべてのD-解釈の値を表すでしょう。xsd:stringという型の唯一不正な型のリテラルは、[XML10]のChar生成規則と一致しないUnicodeコードポイントが含まれているものです。このような文字列は、XML互換の表層構文で書くことができません。
2004年のRDF 1.0仕様では、不正な型のリテラルはIRの値を表す必要があり、RDFSセマンティクスの使用によってのみ、D-不満足を認識できます。
7.2 データ型含意
グラフがあるD-解釈で真の値を持っている場合、それは(単純に)D-満足であるかDを認識して満足でき(satisfiable recognizing D)、グラフSは、Sを満足するすべてのD-解釈がGもD-満足する場合に、(単純に)グラフGをD-含意するか、Dを認識して含意(entails recognizing D)します。
単純解釈の場合とは異なり、グラフが満足するD-解釈を持たない、つまり、D-不満足であることができます。RDFプロセッサは、不満足なグラフを、エラー状態を示すものとして扱うことができます(MAY)が、これは必須ではありません。
D-不満足なグラフは、あらゆるグラフをD-含意します。
不満足なステートメントがその他のステートメントも含意するという事実は、大昔からずっと知られています。これは、ex falso quodlibet(偽の前提からはいかなる結論も導出できる)の原理と呼ばれます。これは、実際に不満足なグラフから結論を導き出すことが必要であるとか許されさえすることを意味すると解釈すべきではありません。
この言語のすべてにおいて、「D」はデータ型IRIのある集合を表すためのパラメータとして用いられており、異なるD集合は、異なる概念の充足可能性と含意を生成するでしょう。データ型が認識されていればいるほど含意は強くなり、その結果、D ⊂ Eであり、SがGをE-含意する場合、SはGをD-含意しなければなりません。単純含意は、{ }-含意(つまり、Dが空集合である場合にD-含意)であるため、SがGをD-含意する場合、SはGを単純含意します。
8. RDF解釈
RDF解釈は、xsd:stringと、名前空間接頭辞rdf:を持つIRIの無限集合の一部に追加のセマンティック条件を課します。
| RDF語彙 |
rdf:type rdf:subject rdf:predicate rdf:object rdf:first rdf:rest rdf:value rdf:nil rdf:List rdf:langString rdf:Property rdf:_1 rdf:_2 ... |
Dを認識するRDF解釈は、Dにrdf:langStringとxsd:stringが含まれる場合に、D-解釈Iで、それは次を満足します。
RDFのセマンティック条件
<x, I(rdf:Property)>がIEXT(I(rdf:type))にある場合に限り、xはIPにある |
xがI(aaa)の値空間にある場合にのみ、すべてのDのIRI aaaに対し、< x, I(aaa) >はIEXT(I(rdf:type))にある |
そして、これは、次の無限集合のすべてのトリプルを満足します。
RDF公理
rdf:type rdf:type rdf:Property .
rdf:subject rdf:type rdf:Property .
rdf:predicate rdf:type rdf:Property .
rdf:object rdf:type rdf:Property .
rdf:first rdf:type rdf:Property .
rdf:rest rdf:type rdf:Property .
rdf:value rdf:type rdf:Property .
rdf:nil rdf:type rdf:List .
rdf:_1 rdf:type rdf:Property .
rdf:_2 rdf:type rdf:Property .
...
|
RDFは、残りのRDF語彙に特別の規範的な意味を課しません。付録Dでは、この語彙の一部の用途について記述しています。
rdf:langStringおよびxsd:stringというデータ型IRIは、すべてのRDF解釈によって認識されなければなりません(MUST)。
rdf:XMLLiteralおよびrdf:HTMLのその他の2つのデータ型は、[RDF11-CONCEPTS]で定義されています。RDF-D解釈は、これらのデータ型を認識できなくてもかまいません(MAY)。
8.1 RDF含意
Sは、Sを満足するDを認識するすべてのRDF解釈がEも満足する場合にDを認識してEをRDF含意します。Dが{rdf:langString, xsd:string}であれば、我々はSがEをRDF含意すると単純に述べます。(Dを認識して)満足するRDF解釈がなければ、Eは(Dを認識して)RDF不満足です。
前記の単純含意の特性は、必ずしもRDF含意には当てはまりません。例えば、すべてのRDF公理は、すべてのRDF解釈において真であり、したがって、空のグラフによってRDF含意され、RDF含意の補間と矛盾します。
9. RDF解釈
RDFスキーマ[RDF11-SCHEMA]は、RDFをより複雑なセマンティック条件を有するより大きな語彙に拡張します。
| RDFS語彙 |
rdfs:domain rdfs:range rdfs:Resource rdfs:Literal rdfs:Datatype rdfs:Class rdfs:subClassOf rdfs:subPropertyOf rdfs:member rdfs:Container rdfs:ContainerMembershipProperty rdfs:comment rdfs:seeAlso rdfs:isDefinedBy rdfs:label |
(rdfs:comment、 rdfs:seeAlso、rdfs:isDefinedByおよびrdfs:labelは、これらの使用に適用されるいくつかの制約をrdfs:domain、 rdfs:rangeおよびrdfs:subPropertyOfを用いて述べることができるため、ここに含まれています。これ以外には、形式意味論はこれらの意味を制限しません。)
classという新しいセマンティックの構成子(つまり、論議領域内の事物の集合を表す資源で、そのすべてがrdf:typeプロパティーの値としてそのクラスを持っている)でRDFSセマンティクスを述べると便利です。クラスはrdfs:Classという型の事物であると定義されており、解釈のすべてのクラスの集合はICと呼ばれるでしょう。セマンティックな条件は、ICからIRのサブセットの集合への(Iのクラスの外延(Class Extension)に対する)ICEXTというマッピングで述べられます。
クラスは空のクラスの外延を持つことができます。異なる2つのクラスが同じクラスの外延を持つことができます。rdfs:Classのクラスの外延にはrdfs:Classというクラスが含まれます。
(Dを認識した)RDFS解釈は、次の表のセマンティック条件と、その次のRDFS公理トリプルの表のすべてのトリプルを満足する(Dを認識した)RDF解釈Iです。
RDFSのセマンティック条件
ICEXT(y)は{x : < x,y >はIEXT(I(rdf:type))にある}と定義されている。
ICはICEXT(I(rdfs:Class))と定義されている。
LVはICEXT(I(rdfs:Literal))と定義されている。
ICEXT(I(rdfs:Resource)) = IR
ICEXT(I(rdf:langString))は集合{I(E) : E 言語タグ付き文字列}である。
Dの他のすべてのaaaというIRIに対し、ICEXT(I(aaa))はI(aaa)の値空間である。
DのすべてのaaaというIRIに対し、I(aaa)はICEXT(I(rdfs:Datatype)) にある。 |
< x,y >がIEXT(I(rdfs:domain))にあり、< u,v >がIEXT(x)にある場合、uはICEXT(y)にある。 |
< x,y >がIEXT(I(rdfs:range))にあり、< u,v >がIEXT(x)にある場合、vはICEXT(y)にある。 |
IEXT(I(rdfs:subPropertyOf))はIPにおいて推移的で反射的である。 |
<x,y>がIEXT(I(rdfs:subPropertyOf))にある場合、xとyはIPにあり、IEXT(x)はIEXT(y)のサブセットである。 |
xがICにある場合、< x, I(rdfs:Resource) >はIEXT(I(rdfs:subClassOf))にある。 |
IEXT(I(rdfs:subClassOf))はICにおいて推移的で反射的である。 |
< x,y >がIEXT(I(rdfs:subClassOf))にある場合、xとyはICにあり、ICEXT(x)はICEXT(y)のサブセットである。 |
xがICEXT(I(rdfs:ContainerMembershipProperty))にある場合、
< x, I(rdfs:member) >はIEXT(I(rdfs:subPropertyOf))にある。 |
xがICEXT(I(rdfs:Datatype))にある場合、< x, I(rdfs:Literal) >はIEXT(I(rdfs:subClassOf))にある。 |
RDFS公理トリプル
rdf:type rdfs:domain rdfs:Resource .
rdfs:domain rdfs:domain rdf:Property .
rdfs:range rdfs:domain rdf:Property .
rdfs:subPropertyOf rdfs:domain rdf:Property .
rdfs:subClassOf rdfs:domain rdfs:Class .
rdf:subject rdfs:domain rdf:Statement .
rdf:predicate rdfs:domain rdf:Statement .
rdf:object rdfs:domain rdf:Statement .
rdfs:member rdfs:domain rdfs:Resource .
rdf:first rdfs:domain rdf:List .
rdf:rest rdfs:domain rdf:List .
rdfs:seeAlso rdfs:domain rdfs:Resource .
rdfs:isDefinedBy rdfs:domain rdfs:Resource .
rdfs:comment rdfs:domain rdfs:Resource .
rdfs:label rdfs:domain rdfs:Resource .
rdf:value rdfs:domain rdfs:Resource .
rdf:type rdfs:range rdfs:Class .
rdfs:domain rdfs:range rdfs:Class .
rdfs:range rdfs:range rdfs:Class .
rdfs:subPropertyOf rdfs:range rdf:Property .
rdfs:subClassOf rdfs:range rdfs:Class .
rdf:subject rdfs:range rdfs:Resource .
rdf:predicate rdfs:range rdfs:Resource .
rdf:object rdfs:range rdfs:Resource .
rdfs:member rdfs:range rdfs:Resource .
rdf:first rdfs:range rdfs:Resource .
rdf:rest rdfs:range rdf:List .
rdfs:seeAlso rdfs:range rdfs:Resource .
rdfs:isDefinedBy rdfs:range rdfs:Resource .
rdfs:comment rdfs:range rdfs:Literal .
rdfs:label rdfs:range rdfs:Literal .
rdf:value rdfs:range rdfs:Resource .
rdf:Alt rdfs:subClassOf rdfs:Container .
rdf:Bag rdfs:subClassOf rdfs:Container .
rdf:Seq rdfs:subClassOf rdfs:Container .
rdfs:ContainerMembershipProperty rdfs:subClassOf rdf:Property .
rdfs:isDefinedBy rdfs:subPropertyOf rdfs:seeAlso .
rdfs:Datatype rdfs:subClassOf rdfs:Class .
rdf:_1 rdf:type rdfs:ContainerMembershipProperty .
rdf:_1 rdfs:domain rdfs:Resource .
rdf:_1 rdfs:range rdfs:Resource .
rdf:_2 rdf:type rdfs:ContainerMembershipProperty .
rdf:_2 rdfs:domain rdfs:Resource .
rdf:_2 rdfs:range rdfs:Resource .
...
|
2004年のRDF 1.0セマンティクスでは、LVは単純解釈構造の一部として定義されており、ここで示されている定義は制約でした。
IはRDF解釈であるため、最初の条件はIP = ICEXT(I(rdf:Property))を意味します。
RDF解釈のセマンティクス条件は、ICEXTのRDFS条件と合わせて、すべての認識されたデータ型を、その拡張がデータ型の値空間であるクラスとして扱うことができ、そのデータ型を持つすべてのリテラルは参照しないか、そのクラスの値を参照することを意味します。
RDFSセマンティクスを用いる場合、すべての認識されたデータ型IRIの指示対象は、rdfs:Datatypeというクラスにあると考えられます。
上記の公理と条件には、いくぶん重複があります。例えば、RDF公理トリプルの1つを除くすべては、RDFS公理トリプルとICEXTのセマンティック条件、 rdfs:domainとrdfs:rangeから得ることができます。
すべてのRDFS解釈において真でなければならないその他のトリプルには次のものが含まれています。これは完全な集合ではありません。
一部のrdfs-有効のトリプル
rdfs:Resource rdf:type rdfs:Class .
rdfs:Class rdf:type rdfs:Class .
rdfs:Literal rdf:type rdfs:Class .
rdf:XMLLiteral rdf:type rdfs:Class .
rdf:HTML rdf:type rdfs:Class .
rdfs:Datatype rdf:type rdfs:Class .
rdf:Seq rdf:type rdfs:Class .
rdf:Bag rdf:type rdfs:Class .
rdf:Alt rdf:type rdfs:Class .
rdfs:Container rdf:type rdfs:Class .
rdf:List rdf:type rdfs:Class .
rdfs:ContainerMembershipProperty rdf:type rdfs:Class .
rdf:Property rdf:type rdfs:Class .
rdf:Statement rdf:type rdfs:Class .
rdfs:domain rdf:type rdf:Property .
rdfs:range rdf:type rdf:Property .
rdfs:subPropertyOf rdf:type rdf:Property .
rdfs:subClassOf rdf:type rdf:Property .
rdfs:member rdf:type rdf:Property .
rdfs:seeAlso rdf:type rdf:Property .
rdfs:isDefinedBy rdf:type rdf:Property .
rdfs:comment rdf:type rdf:Property .
rdfs:label rdf:type rdf:Property .
|
RDFSは論議領域をクラス、プロパティーおよび個体の素のカテゴリーに分割しません。論議領域のあらゆる事物は、そのステータスを、クラスにあったりプロパティーを持ちえる個体として保持しつつ、クラス、プロパティーまたはこれらの両方として使用できます。したがって、RDFSでは、他のクラス、プロパティーのクラス、クラスのプロパティーなどを含んだクラスが許されています。上記の公理トリプルが示すとおり、自身を含むクラスと、自身に適用されるプロパティーも許されています。クラスのプロパティーは必ずしもそのメンバーのプロパティーではなく、その逆も同様です。
9.2 RDFS含意
Sは、Sを満足するすべてのDを認識するRDFS解釈がEも満足する場合に、Dを認識してEをRDFS含意します。
すべてのRDFS解釈はRDF解釈であるため、SがEをRDFS含意する場合、SはEもRDF含意します。しかし、RDFS含意はRDF含意より強力です。空のグラフでさえ、RDF含意でない多くのRDFS含意を持っています。例えば、次の形式のすべてのトリプル
aaa rdf:type rdfs:Resource .
は、aaaがIRIである場合、すべてのRDFS解釈において真です。
10. RDFデータセット
RDFデータセット(RDF概念[RDF11-CONCEPTS]で定義されている)は、1つの無名のデフォルトRDFグラフと一緒に、0以上の名前付きRDFグラフをパッケージします。1つのデータセット内の複数のグラフは、空白ノードを共有することができます。SPARQL[SPARQL11-QUERY]は、グラフとグラフ名IRIとの関連を用いてクエリを特定のグラフに向けることを可能とします。
データセット内のグラフ名は、それが対となるグラフ以外のものを参照できます。これによって、人などの他の種類のエンティティーを参照するIRIを、グラフ名IRIで示されるエンティティーに関する情報のグラフを識別するために、データセット内で用いることが可能となります。
グラフ名がデータセットのRDFトリプル内で用いられているとき、それは、それが指定しているグラフを参照することも、しないこともあります。外的な理由がなければ、RDFトリプル内で用いられているグラフ名が、それが指定しているグラフを参照することをセマンティクスは要求せず、RDFエンジンもそれを仮定すべきではありません。
RDFデータセットは、RDFの内容を表すために使用できます(MAY)。この方法でデータセットが用いられている場合、そのデフォルト・グラフと少なくとも同じ内容を持つと理解すべきです(SHOULD)。しかし、データセットのデフォルト・グラフを論理上同等なグラフに置き換えることは、例えば、デフォルト・グラフとデータセット内の他のグラフとの間の空白ノードの同時発生を妨害する可能性があるため、一般的に、構造的に類似したデータセットは生成されないだろうということに注意してください。これは、データセット内のグラフのセマンティクス以外の理由から重要かもしれません。
その他のセマンティックの拡張と含意レジームは、RDFグラフと同じく、RDFデータセットにさらにセマンティックな条件と制限を設けることができます(MAY)。例えば、そのような拡張の1つは、データセット間の含意が、同じ名前(求められるような空のグラフを加えて)を持つグラフ間のRDFグラフ含意を要求するように、モーダルのような解釈構造を設定できます。
付録
D. RDF具象化、コンテナおよびコレクション(参考情報)
この項は非規範的です。
RDFのセマンティック条件は、コンテナや有限のコレクションを記述する際の使用を意図した多くのRDF語彙や、RDFグラフがRDFトリプルを記述できるようにすることを意図した具象化語彙の意味に形式的な制約を置きません。この付録では、この語彙の意図する意味を簡潔に概観します。
形式意味論からこれらの条件を省略することは、既存のRDF使用の変更に適応し、形式的なRDF含意をチェックするプロセスの実装をより簡単にするための設計上の決定事項です。例えば、実装においては、特別な手続き型の技術を用いてRDFコレクションの語彙を実装することを決定できます。
D.1 具象化
| RDF具象化語彙 |
rdf:Statement rdf:subject rdf:predicate rdf:object |
この語彙が意図する意味は、RDFグラフが、他のRDFトリプルを記述するメタデータとして機能できるようにすることです。
1つのトリプルが含まれている、次のグラフの例を見てみましょう。
ex:a ex:b ex:c .
そして、このグラフを識別するためにex:graph1というIRIが用いられていると仮定します。この識別が厳密にどのように達成されるかはRDFモデルの範囲外ですが、グラフを記述する具象構文ドキュメントに対するIRI解決、または、データセット内の名前付きグラフの関連する名前であるIRIによるかもしれません。トリプルを参照するためにIRIを使用できると仮定すると、具象化語彙によって、最初のグラフを別のグラフで記述できるようになります。
ex:graph1 rdf:type rdf:Statement .
ex:graph1 rdf:subject ex:a .
ex:graph1 rdf:predicate ex:b .
ex:graph1 rdf:object ex:c .
2番目のグラフは最初のグラフのトリプルの具象化と呼ばれます。
具象化は引用の形式ではなく、トリプルのトークンとトリプルが参照する資源との関係を記述するものです。rdf:subjectプロパティーの値は、主語のIRI自身ではなく、それが示すものであり、rdf:predicateとrdf:objectでも同じです。例えば、ex:aの指示対象がエベレスト山であれば、具象化されたトリプルの主語も、それを参照するIRIではなく、その山です。
具象化は、空白ノードで主語として記述するか、トリプルの具象的な実現物を識別しないIRIの主語として記述することができ、どちらの場合にも、記述されたトリプルの存在をシンプルに言明します。
具象化の主語は、抽象的なオブジェクトとみなされるトリプルではなく、表層構文のドキュメントなどの、RDFトリプルの具象的な実現物を参照することを意図しています。これは、構成の日付や来歴情報などのプロパティーが具象化されたトリプルに適用されるユースケースをサポートしており、それはトリプルの特定のインスタンスやトークンの参照と見なされる時にのみ意味があります。
トリプルの具象化はそのトリプルを含意せず、それによって含意されることもありません。具象化は、トリプルのトークンが存在していることと、それが何なのかを述べるだけで、それが真だとは述べず、したがって、それはトリプルを含意しません。一方、トリプルを言明しても、トリプルによって記述されている論議領域にトリプルのトークンが存在するということを自動的に示唆するわけではありません。例えば、トリプルは動物について記述しているオントロジーの一部かもしれず、それは、論議領域には動物のみが含まれているという解釈によって満足でき、したがって、その具象化は偽でありえます。
任意のRDFグラフまたは複数のグラフのトリプルとトリプルの具象化との関係は、1対1である必要はなく、具象化で記述されたあるエンティティーに関するプロパティーの言明が、同じプロパティーが別のそのようなエンティティーを保持する(同じ構成要素を持っていたとしても)ことを含意する必要はありません。例えば、
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject ex:subject .
_:xxx rdf:predicate ex:predicate .
_:xxx rdf:object ex:object .
_:yyy rdf:type rdf:Statement .
_:yyy rdf:subject ex:subject .
_:yyy rdf:predicate ex:predicate .
_:yyy rdf:object ex:object .
_:xxx ex:property ex:foo .
は、
_:yyy ex:property ex:foo .
を含意しません。
D.2 RDFコンテナ
| RDF(S)コンテナ語彙 |
rdf:Seq rdf:Bag rdf:Alt rdf:_1 rdf:_2 ... rdfs:member rdfs:Container rdfs:ContainerMembershipProperty |
RDFは、3種類のコンテナを記述するための語彙を提供します。コンテナには型があり、そのメンバーはコンテナ・メンバーシップ・プロパティーの固定の集合を用いて列挙できます。これらのプロパティーは、メンバーを互いに区別する方法を提供するために整数でインデックス化されますが、これらのインデックスは必ずしもコンテナ自身の順序を定義していると考えるべきではありません。一部のコンテナは、順序付されていないと考えられます。
RDFS語彙により、位置に関係なく成立する総括的なメンバーシップ・プロパティーと、すべてのコンテナとすべてのメンバーシップ・プロパティーが含まれているクラスが追加されます。
この語彙は、コンテナを構築するためのツールと理解するのではなく、一般的にプログラミング言語で提供されるような、コンテナを記述するものと理解しなければなりません。実際のコンテナはセマンティックな論議領域内のエンティティーであり、語彙を用いるRDFグラフは単にこれらのエンティティーに関する非常に基本的な情報を提供し、それにより、RDFグラフがコンテナ型を示し、コンテナのメンバーに関する部分的な情報を提供することが可能となります。RDFコンテナ語彙は非常に制限されているため、RDFコンテナに関する多くの自然な仮定が、RDF形式意味論では形式的には認められません。これは、これらの仮定が誤りであることを意味するのではなく、単にRDFはそれが真に違いないことを形式的に含意しないと考えるべきです。
コンテナ語彙には特別なセマンティック条件はありません。そのコンテナが持っているとRDFが推定する構造のみが、この語彙の使用と一般的なRDFのセマンティック条件から推論できるものです。要するに、これは、コンテナの型を知るということと、コンテナにアイテムの部分的な列挙があるということです。意図される使用モードは、rdf:Bagという型は順序付けがないが重複が許され、rdf:Seqという型は順序付けされており、rdf:Altという型は選択肢の集合を表し、恐らく優先順位付きであると考えられます。コンテナが順序付きの型であれば、コンテナ内のアイテムの順序はコンテナ・メンバーシップ・プロパティーの番号順(単一値であると思われる)に示されるようになっています。しかし、これらの非形式的な条件は形式的なRDF含意には反映されません。
RDFセマンティクスは、順序付けのないrdf:Bagの要素を異なる順序で列挙することで発生する可能性がある含意をサポートしません。例えば、
_:xxx rdf:type rdf:Bag .
_:xxx rdf:_1 ex:a .
_:xxx rdf:_2 ex:b .
は、
_:xxx rdf:_1 ex:b .
_:xxx rdf:_2 ex:a .
を含意しません。
(この結論が有効であれば、それを元のグラフに追加した結果は、グラフによって含意され、両方の要素が両方の位置にあることを言明するでしょう。これは、RDFが純粋に言明的な言語であるという事実の結果です。)
コンテナのプロパティーがコンテナの要素のどれにも適用され、その逆も成り立つという仮定はできません。
3種類のコンテナが互いに素であるという形式的な要件はないため、例えば、何かがrdf:Bagとrdf:Seqの両方であると言明することには整合性があります。コンテナが隙間がないという仮定はないため、例えば、
_:xxx rdf:type rdf:Seq.
_:xxx rdf:_1 ex:a .
_:xxx rdf:_3 ex:c .
は、
_:xxx rdf:_2 _:yyy .
を含意しません。
RDFには、コンテナに固定数のメンバーのみが含まれていると言明する方法はありません。これは、任意のコンテナのメンバーシップ・プロパティーを言明するグラフに、トリプルを追加しても常に整合性があるという事実を反映しています。そして最後に、RDFコンテナに有限の数のメンバーがあるという既存の仮定はありません。
D.3 RDFコレクション
| RDFコレクション語彙 |
rdf:List rdf:first rdf:rest rdf:nil |
RDFはコレクション記述用の語彙、つまり、head-tailリンクでの「リスト構造」を提供します。コレクションは、分岐構造が可能で、明示的な終端があるという点でコンテナと異なっており、アプリケーションがコレクション内のアイテムの集合を正確に決定できます。
コンテナのように、この語彙には、rdf:nilの型がrdf:Listである以外に、特別なセマンティック条件は課されません。これは、次の形式の2つのトリプル
_:c1 rdf:first aaa .
_:c1 rdf:rest _:c2 .
で個々に記述されている「整形式の」アイテムのシーケンスを接続するために空白ノードを用いてコンテナを記述するような状況における使用を一般的に想定しており、その場合、rdf:restというプロパティーの値としてrdf:nilを用いることで最後のアイテムが示されます。よく知られている慣習では、rdf:nilを空のコレクションと見なすことができます。そのようなグラフは、コレクションが存在するという言明を意味し、コレクションのメンバーは検査によって決定できるため、多くの場合、何が意味されているのかをアプリケーションは十分に決定できます。セマンティクス的には、グラフで明示的に言及されたもの(そして、空のコレクション)以外にコレクションが存在する必要はありません。例えば、2つのアイテムが含まれているコレクションの存在により、交換されたアイテムと同じようなコレクションも存在することが自動的に保証されることはありません。
_:c1 rdf:first ex:aaa .
_:c1 rdf:rest _:c2 .
_:c2 rdf:first ex:bbb .
_:c2 rdf:rest rdf:nil .
は、
_:c3 rdf:first ex:bbb .
_:c3 rdf:rest _:c4 .
_:c4 rdf:first ex:aaa .
_:c4 rdf:rest rdf:nil .
を含意しません。
さらに、RDFはこの語彙の使用に「整形式性」の条件を課さないため、末尾が分岐したり、リストではなかったり、先頭が複数あるリストなどの非常に特殊なオブジェクトの存在を言明するRDFグラフを書くこともできます。
_:666 rdf:first ex:aaa .
_:666 rdf:first ex:bbb .
_:666 rdf:rest ex:ccc .
_:666 rdf:rest rdf:nil .
そのrdf:restプロパティーの値の指定に失敗してコレクションに曖昧さがあるトリプルの集合を書くこともできます。
セマンティックの拡張では、そのようなグラフを排除するために、この語彙の使用に対して、構文上の整形式性の制限を追加できます。それらは、上記の形式の2つのトリプルのアイテムの「リンクした」コレクションの主語(rdf:nilで終わるアイテムで終わる)は、そのメンバーがアイテムのrdf:firstの値を表したものであり、主語からrdf:nilへrdf:restプロパティーを追跡することで得られた順序で完全に順序付けられたシーケンスを表すという規定に違反するコレクション語彙の解釈を排除できます。これにより、他のシーケンスを含んだシーケンスが可能となります。
RDFSのセマンティック条件により、rdf:firstプロパティーの主語およびrdf:restプロパティーの主語または目的語は、rdf:type rdf:Listに属する必要があります。