要約
この入門は、RDFを効果的に利用するために必要な基礎知識を読者に提供することを目指しています。RDFの基本概念を紹介し、RDF利用の具体例を示します。3~5項は、RDFの重要要素に対する必要最低限の入門として使用できます。RDF 1.1とRDF 1.0(2004年のバージョン)の間の変更点については、「RDF 1.1の新機能」[RDF11-NEW
このドキュメントのステータス
この項は、このドキュメントの公開時のステータスについて記述しています。他のドキュメントがこのドキュメントに取って代わることがありえます。現行のW3C の刊行物およびこの技術報告の最新の改訂版のリストは、http://www.w3.org/TR/のW3C 技術報告インデックス
このドキュメントは、RDF 1.1ドキュメント群の一部です。それは、RDFの重要概念に関する参考情報となるメモです。RDF 1.1の規範的な仕様については、読者はRDF 1.1概念および抽象構文ドキュメント[RDF11-CONCEPTS
このドキュメントは、RDFワーキンググループ によってワーキンググループ・ノートとして発表されました。このドキュメントに関してコメントを行いたい場合には、public-rdf-comments@w3.org (購読 、アーカイブ )にお送りください。どのようなコメントでも歓迎します。
ワーキンググループ・ノートとしての公開は、W3C メンバーによる承認を意味するものではありません。これは草案ドキュメントであるため、他のドキュメントによって、随時更新されたり、置き換えられたり、廃止されることもありえます。このドキュメントを「作業中」以外のものとして引用することは適当ではありません。
このドキュメントは、2004年2月5日のW3C 特許方針 の下で活動しているグループによって作成されました。W3C は、このグループの成果物に関連するあらゆる特許の開示の公開リスト を維持し、このページには特許の開示に関する指示も含まれています。不可欠な請求権 (Essential Claim(s))を含んでいると思われる特許に関して実際に知っている人は、W3C 特許方針の6項
1. はじめにRDF(Resource Description Framework)は、資源 に関する情報を表わすための枠組みです。資源は、ドキュメント、人間、物体、抽象的な概念を含む何ものでもありえます。
RDFは、人間に表示するだけではなく、アプリケーションがウェブ上の情報を処理する必要のある状況を目的としています。RDFは、この情報を表現するための共通の枠組みを提供するため、意味を損なわずにアプリケーション間で情報交換が行えます。共通の枠組みであるため、アプリケーションの設計者は共通のRDFパーサや処理ツールを有効利用できます。異なるアプリケーション間で情報交換できるということは、情報が元々作成された以外のアプリケーションでその情報を利用できることを意味します。
RDFはとりわけ、ウェブ上のデータを公開し連結するために使用できます。例えば、http://www.example.org/bob#meを検索すると、ボブに関するデータを提供できます。ボブはアリスのIRI(IRIは「International Resource Identifier」。3.2項 を参照)で識別されるため、これには、ボブが彼女のことを知っているという事実が含まれます。次に、アリスのIRIを検索すると、彼女の友達や関心などに関するその他のデータセットへのリンクを含む、彼女に関するより多くのデータを提供できます。その後、人または自動プロセスが、そのようなリンクをたどって、これらの様々な事物に関するデータを集約できます。RDFのこのような利用は、しばしばリンクト・データ[LINKED-DATA
このドキュメントは規範的ではなく、RDF 1.1を完全に説明するものでもありません。RDFの規範的な仕様は、次のドキュメントで見ることができます。
RDFの基礎となる基本的な概念と抽象構文を記述したドキュメント(「RDF概念および抽象構文」)[RDF11-CONCEPTS
RDFの形式モデル理論セマンティクスを記述したドキュメント(「RDFセマンティクス」)[RDF11-MT
RDFのシリアル化フォーマットの仕様:
RDFスキーマを記述したドキュメント[RDF11-SCHEMA
2. なぜRDFを使用する?下記は、様々な実践コミュニティーを対象としたRDFの様々な異なる用途を説明しています。
例えば、よく知られているschema.org 語彙を用いて、ウェブ・ページに機械可読情報を追加し、改善されたフォーマットでウェブ・ページを検索エンジンに表示したり、サード・パーティーのアプリケーションによる自動処理を可能にする。
サード・パーティーのデータセットにリンクすることによりデータセットを拡充する。例えば、絵に関するデータセットは、Wikidata の対応する芸術家にリンクすることにより拡充することができ、したがって、それらや関連する資源に関する幅広い情報にアクセス可能となる。
APIフィードを連結し、より多くの情報に対するアクセス方法をクライアントが容易に発見できるようにする。
現在公開されているデータセットをリンクト・データ[LINKED-DATA
複数のウェブサイトにわたって人々のRDF記述を連結することにより、分散型のソーシャル・ネットワークを構築する。
データベース間でデータ交換を行うために、標準に準拠した方法を提供する。
組織内の様々なデータセットを連結し、SPARQL[SPARQL11-OVERVIEW
3. RDFデータ・モデル
3.1 トリプルRDFにより、資源について記述することが可能となります。このステートメントの形式はシンプルです。ステートメントは、常に次の構造を持っています。
<主語> <述語> <目的語>
RDFステートメントは、2つの資源の間の関係を表わします。主語 と目的語 は関連付けられる2つの資源を表わし、述語 はこれらの関係の性質を表わします。関係は、方向性を持った方法(主語から目的語への)で表現され、RDFではそれをプロパティー と呼びます。RDFステートメントは3つの要素で構成されるため、トリプル と呼びます。
以下にRDFトリプルの例を示します(非形式的に擬似コードで表現)。
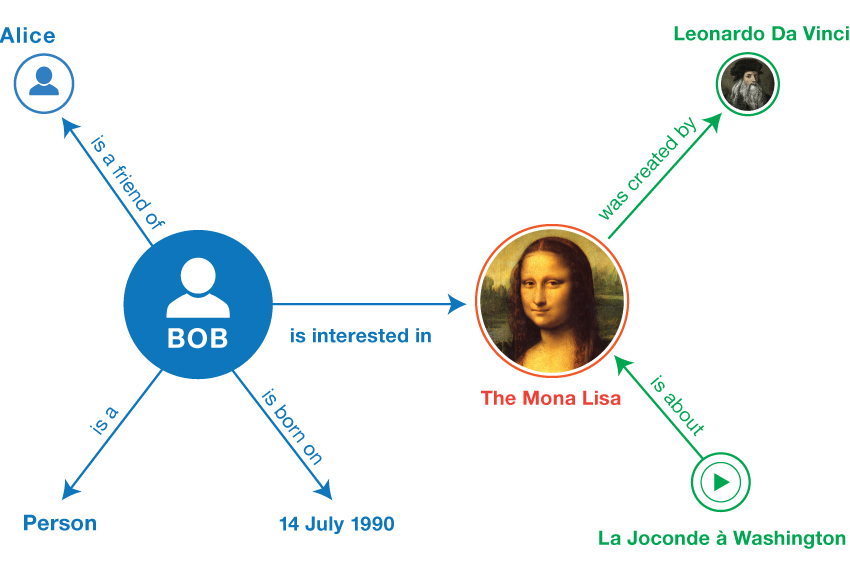
例1 : トリプルの例(非形式的)
<Bob> <is a> <person>.
<Bob> <is a friend of> <Alice>.
<Bob> <is born on> <the 4th of July 1990>.
<Bob> <is interested in> <the Mona Lisa>.
<the Mona Lisa> <was created by> <Leonardo da Vinci>.
<the video 'La Joconde à Washington'> <is about> <the Mona Lisa>
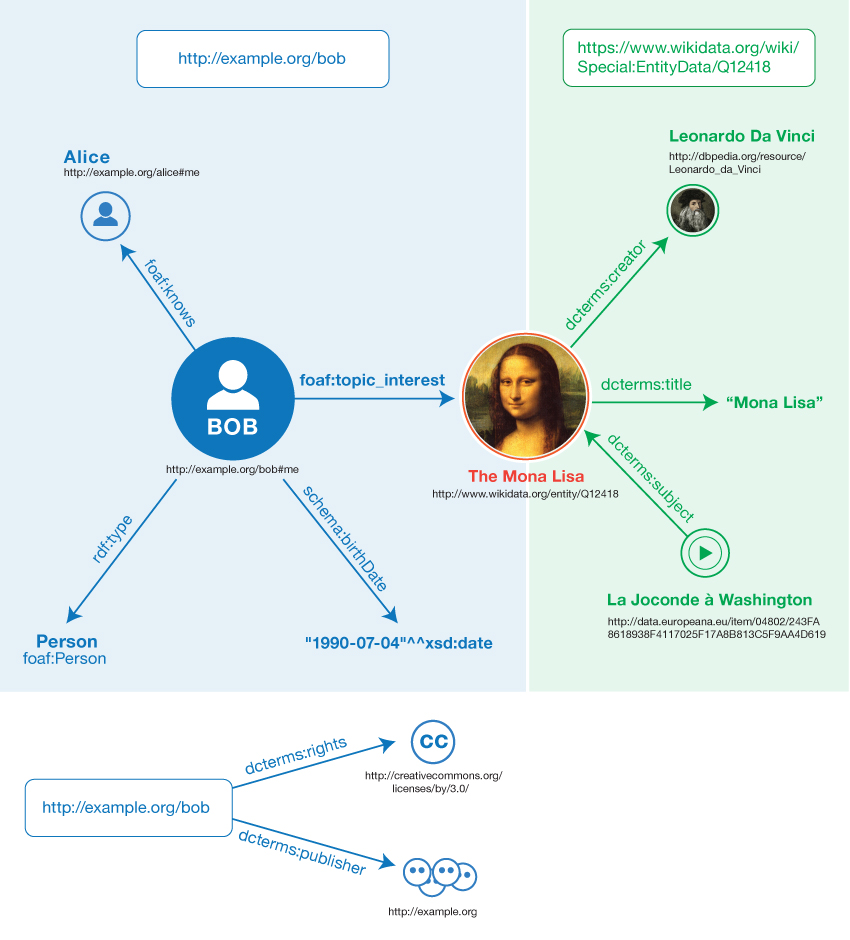
複数のトリプルが同じ資源を参照することがしばしばあります。上の例では、ボブ(Bob)は4つのトリプルの主語で、モナ・リザ(Mona Lisa)は1つのトリプルの主語と2つのトリプルの目的語です。同じ資源を、あるトリプルでは主語の位置に、別のトリプルでは目的語の位置に持つことができるこの能力により、トリプル間の関係性を発見でき、そのことはRDFの能力の重要要素となっています。
トリプルは、連結グラフ として視覚化できます。グラフは、ノードとアークで構成されます。トリプルの主語と目的語はグラフのノードを構築し、述語はアークを形成します。図1 は、上記のトリプルの例を基に作成されるグラフを示します。
図1 トリプルの例の非形式的なグラフ
一度このようなグラフが得られれば、SPARQL[SPARQL11-OVERVIEW
この項では、RDFデータ・モデルは、「抽象構文」、つまり、特定の具象構文(テキスト・ファイルで格納されているトリプルを表わすために用いられる構文)に依存しないデータ・モデルの形式で記述しています。異なる具象構文は、抽象構文から見れば全く同じグラフを生成するかもしれません。RDFグラフ[RDF11-MT 5項 で紹介します。
次の3つの小項目では、IRI、リテラル、空白ノードという、トリプルに現れる3種類のRDFデータについて論じます。
3.2 IRIIRIという略語は「International Resource Identifier」の省略形です。IRI は資源を識別します。Webのアドレスとして用いられているURL(Uniform Resource Locators)は、IRIの1つの形式です。その他のIRIの形式は、その位置や、それにアクセスする方法を示唆することなく、資源に識別子を提供します。IRIという概念はURI(Uniform Resource Identifier)を一般化したもので、非ASCII文字をIRIの文字列で使用できます。IRIは、RFC 3987[RFC3987
IRIは、トリプルの3つの位置すべて に出現できます。
前に述べたように、IRIは、ドキュメント、人間、物体、抽象的な概念などの資源を識別するために用いられます。例えば、DBpedia 内のレオナルド・ダ・ヴィンチのIRIは次のとおりです。
Europeana の「La Joconde à Washington」と題するモナ・リザに関するINA のビデオのIRIは、次のとおりです。
IRIはグローバルな識別子です。したがって、他の人々が、同じものを識別するためにこのIRIを再利用できます。例えば、人々の間の知り合い関係を記述するために、多くの人が次のIRIをRDFプロパティーとして用いています。
RDFは、IRIが何を表わすかに依存しません。しかし、特定の語彙や規定でIRIに意味を与えることができます。例えば、DBpedia は、対応するウィキペディアの記事で記述されているものを示すためにhttp://dbpedia.org/resource/Nameという形式のIRIを用いています。
3.3 リテラルリテラル は、IRIでない基本的な値です。リテラルの例には、「La Joconde」のような文字列、「the 4th of July, 1990」のような日付、「3.14159」のような数が含まれます。リテラルは、データ型 に関連付けることで、その値を正確に解析、解釈できるようになります。文字列のリテラルは、オプションで言語タグ に関連付けることができます。例えば、「Léonard de Vinci」は「fr」という言語タグに、「李奥纳多·达·文西」は「zh」という言語タグに関連付けることができます。
リテラルは、トリプルの目的語の位置 にのみ出現できます。
RDF概念のドキュメントは、(完全ではない)データ型のリスト を提供します。これには、文字列、ブール値、整数、10進数、日付などのXMLスキーマで定義されている多くのデータ型が含まれています。
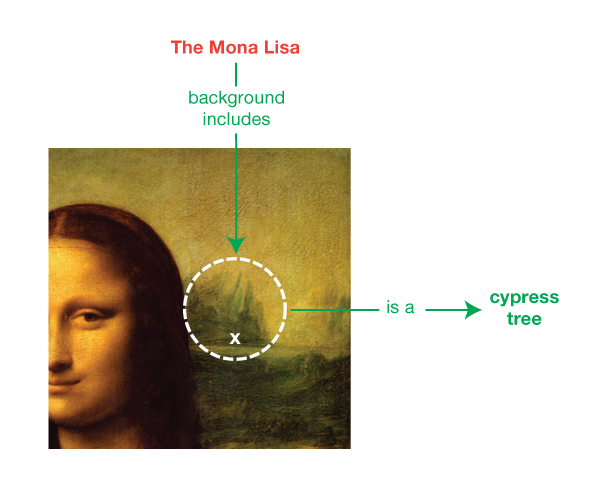
3.4 空白ノードIRIとリテラルはともに、RDFステートメントを記述するための基本的な材料となります。それに加えて、グローバルな識別子を用いずに資源を記述できると便利なことがあります。例えば、モナ・リザの絵の背景にヌマスギ(cypress tree)として知られている未確認の木が描かれていると述べたいとします。絵のヌマスギのようなグローバルな識別子のない資源は、RDFでは空白ノード で表わすことができます。空白ノードは、代数の単純変数に似ています。つまり、その値が何なのかを述べずに事物を表わします。
空白ノードは、トリプルの主語と目的語の位置 に出現できます。これを使用すれば、明示的にIRIで指定せずに、資源を示すことができます。
図2 非形式的な空白ノードの例: モナ・リザの背景には、ヌマスギのクラスに属する名前のない資源が描かれている。
3.5 複数のグラフRDFは、複数のグラフのRDFステートメントをグループ化し、そのようなグラフをIRIに関連付ける方法を提供します。複数のグラフは、RDFデータ・モデルの最近の拡張です。実際のところ、RDFツールの開発者やデータの管理者には、トリプルの集合のサブセットについて記述する方法が必要でした。複数のグラフは、RDFクエリ言語SPARQLで最初に導入されました。したがって、RDFデータ・モデルは、SPARQLと緊密に関連する複数のグラフの概念で拡張されました。
RDFドキュメントの複数のグラフは、RDFデータセット を構成します。RDFデータセットは、複数の名前付きグラフと、高々1つの名前のない(「デフォルト」)グラフを持つことができます。
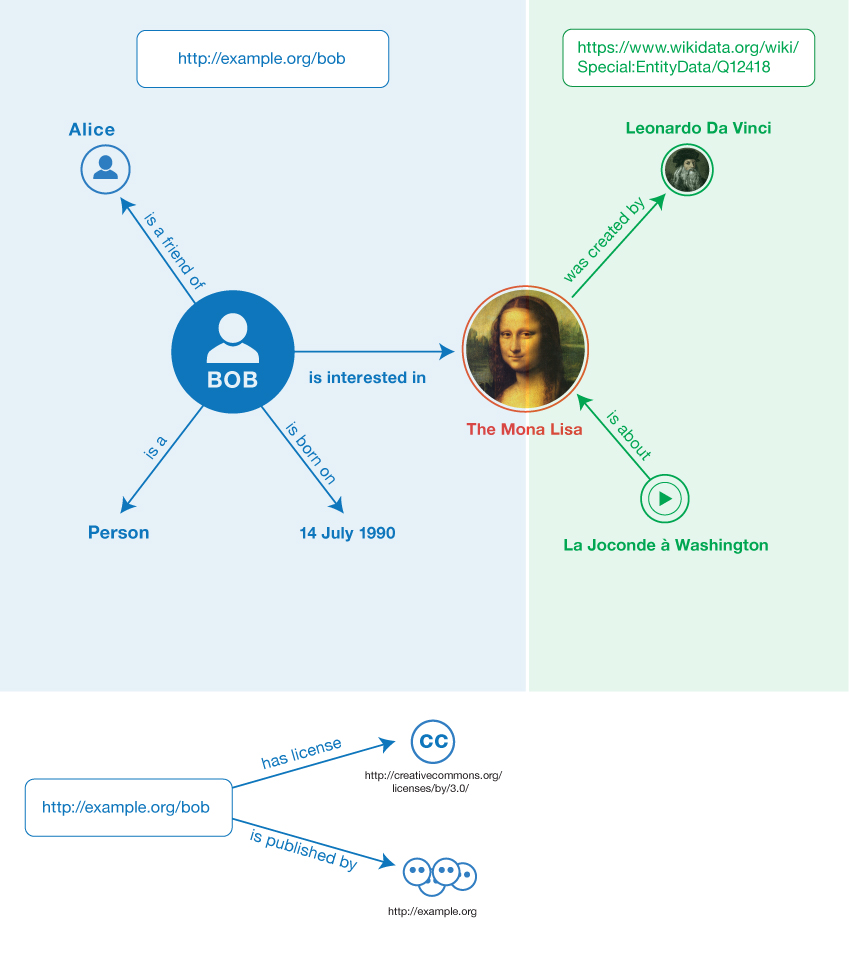
例えば、例1 のステートメントは、2つの名前付きグラフにグループ化できます。最初のグラフは、ソーシャル・ネットワーキングのサイトで提供します。これはhttp://example.org/bobで識別できます。
例2 : データセットの例の最初のグラフ
<Bob> <is a> <person>.
<Bob> <is a friend of> <Alice>.
<Bob> <is born on> <the 4th of July 1990>.
<Bob> <is interested in> <the Mona Lisa>.
グラフに関連付けられたIRIをグラフ名 と呼びます。
2番目のグラフはWikidata で提供します。これはhttps://www.wikidata.org/wiki/Special:EntityData/Q12418で識別できます。
例3 : データセットの例の2番目のグラフ
<Leonardo da Vinci> <is the creator of> <the Mona Lisa>.
<The video 'La Joconde à Washington'> <is about> <the Mona Lisa>
下記は名前のないグラフの例です。これには、グラフ名<http://example.org/bob>を主語として持つ2つのトリプルが含まれています。このトリプルは、公開者とライセンスの情報をこのグラフIRIに関連付けています。
例4 : データセットの例の名前のないグラフ
<http://example.org/bob> <is published by> <http://example.org>.
<http://example.org/bob> <has license> <http://creativecommons.org/licenses/by/3.0/>.
このデータセットの例では、グラフ名は、対応するグラフ内で保持されているRDFデータの情報源を表わすと考えられます。つまり、<http://example.org/bob>を検索すると、そのグラフ内の4つのトリプルにアクセスすることになるでしょう。
注
RDFには、データセットの他の利用者にこのセマンティックな仮定(つまり、グラフの名前はRDFデータの情報源を表わすという仮定)を伝える標準的な方法がありません。意図されているとおりに利用者がデータセットを解釈するためには、コミュニティーの定着した慣習のようなの帯域外の知識(out-of-band knowledge)に頼る必要があるでしょう。考えられるデータセットのセマンティクスに関しては、別のノート[RDF11-DATASETS
図3 データセットの例の非形式的なグラフ
5.1.3項 は、このグラフの具象構文の例を提供します。
4. RDF語彙RDFデータ・モデルは、資源について記述する方法を提供します。前に述べたように、このデータ・モデルは、IRIがどのような資源を表わすかに関していかなる仮定も行いません。実際には、RDFは一般的に、これらの資源に関してセマンティックな情報を提供する語彙やその他の規定と組み合わせて用いられます。
語彙の定義をサポートするために、RDFはRDFスキーマ言語[RDF11-SCHEMA http://www.example.org/friendOfというIRIはプロパティーとして使用でき、http://www.example.org/friendOfのトリプルの主語と目的語は、http://www.example.org/Personというクラスの資源でなければならないと述べることができます。
RDFスキーマは、資源の分類に使用できるカテゴリーを指定するためにクラス の概念を用います。そのクラスとインスタンスとの関係は型 プロパティーで記述します。RDFスキーマで、クラスとサブクラスの階層およびプロパティーとサブプロパティーの階層を作ることができます。特定のトリプルの主語と目的語に対する型の制限は、定義域 と値域 の制限で定義できます。定義域制限の一例として、「friendOf」トリプルの主語はクラス「Person」に属しているべきである、という例を上記に示しました。
RDFスキーマで提供される主要なモデリング構成子を次の表で要約しています。
表1: RDFスキーマ構成子
構成子
構文形式
説明
クラス (Class) - (クラス)C rdf:type rdfs:ClassC (資源)はRDFクラス
プロパティー (Property) - (クラス)P rdf:type rdf:PropertyP (資源)はRDFプロパティー
型 (type) - (プロパティー)I rdf:type C I (資源)はC (クラス)のインスタンス
~のサブクラス (subClassOf) - (プロパティー)C1 rdfs:subClassOf C2 C1 (クラス)はC2 (クラス)のサブクラス
~のサブプロパティー (subPropertyOf) - (プロパティー)P1 rdfs:subPropertyOf P2 P1 (プロパティー)はP2 (プロパティー)のサブプロパティー
定義域 (domain) - (プロパティー)P rdfs:domain C P (プロパティー)の定義域はC (クラス)
値域 (range) - (プロパティー)P rdfs:range C P (プロパティー)の値域はC (クラス)
注
構文形式(2列目)は接頭辞表記法で記述しています。これについては5項 でより詳細に論じます。構成子には2つの異なる接頭辞(rdf:とrdfs:)があるという事実は、多少やっかいな歴史的産物ですが、これは下位互換性のために残されています。
RDFスキーマのおかげで、RDFデータのモデルを構築できます。下記はシンプルで非形式的な例です。
例5 : RDFスキーマ・トリプル(非形式的)
<Person> <type > <Class>
<is a friend of> <type > <Property>
<is a friend of> <domain > <Person>
<is a friend of> <range > <Person>
<is a good friend of> <subPropertyOf > <is a friend of>
<is a friend of>は一般的に、トリプルの述語として用いられる(例1 でそうであったように)プロパティーですが、このようなプロパティー自体は、トリプルで記述したり、他の資源の記述に値を提供したりできる資源であるということに注意してください。この例では、<is a friend of>は、型、定義域、値域の値が割り当てられているトリプルの主語であり、さらに、<is a good friend of>というプロパティーに関して何かを記述しているトリプルの目的語です。
世界的に用いられている初期のRDF語彙の1つは、ソーシャル・ネットワークを記述するための「Friend of a Friend」 (FOAF)の語彙でした。その他のRDF語彙の例は次のとおりです。
ダブリン・コア Dublin Core Metadata Initiativeは、広範囲な資源を記述するためのメタデータ要素セットを維持しています。この語彙は「作成者」(creator)、「公開者」(publisher)、「タイトル」(title)などプロパティーを提供します。
schema.org
Schema.orgは、主要な検索プロバイダのグループによって開発された語彙です。その発想は、ウェブマスターがこれらの用語を用いてウェブ・ページをマークアップできるようにするというもので、その結果、検索エンジンは何に関するページなのかを理解できるようになります。
SKOS SKOSは、ウェブで用語やシソーラスなどの分類表を公開するための語彙です。SKOSは2009年以来、W3C 勧告となっており、図書館界で広く利用されています。米国議会図書館(Library of Congress)は、自身の件名標目をSKOSの語彙 として公開しています。
語彙は再利用によって価値を持ちます。つまり、IRIは、他者から語彙を再利用されればされるほど、IRIの利用価値が高まります(いわゆるネットワーク効果)。これは、新しいIRIを作り出すのではなく、だれか他の人のIRIを再利用する方が良いということを意味します。
RDFスキーマ構成子のセマンティクスの形式的な仕様については、RDFセマンティクスのドキュメント[RDF11-MT OWL2-OVERVIEW
5. RDFグラフの記述RDFグラフを記述するために、多数の様々なシリアル化形式が存在しています。しかし、同じグラフを別の方法で記述してもまったく同じトリプルになりえ、したがって、それらは論理的に同等です。
この項では、例に注釈を付しながら、次の形式について簡潔に紹介します。
RDF言語のTurtleファミリー(N-Triples 、Turtle 、TriG 、N-Quads )
JSON-LD (JSONベースのRDF構文)RDFa (HTMLとXML組み込み用)RDF/XML (RDF用XML構文)
注
読むにあたってのヒント: 5.1項(Turtleなど )では、RDFをシリアル化するためのすべての基本概念について論じています。RDFの特定の利用に興味がある場合にのみ、JSON-LD、RDFa、RDF/XMLの項を読まれることをお勧めします。
5.1 RDF言語のTurtleファミリーこの小項目では、密接な関連性を有する4つのRDF言語を紹介します。N-Triplesは、RDFトリプルを記述するための基本的な構文を提供するため、N-Triplesの紹介から始めます。Turtle構文は、読みやすさを改善するために、様々な糖衣構文形式でこの基本的な構文を拡張します。続いて、TriGとN-Quadsについて論じます。これらはそれぞれTurtleとN-Triplesの拡張で、複数のグラフをエンコードするためのものです。これらの4つを合わせて「RDF言語のTurtleファミリー」と呼びます。
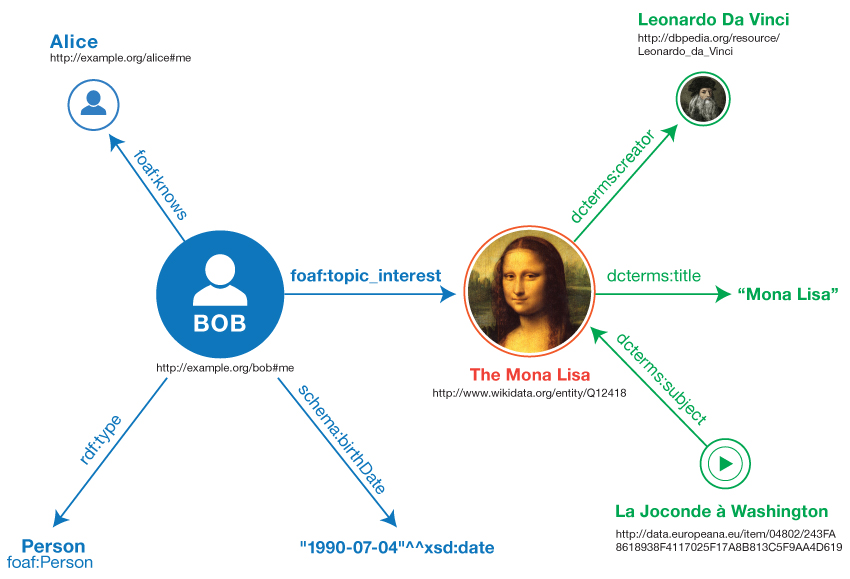
5.1.1 N-TriplesN-Triples[N-TRIPLES 図1 の非形式的なグラフは、次の方法でN-Triplesで表わすことができます。
例6 : N-Triples
01 <http://example.org/bob#me> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> .
02 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> .
03 <http://example.org/bob#me> <http://schema.org/birthDate> "1990-07-04"^^<http://www.w3.org/2001/XMLSchema#date> .
04 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/topic_interest> <http://www.wikidata.org/entity/Q12418> .
05 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/title> "Mona Lisa" .
06 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Leonardo_da_Vinci> .
07 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> <http://purl.org/dc/terms/subject> <http://www.wikidata.org/entity/Q12418> .各行はトリプルを表わします。フル形式のIRIは、山括弧(<>)で囲んでいます。行末のピリオドは、トリプルの終わりを示します。3行目には、リテラルの例があります。この場合、それは日付です。データ型は、^^という区切り記号でリテラルに付記されます。日付の表現は、XMLスキーマ・データ型の日付 の規定に従います。
文字列のリテラルは至る所に出現するため、N-Triplesでは、文字列のリテラルを書く場合には、ユーザはデータ型を省略できます。したがって、5行目の"Mona Lisa"は、"Mona Lisa"^^xsd:stringと同等です。言語タグ付き文字列の場合には、"La Joconde"@fr(モナ・リザのフランス語名)のように、タグは、@という記号で区切って文字列の直後に出現します。
注
技術的な理由で、言語タグ付き文字列のデータ型はxsd:stringではなくrdf:langStringです。言語タグ付き文字列のデータ型は、決して明示的に指定されません。
下の図は、例の結果のトリプルを示します。
図4 N-Triplesの例の結果作成されるRDFグラフ
N-Triplesの例の7行が上の図の7つのアークに相当することに注意してください。
N-Triplesは、大量のRDFの交換や、行指向型テキスト処理ツールで大規模なRDFグラフを処理するためにしばしば用いられます。
5.1.2 TurtleTurtle[TURTLE N-Triplesの拡張 です。Turtleは、基本的なN-Triples構文に加えて、名前空間接頭辞、リスト、データ型リテラルの省略形のサポートなど、多くの構文の省略形を導入しています。Turtleは、記述の容易さと解析および可読性の容易さの間のトレードオフを提供します。図4 で示しているグラフは、Turtleで次のように表わすことができます。
例7 : Turtle
01 BASE <http://example.org/>
02 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
03 PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
04 PREFIX schema: <http://schema.org/>
05 PREFIX dcterms: <http://purl.org/dc/terms/>
06 PREFIX wd: <http://www.wikidata.org/entity/>
07
08 <bob#me>
09 a foaf:Person ;
10 foaf:knows <alice#me> ;
11 schema:birthDate "1990-07-04"^^xsd:date ;
12 foaf:topic_interest wd:Q12418 .
13
14 wd:Q12418
15 dcterms:title "Mona Lisa" ;
16 dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> .
17
18 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619>
19 dcterms:subject wd:Q12418 .このTurtleの例は、N-Triples の例と論理的に同等です。1~6行目には、IRI記述の省略形を提供する多くの指示子が含まれています。相対IRI(8行目のbob#meなど)は、上記の1行目で指定されている基底IRIに対して解決されます。2~6行目では、IRI接頭辞(foaf:など)を定義しており、これはフル形式のIRIの代わりに接頭辞名(foaf:Personなど)に使用できます。対応するIRIは、接頭辞をその対応するIRIに置き換えることで作成されます(この例では、foaf:Personは<http://xmlns.com/foaf/0.1/Person>を表わす)。
8~12行目は、同じ主語を持つトリプルにTurtleが省略形を提供する方法を示しています。9~12行目は、<http://example.org/bob#me>を主語として持つ、述語-目的語部分を指定しています。9~11行目の末尾のセミコロンは、その後の述語-目的語のペアが、データ内で示されている最も新しい主語を用いた新しいトリプル(この場合はbob#me)の一部であることを示します。
9行目は、特殊な糖衣構文の例を示しています。トリプルは、非形式的に「Bob (is) a Person」と読むべきです。aという述語はインスタンス関係をモデル化するプロパティーrdf:typeの短縮形です(表1 を参照)。aという短縮形は、rdf:typeに関する人間の直観と一致させることを目的としたものです。
空白ノードの表現
以下に、以前のヌマスギ(cypress tree)の例を用いて、空白ノードを記述するための2つの異なる構文を示します。
例8 : 空白ノード
PREFIX lio: <http://purl.org/net/lio#>
<http://dbpedia.org/resource/Mona_Lisa> lio:shows _:x .
_:x a <http://dbpedia.org/resource/Cypress> .
_:xという用語は空白ノードです。これは、モナ・リザの絵に描かれている名前のない資源を表わし、この名前のない資源はCypressというクラスのインスタンスです。上の例は、図2 の非形式的なグラフの具象構文です。
Turtleには、空白ノード用の別の表記法もあり、_:xのような構文を用いる必要はありません。
例9 : 空白ノード(別の表記法)
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
# Some resource (blank node) is interested in some other resource
# entitled "Mona Lisa" and created by Leonardo da Vinci.
[] foaf:topic_interest [
dcterms:title "Mona Lisa" ;
dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> ] .
角括弧は、ここでは空白ノードを表わします。角括弧内の述語-目的語のペアは、空白ノードを主語として持つトリプルと解釈されます。「#」で始まる行はコメントを表わします。
Turtleの構文に関する詳細は、Turtleの仕様[TURTLE
5.1.3 TriGTurtleの構文は、グラフに「名前を付ける」手段がなく、1つのグラフの仕様のみをサポートします。TriG[TRIG Turtleの拡張 です。
注
RDF 1.1では、あらゆる正当なTurtleドキュメントは正当なTriGドキュメントです。それを1つの言語と見ることができるでしょう。TurtleとTriGの名前は、歴史上の理由によりまだ存在しています。
我々の例の複数グラフのバージョン は、TriGで次のように指定できます。
例10 : TriG
01 BASE <http://example.org/>
02 PREFIX foaf: <http://xmlns.com/foaf/0.1/>
03 PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
04 PREFIX schema: <http://schema.org/>
05 PREFIX dcterms: <http://purl.org/dc/terms/>
06 PREFIX wd: <http://www.wikidata.org/entity/>
07
08 GRAPH <http://example.org/bob>
09 {
10 <bob#me>
11 a foaf:Person ;
12 foaf:knows <alice#me> ;
13 schema:birthDate "1990-07-04"^^xsd:date ;
14 foaf:topic_interest wd:Q12418 .
15 }
16
17 GRAPH <https://www.wikidata.org/wiki/Special:EntityData/Q12418>
18 {
19 wd:Q12418
20 dcterms:title "Mona Lisa" ;
21 dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> .
22
23 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619>
24 dcterms:subject wd:Q12418 .
25 }
26
27 <http://example.org/bob>
28 dcterms:publisher <http://example.org> ;
29 dcterms:rights <http://creativecommons.org/licenses/by/3.0/> .このRDFデータセットには2つの名前付きグラフが含まれています。8行目と17行目に、これらの2つのグラフの名前を記述しています。名前付きグラフ内のトリプルは、一揃いの中括弧の間に置かれます(9行目と15行目、18行目と25行目)。オプションで、GRAPHというキーワードをグラフ名の前に置くことができます。これによって読みやすさが改善するかもしれませんが、これは主にSPARQL更新[SPARQL11-UPDATE
最上部のトリプルと指示子の構文は、Turtle構文に準拠しています。
27~29行目で指定されている2つのトリプルは、名前付きグラフの一部ではありません。これらは、合わせて、このRDFデータセットの名前のない(「デフォルトの」)グラフを形成します。
下記の図は、この例の結果として作成されるトリプルを示します。
Fig. 5 TriGの例の結果作成されるトリプル
5.1.4 N-QuadsN-Quads[N-QUADS
例11 : N-Quads
01 <http://example.org/bob#me> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> <http://example.org/bob> .
02 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> <http://example.org/bob> .
03 <http://example.org/bob#me> <http://schema.org/birthDate> "1990-07-04"^^<http://www.w3.org/2001/XMLSchema#date> <http://example.org/bob> .
04 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/topic_interest> <http://www.wikidata.org/entity/Q12418> <http://example.org/bob> .
05 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/title> "Mona Lisa" <https://www.wikidata.org/wiki/Special:EntityData/Q12418> .
06 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Leonardo_da_Vinci> <https://www.wikidata.org/wiki/Special:EntityData/Q12418> .
07 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> <http://purl.org/dc/terms/subject> <http://www.wikidata.org/entity/Q12418> <https://www.wikidata.org/wiki/Special:EntityData/Q12418> .
08 <http://example.org/bob> <http://purl.org/dc/terms/publisher> <http://example.org> .
09 <http://example.org/bob> <http://purl.org/dc/terms/rights> <http://creativecommons.org/licenses/by/3.0/> .N-Quadsの例の9つの行は、図5 の9つのアークに相当します。1~7行目はクアッド(quad;4つ組)を表わし、その最初の要素がグラフIRIです。クアッド内のグラフIRIより後の部分は、N-Triplesの構文規定に従い、ステートメントの主語、述語、目的語を指定します。8行目と9行目は、名前のない(デフォルトの)グラフのステートメントを表わし、これには4番目の要素がなく、したがって、通常のトリプルを構成します。
N-Triplesと同様に、N-Quadsは通常、大量のRDFデータセットの交換や行指向型テキスト処理ツールでRDFを処理するために用いられます。
5.2 JSON-LDJSON-LD[JSON-LD @graphというキーワードの使用によりRDFデータセットをシリアル化する方法も提供します。
次のJSON-LDの例は、図4 のグラフをエンコードしたものです。
例12 : JSON-LD
01 {
02 "@context": "example-context.json",
03 "@id": "http://example.org/bob#me",
04 "@type": "Person",
05 "birthdate": "1990-07-04",
06 "knows": "http://example.org/alice#me",
07 "interest": {
08 "@id": "http://www.wikidata.org/entity/Q12418",
09 "title": "Mona Lisa",
10 "subject_of": "http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619",
11 "creator": "http://dbpedia.org/resource/Leonardo_da_Vinci"
12 }
13 }2行目の@contextキーは、どのようにドキュメントをRDFグラフにマッピングできるかを記述したJSONドキュメントを指し示します(下記を参照)。個々のJSONオブジェクトは、RDF資源に相当します。この例では、3行目で@idキーワードを用いて指定しているように、記述されている主な資源はhttp://example.org/bob#meです。@idキーワードは、JSON-LDドキュメントでキーとして用いた場合、現在のJSONオブジェクトに対応する資源を識別するIRIを指し示します。4行目でこの資源の型、5行目でその生年月日、6行目でその友達の1人を記述しています。7~12行目に、関心の1つである、モナ・リザの絵について記述しています。
この絵を記述するために、7行目で新しいJSONオブジェクトを作成し、8行目でそれをWikidataのモナ・リザのIRIに関連づけています。その後、9~11行目でその絵の様々なプロパティー(特性)を記述しています。
この例で用いているJSON-LDのコンテキストを下記で示しています。
例13 : JSON-LDコンテキスト仕様
01 {
02 "@context": {
03 "foaf": "http://xmlns.com/foaf/0.1/",
04 "Person": "foaf:Person",
05 "interest": "foaf:topic_interest",
06 "knows": {
07 "@id": "foaf:knows",
08 "@type": "@id"
09 },
10 "birthdate": {
11 "@id": "http://schema.org/birthDate",
12 "@type": "http://www.w3.org/2001/XMLSchema#date"
13 },
14 "dcterms": "http://purl.org/dc/terms/",
15 "title": "dcterms:title",
16 "creator": {
17 "@id": "dcterms:creator",
18 "@type": "@id"
19 },
20 "subject_of": {
21 "@reverse": "dcterms:subject",
22 "@type": "@id"
23 }
24 }
25 }このコンテキストは、どのようにJSON-LDドキュメントをRDFグラフにマッピングできるかを記述しています。4~9行目では、Person(人)、interest(関心)、knows(知っている)を、3行目で定義しているFOAF名前空間の型とプロパティーにマッピングする方法を定めています。8行目で、knowsキーは、@typeと@idのキーワードの使用により、IRIとして解釈される値を持つこということも定めています。
10~12行目では、schema.orgプロパティーのIRIにbirthdate(生年月日)をマッピングし、その値をxsd:dateデータ型にマッピングできることを定めています。
16~23行目では、ダブリン・コアのプロパティーのIRIに、title(タイトル)、creator(作成者)、subject_of(~のキーワード)をマッピングする方法を記述しています。21行目の@reverseキーワードは、このコンテキストを用いたJSON-LDドキュメントで"subject_of": "x"に遭遇した場合は常に、主語がx IRI、プロパティーがdcterms:subject、目的語が親のJSONオブジェクトに対応した資源であるRDFトリプルにそれをマッピングすべきであることを定めるために用いられています。
5.3 RDFaRDFa[RDFA-PRIMER schema.org とRich Snippets を参照)。
次のHTMLの例は、図4 で描かれているRDFグラフをエンコードしています。
例14 : RDFa
01 <body prefix="foaf: http://xmlns.com/foaf/0.1/
02 schema: http://schema.org/
03 dcterms: http://purl.org/dc/terms/">
04 <div resource="http://example.org/bob#me" typeof="foaf:Person">
05 <p>
06 Bob knows <a property="foaf:knows" href="http://example.org/alice#me">Alice</a>
07 and was born on the <time property="schema:birthDate">1990-07-04</time>.
08 </p>
09 <p>
10 Bob is interested in <span property="foaf:topic_interest"
11 resource="http://www.wikidata.org/entity/Q12418">the Mona Lisa</span>.
12 </p>
13 </div>
14 <div resource="http://www.wikidata.org/entity/Q12418">
15 <p>
16 The <span property="dcterms:title">Mona Lisa</span> was painted by
17 <a property="dcterms:creator" href="http://dbpedia.org/resource/Leonardo_da_Vinci">Leonardo da Vinci</a>
18 and is the subject of the video
19 <a href="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619">'La Joconde à Washington'</a>.
20 </p>
21 </div>
22 <div resource="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619">
23 <link property="dcterms:subject" href="http://www.wikidata.org/entity/Q12418"/>
24 </div>
25 </body>上記の例には、HTML内でRDFトリプルの仕様を有効にする、resource(資源)、property(プロパティー)、typeof(~の型)、prefix(接頭辞)の4つの特別なRDFa属性が含まれています。
1行目のprefix属性は、Turtle接頭辞と同じような方法でIRIの省略形を指定します。厳密に言えば、RDFaには、この例で用いているものを含め、定義済み接頭辞 のリストがあるため、これらの特別な接頭辞は省略可能でした。
4行目と14行目のdiv要素には、このHTML要素内でRDFステートメントを記述できるIRIを指定するresource属性があります。4行目のtypeof属性の意味は、Turtleの(is) aという省略形に似ており、主語であるhttp://example.org/bob#meは、foaf:Personというクラスのインスタンス(rdf:type)です。
6行目にはproperty属性があり、この属性の値(foaf:knows)は、RDFプロパティーIRIとして解釈されます。href属性の値(http://example.org/alice#me)は、ここではトリプルの目的語として解釈されます。したがって、6行目の結果であるRDFステートメントは次のとおりです。
<http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> .7行目には、リテラル値を目的語として持つトリプルがあります。property属性は、ここではHTMLのtime要素で指定されています。HTMLでは、時間(time)要素の内容は、何らかの有効な時間の値 である必要があります。time要素の組み込み済みのHTMLセマンティクスを用いれば、RDFaは、明示的なデータ型宣言なしに、値をxsd:dateとして解釈できます。
10~11行目には、トリプルの目的語を指定するためにも用いられているresource属性があります。このアプローチは、目的語がIRIで、IRI自体がHTMLコンテンツ(href属性など)の一部ではない場合に用いられます。16行目には、2番目のリテラルの例(「モナ・リザ」)が含まれており、ここではspan属性のコンテンツとして定義されています。RDFaは、リテラルのデータ型を推論できない場合には、データ型はxsd:stringであると推測するでしょう。
RDFステートメントをドキュメントのHTMLコンテンツの一部として定義することが可能だとは限りません。その場合、コンテンツを表示しないHTML構成子を用いてトリプルを指定できます。22~23行目にその例があります。23行目のHTMLのlink要素は、Europeanaのビデオ(22行目)のトピックが何なのかを明示するためにここで用いられています。
この例のRDFaの使用は、RDFa Lite[RDFA-LITE RDFA-PRIMER
5.4 RDF/XMLRDF/XML[RDF-SYNTAX-GRAMMAR
下記のRDF/XMLの例は、図4 で描かれているRDFグラフをエンコードしています。
例15 : RDF/XML
01 <?xml version="1.0" encoding="utf-8"?>
02 <rdf:RDF
03 xmlns:dcterms="http://purl.org/dc/terms/"
04 xmlns:foaf="http://xmlns.com/foaf/0.1/"
05 xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
06 xmlns:schema="http://schema.org/">
07 <rdf:Description rdf:about="http://example.org/bob#me">
08 <rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person"/>
09 <schema:birthDate rdf:datatype="http://www.w3.org/2001/XMLSchema#date">1990-07-04</schema:birthDate>
10 <foaf:knows rdf:resource="http://example.org/alice#me"/>
11 <foaf:topic_interest rdf:resource="http://www.wikidata.org/entity/Q12418"/>
12 </rdf:Description>
13 <rdf:Description rdf:about="http://www.wikidata.org/entity/Q12418">
14 <dcterms:title>Mona Lisa</dcterms:title>
15 <dcterms:creator rdf:resource="http://dbpedia.org/resource/Leonardo_da_Vinci"/>
16 </rdf:Description>
17 <rdf:Description rdf:about="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619">
18 <dcterms:subject rdf:resource="http://www.wikidata.org/entity/Q12418"/>
19 </rdf:Description>
20 </rdf:RDF>RDF/XMLではRDFトリプルは、rdf:RDFというXML要素内で指定します(2行目と20行目)。rdf:RDF開始タグの属性(3~6行目)は、XMLの要素と属性の名前を記述するための省略形を提供します。rdf:DescriptionというXML要素(http://www.w3.org/1999/02/22-rdf-syntax-ns#Descriptionの省略形)は、about属性で指定されているIRIを主語として持つトリプルの集合を定義するために用いられます。最初の記述ブロック(7~12行目)には4つの下位要素があります。下位要素の名前は、RDFプロパティーを表わすIRI(例えばrdf:type)です(8行目)。ここの下位要素はそれぞれ1つのトリプルを表わします。トリプルの目的語がIRIでもある場合には、プロパティー下位要素には内容がなく、その目的語のIRIはrdf:resource属性を用いて指定されます(8、10~11、15、18行目)。例えば、10行目は次のトリプルに相当します。
<http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> .トリプルの目的語がリテラルであれば、そのリテラルの値がプロパティーの要素のコンテンツとして入力されます(9行目と14行目)。データ型はプロパティーの要素の属性として指定されます(9行目)。データ型が省略され(14行目)、言語タグが存在しない場合、リテラルはxsd:stringというデータ型を持つと考えられます。
例は、ベースラインの構文を示しています。構文のより詳細な処理に関しては、RDF/XMLドキュメント[RDF11-XML
6. RDFグラフのセマンティクスRDFを使用する重要な目標は、整合性と有用性を保ちつつより大きな集合を形成するために複数の情報源の有用な情報を自動的に結合できることです。この結合のための出発点として、上で述べたように、すべての情報は、主語-述語-目的語のトリプルという同じシンプルな形式で伝えられます。しかし、情報の整合性を保つためには、単なる標準構文を越えることが必要で、これらのトリプルのセマンティクスについて合意する必要もあります。
入門仕様のこの時点までに、読者は、RDFのセマンティクスを直観的に理解できるようになっているでしょう。
主語、述語、目的語を指定するために用いるIRIの範囲は「グローバル」で、これらを使用するたびに同じものが指定されます。
主語と目的語の間に述語関係が実在する場合に限り、個々のトリプルは「真」です。
RDFグラフ内のすべてのトリプルが「真」である場合に限り、そのRDFグラフは「真」です。
これらの概念(また、他のものも)、RDFセマンティクスのドキュメント[RDF11-MT
これらの宣言的セマンティクスを持つRDFの利点の1つは、システムが論理的な推論を行うことができるということです。すなわち、真として受け入れたあるトリプルの入力データの集合を与えられれば、システムは、ある状況下において、論理的に他のトリプルも真であるに違いないと推定できます。我々は、最初のトリプルの集合が追加のトリプルを「含意する」といいます。「推論システム」と呼ばれるこれらのシステムは、与えられたトリプルの入力データが互いに矛盾することがあると推定することもできます。
新しい概念を使用したい時に新しい語彙を作成できる場合、RDFの柔軟性が得られれば、実行したい異なる種類の推論がたくさんあります。特定の種類の推論が様々なアプリケーションに役立つと思われる場合には、それを含意レジーム (entailment regime)としてドキュメント化できます。いくつかの含意レジームがRDFセマンティクスで規定されています。他のいくつかの含意レジームと、SPARQLでこれらを用いる方法の技術的な解説については[SPARQL11-ENTAILMENT
含意の例として、次の2つのステートメントについて考えてみてください。
ex:bob foaf:knows ex:alice .
foaf:knows rdfs:domain foaf:Person .
このグラフから次のトリプルを導き出すことは正当であることが、RDFセマンティクスのドキュメントから分かります。
ex:bob rdf:type foaf:Person .
上記の導出は、RDFスキーマ含意[RDF11-MT
リテラルがXMLスキーマ・データ型のinteger (整数)に対して定義されている制約に準拠していないため、RDFのセマンティクスから、
ex:bob ex:age "forty"^^xsd:integer .
このトリプルには論理矛盾が生じることも分かります。
RDFツールがすべてのデータ型を認識するとは限らないことに注意してください。最小限、ツールは文字列のリテラルと言語タグ付きリテラル用のデータ型をサポートする必要があります。
他の多くのデータ・モデリング言語とは異なり、RDFスキーマはモデリングに関し相当な自由度が認められています。例えば、同じエンティティーをクラスとプロパティーの両方として使用できます。さらに、「クラス」と「インスタンス」の領域には厳密な区別はありません。したがって、RDFセマンティクスは、次のグラフを有効なものと見なします。
ex:Jumbo rdf:type ex:Elephant .
ex:Elephant rdf:type ex:Species .
したがって、elephant(象)は、クラス(Jumboを例のインスタンスとして持つ)とインスタンス(つまり、動物種(animal species)のクラスに属する)の両方になりえます。
この項の例は、RDFセマンティクスによって何がもたらされるのかに関する何らかの感覚を読者に与えることだけを目的としています。完全な記述に関しては[RDF11-MT
7. RDFデータRDFにより、任意の情報源の複数のトリプルをグラフへと結合させ、正当なRDFとして処理できるようになります。大量のRDFデータは、リンクト・データ[LINKED-DATA SPARQL11-OVERVIEW
リンクト・データとして利用可能なデータセットのリストがdatahub.io で維持されています。
RDFデータの情報源間のリンクを記録するための語彙の用語がたくさん普及しました。次の例は、OWL語彙が提供しているsameAsプロパティーです。このプロパティーは、2つのIRIが実際には同じ資源を指し示すことを表わすために使用できます。異なる公開者が、異なる識別子を用いて同じものを表わすことができるため、これは便利です。例えば、VIAF(上記参照)にはレオナルド・ダ・ヴィンチを示すIRIもあります。owl:sameAsのおかげで、我々はこの情報を次のように記録できます。
例16 : データセット間のリンク
<http://dbpedia.org/resource/Leonardo_da_Vinci>
owl:sameAs <http://viaf.org/viaf/24604287/> . RDFデータ処理ソフトウェアは、このようなリンクを、例えば、同じ資源を指し示すIRIのRDFデータを結合したり比較することにより、展開できます。
8. さらなる情報これで、RDFに関する簡潔な紹介を終了します。より多くの詳細情報を得るためには、参考文献をご覧ください。W3C のリンクト・データのページ
A. 謝辞Antoine Isaacが、様々な構文形式を含む多くの例を提供しました。Pierre-Antoine Champinは、JSON-LDの例の1つを提供しました。Andrew Woodは図を作成しました。Sandro Hawkeは、RDFセマンティクスに関する項の最初の部分を書きました。
Gareth Adams、Thomas Baker、Dan Brickley、Pierre-Antoine Champin、Bob DuCharme、Sandro Hawke、Patrick Hayes、Ivan Herman、Kingsley Idehen、Antoine Isaac、Markus LanthalerおよびDavid Wood(ABC順)から提供されたコメントに感謝申し上げます。
このドキュメントの「はじめに」には、2004年の入門[RDF-PRIMER