 |
 |
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
|
|
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
前ページでは Pacemaker の RHEL/CentOS 6.4 の標準パッケージを使うやり方を説明した。対してこちらは、UltraMonkey-L7 文書サイトの Pacemaker環境用インストールマニュアル に挙げられている Pacemaker パッケージを使って検証したまとめだ。crm_gui というグラフィカル設定ツールが使えるのも利点といえば利点。ただし、heartbeat は完全に廃し、前ページと同じく UltraMonkey-L7 + Pacemaker + corosync というコンビネーションで組み立てた。corosync は RHEL/CentOS 6.4 の標準パッケージを使用する。
ここで使用する pacemaker-1.0.13 はクラスタ設定/コントロールコマンドラインツール crm (crmsh) を含んでいる。そのため、クラスタの設定や操作は、前ページで使った pcs でなく、crm で行う。両コマンドの対照サンプルとしても役に立つかもしれない。
Linux-HA Japan提供パッケージ一覧 から Pacemakerリポジトリパッケージ (RHEL6) へと進み、pacemaker-1.0.13-1.1.el6.x86_64.repo.tar.gz をダウンロード。このrepoパッケージには、レポジトリ定義ファイルの他に実際のパッケージも含まれている。ダウンロードしたら /tmp/ に展開。repoファイルの造りから、必ず /tmp/ でなければいけない。
# cd /tmp # tar xzvf /PATH/TO/pacemaker-1.0.13-1.1.el6.x86_64.repo.tar.gz # cd pacemaker-1.0.13-1.1.el6.x86_64.repo
依存する標準パッケージはCentOS-baseやupdatesレポジトリから取得されるため、インターネットへの接続にプロキシの必要な環境では、上記ディレクトリ下の pacemaker.repo を調整しておく必要がある。以下の記述をファイル先頭に挿入する。
[main] proxy=http://YOUR.PROXY.SERVER:PORT
では続きを。
# yum clean all # yum -c pacemaker.repo install \ pacemaker-1.0.13-1.el6 \ <--pacemakerのみバージョンまで具体的に指定する(※) pacemaker-mgmt \ pacemaker-mgmt-client \ pm_crmgen \ pm_logconv-hb \ pm_diskd \ pm_extras \ pm_kvm_tools \ vm-ctl \ ipmitool \ corosync Installing: corosync x86_64 1.4.5-1.el6 pacemaker 164 k pacemaker x86_64 1.0.13-1.el6 pacemaker 5.6 M pacemaker-mgmt x86_64 2.0.1-1.el6 pacemaker 79 k pm_crmgen noarch 1.3-1.el6 pacemaker 45 k pm_diskd x86_64 1.2-1.el6 pacemaker 14 k pm_extras x86_64 1.3-1.el6 pacemaker 24 k pm_kvm_tools x86_64 1.1-1.el6 pacemaker 44 k pm_logconv-hb noarch 1.2-1.el6 pacemaker 53 k vm-ctl noarch 1.1-1.el6 pacemaker 12 k Installing for dependencies: PyXML x86_64 0.8.4-19.el6 base 892 k cluster-glue x86_64 1.0.11-1.el6 pacemaker 261 k cluster-glue-libs x86_64 1.0.11-1.el6 pacemaker 110 k corosynclib x86_64 1.4.5-1.el6 pacemaker 143 k heartbeat x86_64 3.0.5-1.1.el6 pacemaker 162 k heartbeat-libs x86_64 3.0.5-1.1.el6 pacemaker 263 k libesmtp x86_64 1.0.4-16.el6 pacemaker 57 k openhpi-libs x86_64 2.14.1-3.el6_4.3 updates 135 k pacemaker-libs x86_64 1.0.13-1.el6 pacemaker 262 k perl-TimeDate noarch 1:1.16-11.1.el6 base 34 k resource-agents x86_64 3.9.5-1.el6 pacemaker 459 k
※ CentOS 6.4の標準パッケージのほうがバージョンが高いため、pacemekerのバージョンを指定しないと updatesレポジトリからダウンロードされてしまう。これにより、依存関係でcluster-glueなども pacemakerローカルレポジトリにあるものがインストールされる。
このバージョンの pacemaker パッケージは crm (crmsh)を含んでいるが、pcs もインストールしておきたければ、標準レポジトリからインストールできる。
# yum install pcs
Installing:
pcs noarch 0.9.26-10.el6_4.1 updates 72 k
SourceForgeのUltraMonkey-L7ダウンロードページから ultramonkeyl7-repo-3.1.0-1.el6.x86_64.rpm をダウンロード。これは、単なる yum のrepo定義ファイルでなく、実際のパッケージ一式も含んでいる。ダウンロードしたrepoパッケージをインストール。
# rpm -ivh ultramonkeyl7-repo-3.1.0-1.el6.x86_64.rpm
インストールすると、/etc/yum.repos.d/ にrepo定義ファイル、/opt/ultramonkey-l7/ultramonkeyl7/ 配下に rpmパッケージ群が展開される。これで ultramonkey-L7 がインストールできる。
# yum install ultramonkeyl7
Installing:
ultramonkeyl7 x86_64 3.1.0-1.el6 ultramonkeyl7 1.6 M
Installing for dependencies:
apache-log4cxx x86_64 0.10.0-1.el6 ultramonkeyl7 446 k
perl-IO-Socket-INET6 noarch 2.56-4.el6 base 17 k
perl-IO-Socket-SSL noarch 1.31-2.el6 base 69 k
perl-Net-LibIDN x86_64 0.12-3.el6 base 35 k
perl-Net-SSLeay x86_64 1.35-9.el6 base 173 k
perl-Socket6 x86_64 0.23-3.el6 base 23 k
repo一式はもう必要なくなったので捨てる。
# rpm -e ultramonkeyl7-repo
l7vsd と l7directord を起動するためのリソースエージェントをインストール。
# cp -p /usr/share/doc/ultramonkeyl7-3.1.0/heartbeat-ra/{L7vsd,L7directord} \
/usr/lib/ocf/resource.d/heartbeat
クラスタ内でノードを短い名前で扱えるよう、hostsファイルなどを調整しておいたほうがよい。
HOSTNAME=centos6u.hoge.local
のようになっていたら、ドメイン部を取り除いて、
HOSTNAME=centos6u
のように直す。
domain hoge.local
がなければ加える。
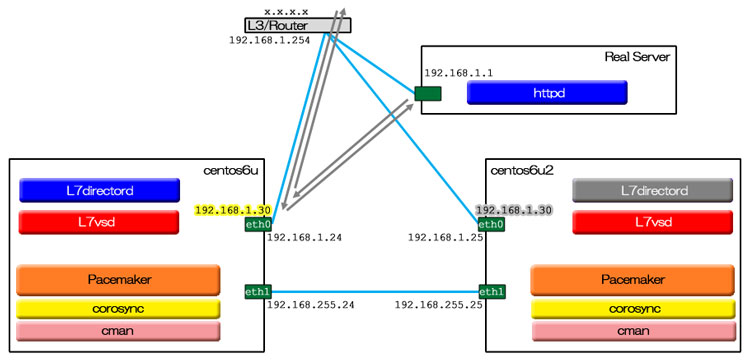
RedHat/CentOS 6 のOSインストール直後の状態では、IPv4 と IPv6 のループバックアドレスしか書かれていない。自ホストはもちろんだが、クラスタファームを構成するノードはリストしておいたほうがいい(実際は他ノードは書かなくても動く)。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.24 centos6u.hoge.local centos6u 192.168.1.25 centos6u2.hoge.local centos6u2
ホストネームの変更を反映するため、マシンを一旦リブート。
pacemaker と一緒にインストールした pacemaker-mgmt-client は Pacemaker/corosync のグラフィカルインターフェイス。使うためには Linuxアカウント hacluster にパスワードを与えておく。当ページでは使い方には触れないが、GUI を起動するには crm_gui とコマンドする。起動は一般ユーザ権限で構わない。
UltraMonkey-L7 単独の動作試験から始めたいところだが、フローティングIP が存在しないことには L7vsd が立ち上げられない。そのため、先に corosync + Pacemaker の基本設定をしておく。
# cp -p /etc/corosync/corosync.conf{.example,}
`man corosync.conf' を読み、/etc/corosync/corosync.conf を編集。
compatibility: whitetank
totem {
version: 2
secauth: off
threads: 0
rrp_mode: passive <--当例のようにハートビートLANを複数持たせる場合は書く必要あり
nodeid: 24 <--ノードID。ファーム内のノード毎に設定ファイルが異なるのはここだけ
interface { <--ハートビートインターフェイス1(ハートビート専用)
ringnumber: 0
bindnetaddr: 192.168.255.0 <--ハートビート専用インターフェースのIPアドレスのネットワークアドレスを指定
mcastaddr: 239.255.1.1 <--マルチキャストアドレス。Cluster from Scratch の 2.5.2. Notes on Multicast Address Assignment を一読
mcastport: 5405
ttl: 1
}
interface { <--ハートビートインターフェイス2(サービス提供兼ハートビート)
ringnumber: 1
bindnetaddr: 192.168.1.0 <--サービス提供兼ハートビートインターフェースのIPアドレスのネットワークアドレス
mcastaddr: 239.255.1.1
mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: no
to_syslog: yes
syslog_facility: local5
debug: off
timestamp: off
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
上記でログを syslog 経由にしたので、/etc/rsyslog.conf に下記定義を追加。
local5.* /var/log/cluster/corosync.log
/etc/corosync/service.d/pacemaker を新規に作成して編集。
service {
name: pacemaker
ver: 0 <--このバージョンのPacemakerはinitスクリプトを持たず、corosync経由で起動されるため、必ず0に
use_mgmtd: yes <--Pacemaker GUIを使用する場合はこの行を記載
}
ノード間で corosync どうしが通信し合うための対称キーを、1台のノード上で生成する。
# corosync-keygen
上記コマンドを発行すると「エントロピー生成のためにキーボードを叩け」と言われるので出鱈目に叩き続ける。やがて /etc/corosync/authkey ファイルが出来る。このキーファイルを、他のノードにもコピーする。パーミッションは root:root 400 に。
corosync + Pacemaker を始動。
# service corosync start # crm status
ここまでの工程を、他のノードでも実施し、同様に corosync を立ち上げる。設定が間違っていなければ、別ノード上でデーモンが立ち上がるとすぐに、クラスタファームに組み入れられる。`crm status' で両ノードが表示されるはずだ。以後、クラスタの設定を進めていくと、全てのノード上の cib が更新されていく。
マスターノード上で設定の続きを。
STONITH の実装は本来必須だが、後で追加設定するまでは無効にしておく。また、クラスタは2台構成なので QUORUM も無視されるようにしておく。
# crm # configure crm# property stonith-enabled=false crm# property no-quorum-policy=ignore crm# commit crm# show cib-bootstrap-options property $id="cib-bootstrap-options" \ dc-version="1.0.13-30bb726" \ cluster-infrastructure="openais" \ expected-quorum-votes="2" \ stonith-enabled="false" \ no-quorum-policy="ignore" crm# quit
起動状態を確認。
# corosync-cfgtool -s
Printing ring status.
Local node ID 24
RING ID 0
id = 192.168.255.24
status = ring 0 active with no faults
RING ID 1
id = 192.168.1.24
status = ring 1 active with no faults
さて、IPaddr2 というリソースエージェントを使ってフローティングIPリソースを作ろう。
# crm configure crm# primitive FIP1 ocf:heartbeat:IPaddr2 \ params ip=192.168.1.30 nic=eth1 cidr_netmask=24 \ op start interval=0s timeout=60s on-fail=restart \ op monitor interval=30s timeout=60s on-fail=restart \ op stop interval=0s timeout=60s on-fail=block crm# show crm# commit
リソースエージェント(RA)とは、実際にサービスやリソース(例えばフローティングIP)を立ち上げたり、リソースの死活監視(ゲイトウェイへ定期的にpingを飛ばすことによるインターフェイス死活監視など) をするためのプログラムで、/usr/lib/ocf/resource.d/ 配下にディレクトリ階層で管理されている。例えば、上記で指定している ocf:heartbeat:IPaddr2 は、resource.d/heartbeat/ にある IPaddr2 というファイル名のシェルスクリプトだ。中間フィールドの heartbeat をリソースプロバイダ と呼ぶ。各スクリプトは Open Clustering Framework Resource Agent API という規格に沿って書かれている。OCF についてもっと深く知りたい、あるいは自分でカスタムエージェントを書きたいという人は The OCF Resource Agent Developer’s Guide を読むといいだろう。
どんなプロバイダや RA があるかやその使い方は、crm の場合、以下のようなコマンドで調べることができる。
RA規格(例えばocf)とプロバイダをリストアップするには:
# crm ra classes
リソースエージェントをリストアップするには:
# crm ra list heartbeat
リソースエージェントの説明を表示するには:
# crm ra info ocf:heartbeat:IPaddr2
きちんと定義されたかどうか確認する。
# crm status <--出来上がった途端にもうフローティングIPはstartedになっているはずだ # crm resource show # crm configure show FIP1 # ip addr show <--IPが確かに発生していることを確認 # crm configure show xml
最後のコマンドは、cib のXMLを表示する。cib とは Cluster Information Base の略で、クラスタに関しての、定義やオプション、ノード、リソース、それらの関係性、ステータスなどを管理するデータベース。実体は /var/lib/heartbeat/crm/ にある(Pacemaker 1.1 では /var/lib/pacemaker/cib/ )。pcs や crm などのツールが登場するまでは(筆者はその時代を知らないが)、その複雑なXMLファイルを直接編集しなければならなかったらしい。cib は corosync によって、クラスタファームを構成するノード間で同期される。corosync のログを見ていると、どうやら一種の diff を採って差分転送しているようだ。
何はともあれ、UltraMonkey-L7 - SourceForge.JP -> 文書 にある UltraMonkey-L7 Pacemaker 環境インストールマニュアル を読むべし。
l7directord の設定ファイルサンプルをコピーして土台を作る。
# cp -p /etc/ha.d/conf/l7directord.cf{.sample,}
l7directord.conf を然るべく編集。
振り分け先の実サーバ上で実サービス(httpd) を立ち上げておいてから、ロードバランサの基本的な動作テスト。
# service l7vsd start # service l7directord start # l7vsadm -l -n
想定通り動くようであれば、クラスタの作り込みのために一旦 UltraMonkey-L7 を落とす。
# service l7directord stop # service l7vsd stop
# crm configure crm# primitive L7VSD ocf:heartbeat:L7vsd \ op start interval=0s timeout=60s on-fail=restart \ op monitor interval=30s timeout=60s on-fail=restart \ op stop interval=0s timeout=60s on-fail=block crm# show L7VSD crm# commit
crm# primitive L7DRCTOR1 ocf:heartbeat:L7directord \ op start interval=0s timeout=60s on-fail=restart start-delay=5s \ op monitor interval=30s timeout=60s on-fail=restart \ op stop interval=0s timeout=60s on-fail=block crm# show L7DRCTOR1 crm# commit
crm# primitive PINGD ocf:pacemaker:ping \ params name=pingd_score host_list="192.168.1.254 192.168.1.253" multiplier=100 \ op start interval=0s timeout=60s on-fail=restart \ op monitor interval=10s timeout=30s on-fail=restart \ op stop interval=0s timeout=60s on-fail=ignore crm# show PINGD crm# commit
UltraMonkey-L7 のドキュメントでは ocf:pacemaker:ping でなく pingd を使う記述になってるが、より進化した ping のほうを使うことにした。LANケーブルの抜線によるフェイルオーバー試験でも、pingd ではどうしてもフェイルオーバーがトリガーされてくれず、ping に差し替えるとうまくいった。
pacemaker:ping リソースエージェントは、fping バイナリがシステムにインストールされていると、ping コマンドでなく fping コマンドを使うようにできている。筆者の検証では、host_list に複数のターゲットを指定した場合に、ping コマンド動作ではうまく動かなかった。fping のRPMパッケージは RepoForge からダウンロードできる。
crm# primitive DISKD ocf:pacemaker:diskd \ params name=local_disk_status device=/dev/sda3 interval=10 \ op start interval=0s timeout=60s on-fail=restart \ op monitor interval=10s timeout=60s on-fail=restart start-delay=30s \ op stop interval=0s timeout=100s on-fail=ignore crm# show DISKD crm# commit
Linux-HA JAPANの提供するこのリソースエージェントは、上記の pingd のように特定のIPアドレスに対して ping 確認をするのだが、フローティングIPが存在していないことを確認するためのものなので、ping が飛ぶと false、飛ばないと true を返す。なので、定義した途端活性化してエラーになるが、びっくりしてはいけない。もう言うまでもなく、target_ip に指定するのは先に作った FIP1 のIPアドレスだ。
crm# primitive VIPCHK1 ocf:heartbeat:VIPcheck \ params target_ip=192.168.1.30 count=1 wait=10 \ op start interval=0s timeout=90s on-fail=restart start-delay=4s crm# show VIPCHK1 crm# commit
リソースエージェントの単体テストの手段が用意されている。ocf-tester というコマンドだ。例えば、
# ocf-tester -v -n VIPCHK1 \
-o target_ip=192.168.1.30 -o count=1 -o wait=10 \
/usr/lib/ocf/resource.d/heartbeat/VIPcheck
とやると、VIPcheck の動作がテストできる。なお、VIPcheck の場合、先ほど言ったように、フローティングIPを停止しておかないと 1 (false) が返ってきてしまうので、テストの前に `crm resource stop FIP1' で FIPリソースを停止しておくのを忘れずに。
ocf-testerを介してリソースエージェントを走らせるとデバグオプションが有効になるようなのだが、pacemaker:ping の場合、デバグ出力ルーティンが不足しているため、せっかく ocf-tester に掛けても何が行われているのか分かりにくい。差分を採っておいたので当てていただくといいだろう。
リソース制約 (Constraints) とは、クラスタリソース間の依存関係や、どのノード上で優先的に活性化させるかなどといった規定のことだ。先に定義した FIP衝突チェックリソースや、ネットワーク経路死活確認リソースも、ちゃんと役に立つかどうかはリソース制約にかかっている。
まず、ノード間を一団となって移動できるよう、ロードバランサの最前線リソースをグループにまとめる。
crm# group GrpBalancer VIPCHK1 FIP1 L7DRCTOR1
全てのノードで同時に活性化するリソースを、クローンしておく。
crm# clone PINGD-clone PINGD crm# show PINGD-clone crm# clone DISKD-clone DISKD crm# show DISKD-clone crm# clone L7VSD-clone L7VSD crm# show L7VSD-clone crm# commit crm# end crm# status
ひとつのノード上で一緒に活性化すべきリソースを定義。「GrpBalancer は必ず、PINGD-clone の活性化しているノード上で活性化すべき」等々。
crm# configure crm# colocation col-GrpBalancer-with-PINGD inf: GrpBalancer PINGD-clone crm# colocation col-GrpBalancer-with-DISKD inf: GrpBalancer DISKD-clone crm# colocation col-GrpBalancer-with-L7VSD inf: GrpBalancer L7VSD-clone crm# show crm# commit
結果、cib 上には下記のようなパラメータとして登録される。
<rsc_colocation id="col-GrpBalancer-with-PINGD" rsc="GrpBalancer" score="INFINITY" with-rsc="PINGD-clone"/> <rsc_colocation id="col-GrpBalancer-with-DISKD" rsc="GrpBalancer" score="INFINITY" with-rsc="DISKD-clone"/> <rsc_colocation id="col-GrpBalancer-with-L7VSD" rsc="GrpBalancer" score="INFINITY" with-rsc="L7VSD-clone"/>
1行目で言うと、クラスタはまず PINGD-clone をどのノード上で活性化するか判断する。そして、GrpBalancer をその同じノード上で活性化する。そのノードで PINGD-clone が活性化できなければ、GrpBalancer も活性化できない。ただし、GrpBalancer が活性化できなかったとしても PINGD-clone を敢えて停止したりはしない。
活性順の制約。例えば L7VSD は GrpBalancer より先に活性化されなければならない。symmetrical 属性は、true だと停止する際の順序が開始時とは逆になる。
crm# order order-PINGD-then-GrpBalancer \ mandatory: PINGD-clone GrpBalancer symmetrical=false crm# order order-DISKD-then-GrpBalancer \ mandatory: DISKD-clone GrpBalancer symmetrical=false crm# order order-L7VSD-then-GrpBalancer \ mandatory: L7VSD-clone GrpBalancer symmetrical=true crm# order order-VIPCHK1-then-FIP1 \ mandatory: VIPCHK1 FIP1 symmetrical=true crm# order order-FIP1-then-L7DRCTOR1 \ mandatory: FIP1 L7DRCTOR1 symmetrical=true crm# show crm# commit
4~5行目による cib エントリを以下に示す。
<rsc_order first="VIPCHK1" id="order-VIPCHK1-then-FIP1" score="INFINITY" symmetrical="true" then="FIP1"/> <rsc_order first="FIP1" id="order-FIP1-then-L7DRCTOR1" score="INFINITY" symmetrical="true" then="L7DRCTOR1"/>
この2エントリによって3つのリソースの依存関係を定義している。order constraint の1エントリは2つのリソースの関係性しか定義できないので、このように分けて設定する。活性化の際には VIPCHK1 を FIP1 より先に活性化し、非活性化の際には逆に FIP1 -> VIPCHK1 の順で停止される。VIPCHK1 を活性化しようとした時に既に FIP1 が活性だった場合には、FIP1 を停止し再活性化してから VIPCHK1 が活性化される。VIPCHK1 が活性化できない場合には FIP1 も活性化されない。2つのエントリの複合によって、開始時: VIPCHK1 -> FIP1 -> L7DRCTOR1、停止時: L7DRCTOR1 -> FIP1 -> VIPCHK1 という依存関係が構成される。
ここまで、ほとんど制約エントリ毎ばらばらに、しかも all or nothing でしか効果を解説してこなかったが、実際には、順序制約やコロケーション制約などそれぞれの重み(score) と、リソース毎のプライオリティ (リソースのmeta要素のpriority属性) が総合計算されて最終的な動作が決定するようだ。Cluster Labs の Ordering Explained や Colocation Explained という文書が理解の助けになるが、筆者のようなエセ理系脳ではまだ理解しきれない。
crm# location loc-GrpBalancer GrpBalancer \ rule $id=loc-GrpBalancer-primary 200: #uname eq centos6u \ rule $id=loc-GrpBalancer-slave 100: #uname eq centos6u2 \ rule $id=loc-GrpBalancer-ping-ng -inf: \ not_defined pingd_score or pingd_score lt 200 \ rule $id=loc-GrpBalancer-localdisk-ng -inf: \ not_defined local_disk_status or local_disk_status eq ERROR crm# show crm# commit crm# quit
意味はこうだ:
GrpBalancer リソース(グループ)は、なるべくノード名=centos6u 上で起動させたい(スコアが高い)。
ノード名=centos6u2 上では、他の条件が合えば起動させてもよい(スコアが低い)。
cibのステータスに pingd_score 属性が存在しない(つまりocf:pacemaker:pingが活性化していない)か、
あるいは、pingd_score < 200 の時には、GrpBalancer リソースは活性化してはならない(スコアがマイナス無限大)。
ここでは pingd_score に要求する値を 200 にしている。これは、PINGDリソースの設定が、pingターゲット2ヶ所 x multiplier=100 だから。1ヶ所にしか飛ばさないように定義した場合は、100 にしないと常に false になってしまうので注意。
さあ、一通り設定が終わったので、クラスタをきれいに立ち上げなおす。
# service corosync restart # crm status # l7vsadm -l -n
本格始動。このバージョンの Pacemaker は corosync 経由でしか起動できない。
# service corosync restart # chkconfig corosync on
実験を効果的にモニタするには、クラスタの状態をオンタイムで表示してくれる crm_mon をひとつのターミナルで起動しておく。
# crm_mon -f -V
さてここで、PINGD チェックが失敗するように、現在アクティブなノードで、ネットワークケーブルを抜くか、下記のような iptables ルールを投入して ping の着信を妨害してみる。
# iptables -A INPUT -p icmp -s 192.168.1.254 -j DROP
何も調整しない状態では、PINGD が1度失敗しただけで、リソースは別ノードへ移る。そして、iptables ルールを削除して再び ping 応答が受け取れるようにする。
# iptables -F INPUT
そうすると、何も命令しないのにリソースはまた最初のノードへ戻ってくる。この動きでいい場合もあるだろうが、実運用を考えるとあまり宜しくない。サービス提供が2度止まるし、障害条件によってはリソースがノード間を何度もシーソーしてしまう可能性があるからだ。
リソースに失敗が何回起こったらフェイルオーバーするかは、migration-threshold パラメータでコントロールできる。これはリソース毎に設定できるが、幾つものリソースに対して設定するのは手間が掛かるので、リソース全般のデフォルト値を変えてやる。例外にしたいリソースがあれば、個別に migration-threshold を設定すればそのリソースだけデフォルトをオーバーライドできる。失敗 2回までは同じノード上でリソースを再起動し、3回目でフェイルオーバーするようにするには、
# crm configure crm# rsc_defaults migration-threshold=3 crm# commit
失敗回数は cib に、ノード毎かつリソース毎に記録される。既定では自動リセットは行われない。つまり、制約と相まって、そのノードへはもうフェイルオーバーできない。この挙動を司るのが failure-timeout。1時間後にフェイルカウントがリセットされるようにするには、
crm# rsc_defaults failure-timeout=60m crm# commit
元いたノードが健常性を取り戻しても自動フェイルバックしないようにするには、resource-stickiness を変える。
crm# rsc_defaults resource-stickiness=INFINITY crm# commit
設定されたことを確認するには、
crm# show rsc-defaults-options
では、調整結果をテストしてみよう。PINGD は設定や疑似テストの方法によってはフェイルカウントが上がらないので、l7vsd デーモンを停止させる試験に切り替えてみるといいだろう。
# crm_mon -f -V
# service l7vsd stop
リソースが再起動されたのを crm_mon の画面で確認したら、あと2回、同様に l7vsd を stop してみる。フェイルオーバーが起こるはずだ。元いたノード上で L7VSD リソースのフェイルカウントを確認してみよう。
# crm resource failcount L7VSD show centos6u
L7VSDはL7VSD-clone としてクローンしてあるが、フェイルカウントはクローン元のリソース名と結びついて記録されるようだ。
1時間も待てないので今すぐフェイルカウントをリセットしたいと思うだろう。手動で即座にリセットするには、
# crm resource cleanup L7VSD [centos6u]
または、
# crm resource failcount L7VSD set centos6u 0
ちょっとクセがあるので触れておかなくてはならない。リソースを手動でマイグレーション(移動)させるには、
# crm resource move GrpBalancer [centos6u2]
ただし、移動後の状態にひとつ小難しい点があって、元いたノードに対して「もうこっちでは活性化させない」というlocation制約が立ってしまうのだ。この状態でも手動マイグレーションは可能で、もう一度手動マイグレーションをして居場所を戻せば、この制約は消去され、今度はさっきいたノードのほうにlocation制約が立つ。しかし、自動フェイルオーバーは阻害されてしまう。立ってしまったこの制約を取り除くには、
# crm configure crm# delete cli-standby-<RSC_NAME> [NODE] crm# commit
<RSC_NAME> の部分には当該のリソース名が付く。例えば cli-standby-GrpBalancer という具合だ。