Iptablesチュートリアル 1.2.2
 |
独自ドメインサイトへ移行しました。5秒後に https://straypenguin.winfield-net.com/ipttut/ へジャンプします。 |
Oskar Andreasson
Tatsuya Nonogaki - 日本語訳
Japanese translation v.1.0.1Copyright © 2001-2006 Oskar Andreasson
Copyright © 2005-2008 Tatsuya Nonogaki
この文書を、フリーソフトウェア財団発行の GNU フリー文書利用許諾契約書バージョン1.1 が定める条件の下で複製、頒布、あるいは改変することを許可する。序文とその副章は変更不可部分であり、「Original Author: Oskar Andreasson」は表カバーテキスト、裏カバーテキストは指定しない。この利用許諾契約書の複製物は「GNU フリー文書利用許諾契約書」という章に含まれている。
このチュートリアルに含まれるすべてのスクリプトはフリーソフトウェアです。あなたはこれを、フリーソフトウェア財団によって発行された GNU 一般公衆利用許諾契約書バージョン2の定める条件の下で再頒布または改変することができます。
これらのスクリプトは有用であることを願って頒布されますが、*全くの無保証* です。商業可能性の保証や特定の目的への適合性は、言外に示されたものも含め全く存在しません。詳しくはGNU 一般公衆利用許諾契約書をご覧ください。
あなたはこのチュートリアルと共に、GNU 一般公衆利用許諾契約書の複製物を一部受け取ったはずです。もし受け取っていなければ、フリーソフトウェア財団まで請求してください(宛先は the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA)。
献辞
僕はこのドキュメントを僕の素晴らしい妹と姪、それに義弟に捧げる。彼らは僕を応援し、インスピレーションを与えてくれた。彼らは、なくてはならない幸せの源であり一筋の光だ。感謝!
それに、僕に執筆の励みを与え、以心伝心で世話をしてくれる Ninel に言葉を贈らないわけにはいかない。ありがとう。
そして、僕はこの作品を、とてつもなくきつい仕事をしている Linux 開発者達と維持管理者達に捧げたい。この素晴らしいオペレーティングシステムを世に送り出してくれている人々へ。
- Table of Contents
- 著者について
- 読み方
- 予備知識
- このドキュメントで用いる表記法
- <この日本語訳で用いる表記法>
- 1. 序章
- 1.1. なぜこのドキュメントを書いたか
- 1.2. どのようにして書いたか
- 1.3. このドキュメントで使う用語
- 1.4. まとめ
- 2. TCP/IPのおさらい
- 2.1. TCP/IPのレイヤー
- 2.2. IPの特徴
- 2.3. IPヘッダ
- 2.4. TCPの特徴
- 2.5. TCPヘッダ
- 2.6. UDPの特徴
- 2.7. UDPヘッダ
- 2.8. ICMPの特徴
- 2.9. ICMPヘッダ
- 2.9.1. ICMPエコー要求/応答
- 2.9.2. ICMP到達不能メッセージ (Destination Unreachable)
- 2.9.3. ソースクエンチ (Source Quench)
- 2.9.4. リダイレクト (Redirect)
- 2.9.5. TTL equals 0
- 2.9.6. パラメータ障害
- 2.9.7. タイムスタンプ要求/応答
- 2.9.8. インフォメーション要求/応答
- 2.10. SCTPの特徴
- 2.10.1. イニシャライズとアソシエーション
- 2.10.2. データの送信とコントロールセッション
- 2.10.3. シャットダウンと中止
- 2.11. SCTPヘッダ
- 2.11.1. SCTP共通ヘッダフォーマット
- 2.11.2. SCTPの一般ヘッダと共通ヘッダ
- 2.11.3. SCTP ABORTチャンク
- 2.11.4. SCTP COOKIE ACKチャンク
- 2.11.5. SCTP COOKIE ECHOチャンク
- 2.11.6. SCTP DATAチャンク
- 2.11.7. SCTP ERRORチャンク
- 2.11.8. SCTP HEARTBEATチャンク
- 2.11.9. SCTP HEARTBEAT ACKチャンク
- 2.11.10. SCTP INITチャンク
- 2.11.11. SCTP INIT ACKチャンク
- 2.11.12. SCTP SACKチャンク
- 2.11.13. SCTP SHUTDOWNチャンク
- 2.11.14. SCTP SHUTDOWN ACKチャンク
- 2.11.15. SCTP SHUTDOWN COMPLETEチャンク
- 2.12. TCP/IP宛先誘導型ルーティング
- 2.13. まとめ
- 3. IPフィルタリングとは
- 3.1. IPフィルタとは何か
- 3.2. IPフィルタリングの用語と表現
- 3.3. IPフィルタの計画の仕方
- 3.4. まとめ
- 4. ネットワークアドレス変換とは
- 4.1. NATの利用目的と用語解説
- 4.2. NAT使用時の注意点
- 4.3. 概念を理解するためのNATマシン構築例
- 4.3.1. NATマシン構築に必要なもの
- 4.3.2. NATマシンの配備位置
- 4.3.3. プロキシの配置の仕方
- 4.3.4. NATマシン構築の最終段階
- 4.4. まとめ
- 5. 準備
- 5.1. iptablesの入手先
- 5.2. カーネルのセットアップ
- 5.3. ユーザ空間のセットアップ
- 5.3.1. ユーザ空間アプリケーションのコンパイル
- 5.3.2. Red Hat 7.1 でのインストール
- 5.4. まとめ
- 6. テーブルとチェーンの道のり
- 6.1. 全般
- 6.2. mangleテーブル
- 6.3. natテーブル
- 6.4. Rawテーブル
- 6.5. filterテーブル
- 6.6. ユーザ定義チェーン
- 6.7. まとめ
- 7. ステート機構
- 7.1. はじめに
- 7.2. conntrackエントリ
- 7.3. ユーザ空間でのステート
- 7.4. TCPコネクション
- 7.5. UDPコネクション
- 7.6. ICMPコネクション
- 7.7. デフォルトのコネクション
- 7.8. 追跡除外コネクションとrawテーブル
- 7.9. 複雑なプロトコルとコネクション追跡
- 7.10. まとめ
- 8. 大きなルールセットの保存とリストア
- 8.1. 速度に関する考察
- 8.2. restoreの欠点
- 8.3. iptables-save
- 8.4. iptables-restore
- 8.5. まとめ
- 9. ルールの作り方
- 9.1. iptablesのコマンドの基本
- 9.2. テーブル
- 9.3. コマンド
- 9.4. まとめ
- 10. iptablesのマッチ
- 10.1. 汎用的なマッチ
- 10.2. 暗黙的なマッチ
- 10.3. 明示的なマッチ
- 10.3.1. Addrtypeマッチ
- 10.3.2. AH/ESPマッチ
- 10.3.3. Commentマッチ
- 10.3.4. Connmarkマッチ
- 10.3.5. Conntrackマッチ
- 10.3.6. DSCPマッチ
- 10.3.7. ECNマッチ
- 10.3.8. Hashlimitマッチ
- 10.3.9. Helperマッチ
- 10.3.10. IP rangeマッチ
- 10.3.11. Lengthマッチ
- 10.3.12. Limitマッチ
- 10.3.13. MACマッチ
- 10.3.14. Markマッチ
- 10.3.15. Multiportマッチ
- 10.3.16. Ownerマッチ
- 10.3.17. Packet type マッチ
- 10.3.18. Realmマッチ
- 10.3.19. Recentマッチ
- 10.3.20. Stateマッチ
- 10.3.21. TCPMSSマッチ
- 10.3.22. TOSマッチ
- 10.3.23. TTLマッチ
- 10.3.24. Uncleanマッチ
- 10.4. まとめ
- 11. iptablesのターゲットとジャンプ
- 11.1. ACCEPTターゲット
- 11.2. CLASSIFYターゲット
- 11.3. CLUSTERIPターゲット
- 11.4. CONNMARKターゲット
- 11.5. CONNSECMARKターゲット
- 11.6. DNATターゲット
- 11.7. DROPターゲット
- 11.8. DSCPターゲット
- 11.9. ECNターゲット
- 11.10. LOGターゲット
- 11.11. MARKターゲット
- 11.12. MASQUERADEターゲット
- 11.13. MIRRORターゲット
- 11.14. NETMAPターゲット
- 11.15. NFQUEUEターゲット
- 11.16. NOTRACKターゲット
- 11.17. QUEUEターゲット
- 11.18. REDIRECTターゲット
- 11.19. REJECTターゲット
- 11.20. RETURNターゲット
- 11.21. SAMEターゲット
- 11.22. SECMARKターゲット
- 11.23. SNATターゲット
- 11.24. TCPMSSターゲット
- 11.25. TOSターゲット
- 11.26. TTLターゲット
- 11.27. ULOGターゲット
- 11.28. まとめ
- 12. スクリプトのデバグ
- 12.1. デバグ、それは必要欠くべからざるもの
- 12.2. Bashデバグテクニック
- 12.3. デバグに役立つシステムツール
- 12.4. iptablesのデバグ
- 12.5. その他のデバグツール
- 12.6. まとめ
- 13. rc.firewallファイル
- 13.1. 例 rc.firewall
- 13.2. rc.firewallの解説
- 13.2.1. 設定オプション
- 13.2.2. 追加モジュールの初期ロード
- 13.2.3. procの設定
- 13.2.4. 各種チェーンへのルール配置
- 13.2.5. デフォルトポリシーの設定
- 13.2.6. filterテーブルにユーザ定義チェーンを作る
- 13.2.7. INPUTチェーン
- 13.2.8. FORWARDチェーン
- 13.2.9. OUTPUTチェーン
- 13.2.10. natテーブルのPREROUTINGチェーン
- 13.2.11. SNATの開始とPOSTROUTINGチェーン
- 13.3. まとめ
- 14. スクリプト例
- 14.1. rc.firewall.txtスクリプトの構造
- 14.1.1. 構造
- 14.2. rc.firewall.txt
- 14.3. rc.DMZ.firewall.txt
- 14.4. rc.DHCP.firewall.txt
- 14.5. rc.UTIN.firewall.txt
- 14.6. rc.test-iptables.txt
- 14.7. rc.flush-iptables.txt
- 14.8. Limit-match.txt
- 14.9. Pid-owner.txt
- 14.10. Recent-match.txt
- 14.11. Sid-owner.txt
- 14.12. Ttl-inc.txt
- 14.13. Iptables-save ruleset
- 14.14. まとめ
- 15. iptables/netfilter用グラフィカルユーザインターフェイス
- 15.1. fwbuilder
- 15.2. Turtle Firewall プロジェクト
- 15.3. Integrated Secure Communications System
- 15.4. IPMenu
- 15.5. Easy Firewall Generator
- 15.6. まとめ
- 16. Linux, iptables及びnetfilterをベースとした製品
- 16.1. Ingate Firewall 1200
- 16.2. まとめ
- A. 特別なコマンドの詳細解説
- A.1. 稼働中のルールセットのリストアップ
- A.2. テーブルのアップデートとフラッシュ
- B. よくある問題と質問
- C. ICMPタイプ
- D. TCPオプション
- E. その他の資料とリンク
- F. 謝辞
- G. History
- H. GNU Free Documentation License
- I. GNU General Public License
- J. スクリプト例コードベース
- Index
- List of Tables
- 2-1. SCTPタイプ
- 2-2. エラー原因コード
- 2-3. INITの可変長パラメータ
- 2-4. INIT ACK の可変長パラメータ
- 6-1. ローカルホスト (我々のマシン) を宛先とするパケット
- 6-2. ローカルホスト (我々のマシン) を送信元とするパケッ ト
- 6-3. フォワードパケット
- 7-1. ユーザ空間でのステート
- 7-2. 内部ステート
- 7-3. サポートされている複雑なプロトコル
- 9-1. テーブル
- 9-2. コマンド
- 9-3. オプション
- 10-1. 汎用的なマッチ
- 10-2. TCPマッチ
- 10-3. UDPマッチ
- 10-4. ICMPマッチ
- 10-5. SCTPマッチ
- 10-6. アドレスタイプ
- 10-7. Addrtypeマッチオプション
- 10-8. AHマッチオプション
- 10-9. ESPマッチオプション
- 10-10. Commentマッチオプション
- 10-11. Connmarkマッチオプション
- 10-12. Conntrackマッチオプション
- 10-13. DSCPマッチオプション
- 10-14. ECNマッチオプション
- 10-15. IP内のECNフィールド
- 10-16. Hashlimitマッチオプション
- 10-17. Helperマッチオプション
- 10-18. IP rangeマッチオプション
- 10-19. Lengthマッチオプション
- 10-20. Limitマッチオプション
- 10-21. MACマッチオプション
- 10-22. Markマッチオプション
- 10-23. Multiportマッチオプション
- 10-24. Ownerマッチオプション
- 10-25. Packet typeマッチオプション
- 10-26. Realmマッチオプション
- 10-27. Recentマッチオプション
- 10-28. Stateマッチオプション
- 10-29. TCPMSSマッチオプション
- 10-30. TOSマッチオプション
- 10-31. TTLマッチオプション
- 11-1. CLASSIFYターゲットオプション
- 11-2. CLUSTERIPターゲットオプション
- 11-3. CONNMARKターゲットオプション
- 11-4. CONNSECMARKターゲットオプション
- 11-5. DNATターゲットオプション
- 11-6. DSCPターゲットオプション
- 11-7. ECNターゲットオプション
- 11-8. LOGターゲットオプション
- 11-9. MARKターゲットオプション
- 11-10. MASQUERADEターゲットオプション
- 11-11. NETMAPターゲットオプション
- 11-12. NFQUEUEターゲットオプション
- 11-13. REDIRECTターゲットオプション
- 11-14. REJECTターゲットオプション
- 11-15. SAMEターゲットオプション
- 11-16. SECMARKターゲットオプション
- 11-17. SNATターゲットオプション
- 11-18. TCPMSSターゲットオプション
- 11-19. TOSターゲットオプション
- 11-20. TTLターゲットオプション
- 11-21. ULOGターゲットオプション
- C-1. ICMPタイプ
- D-1. TCPオプション
著者について
Iptablesチュートリアルの著者は xxxx年に生まれ...
なんて、冗談はやめておこう。僕は 8 歳の時のクリスマスプレゼントで最初のコンピュータ Commondore 64 をもらった。C-1541 ディスクドライブの付いたやつで、8 ドットのドットプリンタと幾つかのゲームソフトも一緒だった。父は、なんとか動くところまで漕ぎ着け、二日掛かりで遂にゲームをロードする術を会得し、一人でもできるように僕にやり方を教えてくれた。今思えば、これが僕のコンピュータ漬け人生の始まりだった。その時点ではまだ、ほぼゲームで遊ぶだけ。しかし、何度かおもしろ半分で C-64 ベーシック言語もいじってみたりした。数年後には、Amiga 500 を手に入れた。主にゲームと宿題に使いながら、いじくり回した。その次は Amiga 1200 だ。
1993年か1994年のある日、父は Amiga には (残念ながら) 明日はないということを悟った。明日があるのは PC、i386だと。僕の涙の訴えも空しく、父は 50MHz の 486 と 16MB の RAM を積んだ Compaq PC を買い与えた。これがまさしく最悪の設計で、スピーカーからモニタから何から何まで一体化されていた。一世を風靡していた Apple のデザインを真似たつもりだろうが、見事に失敗していた。とはいえ、このマシンこそ、僕を本格的にコンピュータにのめり込ませたマシンだったことは間違いない。コーディングを本格的にやりだしたのも、インターネットを使い始めたのも、最初に実際に Linux をインストールしたのもこのマシンだった。
僕はもう長いこと、熱烈な Linux ユーザであり Linux アドミニストレータだ。僕の Linux 経験は、知り合いから借りた CD でインストールした slackware とともに 1994 年に始まる。この初めてのインストールはほとんど実験的なものだった。全く未経験なため、モデムやら何やらを動作させるだけでえらく時間が掛かった。しかもデュアルブートで別の OS を温存していた。2回目のインストールは circa 1996 だったが、メディアを持っていなかったので 28k8 モデムで slackware の A, AP, D, Nディスクを FTPダウンロードする羽目になった。グラフィカルインターフェイスからは何も学べないと悟っていた僕は、基本に立ち戻った。コンソールあるのみ。svgalib こそあれ、X11 もグラフィックもかなぐり捨てた。顧みれば、この経験がどれほど役に立ったかは疑うべくもない。何かを学ぼうと思ったら、やるしかない状態に自分を追い込んでしまうのが一番ではないだろうか。勉強するしかなかった。そんな状態でほぼ 2年が過ぎた。それからやっと、 XFree86 をスクラッチでインストールした。24時間掛かってやっとコンパイルした挙げ句、設定が出鱈目だったことに気づいて、また一からコンパイルしなおす羽目になった。人間、間違いはつきものだ。間違いは起こる時には起こるものであって、慣れるしかない。それに、こつこつと積み上げていくプロセスは忍耐というものを教えてくれる。急がば回れというやつだ。
2000年から2001年、僕はニュースサイトを運営する或る小集団の一員だった。内容は Amiga 関係のニュースが中心だったが、Linux やその他コンピュータ全般についても扱っていた。 BoingWorld という名称で、サイトは www.boingworld.com にあった (残念ながら今はもう見られない)。当時、カーネル 2.3 がリリース間近で、カーネル 2.4 が姿を現そうとしていた。その中に、今までのコンセプトをほぼ一新するファイヤーウォールが盛り込まれていることを僕は知った。確かに僕も ipfwadm や ipchains は或る程度触ったことがあったが、突き詰めてやった経験はなかった。また同時に、そのドキュメントがほとんどないに等しいということに気づいた。そこで、boingworld に iptables のチュートリアルを書いてみてはどうかと思ったわけだ。有言実行、僕は今あなたの読んでいるものの最初の 5〜10ページを書いた。これがスマッシュヒットとなり、新しい材料をチュートリアルにどんどん加えていった。当初のページはもうこのチュートリアル/ドキュメントには影も形もない。しかしコンセプトは今も引き継がれている。
僕は幾つかの企業で仕事をし、Linux やネットワークの管理をしたり、ドキュメントを書いたり、教材を作ったり、iptables や netfilter やその他諸々に関する質問の Email をくれた数千とは言わないまでも数百人の人たちをサポートしてきた。2度の CERTconf に参加し、それぞれのカンファレンスで 3つのプレゼンテーションを行った。Netfilter ワークショップ 2003 にも参加した。iptables チュートリアルを維持していくのはきつい仕事で、時には虚無感に襲われることさえあるのだが、出来上がってみれば、僕はその仕上がりに満足しているし、作り上げたことを誇りに思っている。筆を持っているこの 2006 年暮れまで、このプロジェクトが数年間に渡ってほとんど休止状態だったことは残念に思う。来年は状況を変え、たくさんの人がこの作品を長きにわたって役立つものと認めて、有用なドキュメントのひとつに加えてくれることを願っている。
読み方
当ドキュメントはリファレンス辞書として使ってもらってもいいし、頭から通して読んでもらってもいい。この文書は、当初は iptables と、少々だが netfilter を紹介するだけの小さなドキュメントだった。しかし、その目的は年月を経て変化し、今では、iptables および netfilter について可能な限り幅広く網羅したリファレンスであると同時に、少なくともこの領域を理解するために必要となる基礎知識を、的を絞って学習あるいはおさらいしてもらおうという内容となっている。断っておかなければならないのは、このドキュメントは iptables と netfilter の内外どちらのバグについては扱わないし、今後も扱うことはないという点だ。同様に、そういったバグへの対処法にも触れることはない。
iptablesやそのサブコンポーネントにバグやおかしな挙動を見つけた時は、Netfilter メーリングリストに上げてほしい。そうすれば、それが本当にバグなのかや、既に修正されているかどうか、答えが得られるだろう。 iptables と Netfilter にもセキュリティ関係のバグは存在し、時たま 1 個か 2 個のバグも紛れ込むことはある。それは避けられないことだ。こういった話は Netfilterのメインページにきちんと書いてあるので、そこで調べていただくといいだろう。
ひいては、このチュートリアルで網羅しているルールセットも、 Netfilter 内のバグを踏まえたものにはなっていないことになる。ここで示すルールセットの目的は、我々が遭遇するであろう課題に対処するためのルールを、なるべくきれいでシンプルにセットアップするやり方を示すことだ。例えば、 HTTP ポートを閉じる方法は扱っていない。理由は単純、これは Apache 1.2.12 がたまたま持っている脆弱性の問題だからだ (実際のところ網羅しているのだが、それは別の理由から)。
このドキュメントは、iptables をこれから始めるに人たちに質の高いシンプルな下地を提供することを目的としている。しかし同時に、iptables について可能な限り幅広く網羅するよう努めている。この文書では patch-o-matic に含まれるターゲットやマッチは網羅していない。理由は単純で、patch-o-matic リストのアップデートに合わせていくのは大変な労力だからだ。 patch-o-maticアップデートに関する情報が知りたければ、 patch-o-matic に付属する info や、 Netfilterのメインページに載っている他のドキュメントを読んでほしい。
漏れている項目や、iptables と netfilter に関する間違いや問題点を見つけた気がしたら、気兼ねなく知らせてほしい。僕は喜んで目を通すし、不足している事柄は追加させていただくかもしれない。
予備知識
このドキュメントを理解するには、カーネルのコンパイル方法やカーネル内部に関する知識の他、Linux/Unix とシェルスクリプティングについて、或る程度の予備知識を必要とする。
ドキュメントの大枠を把握するところまでは、可能な限り予備知識の必要性を排除したつもりだが、まったく無しで理解できるようにするのは無理な話だ。
このドキュメントで用いる表記法
当ドキュメントでは、コマンド、ファイル、その他特定の事柄に関して、以下のような表記を行う。
長文となるコードの引用とコマンドの出力は、下記のように表す。スクリーンのダンプや、コンソールから採った長い出力例もこれに含まれる。
[blueflux@work1 neigh]$ ls default eth0 lo [blueflux@work1 neigh]$コマンドとプログラムの名称は太字 (bold) で表す。タイプするコマンド全体やその一部もこれに含まれる。
ハードウェアなどのシステムアイテム、カーネルの内部構造、ループバックインターフェイスなどシステムの論理アイテムは イタリック (Italic) で示す。
コンピュータの出力は、テキスト内で this way のような様式で書く。つまりコンピュータがコンソールへ出力するもの全てがこれに該当する。
ファイルシステム上のファイル名とパスは /usr/local/bin/iptables のように表す。
<この日本語訳で用いる表記法>
訳者は、Linux のドキュメントの翻訳物にありがちな「直訳」は本当の意味での正確な訳ではないと考えました。そのため、多少、元の構文を無視して意訳的な訳し方をした部分もあります。こうすることで、著者の表したかったことが、より正確に伝わるものと信じています。それでも、言語および言語習慣の違いから、どうしても言い表せない、あるいは、言い表そうとすれば日本語とはかけ離れた奇妙で読みにくい文章になってしまう部分もあります。そういった場合には、以下のような補足を織り込むことにしました。
[訳者註: ] または省略して [: ] は、訳者が加えた補足事項で、原文にはありません。
(masquerading) のように ( ) で囲まれた英語句は、その直前の訳語が原文でどう書かれているかを示しています。ネットワークの常識として把握しておくべき語句だったり、設定時やログメッセージなどで実際に出くわす機会があるため英語表記を知っておいたほうがいい場合などに用いています。
Chapter 1. 序章
1.1. なぜこのドキュメントを書いたか
何というか、出回っている HOWTO には、Linux 2.4.x カーネルの iptables と Netfilter の機能に関して、情報がすっぽり抜けていると感じたから。特に、ステート (state) マッチングのような新しい機能について沸き上がるであろう疑問に対しては、できるだけ答えるようにしていこう。その大部分は、 /etc/rc.d/ のスクリプトとして使える rc.firewall.txt を使って解説していく。そう、お気づきの方もおられようが、このファイルは masquerading HOWTO のものをベースにしている。
また、実際僕にも経験のあることだが、設定がぐちゃぐちゃになってしまった時のために、小さなスクリプト rc.flush-iptables.txt も用意しておいた。
1.2. どのようにして書いたか
このチュートリアルは boingworld.com に書いたほんの短い文書に端を発している。それは数年前に、僕を含めた少人数のメンバーで運営していたニュースサイトで、 Amiga や Linux、その他の全般的な事柄を扱うものだった。沢山の読者を得て多くのコメントが寄せられたのに元気づけられて、僕は執筆を続けた。初めは印刷すると A4 で 10〜15 ページほどの分量だったが、少しずつ、しかし着実にボリュームアップしていった。それはもう沢山の人たちが、執筆、校正、バグチェックなどを手伝ってくれた。この文章を書いている時点で、http://iptables-tutorial.frozentux.net/ は延べ 600,000 ヒットを数えるに至った。
このドキュメントは、セットアップの行程を順を追って案内していく流れを採っている。そうすることで、 iptables パッケージを少しでもよく理解してもらう手助けになればと思う。 iptables の使い方を学ぶには例を見るのが一番だと思うので、ほとんどの要素は、例 rc.firewall ファイルに集約したつもりだ。僕は、まず基本的なチェーン構造をカバーし、そこから、パケットの通っていくチェーンのひとつひとつを記述していくことで、スクリプトの働きを説明することにした。このやり方だと、より論理的である反面、チュートリアルについていくのはやや難しくなるかもしれない。[訳者補足: スクリプトで] 理解しにくいところが出てきたら、いつでもこのチュートリアルに戻ってくればいい。
1.3. このドキュメントで使う用語
事前説明の必要な用語は、このドキュメントにはわずかしかない。このセクションでは、主立った用語と、それをドキュメント中で使う理由を説明する。
コネクション -- (Connection) このドキュメントにおいてのこの語彙は、相互に関わりを持つパケットの集まりを指す。パケット同士は、確立済み (established) の関係となるわけだ。コネクションはまた、一連のパケットの遣り取りだとも言える。 TCP 接続で言えば 3 ウェイハンドシェイクを踏んで接続を確立することを主に指し、切断のためのハンドシェイクが完了するまでがひとつのコネクションと解釈される。
DNAT -- 宛先ネットワークアドレス変換 (Destination Network Address Translation)。 DNAT とは、パケットの宛先IPアドレスを変換する技術、または変えること自体を指す。 SNAT と組み合わせて、インターネット上でルーティング可能な 1 個の IPアドレスを複数のホストでシェアしたり、サーバサービスを提供したりするのに用いられる。これは通常、インターネット上でルーティング可能な 1 個の IPアドレスに対して、別のポートを振り直し、 Linux ルータに宛先を指示することにより行われる。
IPSEC - インターネット・プロトコル・セキュリティ (Internet Protocol Security) は IPv4 パケットを暗号化してインターネットへ安全に送信するためのプロトコル。 IPSEC についてもっとよく知りたければ、付録 その他の資料とリンク を参照して他の資料を探してみるといいだろう。
カーネル空間 -- (Kernel space) いわば、ユーザ空間の反意語。カーネルの内側での出来事、カーネルの外でないところで起こるあらゆる事象を指す。
パケット -- (Packet) ネットワーク伝送の最小単位であり、ひとつのヘッダとデータ部から成る。例えば IP パケットや TCP パケットがある。インターネットの規約 (Request For Comments = RFC) では、 IP パケットを表すにはデータグラム (datagram)、 TCP パケットにはセグメント (segment) という呼び名が使われるが、"パケット"という言葉は普遍化されていない。僕は、物事を単純化するために、このドキュメント内ではどれもこれもパケットと呼ぶことにした。
QoS - サービス品質 (Quality of Service) とは、特定のパケットの送信に際してパケット処遇の優先度や提供する品質を指定するひとつの方法だ。この話題に関しては チャプター TCP/IPのおさらい でも述べているし、付録 その他の資料とリンク からは外部資料にアクセスすることができる。
セグメント -- (Segment) TCPセグメントは "パケット" とほぼ同義だが、 TCP パケットを表す時の "かしこまった" 呼び方。
ストリーム -- (stream) この語句は、某かの意味で互いに関係性のあるパケットをやりとりする接続を指す。僕は元来、2つ以上のパケットを双方向に送るあらゆる接続に対してこの語句を使ってきた。つまり TCP においては、SYN を送り SYN/ACK で応答することを意味するが、SYN を送り ICMP Host unreachable を受け取ることも、やはりこの語句に当てはまる。非常に曖昧に使う、とも言える。
SNAT -- 送信元ネットワークアドレス変換 (Source Network Address Translation)。パケットの送信元アドレスを変換する技術のこと。 IPアドレスの枯渇 (IPv6が救うだろう) に瀕した現在、この技術よって、ひとつの IPv4インターネットIPアドレスを複数のホストで共有可能にしている。
ステート -- (state) この語句は、パケットがどの状態にあるかを指す。状態とは RFC 793 - Transmission Control Protocol に照らして言う場合もあるし、 Netfilter/iptables で使用されるユーザ空間上での状態を言う場合もある。憶えておいてほしいのは、iptables の利用するステート は、カーネル内外のどちらのステート も、 RFC793 の定義とは異なるという点だ。その主たる理由は、 Netfilter が接続とパケットについてあれこれと推測を行うためそれらを駆使する必要があるからだ。
ユーザ空間 -- (User space) 僕はこの語句で、カーネルの外で起きるあらゆる事柄を指す。例えば、iptables -h はカーネルの外だが、iptables -A FORWARD -p tcp -j ACCEPT はルールセットに新たなルールを加えるので (部分的にしても) カーネル内の出来事だ。
ユーザランド -- (Userland) ユーザ空間を参照のこと。
VPN - バーチャル・プライベート・ネットワーク (Virtual Private Network) は、非プライベートなネットワーク上 (インターネットなど) で、プライベートなネットワークを仮想的に形成する技術のこと。 VPN を形成するそうした技術のひとつに IPSEC がある。 OpenVPN もそのひとつだ。
1.4. まとめ
このチャプターは、当ドキュメントをなぜ、どうやって書いたのかをざっと見ていただいた。また、このドキュメントのそこここに現れる主な用語についても説明した。
次のチャプターは、TCP/IP に関するいささか長大な事始め とおさらいだ。そこで扱うのは基本的に、iptables と netfilter で利用される IPプロトコルとそのサブプロトコルであり、TCP, UDP, ICMP, SCTP が含まれる。SCTP は、他のものに比べると新参の規格なので、まだ馴染みのない人たちのために、かなりのページと時間を割いた。また、今日使われている基本的なルーティング及び高度ルーティングの技術についても幾らか述べている。
Chapter 2. TCP/IPのおさらい
iptables は知識のあるなしで大違いのツールだ。別の言い方をすれば、 iptables をフル活用するにはそれなりの知識が必要だということだ。中でも TCP/IP プロトコルには充分に精通している必要がある。
このチャプターは、とにかく TCP/IP についての「必須知識」を解説するために設けた。先へ進んで iptables と取っ組み合うのはそれからだ。ここでは特に、 IP, TCP, UDP, ICMP プロトコルとそのヘッダについてと、それぞれの用途の違い、それに、各プロトコル同士の関係について、駆け足で見ていく。 iptables はインターネット層とトランスポート層で働く。それ故に、このチャプターではそれらのレイヤー [訳者註: 層] にも焦点を当てる。
iptables はより表層のレイヤーで機能することも可能で、例えばアプリケーション層で作用することもできる。だが、 iptables は本来、そうした用途は意図しておらず、そんな使い方をすべきではない。それについては IPフィルタリングとは のチャプターでもう少し詳しく述べることにしよう。
2.1. TCP/IPのレイヤー
先にも述べたように、 TCP/IP は多層構造になっている。ということは、或る層でひとつの機能を働かせながら、別の層で別の機能を働かせ、そしてまた別の層で...ということが可能なわけだ。レイヤー構造を持つ意義は、考えてみれば単純だ。
多層構造となっている最も大きな理由は、拡張を容易にするため。例えばアプリケーション層に新たな機能を追加したい時にも、わざわざ TCP/IP スタックのコードを書き直したり、アプリケーション側に TCP/IP スタックの一切合切を装備しなくても済む。同様に、新しいネットワークインターフェースカードを創るたびにプログラムを逐一書き直すなんてことも必要ない。各レイヤーは独立して働けるように、他のレイヤーのことには必要最小限だけ関知していればいいようになっているのだ。
| カーネルの備える TCP/IP プログラミングコードについて語る時、実はそれは TCP/IP スタックのことを言っている場合が多い。 TCP/IP スタックとは、ネットワークアクセス層から表層のアプリケーション層に至るまでの、サブレイヤー一切合切のことである。 |
レイヤーの話をする時、大元となる構造定義がふたつある。ひとつは OSI (Open Systems Interconnect) 参照モデルで、これは TCP/IP を 7 層に分けている。ただし、我々の興味はどちらかというと TCP/IP 階層モデルのほうにあるので、ここではざっと眺める程度にしておこう。しかし、歴史的な意味から、OSI参照モデルにも興味深い点はある。特に、さまざまな種類の異なるネットワークを扱わなければならない場合だ。 レイヤーは OSI参照モデルの の一覧に示した通りだ。
| どちらの参照モデルが広く使われているかについては、意見が分かれている。ただ、どちらかといえば OSI 参照モデルのほうが未だに優勢なように見える。とはいえ、事情は国によっても異なる。US および EU の大多数の国においては、技術者や営業の会話の中で使うなら OSI を基本と考えるほうがいいようだ。 しかしながら当文書では、特に断りのない限り、一貫して TCP/IP 参照モデルのほうで話を進める。 |
アプリケーション層 (Application layer)
プレゼンテーション層 (Presentation layer)
セッション層 (Session layer)
トランスポート層 (Transport layer)
ネットワーク層 (Network layer)
データリンク層 (Data Link layer)
物理層 (Physical layer)
我々がひとつのパケットを送ったとすると、そのパケットはリストの上方から下方へと進み、それぞれのレイヤーが、カプセル化 (encapsulation) と呼ばれる段階で各々独自のヘッダ一式をくっつける。そして目的地へ行き着くと、今度はリストを逆順に辿り、パケットからヘッダが一個一個取り除かれていく。取り除かれる際、各ヘッダは、パケット内のデータから目的のホストの得るべき情報を全て渡していく。そうして遂に、送信目的だったアプリケーションあるいはプログラムに辿り着くわけだ。
もうひとつの、そして我々にとって、より重要な意味を持つレイヤーモデルが、 TCP/IP構造モデルだ。それを一覧にしたのが下記の TCP/IP 構造リスト。 TCP/IP構造モデルの階層数については、これといった共通認識は存在しない。とはいえ、3 ないし 5 層から成るというのが一般的な認識となっていて、図解や説明がなされる時には、たいてい 4 層として扱われているようだ。混乱を避けるため、このドキュメントでも、一般的な 4 層モデルのみを対象に話を進める。
アプリケーション層 (Application layer)
トランスポート層 (Transport layer)
インターネット層 (Internet layer)
ネットワークアクセス層 (Network Access layer)
見ての通り、 TCP/IP の構造は OSI参照モデルとそっくりだ。だが、まだそう断じるのは早計だ。入る時、出る時に、ヘッダをくっつけたり取り去ったりするのは OSI参照モデルの時と同じだ。
では、最近よくコンピュータネットワーキングの比喩に用いられるスネイルメールの手紙に喩えてみよう。[訳者註: snail-mail: 昔ながらの紙の手紙のこと。 eメールの普及によって逆に最近生まれた言葉]。物事にはすべて順序がある。 TCP/IP も同じだ。
ご機嫌伺いの手紙を送ろうとしているとしよう。まず初めに、内容あるいは質問する事柄を考えなければならない。実際のデータで言えば、これはアプリケーション層に置かれることになる。
そうしたら次に、便箋に内容を書いて封筒に入れ、どこの会社あるいはどこの家の誰かさん宛てだという旨を封筒に書くはずだ。例えばだが、おそらくこんな風に:
ジョン・ドー 様
これは TCP/IP で言うところのトランスポート層にあたる。トランスポート層で、今仮に TCP を相手にしているとすれば、必ずというわけではないがこれは何らかのポートナンバー (例えば 25 など) かもしれない。
ここで、今度は封筒に受取人の住所を書く。こんな具合だ:
V. Andersgardsgatan 2
41715 Gothenburg
これはインターネット層にあたる。インターネット層は、 TCP/IP ネットワーク上のどこへ行けば受取人つまりホストへ行き着けるかを示す情報を格納する。ちょうど、封筒に書く宛名と同じ。つまり、'192.168.0.4' といった IPアドレスがこれにあたる。
そして最後のステップは、この封筒に収まった手紙をポストへ投函する作業だ。これとほぼ同義なのが、パケットをネットワークアクセス層へ送り込むこと。ネットワークアクセス層は、パケットの搬送される物理的なネットワークにアクセスするための、機能や手順を含有している。
受取人は、封書を受け取ったら、封筒から手紙を取り出すだろう (つまり非カプセル化(decapsulate))。受け取った手紙には返事が必要かもしれないしそうでないかもしれない。いずれにしろ、返信するとすれば、受け取った人は、手紙に書いてあった宛先と差出人を逆にして送るだろう。差出人が宛先に、宛先だった人が差出人になるようにするわけだ。
| ここで頭に入れておかなければならないのは、 iptables はインターネット層 とトランスポート層 のヘッダに作用するべく作られているということだ。確かに、基本的フィルタの中にもアプリケーション層 やネットワークアクセス層 で使えるものがある。しかし、こうした事柄は iptables の設計意図から外れるものだし、 iptables はそういう用途に向くようには作られていないのだ。 例えば string マッチを使ってパケットの中の文字列、例えば "GET /index.html" でパケットを捕まえるとしよう。これはうまくいくだろうか? 普通は YES だ。だが、パケットのサイズが非常に小さい時にはそうはいかない。これは iptables がパケット単位で作用するように作られているからで、もしも文字列が複数のパケットへと分断されていたとしたら、 iptables はそれを一続きの文字列として検出することができない。そうした理由から、アプリケーション層 でのフィルタリングを行うという用途であれば、プロキシなど別のものを使うほうがずっとずっと確実だ。こうした問題については、 IPフィルタリングとはで詳しく考察する。 |
iptables および netfilter の活動の舞台は主にインターネット層 とトランスポート層 なので、当チャプターのこれ以降のセクションでも、主としてそれらの層に焦点を当てていく。インターネット層 の配下には、 IP プロトコルという無視しがたい存在がある。その他に、例えば GRE プロトコルのように、言及すべきものもなくはないが、そうしたプロトコルに出会う機会は限られている。また、 iptables は (その名が示す通り) その種のプロトコルを上手に扱うようには作られていない。上に挙げた様々な理由から、このドキュメントでは主に、インターネット層 の IP プロトコルと、トランスポート層 の TCP, UDP, ICMP に焦点を当てていく。
| ICMP プロトコルは、実はふたつのレイヤーが混じり合ったものだ。 ICMP パケットはインターネット層 で活動するものでありながら、 IP プロトコルと全く変わらないヘッダを持ち、その他幾つかのヘッダに加え、カプセルのすぐ内側にはデータも格納している。これについては ICMPの特徴 の中でもっと詳しく述べることにする。 |
2.2. IPの特徴
既に述べたように、 IP プロトコルはインターネット層 に属している。 IP プロトコルは TCP/IP スタックのうちで、コンピュータやルータ、スイッチなどにパケットの行き先を教える役割を担うプロトコルだ。 IP プロトコルこそ、 TCP/IP スタックの心臓部であり、インターネットの土台を支えているプロトコルである。
IP プロトコルはトランスポート層 のパケットをカプセル化 (encapsulate) し、使用されているトランスポート層プロトコルの種別、行き先および送信元のホスト情報をはじめ、その他幾つかの有用な情報を格納する。この処理は全て、微に入り細に入り規格化がなされている。こうした厳格さは、当チャプターで述べていくいずれのプロトコルにも当てはまることだ。
IP プロトコルには、必ず備えなければならない幾つかの基本的機能が定められている。 IP プロトコルは、データグラムつまり、トランスポート層 の作る次の建屋を用意できなくてはならない (トランスポート層 とは例えば TCP, UDP, ICMP のいずれか)。 IP プロトコルはまた、今日我々がお世話になっているインターネットの住所指定の仕組みも司る。つまり、 IP プロトコルはホスト間を往き来する方法を定め、それ故に当然、パケットをルーティングできるのも IP プロトコルのおかげというわけだ。ここで話題にしている住所 (address) とは、いわゆる IPアドレス のこと。通常我々が "IPアドレス" と言う時、ドット区切りの 4つの数字 (例えば 127.0.0.1) を指す。ただし、この形式は専ら人が見て読みやすいようにするためのもので、 IPアドレスの実体は 32 ビット長の 1 と 0 の羅列でしかない (即ち 127.0.0.1 なら、実際のヘッダ上では 01111111000000000000000000000001 と書かれている)。
IP プロトコルがその袖口で演ずるべきマジックはこれだけではない。 IP データグラム (IPデータ) をカプセル化および非カプセル化できる能力、ネットワークアクセス層 とでもトランスポート層 とでもデータを遣り取りできる能力だ。これはことさら目につく働きではないかもしれない。しかしそれ以上に、 IP プロトコルには果たさなければならない更にふたつの重要な機能がある。しかもファイヤーウォール構築とルーティングに関わり合う人なら興味を惹かれずにいられない機能だ。 IP プロトコルは、ホストからホストへのパケットばかりでなく、どこかのホストから自分以外のホスト宛てのパケットが入ってきた際の動作も司っているのだ。ひとつのネットワークにしかアクセスしないホストであれば、処理はほとんどの場合至って単純だ。選択肢はふたつしかない。自分につながっているローカルネットワーク行きのパケットか、デフォルトゲートウェイを通るパケットのどちらかだ。しかし、ひと度、複数のインターフェース、複数のルートを持つマシンでファイヤーウォールやセキュリティポリシーを触り始めると、途端にネットワーク管理者は頭痛がしてくる。 IP プロトコル最後の機能は、既にフラグメントされているデータグラムを再フラグメントしたり再構成したり、自分の近隣のネットワークのハードウェアトポロジーに合わせてフラグメントする能力だ。パケットのフラグメントサイズが目に見えて小さい場合にもやはり、ファイヤーウォール管理者は酷い頭痛に悩まされることとなる。パケットが粉微塵にフラグメントしているがために、肝心のデータグラムばかりか、パケットヘッダを読み取るのにさえ支障を来しているわけだ。
 | 2.4 シリーズの Linux カーネルおよび iptables では、 Linux でファイヤーウォールを運営する上でこれはもはや問題とはならなくなった。 iptables がステートマッチングや NAT に使用するコネクション追跡メカニズムは、フラグメントされたパケットを読む必要がある。そのため、パケットがカーネルの netfilter/iptables 構造部に届く以前に conntrack が全てのパケットのデフラグメンテーションを行うからだ。 |
IP プロトコルのもうひとつの特質は、コネクションレスなプロトコルであるという点だ。つまり、 IP は接続に際しての "ネゴシエーション (negotiation = 折衝)" を行わない。これに対して、コネクション指向のプロトコルは、コネクションのネゴシエーション (ハンドシェイク と呼ばれる) を行い、データを全て送り終えたら接続の解消を行う。 TCP はそういったプロトコルの一例だが、 TCP は IP プロトコルよりひとつ上の層だ。 IP 層の段階でコネクション指向にしない理由はいろいろあるが、取り立てて言えるのは、このレベルで敢えて不要なオーバーヘッドを伴うハンドシェイクを実装する意味がないからだ。その重荷は他のプロトコルに背負ってもらえばいい。オーバーヘッドは、返答が得られない場合には伝送経路のどこかでパケットが失われたと判断し、当初のリクエストを送信しなおす、という処理から生じる。お察しの通り、この場合、リクエストを送って一定の時間だけ回答を待つほうが賢い。でなければ、まずコネクション開始の要望を知らせるパケットを送り、次にコネクションが開いたと告げる知らせのパケットを受け取り、続いてコネクションが開いたことを確かに承知しましたという承認を行い、ここでやっとこさ当の目的のリクエストを送り、そうしたらコネクションを切断するためのパケットを更に送りその返事を待つ、という手間になってしまうのだ。
IP はまた、低信頼性 の (unreliable) プロトコルとしても知られる。簡単に言えば、パケットが届いたのか届かなかったのかには無頓着なのだ。 IP プロトコルはただ単純にトランスポート層 からパケットを受け、やるべきことだけやったらネットワークアクセス層 へ渡して、それでおしまい。返答のパケットが来るかもしれないが、それがネットワークアクセス層 から IP プロトコルへとやってくると、 IP はまたやるべきことをやり、上のトランスポート層 へと渡す。しかし、返事のパケットが来るのかパケットが行き先まで届いたのかにはお構いなしだ。 IP のこの低信頼性についても、先ほどの "コネクションレスさ" と同様のことが言える。なぜなら、低信頼性を何とかしようとすれば、パケットを送るたびに追加のパケットが必要となるからだ。 DNS 検索を例に採ってみよう。通常やるように、 servername.com を牽こうと DNS リクエストを送信する。返答が得られなければ、何か手違いがあったと考えてルックアップを再要求する。しかし通常は、リクエストを 1回送り、回答を 1回受けて終わりだ。信頼性を高めようと思ったらどうなるか。リクエストには 2回のパケットを要し (リクエスト 1回と、パケット到着確認 1回)、返答も 2回要る (回答 1回と、回答の領収の通知で 1回)。つまり、送らなくてはならないパケットの数は倍になり、流れるデータの量もほぼ 2倍になってしまう。
2.3. IPヘッダ
IP プロトコルの概要を示した前章でお分かりかと思うが、 IP パケットはヘッダに幾つかの部位を備えている。ヘッダ全体は性質毎に細分化され、オーバーヘッドを可能な限り抑えるという命題のために、それぞれの部位は機能できる必要最小限にまでサイズが切り詰められている。 IP ヘッダの諸元は、図「IPヘッダ」 にある。
| ヘッダの部位に関する説明は、ほんのさわりに過ぎず、この先もその基本骨子にしか触れないという点を、ご承知おきいただきたい。これから各ヘッダについて述べる中で、当該のヘッダのより細かい説明を提供してくれる適切な RFC は紹介していく。補足の補足として書いておくが、 RFC は、Request For Comments [訳者註:「インターネット規約」と訳されることが多い。直訳すると「回答伺い」あるいは「回答募集中」] の意味だが、今日のインターネットコミュニティにおいては、名称とは全く異なる意味合いを持つようになった。研究者達が RFC を書き始めた当初とは違って、今の RFC はインターネットそのものを規定したり標準化するものとなっている。遡れば RFC はその名の通りコメントを要望する文書であり、自分の意見に対して他の研究者達に見解を乞う手段だったのである。 |
IP プロトコルについての大部分は RFC 791 に書かれている。ただし、 この RFC は RFC 1349 - Type of Service in the Internet Protocol Suite によって一部改訂 (update) され、その RFC 1349 はまた RFC 2474 - Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers によって廃版 (obsolete) とされ、その RFC 2474 は RFC 3168 - The Addition of Explicit Congestion Notification (ECN) to IP および RFC 3260 - New Terminology and Clarifications for Diffserv により一部改訂された。
| ご覧のように、こうした標準化文書は時として、追いかるのにかなり骨が折れる。関係する RFC 群を見つけるひとつの手は、 RFC-editor.org の備える検索機能を活用することだ。 IP の場合には、 RFC 791 が大元で、その他の RFC はそれを改訂したり変更を加えているに過ぎない。そうしたことについては、以降で扱うヘッダの中で、新しい RFC によって変更されたものが出てきた時に、その都度詳しく述べる。 ひとつ憶えておいてほしいのは、 RFC は廃版にされる (もう一切使われなくなる) ことがあるという点だ。そうなるのは大抵、その RFC が大幅に変わり、丸ごと置き換えたほうが得策だと判断された時。別の理由で廃版にされる場合もある。廃版となった RFC には、それに取って代わった新しい RFC を指し示す文言が書き添えられる。 |

バージョン (Version) - ビット 0-3。これは IP プロトコルのバージョンナンバーを 2進数で表している。 IPv4 は 0100、 IPv6 は 0110 で表される。このフィールドがフィルタリングに使われることはほとんど無い。 RFC 791 に書かれているのは IPv4 のほうだ。
IHL (インターネットヘッダ長 Internet Header Length) - ビット 4-7。このフィールドは IPヘッダ の長さを 32ビット毎のワード数で示したもの。お分かりの通り、 IP ヘッダの図はこれに倣って 1行当たり 32ビットとなるようヘッダを区切ってある。 Options フィールドは自由長なので、この IHL フィールド無しにはヘッダ全体の長さを特定することができない。このヘッダの長さは最小 5 ワードだ。
サービスタイプ (Type of Service), DSCP, ECN - ビット 8-15。ここは IPヘッダ の中でも最も難解な部分。というのも、3度にも渡って変更されてきたからだ。いずれの改訂でも基本的な用途こそ変わらなかったものの、実装方法が度々変更になった。まず最初、このフィールドはサービスタイプ (Type of Service) フィールドと呼ばれていた。このフィールドのうちビット 0 からビット 2 までは優先区分 (Precedence) フィールドと呼ばれた。ビット 3 は遅延の中/低 (Normal/Low delay)、ビット 4 はスループットの中/高 (Normal/High throughput)、ビット 5 は信頼性の中/高 (Normal/High reliability) であり、ビット 6 から 7 は将来の用途のための未使用域とされていた。このヘッダは、現在でも旧式なハードウェアを運用している場所ではかなり使われており、そして相変わらずインターネットに弊害をもたらし続けている。特に、ビット 6 からビット 7 がゼロにセットされていなくてはならないという規定が問題だ。 ECN の改訂 (RFC) でこれらのビットが使われるようになり、ゼロ以外の値にセットするケースが出てきたからだ。ところが、旧型のファイヤーウォールやルータの中には、これらのビットが 1 になっていないかのチェック機構を内蔵しているものがあり、それに引っ掛かったパケットを破棄してしまうのである。そうした挙動は今日の RFC に完全に抵触しているわけだが、我々にできることはといえば悪態をつくことくらいのもので、為す術がないのが実情だ。
2度目のでんぐり返しである RFC 2474 によって、このフィールドは DS フィールドと呼ばれることになった。 DS は Differentiated Services を表す。この規格によれば、ビット 8-13 は Differentiated Services Code Point (DSCP) となり、残りの 2 ビット (14-15) は引き続き未使用だった。 DSCP フィールドの利用法は ToS フィールドの時とさほど変わらない。つまり、区別ができるようルータを設定しておけば、このフィールドを目印にしてパケット毎に処遇を切り替えられるというものだ。この改訂で大きく変わったのは、 RFC 2474 準拠であるためには、デバイスは未使用のビットを無視しなければならなくなったという点。これによって、デバイスを作る側がこの RFC に従う限りは、前の規格で格闘を余儀なくされていた難解な設定とはおさらばできるようになった。
ToS フィールドの 3度目であり実質的に最後の変更となったのが FRC 3168。それによって、以前は未使用だったふたつのビットが ECN (Explicit Congestion Notification = 明示的輻輳通知) に使用されるようになった。 ECN は、ルータが輻輳を起こした際、実際にルータがパケットを取りこぼし始める前に、末端のノードに輻輳を知らせる役目を持つ。このおかげで、末端のノードは、ルータが実際にデータを取りこぼす前にデータの送信速度を落とすことができる。この規格ができるまでは、ルータにとっては、実際にデータを破棄するしか過負荷を知らせる術がなく、エンドノードはそれを見て速度を一旦がくんと落とし (slow restart)、破棄されたパケットをおもむろに送り直し、具合をみながら元のスピードまで上げていくという手段をとっていた。ふたつのビットは、 ECT (ECNCapable Transport) コードポイントと CE (Congestion Experienced) コードポイントと呼ばれる。
一連の堂々巡りの最後の変更は RFC 3260 で、 DiffServ 機構を使用する上での新しい用語の規定と、規格の明確化が行われた。この改訂は技術用語の類が主で、更新や変更はそれほど沢山盛り込まれていない。 RFC は開発者達の議論を経て要点を整理するという役割も持っているのだ。
全長 (Total Length) - ビット 16-31。このフィールドは、ヘッダをはじめ一切合切を含めたパケット全体のサイズをオクテット単位で示す。パケットひとつのサイズの上限は 65535 オクテット (=バイト)。到着した時点でパケットがフラグメントしているかどうかにかかわらず、最小サイズは 576 バイトだ [訳者註: フラグメントしている時の値は再構成後の合計サイズではなくフラグメント個々のサイズ]。 RFC 791 によれば、この制限を上回るサイズのパケットを送るのは、そのホストが必ず受け取れるという保証のある場合だけにすべきとされている (recommended)。ただし、今日ではほとんどのネットワークがパケットサイズを 1500 バイトにして運用している。ほぼ全てのイーサネット接続がそうだし、ほとんどのインターネットコネクションもそこに含まれる。
識別子 (Identification) - ビット 32-46。このフィールドはパケットフラグメントの再構成を手助けするためにある。
フラグ (Flags) - ビット 47-49。このフィールドはフラグメンテーションに関するその他のフラグを含んでいる。最初のビットは予約済みだが、まだ使用されておらず、ゼロになっていなければならない。 第2 ビットは、パケットをさらにフラグメンテーションしてもよい場合は 0 に、それ以上のフラグメンテーションを許さない場合には 1 にセットする。 3番目 (つまり最後) のビットは、これが最終フラグメントであれば 0 、同一パケットに属するフラグメントが他にもあるなら 1 にセットする。
フラグメントオフセット (Fragment Offset) - ビット 50-63。フラグメントオフセットは、そのパケットが元のデータグラムのどの位置にあたるのかを表す。フラグメントは 64 ビットで計算される。最初のフラグメントのオフセットは 0 である。
Time to live - ビット 64-72。 TTL フィールドが示すのは、そのパケットがどれだけ生きられるか。もう少し具体的に言うと、インターネットの中を何回 "ホップ" できるかだ。パケットに触れた各プロセスは TTL を必ず 1 ずつ奪い取っていき、もし TTL がゼロになったらそのパケットはかけらも残さず破棄されなくてはならない。この仕組みは、パケットがホスト間で制御不能のループを引き起こさないようにするための、一種の安全装置である。破棄の際には、ホストは送信者へ ICMP の Destination Unreachable メッセージを送るべきとされている (should)。
プロトコル (Protocol) - ビット 73-80。このフィールドには上位レイヤーのプロトコルが記載される。一部を挙げれば TCP, UDP, ICMP などである。それらを示すナンバーは Internet Assigned Numbers Authority (IANA) で規定されている。ナンバーの全てはホームページ Internet Assigned Numbers Authority で調べることができる。
ヘッダチェックサム (Header checksum) - ビット 81-96。そのパケットのヘッダのチェックサムだ。ヘッダに変更を加えたホストはこのフィールドを必ず再構成しなければならない。実際のところ、パケットの通り道となったホストは TTL フィールドをはじめパケットのどこかをほぼ必ずいじるので、再計算はほとんどのホストで行われると思って間違いない。
送信元アドレス (Source address) - ビット 97-128。送信元アドレスを示すフィールド。我々が普段目にする時にはたいてい、2進数から 10進数に変換して間をドットでつないだ 4 オクテットの値として表される。例えば 127.0.0.1 といった具合だ。このフィールドはパケットがどこから来たのかを受信者に伝える。
宛先アドレス (Destination address) - ビット 129-160。 Destination address フィールドは宛先のアドレスを格納しているが、あらビックリ、フォーマットは送信元アドレスと同じだ。
オプション (Options) - ビット 161-192<>478。名前の響きとは裏腹に、オプションフィールドの存在は任意ではない。正直なところ、このフィールドは IP ヘッダの中でもかなり複雑な部類。オプションフィールドは、インターネットタイムスタンプ、SACK、レコードルートオプション (record route options) などといった様々なオプションセッティングを格納するヘッダだ。これらの値を持つかどうかは全て任意なので、オプションフィールドの長さも可変であり、結果として IP ヘッダ自体の長さも変化することになる。ただし IP ヘッダでは常に 32 ビットを 1 ワードとして扱うため、ヘッダは必ず 32 の倍数となる偶数で終わらなければならない。このフィールドは 0 個以上のオプションを持つことができる。
オプション フィールドは 8 ビット長の短いフィールドから始まり、その部分はパケットでどういったオプションが用いられているかを知らせる。付録 TCPオプション の TCPオプション という表に全オプションを挙げておいた。各オプションの詳細を知りたければ、該当する RFC を読んでいただきたい。 IPオプション リストの最新情報は Internet Assigned Numbers Authority で調べるといいだろう。
パディング (Padding) - ビット可変。ここは、ヘッダが 32 ビット境界で終わるように調整するための詰め物。このフィールドは頭から終わりまでゼロばかりが並んでいなければならない。
2.4. TCPの特徴
TCP プロトコルは IP プロトコルのひとつ表層に位置する。 TCP はステートフル (stateful) なプロトコルであり、データがもう一方のホストまで届いたかどうかを確認する機能を自ら備えている。 TCP プロトコルの主な目的は、データが信頼性を損なうことなく受送信されたかを確認することであり、また、データがインターネット層 とアプリケーション層 との間で正しく伝搬されたかどうか、パケットデータがアプリケーション層 において適切なプログラムにきちんと渡ったか、プログラムに正しい順序で届いたかを確認することである。これらはいずれも、パケットに TCP ヘッダがあるからこそ実現できていることなのだ。
TCP プロトコルは、データを、開始の合図と終了合図を持つ一続きのデータストリームとして捉えている。新たなストリームが通路の開くのを待っているということを表すのが、 TCP の SYN スリーウェイハンドシェイクであり、これは SYN ビットの立ったひとつのパケットから成る。相手方は、コネクションを受け入れたなら SYN/ACK、拒絶したと知らせるなら SYN/RST で回答する。クライアントは、受け取ったのが SYN/ACK だったら、もう一度、今度は ACK パケットを送る。この時点でコネクションが確立し、データが送れる状態になる。この TCP コネクションの間じゅう変わらず使われる ECN, SACK などといったコネクション固有のオプションも、この最初のハンドシェイクで話し合って取り決め (negotiate) がなされる。
データストリームの活動中には、パケットが相手にきちんと届いたかを確かめる更なる仕組みがある。 TCP の高信頼たる部分だ。これはパケット内のシーケンスナンバー (Sequence number) を使って理路整然と行われる。パケットを送信する時には、その度に シーケンスナンバーを必ず更新して送り、受け取った相手方は送り主に ACK パケットを返す。 ACK パケットはパケットを確かに受け取ったという受領の証 (acknowledge) だ。シーケンスナンバーはまた、パケットがデータストリーム内に順番通りに挿入されたことを保証する役目もしている。
コネクションを閉じる際には、一方が FIN パケットを送ることによって処理が始まる。すると相手は FIN/ACK パケットを送信する。 FIN を送った方はもう何のデータも送らないが、もう一方の相手はまだ残りのデータがあれば送りきることができる。後者は、いよいよコネクションを完全に閉じていい状態になると、初めに終局を言い出した方の端末に向かって FIN パケットを送る。そうすると前者が FIN/ACK パケットで応える。こうした一連の手順が完了して初めて、コネクションは正式に切断されるのだ。
後で触れることになるが、 TCP ヘッダにはチェックサム というものもある。チェックサム はパケットの単純なハッシュ値だ。このハッシュを使って、ホスト間の伝送中にパケットに損傷が起きたかどうかが、かなりの精度で検査できる。
2.5. TCPヘッダ
TCP ヘッダには、前述の役目を全て達成できる素養が求められる。幾つかのヘッダについては、それがいつ、どのように利用されるか既に説明したが、まだ明らかにしていない領域が他にも沢山ある。下に、 TCP ヘッダを全て網羅した図を示した。見ての通り、1 段を 32 ビットワードとした形になっている。
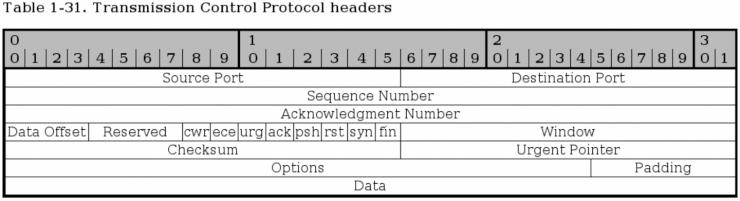
送信元ポート (Source port) - ビット 0-15。パケットの送信元ポート。元来は、送信元ポートはそれを送信したシステム上のプロセスを直接指し示すものだった。今日では、双方の IP アドレスから求めたハッシュ値と、宛先ポートおよび送信元ポートを併用して、各々のアプリケーション (プログラム) との一意性を確保している。
宛先ポート (Destination port) - ビット 16-31。 TCP パケットの宛先ポート。送信元ポートと同様に、元来は受信側システム上のプロセスを直接指し示していた。今日では、より多くのコネクションを同時に張れるよう、ハッシュ値が用いられる。パケットを受信したら、送信元への返答では宛先ポートと送信元ポートを逆さにする。つまり、元の宛先ポートが送信元ポート、送信元ポートが宛先ポートになるようにするわけだ。
シーケンスナンバー (Sequence Number) - ビット 32-63。シーケンスナンバーフィールドは各 TCP パケットに付け、 TCP ストリームが歯抜けにならないようにする (例えば、パケットが正しい順番で並ぶこと)。同じシーケンスナンバーは、パケットが問題なく届いたことを知らせるために、回答の際 ACK フィールドに載せて返される。
確認応答ナンバー (Acknowledge Number) - ビット 64-95。ホストの受け取った特定のパケットに対して承認を行う際に使用される。具体的に言えば、或るシーケンスナンバーを持ったパケットを受け取った時、パケットに特に問題がなかったら ACK パケットで承認の返事をするわけだが、その際、受け取ったパケットのシーケンスナンバーと同じ値をその確認応答ナンバーフィールドへセットして返答するのだ。
データオフセット (Data Offset) - ビット 96-99。このフィールドは、 TCP ヘッダの長さと、パケットのデータ部がどこから始まっているのかを示す。これは 4 ビットで表され、 TCP ヘッダを 32 ビットのワード単位で数えた値となる。ヘッダは、どんなオプションが使われていようとも常に 32ビット境界で終わっていなければならない。それを可能にしているのは、 TCP ヘッダの末端にあるパディングフィールド だ。
予約域 (Reserved) - ビット 100-103。これらのビットは将来の用途のために確保されている。 RFC 793 では、 CWR ビットと ECE ビットの位置もこの予約域こ規定されていた。 RFC 793 によれば 100-105 (つまり、ここと CWR および ECE フィールド) はゼロになっていなければ、規格に完全に整合しているとはいえないのだ。後になって ECN が提唱されると、多くのインターネットアプリケーション (例えばファイヤーウォールやルータ) がこの部分のビットの立ったパケットを破棄してしまうという障害を多発させる結果となった。こうして書いている今現在でも、この問題は継続している。
CWR - ビット 104。このビットは RFC 3268 で追加され、 ECN に利用されている。 CWR は Congestion Window Reduced を表し、データを送った側が受け取り側へ、輻輳制御ウィンドウ (congestion window) が縮小されたことを知らせるために利用される。輻輳制御ウィンドウ が縮小したら、我々は時間当たりの送信データ量を減らすことによってネットワーク負荷の総量の折り合いを付けることができる。
ECE - ビット 105。このビットも RFC 3268 で追加され、 ECN に利用されている。 ECE は ECN Echo を表す。 ECE は受信側の TCP/IP スタックによって使用され、 CE パケットを受け取った旨を送信側ホストに知らせる役目をする。ここでも CWR ビットと同じことが言え、ここがかつて予約済みフィールドだったことから、ゼロ以外の値を持つパケットは、ネットワーク機器によっては破棄されてしまう恐れがある。残念なことだが、実際、そうしたアプライアンスはまだまだ存在する。
URG - ビット 106。このフィールドは、緊急ポインタ (Urgent Pointer) フィールドを使用するべきか否かを伝える。 0 ならば緊急ポインタは使うな、 1 ならば緊急ポインタを使うべし、となる。
ACK - ビット 107。パケットにこのビットを立てるのは、そのパケットが他のパケットに対する返答であり、先ほどのパケットがデータをきちんと運んできたという旨を知らせる時だ。パケットを正しく受け取り、パケットに何のエラーもなかった場合には、そのことを伝えるために必ず確認応答 (Acknowledgement) パケットを送ることになっている。このビットが立っているのを見たら、先ほどデータを送った送り主は、確認応答ナンバー (Acknowledgment Number) を見て承認の対象がどのパケットかを確認した後、バッファに保持していたそのデータを破棄する。
PSH - ビット 108。プッシュ (PUSH) フラグは、経路途中のあらゆるホスト上の TCP プロトコルに対して、データをすぐに最終ユーザへ送れと告げるのが役目。 "ホスト上のTCP" には、データを受け取ることになるホストが実装する TCP 機構も含まれる。この指示が行われると、 TCPウィンドウ上に残留しているデータの量にかかわらず、全データが強制送出 (push) される。
RST - ビット 109。リセット (RESET) フラグをセットするのは、相手方へ TCP コネクションの切断を要求したい時だ。切断の行わる場面は幾つか考えられるが、代表的なのが、既にコネクションが存在しなくなっていたりパケットが不正なものだったりした時の強制断絶だ。
SYN - ビット 110。 SYN (Synchronize sequence numbers = 同期シーケンスナンバー) は、コネクションの初めの接続確立行程で使用される。 SYN はふたつの場面で使われる。ひとつはコネクションの皮切りのパケット、そしてもうひとつが返答の SYN/ACK パケットだ。 SYN フラグをこれ以外の場面で使用することは許されていない。
FIN - ビット 111。 FIN ビットは、FIN ビットを送ったホストはもう送るべきデータがない、ということを示す。 FIN ビットを受け取った相手は FIN/ACK で応える。このやりとりが行われると、先に FIN ビットを出したホストはもうデータを送ることができない。ただしもう一方は、送信しかけていたデータを最後まで送りきることはできる。送りきった後、ホスト [: 後者] は FIN パケットを返し、締めの FIN/ACK を待つ。この手順を経ることによって、コネクションは CLOSED ステートへと落ちる。
ウィンドウ (Window) - ビット 112-127。ウィンドウフィールドは、パケットを受け取る側が、その時点で受け取り可能なデータの量を送信側へ知らせるのが役目。これは ACK パケットによって行われるのだが、その ACK パケットには、先ほど受け取ったパケットの承認を示すシーケンスナンバー とともに、次の ACK パケットまでに送信側の指定可能なシーケンスナンバーの最大値がウィンドウフィールドとして記載される。次の ACK パケットにはまた新しいウィンドウが反映される。
チェックサム (Checksum) - ビット 128-143。このフィールドは TCP ヘッダ全体としてのチェックサムを格納している。チェックサムは、ヘッダ 16 ビット毎の相補 (one's complement = 1の補数) の和 (sum) を求め、それの相補を求めた値。もしもヘッダが 16 ビット境界で終わっていなければ、それ以降のビットはゼロで埋められる。チェックサムを計算している最中は、チェックサム 自体はゼロにしておく。チェックサム はまた、96 ビットの疑似ヘッダを内包し、この疑似ヘッダには、宛先アドレス、送信元アドレス、プロトコル、TCP パケット長が含まれる。チェックサム は TCP の信頼性を一段と高めるためにある。
緊急ポインタ (Urgent Pointer) - ビット 144-159。これは、緊急性の求められるデータの終端位置を指すポインタだ。受け取り側にいち早く処理してもらわなくてはならない重要なデータがコネクションに含まれている場合、送信側は、 URG フラグ を立てた上で、緊急ポインタ に緊急データの終端位置を示す。
オプション (Options) - ビット 160-**。オプションフィールド は可変長で、必須のもの以外に使いたいヘッダがあればここに入っている。このフィールドは必ず、大別すると 3つのサブフィールドから成っており、最初のフィールドはオプションフィールド の長さ、2番目は、どのオプションを使用しているか、そして最後にオプションそのものが来る。 TCPオプション の全種類は付録 TCPオプション で見られる。
パディング (Padding) - ビット **。 TCP ヘッダが 32 ビット境界で終わるように終端に詰め物 (padding) をするのがパディングフィールド の役割。これがあるおかげで、パケットのデータ部は 32 ビット境界から開始することができ、パケット内のデータを隈無く読んでもらえるのだ。詰め物は常に全部ゼロ。
2.6. UDPの特徴
UDP プロトコル (User Datagram Protocol) は、 IP プロトコルのひとつ表層に位置する非常にベーシックでシンプルなプロトコルだ。 UDP はいかなるエラー検出も伴わないシンプルなデータ伝送を目して開発された。とはいえ、問い合わせと回答で成り立つ類のアプリケーションにも適している。 例えば DNS などだが、 DNS では、 DNS サーバから回答が来なければ、それは自ずと問い合わせがどこかで失敗したことを示すからだ。 TCP よりも UDP プロトコルのほうが向いている場面は他にもある。例えば、エラーやロスは検知したいけれどもパケットの順序は気にしなくてもいい場合だ。そうすれば、 TCP プロトコルに付き物のオーバーヘッドを、ほとんど排除できる。また例えば、 UDP のひとつ上に、エラーやロスの検出機能は備えずシーケンス管理だけを行う独自のプロトコルを作るという利用法も考えられる。
UDP プロトコルは RFC 768 - User Datagram Protocol で規定されている。この RFC は極めて簡潔で、いかにもこのシンプルなプロトコルに似つかわしい。
2.7. UDPヘッダ
UDP の備えているヘッダは、 TCP ヘッダの基本部分を簡略化したようなものと言える。 UDP ヘッダに含まれるのは、下図に見るように、宛先ポート、送信元ポート、ヘッダ長、チェックサムである。

送信元ポート (Source port) - ビット 0-15。これはパケットの送信元となったポートであり、返信のパケットはそこ宛てに返されなければならない。特に当てはまらない時にはゼロにしてしまうことも可能だ。返答を必要としない状況というのもあるわけで、その場合にはパケットのソースポートをゼロにセットすることもある。ほとんどの実装では、ここには何らかのポートナンバーをセットする。
宛先ポート (Destination port) - ビット 16-31。パケットの宛先ポート。これは送信元ポートとは異なりどのパケットにも必須である。
全長 (Length) - ビット 32-47。レングスフィールドには、ヘッダ部もデータ部も含めたパケット全体の長さをオクテット単位で指定する。パケット長の最小は 8 オクテット。
チェックサム (Checksum) - ビット 48-63。チェックサムは TCP ヘッダのものとほぼ同様だが、持っているデータが異なる。具体的に言うと、 IPヘッダ、 UDP のヘッダおよびデータそれぞれの相補 (one's complement = 1の補数) の和から、その相補を求めたもので、必要であれば末尾がゼロでパディングされる。
2.8. ICMPの特徴
ICMP メッセージは、ホストどうしあるいはホスト-ゲートウェイ間でのごく基本的なエラー通知に利用される。ゲートウェイどうしのエラー通知では、ゲートウェイtoゲートウェイプロトコル (GGP) を使用すべきという考え方が一般的だ。既に見てきたように、 IP プロトコルの備えるエラー処理は完全ではないが、 ICMP メッセージはそうした問題の一部を解決してくれる。或る意味 ICMP の手強い点は、ヘッダがかなり複雑で、メッセージの種類毎にも微妙に異なるという点だ。しかし、フィルタリングの観点では、これが大きな問題となることはほとんどない。
ICMP メッセージの基本的なフォーマットは、通常通りの IP ヘッダと、タイプ (type)、コード (code)、チェックサム (checksum) を備える。これらはどの ICMP メッセージでも必ず持っている。タイプ は、そのパケットがどういった種類のエラーメッセージあるいは返答であるかという情報を表す。例えば destination unreachable や、 echo, echo reply, redirect といったメッセージだ。コード フィールドは、もし必要があれば、追加的な情報を指定する。仮にパケットのタイプが destination unreachable だとすれば、このコードフィールドは network unreachable, host unreachable をはじめとした何種類かの値を採り得る。チェックサム は単純にパケット全体のチェックサムだ。
お気づきの方もいると思うが、上で僕ははっきりと「ICMP パケットが "IPヘッダ" を持つ」と言った。なぜなら、実は ICMP パケットは IPヘッダ そのものを構成要素のひとつにしていて、或る意味、 IP プロトコルと同じ層で働いているとも言えるからだ。 ICMP は IP プロトコルを高次の別階層として利用しているとも言えるし、同時に、 IP プロトコルと同じ階層のプロトコルだとも言えるのだ。 ICMP は IP と渾然一体の関係にあり、故に、 IP を実装する際には必ず ICMP も実装する決まりになっている。
2.9. ICMPヘッダ
前にも述べたが ICMP のヘッダはメッセージのタイプ毎に少しずつ異なる。ほとんどの ICMP タイプはヘッダを基準にして幾つかのグループに分けることができる。そういうわけで、ここからは、まず初めに基本的なヘッダ形態について述べ、それから、特記すべきタイプグループ毎に特性を見ていくことにする。
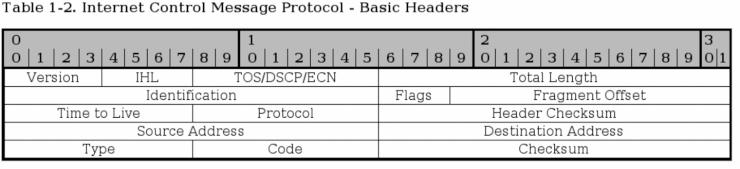
いずれのタイプのパケットも、基本的な IPヘッダ の値はもれなく持っている。IPヘッダ については既に述べたので、ここでは簡単なリストにちょっとしたコメントを添えるだけに留める。
バージョン (Version) - 必ず 4 となる。
インターネットヘッダ長 (Internet Header Length) - 32 ビット単位で数えたヘッダの長さ。
サービスタイプ (Type of Service) - 前記参照。 RFC 792 - Internet Control Message Protocol によればここに指定できる有効な値は 0 しかないので、必ず 0。
全長 (Total Length) - ヘッダとデータ部を合わせたパケット全体の長さ。単位はオクテット。
識別子 (Identification), フラグ (Flags), フラグメントオフセット (Fragment offsets) - IP プロトコルからコピーする。
Time To Live - そのパケットが生きていられるホップ (hop) 数。
プロトコル (Protocol) - 使用されている ICMP のバージョン (常に 1)。
ヘッダチェックサム (Header Checksum) - IP での説明 を参照のこと。
送信元アドレス (Source Address) - パケットを送ってきた者のアドレス。この表現は正確とは限らない。というのは、パケットに刻まれているアドレスが今問題にしているマシン上のものとは限らず、どこか別の所であることもあり得るからだ。そうした性格を持つ ICMP タイプについては適宜述べる。
宛先アドレス (Destination Address) - そのパケットの宛先アドレス。
どのタイプの ICMP でも必ず備えるヘッダには、ここで初登場する 2〜3 のものもある。それが以下。ここからはもう少し詳しいコメントを添えよう。
タイプ (Type) - タイプ フィールドはそのパケットの ICMP タイプを収めている。これには ICMP のタイプ毎に違った値がある。例えば ICMP Destination Unreachable パケットならばここにタイプ 3 が入る。 ICMPタイプ の全リストは付録 ICMPタイプ で見られる。このフィールドは全部で 8 ビット。
コード (Code) - コード も ICMP のタイプ によって異なる。あるタイプ ではひとつのコード しか指定できないが、何種類かのコード を指定できるタイプ もある。例えば ICMP Destination Unreachable (タイプ3) が採れるコード には少なくとも 0, 1, 2, 3, 4, 5 のバリエーションがある。組み合わせによってコード の示す意味が変わる。コード の全リストは付録の ICMPタイプ にある。このフィールドの長さは全部で 8 ビット。各コード についてはこのセクションの後半でもう少し詳しく述べる。
チェックサム (Checksum) - チェックサム は 16 ビット長のフィールドで、 ICMPタイプ をはじめとした全てのヘッダから求めた相補 (one's complement = 1の補数) の和の相補である。チェックサムの計算は、チェックサムフィールド自体の値をゼロにした上で行うことになっている。
ここから先は、ヘッダはパケットの種類によって違ってくる。よく出くわす ICMP タイプをひとつずつ取り上げ、そのヘッダとコードの違いを簡単に述べていくことにしよう。
2.9.1. ICMPエコー要求/応答

僕は、ここで ICMPエコー の応答パケット (reply) と要求パケット (request) をまとめて説明することにした。ふたつは極めて密接な関係にあるからだ。違いのひとつ目はまず、エコー要求 はタイプ 8 であり、エコー応答 はタイプが 0 だという点。或るホストがタイプ 8 を受け取れば、応答はタイプ 0 で行う。
応答パケットを送る際には、送信元アドレスと宛先アドレスも入れ替わる。そうした処理を全て行った後に、チェックサム を再計算してから返答が送信される。ただしそのどちらもコードはひとつに決まっており、常に 0 にセットされる。
識別子 (Identifier) - ここは要求パケットの時にセットされ、それに対する応答エコーの中で繰り返し使用される。複数の ping の中から要求と応答の対を見分けるためである。
シーケンスナンバー (Sequence number) - ホスト毎のシーケンスナンバー。通常 1 から始まり、パケットひとつ毎に 1 ずつ加算される。
パケットにはデータ部もひとつある。デフォルトではデータ部は通常は空だが、任意の量のランダムなデータを収容することもできる。
2.9.2. ICMP到達不能メッセージ (Destination Unreachable)

図に見られる最初の 3つのフィールドは前記と同じ。 Destination Unreachable のタイプでは、以下のリストのように、基本的に 16種類のコードを採る可能性がある。
コード 0 - Network unreachable (ネットワーク到達不能) - 指定されたネットワークへの到達が現在不能であることを知らせる。
コード 1 - Host unreachable (ホスト到達不能) - 指定されたホストへの到達が現在不能であることを知らせる。
コード 2 - Protocol unreachable (プロトコル到達不能) - このコードは指定されたプロトコル (tcp, udp など) への到達が現在できないということを知らせる。
コード 3 - Port unreachable (ポート到達不能) - このメッセージを受けるのは、ポート (ssh, http, ftp-data など) への到達ができない時。
コード 4 - Fragmentation needed and DF set (フラグメント必要だがDFフラグあり) - パケットをフラグメントする必要があるのだが "フラグメント不可" を表すビットがパケットにセットされている時に、ゲートウェイが返すメッセージ。
コード 5 - Source route failed (送信元指示によるルーティング失敗) - 送信元の指示によるルーティングが某かの理由で失敗に終わった時、このメッセージが返される。
コード 6 - Destination network unknown (宛先ネットワーク発見できず) - 指定されたネットワークまで達する経路がない時、このメッセージが返される。
コード 7 - Destination host unknown (宛先ホスト発見できず) - 指定されたホストまでの経路がない時、このメッセージが返される。
コード 8 - Source host isolated (発信元ホストへのルートなし)(廃) - ホストが孤立している場合にはこのメッセージを返すことになっている。当コードは旧式で今日では使われなくなった。
コード 9 - Destination network administratively prohibited - (宛先ネットワーク設定によりアクセス拒否) - 或るネットワークがゲートウェイでブロックされ、そのせいでパケットが対象のネットワークに到達できなかった場合、この ICMP コードが返ってくることになっている。
コード 10 - Destination host administratively prohibited (宛先ホスト設定によりアクセス拒否) - ホストが規制 (例えばルーティング規制) によってアクセス禁止となっているがために行き着けなかった時、返事としてこのメッセージが返ってくる。
コード 11 - Network unreachable for TOS (TOS種別によりネットワーク到達不能) - 送信したパケットの "不適切" な TOS のせいでネットワークまで届かなかった時、リターンパケットはこのコードで作られる。
コード 12 - Host unreachable for TOS (TOS種別によりホスト到達不能) - パケットの TOS のせいで送信パケットがホストまで届かなかった時、返事に受け取るのがこのメッセージ。
コード 13 - Communication administratively prohibited by filtering (フィルタリング設定により通信禁止) - 何らかのフィルタリング (例えばファイヤーウォール) によってパケットの着信が禁止されていた場合に、我々送信側はコード 13 を受け取る。
コード 14 - Host precedence violation (ホスト優先区分侵害) - このメッセージは第 1 ホップのルータが送ってくる。パケットの採用している優先区分 (precedence) が当該の宛先/送信元の組み合わせにおいては許容されないということを、接続してきたホストに伝える。
コード 15 - Precedence cutoff in effect (優先区分により遮断発動) - 渡されたデータグラムにセットされていた優先レベル (precedence level) が低すぎたた場合に、第 1 ホップのルータはホストへこのメッセージを送ってもよいことになっている (may)。
これに加えて、小さなデータ部を持つこともでき、その中身はインターネットヘッダ (IPヘッダ) のヘッダ全てと、元の IP データグラムのうちの 64 ビットを写したものとなる。次のレベルのプロトコルがポート定義などを持っているとすれば、この 64 ビットデータ部からそれが読み取れるはずである。
2.9.3. ソースクエンチ (Source Quench)

パケットまたはそのストリームの発信元に対して、送信を継続するのならパケットの送信間隔を緩めてくれと伝えるために、ソースクエンチパケットが送られることがある。ただし、パケットが渡り歩いていくそうしたゲートウェイやホストはソースクエンチパケットなど送らずに黙ってパケットを破棄しても構わないことになっている点に注意しなければならない。
このパケットには特別なヘッダはなく、データ部に特徴がある。そのデータ部は、元のデータのインターネットヘッダ と、データグラムのうちの 64 ビット分を格納している。それによって、そのソースクエンチメッセージが、問題のゲートウェイや宛先ホストを通じてデータを送ろうとしているどのプロセス に対するものなのかが、適切に割り出せる。
ソースクエンチパケットは ICMP タイプが必ず 4 である。コードは 0 しかあり得ない。
| ゲートウェイや宛先のホストの過負荷を送信ホストや受信ホストへ知らせるには、今日では 2〜3 種類の手段がある。そのひとつとして ECN (Explicit Congestion Notification = 明示的輻輳通知) という仕組みがある。 |
2.9.4. リダイレクト (Redirect)

ICMPリダイレクト パケットが使用されるケースはひとつしかない。こういう場合を考えてみよう。ここに、何台かのクライアントやサーバとふたつのゲートウェイを持つネットワーク (192.168.0.0/24) があるとする。ゲートウェイのひとつは 10.0.0.0/24 のネットワーク、もうひとつのゲートウェイはその他のインターネット全般へつながっている。さてここで、 192.168.0.0/24 内に、デフォルトゲートウェイは知っているが 10.0.0.0/24 へのルートを知らない 1 台のホストがあったとしよう。そのホストはパケットをデフォルトゲートウェイへ送る。デフォルトゲートウェイは当然 10.0.0.0/24 ネットワークの存在を知っている。デフォルトゲートウェイは、そのパケットはどうせ 10.0.0.0/24 のインターフェイスから出入りすることになるのだから、直接 10.0.0.0/24 用のゲートウェイへ送ったほうが早いと判断することができる。そこでデフォルトゲートウェイは、正しいゲートウェイを知らせる ICMPリダイレクト パケットをホストへと送り、先ほどのパケットは 10.0.0.0/24 のゲートウェイへ渡す。これによって問題のホストは 10.0.0.0/24 ゲートウェイという近道を知るので、うまくすれば次回からはそちらを使うようになるかもしれない、というわけだ。
リダイレクト タイプのパケットの主役となるヘッダはゲイトウェイインターネットアドレス (Gateway Internet Address) フィールドだ。このフィールドは、その時使用すべき適切なゲートウェイについての情報をホストに伝える。このパケットはそれ以外にも、元のパケットの IPヘッダ と、そのデータ部の初めの 64 ビット分も収めている。その情報は、当のリダイレクトパケットと、データを発したプロセスとを適切に結びつけるために利用される。
リダイレクト タイプは 4 種類のコードを採ることができる。それらを以下に挙げる。
コード 0 - Redirect for network - (上記の例のように) ネットワーク丸ごとのリダイレクトである時にだけ使用される。
コード 1 - Redirect for host - 特定のホストに関するリダイレクトの際にだけ使用される (例えばホストルーティング)。
コード 2 - Redirect for TOS and network - サービスタイプとネットワーク丸ごとのリダイレクトの際にのみ使用される。意味合いとしてはコード 0 と同じだが TOS にも関係している場合だ。
コード 3 - Redirect for TOS and host - サービスタイプとホストのリダイレクトである時に使用される。つまり、扱いとしてはコード 1 と同じだが TOS にも絡んでいる場合だ。
2.9.5. TTL equals 0

TTL equals 0 の ICMP タイプは別名 "時間超過メッセージ (Time Exceeded Message)" とも呼ばれる。セットされるタイプは 11 で、コードは 2 種類のうちから選べる。ゲートウェイでの伝送過程や宛先ホストでのフラグメント再構成中に TTL フィールドが 0 に達してしまった場合には、そのパケットは破棄されなければならない。パケットを送ってきたホストにそれを知らせるために使うのが TTL equals 0 の ICMP パケットだ。これにより送信者は、今度そこへパケットを送る必要が生じた時にはパケットの TTL を大きくしよう、と判断することができる。
このタイプのパケットは付加データ部だけを備える。このデータフィールドには、元のパケットのインターネットヘッダ と 64 ビット分のデータが入っており、相手方はその情報を頼りに送信元となったプロセスを正しく割り出すことができる。先にも述べたように、 TTL equals 0 タイプは 2 種類のコードを採ることができる。
コード 0 - TTL equals 0 during transit - いずれかのゲートウェイで転送を行おうとした時点で TTL が 0 になった場合に、このコードが送信元ホストへ送られる。
コード 1 - TTL equals 0 during reassembly - パケットがフラグメントされており、その再構成中に TTL が 0 に達してしまった場合に、このコードが送られる。このコードは最終目的地のホストからしか送られてこない。
2.9.6. パラメータ障害

パラメータ障害 (parameter problem) の ICMP はタイプ 12 を使用し、 2 種類のコード値も採り得る。パラメータ障害メッセージは、ゲートウェイか受信ホストがエラー等によって IPヘッダ の一部を理解できない場合や、必要とされるオプションが見あたらない場合に、送信元のホストにそれを知らせるために使用される。
パラメータ障害 タイプの ICMP メッセージは或る特殊なヘッダを備える。それは、元のパケットにおけるエラー原因フィールドへのポインタだ (コードが 0 の場合)。有効なコードを以下に述べる:
コード 0 - IP header bad (IPヘッダ異常)(全てのエラーを包括) - これは、上述したような全てのエラーを包括したエラーメッセージだ。このコードをポインタと組み合わせると、エラーが IPヘッダ のどの部位にあるかを伝えることができる。
コード 1 - Required options missing (必須オプション欠如) - 必要なオプションが欠けている時、このコードで知らせる。
2.9.7. タイムスタンプ要求/応答

タイムスタンプタイプは今日では廃れて使われなくなっているが、ここでは簡単に取り上げておく。応答も要求も同じコード (0) を持つ。要求の場合はタイプ 13、応答はタイプ 14 である。タイムスタンプパケットは UT (Universal Time) 午前 0 時からの時間をミリ秒で表した 32 ビットのタイムスタンプを 3つ格納している。
最初のタイムスタンプはオリジナルタイムスタンプ、つまり送信元が最後にパケットに触れた時を表す。レシーブタイムスタンプ はエコーを返そうとしたホストが初めてパケットに触れた時、トランスミットタイム は、パケットがエコー送信者の手を離れる瞬間のタイプスタンプである。
いずれのタイムスタンプメッセージも、述べたもの以外に、ICMPエコー パケット同様の識別子 とシーケンスナンバー を持つ。
2.9.8. インフォメーション要求/応答

インフォメーション要求とインフォメーション応答というタイプは、今日では、必要であれば IP プロトコルより上に同目的で利用できるプロトコル (DHCP など) があるため、既に廃止されている。インフォメーション要求は、それを受け取ったネットワーク上に存在する応答可能な全ホストから回答を発生させる。
情報を要求したホストは、送信元アドレスを自分の属するネットワーク (例えば 192.168.0.0)、宛先を 0 にしてパケットを送る。応答のパケットには様々な数値情報 (ネットマスクと IPアドレス) が書かれている。
インフォメーション要求は ICMP タイプが 15、かたや応答はタイプ 16 で送られる。
2.10. SCTPの特徴
Stream Control Transmission Protocol (SCTP) はネットワーク戦線ではまだ新顔の部類に入るプロトコルだが、利用される場面は日に日に広がりつつあり TCP および UDP プロトコルの弱点を改善するものでもあるため、こうしてセクションを設けて解説することにした。 SCTP は TCP にも勝る高信頼性を備え、なお且つ、プロトコルヘッダの造りから、オーバーヘッドが低く抑えられている。
SCTP には非常に興味深い特長がいくつかある。このプロトコルについてより詳しく知りたい人は、RFC 3286 - An Introduction to the Stream Control Transmission Protocol と RFC 2960 - Stream Control Transmission Protocol を読んでいただくといい。前者は SCTP の紹介文書で、もう少しよく知りたいという人にとって非常に興味深い文書だろう。ふたつ目はプロトコルの仕様書そのもので、このプロトコルを使って何かを開発しようとする人か本気で興味を持った人でもなければ、読んでもあまり役には立たないかもしれない。
SCTP は元々 Telephony over IP や Voice over IP (VoIP) 用に開発されたプロトコルで、このことに由来した非常に興味を惹く特性がいくつかある。商用グレードの VoIP では非常に高次の信頼性が求められる。つまり、様々な障害に対する障害回復機能が幾重にも張り巡らされているのだ。以下に挙げるのが SCTP の主な特徴である。
マルチキャスト 属性によるユニキャスト 。ポイントtoポイント のプロトコルでありながら、末端ホストに対する複数のアドレスをサポートしているということだ。言い換えると、エンドホストまで到達するために複数の経路が利用できる。これに対して TCP では、搬送経路が断ち切られた時、 IP プロトコルによる補正に助けてもらわない限り断絶は避けられない。
高信頼性伝送 (Reliable transmission)。チェックサムと SACK を使用して、データの衝突 (corrupted)、損傷、破棄 (discarded)、重複 (duplicated)、入れ違い (reordered) の検出を行い、そうした場合には必要に応じて再送を行う。この点は TCP も同じだが、特に、順序の入れ違ったデータに関しては SCTP のほうが回復能力に優れ、検知も早い。
メッセージ指向 (Message oriented) メッセージ単位でフレーム化ができるため、データグラムの構造や順序を見失わずにすむ。 TCP はバイト指向であり、受け取れるのは中で順序がばらばらになったバイトの流れ (stream) でしかなく、それを補うために追加のレイヤーを必要とする。
レート対応 (Rate adaptive)。 TCP と協調/共存して帯域幅調整を行うことができるように作られている。 TCP と同様に、ネットワーク負荷に応じて帯域幅の増減ができる。また、スロースタート に相当するアルゴリズムも備える。ECN にも対応している。
マルチホーミング (Multi-homing)。先にも述べたように、複数のエンドノードと遣り取りする機能がプロトコル自体に組み込まれている。そのおかげで、 IP レイヤーに頼らなくても障害回復ができる。
マルチストリーム (Multi-streaming)。ひとつのストリームの中で複数のストリームを同時に流すことができる。これが Stream Control Transmission Protocol という名前の由来だ。例えば、ひとつの Webページをダウンロードするために 1本のストリームを開いておき、その中だけでイメージや html ドキュメントを同時進行的にダウンロードすることができる。これを複数のコントロールストリームの発生可能なデータベースプロトコルで活用すれば、複数のクエリに対する回答を並行して受け取ることができることは言うまでもない。
イニシエーション。コネクションの確立 (initiation) は 4 つのパケットから成るが、3番目と 4番目はデータの送信にも利用できる。syncookies と同等の仕組みも標準で組み込まれており、DoS 攻撃が防げる。SCTP コネクションのバッティングを防ぐことを目的に INIT collision resolution (初期化衝突解決機能) を備えている。
上のリストは、やろうと思えばいくらでも増やせるが、やめておく。関連の情報は RFC 3286 - An Introduction to the Stream Control Transmission Protocol のドキュメントで入手可能なので、必要があればそちらを読んでいただきたい。
| SCTP の話をする時には、これまでのような パケット や ウィンドウ は使わず、チャンク (chunks) という言葉が用いられる。SCTP はメッセージ指向であるため、ひとつの SCTP フレーム が複数のチャンク を含むこともある。チャンク には、コントロールチャンク と データチャンク があり、各チャンク はそのどちらかとなる。コントロールチャンク はセッションの制御を行い、実際のデータは データチャンク によって送られる。 |
2.10.1. イニシャライズとアソシエーション
コネクションのイニシャライズ (initialize = 初期確立) は、互いに通信を交わしたいホストとホストの間で関係を締結すること (association) によって行われる。関係締結のイニシャライズはユーザからの要請があった時に行われ、それが以後必要に応じて使用される。
イニシャライズは 4つのパケットによって行われる。まず INIT チャンク を送信し、それに対して、クッキーを含んだ INIT ACK が返され、そこからデータの送信が始まる。しかし、イニシャライズの続きがまだあり、さらに 2個のパケットの遣り取りがなされる。クッキーに対して返す COOKIE ECHO チャンク と、その回答でありイニシャライズの締めとなる COOKIE ACK チャンク だ。
2.10.2. データの送信とコントロールセッション
SCTP は、ここまで準備が整えばデータの送信ができる。 SCTP においては コントロールチャンク と データチャンク があることは前に述べた。データチャンク は DATA チャンク によって送られ、 DATA チャンク は SACK チャンク の送信によって承認される (acknowledged)。実質的には TCP の SACK と同じだ。この SACK チャンク が コントロールチャンク だ。
コントロールチャンク はこの他にもある。HEARTBEAT と HEARTBEAT ACK チャンクがそのひとつ、もうひとつが ERROR チャンクだ。HEARTBEAT が使われるのはコネクションのキープアライブのため、 ERROR は、ストリーム ID の異常や、必須パラメータの欠如など、コネクション上の様々な問題やエラーを報告するために使われる。
2.10.3. シャットダウンと中止
いよいよ SCTP コネクションを閉じようという時には、ABORT チャンク あるいはより行儀正しい SHUTDOWN チャンク を送信する。SCTP には TCP のような半閉鎖 状態は存在しない。つまり、一端が送信ソケットを閉じてしまったら、他端はもう送信を継続することはできない。
ユーザあるいはアプリケーションが礼儀正しく SCTP ソケットを閉じようとする時には、プロトコルに対して SHUTDOWN を要望する。すると、SCTP はバッファ上に残存するデータを送りきった後、 SHUTDOWN チャンク を送信する。他端は、この SHUTDOWN を受け取るとアプリケーションからのデータを受け取るのをやめ、送信すべきデータをすべて完了させようとする。データに対しての SACK がすべて受信できたら、この端末は SHUTDOWN ACK チャンク を送信し、初めにクローズを言い出した側は締めの SHUTDOWN COMPLETE チャンク で返事をする。これでセッションは完全に終了だ。
セッションのクローズの仕方にはもうひとつある。それが ABORT。こちらは SCTP アソシエーション の礼儀正しくない解消法だ。一対の SCTP アソシエーション を即時に解消したい時がこれで、一方が然るべき値を持った ABORT チャンク を送る。バッファ上にあるものも含め、未送信のデータはすべて破棄されて、アソシエーションが解消される。相手方も、 ABORT チャンク の正当性を検査した後に同様の処理を行う。
2.11. SCTPヘッダ
この節は SCTP ヘッダの非常に手短な紹介だ。SCTP には沢山のタイプのパケットがあるのだが、RFC に示されているものはできるだけすべて網羅するようにし、それらの中で各ヘッダの果たす役割を説明してみようと思う。まずは SCTP パケット全般に共通するヘッダについての概論から始めることにしよう。
2.11.1. SCTP共通ヘッダフォーマット
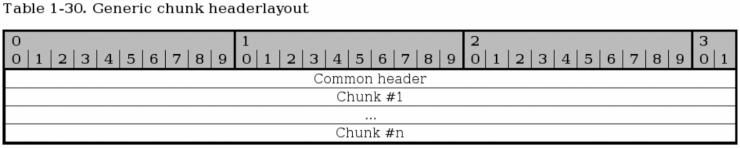
これが SCTP パケット全般のレイアウトだ。基本としてまず最初にくるのは、パケット全体についての情報と送信元および宛先のポートなどを伝える一般ヘッダ (common header) だ。一般ヘッダに関しては以降で詳しく述べる。
一般ヘッダの後ろには任意の数の チャンク がくる。 チャンク の最大数は MTU の許す範囲内だ。 チャンク はこのように「束」にできるわけだが、 INIT, INIT ACK, SHUTDOWN COMPLETE は束には入れられない。 DATA チャンクは、パケットの MTU 内に収めるために分割することもできる。
2.11.2. SCTPの一般ヘッダと共通ヘッダ

すべての SCTP パケットは上記に見る一般ヘッダを備えている。ヘッダには 4つのフィールドがあり、 SCTP パケット毎にそれぞれの値がセットされる。
送信元ポート (Source port) - ビット 0-15。そのパケットの送り元となったソースポートを伝える。 TCP と UDP のソースポートと同じだ。
宛先ポート (Destination port) - ビット 16-31。パケットの宛先ポート、つまりパケットの行こうとしているポート。TCP と UDP の宛先ポートと同じだ。
検証タグ (Verification Tag) - ビット 32-63。検証タグは、そのパケットがどの相手から送られてきたのかを検証するために使われる。この値は、アソシエーションのイニシャライズの段階で対向のピアから Initiate タグ で受け取った値がずっと使われる。ただし以下のような少数の例外もある:
INIT チャンクを含む SCTP パケットは 検証タグ が 0 と決められている。
T-bit のセットされた SHUTDOWN COMPLETE チャンクでは、 検証タグ は SHUTDOWN-ACK チャンクの 検証タグ の複製でなければならない。
ABORT チャンクを含むパケットでは、 検証タグ は、 ABORT の元となったパケットの 検証タグ と同じものでもよいことに なっている (may)。
チェックサム (Checksum) - ビット 64-95。Adler-32 アルゴリズムによって計算した、その SCTP パケット全体のチェックサム。アルゴリズムについては RFC 2960 - Stream Control Transmission Protocol の appendix B を参照されたし。

すべての SCTP チャンクは、上図に示した決まったレイアウトに則っている。ただし、これらはヘッダそのものではなく、「チャンク はおしなべてこういうフォーマットになっている」という定型を示したものに過ぎない。
タイプ (Type) - ビット 0-7。そのパケットの チャンクタイプを指定する。例えば INIT チャンクなのか SHUTDOWN チャンクなのかそれとも... といった具合。チャンク には、下表に示したようにそれぞれ決まったナンバーが割り当てられている。すべてのチャンク タイプをリストアップしたのが次の表だ:
Table 2-1. SCTPタイプ
| チャンクナンバー | チャンク名 |
|---|---|
| 0 | ペイロードデータ (Payload Data) (DATA) |
| 1 | イニシエーション (Initiation) (INIT) |
| 2 | イニシエーション承認 (Initiation Acknowledgement) (INIT ACK) |
| 3 | 選択的承認 (Selective Acknowledgement) (SACK) |
| 4 | ハートビート要求 (Heartbeat Request) (HEARTBEAT) |
| 5 | ハートビート承認 (Heartbeat Acknowledgement) (HEARTBEAT ACK) |
| 6 | 中止 (Abort) (ABORT) |
| 7 | シャットダウン (Shutdown) (SHUTDOWN) |
| 8 | シャットダウン承認 (Shutdown Acknowledgement) (SHUTDOWN ACK) |
| 9 | オペレーションエラー (Operation Error) (ERROR) |
| 10 | ステートクッキー (State Cookie) (COOKIE ECHO) |
| 11 | クッキー承認 (Cookie Acknowledgement) (COOKIE ACK) |
| 12 | 明示的輻輳通知エコー用の予約域 (Reserved for Explicit Congestion Notification Echo) (ECNE) |
| 13 | 輻輳ウィンドウ縮小用の予約域 (Reserved for Congestion Window Reduced) (CWR) |
| 14 | シャットダウン完了 (Shutdown Complete) (SHUTDOWN COMPLETE) |
| 15-62 | IETFによる予約域 (Reserved for IETF) |
| 63 | IETFによって定義済みのチャンク拡張 (IETF-defined chunk extensions) |
| 64-126 | IETFによる予約域 (reserved to IETF) |
| 127 | IETFによって定義済みのチャンク拡張 (IETF-defined chunk extensions) |
| 128-190 | IETFによる予約域 (reserved to IETF) |
| 191 | IETFによって定義済みのチャンク拡張 (IETF-defined chunk extensions) |
| 192-254 | IETFによる予約域 (reserved to IETF) |
| 255 | IETFによって定義済みのチャンク拡張 (IETF-defined chunk extensions) |
チャンクフラグ (Chunk Flags) - ビット 8-15。 チャンクフラグ はほとんど使われることはないが、他の用途に明け渡す必要が生じない限り、将来の活用に備えて確保されている。フラグ はチャンク 毎に特有のフラグやビットで、対向のピアに必要な情報を格納する。現時点での規格によれば、これらのフラグ は DATA, ABORT, SHUTDOWN COMPLETE パケットでのみ使うことになっている。ただし将来変更になる可能性もある。
 | RFC を読んでいると、前にも踏んだはずの危険な轍がそこここに転がっていることに気づかされる。 RFC 2960 - Stream Control Transmission Protocol の文書もそのひとつ。チャンクフラグ は必ず 0 でなくてはならないが、特に用途のない限りは無視される、という規定だ。いたるところに見られるこのような規定は、将来、問題になる危険性をはらんでいる。これには目を光らせておかなくてはならない。というのも、こういったフィールド規定は将来変更となる可能性があり、その時には、道理のいかない理由であなたのファイヤーウォールが爆弾を抱えることになってしまうのだ。同じことは、過去に IP ヘッダ に ECN が取り入れられた時にも起こっている。詳しくはこのチャプターの IPヘッダ セクションを読んでいただきたい。 |
チャンク長 (Chunk Length) - ビット 16-31。バイト単位で数えたチャンク の長さ。チャンクタイプ, チャンクフラグ, チャンク長, チャンク値 を含めたヘッダすべてを含めた長さだ。チャンク値 がひとつもない場合の長さは 4 (バイト) となる。
チャンク値 (Chunk Value) - ビット 32-n。ここはチャンク 毎に固有で、チャンクタイプ に応じた追加のフラグ およびデータを格納できる。空の場合もあり、その時のチャンク長 は 4 に設定される。
2.11.3. SCTP ABORTチャンク

ABORT チャンクは、当チャプターの シャットダウンと中止 で述べたようにアソシエーションを断ち切る時に使用する。 ABORT は、データやヘッダの異常など、アソシエーションの中で回復不能の問題が発生した際に発行される。
タイプ (Type) - ビット 0-7。このチャンクタイプ では常に 6。
予約域 (Reserved) - ビット 8-14。将来のチャンクフラグ 拡張用に予約されているが、投稿執筆時点ではまだ使われていない。チャンクフラグ フィールドについては SCTPの一般ヘッダと共通ヘッダ を参照のこと。
T-bit - ビット 15。このビットが 0 だとすれば、このパケットには送信元で TCB が関連付け (associated) されていて、そのパケットがそれを無効化した (destroyed) ということを示している。送信元で TCB を使っていない時には、T-bit は 1 にすることになっている。
全長 (Length) - ビット 16-31。エラーの原因も含めたチャンク の長さのバイト表記。
2.11.4. SCTP COOKIE ACKチャンク

COOKIE ACK チャンクはコネクションのイニシャライズの際にのみ使用され、コネクション中の他の場面で使われることはない。必ず DATA および SACK チャンクよりも前に送らなければならないが、そうした中の最初のパケットをこれに兼用してもよいことになっている。
タイプ (Type) - ビット 0-7。このタイプでは常に 11。
チャンクフラグ (Chunk flags) - ビット 8-15。今のところ未使用。RFC 2960 - Stream Control Transmission Protocol によれば常に 0 にすることになっている。こういった旨を記した RFC には常に目を光らせておかなければならない。というのは、将来変更される可能性があり、それによってあなたのファイヤーウォールにヒビが入ることになるからだ。 IP の ECN で起きたことの二の舞である。詳しくは SCTPの一般ヘッダと共通ヘッダ のセクションを参照していただきたい。
全長 (Length) - ビット 16-31。このタイプのチャンク では常に 4 (バイト)。
2.11.5. SCTP COOKIE ECHOチャンク

COOKIE ECHO チャンクが使われるのは SCTP コネクションのイニシャライズの過程で、接続の申し出を受けた側が INIT ACK パケットの State クッキー フィールドで送ってきたクッキーに対して、接続を申し出た側が回答する時だ。 COOKIE ECHO チャンクは DATA チャンクを乗せたパケット内で一緒に送ってもよいが、その場合には DATA チャンクよりも前に置かなければならない。
タイプ (Type) - ビット 0-7。このチャンクでは常に 10。
チャンクフラグ (Chunk flags) - ビット 8-15。今日ではまだ使用されていない。 RFC はこのフラグを必ず 0 にせよとしているが、このことは SCTPの一般ヘッダと共通ヘッダ のセクション (特にチャンクフラグの説明部分) で述べたようなトラブルを引き起こす可能性がある。
全長 (Length) - ビット 16-31。チャンク の長さ。タイプ, チャンクフラグ, 全長 および クッキーフィールド を含んだ長さで、バイト表記。
クッキー (Cookie) - ビット 32-n。このフィールドは、これに先立つ INIT ACK チャンクで送信されたクッキーと同じものを持つ。返答をよこした側の送ってきたクッキーと正確に一致していないと、コネクションはオープンできない。 RFC 2960 - Stream Control Transmission Protocol は、互換性を損なわないためにクッキーは可能な限り小さくせよと述べているが、曖昧で、多くを語ろうとしない。
2.11.6. SCTP DATAチャンク

DATA チャンクはストリームの中で実際のデータを送るためのもので、見方によってはかなり込み入っているように思えるかもしれないが、実際のところは TCP ヘッダの一般フォーマットとどっこいどっこいだ。 ひとつのパケットの中に同居していたとしても、各 DATA チャンクは別のストリームに属するものかもしれない。なぜなら、 SCTP はひとつのコネクションで複数のストリームを扱うことができるからだ。
タイプ (Type) - ビット 0-7。DATA チャンクでは常に 0 に設定される。
予約域 (Reserved) - ビット 8-12。今日では未使用。将来の変更のために確保されている。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
U-bit - ビット 13。 U-bit は、その DATA チャンクが順不同で構わないものかどうかを表す。順不同であれば、ストリームシーケンスナンバー は無視する決まりになっており、 DATA を並べ直そう (re-order) とはせずにいち早く上位レイヤーに渡さなくてはならない。
B-bit - ビット 14。 B-bit は、フラグメントされた DATA チャンクの存在を示す。このビットが正で E (ending) ビットが正でない場合、このチャンクがいくつかにフラグメントされた DATA チャンクの最初の断片であることを表している。
E-bit - ビット 15。 E-bit は、フラグメントされた DATA チャンクの最終断片を表す。このフラグが正になったものは、 SCTP の受け取り側にとって、フラグメントの再構成を開始し上位レイヤーに渡せという合図になる。また、 B ビット も E ビット も 0 であれば、それはこのチャンクがフラグメントの半ばのチャンクであることを表す。両方とも 1 にセットされるのは、パケットはフラグメントされておらず再構成も必要ない場合などだ。
全長 (Length) - ビット 16-31。チャンクタイプ も含めてチャンク終端まで全部をビット単位で計算した DATA チャンクの長さ。
TSN - ビット 32-63。トランスミッションシーケンスナンバー (Transmission Sequence Number = TSN) は DATA チャンクの中で送られ、受信側ホストはこれを受け取ると、チャンクがきちんと届いたと認め (acknowledge)、引き替えに SACK チャンクを送る。値はその SCTP アソシエーション を通じてカウントされていく。
ストリーム識別子 (Stream Identifier) - ビット 64-79。ストリーム識別子 は DATA に付属して送られ、その DATA チャンクがどのストリームに関連付けられているかを明らかにする。これが存在するのは、 SCTP がひとつのアソシエーションの中で複数のストリームを運ぶ能力を備えているからだ。
ストリームシーケンスナンバー (Stream Sequence Number) - ビット 80-95。 ストリーム識別子 で括られるひとつのストリームの中でのシーケンスナンバー。このシーケンスナンバーは各ストリーム識別子 毎に管理される。チャンクがフラグメントされている場合には、元チャンクが同一ならばすべての断片に同じストリームシーケンスナンバー を付けなければならない。
ペイロードプロトコル識別子 (Payload Protocol Identifier) - ビット 96-127。この値は上位レイヤーまたは、SCTP を使用しているアプリケーションによって入れられ、それらどうしが DATA チャンクの内容を伝え合うために使われる。このフィールドは必ず送信する必要があり、フラグメントしたチャンクもその例外ではない。というのは、フラグメントされたチャンクであっても経路上のルータやファイヤーウォールなどがこの情報を必要とするからだ。値が 0 だった場合、上位レイヤーがセットしなかったと解釈される。
ユーザデータ (User data) - ビット 128-n。そのチャンクの運ぶデータそのもの。可変長だが、偶数オクテットで終わらなければならない。ストリーム S のストリームシーケンスナンバー n 番のデータ。
2.11.7. SCTP ERRORチャンク

ERROR チャンクは、特定のストリームの中で起きた問題を対向のピアに知らせるためにある。ひとつの ERROR チャンクは複数の エラー原因 を格納することもでき、そのことについては RFC 2960 - Stream Control Transmission Protocol で詳説されている。僕がここで述べるのは基本だけで、それ以上詳しく述べるのは控えておく。中身が濃すぎるからだ。 ERROR チャンクは、それ自体が致命的 (fatal) な性格のものというよりも、発生したエラーの詳細内容を知らせるものといえる。とはいえ、 ABORT チャンクと組み合わせると、コネクションを断ち切るぞという知らせにもなりうる。
タイプ (Type) - ビット 0-7。 ERROR チャンクでは常に 9。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更を目してのフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
全長 (Length) - ビット 16-31。すべての エラー原因 フィールドを含めた長さをバイトで指定する。
エラー原因 (Error causes) - ビット 32-n。ひとつの ERROR チャンクはひとつ以上の エラー原因 フィールドを含むことができ、それぞれのフィールドで対向ピアにコネクションに関する問題を知らせる。ひとつの エラー原因 の中にも決まったフォーマットがあり、それは RFC 2960 - Stream Control Transmission Protocol ドキュメントで述べられているが、ここではそれに踏み込むのはやめ、フィールドが 原因コード と 原因長 (cause length) および、原因毎に特有の情報フィールドから成ると言うだけに留める。指定可能な エラー原因 は下表の通りだ:
Table 2-2. エラー原因コード
| Cause Value | Chunk Code |
|---|---|
| 1 | Invalid Stream Identifier (無効なストリーム識別子) |
| 2 | Missing Mandatory Parameter (必須パラメータの欠如) |
| 3 | Stale Cookie Error (「失効したクッキー」エラー) |
| 4 | Out of Resource (リソースの欠乏) |
| 5 | Unresolvable Address (リゾルブできないアドレス) |
| 6 | Unrecognized Chunk Type (未知のチャンクタイプ) |
| 7 | Invalid Mandatory Parameter (必須パラメータの値が無効) |
| 8 | Unrecognized Parameters (未知のパラメータ) |
| 9 | No User Data (ユーザデータの欠如) |
| 10 | Cookie Received While Shutting Down (シャットダウン中にクッキーを受信) |
2.11.8. SCTP HEARTBEATチャンク

HEARTBEAT チャンクは、特定の SCTP 端末アドレスが無効になっていないか走査する目的で、ひとつのピアが送信する。これはアソシエーションのイニシャライズの過程で関係を結んだ (negotiated) 複数のアドレスに対して行われ、それらが生存しているかどうかの確認に使われる。
タイプ (Type) - ビット 0-7。 HEARTBEAT チャンクでは、タイプ は常に 4。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更で使用されるようになる可能性がある。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
全長 (Length) - ビット 16-31。Heartbeat Information TLV を含めた、チャンク全体の長さ。
ハートビートインフォメーション TLV (Heartbeat Information TLV) - ビット 32-n。 RFC 2960 - Stream Control Transmission Protocol で定義された可変長のパラメータ。 HEARTBEAT チャンクには必須のパラメータで、infoタイプ=1, info長, 送信元固有の ハートビートインフォメーション パラメータの 3つのフィールドから成る。最後のフィールドは送信元によって内容がかなり異なり、例えば、ハートビートが前回いつ送られたかや送信先の IPアドレスが入ったりする。このパラメータと同じものが HEARTBEAT ACK チャンクで返される。
2.11.9. SCTP HEARTBEAT ACKチャンク

HEARTBEAT ACK は、HEARTBEAT が受理されコネクションは正常に機能しているという了解 (acknowledge) を示すために使われる。 HEARTBEAT ACK は要求のやってきた IPアドレスに対して返される。
タイプ (Type) - ビット 0-7。 HEARTBEAT ACK チャンクでは常に 5。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更に備えて確保されている。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk length) - ビット 16-31。 ハートビートインフォメーション TLV を含めた HEARTBEAT ACK チャンクの長さをバイト単位で表したもの。
ハートビートインフォメーション TLV (Heartbeat Information TLV) - ビット 32-n。 ここには必ず、元となった HEARTBEAT チャンクの ハートビートインフォメーション パラメータと同じものを格納する。
2.11.10. SCTP INITチャンク

INIT チャンクは、宛先ホストとの新たなアソシエーションを開始 (initiate) する時に用いられるもので、コネクションを張ろうとするホストの発する一番最初のチャンクがこれだ。 INIT チャンクはいくつかの固定長パラメータと、省略可能な可変長パラメータから成る。固定長の必須パラメータには、既に他のヘッダで述べたものの他に、 イニシエートタグ (Initiate Tag), 受信ウィンドウ保証量広告 (Advertised Receiver Window Credit), 送出ストリーム数 (Number of Outbound Streams), 流入ストリーム数 (Number of Inbound Streams), 初期TSN (Initial TSN) パラメータがある。その後ろに下の「省略可能なパラエータ」の段落で挙げているいくつかのオプションパラメータが続く。
タイプ (Type) - ビット 0-7。INIT チャンクでは常に 1。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更に備えて確保されている。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk Length) - ビット 16-31。 チャンク長 は、オプションパラメータも含めたすべてのヘッダを含めたパケットの全長。
イニシエートタグ (Initiate Tag) - ビット 32-63。イニシエートタグ は INIT チャンクの中で決められ、それが 検証タグ (Verification Tag) に利用されて、このアソシエーション中ずっと受信側によるパケット承認に使用される。 イニシエートタグ は 0 以外ならどんな値でも採ることができる。決まりに反して 0 にされた場合には、受信側は ABORT を発生させなければならない。
受信ウィンドウ保証量広告 (Advertised Receiver Window Credit) (a_rwnd) - ビット 64-95。 INIT チャンクの送り主がこのアソシエーション用に割り当てることにしている受信バッファの最小量。 a_rwnd の受け取り側は、この値によって、どれだけの量のデータが SACK で区切らずに送り出せるかを知る。実際の受信ウィンドウをここで広告したサイズよりも縮小することは推奨されないが、 SACK チャンクで改めて a_rwnd を送ることによってサイズを減らす余地はある。
送出ストリーム数 (Number of Outbound Streams) - ビット 96-111。相手に向かって張りたい、こちらから出て行く方向のストリームの最大数を規定する。この値を 0 とすることは許されておらず、もしもそうすれば相手はアソシエーションを即刻 ABORT しなくてはならない。送出ストリームに関しても流入ストリームに関しても最小数についての折衝はなく、単純に、両ホストがヘッダで指定したうちの小さい方が最小値となる。
流入ストリーム数 (Number of Inbound Streams) - ビット 112-127。このセッションで送り側が受信側ホストに生成を許可する、流入方向のコネクションの最大数。0 にすることは許されておらず、そうすれば受信側ホストはコネクションを ABORT しなければならない。送出ストリームに関しても流入ストリームに関しても最小数についての折衝はなく、単純に、両ホストがヘッダで指定したうちの小さい方が最小値となる。
初期 TSN (Initial TSN) - ビット 128-159。この値は、送り手側がデータの送信に使用する 伝送シーケンスナンバー (Transmit Sequence Number = TSN) の初期値を規定する。イニシエートタグ と同じ値を使用してもよいことになっている。
上記に挙げた固定長の必須ヘッダに加えて、設定してもよい オプショナルな数種の可変長パラメータがある。少なくとも IPv4, IPv6, Hostname のいずれかひとつは指定しなければならない。 Hostname はひとつだけしか指定できず、指定してある時には IPv4 と IPv6 パラメータはいずれも指定できない。ひとつの INIT チャンクで IPv4 と IPv6 パラメータを複数指定することは許されている。また、送り手側がひとつのアドレスしか持たずそれをチャンク の送信元として使う場合には、これらのパラメータを 3つとも省略することもできる。これらのパラメータは相手ピアとの接続に使用するアドレスを取り決めるためにある。下記が INIT チャンクで利用可能な全パラメータのリストだ:
Table 2-3. INITの可変長パラメータ
| パラメータ名 | ステータス | タイプ値 |
|---|---|---|
| IPv4 Address | 省略可 | 5 |
| IPv6 Address | 省略可 | 6 |
| Cookie Preservative | 省略可 | 9 |
| Host Name Address | 省略可 | 11 |
| Supported Address Types | 省略可 | 12 |
| Reserved for ECN Capable | 省略可 | 32768 |
以下に、 INIT チャンクで最も一般的な 3つのパラメータについて述べる。

IPv4 パラメータは INIT チャンクで IPv4 アドレスを送るためにある。これによって指定するのは、そのアソシエーションの中でデータ送信に使用していく IPv4 アドレスだ。ひとつの SCTP アソシエーションに対して IPv4 アドレスや IPv6 アドレスを複数指定することもできる。
パラメータタイプ (Parameter Type) - ビット 0-15。IPv4 アドレスパラメータでは常に 5。
全長 (Length) - ビット 16-31。 IPv4 アドレスパラメータでは常に 8 となる。
IPv4 アドレス - ビット 32-63。送り手側端末の、ひとつの IPv4 アドレス。

このパラメータは INIT チャンクで IPv6 アドレスを送るためにある。ここで指定したアドレスはそのアソシエーションの中での送り手側端末との通信に利用することができる。
タイプ (Type) - ビット 0-15。 IPv6 パラメータでは常に 6。
全長 (Length) - ビット 16-31。 IPv6 パラメータでは常に20となる。
IPv6 アドレス - ビット 32-159。送り手側エンドポイントの、ひとつの IPv6 アドレス。受け手側エンドポイントはこのアドレスと通信することになる。

Hostname パラメータは、アドレスとしてのひとつのホストネームを送るためにある。受信側ホストはここで指定されたホストネームをルックアップし、それによって得られた何れかまたはすべてのアドレスを利用する。Hostname パラメータを送るのであれば、 IPv4 や IPv6 も、余計な Hostname パラメータも送ることはできない。
タイプ (Type) - ビット 0-15。 Hostname パラメータでは常に 11。
全長 (Length) - ビット 16-31。 タイプ, 全長 をはじめとする全フィールドを含めたパラメータ全体の長さ。 Hostname フィールドは可変長だ。単位はバイト。
Hostname - ビット 32-n。ホストネームを格納する可変長パラメータ。個々で指定したホストネームは受信側エンドポイントでリゾルブが行われ、そこで得られたアドレスが送り手側エンドポイントとの通信に利用される。
2.11.11. SCTP INIT ACKチャンク

INIT ACK チャンクは INIT チャンクへの返事として送られる。ヘッダは基本的に INIT と同じだが、それらの値はこれを送ってきたピア (つまり元の INIT を受けた側) のものに置き換えられる。また、 INIT にはない追加の可変長パラメータ、 ステートクッキー と 認識不能パラメータ (Unrecognized Parameter) パラメータがある。
タイプ (Type) - ビット 0-7。 INIT ACK チャンクでは常に 2。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更を目して確保されているフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk Length) - ビット 16-31。チャンク長 は、省略可能なパラメータも入れたすべてのヘッダを含めたパケット全体の長さ。
イニシエートタグ (Initiate Tag) - ビット 32-63。 INIT ACK チャンクの イニシエートタグ を受け取った端末は、その値を記録した上で、INIT ACK チャンクを送りつけてきた端末へ送り返すすべてのパケットの 検査タグ (Verification Tag) フィールドにそれをコピーしなければならない。 イニシエートタグ は 0 であってはならず、もし 0 であれば、その INIT ACK チャンクを受け取ったピアは ABORT によってコネクションをクローズしなければならない。
受信ウィンドウ保証量広告 (Advertised Receiver Window Credit) (a_rwnd) - ビット 64-95。送り手側が受信トラフィック専用に確保したバッファのサイズ。単位はバイト。専用バッファをこれより小さくしてはならない。
送出ストリーム数 (Number of Outbound Streams) - ビット 96-111。出て行く方向のストリームを送り手側ホストがいくつ生成したいか。0 にしてはならず、もしそうすれば INIT ACK を受信した側はそのアソシエーションを ABORT しなくてはならない。送出ストリームに関しても流入ストリームに関しても最小数についての折衝はなく、単純に、両ホストがヘッダで指定したうちの小さい方が最小値となる。
流入ストリーム数 (Number of Inbound Streams) - ビット 112-127。送信側エンドポイントがすすんで受け入れる流入方向ストリームの最大数。0 にしてはならず、もしそうすれば INIT ACK を受信した側はそのアソシエーションを ABORT しなくてはならない。送出ストリームに関しても流入ストリームに関しても最小数についての折衝はなく、単純に、両ホストがヘッダで指定したうちの小さい方が最小値となる。
初期 TSN (Initial TSN) - ビット 128-159。送信側がそのアソシエーションで最初に使う 伝送シーケンスナンバー初期値 (Initial Transmission Sequence Number = I-TSN)。
この後、 INIT ACK チャンクにはオプションの可変長パラメータが続く。パラメータは基本的には INIT チャンクのものと同じだが、 ステートクッキー パラメータと 認識不能パラメータ パラメータが加わり、対応アドレスタイプ (Supported Address Types) パラメータがなくなる。つまり下表のような塩梅だ:
Table 2-4. INIT ACK の可変長パラメータ
| パラメータ名 | ステータス | タイプ値 |
|---|---|---|
| IPv4 Address | 省略可 | 5 |
| IPv6 Address | 省略可 | 6 |
| State Cookie | 必須 | 7 |
| Unrecognized Parameters | 省略可 | 8 |
| Cookie Preservative | 省略可 | 9 |
| Host Name Address | 省略可 | 11 |
| Reserved for ECN Capable | 省略可 | 32768 |

ステートクッキー は INIT ACK チャンクで使用され、対向のホストにクッキーを送るためにある。これを受信したホストが COOKIE ECHO チャンクで回答するまでは、そのアソシエーションが正当なものであることは保証されない。 TCP プロトコルでいうところの SYN アタックを防ぐための仕組みだ。
タイプ (Type) - ビット 0-15。ステートクッキー パラメータでは常に 7。
全長 (Length) - ビット 16-31。タイプ, 全長, ステートクッキー フィールドを含めたパラメータ全体のサイズ。バイト表記。
ステートクッキー (State Cookie) - ビット 31-n。任意の長さのクッキーを格納する。クッキーがどのように生成されるかについては RFC 2960 - Stream Control Transmission Protocol を参照。
2.11.12. SCTP SACKチャンク
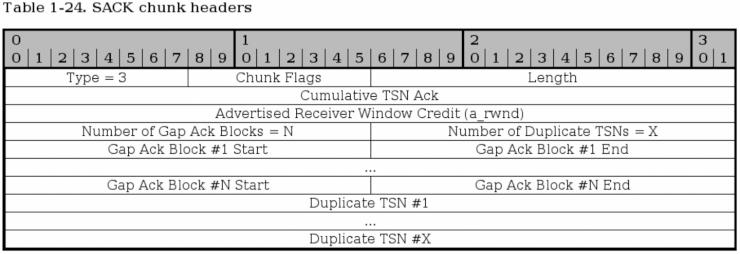
SACK チャンクの使用目的は、受信した TSN に照らしてどのチャンク が受信済みでストリームのどこにギャップがあったかを DATA チャンクの送信元に伝えることにある。 SACK チャンクの働きは、ざっくり言えば、特定の時点 (累積 TSN Ack パラメータ) までに受け取ったデータを承認し (acknowledges)、その 累積 TSN Ack ポイントまでに受け取った全データに対する ギャップ Ack ブロック を加えていくというものだ。 SACK チャンクの送信は DATA チャンクの受信 1回に対して 1回だけと決められている。
タイプ (Type) - ビット 0-7。 SACK チャンクでは常に 3。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更を目して確保されているフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk Length) - ビット 16-31。すべてのヘッダおよびパラメータを含めたチャンク全体の長さ。
累積 TSN Ack (Cumulative TSN Ack) - ビット 32-63。この 累積 TSN Ack パラメータはデータを承認するためにある。その DATA チャンクを受け取ったホストは、アソシエーションにおける現時点までのデータを受信し終えたことをこのフィールドによって送信元ホストに伝える。この時点でまだ明示的に ギャップ Ack ブロック によって承認していないデータは、基本的には喪失扱いになる。
受信ウィンドウ保証量広告 (Advertised Receiver Window Credit) (a_rwnd) - ビット 64-95。この a_rwnd フィールドも基本的には INIT や INIT ACK チャンクの a_rwnd と同じだが、ここでは a_rwnd 値の増減も可能だ。詳しくは RFC 2960 - Stream Control Transmission Protocol を読んでいただきたい。
ギャップ Ack ブロック数 (Number of Gap Ack Blocks) - ビット 96-111。このチャンクに含まれる ギャップ Ack ブロック の数。 ギャップ Ack ブロック ひとつは チャンク の 32 ビットを占有する。
重複 TSN 数 (Number of Duplicate TSNs) - ビット 112-127。重複していた DATA チャンクの数。重複していたすべての TSN はこの チャンク上の ギャップ Ack ブロック の後ろに並べられる。ひとつの TSN を送るには 32 ビットを消費する。
ギャップ Ack ブロック #1 開始点 (Gap Ack Block #1 Start) - ビット 128-143。ここに来るのが、この SACK チャンクで最初の ギャップ Ack ブロック。受け取った DATA チャンクの TSN ナンバーにギャップがひとつもない時には、 ギャップ Ack ブロック はひとつもない。かたや、 DATA の受信順序が乱れたり、伝送中にいくつかの DATA チャンクが失われた場合には、ギャップありと認められ、 ギャップ Ack ブロック を使って報告される。ギャップ Ack ブロック の開始位置は、 累積 TSN の値に ギャップ Ack ブロック開始点 パラメータを足すことによって求められる。そうして求められたのがブロック開始点だ。
ギャップ Ack ブロック #1 終点 (Gap Ack Block #1 End) - ビット 144-159。そのストリームにおける第1 ギャップ Ack ブロック の終点。 ギャップ Ack ブロック開始点 と ギャップ Ack ブロック終止点 の間にある TSN を持つすべての DATA チャンクは受信済み扱いになる。開始点同様に、実際に承認するブロックチャンクの最終 TSN を求めるには、ギャップ Ack ブロック終止点 の値を 累積 TSN と足す。
ギャップ Ack ブロック #N 開始点 (Gap Ack Block #N Start) - ビット可変。 ギャップ Ack ブロック数 パラメータがひとつ増える毎に、 ギャップ Ack ブロック がひとつ追加される (最後の第 N ブロックまで)。例えばつまり、ギャップ Ack ブロック数 = 2 だとすれば、その SACK チャンク内にはふたつの ギャップ Ack ブロック があるはずだ。ここは単純に最後の ギャップ Ack ブロック を意味し、ギャップ Ack ブロック #1 開始点 と同様の値が入ることになる。
ギャップ Ack ブロック #N 終点 (Gap Ack Block #N End) - ビット可変。ギャップ Ack ブロック #N 開始点 と同様。ただし、終点である。
重複 TSN #1 (Duplicate TSN #1) - ビット可変。このフィールドは、重複した TSN のことを通知する。つまり、既に受け取った チャンク と同一の TSN を持つ チャンク を、何度も受信した場合だ。ルーターの悪戯 (送信済みデータの再送) によるもの、エンドポイントの再送によるものなどケースは様々だ。重複した TSN は個々について 1回報告され、例えば、最初の該当データを承認してから 2つの重複 TSN を受信した場合、次回送信する SACK メッセージにふたつの重複 TSN それぞれについての報告が乗る。その SACK 送信後にさらに重複 TSN が観測されたら、そのまた次の回の SACK で知らせ、また... といった具合だ。
重複 TSN #X (Duplicate TSN #X) - ビット可変。ここに、最後の重複 TSN パラメータが来る。パラメータは前のものと同様だ。
2.11.13. SCTP SHUTDOWNチャンク

SHUTDOWN チャンクが発行されるのは、或るコネクションの一方のエンドポイントが現行のアソシエーションのクローズを希望する時だ。これを発行するホストは前もって送信バッファを空にしておく必要があり、 SHUTDOWN チャンクを送ったらもう DATA を一切送ってはならない。受信した側は、やはり送信バッファを空にして、 SHUTDOWN ACK チャンクで回答することになっている。
タイプ (Type) - ビット 0-7。 SHUTDOWN チャンクでは常に 8。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更を目して確保されているフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk Length) - ビット 16-31。 累積 TSN Ack パラメータも含めたパケット全体の長さ。 SHUTDOWN チャンクでは常に 8 となる。
累積 TSN Ack (Cumulative TSN Ack) - ビット 32-63。この 累積 TSN Ack フィールドも SACK チャンクのものと同様。累積 TSN Ack は、対向エンドポイントからこれまでにシーケンス上最後に受け取った TSN に承認を与える。このパラメータは、 SHUTDOWN チャンク以降のデータはもちろん、ギャップ Ack ブロック の承認も行わない。以前承認したはずの TSN が SHUTDOWN チャンクの ギャップ Ack ブロック にないからといって、そのブロックが今になって破棄されたと解釈してはならない。
2.11.14. SCTP SHUTDOWN ACKチャンク

SHUTDOWN ACK チャンクは、受信した SHUTDOWN チャンクを承認するために使用される。 SHUTDOWN ACK を送る前には、送信バッファの中身はすべて絞り出しておかなければならず、アプリケーションから新たなデータを受け取ってもいけない。 SCTP には TCP にあるようなコネクションの半開状態 (half-open) は存在しない。
タイプ (Type) - ビット 0-7。 SHUTDOWN ACK チャンクでは常に 8。
チャンクフラグ (Chunk flags) - ビット 8-15。今日では未使用。将来の変更を目して確保されているフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
チャンク長 (Chunk Length) - ビット 16-31。チャンク全体の長さ。 SHUTDOWN ACK では常に 4 となる。
2.11.15. SCTP SHUTDOWN COMPLETEチャンク

SHUTDOWN COMPLETE チャンクは、SHUTDOWN ACK チャンクへの返答として、 SHUTDOWN を先導したホストによって送信される。アソシエーションのクローズが完了したことを承認するためだ。
タイプ (Type) - ビット 0-7。 SHUTDOWN COMPLETE チャンクでは常に 14。
予約済み (Reserved) - ビット 8-14。今日では未使用。将来の変更を目して確保されているフィールドだ。詳しくは SCTPの一般ヘッダと共通ヘッダ を参照。
T-bit - ビット 15。送信側がこのコネクションに対して 伝送制御ブロック (Transmission Control Block = TCB) を結びつけており、それを無効化したのがその SHUTDOWN チャンクだった場合には、その事実を送信者側に伝えるために T-bit は立てない [訳者註: 0 にする]。 T-bit が立っている [: 1 になっている] とすれば、反故にするような TCB は存在しなかったということになる。
全長 (Length) - ビット 16-31。 SHUTDOWN COMPLETE チャンクでは常に 4。規格が改定でもされない限りは、それより大きくなることはあり得ないからだ。
2.12. TCP/IP宛先誘導型ルーティング
ルーティングという面では、 TCP/IP はかなり複雑になってきている。当初は誰もが、宛先誘導型ルーティング (destination driven routing) だけで充分だと考えていた。ところがここ数年で、あっという間に複雑さを増してきた。今日では、 Linux でも、基本的には IP ヘッダのフィールドやビットのどれを基準にしてでもルーティングができるし、そればかりか TCP, UDP, ICMP のヘッダでもルーティングが可能になっている。そうした仕組みをポリシールーティング (policy based routing)、あるいは高度ルーティング (advanced routing) と呼ぶ。
この章は、宛先誘導型ルーティングがどのように行われるかの簡略な説明だ。送信元ホストからパケットを送信する時、パケットが生まれる。すると次に、コンピュータはパケットの宛先アドレスを見て、コンピュータ自身の保持しているルーティングテーブルと照合を行う。宛先アドレスがローカルなものならば、パケットは直接、ハードウェア MACアドレス を使って送られる。宛先がゲートウェイの向こう側だった場合には、パケットはゲートウェイの MAC アドレスへと送られる。するとゲートウェイはパケットの IP ヘッダを読み、パケットの宛先アドレスを知る。宛先アドレスはここでまたルーティングテーブルと照合され、パケットは次のゲートウェイへ送られる...という行程が、宛先のアドレスの属する向こう側 のネットワークに到達するまで繰り返される。
お分かりの通り、この仕組みのルーティングは基本原則だけで成り立つ単純なものだ。高度ルーティングやポリシールーティングになると話は別で、仕組みはもっと複雑だ。例えば送信元アドレスや TOS 値などに基づいてパケットのルーティングを変えたりできるのだ。
2.13. まとめ
このチャプターでは、次から始まるチャプターを理解できるようにあなたの知識をアップデートしてきた。要点を簡潔にまとめると:
TCP/IPの構造
IPプロトコルの機能とヘッダ
TCPプロトコルの機能とヘッダ
UDPプロトコルの機能とヘッダ
ICMPプロトコルの機能とヘッダ
TCP/IP宛先誘導型ルーティング
このどれもが、この先、実際にファイヤーウォールのルールセットに取り組む際には非常に役に立つはずだ。これらをパズルの駒のようにぴったりと組み合わせることで、より良いファイヤーウォールを設計することができる。
Chapter 3. IPフィルタリングとは
このチャプターでは IPフィルタ の考え方について詳しく説明する。 IPフィルタとは何なのかや、動作の仕組み、ファイヤーウォールの配置場所、ポリシーなどについて述べる。
このチャプターで取り上げる疑問は、例えば、ファイヤーウォールをどこに配置するかだ。ほとんどの場合は答は簡単だ。しかし、大規模な企業のネットワーク環境となると、そう簡単にはいかない。ポリシーとは何なのか。アクセスはどの程度制限すればいいのか。そもそも IPフィルタとは何なのか。こうした疑問の全てを、当チャプターは解きほぐしていく。
3.1. IPフィルタとは何か
IPフィルタが何であるかをよく理解しておくのは重要なことだ。 iptables は IPフィルタである。このことをよく理解しておかないと、今後自分のファイヤーウォールを設計する時に暗礁に乗り上げることになる。
IP フィルタは TCP/IP 参照スタックのうち、主にレイヤー 2 で働く。現代の IPフィルタのほとんどがそうであるように、 iptables も、レイヤー 3 で作用することもできる。しかし、定義上では、 IPフィルタは第 2 層で働くものとされている。
IPフィルタの実装定義に厳格に従うのならば、 IPフィルタは IP ヘッダ (送信元/宛先アドレス, TOS/DSCP/ECN, TTL, プロトコル など、本当の意味で IP ヘッダ内に存在する情報のみ) に基づいてしかパケットをフィルタリングできないことになる。しかし iptables は IPフィルタの定義に対して 100% 厳格ではないので、パケットの奥深くに埋め込まれているヘッダ (TCP, UDP など) や、もっとローレベルのヘッダ (MACソースアドレス) に基づくフィルタリングも行える。
しかしここでひとつ問題がある。 iptables は最近になって、より厳格になってきているということだ。 iptables はストリームを「追いかけること (follow)」はしないし、データ同士を合体させたりもしない。そういった処理はプロセッサやメモリを喰いすぎるのだ。これが何を意味するかは後でじっくりと説明することにしよう。 iptables は TCP/IP スタックそのものがやるのと全く同じように、パケットそれぞれの身元を調べて記憶し、それらが同一のストリームに属しているかどうかを (シーケンスナンバー やポートナンバー などに基づいて) 判断する。これはコネクション追跡 (connection tracking) と呼ばれ、それがあるからこそ、パケットの宛先/送信元ネットワークアドレス変換 (一般的に DNAT, SNAT と呼ばれる) やステートマッチが行えるのだ。
上で明言を控えた点だが、 iptables は別々のパケットから読み取ったデータ同士を (デフォルトでは) くっつけることはできない。そのため、あなたが目にしているのが常にそのデータの全体とは限らない。僕がわざわざこの点に触れるのは、 netfilter/iptables に関係したメーリングリストの幾つかで、根本的に間違ったアイデアについての「どうやったらできるか」という質問が散見されるからだ。例えば、新たな Windows ベースのウイルスが現れる度に、特定の文字列を含むストリームを破棄する方法を質問する輩が現れる。たちが悪いのは、これが実に簡単にやれるという点だ。例えば:
cmd.exe
のような文字列でマッチを行えば、一応はできてしまう。
しかしここで、もしウイルスなりクラッキングプログラムなりのライターが非常にずる賢くて、パケットサイズを非常に小さくして cmd をひとつのパケットに入れ、次のパケットに .exe を乗せるようにしていたらどうなるか。あるいは、経路途中で、そんな小さなサイズのパケットしか通れないようなネットワークを通らざるを得ないとしたら。その通り。文字列マッチ (string match) はパケットの境界線を越えて作用することはできないので、問題のパケットは擦り抜けてしまう。
「どうして、パケットを跨っても作用するように文字列マッチや何かを作り替えないのさ」という疑問の浮かんだ人もいるだろう。答えは単純。 CPU時間 (processor time) を喰ってしまうからだ。コネクション追跡は既に、 CPU時間 を気にせずにいられるぎりぎりの所まで来ている。そこへ更なるレイヤー、例えば前記の機能を加えれば、おそらく想像を絶する数のファイヤーウォールが使用不能となるだろう。その 1個の機能のメモリ消費量の問題を度外視したとしてもだ。
こうした機能に手をつけないのには他にも理由がある。世の中にはプロキシというテクノロジが存在する。プロキシは IP フィルタよりも上層のレイヤーでトラフィックを扱うために開発されたものであり、この要望を達成するにはそちらのほうが適しているのだ。プロキシの開発目的は、速度の遅いインターネット接続でもダウンロードやページ閲覧をできるだけ効率よく行うことだった。例えば WEBプロキシのひとつに Squid がある。誰かが今、或るページのダウンロード要求を出したとすると、プロキシがその要求を横取り、あるいは受信し、WEB ブラウザとのコネクションを開く。次にプロキシは WEB サーバに接続して当該のファイルをダウンロード。ファイル (あるいはページ) のダウンロードが完了したら、それをクライアントへと送る。今度、別のブラウザがさっきと同じページを要求してきたら、ファイル (あるいはページ) は既にプロキシの懐に存在するため、それを直に送ればいいので、帯域の節約になるというわけだ。
知っている人もいるだろうが、プロキシは、ダウンロードするファイルにもっと踏み込んで、内容を読み取る機能も備えている。だから、ストリームやファイル、ページの中身を検査するのなら、こちらにほうがずっと適しているのだ。
既に iptables 及び netfilter でレイヤー7 フィルタリングを行うことの問題点を警告したところで、実は、その問題の解決に挑む一連のパッチも存在する。これは http://l7-filter.sourceforge.net/ と呼ばれるもので、かなり多くのレイヤー7 プロトコルに対してマッチを行うことができる。ただし、l7-filter は、純粋なフィルタリングに使用できなくもないが、メインの用途は QoS や トラフィック・アカウンティング との併用だ。 l7-filter はまだカーネルや netfilterコアチームとは別のところで試験と開発が進められいるところで、それ故、当文書でこれ以上触れるつもりはない。
3.2. IPフィルタリングの用語と表現
これ以降のチャプターをよく理解するためには、 TCP/IP のチャプター で詳説したことも含めて、知っておくべき用語や表現が幾つかある。主要な用語を以下にリストにした。
Drop/Deny (破棄/拒否) - パケットを破棄あるいは拒否すると言う時には、そのパケットは削除され、あとは何のアクションも行わない。パケットが破棄された旨をホストに伝えもしないし、行くはずだったホストにはなおさらだ。ただパケットが消滅するだけだ。 [訳者註: 日本語には deny と reject をうまく区別する語彙がなく、訳すといずれも同じになってしまうので、訳文の中ではなるべく英語彙のまま記述する]
Reject (拒絶) - 基本的には drop や deny ターゲット (ポリシー) と同じだが、 reject の場合にはパケットが破棄されたという事実を送信者に返答する点が異なる。返答の内容は指定することもできるし、自動で決められる場合もある。(残念ながら、執筆時点の iptables には、破棄したパケットの行き先となっていたホストへ報告のパケットを送る機能 (例えば reject ターゲットの意味反転指定) はない。受け取り側ホストには DoS 攻撃をやめさせる術がないという事実に鑑みると、これは利点だともいえる。) [訳者註: 日本語には deny と reject をうまく区別する語彙がなく、訳すといずれも同じになってしまうので、訳文の中ではなるべく英語彙のまま記述する]
State (ステート) - ひとつのストリームの中における、パケットの状態 (state)。具体的に言えば、ファイヤーウォールが初めて観測した (知った) パケットは NEW というステートに識別され (TCPコネクションのSYNパケット)、また、ファイヤーウォールが既に認知している確立済みのコネクションに属しているパケットならば ESTABLISHED と判定される。ステートは、セッションを常に監視しているコネクション追跡機構 によって判断される。
Chain (チェーン) - チェーンは、ルールの集合体 (ルールセット) から成り、パケットがチェーンの中を進んでいく時にそれらのルールが適用される。それぞれのチェーンには特有の役割 (例えばそのチェーンがどのテーブルに属しているかによって、チェーンにできることできないことが決まる) や、適用範囲 (例えば foward されたパケットにのみ適用するとか、自ホスト宛てのパケットだけに適用するなど) がある。後で詳しく述べるが、 iptables には幾つものチェーンがある。
Table (テーブル) - 各テーブルには別個の使用目的があり、 iptables には 4つのテーブルがある。 raw, nat, mangle, filter テーブルだ。例えば filter テーブルはパケットをフィルタリングするためにできており、 nat テーブルはパケットに NAT (Network Address Translation = ネットワークアドレス変換) を施すために設計されている。
Match (マッチ) - IPフィルタリングでは、この語彙にはふた通りの意味がある。ひとつは、或るルールの中の単一の一致条件を指す場合。そのマッチは、ヘッダがこれこれの情報を持っていなければならないということをルールに指示する。例えば --source マッチは送信元アドレスが或る特定のネットワーク範囲やホストアドレスでなければならないということを指示する。もうひとつは、ひとつのルールを丸ごと 1 個のマッチと捉える場合。そのルールに指定してある全ての条件にマッチしたら、ジャンプ (ターゲット) に指定してある動作 (パケットの破棄など) が実行される。
Target (ターゲット) - ルールセットの中の各ルールにはたいてい、ひとつのターゲット・セットがある。ルールの持つ条件が全て満たされたらパケットに何を行うか、を指示するのがターゲットだ。 drop する、 accept する、 NAT を掛けるなどといった処置だ。もうひとつ、ジャンプ (jump) というものもあるが、それは当リストの jump の項目で述べる。最後にひとつ言い添えておくと、ルールには漏れなくひとつのターゲット (あるいはジャンプ) があるとは限らないが、まあ、たいていはある。
Rule (ルール) - ほとんど全ての IPフィルタ一般、そして iptables でも、ルールとは、ひとつのターゲットを従えた 1 項目または数項目の一致条件 (match) の集まりを指す。ひとつのルールが複数のターゲット (アクション) を持てるように実装した IPフィルタもある。
Ruleset (ルールセット) - ルールセットとは、幾つものルールから成るルールの総体のことで、 IPフィルタはこの "ルールセット" をロードして動く。 iptables の場合なら、ルールセットは、 filter, nat, raw, mangle の各テーブルとその下位にある全チェーンに組み込まれた、全てのルールを含有する。通常、ルールセットは設定ファイルの類に書き連ねる。
Jump (ジャンプ) - ジャンプ命令はターゲットと密接な関係にある。 iptables においては、ジャンプ命令はターゲットと全く同じ書き方となるが、唯一異なるのが、ターゲット名ではなく別のチェーンの名前を指定するという点だ。つまり、ルールの条件に一致したら、パケットは指定した副チェーンへと送られ、通常と同じようにそこで処理される。
Connection tracking (コネクション追跡) - ごく簡潔に言うと、コネクション追跡を備えたファイヤーウォールはコネクション/ストリームを追跡することができる。これを行うにはたいてい、プロセッサとメモリに大きな負荷がかかる。残念ながら iptables も例外ではないが、この課題には多くの努力が注ぎ込まれてきた。だが一方、コネクション追跡の良い面は、ファイヤーウォールポリシーの構築者がそれを適切に使えば、この機能を持つファイヤーウォールは持たないものよりも遙かに高いセキュリティを獲得できるということだ。
Accept (許可) - パケットを受け入れ (accept) て、ファイヤーウォール・ルールを通過させること。 drop, deny, reject ターゲットの反対だ。
Policy (ポリシー) - ファイヤーウォールの構築について語る時、ポリシーは大体 2種類の事柄を指す。まず、チェーンのポリシーがある。これは、どのルールにもマッチしなかったパケットを処すデフォルトのアクションをファイヤーウォールに指示する。当書物ではこちらの使い方が大勢を占める。 2種類目のポリシーは、例えば特定の企業や一個のネットワークのためのドキュメントを書く時に、その根底に置く、いわゆるセキュリティ方針だ。セキュリティ方針は、実際にファイヤーウォールの構築に取りかかる前に構想を練ったり問題点を洗い出したりするのに非常に有用なドキュメントだ。
3.3. IPフィルタの計画の仕方
ファイヤーウォールを計画する上でまず最初のステップは、それをどこに置くかだ。ネットワークはたいてい、はっきりとセグメントに分かれているので、これにはそう迷わない。最初に頭に浮かぶのはローカルネットワークとインターネットを隔てるゲートウェイ。ここはかなりタイトなセキュリティを施してしかるべき場所だ。また、大規模なネットワークでは、部署同士をファイヤーウォールで仕切るのも良い考えだ。例えば、開発部が人事部のネットワークへアクセスできる必要があるだろうか。経理部を他のネットワークからガードしない道理があるだろうか。早い話、解雇通知をよこされて頭に来ている従業員に給与データベースを見せて気が紛れるはずもないだろう。
上で言えることは、つまり、そもそもネットワーク自体を組み上げる時によく考え、区画に分けておかなければならないということだ。中/大規模なネットワーク (ワークステーションが 100 台以上の場合。何を基準に大小を論じるかにもよるが) では特にそうだ。小分けにしたネットワーク同士を、通過させたいトラフィックだけを通すようなファイヤーウォールでつなぎ合わせればいい。
また、インターネットからアクセスを受けるサーバがある場合には、ネットワーク内にデミリタライズゾーン (De-Militarized Zone = 非武装地帯, DMZ ) を構築するのも一案だ。 DMZ は極限までアクセスを制限した何台かのサーバから成る物理的に独立した小さな隔離ネットワークのこと。この方法を用いれば、 DMZ 内のマシンに誰かが入り込める可能性は低くなり、潜り込んで外界からトロイの木馬などをダウンロードされる危険性が抑えられる。非武装地帯と呼ばれる理由は (DMZ 一般を一口に言ってしまえば) そこが内側からも外側からもアクセスできる、一種のグレーゾーンだからだ。
ファイヤーウォールにポリシーや既定動作を持たせるには幾つかの方法がある。このセクションでは、実際にファイヤーウォールの実装を始める前に検討すべき実践的なセオリーについて説明する。実装に際して有益な判断材料となるだろう。
まず基本中の基本として、ファイヤーウォールにはほぼ必ず、既定の動作というものがあることを理解しておかなければならない。例えば、或るチェーンの中でそのパケットに合致するルールがひとつも無かった時には、既定動作で drop または accept される。残念ながら各チェーンの持てるデフォルトポリシーはひとつだけだが、例えばネットワークインターフェイス毎に別々のポリシーを与えるなどして、この問題を克服することもできる。
一般によく使うポリシーには 2 つのパターンがある。指定したもの以外は全部 drop するか、反対に、破棄すると指定したもの以外を全て accept するかだ。ほとんどの場合に我々の興味を引くのは専ら drop 型ポリシーのほうで、許可したいものは全て具体的に指定して受け入れる。 drop 型ポリシーは、安全性が高いという事実がある反面、ファイヤーウォールを正常に機能するところまで持っていくだけでも accept 型よりずっと手間がかかる。
あなたが迫られる最初の決断は、どちらのタイプのファイヤーウォールが適切かだ。セキュリティの重大性はどれくらいだろうか。ファイヤーウォール越しにどんなアプリケーションを利用するのだろうか。一部のアプリケーションは、データストリームに使用するポートがコントロールセッション内でのネゴシエーション (話し合い)で決められるという理由から、ファイヤーウォールにとって嫌な相手だ。ファイヤーウォールにとっては、開くポートを知るのが非常に困難なのだ。 iptables は一般的なアプリケーションならばそのほどんどを扱えるが、一般的でないアプリケーションの中には、残念ながらまだ対応していないものもある。
| 対応が不完全なアプリケーションというのもある。そのひとつが ICQ だ。通常の使い方なら完璧に動く。しかし、チャットとファイル送信機能は、プロトコルを扱うために特別なコードを必要とするため、動作させられない。 ICQ プロトコルは標準化されていない (パテント技術であり、いつ何時変更されるか分からない) ので、大多数の IPフィルタは ICQ プロトコルハンドラを蚊帳の外にするか、パッチとしてだけ提供している。 iptables が選択したのはパッチとして別途提供する方向だ。 |
また、多重セキュリティ戦略を用いるのも良いことだ。実は、その一部については既に言及している。どういうことかというと、できるだけ多くの安全策を張り巡らし、単一の政策に頼り切らないようにするのだ。そうしたコンセプトを採ることによって、軽く 10倍はセキュリティを高めることができる。例としてこれを見てもらおう。
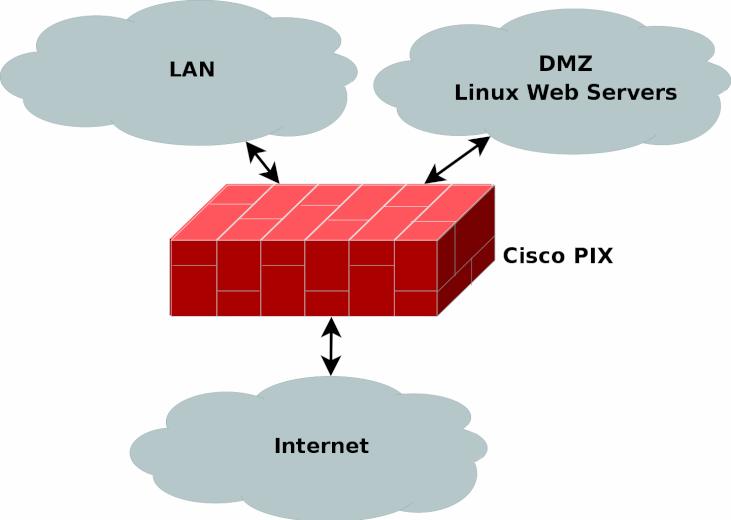
ご覧のように、この例では全てのネットワークコネクションの接点となる位置に 1台の Cisco PIX ファイヤーウォールを据えている。このファイヤーウォールは内部の LAN を NAT し、また必要に応じて DMZ に対しても NAT を行ことになるだろう。また、 http, ftp, ssh の戻りのトラフィックを除いた外向きのトラフィックをすべてブロック。 LAN 及びインターネットからやってくる http トラフィックは通し、 LAN からは ftp, ssh トラフィックも許可するとしよう。これに加えて、 WEB サーバはいずれも Linux で動いていると仮定して、それらサーバ自体にも iptables 及び netfilter を投入し、基本的にファイヤーウォールと同様のポリシーを持たせる。このようにしておけば、万が一何者かが Cisco PIX の陥落に成功したとしても、各マシンのローカルの netfilter ファイヤーウォールが我々を守ってくれるし、その逆もまた大丈夫というわけだ。こうした施策を多重セキュリティと呼ぶ。
そこへ上乗せして、各マシンで Snort を動かすという手もある。 Snort は優れたオープンソースのネットワーク侵入検出システム (NIDS = network intrusion detection system) で、接したパケットの中のシグネチャを検査する。そしてもし何らかのアタックや侵入を示すシグネチャを発見したら、システム管理者へ eメールで知らせたり、さらに一歩踏み込んで、アタックの出所だった IP をブロックするなどの積極的対応を行うこともできる。ただし、積極的対応 は安易に使用してはならないということも言い添えておく。というのも、 Snort にはかなりの誤検出をレポートする悪い癖 (本当はアタックではないのにアタックとして報告するなど) があるからだ。
WEB サーバの手前にプロキシを導入して不正なパケットを捕まえるというのも良い考えだ。あるいはまた、ローカルネットワークからの WEB トラフィック用のプロキシを配置するという手もある。 WEBプロキシを使うと、従業員によって消費されるトラフィックが削減でき、さらに、彼らの WEB 使用量を或る程度制限することさえ可能だ。自社 WEB サーバ用 WEBプロキシのほうは、典型的な侵入の企みを防ぐ効果もある。使ってみる価値のある優秀なプロキシといえば Squid だ。
それ以外に考え得る防衛策のひとつに Tripwire のインストールがある。これは、最終防衛ラインとも言うべき優れたアプリケーションで、ホスト侵入検知システム (Host Intrusion Detection System) と呼ばれるもののひとつだ。 Tripwire は、設定ファイルで指定した全てのファイルに対してチェックサムを作成し、 cron で定期的にチェックすることにより、ファイルが前と変わりないか、改変されていないかを確認する。つまり、何者かがシステムに侵入して不正書き換えを行っていないかを、監視できるわけだ。お勧めするのは、全ての WEB サーバでこれを動かしておくことだ。
そして最後に挙げる重要な留意事項は、もう承知のことかもしれないが、標準化されていない技術や規格を使用しないのが最善であるということだ。 ICQ の話でも分かったように、標準化されていないシステムは使わないようにしないと、ほころびがほころびを呼んで酷いことになる。閉じた環境内でなら多少のことは問題ないが、ブロードバンドサービスやモデムプールを運営する場合には、これは大変重要な問題だ。あなたのところと遣り取りする人は全員あなたのところの規格に従わなければならないわけだが、全員に同じオペレーティングシステムを期待するのは無理な話。ある人は Windows、ある人は Linux、さらには VMS を使いたがる人もいるかもしれない、といった具合だ。セキュリティを特殊なパテント技術に負っていると、某かの問題を抱え込むことになる。
その典型例に、スウェーデンで最近始まった一種のブロードバンドサービスがある。このサービスはマイクロソフトネットワークログオンの上に成り立っている。そう聞いただけでは名案だと思えるかもしれないが、オペレーティングシステムが異なる場合を考えると、これはもう名案どころではない。 Linux ユーザはどうしたらログインできるのか? VAX/VMS だったら? HP/UX は? もちろん Linux であれば利用も不可能ではないが、それもネットワーク管理者がそんなブロードバンドサービス通信をブロックしていなかったとしての話だ。何はともあれ、当文書はどれが一番かを論じる宗教論争本ではないので、非標準化技術の利用が間違いであるという例として触れるだけに留めておく。
3.4. まとめ
このチャプターでは IP フィルタリングの概念と、ネットワークやワークステーションやサーバのセキュリティを固めようとした時にどういった戦略を採り得るかについて述べてきた。取り上げた論点は:
IPフィルタリングの適用法
IPフィルタリングにおけるポリシー
ネットワークの設計プラン
ファイヤーウォールの設計プラン
多重セキュリティテクニック
ネットワークのセグメント化
次のチャプターで我々は、ネットワークアドレス変換 (NAT) とは何かについて簡単に触れ、その後 iptables とその働きを詳しく見て回り、いよいよこの魔物との闘いに着手する。
Chapter 4. ネットワークアドレス変換とは
NAT は今日の Linux 及び iptables で最も興味をそそる機能のひとつだと思う。例えば Cisco PIX などといったサードパーティのソリューションにたいまいをはたく代わりに、多くの中小企業や個人ユーザがソリューションとしてこちらを選択している。その大きな理由のひとつが、廉価で且つセキュアだという点だ。型落ちのコンピュータと比較的新しい Linux ディストリビューション (しかもダウンロードで無料で手に入る) と、余り物のネットワークカード 1 枚か 2 枚とケーブル。それくらいあればいいのだから。
このチャプターでは NAT の基本的理屈について少々語り、利用目的や動作の仕組み、それに、 NAT と取っ組み合う前に検討しておくべき事柄について述べていく。
4.1. NATの利用目的と用語解説
簡単に言えば、 NAT は何台かのホストでひとつの IPアドレスの共用を可能にするひとつの手段だ。例えば今ここに、5 〜 10 台のクライアントから成るローカルネットワークがあるとしよう。クライアント全てのデフォルトゲートウェイが 1 台の NAT サーバを指すようにする。普通ならばパケットはゲートウェイマシンによって単純にフォワードされるだけだが、 NAT サーバの場合は少し事情が異なる。
NAT サーバは (前にも軽く触れたことだが) パケットの送信元アドレスと宛先アドレスを別のアドレスへと変換する。 NAT サーバは、パケットを受け取ると送信元と宛先のいずれかまたは両方を書き換え、パケットの持つチェックサムを計算しなおす。 NAT を使う時、たいていの場合は SNAT (送信元ネットワークアドレス変換) であることが多い。前記の例で SNAT を使うのは、大概、クライアントにひとつ残らず正真正銘のパブリック IP を与える予算がなかったり、どうしたらそんなことが実施できるか思いつかない場合だ。そうした時、我々はプライベート IP 域からひとつの範囲 (192.168.1.0/24 だとしよう) を選び出して使い、そのネットワークに SNAT を施す。すると SNAT は 192.168.1.0 内の全アドレスを NAT サーバ自身の持つパブリック IP (例えば 217.115.95.34) へと通訳 (translate) する。このやり方をすれば、 5 〜 10 台あるクライアント (その気になればもっともっと) で 1 個の IP アドレスを共用することができるわけだ。
もうひとつ DNAT と呼ばれるものも存在する。これはサーバを立てる時などに大活躍する。一番の恩恵は IP スペースの節約に大いに役立つこと、次に、サーバと本物のサーバ群との間に、ほぼ侵入不可能なファイヤーウォールが簡単に実現できること、さらに、物理的に独立した複数台のサーバでひとつの IP を共用できることだ。次のようなわりと小規模な企業のサーバ集合体を考えてみよう。 WEB サーバと FTP サーバは 1 台で運用している。その他に、出先や自宅にいる社員が社内にいる社員といつでも話をできるよう、チャットサービスを提供する物理的に別個のサーバが 1 台ある。 DNAT を介すれば、これら全てのサーバサービスをたったひとつの IP で外部に提供できるのだ。
上記の例は、セパレートポートNAT (PNAT と呼ぶことも多い) のことだという見方もできる。当文書ではセパレートポートNAT にはあまり言及しない。というのも、 netfilter においては、その機能は DNAT と SNAT の中に取り込まれているからだ。
実は Linux ではふたつの違ったタイプの NAT が使えるようになっている。 Fast-NAT と Netfilter-NAT だ。 Fast-NAT は Linux カーネル内の IP ルーティングコードとして実装されており、 Netfilter-NAT は、 Linux カーネル内ではあるがその netfilter コードの中にある。この文書は IP ルーティングコードに深入りはしないのでこの辺でやめておくが、参考にひとつふたつ話をしておこう。 Fast-NAT がその名で呼ばれるのは、 Netfilter-NAT コードよりも格段に速いからだ。 Fast-NAT はコネクション追跡を行わない。そこが Fast-NAT の利点でもあり欠点でもある。コネクション追跡は多くの CPU パワーを必要とし、それが故に処理速度が遅い。これが Fast-NAT が Netfilter-NAT より速い理由だ。先ほど述べたように Fast-NAT の困ったところはコネクション追跡を行わない点で、ネットワーク単位の SNAT がうまく扱えないし、 Netfilter-NAT の得意とする FTP, IRC をはじめとした複雑なプロトコルの NAT もできない。不可能というわけではないのだが、 Netfilter を使ってやるよりも遙かに手間がかかる。
最後に残った単語がひとつある。基本的には SNAT の同義語なのだが、それがマスカレード (Masquerade) という単語だ。 Netfilter においてはマスカレードは SNAT と極めて近い。唯一の違いは、変換後の送信元アドレスを、自動的に、外と接するネットワークインターフェイスの持つデフォルト IP アドレスにするという点だ。
4.2. NAT使用時の注意点
これまでにも軽く触れたが、NAT を使用する際には幾つか細かい注意点がある。まず第一に、全く機能しないアプリケーションがあることだ。ありがたいことに、こうしたアプリケーションはネットワークの世界でマイナーな存在であり、大きな問題につながることは少ない。
二番目は先の問題よりも小さいが、一部不完全にしか動作しないアプリケーションやプロトコルの問題だ。そうしたプロトコルは、全く動作しないプロトコルよりはメジャーなもので、残念ながら、現在のところ、この点に関して我々にできることは少ない。もしこれからも複雑なプロトコルが登場し続けると、我々はこうした問題に延々と付き合わされることになる。特に、標準化されていないプロトコルが問題だ。
残る三番目の大問題は、やや僕の私見になるが、 NAT サーバによってインターネットと隔てられそこを介してしか外へ出て行けないユーザは、自分のサーバを立てることはできないという事実だ。もちろんやれないことではない。しかし設定には多くの時間と労力が要求される。これも、企業においては、インターネットからアクセス可能なサーバが社員達の手で無統制に山ほど立てられるよりは好ましいことだろう。しかし、話をホームユーザに転じると、これは是が非でも避けなければならない事態だ。あなた方がインターネットサービスプロバイダならば、利用者にプライベート IP を割り当てておいてパブリック IP へ NAT するなどということをしてはいけない。そんなことをすれば、あなたは無用のトラブルを抱え込むこととなる。あのプロトコルがちゃんと動くようにしてくれ、このプロトコルも通るようにしてくれと、ユーザからの要求が次から次へと押し寄せることになるだろう。ユーザが変に静かだとすれば、あなたのワラ人形に密かに釘を打ちつけているのかもしれない。
NAT の注意点として最後に添えておきたいのは、元来 NAT は応急処置的に考え出された技術だという点だ。インターネットのあまりにも急速な普及で IPアドレスがじきに枯渇するということが IANA をはじめとした各種団体によって指摘されたのを受け、考え出されたひとつの打開策なのだ。 NAT は、かつて IPv4 (これまで話の中で使ってきた IP とは、実は IPv4 つまり Internet Protocol version 4 の省略形だった) の欠点を補うための急場しのぎとして考案され、そして今でも使われている。 IPv4 アドレス枯渇の根本的解決は IPv6 であり、 IPv6 が普及すれば他にも様々な問題が解決できる。 IPv4 の IPアドレスが 32 ビットであるのに対して、 IPv6 ではアドレスの定義に 128 個のビットを使用する。アドレス空間は飛躍的に増えることになる。しかし IPアドレスの数が充分だからといって地球上の全てのネットワーク最小単位にいちいち IPアドレスを与えるのは馬鹿げているのではないだろうか。かつて、 IPv4 のアドレス空間だって小さすぎるなどとは誰も思ってもみなかったのだ。
4.3. 概念を理解するためのNATマシン構築例
ここでは、 NAT の概念を示すため、ネットワークふたつとインターネットコネクションとの真ん中に NAT サーバを配置するという比較的単純な例を紹介する。目標とするのは、ふたつのネットワークをつなぎ、両ネットワークが互いにアクセスでき、且つ、インターネットへもアクセスできるようにすることだ。また、ハードウェアに関して考慮すべき点や、実際に NAT マシンの構築を始める前に考慮しておかなければならないその他のセオリーについても述べる。
4.3.1. NATマシン構築に必要なもの
本題に入る前にまず、 NAT 用 Linux マシンを仕立てるのにどういった類のハードウェアが必要かを知っておかなくてはならない。小規模なネットワークのほとんどでは取り立てて問題にはならないだろうが、大規模なものを扱うようになるとこれが問題になってくる。最大の問題は、 NAT がかなり急速にリソースを食いつぶすという点だ。 1 から 10 台くらいのユーザしかいない小規模なプライベートネットワークなら、 RAM 32 MB の 486 マシンで充分以上に動く。しかし、もし 100 ユーザ以上を扱うつもりならば、手元にあるハードウェアで大丈夫か、よく考えてみる必要が出てくる。当然、帯域幅や、どれくらいの数のコネクションが同時に発生するかについても考察しておくのが正しい。とはいえ、大概は余り物のコンピュータでもしっかりと仕事をしてくれるし、それが Linux ベースのファイヤーウォールの大きな利点でもある。余っていた古いドンガラが使え、おかげで、他のファイヤーウォール製品に比べてずっと安価にファイヤーウォールが仕立てられるのだ。
ネットワークカードについてもよく検討する必要がある。幾つのネットワークが NAT/フィルタマシンに接続してくるのだろうか。たいていの場合、インターネットコネクションへコネクトさせるのはネットワークひとつだけで充分だ。イーサネットを使ってインターネットへ接続するなら、必要なのは通常 2 枚のイーサネットカードとその他諸々だ。スケーラビリティを考慮すると比較的有名なブランドの 10/100 mbit/s ネットワークカードを選ぶに越したことはないが、 Linux のカーネルがドライバを持っていれば大体どんなカードでも動くことは動く。この点で少々言っておかなければならないことがある: 頒布されている Linux カーネルがドライバを備えていないようなネットワークカードを使ったり、使おうとして手に入れるのは、避けるべきだ。僕には、ドライバが別途ディスクで添付されている型式やブランドのネットワークカードに行き当たって、惨めな結果に終わった経験が何度かある。そうしたドライバは更新がきちんと行われていないことが多く、仮に今標的にしているカーネルで動作に漕ぎ着けたとしても、将来、カーネルのメジャーアップグレードをした際にきちんと動いてくれる可能性は極めて小さい。そうした事柄を考え合わせると、結局、ちょっとばかり高めのネットワークカードを使えというところに落ち着く。長い目で見れば決して損にはならないはずだ。
参考までに付け加えておく。ファイヤーウォールをかなり旧式のハードウェアで作ろうと思っているとしたら、できる限り PCI バスかそれ以上のインターフェイスの使用を検討したほうがいい。第一に、そのカードは将来マシンをアップグレードする時にもおそらく流用できるだろう。それにもうひとつ、 ISA バスは非常に低速で、 CPU の使用率も高いという点だ。 ISA ネットワークカードによる CPU パワーの大量消費は、マシンをダウンさせる危険と隣り合わせなのだ。
最後の一点として、どれくらいのメモリを NAT/ファイヤーウォールマシンに搭載するかを検討しないわけにはいかない。 32 MB でも動かないこともないが、可能であれば、最低でも 64 MB 以上のメモリを積んだほうがいい。 NAT はメモリに関しては極端に大食いというわけではないが、想定した以上のトラフィックが発生した場合に備えて、できるだけたくさん積んでおくのが正しい選択だ。
ご覧のように、ハードウェア面で検討しておく事項はかなりたくさんある。しかし、本当に正直なところを言ってしまえば、大規模ネットワーク用の NAT マシンを作る場合を除けば、これらはほたいてい全く考える必要がない。ほとんどのホームユーザは考える必要はなく、手近にあるハードウェアの中からどれを使おうと構わない。この問題に関する総合的な比較やテストというものは行われたことがない。ただ、常識的な思慮をちょっと働かせれば、事はずっとうまく運ぶはずだ。
4.3.2. NATマシンの配備位置
この問題は非常に単純に思われるかもしれない。しかし、大きなネットワークでは、思ってもみなかったほどの難問になることがある。一般論としては、 NAT マシンはちょうどフィルタリングマシンと同じようにネットワークの境界点に設置する。当然の帰結として、 NAT とフィルタリングは同一のマシンである場合が多いわけだ。また、非常に大規模なネットワークを扱うのであれば、ネットワーク全体を幾つかのセグメントに分割し、セグメント毎に個別の NAT/フィルタリングマシンを割り当てるという方策にも一考の余地がある。 NAT は多くの CPU パワーを要求するので、このやり方はラウンドトリップ時間 (RTT、ひとつのパケットが宛先へ到達して返答が返ってくるまでの時間) の増加を抑えるのにも効果的だ。
既に示した、ふたつのネットワークとインターネット接続を持つ例のネットワーク構成では、それらふたつのネットワークの規模を勘案する必要がある。比較的小さいと考えれば、クライアントがどんなことを要求するかにもよるが、まともな NAT マシンにとって 200 や 300 のクライアントは問題とならない。とはいえ、パブリック IP を各々与えた NAT マシンを数台置いて負荷を分け合い、各 NAT マシンは担当のセグメントの面倒だけを見るようにして、トラフィックを最終的に 1 台のルーティング専用マシンへ委譲させるように仕立てる手もある。ただし、これをやるには、充分な数のパブリック IP と、パケットをルーティングできるルーティングマシンのことも考えなくてはならない。
4.3.3. プロキシの配置の仕方
不幸なことに、 NAT にとって、プロキシ、特に透過プロキシとの問題は付きものだ。普通のプロキシならばそれほど問題となることはないが、大規模なネットワークでは特に、透過プロキシは強敵となる。第一点として、プロキシは NAT と並んで大量の PCU パワーを必要とする。大規模なネットワークの場合、 NAT とプロキシを 1 台のマシンで賄うのは無理だ。第二に、送信元と宛先の両方を NAT した場合、プロキシには、いったいどのホストへ接続したがっていたのかが分からない。例えば、そのクライアントがどのサーバへコネクトしたがっていたのかが、判定できないのだ。パケットの本来持っていた宛先情報は NAT 変換を施した際に消え、パケットは元の情報を同時には保持できないため、こうした問題が生じる。ただ、ローカル内でだけなら、パケットの備えるしかるべき 内部データ構造にそうした情報を書き加えることによって、プロキシ (例えば Squid) に情報を伝えることは可能だ。
ご覧のように、透過プロキシの問題に突き当たったら対処策の選択肢はほとんど限られてしまっている。もちろん他にも考えられなくはないが、あまりお勧めできる方法ではない。そのひとつとしては、ファイヤーウォールの外側にプロキシを立て、全ての WEB トラフィックをそこへ導くようなルーティングテーブルを作成して、プロキシマシンそれ自体の中で、 WEB パケットをプロキシで決めてある所定のポートへ NAT するというやり方だ。こうすれば、必要な情報はパケットがプロキシマシンに到着するまで保持され、プロキシマシンもその情報を利用できる。
もうひとつの方策は、ファイヤーウォールの外側にプロキシを立て、 WEB トラフィックはプロキシマシン宛てのもの以外全部遮断するという方法だ。こうすると、全ユーザにプロキシの使用を強制することができる。強引なやり方ではあるが、うまくいかなくも ないだろう。
4.3.4. NATマシン構築の最終段階
最後のステップとして、これまで述べてきた情報全てを統合し、どう NAT マシンを仕上げるかについて見ていく。まずネットワーク同士の関係を思い描いてみることにしよう。我々は前述の中で、プロキシを NAT/フィルタリングマシンのすぐ外、且つ、ルータよりも内側に設置することに決めた。この領域は DMZ だと考えることができ、 NAT/フィルタリングマシンはこの DMZ とふたつの内部ネットワークとの間に位置する。下の図で、今話している構想のレイアウトが見て取れるだろう。
NAT 処理されるネットワーク [訳者註: つまりふたつの LAN] から来た通常のトラフィックは全て、 DMZ をくぐってルータへと送られ、ルータがインターネットへと送り出す。ただし、お察しの通り、 WEB トラフィックだけは、 NAT マシン上の netfilter がマークを付け、そのマークに基づいてプロキシマシンへとルーティングする。僕が何を言っているのか整理しよう。今、 NAT マシンが http パケットを見つけたとする。 mangle テーブルを使ってパケットに netfilter の mark (nfmark とも呼ばれる) が付けられる。この nfmark はあとでパケットをルータへとルーティングする時になってもルーティングテーブルと照合できるので、この http パケットを選り分けてプロキシサーバへとルーティングすることができる。それが終わると、プロキシサーバはパケットに対して本来の自分の仕事を果たす。ルーティング関連の部分は、幾分、高度ルーティングの領域に属する事柄だが、この話題には当文書の後半でも幾らか詳細に触れることにしている。
NAT マシンにはインターネット上で通用する本物の IPアドレスを与えている。ルータと、インターネットから見えなくてはならない数台のマシンもそうだ。かたや、 NAT されるネットワークの中のマシンは全てプライベートアドレスだ。これによって、予算もインターネットアドレス空間も節約できる。
4.4. まとめ
このチャプターでは NAT とそれに関連する理論について詳しく説明してきた。中でも、採り得るべき幾つかの視点と、 NAT をプロキシと併用する場合に惹起される一般的な問題については詳しく述べた。以下のような項目だ。
NATの使い方
NATの構成要素
NATの歴史
NAT関係の用語
NATを利用する上でのハードウェアについて
NATの問題点
いずれも、 netfilter/iptables に取り組んでいる間中ずっと役に立っていく話題だ。不幸かな予測のつかなかった或る問題への一時的な解決手段に過ぎないにしても、 NAT は、現在のネットワークで広く使われている。 NAT に関しては、追って Linux の netfilter/iptables の実装について具体的な説明を始める辺りでも、当然、もっと詳しく話をする。
Chapter 5. 準備
このチャプターは、心の準備をするところであり、Netfilter と iptables が今日の Linux で担う役割を理解していただくところでもある。このチャプターを読み終わったら、いざ実験とファイヤーウォール構築に向けて準備完了、となっていることを切に願う。ここはじっくり忍耐で、あなたのやりたいことはもうすぐそこだ。
5.1. iptablesの入手先
iptables のユーザ空間パッケージは http://www.netfilter.org/ でダウンロードできる。 iptables パッケージはカーネル空間の機能も利用するが、それらは make configure の際にカーネルに組み込まれる。必要な手順は追って解説する。
5.2. カーネルのセットアップ
iptables の根幹部分を機能させるには、カーネルの make config あるいはそれに類するコマンドの中で、下記のオプションを設定する必要がある:
CONFIG_PACKET -- このオプションによって、様々なネットワークデバイスと直接やりとりしながら働くようなアプリケーションやユーティリティが、動作可能となる。そうしたユーティリティには tcpdump や snort などがある。
| 厳密に言えば、CONFIG_PACKET は iptables を動作させるのに必須ではないのだが、実に様々な使い方ができるので、ここに含めることにした。入れたくないなら入れなくてもいい。 |
CONFIG_NETFILTER -- コンピュータをインターネットへのファイヤーウォールかゲイトウェイとして使うつもりなら、このオプションが必要。言い換えれば、そもそもこのチュートリアルに出てくる何かひとつでも働かせたいなら、何はなくとも必ず要る。このドキュメントを読んでいるということは、必要なはずだ。
それにもちろん、インターフェースをきちんと動作させるための適切なドライバも加えなくてはいけない。イーサネットアダプタ、 PPP、SLIP インターフェースなどだ。上記は iptables の根幹の一部を加えてくれるだけ。正直言って建設的なことは何もしていないわけで、ただカーネルに骨組みを与えているだけだ。 iptables でより高度なオプションを使うには、適切なカーネル設定オプションを加えなければならない。これから、ベーシックな 2.4.9 カーネルで指定できるオプションの紹介と、その簡単な説明をしていこう:
CONFIG_IP_NF_CONNTRACK -- このモジュールはコネクション追跡 (Connection tracking) を行うのに必要。コネクション追跡はいろいろな用途に利用されるが、特に NAT とマスカレード (Masquerading) で重要となる。 LAN のマシンをファイヤーウォールで守りたいのなら、絶対にマークを付けなくてはならない。例えば rc.firewall.txt を動かすためにも必須条件となる。
CONFIG_IP_NF_FTP -- FTP 接続のコネクション追跡を行いたいならこのモジュールが必要。FTP 接続は、通常の状態では追跡が非常に困難なため、conntrack だけでなく、ヘルパー と呼ばれる追加モジュールが必要となる。このオプションがそのヘルパーのコンパイル指定だ。このモジュールを加えないと、ファイヤーウォールやゲイトウェイを越えて FTP することはできない。
CONFIG_IP_NF_IPTABLES -- 何かしらのフィルタやマスカレード や NAT を行いたいなら、このオプションが必要。これはまさに iptables の識別構造の一切合切をカーネルに与える。 iptables で何かやるなら、これがなくては始まらない。
CONFIG_IP_NF_MATCH_LIMIT -- 厳密には必須でないが、rc.firewall.txt で使っている。このオプションは LIMIT マッチを可能にする。つまり、しかるべきルールを書くことで、1 分あたりにいくつのパケットがマッチするかを制御することができる。例を挙げると、-m limit --limit 3/minute には、1 分あたり 3 個のパケットがマッチする。このモジュールはまた、ある種の DoS 攻撃を避けるのにも利用できる。
CONFIG_IP_NF_MATCH_MAC -- これは MAC アドレスによるパケットマッチを可能にする。イーサネットアダプタ は必ず MAC アドレスを持っている。MAC アドレスは滅多に変わらないため、例えば、どういった MAC アドレスを使用しているかによってパケットを遮断すれば、特定のコンピュータを非常に効果的にブロックすることができる。 rc.firewall.txt をはじめ、どの例でも、このオプションは使っていない。
CONFIG_IP_NF_MATCH_MARK -- MARK マッチを可能にする。 MARK ターゲットを使えば、パケットにマークを付けておき、マークがセットされているかどうか調べることで、マークを評価基準としたマッチが行える。実のところ、このオプションは MARK マッチに関するものだが、MARK ターゲット に関するオプションも後で出てくる。
CONFIG_IP_NF_MATCH_MULTIPORT -- 宛先または送信元ポートを複数指定してパケットをマッチさせることができる。こうしたことは通常は不可能だが、これを使えば可能になる。
CONFIG_IP_NF_MATCH_TOS -- この評価を使えば、パケットの TOS フィールドに基づいてパケットをマッチさせられる。 TOS とは Type Of Service のこと。TOS は mangle テーブルのしかるべきルールや ip/tc のコマンドを使用して書き換える こともできる。
CONFIG_IP_NF_MATCH_TCPMSS -- MSS フィールドに基づいて TCP パケットのマッチを行う機能を追加する。
CONFIG_IP_NF_MATCH_STATE -- これは、ipchains との違いの中で最も大きな話題のひとつだ。このモジュールのおかげで、パケットのステートフルマッチが行える。例えば、ある TCP コネクションで既に双方向のトラフィックを検出している時、このパケットは ESTABLISHED と判定される。 rc.firewall.txt の中でも駆使している。
CONFIG_IP_NF_MATCH_UNCLEAN -- このモジュールは、タイプの規定に従わない IP、TCP、UDP、ICMP パケットや、無効なパケットを選別する機能を追加する。例えば、パケットの正当性に無頓着に、これらのパケットを捨て去ることができる。留意すべきは、このマッチはまだ実験段階にあり、たいていの場合完全には機能しないという点だ。
CONFIG_IP_NF_MATCH_OWNER -- このオプションはソケット のオーナーに基づいたマッチ機能を追加する。例えば、root にだけインターネットアクセスを許すといったことができる。このモジュールは元々、新しい iptables の機能を示す例として書かれたもの。このマッチは実験段階にあり、必ずうまく動くとは限らない点に注意。
CONFIG_IP_NF_FILTER -- このモジュールは基本的な filter テーブルを加え、これによって初めて IP フィルタリングが可能となる。 filter テーブル内には INPUT チェーン、FORWARD チェーン、OUTPUT チェーンがあるということは、後々分かるだろう。送受信パケットについて何にせよフィルタリングを行うつもりなら、このモジュールは必要だ。
CONFIG_IP_NF_TARGET_REJECT -- このターゲットを用いれば、入ってくるパケットに対して、黙殺して床に投げ捨てるのではなく ICMP エラーメッセージを返すことができる。 ICMP や UDP とは異なり、 TCP では TCP RST パケットによって接続のリセットや拒否ができるということも記憶に留めておこう。
CONFIG_IP_NF_TARGET_MIRROR -- パケットをその送り主に跳ね返すことが可能となる。例えば、 INPUT チェーンで宛先ポート HTTP に対して MIRROR ターゲットを設定しておく。ある人がこのポートにアクセスしようとすると、パケットは跳ね返されるので、結果として彼には自分のホームページが見えるはずだ。
 | MIRROR ターゲットは、軽々しく使っていい類のターゲットではない。 MIRROR ターゲットは元々テスト向けの用例モジュールとして作られたものであり、得てして、設定を行った側に重大な危険をもたらす (例えば極度の DDoS に陥る等)。 |
CONFIG_IP_NF_NAT -- このモジュールは様々な形でのネットワークアドレス変換 つまり NAT を可能とする。テーブル群のうちの nat テーブルへアクセスできるようになる。ポートフォワードやマスカレードなどを行うには、このオプションが必要だ。LAN のファイヤーウォール構築やマスカレードには必須ではないが、ユニークな [訳者補足:インターネットで有効な] IP アドレスをホスト全部に与えられる場合を除き、これは備えておかなくてはならない。そういうわけで、 rc.firewall.txt スクリプトを動作させるのに必要だし、そもそも、上記のような IP アドレスを自由に追加できないネットワークでは、なくてはならないモジュールだ。
CONFIG_IP_NF_TARGET_MASQUERADE -- このモジュールは MASQUERADE ダーゲットを加える。例えば、どんな IP でインターネットにつながっているか分からない時に、 IP を獲得するための手段として、 DNAT や SNAT の代わりに用いることが多い。言い換えると、DHCP、PPP、SLIP などによって IP をもらっているなら、 SNAT でなくこちらを使う必要がある。マスカレードはコンピュータへの負荷が NAT よりも多少大きいが、 IP アドレスをあらかじめ調べておかなくても機能してくれるのが強みだ。
CONFIG_IP_NF_TARGET_REDIRECT -- このターゲットはアプリケーションプロキシを使う場合などに便利。パケットを直に遣り取りする代わりに、パケットをリマップしてローカルマシンに送ることができる。つまり、この手段によって透過プロキシの構築が可能となる。
CONFIG_IP_NF_TARGET_LOG -- LOG ターゲットを加え、 iptables にそれを利用する能力を与える。このモジュールを使えば、特定のパケットを syslogd に記録させることができ、ひいては、パケットに何が起きているのか調べることができる。セキュリティ監査とスクリプトのデバグにはもってこいの機能。
CONFIG_IP_NF_TARGET_TCPMSS -- このオプションは、 ICMP の Fragmentation Needed パケットをブロックしてしまうインターネットサービスプロバイダと対峙するのに使う。 WEBページが通らない、小さなメールはいいが大きなメールが通らない、ssh はいいが scp がだんまりになる、などといった症状だ。その場合、 TCPMSS ターゲットを使用し、 MSS (Maximum Segment Size) を PMTU (Path Maximum Transmit Unit) へ強制的に書き換えることによって障害を乗り越えることができる。カーネルの設定ヘルプで Netfilter の制作者たちがいうところの 「犯罪的にトロいISPやサーバ」 に、これでもって立ち向かえるのだ。
CONFIG_IP_NF_COMPAT_IPCHAINS -- 旧式 ipchains との互換モードを加える。 Linux 2.2 カーネルから Linux 2.4 カーネルへ移行する際の、根本的永続的な解決策だと思ってはいけない。カーネル 2.6 ではうまく面倒を見てくれるだろうから。
CONFIG_IP_NF_COMPAT_IPFWADM -- 旧式 ipfwadm との互換モード。根本的永続的な解決策だと思ってはいけない。
ご覧の通り、オプションは山のようにある。各モジュールでどんな付加機能が得られるのか、ざっと説明してきたわけだが、これらは、無垢な Linux 2.4.9 カーネルで利用できるオプションのみに過ぎない。もっとたくさんのオプションが知りたければ、 Netfilter のユーザ空間にある patch-o-matic (POM) 機構を覗いてみるといいだろう。そうすれば、カーネルに追加できるオプションはまだまだ出てくる。 POM パッチは、行く行くカーネルに加わる予定だがまだカーネルに盛り込まれていない追加オプションたちだ。入り込めていないのにはいろいろと理由がある。パッチの安定性が充分でない、 Linus Tovalds 氏が把握しきれていない、カーネルのメインストリームに乗せるにはまだ実験的すぎる、などなどの理由だ。
rc.firewall.txt スクリプトを動作させるには、下記のオプションがカーネルにコンパイルされている必要がある。他のスクリプトに必要なオプションが知りたい時は、スクリプト例のセクションを見てほしい。
CONFIG_PACKET
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_FTP
CONFIG_IP_NF_IRC
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_TARGET_LOG
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_TARGET_MASQUERADE
rc.firewall.txt スクリプトには、最低でも上記のものが必要だ。各スクリプトが必要とするものは、そのセクションで随時説明する。さしあたり、今精査すべきメインスクリプトに集中することにしよう。
5.3. ユーザ空間のセットアップ
まず最初に iptables パッケージのコンパイルの仕方を見ていこう。大切なのは、iptables のコンフィギュレーションとコンパイルの大部分が カーネル のコンフィギュレーションとコンパイルに密接に結びついているということを意識しておくことだ。いくつかのディストリビューションでは、 iptables パッケージがプレインストールされている。例えば Red Hat がそうだが、古い Red Hat のデフォルトでは iptables が無効になっている。有効にする方法は、その他のディストリビューションも含めて、このチャプターの後のほうで、つまびらかにする。
5.3.1. ユーザ空間アプリケーションのコンパイル
まずはともかく、 iptables パッケージを解凍する。ここでは、iptables 1.2.6a パッケージと 2.4 の無垢なカーネルを使用している。通常通り、 bzip2 -cd iptables-1.2.6a.tar.bz2 | tar -xvf - (あるいは tar -xjvf iptables-1.2.6a.tar.bz2 でも、前者とまったく同じ結果が得られが、バージョンの古い tar ではこれは動作しない) で解凍する。パッケージが iptables-1.2.6a という名前のディレクトリに正常に解凍されたはずだ。もっと詳しく知りたければ、iptables-1.2.6a/INSTALL ファイルを読めばいい。コンパイルと、プログラムの動かし方について、かなり役立つ情報が書かれている。
それが終わったら、ここで、どの追加モジュールや追加オプションをカーネルにコンフィギュア/インストールするかが選択できる。ここでは、カーネルへの組み込みが保留されている標準的なパッチのみインストールを検討する。もっと実験的なパッチもまだまだ存在するが、それらは、この後の手順を行ってからでないと手が出せない。
| これらのパッチのうちいくつかは極めて実験的であり、インストールするのは得策でない。それでも、この行程でインストールするものの中には、非常に興味深いマッチやターゲットもある。恐れずに、見るだけでも見てみようではないか。 |
実行するには、 iptables パッケージのルートディレクトリで、こういったことを行う:
make pending-patches KERNEL_DIR=/usr/src/linux/
変数 KERNEL_DIR には、カーネルソースのある場所を指定する。通常 /usr/src/linux/ となるが、異なっているかもしれない。おそらく、カーネルソースの所在はあなた自身が一番よく知っているのではなかろうか。
上記のコマンドは、何らかの形でカーネル内に入り込んでゆく一部のパッチをインストールするよう、お伺いを立てる。 Netfilter の開発陣がカーネルに加えようとしているパッチや追加機能はまだまだあるが、それらに辿り着くのはなかなか骨が折れる。そういったものをインストールするひとつの方法は、下記のようにすることだ:
make most-of-pom KERNEL_DIR=/usr/src/linux/
上記コマンドは、 Netfilter 界で patch-o-matic と呼び称せられるパーツをインストールするよう、お伺いを立てる。ただし、カーネルに不具合を起こす危惧のある突飛なパッチはスキップされる。「お伺いを立てる」 と書いている点に注目してほしい。なぜか。それが、まさにこれらのコマンドがすることだからだ。カーネルソースに何か変更を加える場合、実行の前に確認を求めてくるのだ。 patch-o-matic の全部をインストールするには、以下のコマンド:
make patch-o-matic KERNEL_DIR=/usr/src/linux/
実行する前に、各パッチのヘルプをよく読むこと。或るパッチは、他のパッチを壊してしまうこともあるし、 patch-o-matic やそれ以外のパッチとの組み合わせによってはカーネルを破壊してしまうこともある。
| カーネルにパッチを加えるつもりがなければ、上記の手順はまったく無視してもらっても構わない。必須ではないわけだ。それでも、patch-o-matic の中には、一見に値する本当に興味深いものもあるので、コマンドを実行して、そこに何が含まれているか見てみるのも悪くないだろう。 |
ここまでやれば、インストールの pach-o-matic 部分は完了。カーネルソースに追加した新しいパッチの有効となった、新しいカーネルをコンパイルする環境が整った。さっき追加したパッチは今のコンフィギュアオプションにはまだ記述されていないはずなので、カーネルをもういちど configure するのを忘れずに。ただし、できれば、ユーザ空間の iptables プログラムをコンパイルするまで、カーネルのコンパイルは待っていただきたい。
ユーザ空間のアプリケーション iptables を、ここでコンパイルする。 iptables をコンパイルするには、こういうシンプルなコマンドを発行する:
make KERNEL_DIR=/usr/src/linux/
これでユーザ空間アプリケーションはきちんとコンパイルされたはずだ。うまくいかない場合は、自分で解決するか、Netfilter メーリングリスト に投稿してみよう。 Netfilter メーリングリストなら、トラブルの解決を助けてもらえるチャンスがある。 iptables のインストール時に問題が起こることはあまりないので、うまく動かなかったとしてもパニックに陥らないでほしい。理論的に考察してどこに間違いがあるか探すか、誰か助言してくれる人を見つけよう。
すべてうまくいったら、もうバイナリをインストールする準備が整った。インストールを実行するには下記のコマンドを発行:
make install KERNEL_DIR=/usr/src/linux/
うまくいけば、今やすべてはプログラムとして動いてくれるはずだ。ユーザ空間アプリケーション iptables に加えた変更を利用するには、まだやっていないならここでカーネルとカーネルモジュールを再コンパイルしなくてはいけない。ユーザ空間アプリケーションをソースからインストールするためのより詳しい情報が欲しければ、ソースに含まれる INSTALL ファイルを見てみよう。インストールに関する情報が充実している。
5.3.2. Red Hat 7.1 でのインストール
Red Hat 7.1 には、Netfilter と iptables を組み込んだ 2.4 カーネルがプレインストールされている。 iptables を動かせるだけの基本的なユーザ空間プログラムと設定ファイルも含まれている。しかし Red Hat 陣は、下位互換の ipchains モジュールを使用することによって、それら一切を無効化してしまっているのだ。うっとうしい話だ。おかげで、なぜ iptables が動かないのか、という質問がそこらじゅうのメーリングリストで飛び交っている。そこで、 ipchains モジュールを殺して iptables をインストールする方法を、ざっとさらっておくことにする。
| Red Hat 7.1 にデフォルトインストールされているユーザ空間アプリケーションは、悲しくなるほどバージョンが古い。 iptables を本気でいじりたいのなら、新しいバージョンのアプリケーションをコンパイルして、カスタムカーネルの再構築・インストールを行うことをお勧めする。 |
まずはともかく、 ipchains モジュールが以後起動しないよう無効にしておかなくてはならない。それには /etc/rc.d/ ディレクトリ下のいくつかのファイル名を変える必要がある。以下のコマンドで行える:
chkconfig --level 0123456 ipchains off
これによって、/etc/rc.d/init.d/ipchains スクリプトを指す全てのソフトリンクの名前が K92ipchains に変わる。ファイル名の最初の文字は、デフォルトでは S で、そのスクリプトを start せよ、と init スクリプトに伝える。それを K に変えることにより、反対に、サービスを kill せよ、または、起動していない場合でも起動しなくていい、と伝えられる。これで、 ipchains サービスが将来再び起動することはなくなった。
しかし、現在既に作動中のサービスを止めるには、コマンドがもうひとつ必要。作動中のサービスに働きかける service コマンドだ。 ipchains サービスを止めるには下記のコマンドを発行する:
service ipchains stop
これでやっと iptables サービスが開始できる。まず、どの runレベル で起動させるか決めなくてはならない。通常は runレベル 2、3、5 だ。これらの runレベルは以下の目的に使われる:
2. NFS なしのマルチユーザ。ネットワークなしの場合は 3 と同じ。
3. 完全なマルチユーザモード。つまり、通常、ブート後に入るのがこの runレベル。
5. X11。自動的に Xwindow でブートする場合に使われる。
以上の runレベルで iptables を有効にするには、下記のコマンド:
chkconfig --level 235 iptables on
上記コマンドは、runレベル 2、3、5 で iptables サービスを起動させることになる。もし他の runレベルで iptables サービスを起動したいなら、その runレベルを指定して同様のコマンドを発行する。しかし、これ以外の runレベルは使ってはいけないので、そうする必要もない。レベル 1 はシングルユーザモードであり、マシンがおかしくなった場合などに使うレベル。レベル 4 は使われていないはず。[訳者による修正: レベル 0 はコンピュータをシャットダウンする時で、レベル 6 はコンピュータを再起動する際にだけ使われる]。
iptablesサービスを活動状態にするには、下のコマンドを走らせればいい:
service iptables start
iptables スクリプトには、ルールはまだひとつも書かれていない。 Red Hat 7.1 のコンピュータでルールを追加するには、ふたつの方法がある。まず、 /etc/rc.d/init.d/iptables スクリプトを直接編集する方法。これには望まざる副作用があって、 RPM で iptables パッケージをアップデートすると、ルールが全部消されてしまう。もうひとつは、ルールセットをロードしてから iptables-save コマンドで保存し、それを rcスクリプトで自動的にロードさせる方法だ。
それではまず最初に、 iptables の init.d スクリプトにカット & ペーストして iptables を設定する方法を解説する。コンピュータがサービスを起動したときに読み込まれるようルールを追加するには、start) セクションか start() 関数にルールを記述する。 start) セクションにルールを記述する場合には、start) セクション内の start() 関数を無効化しておくことを忘れずに。また、コンピュータがシャットダウンする時、あるいは iptables を必要としない他の runレベルに移行する際に何をすべきかを stop) セクションに書いておくのも忘れてはいけない。さらにまた、 restart) セクションと condrestart) セクションの点検も忘れないように。心しておくべきは、こうした変更は、例えば Red Hat Network でパッケージの自動アップデートが行われたりすると、全部帳消しになってしまうということ。 iptables を RPM でアップデートした場合も同じだ。
2 番目の設定方法は、以下の手順を踏む: まず初めに、あなたの望む内容で、シェルスクリプトにルールセットを書くか、 iptables で直接ルールセットを作る。少しはテストもしなくてはいけない。バグがなく、問題なく動作する設定に行き着いたら、 iptables-save コマンドを使う。 iptables-save > /etc/sysconfig/iptables のように普通に使うも良し。このコマンドは /etc/sysconfig/iptables ファイルにルールセットを保存する。それ以後は、rc.d の iptables スクリプトがこれを自動的に読み取って、ルールセットをリストアしてくれる。もうひとつの方法は、service iptables save。これも /etc/sysconfig/iptables にスクリプトを自動的に保存してくれる。次回コンピュータをリブートした際には、 rc.d の iptables スクリプトが、 iptables-restore コマンドを使用して保存ファイル /etc/sysconfig/iptables からルールセットをリストアする。これらふたつのやりかたをごちゃ混ぜにしてはいけない。かち合って、ファイヤーウォール設定を台無しにしてしまうだろう。
ここまでの行程が終われば、インストールされている ipchains と iptables をアンインストールできる。なぜ iptables をアンインストールするかといえば、プレインストールの古い iptables と、新しいユーザ空間 iptables アプリケーションを混在させたくないからだ。この行程が必要なのは、 iptables をソースパッケージからインストールする場合だけだ。新旧のパッケージがごちゃ混ぜにならないケースも珍しくはない。というのは、 RPM ベースのインストールではファイルが通常とは違う場所にインストールされるため、新たに iptables をインストールしても上書きされないからだ。アンインストールを実行するには下記:
rpm -e iptables
もう使うことのない ipchains をそこらに転がしておく道理はないだろう。古い iptables でやったのと同様にして削除できる:
rpm -e ipchains
既にソースインストールの手順に従って iptables はアップデートしてあるだろうから、これにて作業は完了。古いバイナリ、古いライブラリやインクルードファイルは、きれいさっぱりなくなっているはずだ。
5.4. まとめ
このチャプターでは、iptables および Netfilter の入手方法と、主要なプラットフォームでのインストール方法について述べた。最近の Linux ディストリビューションのほとんどでは iptables が標準でインストールされる。ただし一部のディストリビューションではカスタムカーネルと iptables バイナリのコンパイルを行って最新のものにアップデートしてやらなければならない場合がある。当チャプターはそういったことをする上での一助となったのではなかろうか。
次のチャプターでは、テーブルとチェーンをパケットがどのように巡っていくかや、その際の順番などについて述べる。これは、ルールセットを自分で構築して運用するには是非とも理解しておかなければならない非常に重要な事柄だ。また、それぞれのテーブルについてもかなり掘り下げて解説する。各テーブルにはそれぞれ特有の役割があるからだ。
Chapter 6. テーブルとチェーンの道のり
このチャプターでは、パケットが各種チェーンをどういう順番で通過するかを議論する。また、各種テーブルをどのように通過していくかについても考えていく。これがどれほど役に立つかは、あとで自分のルールを書く時に身に浸みるだろう。ここではまた、カーネルにも依存するその他の構成要素がどこで関わってくるのかにも光を当てる。つまり、各段階でのルーティング判断などといった事柄だ。これは、パケットに応じてルーティングパターンや適用ルールを切り替えるような iptables ルールを書こうとする場合に、必要不可欠な知識となる。つまり、パケットがどういう時にどんな風にルーティングされるかといった話で、これが関わってくる代表的なものが DNAT と SNAT だ。もちろん TOS ビットのことも忘れるわけにはいかない。
6.1. 全般
パケットがファイヤーウォールに入ると、まずハードウェアに行き当たり、次にカーネルの持つしかるべきデバイスドライバ に渡される。それから、目的の (ローカル上の) アプリケーションに送られるとか、別のホストに送られるなど、某かの沙汰を受けるまでに、パケットはカーネル内の一連の行程を通過していく。
まず、我々のローカルホスト に宛てたパケットについて見てみよう。受信すべきアプリケーションに辿り着くまでに、パケットは以下のような道のりを旅する。
Table 6-1. ローカルホスト (我々のマシン) を宛先とするパケット
| 行程 | テーブル | チェーン | コメント |
|---|---|---|---|
| 1 | 通信ケーブル上。 例) インターネット | ||
| 2 | インターフェースに入る。 例) eth0 | ||
| 3 | raw | PREROUTING | このチェーンは、コネクション追跡の発動する手前でパケットを処理する時に使用する。例えば、特定のコネクションにコネクション追跡が働かないようにするといった使い方がある。 |
| 4 | ステート機構 チャプターで述べるコネクション追跡が機能するのがここ。 | ||
| 5 | mangle | PREROUTING | このチェーンは通常、パケットの改変 (mangle) に使う。例えば TOS の変更などだ。 |
| 6 | nat | PREROUTING | 主に DNAT に使用するチェーン。このチェーンはバイパスされる場合もあるので、ここでのフィルタリング処理は御法度。 |
| 7 | ルーティング判断。例) ローカルホスト宛か、フォワードされるならどこへ | ||
| 8 | mangle | INPUT | この時点で、mangle の INPUT チェーンにぶつかる。ルーティング後、且つ、マシン上の実際のプロセスに送られる前の、パケット改変に使用する。 |
| 9 | filter | INPUT | ローカルホスト宛のパケットに対してフィルタリングを行うのは、すべてここ。ローカルホスト宛の進入パケットは、インターフェースや入ってきた方向に関わらず、必ずこのチェーンを通る。 |
| 10 | ローカルプロセス/アプリケーション。 例) サーバ/クライアントプログラム |
今回は FORWARD チェーンでなく INPUT チェーンを通ってくるという点を憶えておいてていただきたい。極めて論理的だ。おそらく最初は、論理的に見えることといったらテーブルとチェーンを巡ってくることくらいしかないかもしれないが、しばらく考察していけば、じきにはっきりしてくるはずだ。
では次に、我々のローカルホスト から出ていくパケットとその通り道を見てみよう。
Table 6-2. ローカルホスト (我々のマシン) を送信元とするパケッ ト
| 行程 | テーブル | チェーン | コメント |
|---|---|---|---|
| 1 | ローカルプロセス/アプリケーション。 例) サーバ/クライアントプログラム | ||
| 2 | ルーティング判断。どういった送信元アドレスを使用するか、出口はどのインターフェースかなど必要な情報の収集。 | ||
| 3 | raw | OUTPUT | ローカルで発生したパケットにコネクション追跡が働く前に処理を施すならここ。例えば、特定のコネクションに追跡が働かないようマークを付けるといったことができる。 |
| 4 | ローカルで発生したパケットにコネクション追跡が働くところ (ステートの変化など)。それについては ステート機構 チャプターで詳しく述べる。 | ||
| 5 | mangle | OUTPUT | パケットを改変するところ。副作用を避けるため、フィルタリング処理はすべきでない。 |
| 6 | nat | OUTPUT | ファイヤーウォールから出ていくパケットに NAT をかけるのはここ。 |
| 7 | ルーティング判断。ここでルーティング判断が必要なのは、パケットに求められるルーティング方針が、前の mangle と nat によって変更された可能性があるからだ。 | ||
| 8 | filter | OUTPUT | ローカルホストから出ていくパケットをフィルタリングするのがここ。 |
| 9 | mangle | POSTROUTING | mangle テーブルの POSTROUTING チェーンは、パケットがホストを離れる前、且つ、ルーティング判断がなされた後で、パケット改変をしたい場合に使う。ファイヤーウォールを通過中のパケットも、ファイヤーウォールで作られたパケットも、ともにこのチェーンにぶつかる。 |
| 10 | nat | POSTROUTING | 前に説明した SNAT が行われるのはここ。副作用を避けるため、ここではフィルタリングを行うべきでない。デフォルトポリシーを DROP にしても、ある種のパケットはここを擦り抜けてしまう。 |
| 11 | いずれかのインターフェースから出ていく。例) eth0 | ||
| 12 | 通信ケーブル上。 例) インターネット |
この例では、パケットは他ネットワーク上の他ホストに宛てられたものだとする。パケットは今までとは異なった下記のような道のりを巡る。
Table 6-3. フォワードパケット
| 行程 | テーブル | チェーン | コメント |
|---|---|---|---|
| 1 | 通信ケーブル上。 例) インターネット | ||
| 2 | インターフェースに入る。 例) eth0 | ||
| 3 | raw | PREROUTING | ここで、特定のコネクションがコネクション追跡処理されないようにしておくことができる。 |
| 4 | ローカル以外で発生したコネクションにコネクション追跡が作用するのがここ。 ステート機構 チャプターで詳しく述べる。 | ||
| 5 | mangle | PREROUTING | このチェーンは通常、パケットの改変に使われる。例えば TOS の変更などだ。 |
| 6 | nat | PREROUTING | 主として DNAT に使うチェーン。SNAT は後で行う。パイパスされる場合もあるのでフィルタリングは避けるべき。 |
| 7 | ルーティング判断。例) ローカルホスト宛か、フォワードならどこへ | ||
| 8 | mangle | FORWARD | 次にパケットは mangle テーブルの FORWARD チェーンに送り込まれる。極めて特殊な用途でのパケット改変に使用する。ここでの改変は、最初のルーティング判断の後であり、且つ、パケットが送出される直前の最終ルーティング判断の前となる。 |
| 9 | filter | FORWARD | パケットは FORWARD チェーンに送られる。ここを通るのはフォワードされたパケットだけで、そのフィルタリングはここで行う。フォワードされたパケットは (進行方向にかかわらず) 必ずここを通るので、ルールセットを書く際には、ここを検討しよう。 |
| 10 | mangle | POSTROUTING | すべてのルーティング判断を経た後だが、まだパケットがマシン上にあるうちに施す、特殊なタイプのパケット改変処理をしたい場合にこのチェーンを使う。 |
| 11 | nat | POSTROUTING | SNAT を行うならここをおいて他にない。ある種のパケットはカスりもせずに擦り抜けてしまうので、フィルタリングに使ってはならない。ここはマスカレード を行う行程でもある。 |
| 12 | 出口インターフェースから出る。 例) eth1 | ||
| 13 | 再び通信ケーブル上へ。 例) LAN |
ご覧の通り、かなりたくさんの行程を通って行く。パケットを止めるのは iptables のどのチェーンでもできるし、壊れたパケットはさらに他のどこでも止めることができる。しかし、何より注目すべきは、iptables 全体を貫くこの流れだ。インターフェースなどの違いによって使い分けるような特定のチェーンやテーブルなど一切ないという点に注目していいただきたい。このファイヤーウォール/ルータを通ってフォワードされるパケットは、もれなく FORWARD を通るのだ。
 | フィルタリングを行うのに、前のシナリオに出てきた INPUT チェーンを使ってはいけない! INPUT は、他ならぬローカルホストを行き先とするパケット専用にできているのだ。 |
シナリオが異なればパケットの通ってゆくチェーンも三者三様であることが分かっただろう。それを上手にマップにまとめると、こんな風になる:
図の意味を明確にするため、こんな場合を考えてみよう。ローカルマシン以外に宛てたパケットが、最初のルーティング判断に入ってきたとすると、そのパケットは FORWARD チェーンを通るよう誘導される。一方、ローカルホストが聞き耳を立てている IP アドレスに宛てられたパケットは、 INPUT チェーンを通してローカルマシンに送られる。
もうひとつ注目すべきは、パケットが他でもないローカルマシンに宛てたものだとしても、 PREROUTING チェーンで NAT することにより、宛先を変更できるという事実だ。この変更は最初のルーティング判断より前に行われるため、パケットはそれ以降、変更された宛先を反映した形で扱われる。この方法により、ルーティング判断の前にパケットの誘導方針が変更できるのだ。パケットは、図中のどれかひとつの経路を必ず通ることにも注目してほしい。もし、パケットがやってきたのと同じネットワークへ DNAT してやれば、最終的にネットワークをおさらばするまで、パケットはチェーンの残り部分をさらに旅し続ける。
| もっと詳しく知りたくなったなら、rc.test-iptables.txt を使うといい。このスクリプトを使えば、テーブルとチェーンをパケットがどのように通っていくか試すための実験に必要なルールが出来上がるはずだ。 |
6.2. mangleテーブル
前述したように、このテーブルは主にパケットの改変に使われる。つまり、このテーブル内では、 TOS (Type Of Service) の変更をはじめ、改変用ターゲットが大手を振って使用できる。
| くれぐれも、mangle テーブルをフィルタリングに使わないように。DNAT、SNAT、マスカレード (MASQUERADE) もこのテーブルでは機能しない。 |
下記のターゲットは mangle テーブルでのみ有効なターゲットだ。 mangle テーブル以外で使用することはできない。
TOS
TTL
MARK
SECMARK
CONNSECMARK
TOS ターゲットは、パケットの Type Of Service フィールドを設定または変更 (または両方) するために使う。この仕組みは、パケットをどういった具合にルーティングするかといったポリシーを、ネットワークに与えるのに利用できる。気を付けなくてはならないのは、 TOS は、インターネット上では扱いが不完全かあるいは全く考慮されておらず、ルータの多くは、 TOS フィールドの値を完全に無視したり、時には見当違いの振る舞いをしたりするということだ。つまり、設定しておいた TOS を (iproute2 を使って) ルーティング決定に利用するつもりなら話は別だが、インターネットへと出ていくパケットに TOS を設定するのは御法度だ。
TTL ターゲットは、パケットの TTL (Time To Live) フィールドを変更するのに使う。 TTL を特定の値にセットする場合などだ。活用法のひとつは、詮索好きなインターネットサービスプロバイダーにこちらの情報をさらけ出したくない場合だ。プロバイダの中には、ひとつの接続に対して複数のコンピュータをつないでいるユーザを許さないところがあり、その中にはさらに、発生する TTL の値が変化するようなホストを嗅ぎ回って、複数のコンピュータを接続している証拠のひとつとして取り沙汰するプロバイダも世に知られている。
MARK ターゲットは、パケットに特別なマークを付けるのに使う。マークの有無や、どんなマークが付いているかを iproute2 プログラムを使って調べることによって、パケットのルーティングを切り替えることができる。このマークは帯域制限や Class Based Queuing にも利用できる。
SECMARK ターゲットは、 SELinux をはじめ、セキュリティコンテキストを扱えるセキュリティ機構で使えるセキュリティコンテキストマークを、特定のパケットに付けることができる。そうしておけば、どのパケットにどのサブシステムがタッチできるかといったきめ細かなセキュリティが掛けられる。 SECMARK をコネクション単位で付けるには CONNSECMARK ターゲットが用意されている。
CONNSECMARK を使用すると、単一のパケットのセキュリティコンテキストをコネクション全体にコピーしたり、逆にコネクションからパケットへコピーしたりできる。そうしたことを行えば、 SELinux などのセキュリティ機構を利用してコネクションレベルのきめ細かなセキュリティ対策が施行できる。
6.3. natテーブル
このテーブルはパケットの NAT (Network Address Translation) にしか利用できない。つまり、パケットの送信元フィールドまたは宛先フィールドを変更する目的にだけ使用するテーブルだ。前にも述べたことだが、このテーブルに行き当たるのは、ストリームの最初のパケットだけ。後続のパケットは全て、先頭パケットの執った行動に倣う。こうしたことを行う具体的なターゲットは:
DNAT
SNAT
MASQUERADE
REDIRECT
DNAT ターゲットは主に、あなたがパブリック IP を持っている場合に、ファイヤーウォールへのアクセスをその他の (例えば DMZ 上の) ホストへ振り向ける際に使用する。つまり、パケットの宛先アドレスを変更して、特定のホストへルーティングするわけだ。
SNAT は、主としてパケットの送信元アドレスの変更に用いる。通常、こちらのローカルネットワークや DMZ などは外部にさらけ出さないものだ。格好の例が、外部向け IPアドレスの分かっているファイヤーウォールを置いていて、そのファイヤーフォールの持っている外部 IPアドレスを、ローカルネットワーク内のホストに送信元アドレスとして使わせる必要がある場合だ。このターゲットを利用すれば、ファイヤーウォールがパケットの SNAT と逆SNAT 処理を自動的にやってくれるので、LAN からインターネットへの接続が可能となる。あなたのネットワークが例えば 192.168.0.0/netmask というアドレスだった場合、 IANA の規定ではこのアドレス (他にもあるが) はプライベートアドレスであり、閉じた LAN 内でのみ有効なものとされているため、インターネットからは決して返事をしてもらえないのだ。
MASQUERADE ターゲットは SNAT とまったく同じような使い方をする。ただし、 SNAT と比べると処理にかかる負荷は少々大きい。 SNAT ターゲットがひとつの固定した IPアドレスを使えばいいのに対して、 MASQUERADE ターゲットは、パケットが来る度に、使用すべき IPアドレスを調べているからだ。 MASQUERADE ならば、 ISP が 動的に DHCP IPアドレスを割り当ててくる PPP や PPPoE、 SLIP のインターネット接続下でも、きちんと動作してくれる。
6.4. Rawテーブル
raw テーブルの用途はほぼひとつだけ。コネクション追跡で扱われないよう特定のパケットにマークを付けることだ。これはパケットに NOTRACK ターゲットを適用することによって行える。パケットが NOTRACK ターゲットにヒットすると、conntrack は以後、そのコネクションを追跡しなくなる。こういうことは、新たなテーブルなしには不可能なことだった。というのは、 conntrack がパケットに作用したり conntrack テーブルにコネクションが記録されたり既にトラッキング済みのコネクションに照会されたりする以前にパケットが通るテーブルは、ひとつもなかったからだ。これについての詳しいことは、ステート機構 チャプターに書いてある。
このテーブルには PREROUTING と OUTPUT チェーンしかない。コネクション追跡に触れる前にパケットを処理できるのはこれらだけなので、それ以外のチェーンは必要ないのだ。
| このテーブルが機能するには iptable_raw モジュールがロードされていなければならない。ただし、このモジュールが利用可能な環境であれば、iptables が -t raw キーワードとともにコールされるとこのモジュールは自動的にロードされる。 |
| raw テーブルは比較的最近になって iptables およびカーネルに取り入れられたものだ。 2.4 カーネルや初期の 2.6 カーネルでは、パッチを当てないと機能しないだろう。 |
6.5. filterテーブル
filter テーブルは、主としてパケットのフィルタリングに使用される。お好み次第でパケットを条件選択し、ふるいに掛けることができる。このテーブルこそが、我々がパケットを操作する場所であり、パケットの中身を調べ、その内容に基づいて DROP したり ACCEPT したりといった処置を施す場所だ。もちろん事前処理的なフィルタリングもやらなくはないが、このテーブルはフィルタリングを行うためにこそしつらえられた場所なのだ。ここでは、ほぼすべてのターゲットが使用できる。 filter テーブルについては後でたっぷりとスペースを割くが、とにかく知っておいていただきたいのは、中核的なフィルタリングを施すのは、ここが舞台だということだ。
6.6. ユーザ定義チェーン
パケットが例えば filter テーブルの INPUT チェーンにいる時に、そこから同じテーブル内の別のチェーンへ飛ばす jump ルールを指定することができる。ジャンプ先のチェーンはユーザ定義チェーンでなければならず、 INPUT や FORWARD のようなビルトインチェーンでは駄目だ。ルールをチェーンの中で指し示すポインタだと考えると、このポインタは通常、ルールから次のルールへ、上から下へと、然るべきターゲットに行き当たるかメインチェーン (例えば FORWARD や INPUT など) の終点に行き着くまで移動していく。終点に到達した場合には、当のビルトインチェーンのデフォルトポリシーが適用される。
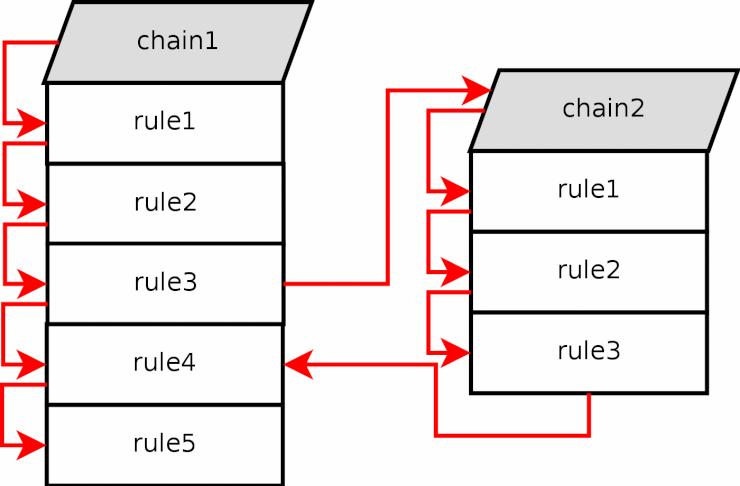
マッチしたルールがジャンプ定義によって他のユーザ定義チェーンを指していた場合には、ポインタは指定されたチェーンに飛び移り、そのチェーンを上から下へと進行していく。例として、上図のルール 3 からチェーン 2 へのジャンプするところを見ていただきたい。パケットがルール 3 にマッチしたとして、そこで指定されていたジャンプ/ターゲットが、パケットをチェーン 2 へ送ってさらなる審査を行えという指示だったとしよう。
| ユーザ定義チェーンには、チェーンの末尾に達した時に適用するデフォルトポリシーを指定することはできない。それが可能なのはビルトインチェーンだけだ。ただし、そのユーザ定義チェーン内のどのルールにもマッチしなかったパケットを捕まえるルールを末尾に書いておき、それをデフォルトポリシーのように作用させれば、この制限に対処することはできる。ユーザ定義チェーンでいずれのルールもマッチしなかった場合、規定の動作では、元のチェーンへ舞い戻ることになっている。上の図で言えば、ルールの執行はチェーン 2 から、チェーン 1 のルール 4 へ、つまり、チェーン 2 の執行のきっかけとなったルールのすぐ下のルールへと戻ることになる。 |
ユーザ定義チェーン内では、順々にひとつずつルールが審査されていき、それが終わるのは、いずれかのルールにマッチした時か (この場合、ターゲットによっては処理がそこで終了する場合とさらに続く場合がある)、ユーザ定義チェーンの終端に達した時だ。ユーザ定義チェーンの終端に達した場合には、パケットは、このジャンプをトリガーしたチェーンへ戻される。トリガーするチェーンは、別のユーザ定義チェーンでもいいしビルトインチェーンでもいい。
6.7. まとめ
このチャプターでは幾種類ものチェーンやテーブルについて述べ、標準のビルトインチェーンとユーザ定義チェーンも含めてそれらがどのように辿られていくかを説明した。ここは是非とも理解しておきたい内容だ。分かってしまえば簡単かもしれないが、理解が不十分だと、致命的なミスを犯すのもまた簡単だ。
次のチャプターでは、netfilter のステート機構について深く掘り下げ、コネクション追跡機構の中でステートがどのようにして生成され、それがパケットにどう設定されるかを見ていく。このチャプターにも引けを取らない重要なチャプターだといえる。
Chapter 7. ステート機構
このチャプターでは、ステート機構 (state machine) を取り上げ、その詳細を説明していく。このチャプターを読み終われば、ステート機構の働き全般について、一通りの理解ができているはずだ。また、ここではステート機構の内部でステートがどのように処理されていくかについても、多数の例を挙げながら精査していく。実際の動きを見ることで、物事がくっきりと見えてくるだろう。
7.1. はじめに
ステート機構は iptables の中でも特別な部分であり、本当はステート機構などという名前でさえない。本当はコネクション追跡 (connection tracking) メカニズムのひとつだ。しかし、一般には前者の名で知られている。このチャプターを通して、僕はこれらふたつの名前を同義語のように使っていくが、おそらくひどい混乱を引き起こすことはないだろう。コネクション追跡は、特定の接続における状態 (state) を Netfilter のフレームワークに伝えるためのものだ。こうした機能を備えたファイヤーウォールは、ステートフル (stateful) ファイヤーウォールと呼ばれる。概して、ステートフルファイヤーウォールでは、よりタイトなルールセットが書けるので、ステートフルでないファイヤーウォールよりも高いセキュリティが得られる。
iptables 内部では、パケットは、追跡済みの接続 (tracked connections) との関連性に応じて 4 つの"ステート "なるものに類別される。 NEW, ESTABLISHED, RELATED, INVALID の 4 つだ。各ステートについては追って詳しく述べるが、新たなセッションの開始を誰に、あるいは何に対して許可するかが、 --state マッチを使えばいとも簡単に制御できる。
コネクション追跡は、カーネル内部の conntrack と呼ばれる特別なフレームワークによって行われる。この conntrack はモジュールとしてロードすることもできるし、カーネル自体に組み込んでおくこともできる。たいていは、デフォルトの conntrack エンジン単独でできるよりも、もっと特殊なコネクション追跡を必要とすることのほうが多い。そのために、 TCP、 UDP、 ICMP プロトコルに対して作用するものなど、より特殊なコンポーネントも用意されている。これらのモジュールは、パケットから特有の情報を読み取り、データストリームを追跡の目から逃さないようにする。 conntrack が収集した情報は、ストリームが現在どのステートにあるのかを conntrack が判断するために用いられる。例えば UDP ストリームであれば、あくまでも一般論だが、宛先IPアドレス, 送信元IPアドレス, 宛先ポート, 送信元ポートによってストリームを特定することができる。
先代のカーネルでは、デフラグメンテーション のオン/オフを切り替えることも可能だった。しかし、 iptables と Netfilter、殊にコネクション追跡が提供されるようになってからは、このオプションは無用となった。コネクション追跡はパケットのデフラグメンテーションなしには正常に機能しないため、デフラグメンテーションは conntrack に組み込まれて自動的に行われるようになったからだ。もはや、デフラグメンテーションをオフにするには、コネクション追跡を切るしかない。コネクション追跡を有効にすれば、デフラグメンテーションも常に行われる。
パケットがローカルで発生したものである場合を除き (この場合は OUTPUT チェーンで行われる)、コネクション追跡はすべて PREROUTING チェーンで行われる。つまり、ステートの再検出などすべての処理は PREROUTING チェーン内で行われるのだ。ローカルからストリームの開始となるパケットを送出した場合、 OUTPUT チェーンにおいて、このストリームは NEW ステートだと判定が下される。このパケットに対して返答が返ってくれば、 PREROUTING チェーンでステートが ESTABLISHED に変わる、といった具合だ。最初のパケットがローカルを始祖とするものでなかった場合には、PREROUTING チェーンで下される判断は、無論 NEW ステートとなる。
7.2. conntrackエントリ
それでは、conntrack エントリの様子と /proc/net/ip_conntrack の読み方を簡単に見てみよう。 conntrack エントリには、あなたのマシンの現在の conntrack データベースエントリがリストされている。 ip_conntrack モジュールがロードされていれば、 /proc/net/ip_conntrack を cat すると以下のような感じになるだろう:
tcp 6 117 SYN_SENT src=192.168.1.6 dst=192.168.1.9 sport=32775 \
dport=22 [UNREPLIED] src=192.168.1.9 dst=192.168.1.6 sport=22 \
dport=32775 [ASSURED] use=2
この例は、特定のコネクションのステートを判断するために conntrack モジュールが管理する情報をつぶさに示している。まず最初に、プロトコルが読み取れる。この場合 tcp だ。次に、プロトコルの 10 進表記。その次には、この conntrack エントリがどれだけの時間保持されるかが書いてある。現在の値は 117 秒で、新たなトラフィックを検出するまでの間、この値は一定間隔で減ってゆく。その後、しかるべき時に達すると、コネクションの置かれたステートに応じたデフォルト値へとリセットされる。次のフィールドには、現時点で置かれているステートそのものが書いてある。今観察している上記パケットのケースでは、SYN_SENT と読み取れる。内部で使われるコネクションの値は、我々が iptables で使う表層用の記述とは少々異なっている。 SYN_SENT という値は、ここで見ているコネクションでは、今のところ片方向の TCP SYN パケットだけが検出されていることを物語っている。続いては、送信元IPアドレス、宛先IPアドレス、送信元ポート、宛先ポートが並ぶ。次に来るのが、このコネクションに対する返答はまだ受け取っていないということを示す、特別なキーワードだ。そして最後に、返答パケットに期待される事柄が記載されている。上記で見られる情報は、送信元IPアドレス、宛先IPアドレス (ただし、送り返されるパケットを期待しているわけなので、アドレスは入れ替わっている) を具体的に示している。そして送信元ポートと宛先ポートに関しても同様。多少なりとも我々の興味を惹く、こうした値だ。
コネクション追跡エントリの初期値は、数セットの異なったバリエーションがあり、その値は linux/include/netfilter-ipv4/ip_conntrack*.h ファイルの conntrack ヘッダで定義されている。値は、どの IP サブプロトコルを使用するかによって異なる。 TCP, UDP, ICMP プロトコルの場合には linux/include/netfilter-ipv4/ip_conntrack.h で定義された特定のデフォルト値を採る。それぞれを精査するのは、そのプロトコルを解説する下りまでとっておくことにしよう。 conntrack の内部機構以外でそれらを使うことはほとんどないので、これ以上このチャプターで触れるのは止めておく。コネクションが破棄されるまでの時間の値もまた、ステートの推移によって逐次変化していく。
| 最近、 iptables patch-o-matic に、tcp-window-tracking と呼ばれる新しいパッチが上がった。このパッチが面白いのは、特に、前述のタイムアウト値を特定の sysctl 変数で書き換えることができるという点だ。つまり、システムの稼働中でも、随時書き換えが可能になるのだ。タイムアウト値を変えるために、いちいちカーネルをリコンパイルする必要がなくなる。 これらの値の変更は、 /proc/sys/net/ipv4/netfilter ディレクトリにある特別なシステムコールによって行える。 /proc/sys/net/ipv4/netfilter/ip_ct_* は必見と言っていいだろう。 |
コネクションが双方向のトラフィックを検出すると、conntrack エントリから [UNREPLIED] フラグが消え、リセットされる。上記コードの末尾付近の [ASSURED] フラグが、コネクションはまだ双方向のトラフィックを観察していないということを示していたエントリに取って代わるのだ。 [ASSURED] フラグは、このコネクションが確立済みであることを表し、コネクション追跡の数が制限数に達したとしても消去されない。このようにして[ASSURED] にマークされたコネクションは、未確立の ([ASSURED] とマークされていない) コネクションとは異なり、抹消されることがなくなる。コネクション追跡テーブルが接続をいくつ保持できるかは、或る変数に依存しており、それは現行カーネルでは ip-sysctl によって設定できる。デフォルト値はマシンの実装メモリの量と深く関係しており、RAM が 128MB の場合は 8192 エントリが上限、256MB では 16376 エントリとなる。値の確認と設定は /proc/sys/net/ipv4/ip_conntrack_max で行える。
それと同じことをやるには他にも方法があり、こちらのほうがより効率的。 ip_conntrack モジュールのロードの際に hashsize オプションを与える方法だ。常態では、ip_conntrack_max の値はハッシュサイズの 8 倍となる。つまり、 hashsize を 4096 にすれば ip_conntrack_max は 32768 となる。実際に行うとすればどのようになるかを示そう:
work3:/home/blueflux# modprobe ip_conntrack hashsize=4096
work3:/home/blueflux# cat /proc/sys/net/ipv4/ip_conntrack_max
32768
work3:/home/blueflux#
7.3. ユーザ空間でのステート
これまで見てきた通り、カーネルの内部では、パケットはそのプロトコルに応じていくつかの異なったステートを採り得る。しかし、カーネルの外に用意されているのは、前述した 4 つのステートだけだ。ステートは、主に state マッチと組み合わせて、コネクション追跡上での現在のステートを調べることを通じて利用する。利用可能なステートは、NEW, ESTABLISHED, RELATED, INVALID, UNTRACKED だ。下の表に、各ステートの採り得る状態を簡潔にまとめた。
Table 7-1. ユーザ空間でのステート
| State | 説明 |
|---|---|
| NEW | NEW ステートは、それが初めて観測したパケットであることを表す。つまり、或る特定のコネクションの中で conntrack モジュールが初めて検出したパケットがこれに合致する。例えば、SYN パケットが検出されたとして、それがあるコネクションで最初のパケットならマッチする。ただし、必ずしも SYN パケットであるとは限らず、 SYN でなくても NEW と判定される。状況によってはこの点が何らかの問題につながる場合もあるが、よそのファイヤーウォールからの接続を見失ってしまったり、コネクションはタイムアウトしているが接続自体はクローズされていないなどといった局面で、非常に有用な面が多い。 |
| ESTABLISHED | ESTABLISHED ステートの場合、既に双方向のトラフィックが検出されている。それからさらにパケットがやりとりされても、マッチの判定は変わらない。 ESTABLISHED なコネクションは比較的理解が楽だ。 ESTABLISHED ステートに判定されるための必要条件は単純。一方のホストがパケットを送信し、別のホストから返答が来れば、即ち ESTABLISHED だ。 NEW ステートにある接続は、直接あるいはファイヤーウォール越しに返答パケットを受け取った途端、 ESTABLISHED ステートになる。こちらから送ったパケットが送信先にお返しの ICMP メッセージを発生させた場合には、 ICMP 応答も ESTABLISHED と判断される。 |
| RELATED | RELATED ステートは他よりかなりややこしい。あるコネクションが、既に ESTABLISHED な別のコネクションに関係している場合、それが RELATED だ。つまり、接続が RELATED になるためには、前提条件として、既に ESTABLISHED として判定済みの、別の接続が必要なのだ。そこで、 ESTABLISHED コネクションが、自分の主接続の他にもコネクションを発生させる。 conntrack モジュールに RELATED と認められれば、この新たに発生した接続が RELATED だ。 RELATED と判定される幾つかの典型を挙げよう。 FTP-data コネクションは FTP コントロール ポートに RELATED している。 IRC で開かれる DCC コネクションもそうだ。このステートは、ファイヤーウォール越しの ICMP 回答や、 FTP 転送、 DCC を成立させるのに利用される。この仕組みを利用すれば、 ICMP エラーメッセージや、 FTP や DCC によるデータ輸送を、ファイヤーウォール越しでもきちんと機能させることができる。気を付けなければならないのは、こうしたメカニズムに依存するほとんどの TCP プロトコルと一部の UDP プロトコルは、非常に複雑で、 TCP または UDP データセグメントのペイロードを使って接続情報をやりとりしているため、正しく解釈するには特別なヘルパーモジュールを必要とするという点だ。 |
| INVALID | INVALID ステートは、パケットが判定できないか、他のどのステートにも当てはまらない場合だ。こうなる要因は幾つか考えられる。例えば、システムがメモリーを使い果たした場合や、どの既知の接続にも関連しない ICMP エラーメッセージを受け取った場合などだ。おしなべて、このステートに当てはまるものは全部 DROP してしまうのが妥当だ。 |
| UNTRACKED | これは UNTRACKED ステート。簡潔に言えば、 raw テーブルで NOTRACK ターゲットを使ってマークされたパケットが、ステート機構上に UNTRACKED なものとして挙がる。これはつまり、 RELATED なコネクションが捉えられないことにもなるので、UNTRACKED なコネクションの取り扱いには注意が必要だ。例えば、関連した ICMP メッセージなどがステート機構で捕捉できなくなるからだ。 |
ステートを利用するには、 --state マッチを使う。それでコネクション追跡ステートに基づいたパケットマッチが行えるようになる。これが、ステート機構がファイヤーウォールにとって恐ろしく強力で効果的たる所以だ。ローカルネットワークへの返答を受け取るために、以前はよく、1024 から上のポートを全部開け放つ必要に迫られたものだ。だが、ステート機構がそれに取って代わった今、そんなことはもう必要ない。雑多なトラフィックを通すことなく、返答のトラフィックに的を絞ってファイヤーウォールを開けられるのだ。
7.4. TCPコネクション
ここからのセクションでは、基本的プロトコルである TCP, UDP, ICMP それぞれについて、ステートと、それがどのように処理されるかをつぶさに見ていくことにする。さらに、デフォルト つまり、これら 3 つのプロトコルに類別されない場合どうなるのかについても掘り下げる。まずは TCP プロトコルから始めることにした。というのも、 TCP はそれ自体ステートフルなプロトコルであるし、 iptables のステート機構に関わる興味深い特性がたくさんあるからだ。
TCP コネクションは常に 3 ウェイハンドシェークによって開始される。このハンドシェークによって、その先実際のデータを乗せることになるコネクションを確立およびネゴシエート (交渉) する。セッションは、まず SYN パケット、次に SYN/ACK パケットが続き、最後に、セッション確立を承認する ACK パケットが送られて始まる。この時点でコネクションは確立し、データが送れる状態となる。問題は、コネクション追跡がこれにどう追従していくかだ。当然の成り行きといえるだろう。
ユーザの目から見る限り、コネクション追跡はどのコネクションタイプでも基本的には同じように動作する。下図は、コネクションの段階を追う毎にストリームのステートがどう変わってゆくかを端的に示している。ご覧の通り、ユーザの目から見た場合、コネクション追跡が示すコードは、 TCP コネクションの手続きを文字通りに反映したものとはなっていない。まずひとつのパケット (SYN パケット) を検出すると、コネクション追跡はこの接続を NEW と判定する。返答パケット (SYN/ACK) を検出すると ESTABLISHED と判定する。一瞬考えれば、理由は分かるだろう。こうした特別な実装方法を採ることによって、 NEW と ESTABLISHED がネットワークから出ていくのを許可しつつ、戻ってくることができるのは ESTABLISHED コネクションだけに絞ったままで、コネクションは完璧に成り立つのだ。では逆に考えてみよう。もしも、コネクション追跡機構がコネクションの確立過程をひとまとめに NEW と判断してしまったとしたら、返ってくる NEW ステートのパケットもすべて許可しない限り、我々のローカルネットワークへ向けた外からの接続を阻止することは事実上不可能だ。さらに物事をややこしくしているのは、カーネルの内部では、 TCP コネクションに特有のいくつものステートが存在するという点だ。ただし、それらのステートはユーザ空間では利用できない。内部ステートは概ね、 RFC 793 - Transmission Control Protocol の 21-23 ページで規定されたステートに倣っている。これについては、このセクションの後半で考察することにしよう。
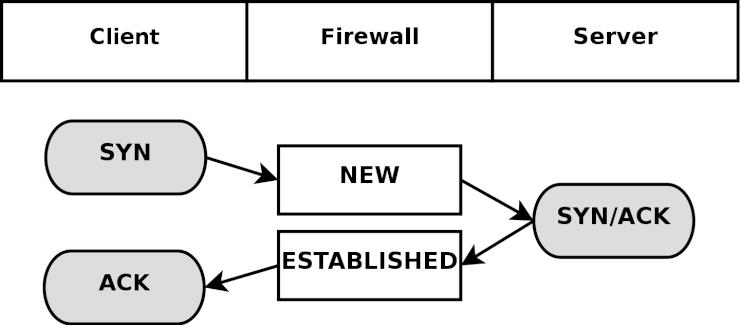
見て分かるように、ユーザの視点から見た場合、ことは非常に単純だ。しかし、カーネル側に視点を移して全体の構造を見ると、やや難解さを増す。例を見てみよう。 /proc/net/ip_conntrack テーブルでコネクションのステートが実際にどう変わってゆくかを考察してみる。最初のステートは、コネクションで最初の SYN パケットを受け取った時点だ。
tcp 6 117 SYN_SENT src=192.168.1.5 dst=192.168.1.35 sport=1031 \
dport=23 [UNREPLIED] src=192.168.1.35 dst=192.168.1.5 sport=23 \
dport=1031 use=1
上記エントリから読み取れる通り、 SYN パケットは送信済み (SYN_SENT フラグがセットされている) で、それに対する返答はまだ受け取っていない ([UNREPLIED] フラグが裏付けている) という、文字通りそのままのステートになっている。次のステートは反対方向のパケットを検出した時に訪れる。
tcp 6 57 SYN_RECV src=192.168.1.5 dst=192.168.1.35 sport=1031 \
dport=23 src=192.168.1.35 dst=192.168.1.5 sport=23 dport=1031 \
use=1
今、こちらからの送信に呼応した SYN/ACK を受け取ったところだ。このパケットを受信した瞬間に、今度はステートが SYN_RECV に変わる。SYN_RECV が示すのは、冒頭の SYN の配信が正常に完了し、返答の SYN/ACK パケットもファイヤーウォールを無事に通った、という意味だ。これに加えて、このコネクション追跡エントリは既に双方向のトラフィックを検出済みなので、即ち返答受け取り済みとなる。ただしこれは明示されない。前述の [UNREPLIED] とは違って暗黙的だ。最後のステップは、3 ウェイハンドシェークの締めとなる ACK を検出した時点でやってくる。
tcp 6 431999 ESTABLISHED src=192.168.1.5 dst=192.168.1.35 \
sport=1031 dport=23 src=192.168.1.35 dst=192.168.1.5 \
sport=23 dport=1031 [ASSURED] use=1
最後の例の時点において、我々は 3 ウェイハンドシェークの最後の ACK を受け取り、コネクションは、少なくとも iptables 内部メカニズムの範疇では ESTABLISHED ステートに移行した。通常、ストリームはこの時すでに ASSURED になっている。
コネクションが [ASSURED] にならずに ESTABLISHED ステートに移行することもある。コネクションピックアップ (pickup) をオンにした場合だ (tcp-window-tracking パッチを適用して ip_conntrack_tcp_loose の値を 1 以上に設定する必要あり)。デフォルトの状態つまり tcp-window-tracking を適用していない場合には、前記のような振る舞いをするはずであり調整は不能だ。
TCP コネクションが閉じられる際には、以下のような流れを採り、ステートは以下のようになる。
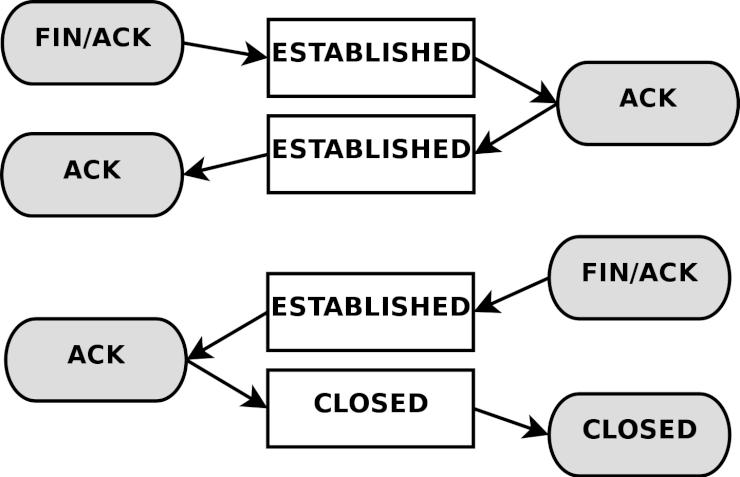
ご覧の通り、本当にコネクションが閉じるのは、最後の ACK が送られてからだ。ただしこの図は、あくまでも、接続が正常にクローズされる場合に限った図式だ。例えば、接続が拒否された場合には RST (リセット) の送信によって閉じられたりする。その場合、接続は即座にクローズする。
TCP コネクションが閉じると、その接続は TIME_WAIT ステートに移行する。デフォルトの待ち時間は 2 分間だ。これは、何らかの障害に遭遇したパケットが、コネクションが既にクローズした後でもルールセットに入って来られるようにするための仕組みだ。これは一種の時間的緩衝域 (buffer time) として働き、パケットがどこかの中継ルータで渋滞に捕まってしまった場合でも、こちらのファイヤーウォールや相手へ到達できるようになっている。
RST パケットによってコネクションがリセットされた場合には、ステートは CLOSE に移行する。この意味するところは、接続が完全にクローズされるまで猶予 (デフォルトは 10 秒) を与えるというものだ。 RST パケットは、いかなる場合にも承認される (acknowledged) ことはない。ただ一方的にコネクションを切断するだけだ。ステートには、解説してきたもの以外にもいくつかの種類がある。 TCP ストリームが採り得るステートを、タイムアウトの値とともに紹介しておこう。
Table 7-2. 内部ステート
| State | タイムアウトの値 |
|---|---|
| NONE | 30 分 |
| ESTABLISHED | 5 日 |
| SYN_SENT | 2 分 |
| SYN_RECV | 60 秒 |
| FIN_WAIT | 2 分 |
| TIME_WAIT | 2 分 |
| CLOSE | 10 秒 |
| CLOSE_WAIT | 12 時間 |
| LAST_ACK | 30 秒 |
| LISTEN | 2 分 |
これらの値は、まったくもって普遍的とは言い難い。カーネルのリビジョンによっても変わるし、proc ファイルシステムの変数 /proc/sys/net/ipv4/netfilter/ip_ct_tcp_* の操作によって変更することもできる。とはいえ、デフォルトの値はかなり熟考されており、理にかなった値になっている。値は秒単位で記述される。初期のバージョンのパッチでは (バグにより) ジッフィ [:jiffy: 1/100 秒] が用いられていた。
| もうひとつ心に留めておかなくてはならないことがある。ユーザ空間でのステート機構は TCP パケットに記載された TCP フラグ (RST, ACK, SYN といったもの) を見ないという点だ。これは大抵の場合、悪い結果を招く。というのも、NEW ステートのパケットをファイヤーウォールを通過させたい場面があるだろうが、その際、 NEW フラグを指定しておいて SYN パケットのことを指しているつもりになっているケースが多々見受けられるのからだ。 これは現在のステート機構の実装にはできない相談だ。実際には、たとえどんな TCP フラグも立っていないパケットだとしても、あるいは ACK フラグの立ったパケットだとしても、 NEW の判定が下されてしまう。この仕組みは冗長化 (redundant) ファイヤーウォールなどに用いられるが、一般的に言って、ファイヤーウォールがひとつしかないようなホームネットワークにおいては非常にまずい。こうした挙動を手当てするには、付録 "よくある問題と質問" の "NEWステートでありながらSYNビットの立っていないパケット" で説明しているコマンドを使う。また別のやり方としては、patch-o-matic の tcp-window-tracking 拡張機能をインストールした上で /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_loose にゼロを設定する方法がある。こうすれば、ファイヤーウォールは NEW パケットのうち SYN フラグのセットされているもの以外は全てドロップするようになる。 |
7.5. UDPコネクション
UDP コネクションそれ自体は、ステートフルなコネクションではない。どちらかといえばステートレスなコネクションだ。理由としてはいくつかあるが、まず、接続の確立もクローズも備えていないという点。そもそも UDP 接続にはシーケンス [訳者補足: sequence = 順序、手順] がない。ある順序で UDP データグラムがやりとりされる場合でも、どういう順序で送るかといった情報のやりとりは何もないのだ。それにもかかわらず、カーネル内部で接続のステートを判定することは可能だ。では、コネクションがどのように追跡されるか、 conntrack の中身はどんな風に見えるかを見ていこう。
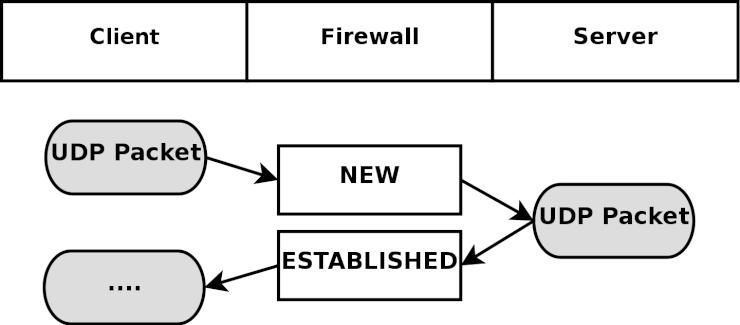
ご覧の通り、 TCP 接続とまったく同じ要領でコネクションが確立する。これはユーザ空間から見た様子だ。内部的に見ると conntrack 情報は少し様子が違う。とはいえ、細部は本質的には変わらない。ではまず、最初の UDP パケットが送られた時のエントリを見てみよう。
udp 17 20 src=192.168.1.2 dst=192.168.1.5 sport=137 dport=1025 \
[UNREPLIED] src=192.168.1.5 dst=192.168.1.2 sport=1025 \
dport=137 use=1
第一と第二の値から、これが UDP パケットであることが分かる。第一はプロトコル名であり、第二はプロトコルナンバーだ。 TCP コネクションと同様である。第三の値は、このステートエントリがどれだけの時間保持されるべきかを示す。そこから先は、検出したパケットの情報と、このコネクションで次に送信主から来るパケットに期待される情報だ。つまり、送信元、送信先、送信元ポート、宛先ポートだ。この時点では、 [UNREPLIED] フラグが記され、このパケットに対する返答はまだ一度も行われていないことを示している。そして最後に、返答パケットに期待される事柄の簡潔なリストがある。後者のグループでは、エントリが前者のものとは入れ違いになっていることも見逃さないでいただきたい。この時点でのタイムアウトは、デフォルトでは 30 秒だ。
udp 17 170 src=192.168.1.2 dst=192.168.1.5 sport=137 \
dport=1025 src=192.168.1.5 dst=192.168.1.2 sport=1025 \
dport=137 [ASSURED] use=1
この時点で、最初の送出パケットへの応答がなされ、コネクションは ESTABLISHED の判定に移行した。見ての通り、その事実はコネクション追跡には明示されない。主な違いは [UNREPLIED] フラグが消え去ったことだ。それに加えて、デフォルトタイムアウトは 180 秒に変わった。ただし、この例では既に 170 秒に減少している。さらに 10 秒後には 160 秒となるだろう。しかし、まだ何かひとつ足りない。そう、前にも述べた [ASSURED] フラグだ。追跡中のコネクションに [ASSURED] フラグが付くには、 NEW 状態のパケットに対して正規な回答パケットが返ってきている必要がある。
udp 17 175 src=192.168.1.5 dst=195.22.79.2 sport=1025 \
dport=53 src=195.22.79.2 dst=192.168.1.5 sport=53 \
dport=1025 [ASSURED] use=1
この時点をもって、コネクションは確立 (assured) した。コネクションの様子は先ほどの例と全く同じだ。もしも、180 秒の間この接続が使用されなければ、コネクションはタイムアウトする。180 秒というとかなり短いように思えるが、ほとんどの場合にはこの数字で充分だ。エントリにマッチするパケットがファイヤーウォールに入ってくる度に、この値はデフォルト値へとリセットされる。他の内部ステートについてもこれと同じことが言える。
7.6. ICMPコネクション
ICMP パケットは、ステートフルとは対極に位置するものだ。というのも、 ICMP は制御に使用するだけであり、いかなるコネクションも張らないからだ。さりながら、 ICMP のうち 4つのタイプだけは、回答パケットを発生させ、これらはふたつのステートを採る可能性がある。 ICMP メッセージが採り得るステートは NEW と ESTABLISHED。これに該当する ICMP タイプが、 Echo の request と reply 、 Timestamp の request と reply 、 Information の request と reply 、そして Address mask の request と reply だ。この中で、 Timestamp の request と reply と、 Information の request と reply は廃れて使われなくなっているため、たいていは捨ててしまって構わない。しかし Echo メッセージはホストに対して ping を打つ時など、各種設定の最中に利用することがある。 Address mask 要求は、それほど使う機会は多くないとはいえ、時々役に立つし、通行を許すだけの価値はある。どんな具合に見えるか、下の図を見ていただこう。
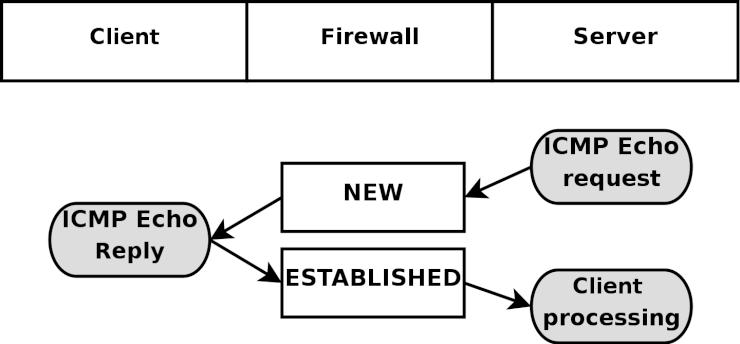
上の図から見て取れるように、ホストが echo request を送ると、ファイヤーウォールでは NEW と判定される。相手が echo reply で返答すれば、それはファイヤーウォールで ESTABLISHED と判定される。最初の echo request を検出した時、ip_conntrack には以下のステートエントリが書き込まれる。
icmp 1 25 src=192.168.1.6 dst=192.168.1.10 type=8 code=0 \
id=33029 [UNREPLIED] src=192.168.1.10 dst=192.168.1.6 \
type=0 code=0 id=33029 use=1
見ての通り、 TCP と UDP で見てきた標準的なステートとは、少し様子が違う。プロトコルもある。タイムアウトもある。送信元と宛先のアドレスもある。しかし問題はその先。今までに見覚えのない、 type, code, id という 3 つのフィールドがあるのだ。だが特殊という程のものでもない。 type フィールドには ICMP タイプが、 code フィールドには ICMP コードが書いてあるだけのことだ。これらは付録 ICMPタイプ で見られる。最後の id フィールドは、 ICMP ID が入っている。 ICMP パケットは、送出される際に固有の ID を与えられ、 ICMP メッセージの受け手は新たな ICMP メッセージにこれと同じ ID をセットして送り出す。こうすることよって、送り主はどれが目的の回答か識別でき、的確な ICMP request と結びつけることができるのだ。
次のフィールドには、どこかで見覚えのある [UNREPLIED] フラグがまたまた読み取れる。以前と同じく、今我々が見ているのが、まだ片方向のトラフィックしか検出していないコネクション追跡エントリだと告げている。最後に、 ICMP 回答パケットに期待される内容が、オリジナルの送信元と宛先が入れ替わった形で書かれている。type と code に関しては、回答パケットに求められる値に書き換わっており、 echo request だったら echo reply に換わっているという具合だ。 ICMP ID は元のままだ。
前に説明したように、返答パケットは ESTABLISHED と判定される。だが、ICMP の回答の後には、もう同じコネクションで正規のトラフィックが交わされることはあり得ない。この理由により、回答が一度 Netfilter 構造を通り抜ければ、そのコネクション追跡エントリは破棄される。
上記のような場面が繰り返される度に、要求は NEW、応答は ESTABLISHED という判定が行われる。もう少し踏み込んでみよう。ファイヤーウォールは、 request パケットを検知すると NEW と判定する。そのホストが要求に対する応答パケットを返すと、ファイヤーウォールは ESTABLISHED と判断するわけだ。
| つまり、応答パケットは、コネクション追跡エントリに基づいて ESTABLISHED を判定するような判定基準に必ずマッチすることになる。その点は他のトラフィックタイプと同様だ。 |
ICMP request は 30 秒のデフォルトタイムアウトを備えており、 /proc/sys/net/ipv4/netfilter/ip_ct_icmp_timeout エントリで変更もできる。タイムアウトとして、これは概ね最適な値だ。これだけあれば、まず間違いなく回答が拾えるだろう。
ICMP に関してもうひとつ極めて重要な点は、 ICMP が、特定の UDP や TCP コネクションあるいはその試みに起きた事柄を、ホストに伝える役割を持っているという点だ。自明な帰結として、 ICMP 要求は多くの場合、その元となったコネクションやコネクションの試みに対して RELATED だと判定される。分かりやすい例が Host unreachable や Network unreachable の ICMP メッセージだ。これらのメッセージは、他のホストへの接続を試み、それが失敗した場合に発生し、こちらへ返信される。目的のネットワークやホストがダウンしていると、問題のサイトにアクセスしようとした最後のルータが、その旨を報告するための ICMP メッセージを返してくる仕組みだ。この時の ICMP 応答は RELATED なパケットだと判定される。下図にその様子を示した。
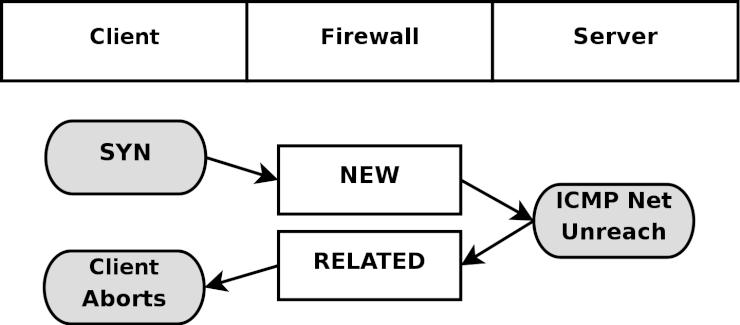
上記の例では、あるアドレスへ向けて SYN パケットを送っている。このパケットはファイヤーウォールで NEW と判定される。だが、パケットがアクセスしようとしているネットワークは到達不能 (unreachable) である。よって、ルータが network unreachable の ICMP パケットを送り返してくる。接続はこの時すでに追跡エントリに追加されているため、コネクション追跡プログラムはこのパケットを RELATED と判定することができる。このようにして ICMP 応答は無事にクライアントまで届き、クライアントは (願わくば) 要求をあきらめる。
UDP 接続においても、上記と同様な障害に突き当たった場合には、前記と同じことが起こる。 UDP コネクションに対して送り返された ICMP メッセージも、すべて RELATED と判定される。下の図を見てほしい。
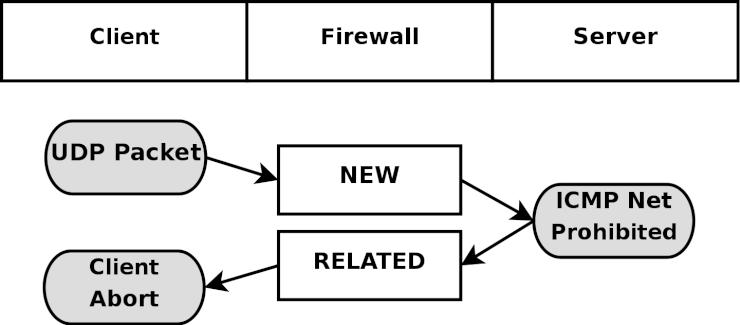
今回ホストに向かって送り出すのは UDP パケットだ。この UDP コネクションは NEW となる。しかし、経路途中のファイヤーウォールかルータによって、目的のネットワークへの接続は禁止 (prohibit) されていたとする。その結果、我々のファイヤーウォールは Network Prohibited の ICMP メッセージを受け取る。ファイヤーウォールはこの ICMP エラーメッセージが既に開かれた UDP コネクションに関連していることを知っているので、これを RELATED なパケットとしてクライアントに渡す。ファイヤーウォールはこの段階でそのコネクション追跡エントリを破棄し、クライアントは ICMP メッセージを受け取って (願わくば) 接続を取り止める。
7.7. デフォルトのコネクション
時として、プロトコルの扱い方が conntrack 機構に分からないことがある。コネクション追跡機構にとって未知のプロトコルだったり、そのプロトコルの動作仕様が分からない場合だ。こうした際には、コネクション追跡はデフォルト動作に立ち返る。デフォルト動作を採るプロトコルの例が、 NETBLT、 MUX、 EGP だ。デフォルト動作は UDP 接続の追跡に似通ったものとなる。初めのパケットは NEW と判断され、回答以降のトラフィックは ESTABLISHED と判断される。
デフォルト動作が選択された場合、これらのパケットはどれも、初期値として同じタイムアウトの値を採る。この値は /proc/sys/net/ipv4/netfilter/ip_ct_generic_timeout の変数で設定可能だ。デフォルト値は 600 秒つまり 10 分となっている。デフォルトコネクション追跡を使用するリンクにどういったトラフィックを乗せたいかによって、この値は調整する必要がある。特に、衛星を経由してトラフィックを送り返す場合などには、長い時間を要する可能性があるため、値を調整しなければならない。
7.8. 追跡除外コネクションとrawテーブル
Linux のコネクション追跡における UNTRACKED はかなり特殊なキーワードだ。ごく平たく言えば、 raw テーブルで追跡を除外するようマークされたパケットを、選別するためのものだ。
まさにこの目的のために作られたのが raw テーブルであり、そこでは、netfilter で追跡してほしくないパケットに対して NOTRACK マークを付けることができる。
| 僕が コネクション ではなく パケット と言っていることにお気づきだろうか。ここで言うマークは、進入してきた各パケットに対して付けられるのだ。もしそうでなかったら、追跡すべきでないパケットかどうかを知るために何らかの追跡が必要、というおかしなことになってしまう。 |
既に当チャプターで述べてきたように、 conntrack およびステート機構はかなりのリソース食いだ。そのため、コネクション追跡とステート機構が働かないようにしたほうがいい時もある。
ひとつの例が、大量のトラフィックを扱うルータで、ルータ自体への入出トラフィックはファイヤウォールしたいが、他へルーティングするトラフィックはファイヤーウォールしたくない場合だ。この時、 raw テーブルで自分宛のパケットは ACCEPT し、それ以外にはすべて NOTRACK マークを付ければいい。そうすれば、ルータ自身へのトラフィックに対してはステートフルマッチが行え、なお且つ、中継するだけのトラフィックに対する CPU パワーがセーブできるのだ。
NOTRACK が活用できる別の例としては、トラフィックの多い Web サーバで、ステートフルな追跡はしたいが Web トラフィック自体の追跡には CPU パワーを消費したくない場合がある。この時には、ローカルな IPアドレスおよび Webサービスを提供している IPアドレスそのもののポート 80 に対しては追跡をオフにすればよい。その結果、既に明らかにオーバーロード状態になっている Web トラフィックに関してはプロセッシングパワーを節約しながら、それ以外のサービスに対しては依然としてステートフルな追跡が行える。
ただし、 NOTRACK には留意しておかなくてはならない問題点もある。コネクションが NOTRACK されるということは、RELATED なコネクションが察知できないということでもあり、conntrack や nat ヘルパーは軒並み機能しなくなるし、関連のある (related) ICMP エラーも拾えなくなるのだ。つまり、そうしたパケットに対しては個別的に門を開いてやらなければならない。特に FTP や SCTP などといった複雑なプロトコルとなると、手動で面倒を見るのは難行だ。だが、このことに注意しておけば、 NOTRACK を操ることは難しくはない。
7.9. 複雑なプロトコルとコネクション追跡
プロトコルの中にはかなり複雑なものもある。つまり、コネクション追跡の面で、こういったプロトコルは正しく追跡するのが難しい。その典型が ICQ、 IRC、 FTP だ。これらはいずれも、データのペイロード自体で情報をやりとりするので、追跡が正しく機能するためにはコネクション追跡にヘルパー が必要となる。
下表に、Linux カーネルでサポートされている「複雑なプロトコル」のリストと、サポートの始まったカーネルバージョンを示す。
FTP
IRC
TFTP
最初に、 FTP を例として取り上げよう。 FTP プロトコルは、まず最初に FTPコントロール セッションと呼ばれる 1 本のコネクションを張る。このセッション上でこちらからコマンド送ると、他に幾つかのポートが開き、コマンドに応じた後続データをそこに乗せて輸送する。こうした接続を行うにはふたつの方式がある。アクティブ とパッシブ だ。 アクティブコネクションでは、 FTP クライアントが、接続に使用するポートと IPアドレスをサーバに伝える。それが終わると、 FTP クライアントが解放したポートに向かって、サーバが特権ポート以外 (>1024) で接続を張り、そこにデータを乗せて送ってくる。
問題は、こうしたネゴシエーションがプロトコルデータのペイロードそのものの中で行われるため、ファイヤーウォールにとっては前記の追加コネクションを知る術がないという点だ。その結果、ファイヤーウォールには、それら特定のポートを通じてサーバからクライアントへ行われる接続を許可すべきだということが分からないのだ。
問題を解決するには、コネクション追跡モジュールに特別なヘルパー を付加して、コントロールコネクション内のデータから特有の書式と情報をスキャンできるようにする。正しい情報に行き当たったら、モジュールはその特別な情報を RELATED として加える。この RELATED エントリを利用すれば、サーバはコネクションを追跡することが可能となるのだ。 FTP サーバがクライアントへコネクションを張り返した時に、ステートがどのようになるか、下の図をとくとご覧いただきたい。
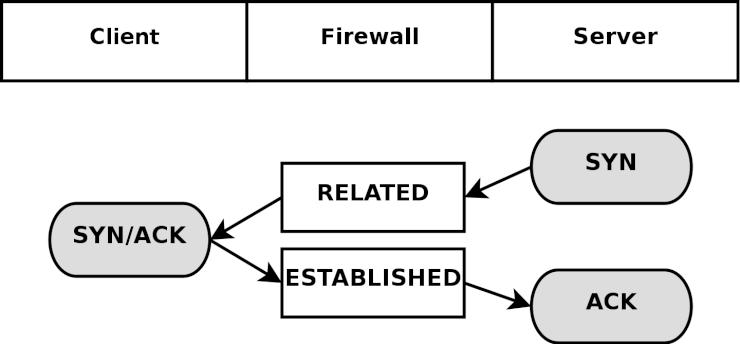
パッシブFTP は、これとちょうど逆の動作をする。 FTP クライアントが特定のデータをサーバに要求する。するとサーバは、これこれの IPアドレス及びポートで接続せよと回答する。このデータを受け取ると、クライアントは自分の 20 番 (FTP-data) ポートで、サーバから言われたポートへ接続を行い、求めていたデータを実際に受け取る。つまり、もしファイヤーウォールの内側に FTP サーバを置いているのなら、インターネット上のクライアントからこのサーバへ正常に接続させるためには、標準の iptables モジュールに加えて、このモジュールが必要となる。また、ローカルネットワーク上のユーザをきつく縛り、インターネット上の HTTP サーバと FTP サーバへだけ接続を許し、その他のポートは塞いでおきたい場合にも、やはり必要だ。下の図で、パッシブFTP における動作を検証してみよう。
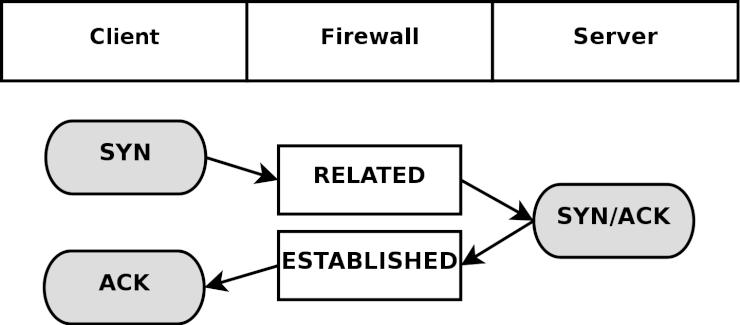
conntrack ヘルパーの幾つかは、カーネルの一部として初めから利用可能になっている。中でも FTP と IRC プロトコル用の conntrack ヘルパーは、このドキュメントを執筆している時点で、もうカーネルに備わっている。見つからない場合は、 iptables ユーザ空間の patch-o-matic ツリーを覗いてみるといいだろう。 patch-o-matic ツリーには、 ntalk や H.323 プロトコル用の conntrack ヘルパーをはじめとして、たくさんのものが見つかるはずだ。必要なヘルパーが patch-o-matic でも見つからない時には、いくつかの選択肢がある。ひとつは、 iptables の CVS ソースツリーに最近仲間入りしていないか調べてみること。もうひとつは、求めるようなモジュールがないか、Netfilter-devel メーリングリストで尋ねてみることだ。まだ存在せず、追加される予定もないと判明したら、残るはただひとつ、自分でそうしたデバイスを書くしかない。その際には、付録 その他の資料とリンク から辿れる Rusty Russell's Unreliable Netfilter Hacking HOW-TO が参考になること請け合いだ。
conntrack ヘルパーは、コンパイル時にカーネルへスタティックに組み込むこともできるし、モジュールとしてコンパイルすることもできる。モジュールとしてコンパイルしてある場合には、下記のコマンドでロードできる。
modprobe ip_conntrack_ftp modprobe ip_conntrack_irc modprobe ip_conntrack_tftp modprobe ip_conntrack_amanda
注意してほしいのは、 NAT とコネクション追跡がまったくの別物だという点だ。よって、コネクションの NAT も同時に行いたいのなら、他にもモジュールが必要となる。例えば、NAT と、 FTP コネクションの追跡がしたいなら、 NAT モジュールも要る。 NAT ヘルパーはすべて、 ip_nat_ で始まる一定の命名法を採っている。例えば、FTP NAT ヘルパーは ip_nat_ftp となるし、 IRC モジュールなら ip_nat_irc だ。 conntrack ヘルパーも同様の命名法に則っているので、 IRC conntrack ヘルパーなら ip_conntrack_irc、 FTP conntrack ヘルパーなら ip_conntrack_ftp で御明算だ。
7.10. まとめ
このチャプターでは、netfilter のステート機構の働きと、それが各種のコネクションをどうやって追跡するかを解説した。また、エンドユーザであるあなた方にとってどんな意義があるか述べ、ステート機構の挙動を変更する方法や、コネクション追跡の面で複雑な処理の必要となる様々なプロトコルと、そこで conntrack ヘルパーがどう関わってくるかについても説明した。
次のチャプターでは、 iptables アプリケーションに付属する iptables-save と iptables-restore を使ってルールセットを保存/リストアする方法について述べる。これらふたつのツールには良い点もあれば悪い点もあるが、そのことについても次章で述べる。
Chapter 8. 大きなルールセットの保存とリストア
iptables パッケージには、大きなルールセットを扱う時に重宝するふたつのツールが付属している。iptabeles-save と iptables-restore と呼ばれるツールで、ルールセットを、以降のドキュメントで扱うスタンダードなシェルスクリプトとはやや異なったフォーマットで、指定のファイルに保存し、復元 (restore) してくれる。
| iptables-restore をスクリプト言語から使うことも可能だ。その際の大きなポイントは、出力を iptables-restore の STDIN に渡すことだ。これだとルールの全てを一挙に素早く挿入できるため、非常に大きな (数千行の) ルールセットを登録する場合にも効率がいい。例えば make_rules.sh | iptables-restore とやればいい。 |
8.1. 速度に関する考察
iptables-save と iptables-restore コマンドを利用する最も大きな要因は、大きなルールセットのロードおよび保存が、これらによってかなり高速化できることだ。 iptables ルールを収めたシェルスクリプトを走らせる場合に一番の問題となるのは、スクリプト中で iptables コマンドを発行する度に、 iptables は、まずカーネル領域からルールセット全体を抽出してから、当該のコマンドが要求するルールの挿入なり、追加なり、変更なりを行うという点だ。そうしてから、自メモリ領域上にできた更新版のルールセットを、カーネルスペースに送り込む。シェルスクリプトを使う場合、ルールの挿入を伴うルールひとつひとつでこうした動作が行われ [訳者註: その度毎にルールセットはより大きくなってゆくので]、抽出と挿入にかかる時間はどんどん長くなっていく。
この難点を解決するために、 iptables-save および restore コマンドがある。 iptables-save コマンドは特別なフォーマットを持ったテキストファイルにルールセットを保存し、 iptables-restore コマンドは、このテキストファイルからルールセットを再びカーネルにロードするためにある。このふたつのコマンドの強みは、ルールセットのロードと保存が、たったひとつのリクエストで片づくという点だ。 iptables-save は、ひと息の動作だけで、カーネルからルールセット全体を掴み取りファイルに保存する。 iptables-restore は、テーブルをひとつの動作単位として、当該のルールセットをカーネルにアップロードする。つまり、極めて巨大なルールセットがここにあるとして、カーネルからの削除を 3,000 回行い、再び同じ数だけカーネルにアップロードする代わりに、丸ごと一挙にファイルへ保存し、いくつのテーブルがあるかにもよるが、 3つやそこらの動作でそれをアップロードできるのだ。
お分かりのことと思うが、 iptables-save と iptables-restore は、もしあなたが膨大なルールを挿入しなければならない環境で作業するのなら、まさにもってこいのツールだ。しかし、短所が存在するのも確か。それについて、以下のセクションで検討していくことにしよう。
8.2. restoreの欠点
既に脳裏にこんな疑問が浮かんだ読者もいるかもしれない。 iptables-restore でスクリプトの類は扱えるのか? 答は、今のところノーだ。おそらくは将来もできないだろう。これが iptables-restore の不備な点であり、設定ファイルから広範な事柄を行うことはできない。例えばあなたが IPアドレスを動的に割り当ててもらっているとしよう。コンピュータが起動する毎にこのダイナミック IP を読み取って、スクリプトの中で利用したいとしたら? iptables-restore では事実上不可能だ。
ひとつの打開策として可能性があるのは、スクリプト中で利用したい値を把握するために小さなスクリプトを用意して、特定のキーワードで iptables-restore ファイルを sed し、小スクリプトによって把握しておいた値に置き換える方法だ。この時点で置き換え結果をテンポラリファイルに保存し、それを iptables-restore でロードする。だがこのやり方にも問題は多い。あなたがリストア用スクリプトに書いておいた置き換え対象のキーワードは、 iptables-save を使用したらすべて削除されてしまう。だから、あなたはもう iptables-save コマンドをろくに使えなくなってしまうのだ。解決策としてはあまりにも不格好だ。
次に考えられるのは、既に述べた例の方法だ。つまり、ルールを iptables-restore のフォーマットで吐き出すようなスクリプトを作成し、その出力を iptables-restore の標準入力に渡すというやり方である。極めて大きなルールセットを扱う場合には、iptables コマンドを直接使うよりもこちらのほうが適切といえるだろう。iptables コマンドには、当チャプターの冒頭でも述べたように、非常に大きなルールセットを登録する時に多くの CPU パワーを消費する悪い癖があるからだ。
他に、先に iptables-restore スクリプトをロードしておいてから、動的ルールを必要箇所に追加で挿入するシェルスクリプトを走らせるという方法も考えられる。だが、こちらもたいして格好が良くなったとはいえない。 iptables-restore は、 IPアドレスが動的割り当ての場合や、設定オプションに応じて振る舞いを変えたいようなケースには、元来、不向きにできているのだ。
iptables-restore および iptables-save のもうひとつの欠点は、このドキュメントの執筆時点でだが、完璧には機能しないケースがあるということだ。これらのツールをまだあまりたくさんの人たちが使っていないために、それだけバグを発見する機会も少ない。そのせいで、一部のマッチやターゲットが正常に挿入されず、予想外の奇妙な挙動を引き起こす場合がある。しかし、こうした問題があってもなお、僕は iptables-restore と iptables-save の利用を強くお勧めする。ツールに扱い方が分からないような極端なターゲットやマッチでも使っていない限り、ほとんどのルールセットでは絶大な効果を発揮してくれるはずだ。
8.3. iptables-save
これまで説明した通り、 iptables-save コマンドは、現在のルールセットを iptables-restore で利用できるファイルへ保存するツールだ。このコマンドは極めてシンプルで、たったふたつの引数しか採らない。コマンド書式を理解するために、以下のコマンドを見ていただこう。
iptables-save [-c] [-t table]
-c 引数は、バイトおよびパケットのカウンタ値を保持するよう iptables-save に指示する。これは例えば、メインファイヤーウォールを再起動したいものの、統計に役立つバイトおよびパケットカウンタは喪失したくない場合に使用する。そうした際に -c 引数付きの iptables-save コマンドを使用すれば、統計および集計のルーティーンをリセットすることなくファイヤーウォールをリブートできる。デフォルトの挙動では、当然、カウンタは無傷では済まない。
-t 引数は、保存対象とするテーブルを iptables-save に指示する。-t を指定しない場合、 iptables-save コマンドは自動的に、有効なすべてのテーブルをファイルに保存する。下記の例は、いかなるルールセットもロードしていない時に iptables-save コマンドが出力するはずの内容を示している。
# Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *filter :INPUT ACCEPT [404:19766] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [530:43376] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *mangle :PREROUTING ACCEPT [451:22060] :INPUT ACCEPT [451:22060] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [594:47151] :POSTROUTING ACCEPT [594:47151] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *nat :PREROUTING ACCEPT [0:0] :POSTROUTING ACCEPT [3:450] :OUTPUT ACCEPT [3:450] COMMIT # Completed on Wed Apr 24 10:19:17 2002
コメントも何行か書かれており、それらは # で始まっている。テーブルは *<table-name> のような書き方になっており、例えば *mangle がそれだ。そして各テーブル毎に、チェーンの定義とルールが記されている。チェーンの定義は :<チェーン名> <チェーンポリシー> [<パケットカウンタ>:<バイトカウンタ>] のような形式だ。チェーン名は例えば PREROUTING などで、それにポリシーが ACCEPT のように続く。最後にパケットカウンタとバイトカウンタが来るが、これは iptables -L -v が出力するものと同じだ。最後に COMMIT キーワードでテーブルの宣言が締めくくられる。 COMMIT キーワードは、取り敢えずこの時点まででカーネルへのパイプライン上にあるすべてのルールを登録実行せよ、という指示をする。
上記は例はちょっと単純すぎる。今度は、ごく小さな iptables-save ルールセット を含む簡単な例を示すのが何よりもの説明になると思う。その状態で iptables-save を掛けたとすると、下記のような出力が得られるはずだ:
# Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *filter :INPUT DROP [1:229] :FORWARD DROP [0:0] :OUTPUT DROP [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A FORWARD -i eth0 -m state --state RELATED,ESTABLISHED -j ACCEPT -A FORWARD -i eth1 -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT -A OUTPUT -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT COMMIT # Completed on Wed Apr 24 10:19:55 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *mangle :PREROUTING ACCEPT [658:32445] :INPUT ACCEPT [658:32445] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [891:68234] :POSTROUTING ACCEPT [891:68234] COMMIT # Completed on Wed Apr 24 10:19:55 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *nat :PREROUTING ACCEPT [1:229] :POSTROUTING ACCEPT [3:450] :OUTPUT ACCEPT [3:450] -A POSTROUTING -o eth0 -j SNAT --to-source 195.233.192.1 COMMIT # Completed on Wed Apr 24 10:19:55 2002
見ての通り、ここでは -c 引数を用いたので、各コマンドの先頭にはバイトおよびパケットカウンタが付いている。その点を除いては、各コマンドラインはほぼスクリプトの生き写しとなっている。今や課題は、出力をいかにしてファイルに書き出すかだけだ。答は簡単、 Linux をちょっと触ったことのある読者なら、やり方はもう分かっているはずだ。渡してやりたいファイルへコマンド出力をリダイレクトするだけである。こんな要領だ:
iptables-save -c > /etc/iptables-save
つまり、このコマンドは、バイトおよびパケットカウンタを保持したまま、ルールセットを丸ごと /etc/iptables-save という名前のファイルに保存する。
8.4. iptables-restore
iptables-restore コマンドは、 iptables-save コマンドで保存した iptables ルールセットを、復元 (restore) するのに使用する。入力は標準入力から読み取られ、このドキュメントを執筆している時点では、残念ながらファイルからロードすることはできない。 iptables-restore のコマンド書式はこうだ:
iptables-restore [-c] [-n]
-c 引数はバイトおよびパケットカウンタをリストアする。 iptables-save で保存しておいたカウンタ値もリストアしたいなら、必ず指定しなくてはならない。長いオプションで --counters と書くこともできる。
-n 引数は、これから書き込もうとする特定のテーブルあるいはすべてのテーブルの内容を上書きしないよう iptables-restore に伝える。デフォルト動作では、iptables-restore は既存のルールをフラッシングし抹消する。短いオプションでは -n だが、長いオプションで --noflush と書くこともできる。
iptables-restore コマンドでルールセットをロードするには幾つかの方法があるが、代表として、最もシンプルで一般的なやり方を紹介しておこう。
cat /etc/iptables-save | iptables-restore -c
下記のコマンドでもできる:
iptables-restore -c < /etc/iptables-save
このコマンドは、 /etc/iptables-save ファイルの保持するルールセットを cat して iptables-restore にパイプ渡しし、 iptables-restore がそれを標準入力を通じてバイトとパケットのカウンタとともに受け取ってリストアする。こんな具合で、そもそもが込み入ったことではない。ただし、やり方は気が遠くなるほどのバリエーションがあり、違った手法はいくらでも挙げられる。しかし、それはこのチャプターの守備範囲から外れるので省略し、各読者諸氏の実地検証に委ねることにしよう。
これにて、ルールセットはカーネルに正しくロードされ動作しているはずだ。もしだめなら、ことによるとコマンドのバグにぶつかってしまったのかもしれない。
8.5. まとめ
このチャプターでは iptables-save プログラムと iptables-restore についてかなり詳しく述べ、その使い方を解説した。これらふたつは iptables パッケージに付属しているプログラムで、長大なルールセットを素早く保存したりそれをまたカーネルに投入したりできる。
次のチャプターでは iptables のルールの書式と、その規則に則ったルールセットを正しく記述する方法について述べる。また、必要に応じて、見本にしてもらえる基本的なコーディングスタイルも紹介していく。
Chapter 9. ルールの作り方
当チャプターと後続の 3 つのチャプターでは、自分のルールを構築する際のやり方を深く掘り下げる。ルールとは、特定のチェーンにおけるコネクションとパケットのブロックや許可に際して、ファイヤーウォールが従うべき指示だと言うことができる。チェーン内の一行一行が、ルールとして解釈される。ここではまた、基本的なマッチとその使い方、ターゲットのいろいろ、独自ターゲット (つまりサブチェーン) の作り方についても検討していく。
このチャプターは、ルール作成のいろはを説明する。ユーザ空間の iptables プログラムに受け入れてもらうにはルールをどう書き、どのようにして組み込めばいいのかや、テーブルの種類、それに、 iptables に与えるコマンドについて取り上げていく。それが終わったら、次のチャプターで、 iptables で利用可能なあらゆるマッチに目を通し、各種ターゲットの詳細に踏み込んでいくことにする。
9.1. iptablesのコマンドの基本
説明してきたように、ルールとは、カーネルがパケットの処置について指示を仰ぐ、行単位の記述だ。そのパケットに完全に一致する評価基準 (つまりマッチ) が見つかると、ターゲット (ジャンプ) に書かれた指示が実行される。我々が記述するルールは、通常、下記のような書式を採る:
iptables [-t テーブル] コマンド [マッチ] [ターゲット/ジャンプ]
ターゲット指示は行末に置かなければならないという根拠はどこにもない。しかし、読みやすさの面から、この文法に付き従うことが多い。ともかく、あなたが目にするほとんどのルールはこの書式を採っているだろう。そのおかげで、誰の書いたスクリプトを読んでも、文法に惑わされることなくルールがすぐに理解できる。
標準以外のテーブルを使いたい場合には [テーブル] のところでテーブルを指定してもいい。しかし、どのコマンドでも iptables はデフォルトで filter テーブルを対象にするので、敢えて書く必要はない。また、指定する位置もここしか駄目というわけではない。行の中のどこに書いても構わないのだが、一番頭に書くのが、いわば常識となっている。
ただし、留意すべき点はある。コマンドは必ず先頭またはテーブル指定の直後になくてはならない。コマンドとは、 iptables に何をさせるかということ。例えば、ルールを挿入する、チェーンの末尾にルールを加える、ルールを削除する、といった事柄だ。これについては後で詳しく述べよう。
マッチとは、ルールの一部であり、それによって、目的とするパケットを他のパケットから見分けるための、パケットの素性をカーネルに教える。つまり、これで指定するのは、パケットがどんな IPアドレスから来るか、どのネットワークインターフェースから入ってくるか、宛先はどんな IPアドレスやポートやプロトコルか、など。利用できるマッチは、このチャプターの後のほうで解説するが、膨大な数に上る。
行の最後にはパケットのターゲットが来る。パケットがすべての条件に合致したら、カーネルはこのターゲットを執行する。一例を挙げれば、カーネルに対して、我々が独自に作成したチェーンへの送致を指令することであり、その場合、独自チェーンは元のチェーンの一部と見なされる。あるいはまた、カーネルに、パケットを黙殺してそれ以上頓着しないようにさせたり、特定の返答を送り主へ返すなどの指示を与えることもできる。この続きは、このチャプターで追い追い詳述してゆくことにしよう。
9.2. テーブル
-t オプションは操作の対象テーブルを指定する。デフォルトでは filter テーブルが使用される。 -t オプションで指定できるテーブルは下記。これはチャプター テーブルとチェーンの道のり の内容を手短に要約したものだ。
Table 9-1. テーブル
| テーブル | 説明 |
|---|---|
| nat | nat テーブルは主としてネットワークアドレス変換 (Network Address Translation) に使用する。"NAT" されたパケットは、ルールに従って IPアドレスが変更される。どのパケットも、ストリーム中で一度だけこのテーブルを通る。つまり、そのストリームの先頭パケットだけがこのテーブルの通行を許されるのだということを心しておかなければならない。ストリームの残りのパケットは、自動的に "NAT" あるいはマスカレード (Masquerade) され、先頭パケットの行動に追従する。言い換えれば、後続パケットは二度とこのテーブルは通らないし、先頭パケットと同じ処方さえ受けないのだ。後でくどいほど説明するが、このテーブルでは一切のフィルタリングを行うべきでないという理由がここにある。ファイヤーウォールに入ってすぐにパケットを変換するには PREROUTING チェーンを使用する。ローカル (つまりファイヤーウォール) で発生したパケットをルーティング判断前に変換するには、OUTPUT チェーンを使用する。そして、パケットがファイヤーウォールを離れる直前に変換を行うためには POSTROUTING チェーンが用意されている。 |
| mangle | このテーブルは主にパケットの改変 (mangle) に利用する。主な利用法は、様々なパケットの内容やヘッダを書き換えること。例えば TTL、TOS、MARK の変更だ。 MARK は厳密にはパケットの変更ではないが、カーネル領域でパケットへのマークが設定される。このマークは、ファイヤーウォール上での以降のフィルタリングにおいて、他のルールやプログラムから利用できるばかりでなく、例えば tc などの高度ルーティングにも利用可能だ。 mangle テーブルは PREROUTING、 POSTROUTING、 OUTPUT、 INPUT、 FORWARD という 5 つの組み込み済みチェーンを持つ。 PREROUTING は、パケットを、ファイヤーウォールへの進入直後、且つルーティング判断前の時点で改変するのに用いる。 POSTROUTING は、すべてのルーティング判断が行われた後に改変を行う。ローカル (つまりファイヤーウォール) で発生したパケットをルーティング判断の後で変換するには OUTPUT チェーンを使用する。 INPUT は、パケットがローカルコンピュータ自体へ誘導された後で、且つデータがユーザ空間アプリケーションに相まみえる前の改変に使う。 FORWARD は、ルーティングの第一判断の後、なお且つ最終ルーティング判断の前にパケットを改変するのに使用する。 mangle は、いかなるネットワークアドレス変換にもマスカレードにも利用できないという点に注意。そうした処理を意図して作られているのは nat テーブルだ。 |
| filter | filter テーブルこそ、まさにパケットフィルタリングを精力的に行う場所だ。例えば、他のテーブルでも可能な DROP、 LOG、 ACCEPT、 REJECT のいずれの処理も、ここでは何の問題なく行える。 filter テーブルは 3 つのチェーンを内蔵している。最初のチェーンは FORWARD で、発生源がローカルでなく、宛先もローカルホスト (つまりファイヤーウォール) 宛でないパケットに対して使用する。 INPUT はローカルホスト (ファイヤーウォール) を宛先とするすべてのパケットに、そして OUTPUT はローカルで発生したパケットすべてに使用する。 |
| raw | raw テーブルとその中のチェーンは、 netfilter にあるどのテーブルよりも先に適用される。これは NOTRACK ターゲットを利用するために考案されたテーブルだ。登場してまだ日が浅く、2.6 後期カーネル以降で、なお且つ、それを使うようにコンパイルされていなければ使用できない。raw テーブルは 2つのチェーンを内包している。PREROUTING と OUTPUT チェーンがそれで、この 2つのチェーンはパケットがどの netfilter サブシステムに触れるよりも前にパケットを処理する。 PREROUTING チェーンは当マシンへ入ってきたパケットとフォワードされたパケットに対して使用することができ、もう一方の OUTPUT チェーンは、ローカルで発生したパケットに他のどの netfilter サブシステムよりも早い段階で変更を加えたい時に使うことができる。 |
上の説明で、利用可能な 4 つのテーブルの概念が分かったことと思う。テーブルはそれぞれ、まったく別々の目的に利用するもので、各々の内蔵チェーンの使い分けを知っておかなければならない。使い方を誤れば、あなたはファイヤーウォールに墓穴を穿ち、ほどなく誰かがそれを発見して何かを潜り込ませ、あなたは自ら掘った穴に落ち込むことになるだろう。前提となるテーブルとチェーンについては、前のチャプター テーブルとチェーンの道のりで説明した。もし理解が完全でないなら、ぜひ、そのチャプターに戻りもう一度通読することをお勧めする。
9.3. コマンド
このセクションでは、いろいろなコマンドとその使用目的を取り扱う。コマンドは、パーサに読み込まれたルールの後続部分をどう処すべきかを、 iptables に伝える。通常、テーブルなどに対して何かを追加あるいは削除する操作を指令する。 iptables では以下のコマンドが利用可能だ:
Table 9-2. コマンド
| コマンド | -A, --append |
| 例 | iptables -A INPUT ... |
| 説明 | チェーンの最後尾にルールを追加する。つまり、このコマンドでは必ずルールセットの最後尾にそのルールが追加され、さらにルールを追加しない限り、テストの順位も最後となる。 |
| コマンド | -D, --delete |
| 例 | iptables -D INPUT --dport 80 -j DROP, iptables -D INPUT 1 |
| 説明 | ひとつのルールをチェーンから削除する。これには書き方が 2種類ある。合致すべきルールの全文を示す (最初の例) か、ルールナンバーで指定するかだ。前者を使用する場合、記述する定義と、チェーンにおけるエントリは、正確に一致していなくてはならない。後者では、削除したいルールのナンバーを一致させればよい。ルールのナンバーはチェーン毎に頭から振られ、1 から始まる。 |
| コマンド | -R, --replace |
| 例 | iptables -R INPUT 1 -s 192.168.0.1 -j DROP |
| 説明 | 指定した行にある既存のルールを置き換える。 --delete コマンドと同じ動作を行うが、ただ単にそのエントリを削除するだけでなく、それを新たなエントリで置き換える。 iptables の組み立てを思考錯誤している最中に利用する機会が多いだろう。 |
| コマンド | -I, --insert |
| 例 | iptables -I INPUT 1 --dport 80 -j ACCEPT |
| 説明 | チェーンの中途にルールを挿入する。ルールはナンバーで指定した箇所に割り込む。つまり、上記の例は INPUT チェーンの 1 番目にルールを挿入し、結果としてそのルールがチェーンの最初のルールとなる。 |
| コマンド | -L, --list |
| 例 | iptables -L INPUT |
| 説明 | このコマンドは指定したチェーンのすべてのエントリをリストアップする。上記の場合 INPUT チェーンのエントリすべてを列挙する。チェーンをまったく指定しないやり方も反則ではなく、この場合には、所定のテーブル内にあるすべてのチェーンの内容をリストアップする (テーブルの指定方法は テーブル セクションを参照)。出力の詳細はパーサに与える -n や -v などといったオプションによって変わる。 |
| コマンド | -F, --flush |
| 例 | iptables -F INPUT |
| 説明 | このコマンドは指定したチェーンからすべてのルールをフラッシングする。ルールをひとつずつ削除していくのと意味は同じだが、こちらのほうがてきめんに迅速だ。このコマンドにオプションは必要なく、所定のテーブル内に存在するチェーンの全ルールがを削除される。 |
| コマンド | -Z, --zero |
| 例 | iptables -Z INPUT |
| 説明 | このコマンドは指定したチェーンまたは全チェーンにおける、全カウンタをゼロに戻すよう iptables に命令する。 -L コマンドで -v オプションを使うと各フィールドの頭にパケットカウンタがつくのを憶えているだろう。このパケットカウンタをゼロリセットしたいときに使うのが -Z だ。 -Z はルールのリストアップこそしないが、 -L と同様の動作を行う。 -L と -Z を同時に用いた場合 (これも反則ではない)、まずチェーンがリストアップされ、その後パケットカウンタがゼロリセットされる。 |
| コマンド | -N, --new-chain |
| 例 | iptables -N allowed |
| 説明 | このコマンドは、指定したテーブルに指定した名称の新しいチェーンを作成するよう、カーネルに指令する。上の例では allowed という名のチェーンを作成している。既に同名のチェーンやターゲットが存在してはならないという点に注意しなければならない。 |
| コマンド | -X, --delete-chain |
| 例 | iptables -X allowed |
| 説明 | 指定したチェーンをテーブルから削除する。このコマンドが成功するには、削除対象になるチェーンを参照しているルールが存在してはならない。つまり、チェーンを削除するには、前もって、そのチェーンを参照しているルールすべてを置換または削除しておく必要がある。このコマンドをオプションなしで使用した時には、対象のテーブルにあるビルトイン以外のチェーンがすべて削除される。 |
| コマンド | -P, --policy |
| 例 | iptables -P INPUT DROP |
| 説明 | このコマンドは、或るチェーンに対してのデフォルトターゲットつまりポリシーを設定するよう、カーネルに指示する。どのルールにもマッチしなかったパケットは、チェーンに設定されたポリシーに従わせられる。指定可能なターゲットは DROP と ACCEPT だ (他にもあるかもしれない -- 見つけたらメールしてほしい)。 |
| コマンド | -E, --rename-chain |
| 例 | iptables -E allowed disallowed |
| 説明 | -E コマンドは、第1引数の名前を持つチェーンを、第2引数の名前に改名する。つまり上の例では、チェーンの名前を allowed から disallowed に変えていることになる。これは当該テーブルの振舞いを実質的に変ているわけではない。つまり、テーブルに対する見た目上の変更に過ぎないということに気を付けてほしい。 |
コマンドラインは必ず、最後まで 1 行で入力しなければならない。でなければ、 iptables のビルトインヘルプかコマンドのバージョンを見せられることになるだろう。バージョンを表示させたいのなら -v オプションがあるし、ヘルプメッセージを出すには -h オプションがある。つまり、とりわけ iptables に限ったオプションではない。次に、コマンド毎に異なるいくつかのオプションを挙げておこう。下記では、どのオプションがどのコマンドで有効で、どう作用するかを解説している。なお、ここで挙げているのは、ルールやマッチに影響しないオプションだけだ。マッチとターゲットについては、このセクションの後半に預けることにしよう。
Table 9-3. オプション
| オプション | -v, --verbose |
| 利用対象コマンド | --list, --append, --insert, --delete, --replace |
| 説明 | このコマンドは出力を冗長 (verbose) にするために使用され、よく --list コマンドと併用する。 --list コマンドと一緒に使用した場合、インターフェースアドレス、ルールオプション、 TOSマスクも表示される。 --verbose オプション付きの --list コマンドはまた、ルール毎のバイトおよびパケットカウンタも表示する。カウンタには、 K (x 1,000), M (x 1,000,000), G (x 1,000,000,000) の単位記号が適宜使用される。これを避けるには、下記に述べる -x オプションを使う。 --verbose オプションを --append, --insert, --delete, --replace コマンドに使用すると、指示したルールがどう解釈されたかの内容と、挿入などが正常に行われたかどうかといった事柄が表示される。 |
| オプション | -x, --exact |
| 利用対象コマンド | --list |
| 説明 | このオプションは数字を展開して見せる。つまり、 --list の出力は K, M, G の単位記号を含まなくなる。問題とするルールにマッチした累計パケット数とバイト数のカウンタ値が、文字通りの数字で表されるのだ。このコマンドは --list コマンドでのみ利用可能で、それ以外どのコマンドにもまったく効き目がないことに注意してほしい。 |
| オプション | -n, --numeric |
| 利用対象コマンド | --list |
| 説明 | このオプションは、値を数字で表示するよう iptables に指示する。 IPアドレスとポートナンバーは、ホスト名、ネットワーク名、アプリケーション名などでなく、数字で表現される。これは --list コマンドでのみ有効。デフォルトでは数字とホストは可能な限りリゾルブされるが、それを抑止するのがこのオプションだ。 |
| オプション | --line-numbers |
| 利用対象コマンド | --list |
| 説明 | --list コマンドとともに使用し、出力に行番号を表示させる。このオプションを使うと、各ルールが行番号付きで出力される。ルールの挿入時には、ルールのナンバーが分かるとありがたいものだ。このオプションは --list コマンドでしか機能しない。 |
| オプション | -c, --set-counters |
| 利用対象コマンド | --insert, --append, --replace |
| 説明 | このオプションは、何らかの形でルールを作成や変更する場面で用いる。その際に、パケットとバイトのカウンタ値を指定の値へと変更できる。書式は --set-counters 20 4000 のようになり、この場合、パケットカウンタを 20 に、バイトカウンタを 4000 にセットするよう、カーネルに指示していることになる。 |
| オプション | --modprobe |
| 利用対象コマンド | すべて |
| 説明 | --modprobe オプションは、カーネルに対して、モジュールの探索 (probe) が必要になった時にどのモジュールを使うべきか伝えるのに利用する。これは、 modprobe コマンドがサーチパス外にある場合に活用するとよい。そうしたケースでは、このオプションを使って、必要なモジュールがロードされていない場合にどうすべきかをプログラムに教えてやる必要があるからだ。このオプションはすべてのコマンドで利用可能だ。 |
9.4. まとめ
このチャプターでは iptables の基本的なコマンドと、netfilter で利用可能なテーブルについて手短に説明してきた。ご覧いただいたように、これらのコマンドを使えば、カーネルにロードされた netfilter パッケージに対して多岐にわたる様々な操作を行うことができる。
次のチャプターでは iptables 及び netfilter で利用可能な全てのマッチを取り上げる。非常にヘビーで長い章だ。しかし、ひとつのご進言として申し上げるとするなら、使いたいものだけ見ればいいのであって、全部のマッチを熟読していく必要はない。どんなことをするマッチがあるのか、ざっと目を通しておいて、必要な時が来たら必要なマッチだけしっかり読み込む、というのもひとつの手だ。
Chapter 10. iptablesのマッチ
このチャプターでは、マッチについて掘り下げる。僕はマッチを 5 つのサブカテゴリーに分類することにした。最初に扱うのが 汎用的なマッチ (generic matches) で、これはあらゆるルールに使用できる。次は、 TCP パケットにだけ用いる TCPマッチ。 UDP パケットにだけ用いる UDPマッチ 、それに、 ICMP パケットにだけ使用できる ICMPマッチ。そして最後に、 state, owner, limit マッチなどの特殊なマッチを扱う。最後のグループに含まれるマッチは、必ずしも互いに区別されるべきものではないのだが、さらに数個のサブカテゴリーに細分化することにした。これが理にかなった分類であり、皆さんの理解の助けになることを願うばかりだ。
前のチャプターを読んだ人ならもうお分かりだと思うが、マッチとは、パケット内に見られる真 (あるいは偽) であるべき某かの条件を指定するものだ。ひとつのルールは複数のマッチを持つことができる。例を示そう。実際にありそうなケースとして、身内のローカルエリアネットワーク内の特定のホストの出したパケットで、なお且つ、そのホスト上の特定のポートから発したパケットをマッチさせたい場合を考える。この場合、特定の送信元アドレスを持ち、 LAN とつながっているインターフェイスを通じて届き、なお且つ、指定したポート群のうちのいずれかに一致するパケットだった時にだけ、ターゲット (つまりジャンプ定義) を適用せよ、という指示を行うマッチを使用する。もしも、このルールの中のマッチがひとつでも一致し損なえば (例えば、他の全ての条件は満たしているが送信元アドレスだけが違っていた場合)、このルールそのものが不一致ということになり、パケットは次のルールの試験へ引き渡される。かたや、マッチが全て満たさされる場合には、ルール中で指定したターゲットが適用される。
10.1. 汎用的なマッチ
このセクションでは汎用的なマッチ を取り扱う。汎用的なマッチは、扱うプロトコルが何であろうと、どんなマッチ拡張をロードしていようと、常に利用可能なマッチだ。マッチの利用に際して特別なパラメータも一切必要としない。僕は、この仲間に、プロトコルのマッチに関わるやや特別なものではあるが --protocol マッチも含めることにした。理由はこうだ。 TCPマッチ を使おうとする場合には、 --protocol マッチを用い、さらにそのオプションとして TCP を指定しなければならない。だが、 --protocol は、特定のプロトコルをマッチさせるという単独のマッチとしても存在しているのだ。常に利用可能なマッチには、以下のものがある。
Table 10-1. 汎用的なマッチ
| マッチ | -p, --protocol |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp |
| 説明 | このマッチは、特定のプロトコルを検出するために用いられる。プロトコルとは TCP, UDP, ICMP といったものだが、内部的に定義済みのプロトコルである TCP, UDP, ICMP のみを指す場合もある。 /etc/protocols ファイルで定義されたプロトコルも引数に採れるが、指定したプロトコルがファイルに見つからない場合にはエラーを返す。また、プロトコルは数字で指定することもできる。例えば ICMP プロトコルの値は 1、 TCP は 6、 UDP は 17 だ。更に、ALL を採ることもできる。ALL は TCP, UDP, ICMP の 3つだけをマッチさせることを意味する。コマンド引数にカンマ区切りのプロトコルリストを採ることもでき、例えば udp,tcp は UDP および TCP のすべてパケットにマッチする。引数に数字のゼロ (0) を与えると ALL の意味となり、それはつまり --protocol マッチをはなから使用しなかった時のデフォルトの動作でもある。マッチは ! 記号で否定することも可能で、つまり --protocol ! tcp は UDP と ICMP を見つけることを意味する。 |
| マッチ | -s, --src, --source |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -s 192.168.1.1 |
| 説明 | これはパケットを送信元の IPアドレスに基づいて判定する送信元 (source) マッチだ。基本形は 192.168.1.1 のように IPアドレスをひとつだけ合致させるのに使う。 CIDR のビット形式 (ネットマスクビットにおいて左側に連続する 1 の個数) によって、ネットマスクも指定することもできる。つまり、例えば 255.255.255.0 のネットマスクを使用するには /24 を付け足せばよい。この方法で、ファイヤーウォールの内側のローカルネットワークやネットワークセグメントなどといった IP領域を根こそぎマッチさせることが可能だ。その際の表現は 192.168.0.0/24 のようになり、これは 192.168.0.x で括られるすべてのパケットにマッチする。ネットマスクを指定するもうひとつ方法は、通常の 255.255.255.255 形式 (例えば 192.168.0.0/255.255.255.0) だ。前の TCPマッチと同様に、 ! でマッチを否定することもできる。つまり、 --source ! 192.168.0.0/24 と指定すれば、 192.168.0.x の領域を送信元アドレスとしない すべてのパケットにマッチさせることができる。デフォルトでは、すべての IPアドレスにマッチする。 |
| マッチ | -d, --dst, --destination |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -d 192.168.1.1 |
| 説明 | --destination マッチは、複数または単一の宛先アドレスに基づいてパケットをマッチさせるのに用いる。 --source マッチとほとんど同様の動作を行い、書式も同じで、ただ、評価基準がパケットの行き先である点が異なるだけだ。 IPを範囲でマッチさせるには、ネットマスクを、文字通りのネットマスク方式か、ネットマスクビットの 1 を左側から数えた個数の、いずれかで指定する。例を挙げるとそれぞれ、 192.168.0.0/255.255.255.0 と 192.168.0.0/24 となる。ふたつは同義だ。前のマッチと同じく、マッチ全体を ! で反転させることもできる。つまり、 --destination ! 192.168.0.1 とすれば、 IPアドレス 192.168.0.1 以外 に宛てられたすべてのパケットにマッチする結果となる。 |
| マッチ | -i, --in-interface |
| カーネル | 2.3, 2.4, 2.5 and 2.6 |
| 例 | iptables -A INPUT -i eth0 |
| 説明 | これはパケットの入ってくるインターフェースに基づいてマッチを行う。このマッチは INPUT, FORWARD, PREROUTING チェーンでのみ有効であり、その他で使用するとエラーメッセージが返ってくるという点に注意しよう。どのインターフェースも指定しない時のこのマッチのデフォルト動作は、文字としての値 + を指定したものとして扱われる。 + は、文字または数字から成る任意の文字列を表す。つまり単独の + は、カーネルに対して、どのインターフェースから入って来るかにかかわらず、すべてのパケットを合致させよと指示することになる。 + 記号はインターフェースのタイプに付加して使用することも可能で、例えば eth+ ならすべてのイーサネットデバイスを表す。 ! 記号の助けを借りて、意味を逆転することも可能だ。その場合の記述は -i ! eth0 のような書き方となり、これは eth0 を除いたすべてのインターフェースにマッチする。 |
| マッチ | -o, --out-interface |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A FORWARD -o eth0 |
| 説明 | --out-interface マッチはパケットが出て行こうとするインターフェイスに基づいてパケットをマッチさせるのに用いる。注意は、 --in-interface とは逆に OUTPUT、FORWARD、POSTROUTING チェーンにしか使えないということだ。この点を除いては、 --in-interface マッチとまったく同様に働く。 + による拡張は、同一タイプのインターフェースすべてに合致すると解釈され、 eth+ ならすべての eth デバイスにマッチするといった具合だ。マッチの意味合いを反転するには、 --in-interface とまったく同様に ! 記号が使用できる。 --out-interface を指定しなかった場合のこのマッチのデフォルト動作は、パケットがどこから出て行くかにかかわらずすべてのデバイスにマッチする。 |
| マッチ | -f, --fragment |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -f |
| 説明 | このマッチは、フラグメンテーションされたパケットの 2番目や 3番目のパケットにマッチさせる時に使用する。これが必要になるのは、パケットがフラグメンテーションされていた場合、後続フラグメントでは、送信元ポートや宛先ポート、 ICMPタイプなど諸々を判定する術がないからだ。フラグメンテーションしたパケットは、非常に希にだが、他のコンピュータへの攻撃に悪用されることもある。しかしパケットフラグメントは他のいかなるルールでも検出不可能。それ故にこのマッチが考案された。このオプションも ! と併用することができる。ただし今回は、 ! -f のように、 ! はマッチの前に付けなければならない。 --fragment マッチが反転された場合には、ヘッダフラグメントか、フラグメンテーションしていないパケットを検出する。つまり、フラグメンテーションしたパケットの先頭パケットにはマッチし、2番目、3番目のパケットなどにはマッチしないということになる。また、搬送経路上でフラグメンテーションされなかったすべてのパケットにもマッチする。ただし、カーネル自体にも、これの代わりに利用可能な非常に優れたフラグメンテーションオプションが用意されていることを覚えておこう。もうひとつの註は、コネクション追跡を使用している場合には、フラグメンテーションはパケットが iptables のテーブルやチェーンに到達する前に処置されるため、フラグメンテーションパケットに出会う可能性は皆無だということだ。 |
10.2. 暗黙的なマッチ
このセクションでは、暗黙的にロードされるマッチを取り扱う。暗黙的なマッチ (implicit match) は、暗示された、存在が前提的自動的に認められたマッチだ。例えば、 --protocol tcp によるマッチをその他の評価基準なしで行う場合などが当てはまる。現在のところ、 iptables は 3つのプロトコルに対応する 3種類の暗黙的マッチを備えている。 TCPマッチ、 UDPマッチ、 ICMPマッチ だ。 TCP ベースのマッチには、 TCP パケットでのみ有効な特有の評価基準がある。 UDP ベースのマッチでは、 UDP パケットにのみ利用可能な、また別の評価基準がある。 ICMP パケットにもまた同じことが言える。これに対して、明示的にロードしなくてはならない、明示的なマッチがあってもおかしくない。明示的なマッチ (explicit match) は、暗黙的でない、自動的でないマッチで、使用したければ明確に指定する必要がある。その際に使うのが -m または --match オプションだが、それについては次のセクションで詳述することにしよう。
10.2.1. TCPマッチ
これらのマッチはプロトコル固有で、 TCP パケットおよび TCP ストリームを取り扱う場合にのみ有効だ。このマッチを使用するには、コマンドライン上の、これらを使用する前で --protocol tcp を指定しなければならない。念を押しておこう。 --protocol tcp は必ず、特定のプロトコルマッチよりも左側に置く必要がある。これらのマッチは、 UDPマッチ と ICMPマッチ がそうであるように、ある意味、暗黙的にロードされる。 UDP および ICMPマッチについては、 TCPマッチ の後に続くセクションで目を通す。
Table 10-2. TCPマッチ
| マッチ | --sport, --source-port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp --sport 22 |
| 説明 | --source-port マッチは、その送信元ポートに基づいてパケットを一致させるのに使われる。このマッチを指定しない時には、すべての送信元ポートを暗に合致させていることになる。後ろにはサービス名かポートナンバーを採る。サービス名を指定した場合、そのサービス名は /etc/services ファイルに載っていなければならない。 iptables はこのファイルを検索するからだ。ポートをポートナンバーで指定したほうが、 iptables はサービス名をチェックする必要がなくなるため、ルールのロードはわずかながら速い。しかし、サービス名を使用するのに比べてルールセットはやや読みにくくなる。 200個以上のルールから成るルールセットを書くなら、速度の違いは顕著になるので、迷うことなくポートナンバーのほうを使うべきだ。 (遅いサーバで 1,000 以上のルールを含むような巨大なルールセットを組んだ場合、 10秒単位の差が出ることも珍しくない)。 --source-port 22:80 といった具合に、 --source-port マッチにポートの範囲を使うことも可能だ。この例は 22 から 80 までのポートにマッチする。最初のポートを省略すると、(暗黙的に) ポート 0 として解釈される。 --source-port :80 はポート 0 から 80 にマッチする。また、最後のポートが省略されると、ポート 65535 として解釈される。ポート範囲をひっくり返した場合には、 iptables が自動的に再逆転して元に戻す。もし --source-port 80:22 と書けば、単純に --source-port 22:80 として解釈される。また、 ! 記号を加えることによってマッチを反転させることもできる。例えば --source-port ! 22 は、ポート 22 以外のすべてのポートに一致する。反転はポート範囲との併用も可能で、即ち --source-port ! 22:80 のような記述となり、この例は 22 から 80 までを除く全ポートにマッチさせたいということを表している。注意としては、このマッチは離ればなれのポートとポートや、複数の範囲を扱うことができない。そうした利用について知りたいなら、マルチポート(multiport) マッチ拡張を見てみてほしい。 |
| マッチ | --dport, --destination-port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp --dport 22 |
| 説明 | このマッチは TCP パケットを宛先ポートによってマッチさせる。文法は --source-port マッチとまったく同じだ。ポートやポート範囲の指定はもちろん、反転も通用する。また同様に、ポート範囲指定における高低の入れ替えも働く。早い話が --source-port の文法と瓜二つだ。注意としては、このマッチは離ればなれのポートとポートや、複数の範囲を扱うことができない。そうした利用について知りたいなら、マルチポート(multiport) マッチ拡張を参照してほしい。 |
| マッチ | --tcp-flags |
| カーネ | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -p tcp --tcp-flags SYN,FIN,ACK SYN |
| 説明 | このマッチは、TCP のフラグでパケットをマッチさせるのに利用する。これはふたつの引数を取り、まず最初の引数では検討するフラグのリスト (マスク)、そして 2番目で、"1" にセットされているべき (ON になっている) フラグのリストを指定する。ふたつのリストはともにカンマ区切りだ。このマッチに理解できるのは SYN, ACK, FIN, RST, URG, PSH のフラグであり、加えて ALL と NONE という語彙も理解する。 ALL と NONE は読んで字の如しだが、 ALL はこのオプションに対してすべてのフラグを指定し、 NONE はどのフラグも指定しないことに通じる。つまり、 --tcp-flags ALL NONE は、 TCP フラグすべてを確認して、そのどれひとつとしてセットされていなければマッチするということだ。このオプションは ! 記号で反転することも可能で、例えば ! SYN,FIN,ACK SYN と指定すれば、ACK ビットと FIN ビットは立っているが SYN ビットの立っていないパケットに合致するマッチを作ることができる。カンマ区切りのリストの中にホワイトスペースを入れてはいけないことに注意しよう。正しい文法は上記の用例で分かるだろう。 |
| マッチ | --syn |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -p tcp --syn |
| 説明 | --syn マッチは ipchains 時代からの遺物の類で、下位互換性と、 ipchains から、あるいは ipchains への移行を容易にするために未だ残されている。もし SYN ビットが立ち ACK ビットと RST ビットが立っていなければ、そのパケットにマッチする。つまり、 --tcp-flags SYN,RST,ACK SYN というマッチと同義だ。このようなパケットは、主として、新しい TCP コネクションをサーバに要求する時に使われる。これらのパケットをブロックすれば、外から接続して来ようとする企てを見事にブロックする効果が得られる。とはいうものの、あなたはまだ外へ出ていくコネクションはブロックしていないだろう。昨今、数々の不正侵入によく使われるのが外へのコネクションなのだ (例えば、正規のサービスをハッキングして何らかのプログラムに類するものをインストールしてから、新たなポートを開けるのではなく既存のコネクションを利用して、あなたのホストへの接続を導き入れるなど)。このマッチは ! --syn のように ! 記号による反転も可能で、これは RST か ACK ビットの立ったパケット、つまり、確立済み (established) のコネクションにマッチする。 |
| マッチ | --tcp-option |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -p tcp --tcp-option 16 |
| 説明 | このマッチはパケットの TCPオプション によるマッチに利用される。 TCPオプションとは、ヘッダの中の特別な部分だ。このヘッダ部位は、意味合いの異なる 3つのフィールドで構成されている。最初のフィールドは 8ビット長で、そのストリームでどんなオプションを使用しているかを告げる。 2番目のフィールドは、やはり 8ビット長だが、オプションフィールドの長さを知らせている。長さを示すフィールドがなぜ必要なのかといえば、 TCPオプションはそもそも存在自体が任意だからだ。すべてのオプションをサポートしていなくても、規格違反というわけではない。だから、パケットに使用されているのがどのオプションかを調べて、それがこちらのサポート外だったら、そのデータを読み飛ばしても構わないのだ。このマッチは、オプションを数字で表した値を使って、様々な TCPオプションをマッチさせる。 ! 記号で反転することも可能で、その場合のマッチは、指定した以外の TCPオプションに合致する。オプションの完全なリストを見たければ Internet Engineering Task Force を参照のこと。 IETF はインターネットで使用される数字規格を管理している団体だ。 |
10.2.2. UDPマッチ
このセクションでは、UDP パケットとの組み合わせでのみ機能するマッチについて述べる。これらのマッチは --protocol UDP を指定することによって暗黙的にロードされ、利用が可能となる。忘れてはならないのは、 UDP パケットがコネクション指向のプロトコルではないという点だ。よって UDP パケットは、コネクションを開きたいのか閉じたいのか、あるいは単にデータを送ろうとしているのかといったデータグラムの目的に応じて、パケットに立てるフラグを区別したりはしない。そればかりか、 UDP パケットはいかなる種類の了解 (acknowledgement) も行わない。パケットが消失したら、ただ消失されっぱなしだ (ICMPエラーメッセージなどは考慮に入れないとしての話)。以上のことから、 UDP パケットで機能するマッチは TCP パケットに比べてはるかに少なくなる。ただし、ステート機構は、 UDP や ICMP といった非コネクション指向のプロトコルであっても、すべての種類のパケットに対して機能する。ステート機構は UDP パケットに対しても TCP パケットとまったく同様に機能するのだ。
Table 10-3. UDPマッチ
| マッチ | --sport, --source-port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p udp --sport 53 |
| 説明 | このマッチは TCP版 とまったく同様に働く。送信元 UDP ポートに基づいてパケットのマッチを行うのに使用する。ポートの範囲、単一のポート、意味の反転も、同様の書式でサポートされている。 UDP ポートの範囲を指定するには、22:80 とすればよく、これは UDP の 22 から 80 番ポートにマッチする。初めの値を省略すると、ポート 0 と解釈、後ろの値を省略すれば 65535 と解釈される。数字の大きいポートが若いポートより前に指定されていた場合には、前後のポートは自動的に入れ替わる。単一UDP ポートによるマッチは上記の例に見る通りだ。ポートマッチを逆転するには ! 記号を使い、 --source-port ! 53 のように書く。これはポート 53 以外のすべてのポートにマッチする。このマッチは /etc/services に記載があるものに限っては、サービス名も理解する。なお、このマッチは離ればなれのポートとポートや、複数の範囲を扱うことができない。そうした利用について知りたいなら、マルチポート(multiport) マッチ拡張を見てほしい。 |
| マッチ | --dport, --destination-port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p udp --dport 53 |
| 説明 | 前記の --source-port と同じことがこのマッチにも当てはまる。 UDP パケットに用いられるということ以外では、 TCP における同一機能のマッチと完全に同じだ。このマッチは UDP の宛先に基づいてパケットマッチを行う。ポートの範囲、単一ポート、意味反転を扱うことができる。単一のポートに使うには --destination-port 53 のように用い、反転するには --destination-port ! 53 などとすればよい。ひとつ目のマッチはポート 53 に宛てられたすべてのパケットにマッチし、2番目の例はポート 53 へ向かおうとするもの以外のパケットにマッチする。ポートの範囲を指定するには --destination-port 9:19 のように用いる。この例は UDP の 9 から 19 までを宛先とするすべてのパケットに合致する。初めのポートが省略されれば、ポート 0 と了解され、2番目が省略されればポート 65535 と解釈される。数字の大きいポートが若いポートより前に指定されていた場合には、自動的に入れ替えられ、若いほうのポートが数字の大きいポートの前に繰り込まれる。なお、このマッチは離ればなれのポートとポートや、複数の範囲を扱うことができない。そうした利用について知りたいなら、マルチポート(multiport) マッチ拡張を見ていただきたい。 |
10.2.3. ICMPマッチ
ICMP にもいくつかのマッチがある。 ICMP パケットは、コネクションレスであるという面で UDP にも増して生存時間が短い、つまり短命だ。 ICMP プロトコルは主に、エラー通知やコネクションコントロールに類する事柄に使われる。 ICMP は、 IPプロトコルの構成要素というよりも、どちらかといえば IP プロトコルを補強する プロトコルとしての性格が強く、エラー担当という役目で IPプロトコルを補佐している。 ICMP パケットのヘッダは IPヘッダ と非常に似通っているものの、いくつかの点において違いがある。その最も特徴的なものが、タイプヘッダだ。これはパケットの目的を表す。ひとつの例を挙げると、アクセス不能の IPアドレスにアクセスしようとした場合、我々は通常、入れ違いに ICMP host unreachable を受け取る。 ICMP タイプの完全なリストが知りたければ、付録 ICMPタイプ を見ていただきたい。 ICMP パケットで利用可能な特有のマッチは 1種類しかないが、たいていはそれだけで事足りる。このマッチは --protocol ICMP を使用した際に暗黙的にロードされ、自動的に利用可能となる。ただし、汎用的なマッチ は ICMP にも使用でき、それによって送信元アドレスや宛先アドレスなどによるマッチも行うことができる。
Table 10-4. ICMPマッチ
| マッチ | --icmp-type | ||
| カーネル | 2.3, 2.4, 2.5, 2.6 | ||
| 例 | iptables -A INPUT -p icmp --icmp-type 8 | ||
| 説明 | このマッチは、合致すべき ICMPタイプ を指定して利用する。 ICMPタイプ は数値でも名称でも指定可能だ。数値は RFC 792 に規定されている。名称での ICMP 値の完全なリストを得るには、 iptables --protocol icmp --help するか、付録 ICMPタイプ を参照のこと。マッチは --icmp-type ! 8 という具合に ! 記号で反転することも可能だ。いくつかの ICMPタイプ は時代遅れで使われなくなっており、他の幾つかのタイプはまた、パケットをお門違いの場所へリダイレクトするなどといった作用も起こしかねないので、きちんと防御していないホストにとって "脅威" とも成り得るという点に注意が必要だ。なお、タイプとコードは、タイプ名称、タイプ番号で書く以外に、 type/code の形で指定することもできる。例えば --icmp-type network-redirect や, --icmp-type 8 や, --icmp-type 8/0 といった具合だ。指定できる名称の全リストは iptables -p icmp --help で得られる。
|
10.2.4. SCTPマッチ
SCTP つまり Stream Control Transmission Protocol は、 TCP や UDP プロトコルに比べると登場して日の浅いネットワークプロトコルだ。SCTP については SCTPの特徴 のチャプターでもっと詳しく述べる。暗黙的な SCTP マッチは iptables コマンドラインに -p sctp を加えた時にロードされる。
SCTP は大手の通信系及びスイッチ/ネットワーク機器メーカー数社によって開発されたプロトコルで、高スループットと信頼性を確保しながら相当数の同時並行トランザクションを成り立たせなければならないような環境に向いている。
Table 10-5. SCTPマッチ
| マッチ | --source-port, --sport |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -p sctp --source-port 80 |
| 説明 | --source-port マッチは SCTP パケットヘッダの送信元ポートに基づいて SCTP パケットをマッチさせるのに使う。ポートには、例に示したように単一のポートを指定することも、 --source-port 20:100 のように範囲で指定したり、 ! マークによって意味を反転させることもできる。最後の形式は例えば --source-port ! 25 といった具合になる。送信元ポートに指定できるのは符号なしの 16ビット数値、つまり最大値は 65535、最小値は 0 ということになる。 |
| マッチ | --destination-port, --dport |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -p sctp --destination-port 80 |
| 説明 | このマッチは SCTP パケットの宛先に対してマッチを行う。 SCTP パケットはもれなく、そのヘッダに、送信元ポートと並んで宛先のポート情報も持っている。ポートは、例のように指定したり、ポート範囲で --destination-port 6660:6670 のように指定することができる。また、--destination-port ! 80 のように ! マークで反転することもで、この例ならポート 80 以外にマッチすることになる。ポートの値に関しては送信元の場合と同様で、最大値 65535、最小値は 0。 |
| マッチ | --chunk-types |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -p sctp --chunk-types any INIT,INIT_ACK |
| 説明 | SCTP パケットのチャンク (chunk) タイプによるマッチを行う。現在のところ、チャンクタイプにはかなりの種類がある。詳しくは下記を参照いただきたい。マッチは --chunk-types キーワードで始まり、続いて、どうマッチさせるかを表す all, any または none のフラグ。その後ろに マッチさせたい SCTPチャンクタイプ を指定する。チャンクタイプの種類は下記の表に別記した。 フラグには、追加パラメータとして チャンクフラグ を付加することもできる。例えば --chunk-types any DATA:Be という指定になる。フラグは SCTPチャンクタイプ 毎に異なり、当該のチャンクに対して有効なものでなければならない (別表に示す)。 フラグを大文字で書いた場合には、それがセットされたパケットに対してマッチは真となり、小文字の場合はセットされていない時に真となる。--chunk-types キーワードの手前に ! 記号を置くとマッチ全体の意味を反転させることができる。例えば --chunk-types ! any DATA:Be は、そのパターンを除いた全てのものにマッチする。 |
下記に示したのが --chunk-types マッチの認識する全ての チャンクタイプ のリストだ。見ての通り膨大な数だが、通常用いられるのは概ね DATA パケットと SACK パケット程度である。その他のものは主にアソシエーションの制御に用いられる。
--chunk-typesで使用できるSCTPチャンクタイプ
ABORT
ASCONF
ASCONF_ACK
COOKIE_ACK
COOKIE_ECHO
DATA
ECN_CWR
ECN_ECNE
ERROR
HEARTBEAT
HE ARTBEAT_ACK
INIT
INIT_ACK
SACK
SHUTDOWN
SHUTDOWN_ACK
SHUTDOWN_COMPLETE
前述した、--chunk-types マッチで使用できるフラグの種類が下記。 RFC 2960 - Stream Control Transmission Protocol の規定によると、これ以外のフラグは予約済みか使用されていないかのどちらかとなっており、必ず 0 でなければならない。ありがたいことに、今のところ iptables はそれを強要する何らの仕組みも持っていない。かつて IP プロトコルに ECN が実装された時の二の舞となりかねないからだ。
--chunk-typesで使用できるチャンクフラグ
DATA - U または u :Unordered bit, B または b :Beginning fragment bit, E または e :Ending fragment bit
ABORT - T または t :TCB destroy flag
SHUTDOWN_COMPLETE - T または t :TCB destroyed flag
10.3. 明示的なマッチ
明示的なマッチ は、-m あるいは --match オプションではっきりとロードする必要のあるマッチだ。例えばステートマッチは、実際に使用したいマッチに先立って -m state ディレクティブ (命令句) を必要とする。この仲間には、プロトコル特有のマッチも幾つかある。また或るものは、プロトコルの種別とは一切無関係 -- 例えばコネクションステートがそうだ。コネクションステートとは NEW (まだ確立していない接続の最初のパケット)、 ESTABLISHED (既にカーネルに記録されている接続)、 RELATED (既存の確立済み接続に関連した接続) などといったものだ。さらに、ごく一部のマッチには、開発途上か実験的だったり、ただ単に iptables の可能性をデモンストレーションする目的で書かれたものもある。そうしたことから、一見しただけではいったい何に使ったらいいのか分からないマッチも存在するのだが、もしかすると、あなた自身がその有効な活用法を発見するかもしれない。さらには、 iptables の新しいリリース毎に、次々と新しいマッチが登場してくる。活用法が見いだせるかどうかは、あなたの創造力とニーズ次第だ。暗黙的なマッチ と 明示的なマッチ との違いは、暗黙的なマッチ 、例えば TCP パケットの性状に基づいてマッチを行うような場合には、そのマッチは自動的にロードされるが、明示的にロードする必要のあるマッチでは、自動的なロードは行われないという点だ。明示的マッチ の発見と活用は、あなたの腕に掛かっている。
10.3.1. Addrtypeマッチ
addrtype モジュールはパケットのアドレスタイプに基づいたマッチを行う。このアドレスタイプを基準にしてカーネルがパケットの分類を行う。このマッチを使えば、カーネルの保持しているアドレスタイプ情報に基づいてパケットをマッチさせることができるわけだ。注意しなければならないのは、アドレスタイプの意味がレイヤー3 のプロトコル毎に異なるという点だ。ここでも概要は述べるが、 Linux Advanced Routing and Traffic Control HOW-TO や Policy Routing using Linux でもっと詳しく読んでおいたほうがいい。利用できるタイプには以下のものがある:
Table 10-6. アドレスタイプ
| Type | 意味 |
|---|---|
| ANYCAST | これは 1対多の関係にあるコネクションであり、実際にデータを受信するのはその多数の受信ホストのうちひとつだけだ。この実装のひとつに DNS が挙げられる。ルートサーバは通常ひとつのアドレスで示すが、実際のルートサーバは複数のロケーションを指しており、パケットは直近のサーバひとつへ誘導されることになる。Linux の IPv4 には実装されていない。 |
| BLACKHOLE | ブラックホールアドレスはパケットをただひらすら破棄し、返答も返さない。おおよそ宇宙のブラックホールと同じだ。これは Linux のルーティングテーブルで設定される。 |
| BROADCAST | ブロードキャストパケットは、ひとつのパケットが 1対多の関係でネットワーク内の全員に送られるタイプのもの。 ARP 解決 (ARP resolution) がその一例で、或る IP への到達路を問い合わせるひとつのパケットが送信されると、我こそはというひとつのホストが然るべき MAC アドレスを回答する。 |
| LOCAL | 我々の今操作しているホスト自体のローカルなアドレス。例えば 127.0.0.1。 |
| MULTICAST | マルチキャストパケットは、最短の距離経路 (distance) を使って複数のホストへ向けて送信される。それぞれの中継地点 (waypoint) へは単一のパケットだけが送られ、そこで特定のマルチキャストアドレスに加入しているホストやルータの分だけ複製して送られる。ビデオやサウンドなど、一方通行のストリーミングメディアに使用されることが多い。 |
| NAT | カーネルによって NAT されたアドレス。 |
| PROHIBIT | blackhole と同じだが、「禁止されている」という返答を発生させる点が異なる。 IPv4 において言うならば、この返答は ICMP communication prohibited (タイプ 3, コード 13) となる。 |
| THROW | Linux カーネルの持つ特殊なルート。ルーティングテーブルでパケットが throw されると、そのパケットは、ルートが見つからなかった時と同じ挙動をする。通常のルーティングでは、ルートがなかったかのように振る舞うことになる。ポリシールーティングにおいては、他のルーティングテーブルを検索して別のルートが割り出される場合もある。 |
| UNICAST | ひとつのアドレスだけを指す正真正銘のルーティング可能なアドレス。最も一般的なルート。 |
| UNREACHABLE | 到達するまでの経路が分からず到達不能なことを知らせる。パケットは破棄され ICMP Host unreachable (タイプ 3, コード 1) が発生する。 |
| UNSPEC | 定義になく正当な意味を持たないアドレス。 |
| XRESOLVE | カーネルの行うルート検索の代わりにユーザ空間のアプリケーションにルート検索指示を送る時に使われるアドレスタイプ。あり得るケースとしては、込み入った汚いルックアップをカーネル外でやらせたり、何らかのアプリケーションにやらせたい場合だ。Linux では実装されていない。 |
addrtype マッチは -m addrtype キーワードを使用した時にロードされる。ロードされると、下表に示すマッチオプションが使えるようになる。
Table 10-7. Addrtypeマッチオプション
| マッチ | --src-type |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -m addrtype --src-type UNICAST |
| 説明 | --src-type マッチオプションは、パケットの送信元のアドレスタイプに対してマッチを行う。アドレスタイプは単一でもよいし、カンマ区切りで複数指定してもよく、例としては --src-type BROADCAST,MULTICAST のようになる。このマッチオプションは手前にエクスクラメーションマークを置いて ! --src-type BROADCAST,MULTICAST のように意味反転を行うことも可能。 |
| マッチ | --dst-type |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -m addrtype --dst-type UNICAST |
| 説明 | --dst-type も --src-type と同様に働き、文法も同じ。違うのは、宛先のアドレスタイプに対してパケットマッチを行うという点だけだ。 |
10.3.2. AH/ESPマッチ
このふたつのマッチは IPSEC の AH と ESP プロトコルを対象にしている。 IPSEC はセキュリティに欠けるインターネット接続上にセキュアなトネリングを構築するためのもの。 AH と ESP プロトコルは、そうしたセキュアなコネクションを構築する際に IPSEC によって利用される。本当のところ、 AH マッチと ESP マッチは全く別個のマッチなのだが、非常によく似たところがあるし用途も共通しているので、ここで一緒に述べることにする。
IPSEC についてここで詳しく述べるのは差し控える。より詳しい情報は以下のページやドキュメントを見て頂きたい:
IPSEC に関するドキュメントはインターネット上に五万とあるが、必要なら思い思いに検索してみてほしい。
AH/ESP マッチを使用するには、 AH マッチなら -m ah、 ESP ならば -m esp を使ってマッチをロードする必要がある。
| カーネル 2.2 と 2.4 においては、Linux は IPSEC を実装するために FreeS/WAN と呼ばれるものを利用していた。しかし Linux カーネル 2.5.47 以降では、カーネル自体が IPSEC を実装するようになり、カーネルへのパッチを必要としなくなった。 Linux の IPSEC 実装部分がまるっきり書きなおされたのだ。 |
Table 10-8. AHマッチオプション
| マッチ | --ahspi |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p 51 -m ah --ahspi 500 |
| 説明 | このマッチは AH パケットの持つ AH Security Parameter Index (SPI) ナンバーを照合する。注意が必要なのは、このマッチを使用するならプロトコルも指定しなければならないという点。 AH は標準的な TCP, UDP, ICMP とは違ったプロトコルの上で働くからだ。 SPI ナンバーは送信元/宛先アドレスと秘密キーとともに、セキュリティアソシエーション (SA = security association) の生成に使われる。 SA はホスト毎の IPSEC トンネルそれぞれに一意性を与える。 SPI は一対のピア-ピア間の個々の IPSEC トンネルを識別するのに利用される。 --ahspi を使うと、パケットの SPI に基づいたマッチングを行うことができる。このマッチでは : を使って SPI 値の範囲をまとめてマッチさせることも可能だ。例えば 500:520 のような使い方で、これは範囲内の SPI に合致する。 |
10.3.3. Commentマッチ
comment マッチを使うと iptables ルールセット及びカーネル内にコメントを記述することができる。ルールセットが理解しやすくなりデバグに役立つだろう。例えば、或る一連のルールがどの bash ファンクションによってどんな理由で差し込まれたかを述べたコメントを加える、といった使い方が考えられる。このマッチは実際のところ本当のマッチではないことに注意していただきたい。comment マッチは -m comment キーワードによってロードされる。現在のところ、以下のオプションが利用できる。
10.3.4. Connmarkマッチ
connmark マッチは、 MARK ターゲットと mark マッチの組み合わせと全く同じような使い方をする。 CONNMARK ターゲットでコネクション単位に付けられたマークに対して、マッチを行うのが connmark だ。オプションはひとつのみ。
| そのコネクションに mark を付けるに至ったまさにその最初のパケットをマッチさせるには、先に CONNMARK ターゲットに最初のパケットへマークを付けさせてから、 connmark マッチを使用しなければならない。 |
Table 10-11. Connmarkマッチオプション
| マッチ | --mark |
| カーネル | 2.6 |
| 例 | iptables -A INPUT -m connmark --mark 12 -j ACCEPT |
| 説明 | mark オプションは、コネクション単位で関連付けされたマーク (mark) に対してマッチを行う時に使用する。マークは完全に一致する必要がある。実際のマッチングに先立って不要なコネクションマークを排除しておきたい場合には、マスクを指定してマークとの論理積 (logical AND) を行わせることもできる。例を示す。或るコネクションにマーク 33 (バイナリ表現 10001) がセットされており、最初のビットだけをマッチさせたいとしよう。この時、 --mark 1/1 のようにコマンドすることができる。マスク (00001) は 10001 に対してマスク適用され、その結果 10001 && 00001 = 1 となり、 1 にマッチすることになる。 |
10.3.5. Conntrackマッチ
conntrack マッチはステートマッチの拡張版であり、ステートマッチよりも格段に詳しくパケットを照合することが可能だ。これは、コネクション追跡機構から得られる情報を、ステートマッチのような "フロントエンド" の助けを借りることなしに直接調べることを可能にしてくれる。コネクション追跡機構についての詳細は ステート機構 のチャプターを参照して頂きたい。
conntrack マッチには、コネクション追跡機構の様々なフィールドに呼応する、幾種類ものマッチが収められている。そうしたマッチを集めたのが、下のリストだ。これらのマッチをロードするには -m conntrack を指定する必要がある。
Table 10-12. Conntrackマッチオプション
| マッチ | --ctstate |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctstate RELATED |
| 説明 | このマッチは conntrack の状態を基にしてパケットのステートをマッチさせる場合に使用する。本来の state マッチでのステートとほぼ同じものを対象にしたい場合に用いる。このマッチで有効なステートエントリは:
ステートエントリをカンマで区切って複数指定することもできる。例えば -m conntrack --ctstate ESTABLISHED,RELATED といった具合だ。また、 -m conntrack ! --ctstate ESTABLISHED,RELATED の例ならば ESTABLISHED と RELATED 以外にマッチする。 |
| マッチ | --ctproto |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctproto TCP |
| 説明 | これは --protocol が行うのと同様にプロトコルでマッチを行う。タイプとして指定できる値も同じで、 ! 記号を使っての反転もできる。例えば -m conntrack ! --ctproto TCP は TCP プロトコルを除く全てのプロトコルにマッチする。 |
| マッチ | --ctorigsrc |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctorigsrc 192.168.0.0/24 |
| 説明 | --ctorigsrc マッチは、特定のパケットに関する conntrack エントリに記録された送信元IP の諸元に基づいてマッチを行う。 --ctorigsrc ! 192.168.0.1 のように --ctorigsrc と IP 指定との間に ! を挟むことにより意味を反転させることもできる。また --ctorigsrc 192.168.0.0/24 といった風に CIDR 形式のネットマスクを採ることも可能だ。 |
| マッチ | --ctorigdst |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctorigdst 192.168.0.0/24 |
| 説明 | このマッチは、照合対象が conntrack エントリの宛先フィールドである点を除けば --ctorigsrc と全く同じ。書式もあらゆる点において共通だ。 |
| マッチ | --ctreplsrc |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctreplsrc 192.168.0.0/24 |
| 説明 | --ctreplsrc マッチは、 conntrack に記載されている回答パケットの送信元に基づいてマッチを行いたい時に使う。基本的には --ctorigsrc と同様なのだが、こちらの場合には、次に期待される返答の送信元と照合する。もちろん、このクラスの前述のターゲットと同様に、反転や、アドレスの範囲指定も可能だ。 |
| マッチ | --ctrepldst |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctrepldst 192.168.0.0/24 |
| 説明 | --ctrepldst マッチは --ctreplsrc と同様で、パケットがマッチしたことにより記録された conntrack エントリの中の、回答の宛先を照合対象にする点が異なる。これも --ctreplsrc 同様に反転や範囲指定ができる。 |
| マッチ | --ctstatus |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctstatus RELATED |
| 説明 | このマッチは ステート機構 のチャプターで述べたコネクションの状態 (status) でマッチを行う。照合できるステータスには以下のものがある:
このマッチもまた ! 記号で反転することができる。例えば -m conntrack ! --ctstatus ASSURED で、これは ASSURED 以外のステータスに合致する。 |
| マッチ | --ctexpire |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m conntrack --ctexpire 100:150 |
| 説明 | このマッチは conntrack エントリの有効期限タイマー (expiration timer) に残っている時間 (秒単位) に基づいたパケットマッチに使用する。単一の値を与えて照合することもできるし、上記の例のように範囲を指定することもできる。また、 -m conntrack ! --ctexpire 100 のように ! 記号を使用しての反転も可能で、これは、ぴったり 100 秒残っているもの以外の有効期限をマッチさせる。 |
10.3.6. DSCPマッチ
このマッチはパケットをその DSCP (Differentiated Services Code Point) フィールドに基づいてマッチさせる。 DSCP については RFC 2638 - A Two-bit Differentiated Services Architecture for the Internet に網羅されている。このマッチは明示的に -m dscp を指定するとロードされる。下記に挙げる、排他関係にあるふたつのオプションが採れる。[訳者補足: DSCP自体については IPヘッダ セクションで幾分か詳しく述べられている]
Table 10-13. DSCPマッチオプション
| マッチ | --dscp |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m dscp --dscp 32 |
| 説明 | このオプションは引数として 10進または 16進表記の DSCP 値を採る。オプション値を 10進で書くとすれば 32 や 16 などといった具合。 16進表記の際には頭に 0x を添えて 0x20 のように書く。 ! の字を使って -m dscp ! --dscp 32 のように意味を反転することも可能。 |
| マッチ | --dscp-class |
| カーネル | 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m dscp --dscp-class BE |
| 説明 | --dscp-class マッチはパケットの DiffServ クラスによってマッチを行う際に使用する。その値は、幾つかの RFC で定義されているように BE, EF, AFxx, CSx のいずれかのクラスとなる。 --dscp と同じく反転もできる。 |
| --dscp オプションと --dscp-class オプションは排他の関係にあり、同時指定はできないことに注意して頂きたい。 |
10.3.7. ECNマッチ
ECN マッチは TCP と IPv4 ヘッダにある ECN フィールド類を照合するのに使う。 ECN の詳細は RFC 3168 - The Addition of Explicit Congestion Notification (ECN) to IP の中で述べられている。このマッチはコマンドラインで -m ecn を指定して明示的にロードしなければならない。 ECN マッチが採れるオプションには以下のようなものがある。[訳者補足: ECN自体については IPヘッダ のセクションで幾分か詳しく述べられている]
Table 10-14. ECNマッチオプション
| マッチ | --ecn |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m ecn --ecn-tcp-cwr |
| 説明 | このマッチは、パケットに CWR (Congestion Window Received) ビットがセットされているかどうかを照合する。 CWR フラグを設定するのは、 ECE を受け取ったかどうかと ECE に対して反応したかを、コネクションの相手方に知らせる時。デフォルトでは、このマッチは CWR ビットがセットされていれば一致するが、エクスクラメーションマークを使って逆の意味にすることもできる。 |
| マッチ | --ecn-tcp-ece |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m ecn --ecn-tcp-ece |
| 説明 | このマッチは ECE (ECN-Echo) ビットでマッチを行うことができる。 ECE ビットは、どちらか一方のエンドポイントが、ルータによって CE ビットの立てられたパケットを受け取った場合にセットされる。すると、受信者は応答の ACK パケットに ECE ビットを立てることによって、相手方に、ペースを遅くする必要があることを知らせる。知らせを受け取った相手は --ecn-tcp-cwr で述べた CWR パケットを送出する。デフォルトではこのマッチは ECE ビットが立っているとマッチするが、エクスクラメーションマークを使って意味を逆転することもできる。 |
| マッチ | --ecn-ip-ect |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m ecn --ecn-ip-ect 1 |
| 説明 | --ecn-ip-ect マッチは ECT (ECN Capable Transport) コードポイントによってマッチを行いたい時に利用する。 ECT コードポイントには幾つかの利用法がある。まず主には、2 ビットあるうちの片方を 1 にセットすることにより、そのコネクションが ECN に対応しているかどうかを折衝する、という使い方。また、ルータにおいては、 ECT コードポイントを 2 ビットとも 1 にして、輻輳の発生を知らせるという使い方もある。 ECT の値は下表 IP内のECNフィールド にまとめておいた。 マッチはエクスクラメーションマークで ! --ecn-ip-ect 2 のように反転することができる。この例の場合、コードポイント ECT(0) を除いた全ての ECN値にマッチする。 iptables で使用できる値は 0 から 3 までだ。それらの値に関しては下表を参照のこと。 |
10.3.8. Hashlimitマッチ
これは Limitマッチ の変形バージョンだ。単にひとつのトークンバケツ (token backet) ではなく、宛先IP, 送信元IP, 宛先ポート, 送信元ポートの組み合わせから成る幾つものトークンバケツを指す、ひとつのハッシュテーブルが構築される。例えば、各 IPアドレス毎に最大 1000個/秒のパケットを受け取れるようにしたり、待ち受け IPアドレスはひとつであっても異なったサービス毎に最大 200パケット/秒まで受け入れるようにするなどといった設定ができる。 hashlimit マッチは -m hashlimit を指定するとロードされる。
hashlimit マッチの使用された各々のルールに対して別個のハッシュテーブルが生成され、ひいては、バケツのサイズ及び数の上限値は各ハッシュテーブル毎に定義できる。このハッシュテーブルはひとつの値だけを保持することもできるし、複数を保持することもできる。その値とは、宛先IP, 送信元IP, 宛先ポート, 送信元ポートのいずれか、またはそれら全てだ。これが形成されれば、それぞれのルールエントリが自分のトークンバケツを limit マッチ同様に参照できるようになる。
Table 10-16. Hashlimitマッチオプション
| マッチ | --hashlimit | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000/sec --hashlimit-mode dstip,dstport --hashlimit-name hosts | ||
| 説明 | --hashlimit はトークンバケツのリミットを設定する。上記の例では、ハッシュリミットを 1000 に設定している。その中でハッシュリミット-モードを dstip,dstport、宛先を 192.168.0.3 にしている。これによって、送信先ホストのポートまたはサービス毎に、1秒あたり 1000個のパケットを受信することができる。これは limit マッチの limit オプションと同じ設定だ。リミットの値には /sec, /minute, /hour, /day のいずれかの接尾語を付けることもできる。接尾語を付けない場合のデフォルトは毎秒となる。
| ||
| マッチ | --hashlimit-mode | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.0/16 -m hashlimit --hashlimit 1000/sec --hashlimit-mode dstip --hashlimit-name hosts | ||
| 説明 | --hashlimit-mode オプションは、ハッシュの値としてどの値を使用するかを定義する。上記の例では、ハッシュ値に dstip (destination IP) だけを使用している。これにより、当例の場合 192.168.0.0/16 のネットワークからの受信は、各相手ホストあたり最大 1000パケット/毎秒に制限される。 --hashlimit-mode に設定可能な値には dstip (宛先IP), srcip (送信元IP), dstport (宛先ポート), srcport (送信元ポート) がある。複数のハッシュ値を含めたい場合にはカンマで区切ることによってどれでも指定することができる。例えば --hashlimit-mode dstip,dstport といった具合だ。
| ||
| マッチ | --hashlimit-name | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts | ||
| 説明 | このオプションは、そのハッシュを利用する際の名称を指定する。ここで指定したものは /proc/net/ipt_hashlimit ディレクトリで見ることができる。上記のものは /proc/net/ipt_hashlimit/hosts ファイルとして見られる。指定できるのはファイル名だけだ。
| ||
| マッチ | --hashlimit-burst | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts --hashlimit-burst 2000 | ||
| 説明 | このマッチは、バケツのサイズを設定するという意味で --limit-burst と同じ。バケツには必ずバーストリミットがある。バーストリミットは、単位時間内にマッチさせることのできる最大パケット数だ。トークンバケツの動作については、 Limitマッチ に示した例を見ていただくといいだろう。 | ||
| マッチ | --hashlimit-htable-size | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts --hashlimit-htable-size 500 | ||
| 説明 | このオプションは、利用可能なバケツの最大数を規定する。上記の例は 500個までのポートが同時にオープンでき並行してアクティブになれることを意味する。 | ||
| マッチ | --hashlimit-htable-max | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts --hashlimit-htable-max 500 | ||
| 説明 | --hashlimit-htable-max はハッシュテーブル・エントリの最大数を指定する。これによって表されるのはコネクションの総数であり、その時トークンバケツを一切使用していない非活性なコネクションも含まれる。 | ||
| マッチ | --hashlimit-htable-gcinterval | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts --hashlimit-htable-gcinterval 1000 | ||
| 説明 | ガーベッジ・コレクション (garbage collection=ゴミ収集) 機能の実行頻度。一般論的には、expire の値よりも低くすべきである。単位はミリ秒。小さくしすぎるとシステムリソースや CPUパワーを無用に消費する一方、大きくしすぎると、使いもしないトークンバケツが長期間ほったらかしになり、他のコネクションが受け入れ不能となる。上記の例では、ガーベッジ・コレクションは 1秒毎に実行される。 | ||
| マッチ | --hashlimit-htable-expire | ||
| カーネル | 2.6 | ||
| 例 | iptables -A INPUT -p tcp --dst 192.168.0.3 -m hashlimit --hashlimit 1000 --hashlimit-mode dstip,dstport --hashlimit-name hosts --hashlimit-htable-expire 10000 | ||
| 説明 | この値は、ハッシュテーブルの特定エントリがどれくらいの期間アイドルを続けたら失効となるかを規定する。バケツの使用されない期間がこの値を超えるとそのエントリは失効し、次回のガーベッジ・コレクションの際に、関連する情報もろともハッシュテーブルから削除される。 |
10.3.9. Helperマッチ
これは、書式の特殊性という意味において、マッチの中でも異端に数えられるマッチと言えるかもしれない。このマッチは、そのパケットがどの conntrack ヘルパーに関係しているかに基づいてパケットを選定する。 FTP セッションを例に採ろう。コントロールセッションが開き、そのコントロールセッションを通じてデータセッション用のポート/コネクションがネゴシエートされる。その情報を見つけるのがヘルパー ip_conntrack_ftp で、それが conntrack テーブルに RELATED エントリを記録する。よって我々は、次のパケットが来た時、それがどのプロトコルに関連したパケットなのかを知ることができ、利用されたヘルパーの種類に基づいたパケットマッチをルールセットの中で行えるのだ。このマッチは、キーワード -m helper を使用することによってロードされる。
Table 10-17. Helperマッチオプション
| マッチ | --helper |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m helper --helper ftp-21 |
| 説明 | --helper オプションの利用法は、文字列値を指定して、合致させたい conntrack ヘルパーを指示することだ。基本的な書式としては --helper irc のようになる。しかしここからがちょっと込み入ってくる。特定のポートで初期ネゴシエーションが行われたパケットだけをマッチさせることも可能なのだ。例えば FTP では、コントロールセッションには通常なら 21番ポートを使うが、 954など他のポートを使用することもある。そういった場合には、どのポートでネゴシエーションが行われたものかを指定すればいい。例えば --helper ftp-954 のようにだ。 |
10.3.10. IP rangeマッチ
IP range マッチは IP の範囲に対してマッチを行う。これは --source マッチや --destination マッチでもできることだが、 IP range マッチでは --source や --destination では不可能だった 始点IP - 終点IP という形での照合が可能となる。特異な設定のネットワークではこうしたやり方が必要で、しかもこちらのほうがやや柔軟性に富む。IP range はキーワード -m iprange を使うことによってロードされる。
Table 10-18. IP rangeマッチオプション
| マッチ | --src-range |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m iprange --src-range 192.168.1.13-192.168.2.19 |
| 説明 | このマッチは送信元 IP の範囲を照合する。指定した範囲は始点から終点までの全 IP を含み、上の例なら 192.168.1.13 から 192.168.2.19 までが入る。 ! を加えることによって意味を反転することもできる。それを使うとすれば上記の例は -m iprange ! --src-range 192.168.1.13-192.168.2.19 のようになり、指定した範囲を除く全 IPアドレスがマッチすることになる。 |
| マッチ | --dst-range |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m iprange --dst-range 192.168.1.13-192.168.2.19 |
| 説明 | --dst-range の動作は、対象が送信元でなく宛先である点を除けば --src-range マッチと全く同様だ。 |
10.3.11. Lengthマッチ
Length マッチを使うと、パケットの長さに基づいたマッチが行える。ことは至って単純だ。もしも何か特別な理由でパケットの長さを制限したかったり、 ping-of-death 的な挙動をブロックしたいのであれば、 length マッチを使うといい。
Table 10-19. Lengthマッチオプション
| マッチ | --length |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m length --length 1400:1500 |
| 説明 | 例に示した --length は、長さが 1400バイトから 1500バイトである全パケットに合致する。また、このマッチは ! 記号を使って -m length ! --length 1400:1500 といった具合に意味を反転させることもできる。更に、 : 記号以下を取り去って特定の長さのパケットだけをマッチさせることも可能だ。言うまでもないが length マッチの対象は「以上」や「以下」であり、指定した数値も含めた中間のあらゆる長さのパケットを含む。 |
10.3.12. Limitマッチ
limit マッチ拡張機能は -m limit オプションによって明示的にロードする必要がある。このマッチは例えば、特定のルールのログを限定的に間引きながら取るなどの活用法がある。或る値が指定数値以下であるパケットにマッチさせ、その数値を超えたら、対象としているイベントのロギングを抑制 (limit) する、などといった場合だ。時間的な limit について考えてみよう。あるルールが一定の単位時間内に何回マッチするかを制限することによって、例えば DoS の synパケット氾濫 (syn flood) 攻撃の影響を低減することができる。これが limit マッチの主な使い道ではあるが、もちろん利用法は他にもある。limit マッチは、マッチの前に ! 記号を用いることによって反転することも可能だ。これを使うと、-m limit ! --limit 5/s と書ける。これは、リミットを突破した後のすべてのパケットにマッチする。[訳者補足: 以下の説明に出てくる "トークン (token)" は地下鉄などの切符を意味する英語彙、"バースト (burst)" は直訳すると "爆発" や "突発"]
より詳しく説明すると、 limit マッチは、理屈としては一種のトークンバケツフィルタ (token bucket filter) だと言える。ここに、水漏れバケツがあるとしよう。このバケツは、単位時間あたり X 個のパケットが漏れる。 X は、条件に合致するパケットがいくつ入ってきたかによって規定が変化する。もし 3パケット入ってくれば、バケツからは単位時間あたり 3 個のパケットが漏れる。 --limit オプションは単位時間あたりいくつのパケットをバケツに補充できるかを規定し、 --limit-burst オプションは、そもそものバケツの大きさを表す。よって、 --limit 3/minute --limit-burst 5 と指定してあるところに 5個のパケットがマッチすると、バケツはカラになる。 20秒 [訳者補足: 1/3 分] 経つと、バケツのトークンは 1 つ増え...が、再び --limit-burst に達するかトークンが使用されるまで繰り返される。
これがどう作動するかの説明に代えて、以下の例を考察していただこう。
-m limit --limit 5/second --limit-burst 10/second というルールを設定する。 limit-burst トークンバケツの初期値は 10 にセットされる。ルールに合致する各パケットはトークンをひとつ消費する。
マッチするパケット 1-2-3-4-5-6-7-8-9-10 が来る。パケットは 1/1000 秒以内で入ってくるとする。
トークンバケツはカラになった。トークンバケツが一旦カラになると、ルールに沿ったパケットであってももうルールにマッチしないので、もし次のルールがあればその評価を受け、なければチェーンのポリシーが適用される。
パケットがマッチしない時間が 1/5 秒続くと、そのたびにトークンカウントが 1 ずつ上がり、最大では 10 まで上がる。先ほどの 10パケットを受け取ってから 1秒経過すると、トークンの残り数は 5 まで復活している。
そして当然、パケットを 1つ受け取る度に、バケツのトークンも 1 ずつ減っていく。
Table 10-20. Limitマッチオプション
| マッチ | --limit |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m limit --limit 3/hour |
| 説明 | limit マッチのための、平均マッチ頻度の最大値を設定する。指定には、数と単位時間 (省略可能) が使用できる。現行では、次の様な単位時間が理解可能だ: /second /minute /hour /day 。デフォルト値は毎時 3回、 つまり 3/hour。この指定は limit マッチに対して、単位時間 (例えば分) あたりに許容するマッチの回数を指示する。 |
| マッチ | --limit-burst |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m limit --limit-burst 5 |
| 説明 | limit マッチにおける burst limit [訳者補足: 短い時間内で爆発的ににヒットする数の上限] を設定する。これは iptables に対して、与えられた単位時間内にマッチするパケットの最大数を伝える。この数は、1 単位時間 (--limit オプションで指定されたもの) がイベントの発生なしに経過する度に、この値の採れる最小値である 1 へ向かって 1 ずつ減ってゆく。イベントがまた発生すると、カウントがバーストリミットに達するまで、カウンタの値はまた増えていく。この繰り返しだ。デフォルトの --limit-burst 値は 5。その動作を確認する簡単な方法は、たったひとつのルールから成るスクリプト例 Limit-match.txt を使ってみることだ。このスクリプトを利用すれば、間隔とバースト数 [訳者補足: 短い時間内で爆発的ににヒットする数] を変えながら ping を送るだけで、 limit ルールがどう働くのかをその目で見ることができる。カウントがバーストリミットのしきい値まで回復するまで、 echo応答 はブロックされて返ってこない。 |
10.3.13. MACマッチ
MAC (Ethernet Media Access Control) マッチは送信元 MACアドレス に基づいたパケットマッチに使用する。このドキュメントを書いている時点では、このマッチには幾らかの制限事項があるが、将来的にはもっと開発が進み便利になるだろう。既に述べたように、送信元の MACアドレス によるマッチしかできない。
| このモジュールを使用するには明示的に -m mac オプションを指定しなければならない。わざわざこんなことを言うのは、 -m mac-source でいいのではないかと勘違いする人が多いからだ。 |
Table 10-21. MACマッチオプション
| マッチ | --mac-source |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01 |
| 説明 | 送信元 MACアドレス に基づいたパケットマッチに使用する。指定する MACアドレス は XX:XX:XX:XX:XX:XX の形式でなくてはならなず、それ以外は通用しない。マッチは ! 記号で反転でき、 --mac-source ! 00:00:00:00:00:01 のように書ける。これはマッチの意味を逆転するので、その MACアドレス 以外から来るパケットにマッチする。留意点として、 MACアドレス はイーサネットタイプのネットワークでだけ用いられており、このマッチもイーサネットインターフェースにしか使用できない。 MAC マッチは PREROUTING, FORWARD, INPUT チェーンでのみ有効で、他で使うことはできない。 |
10.3.14. Markマッチ
mark マッチは、パケットに付けておいたマーク (mark) に基づいてパケットをマッチさせるのに使用する。マークはカーネルの中でのみ維持管理できる特別なフィールドで、パケットがコンピュータの中を通過している間だけ識別に利用できる。マークはトラフィックシェーピングやフィルタリングなどといった様々なカーネル関連ルーティンに利用可能だ。今のところ、マークをセットする Linux で唯一の方法は、iptables の、その名も MARK ターゲットのみだ。同じことが、以前は ipchains の FWMARK ターゲットで行われていた。高度ルーティングのコミュニティで未だに FWMARK が言及されるのは、これが理由だ。現行では、mark フィールドには符号無しの整数が指定でき、32ビットシステムでは 4,294,967,296通りの値を採ることができる。おそらく、この制限にひっかかることは滅多にないだろう。
Table 10-22. Markマッチオプション
| マッチ | --mark |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -t mangle -A INPUT -m mark --mark 1 |
| 説明 | あらかじめマークを付けられたパケットにマッチさせるために用いる。マークは、次のセクションで述べる MARK ターゲットによって付与することができる。 Netfilter を通過している間、パケットにはもれなく特殊なマークフィールドが関連づけされる。このマークフィールドは、パケットの内側にも外側にも、実際に余分なフィールドをくっつけるわけではないという点に注意してほしい。マークは、マークを生成したコンピュータの中に保持されるのだ。マークフィールドが指定したマークに合致すれば、即ちマッチとなる。マークフィールドは符号無しの整数で、 4,294,967,296 通りの値を採ることができる。また、マークにマスクを設定することも可能だ。これを使用した場合、マークの指定は、 --mark 1/1 といった具合になる。マスクが指定されていた場合には、実際の比較に先立って、マスクとマークの論理積が行われる。 |
10.3.15. Multiportマッチ
multiport マッチ拡張によって、複数の宛先ポートや、複数の宛先ポート範囲が指定できるようになる。このマッチの能力を利用しないと、ポートが異なるだけで、同じタイプのルールをいくつも書かなければならない。
| 通常のポートマッチングと multiport マッチを同時に使用することはできない。つまり、このように書くことはできない: --sport 1024:63353 -m multiport --dport 21,23,80。実際にやったらどうなるかといえば、 iptables はルールの最初の要素だけを尊重し、 multiport 指示は無視される。 |
Table 10-23. Multiportマッチオプション
| マッチ | --source-port |
| カーネル | 2.3, 2.4, 2.5 2.6 |
| 例 | iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110 |
| 説明 | このマッチは複数の送信元ポートにマッチする。不連続なポート 15個まで指定できる。上記の例のように、ポートはカンマ区切りで指定する。このマッチは -p tcp または -p udp との併用でしか使用できない。基本的には、通常の --source-port マッチの拡張版だ。 |
| マッチ | --destination-port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110 |
| 説明 | このマッチは複数の宛先ポートを合致させるのに使用する。ポートが宛先である点を除いては、上記の送信元ポートマッチとまったく同様に働く。このマッチも制限は 15個で、 -p tcp または -p udp と組み合わせなければ使えない。 |
| マッチ | --port |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m multiport --port 22,53,80,110 |
| 説明 | このマッチ拡張は、宛先と送信元のポートに基づいてパケットをマッチさせるのに用いる。上記の --source-port と --destination-port と同じように作用する。最大 15個のポートを採ることができ、 -p tcp か -p udp との組み合わせでしか機能しない点も同じだ。ただし、 --port マッチは、送り手のポートと受け側ポートが同じであるパケットのみにマッチする。例えば、ポート 80 からポート 80 へ宛てたパケット、ポート 110 からポート 110 へ宛てたパケット、といった具合だ。 |
10.3.16. Ownerマッチ
owner マッチ拡張は、パケットを作り出したプロセスの身元に基づいてパケットをマッチさせるのに用いる。 owner にはプロセスの ID を指定する。 ID は、当該のコマンドを発行したユーザ、グループ、プロセス、セッションの ID、あるいはコマンドそのもの ID のいずれか。この拡張は元々 iptables の活用方法のひとつを示す例として書かれたものだ。 owner マッチは OUTPUT チェーンでしか使えない。その理由はいくつかある: パケットを送り出したプロセスの身元に関する情報を、着信した先で探し出しすのはほぼ不可能に近い。また、最終的な目的地に辿り着くまでに中継ホップを経ている場合にも、やはり難しい。ある種のパケットはオーナーを欠いているため、たとえ OUTPUT チェーン内に限ったとしても、このマッチはあまり信頼できない。これに類する悪名高いパケットには、(他にもあるが) 様々な ICMP 応答が挙げられる。 ICMP応答 は決してこれにマッチすることはない。
Table 10-24. Ownerマッチオプション
| マッチ | --cmd-owner |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m owner --cmd-owner httpd |
| 説明 | コマンドのオーナーによるマッチであり、パケットを送り出したプロセスの名前に基づいてマッチを行う。例に示したものには httpd が合致する。エクスクラメーションマークを使って -m owner ! --cmd-owner ssh のように意味を反転させることもできる。 |
| マッチ | --uid-owner |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m owner --uid-owner 500 |
| 説明 | このマッチは、パケットを作り出したユーザ の ID が、指定された ID (UID) と一致していればマッチする。これは、誰がパケットを発生させたかに基づいて、ローカルから出ていくパケットを選択するのに用いられる。想定される用途としては、root 以外のユーザがファイヤーウォール外への新規コネクションを開始するのを阻止する場合。あるいは、 http ユーザ以外は HTTP ポートからパケットを送出できなくする、という使い方が考えられる。 |
| マッチ | --gid-owner |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m owner --gid-owner 0 |
| 説明 | このマッチは、パケットのグループID (GID) に基づいてパケットをマッチさせる。つまり、パケットを発生させたユーザがどのグループに属するかによってパケットをマッチさせるわけだ。 network グループに属するユーザを除いてはインターネットに出て行けなくする、あるいは、前のマッチのように HTTP ポートから出ようとするパケットの発行を http グループのメンバーにのみ許す、という使い方ができる。 |
| マッチ | --pid-owner |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m owner --pid-owner 78 |
| 説明 | このマッチは、パケットの元となったプロセス の ID (PID) に基づいてパケットマッチを行うのに使用する。このマッチは使い方がやや難しいが、例えば、PID 94 にだけ HTTP ポートからのパケット送出を許す場合がある (言うまでもなく、HTTPD プロセスがスレッド化されていない場合に限る)。或いは、 ps の出力を利用して探知した特定デーモンの PID に応じてルールを追加するような小さなスクリプトを書いておく、という手法も考えられる。やるとすれば、スクリプト例 Pid-owner.txt で示しているようなルールが書ける。 |
| マッチ | --sid-owner |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m owner --sid-owner 100 |
| 説明 | 当該プログラムのセッションID に基づいてパケットをマッチする。SID つまりセッションID の値は、プロセス自体の ID であると同時に、そのプロセスから派生した全プロセスの SID でもある。後者には、元のプロセスのスレッドや子プロセスも含まれる。つまり、例えば HTTPD がスレッド化されていたとしても (ほとんどの HTTPD はそうだ。 Apache も Roxen も)、すべての HTTPD プロセスは親プロセス (大元の HTTPD プロセス) と同じ SID を持っているはずである。この実例として Sid-owner.txt を作っておいた。この小さなスクリプトの使い道は、 HTTPD が起動しているかどうか調べて必要ならば起動させ、必要に応じて OUTPUT チェーンをフラッシュしてから OUTPUT チェーンをロードし直すような、追加のスクリプトと組み合わせて、例えば 1時間に 1回走らせることだ。 |
| pid, sid マッチは SMPカーネルでは動作が破綻している。これらのマッチはプロセスリストをプロセッサ別に管理するからだ。とはいえ、将来は修正されるだろう。 |
10.3.17. Packet type マッチ
packet type マッチはパケットのタイプに基づいてマッチを行う。言い換えると、特定のひとりに宛てたものなのか、全員なのか、あるいは或る限られたマシンの一団やユーザの一団宛てなのか、ということだ。これら 3つの括りはそれぞれ、ユニキャスト、ブロードキャスト、マルチキャスト と呼ばれる。そのことは TCP/IPのおさらい のチャプターで述べている。このマッチは -m pkttype によってロードする。
Table 10-25. Packet typeマッチオプション
| マッチ | --pkt-type |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m pkttype --pkt-type unicast |
| 説明 | --pkt-type マッチは、どのようなパケットタイプに合致させるかを指示する。例にあるように、その引数には unicast, broadcast, multicast のいずれが指定できる。 ! を使って -m pkttype --pkt-type ! broadcast のように意味を反転することも可能で、この場合、ブロードキャスト以外のパケットタイプにマッチすることになる。 |
10.3.18. Realmマッチ
realm は、そのパケットがどのルーティング・レルム (Routing realm) に属するかによってマッチを行う。ルーティング・レルムは Linux で複雑なルーティングを行う必要のある場面で、例えば、どんな場合に BGP を使用するかといった制御をするのに使われる。 realm マッチはコマンドラインに -m realm キーワードを加えるとロードされる。[訳者註: 英語彙 realm の元々の意味は「領域」「〜界」で、感覚的には domain という語と近い]
Linux においては、ルーティング・レルムというものは複数のルートを幾つかの論理上のグループにまとめるのに使われる。現今の専用ルータでは、RIB (Routing Information Base) と転送エンジン (forwarding engine) は非常に近くにある。例えばだが、どちらもカーネルの中で扱われていたりする。しかし Linux は専用ルータではないので、RIB と FIB (Forwarding Information Base) を別々に扱わざるを得ない。 RIB はユーザ空間、 FIB はカーネル空間にあるわけだ。これが足かせとなり、 RIB の高速検索はかなりリソースに厳しい処理となってしまう。ルーティング・レルムは Linux におけるその解決策であり、柔軟な対応と機能の充実をシステムにもたらしている。
Linux でのレルムは、BGP など、大量のルート情報を遣り取りするプロトコルと組み合わせての使用が想定される。そうすれば、ルーティングデーモンはプレフィクスや AS PATH、送信元などに基づいてそれらをソートし、別々のレルムに仕分けすることができる。 realm は数値だが、 /etc/iproute2/rt_realms ファイルで定義された名前を使うことも可能だ。
Table 10-26. Realmマッチオプション
| マッチ | --realm |
| カーネル | 2.6 |
| 例 | iptables -A OUTPUT -m realm --realm 4 |
| 説明 | このオプションはレルムナンバーと、場合によってはマスクによるマッチを行う。数値以外で指定された時には、ファイル /etc/iproute2/rt_realms を照会して数値への解決も行おうとする。名前によるレルム指定時にはマスクは指定できない。エクスクラメーションマークを使って意味を反転することも可能で、その場合の例は --realm ! cosmos のようになる。[訳者註: マスクの指定方法が原文に抜けているので補足。書式は REALM/MASK] |
10.3.19. Recentマッチ
recent マッチは、かなり幅広い使い方のある複雑なマッチング機構で、前に行われたマッチを手掛かりにしてパケットを選定することができる。例えば、今こちらから IRC コネクションを張ったとしよう。その IPアドレスをホストのリストに記録しておけば、別のルールで、先ほどのパケットから数えて 15秒間だけその IRC サーバからの ident 要求を許可する、といったことができるのだ。
このマッチをつぶさに見ていく前に、その動作の仕組みを分かってもらえるかやってみることにする。まず前提として、 recent マッチを活用するには複数のルールが要る。 recent マッチは最近発生したイベントについてのリストを何種類か使う。デフォルトで使用されるリストは DEFAULT リストだ。リストには set オプションを使ってエントリを追加するのだが、或るルールが完全にマッチする度に (set オプションではマッチは常に真となる)、当該の「最近 (recent) リスト」に set オプションでエントリをさらに追加していく。リスト上の各エントリには、タイムスタンプと、その set オプションのトリガーとなったパケットの送信元 IPアドレスが記録されている。ここまで準備が整えば、それらの情報を頼りに recent マッチの様々なオプションを使ってマッチを行ったり、エントリのタイムスタンプを更新するといったことができる。
最後に付け加えておくと、もし何かの理由で或るエントリをリストから削除したい場合には recent モジュールの提供する remove マッチで削除ができる。他のモジュールと同様、 recent マッチを使用するには recent モジュールをロード (-m recent) しなければならない。では、使用例を云々する前にまず、オプションの全てを見てみよう。
Table 10-27. Recentマッチオプション
| マッチ | --name |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m recent --name examplelist |
| 説明 | name オプションは使用するリストの名前を指定する。デフォルトでは DEFAULT リストが使用されるが、 DEFAULT リストは、複数のリストを使用している時にはおそらく用のないリストだ。 |
| マッチ | --set |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m recent --set |
| 説明 | このオプションを使うと name 済みのリストへエントリを追加できる。リストエントリには、そのルールのトリガーとなったホストの送信元 IPアドレスとタイムスタンプが格納される。このマッチは ! 記号を前置きすれば偽を返すが、そうしない限り常に真を返す。 |
| マッチ | --rcheck |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m recent --name examplelist --rcheck |
| 説明 | --rcheck オプションは指定のリストにそのパケットの送信元 IPアドレスが登録済みかどうかをチェックする。あれば真を返すし、なければ偽を返す。 ! 記号を使えばオプションの意味は反転する。その場合、送信元 IPアドレスがリストになければ真を返し、あれば偽を返す。 |
| マッチ | --update |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m recent --name examplelist --update |
| 説明 | このマッチは、その送信元情報の組み合わせが指定したリストにあれば真となるとともに、そのリストの最終観測時間を更新する。このマッチも前置きの ! 記号で反転でき、例えば ! --update のようにも指定できる。 |
| マッチ | --remove |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --remove |
| 説明 | このマッチを発すると、リストからそのパケットの送信元アドレスを探し、見つかれば真を返す。と同時に、リストから当該のエントリを削除する。これも ! 記号で反転か可能だ。 |
| マッチ | --seconds |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --check --seconds 60 |
| 説明 | このオプションが使えるのは --check または --update マッチと併用した時だけ。 --seconds マッチを使うと、「最近リスト」の最終観測時間カラムが最後に更新されてからの時間を指定することができる。もしも最終更新時間カラムが指定秒以上に古ければ [訳者註: 等しい時は含まない]、マッチは偽を返す。その点を除いては、リストにその送信元アドレスがある時だけ真を返すという通常の振る舞いは変わらない。 |
| マッチ | --hitcount |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --check --hitcount 20 |
| 説明 | --hitcount マッチは --check もしくは --update と一緒に使用しなければならない。このマッチを使用すると、指定回数以上観測された [: イコール含む] パケットにだけマッチするようになる。 --seconds マッチと併用した場合には、指定時間内に指定回数以上のヒットカウントのあったパケットだけがマッチする。マッチの前に ! を置けば意味を反転できる。反転を --seconds と組み合わせた時の意味は、指定時間内に N 回以下しか観測されなかったパケットということになる。 --hitcount と --seconds を両方とも反転した場合、今から遡って S 秒以内にパケットが N 回以下しか観測されなかった時に真となる。 |
| マッチ | --rttl |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --check --rttl |
| 説明 | --rttl マッチを使うと、「最近リスト」にエントリを登録するきっかけになった元パケットと今取り扱っているパケットの TTL の値が同じかどうかを突き合わせることができる。これを利用すれば、 recent マッチで、送信元アドレスを詐称して正規ユーザによるサーバ利用を妨げている奴はいないか、調べることができる。 |
| マッチ | --rsource |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --rsource |
| 説明 | --rsource マッチは送信元のアドレスとポートを「最近リスト」へ保存するよう recent マッチに指示を与える。これが recent マッチのデフォルトの挙動だ。 |
| マッチ | --rdest |
| カーネル | 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m recent --name example --rdest |
| 説明 | --rdest マッチは recent マッチに現在の宛先アドレスとポートを保存させる。その意味で --rsource マッチのちょうど反対だ。 |
recent マッチの使い方を表す小さなサンプルスクリプトを作った。 Recent-match.txt セクションにある。
簡単に言うと、これは netfilter の備えるステート機構の、粗末な代用品だ。現バージョンは基本的に http サーバを想定しているが、おそらくどんな TCP コネクションでも機能するだろう。この中ではまず、 http-recent, http-recent-final というふたつのチェーンを作成している。 http-recent チェーンはコネクションの開始段階と実際のデータ送受信で使われ、 http-recent-final チェーンは最後の FIN, FIN/ACK ハンドシェイクで使用される。
| これはビルトインのステート機構に比べれば非常に出来の悪い代用品で、ステート機構で処理できる全てのケースを扱えるわけではない。とはいえ recent マッチで何ができるかを俯瞰的にさらってみるには良い教材だ。実際の運用環境で使ってはいけない。動作が遅い上に、特殊なケースとなるとうまく対応できないので、あくまでもサンプルとしてのみ使っていただきたい。 例えば、接続しようとしたポートがクローズしていた時や、同期的でない FIN ハンドシェイク (コネクションの片端は接続をクローズしているがもう一方の相手はデータをまだ送り続けている時) などには対応できないのだ。 |
ではサンプルのルールセットの中のパケットの道のりを追ってみよう。まずは、ひとつのパケットが INPUT チェーンに入ってくる。そして、我々はそれを http-recent チェーンに送り込む。
最初のパケットは SYN パケットであり、 ACK,FIN や RST ビットは立っていないはずである。よって --tcp-flags SYN,ACK,FIN,RST SYN の行でマッチさせている。この時 -m recent --name httplist --set の行で httplist にこのコネクションを登録する。そして最終的にこのパケットを受け入れる。
第1パケットの次に我々は、 SYN パケットの受領を示す SYN/ACK パケットを受け取るはずだ。それは --tcp-flags SYN,ACK,FIN,RST SYN,ACK の行で捕捉できる。もちろん FIN や RST は問題外である。この時には -m recent --name httplist --update を使用して httplist を更新し、最終的にパケットを受け入れる。
そろそろ、サーバの送った SYN/ACK を了解する締めの ACK パケットが、コネクションの始動者からやってくるはずだ。このコネクション段階では SYN, FIN, RST は異常である。よって、捕捉のための命令は --tcp-flags SYN,ACK,FIN,RST ACK のようになる。ひとつ前のステップと全く同様に、リストをアップデートし、パケットを受け入れる。
もうデータの送受信がいつでも始められる状態だ。今、コネクションの中で SYN パケットが現れるはずはなく、こちらの送ったデータに対する了解を示す ACK パケットなら見られるだろう。こうしたパケットを観測する度に、我々はリストを更新して受け入れていく。
送受信の終わり方は 2種類ある。単純なのは RST パケット。 RST は即座にコネクションをリセットして断ち切る。 FIN の場合には、相手方がFIN,ACK でそれに答えてコネクションに幕を下ろし、 FIN を送った方のホストはもうデータを送ることはできなくなる。ただし、 FIN を受け取った方のホストはまだデータを送ることが可能だ。かくして、我々はこのコネクションを「最終 (final)」ステージへと引き渡し、ここから先はそちらの受け持ちとなる。
http-recent-final チェーンでは、パケットがまだ httplist にあるかどうか確認し、あれば、そのパケットを http-recent-final チェーンへ送る。そこで、 httplist からコネクションのエントリを削除し、代わりに http-recent-final リストに登録する。一方、コネクションが既に削除されて http-recent-final リストに登録替えされていたら、パケットは http-recent-final2 へ送る。
http-recent-final2 チェーンでは、まだ締め切っていない方のホストがデータを送りきってコネクションをクローズするのを待つ。それを見届けたら、コネクションをエントリから完全に削除する。
ご覧のように recent のリストは結構複雑な様相を呈するが、必要となれば相当いろいろなことを可能にしてくれる。ただし、車輪をもう一度発明しようなどとは思わないように。必要とする機能が既に実装されているなら、独自の解決策を作ろうとするよりも、既存のものを使うほうが得策だ。
10.3.20. Stateマッチ
state マッチ拡張は、カーネルの備えるコネクション追跡コードを利用して働く。ステートマッチは、コネクション追跡機構にそのパケットのコネクション追跡ステートを問い合わせる。これによって、我々は当該の接続がどういう状態 (state) にあるかを知ることができ、 ICMP や UDP などステートレスなプロトコルも含め、ほとんどあらゆるプロトコルへの対処が可能となる。いかなる場合にも、コネクションにはデフォルトタイムアウトが与えられ、やがてはコネクション追跡データベースから破棄される。このマッチを利用するには、ルールには明示的に -m state 句を入れなくてはならない。それで、 state という新たなマッチが利用可能となる。ステートマッチのコンセプトは、チャプター ステート機構 の中で余すところなく語られている。ここで詳述するには手に余る話題だ。
Table 10-28. Stateマッチオプション
| マッチ | --state |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -m state --state RELATED,ESTABLISHED |
| 説明 | このマッチオプションは、 state マッチに対して、マッチするためにはパケットがどういう状態にあるべきかを指示する。現行で利用できるステートは、 INVALID, ESTABLISHED, NEW, RELATED の 4つ。 INVALID は、パケットがどの把握済みのストリームやコネクションにも属していないか、データかヘッダに異常のあるパケットかのどちらかであることを意味する。 ESTABLISHED は、そのパケットが、既に双方向のパケットが検出された確立済みコネクションの一部であり、パケットが完全に正常であることを意味する。 NEW は、そのパケットが、新しいコネクションを開始する (開始した) ものである、つまり、相互どちらの方向にもパケットがやりとりされたことのないコネクションに属していることを意味する。最後の RELATED は、そのパケットが、新しいコネクションを開始しているが、同時に、既に確立したコネクションに関連しているということを表す。これに当たるのが、例えば、 FTP のデータ搬送や、既存の TCP または UDP コネクションに関係した ICMPエラー などだ。気を付けなければならないのは、 NEW ステートは、新しい接続を開こうとする TCP パケットを、SYN ビット の有無を見て判断しているわけではないという点だ。よって、ファイヤーウォールをひとつしか備えず、他のファイヤーウォールとのロードバランシングも行っていない環境で、 NEW ステートを素のまま使うのは好ましくない。それでもなお、 NEW ステートに利用価値のある場面は出てくる。使い方に関してより詳しく知りたければ、チャプター ステート機構 を読んでいただきたい。 |
10.3.21. TCPMSSマッチ
tcpmss マッチを使用すると、 TCP の最大セグメントサイズ (Maximum Segment Size) に基づいたパケットマッチが行える。このマッチが有効なのは SYN と SYN/ACK パケットのみ。 MSS 値に関する子細に渡る解説は、付録 TCPオプション か、 RFC 793 - Transmission Control Protocol、あるいは RFC 1122 - Requirements for Internet Hosts - Communication Layers などのドキュメントを参照していただきたい。このオプションは -m tcpmss によってロードされ、オプションはひとつだけだ。
Table 10-29. TCPMSSマッチオプション
| マッチ | --mss |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp --tcp-flags SYN,ACK,RST SYN -m tcpmss --mss 2000:2500 |
| 説明 | --mss オプションは tcpmss マッチに対して、ヒットさせる最大セグメントサイズ を伝える。特定の MSS 値をひとつだけ指定することもできるし、 : で区切って範囲で指定することもできる。他のマッチと同じく ! 記号を使って下記のように反転させることも可能だ。 -m tcpmss ! --mss 2000:2500 この例は 2000 から 2500 までを除く全ての MSS 値にマッチする。 |
10.3.22. TOSマッチ
TOS マッチは、パケットの TOS フィールドに基づいてパケットマッチを行う時に使用する。 TOS とは Type Of Service のことで、 IP ヘッダの中にあり、8ビットから成っている。このマッチはルールに -m tos を加えることにより明示的にロードされる。 TOS は通常、経由するホストに対して、そのストリームの優先順位や中身についての連絡を行う (本当はそのようなことは行わないのだが、できるだけ早く送るべきだとか、可能な限り大きなペイロードが必要だといった、ストリームに要求される特別な要件を通知する)。これらの値がどう扱われるかは、ルータや管理者毎で大きく異なる。まったく関知しないものが大半だが、その一方で、当該のパケットとそれによってもたらされるデータに対して、でき得る限りの善処を尽くすものもある。
Table 10-30. TOSマッチオプション
| マッチ | --tos |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A INPUT -p tcp -m tos --tos 0x16 |
| 説明 | このマッチは上記のような使い方をする。 TOS フィールドとそこに持つ値に基づいてパケットのマッチを行う。用途は様々だが、例えば、 iproute2 や、 Linux の高度ルーティング機能と組み合わせて、後で利用するためにパケットに mark を付けるといった使い方がある。引数には、16進、10進の数字の他、 'iptables -m tos -h' で得られる名称のどれかひとつを指定できる。執筆時点では、その出力には以下のものが含まれていた: Minimize-Delay 16 (0x10), Maximize-Throughput 8 (0x08), Maximize-Reliability 4 (0x04), Minimize-Cost 2 (0x02), Normal-Service 0 (0x00)。 Minimize-Delay は、パケットを渡す際の遅延 (daley) を最小限にすることを表し、これを必要とする標準的なサービスには、 telnet、SSH、FTP-control がある。 Maximize-Throughput は、できる限り高スループットの経路を探せ、の意味で、標準的プロトコルでは FTP-data がこれに当たる。 Maximize-Reliability は、コネクションの信頼性をできる限り高く、そして、できる限り信頼性の高いラインを使うことを意味しており、例としては BOOTP と TFTP がある。 Minimize-Cost は、パケットがリンクを辿ってクライアントあるいはサーバまで至る間のコストを最小限にすること、例えば、通過コストの最も小さくてすむ経路を見つけることを表す。これを使用する一般的なプロトコルに、RTSP (Real Time Stream Control Protocol) をはじめとするビデオ/ラジオプロトコルがある。最後の Normal-Service は、特別の要件を持たないあらゆる一般的プロトコルを指す。 |
10.3.23. TTLマッチ
TTL マッチは、 IP ヘッダに存在する TTL (Time To Live) フィールドに基づいてパケットのマッチを行うのに用いる。 TTLフィールド は 8ビットのデータを持ち、クライアント・受け取りホスト間で経由するホストによって中継が行われる度に、ひとつずつ減らされていく。 TTL が 0 に達すると、 ICMP のタイプ 11 コード 0 (TTL equals 0 during transmit) または コード 1 (TTL equals 0 during reassembly) が、パケットを送信してきたホストへ発信され、この障害が通知される。このマッチは TTL に基づいたマッチを行うだけであり、パケットにいかなる変更を加えるものでもない。なお、後者はマッチ全般に当てはまる事柄だ。このマッチをロードするには、ルールに -m ttl を加える必要がある。
Table 10-31. TTLマッチオプション
| マッチ | --ttl-eq |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m ttl --ttl-eq 60 |
| 説明 | このマッチはそのものずばりの TTL の値を指定する時に使う。引数は数字で、それとパケットの中の値との照合を行う。意味の反転など、その他の要素は使えない。このマッチは、ローカルネットワークのデバグなどに活用できる。例を挙げるとすれば、LAN 上のホストがインターネット上のホストへ接続できない時や、トロイの木馬による進入路を検査する時などだ。使い道はかなり限られているが、有効活用は発想次第。例えば、不適切な TTL 値を送ってくるホスト (TCP/IP スタックの不適切な実装や単なる設定ミスが原因だろう) の検知が挙げられる。 |
| マッチ | --ttl-gt |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m ttl --ttl-gt 64 |
| 説明 | このオプションは、指定した値よりも大きな TTL に対してマッチを行う時に使用する。指定可能な値は 0 から 255 までで、反転は通用しない。例えば、或る特定の TTL を超えるパケットをマッチさせて一律の値へと矯正する、といった使い方が考えられる。ポリシーに反して複数のマシンを繋いでいるやつがいたら分かるようにと ISP の仕掛ける極単純な偵察システムを掻い潜るのに使えるだろう。 |
| マッチ | --ttl-lt |
| カーネル | 2.3, 2.4, 2.5, 2.6 |
| 例 | iptables -A OUTPUT -m ttl --ttl-lt 64 |
| 説明 | --ttl-lt マッチは、指定値よりも小さな TTL をマッチさせるのに使う。 --ttl-gt マッチとほぼ同じだが、既に述べたように、こちらは TTL の小さい時にマッチする。使い方の面でも --ttl-gt と同様だが、単純に、自分のネットワークから出て行くパケットの TTL を揃えるという使い方もある。 |
10.3.24. Uncleanマッチ
unclean マッチにはオプション引数はなく、明示的にロードさえすれば利用できる。このオプションは実験的なものとされており、常に動作するとは限らない上、汚染された (unclean) パケットや異常を何から何まで捉えられるわけではないという点にも気を付けなければならない。 unclean マッチは、ヘッダやチェックサムがおかしい場合など、異常の認められるパケットをマッチさせようとする。例えば、コネクションを DROP するのに用いたり、異常、或いは悪意のあるストリームを検知するといった目的に利用可能だ。ただし、正規のコネクションまでもが切断される可能性のあることもまた、承知しておかなければならない。
10.4. まとめ
このチャプターでは、iptables で利用できるマッチと、それらにどんなことができるかについて述べた。ご覧いただいたように、iptables および netfilter のマッチング機能は恐ろしくよくできており柔軟性にも富んでいる。続くチャプターでは、ターゲットの子細について述べ、それらによってどういったことが可能なのかを議論する。Linux を利用したファイヤーウォールの懐の深さにも気づかされることになるだろう。
Chapter 11. iptablesのターゲットとジャンプ
ターゲット (target) とジャンプ (jump) は、ルールの条件部に完全に合致するパケットを、どう処すべきかをルールに指示する。基本的なターゲットとしては、まず、最初に説明する ACCEPT と DROP がある。しかしその前に、ジャンプがどのようなものか簡単に見ておくことにしよう。
ジャンプとターゲットの指定方法は、まったく同じだ。ただし、ジャンプの場合には、ジャンプ先のチェーンが同じテーブル内に存在している必要がある。既に述べたように、ユーザ定義チェーンは -N コマンドで作成する。例を示そう。 filter テーブルに tcp_packets という名前のチェーンを作るとすれば、このようにする:
iptables -N tcp_packets
その後、下記のようにすれば、そこへ飛ぶジャンプターゲットが指定できる:
iptables -A INPUT -p tcp -j tcp_packets
こうすると、 INPUT チェーンから tcp_packets チェーンにジャンプして、 tcp_packets チェーンの中を巡ることができる。もし仮に tcp_packets チェーンの終端に達したら、パケットは INPUT チェーンに戻り、他のチェーン (この場合 tcp_packets) へジャンプさせられた項目の次から先を引き続き進んでいく。パケットがサブチェーンのひとつで ACCEPT された場合には、それは親チェーンでも ACCEPT されたことになり、もう親チェーンの中を進むことはない。ただし、他のテーブルのチェーンは通常通り通っていくことに注意しなければならない。テーブルとチェーンの流れについてのより詳しい説明は、チャプター テーブルとチェーンの道のり を参照していただきたい。
かたや、ターゲットは、当該のパケットに対して起こすアクションを定義する。その例が、目的に応じて使い分ける ACCEPT と DROP だ。施したい処理はこの他にもいろいろあるとは思うが、そうしたアクションについては、このセクションで詳しく述べてゆく。ターゲットへのジャンプは、ターゲットが異なれば、伴う結果も自ずと異なる。一部のターゲットでは、パケットは前述のようにチェーンとその親チェーンの進行をやめる。そうしたルールの例が、 DROP と ACCEPT だ。進行をストップしたルールは、もう、そのチェーンのルールも、親チェーンのルールも巡らない。一方、別のターゲットでは、パケットにしかるべきアクションを起こした後も、パケットは残りのルールを進んでいく。この種の例としては LOG, ULOG, TOS といったターゲットがある。これらのターゲットは、パケットをログ・改変した後、現在のチェーンにおける次のルールへパケットを渡す。このような動作をさせたくなるのは、例えば、あるパケット/ストリームの TTL と TOS をともに変えたい場合だ。一部のターゲットでは追加オプション (TOS の値の設定など) も指定できる一方、どんなオプションも必要としないターゲットも存在する -- ただし必要なら使うこともできる (ログ接頭辞、マスカレード先ポートなど)。これからターゲットを解説していく中で、そういった点についてもできるだけカバーしていく。では、どんな種類のターゲットがあるのか見ていくことにしよう。
11.1. ACCEPTターゲット
このターゲットは他にオプションを必要としない。パケットに求められるマッチ条件が完全に満たされた時、ターゲットに ACCEPT が指定されていると、パケットは受け入れ (accept) され、もう、現在のチェーンも、同じテーブル内のどのチェーンも巡らない。ただし、他のテーブルのチェーンは進んでいくので、そこでパケットが破棄される可能性は残されている。このターゲットには特別な事柄は一切なく、オプションの指定も必要でないし、指定する余地もない。使用するには単に -j ACCEPT を指定するだけだ。
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.2. CLASSIFYターゲット
CLASSIFY ターゲットを使うと、様々な qdisc (Queue Disciplines) に利用できるように、パケットを階級分けすることができる。例えば atm, cbq, dsmark, pfifo_fast, htb, prio といった qdisc に活用できる。 qdisc とトラフィック制御の詳細については Linux Advanced Routing and Traffic Control HOW-TO の WEB ページを訪れてみてほしい。
CLASSIFY ターゲットが有効なのは mangle テーブルの POSTROUTING チェーンの中だけだ。
Table 11-1. CLASSIFYターゲットオプション
| オプション | --set-class |
| 例 | iptables -t mangle -A POSTROUTING -p tcp --dport 80 -j CLASSIFY --set-class 20:10 |
| 説明 | CLASSIFY ターゲットの採る引数は --set-class 唯ひとつだけだ。このオプションはパケットをどんなクラスに階級付けするかをターゲットに指示する。クラスは MAJOR:MINOR というように : で区切ったふたつの値から成る。繰り返しになるが、これ以上のことを知りたければ Linux Advanced Routing and Traffic Control HOW-TO のサイトに行ってみていただきたい。 |
| Linux カーネル 2.5 及び 2.6 で動作する。 |
11.3. CLUSTERIPターゲット
CLUSTERIP ターゲットを使うと、単一の IP と MACアドレスにラウンドロビン方式で応答する単純なクラスターノード群を形成することができる。これは簡易型のクラスターで、クラスターを形成しているすべてのホストにひとつの バーチャルIP (Virtual IP = VIP) を与えておき、応答させたいマシンそれぞれで CLUSTERIP を施すというもの。 CLUSTERIP マッチには特別な ロードバランス (load balancing) ハードウェアや専業マシンは必要ない。クラスターを形成する複数のマシン自体だけで機能が成り立つ。これはクラスターを実現するあくまでも簡易的なひとつの方法であって、大規模なものや複雑な構成には不向きだ。また、ハートビート (heartbeat) を取り扱う機能も内蔵していないが、やろうと思えば簡単なスクリプトを用いて実装することも可能だろう。
クラスターのすべてのマシンは VIP に対して共通の マルチキャストMAC (Multicast MAC) アドレスを持ち、 CLUSTERIP ターゲットは特別なハッシュアルゴリズムを使ってコネクション毎にどのクラスターノードが応答すべきかを決定する。 マルチキャストMAC とは、最初の 24ビットに 01:00:5e を持った MACアドレスで、例えば 01:00:5e:00:00:20 といったものになる。 VIP はどんな IPアドレスでも構わないが、構成ノードすべてで同一でなければならない。
| CLUSTERIP で気を付けなければならないのは、 SSH など幾つかのプロトコルは正常に通信できないことがあるという点だ。コネクション自体は正常に通るのだが、次回同じホストに再び接続しようとした時には、他の実マシン、つまり別の鍵セットをもつマシンに接続されてしまうかもしれない。すると当然、ssh クライアントは接続を拒絶するかエラーを表示する。ある種のプロトコルはこうした理由であまりウマくないことになる。これを避けるためには、保守・管理用としてそれぞれのマシンに別のアドレスも与えておくとよい。他の打開策としては、クラスターに属するマシンすべてで同一の SSHキー を使用する方法もある。 |
クラスター をロードバランスするには 3種類のハッシュモード (hashmodes) が利用できる。ひとつ目は 送信元IP (sourceip) のみのモード、ふたつ目は 送信元IP と 送信元ポート のモード (sourceip-sourceport)、そして 3つ目が 送信元IP, 送信元ポート, 宛先ポート のモード (sourceip-sourceport-destport) だ。 ひとつ目のモードは、コネクションの状態 (state) を記憶しておく必要のある場合に最適で、例えば、ショッピングカートを用いているためコネクションを維持しなければならない WEB サーバの場合に向いている。この方式では ロードバランシング は完全に均等というわけにはいかない (或るマシンが他よりも高い負荷を負うことがあるなど)。同じ 送信元IP から来たコネクションは同一のサーバへ振り向けられるからだ。 sourceip-sourceport ハッシュ方式は、ロードバランシング をより均等化したい場合で、サーバ毎のコネクション状態を維持しなくてもよい時に向いている。例えば、大量の情報を掲載するような WEBページで、検索エンジンは備えているとしても簡易的なものである場合がこれにあたるだろう。最後の ハッシュモード、 sourceip-sourceport-destport は、コネクション毎の状態を一切維持する必要のない複数のサービスを稼働させているホストに適しているだろう。 1台のホスト上で ntp と dns と www サービスをシンプルな構成で動かしている場合などだ。この場合、新たな送信先ポートへのコネクションはその度毎にネゴシエートされる -- いや、実際のところ、この場合には単なる ラウンドロビン システムとして働くわけで、各ホストはコネクションを刹那的にひとつまたひとつと受け入れるだけで、ネゴシエーションといったものは行われない。
CLUSTERIP によってクラスターを構成すると、 /proc/net/ipt_CLUSTERIP ディレクトリに VIP 毎にひとつのファイルが作成される。例えば VIP が 192.168.0.5 だったとすると、 cat /proc/net/ipt_CLUSTERIP/192.168.0.5 とコマンドすれば、このマシンが今どのノードを担当しているかが分かる。別のノード、例えばノード2 の担当もさせるには、echo "+2" >> /proc/net/ipt_CLUSTERIP/192.168.0.5 でノードを加えてやればいい。削除は echo "-2" >> /proc/net/ipt_CLUSTERIP/192.168.0.5 とやる。
Table 11-2. CLUSTERIPターゲットオプション
| オプション | --new |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 80 -j CLUSTERIP --new ... |
| 説明 | このオプションは CLUSTERIP の新しいエントリを生成する。これは当該の VIP を扱う最初のルールで設定しなければならない。これによって新しいクラスターが作成されるわけだ。同一の CLUSTERIP に関係するルールが複数ある場合、2回目以降に VIP を参照する時には --new キーワードは省略しても構わない。 |
| オプション | --hashmode |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 443 -j CLUSTERIP --new --hashmode sourceip ... |
| 説明 | --hashmode キーワードは、生成するハッシュの種類を指定する。 hashmode は以下の 3つのいずれかだ。
hashmodes については既にかなり詳しく述べた。簡単に述べると、sourceip は、比較的パフォーマンスが高く、コネクション間の状態を維持する簡潔な仕組みを持つ反面、実マシンの ロードバランシング という意味ではあまり優れていない。 sourceip-sourceport は速度の面でやや劣るハッシング方式で、コネクション相互の状態もあまり上手く管理できないが、 ロードバランシング としての特性では優れる。最後の sourceip-sourceport-destport はメモリを大量に消費する最も低速なハッシュを形成するが、その反面、ロードバランシング 特性では非常に優れている。 |
| オプション | --clustermac |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 80 -j CLUSTERIP --new --hashmode sourceip --clustermac 01:00:5e:00:00:20 ... |
| 説明 | クラスターがコネクションを待ち受ける、クラスタの MAC アドレス。これが、すべてのホストがリッスンする共通の マルチキャストMAC となる。詳しくは前述の説明を参照していただきたい。 |
| オプション | --total-nodes |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 80 -j CLUSTERIP --new --hashmode sourceip --clustermac 01:00:5e:00:00:20 --total-nodes 2 ... |
| 説明 | --total-nodes キーワードは、リクエストに答えるべくクラスターに参加しているホストの数を指定する。詳しくは前述の説明を参照のこと。 |
| オプション | --local-node |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 80 -j CLUSTERIP --new --hashmode sourceip --clustermac 01:00:5e:00:00:20 --total-nodes 2 --local-node 1 |
| 説明 | クラスター内におけるそのマシンのナンバーを指定する。クラスターは ラウンドロビン で要求に答えるので、新たなコネクションがクラスターに結ばれると次のマシンが返答する。そしてまた今度は次のマシンが...という具合だ。 |
| オプション | --hash-init |
| 例 | iptables -A INPUT -p tcp -d 192.168.0.5 --dport 80 -j CLUSTERIP --new --hashmode sourceip --clustermac 01:00:5e:00:00:20 --hash-init 1234 |
| 説明 | ハッシュの初期化に使用するランダムシードを指定する。 |
| CLUSTERIP ターゲットは RFC 1812 - Requirements for IP Version 4 Routers RFC に反しており、それによって惹起されるトラブルには注意しなければならない。特に、同 RFC のセクション 3.3.2 に規定されている、「全てのルータは、マルチキャストMAC を使用していると主張するホストやルータを信用してはならない」という部分だ。 |
| Linux カーネル 2.6 で機能する。実験的なものと位置づけられている。 |
11.4. CONNMARKターゲット
CONNMARK ターゲットは、 MARK とほぼ同様のやり方で、コネクション単位でマークを付ける。そうしておけば、 connmark マッチを使って後でそのコネクションをマッチさせることができる。例えば、ヘッダに或る特定のパターンが見られることが分かっているが、パケットひとつでなく、コネクションそのものにマークを付けたい場合だ。そんな時に打って付けのソリューションが CONNMARK ターゲットだ。
CONNMARK ターゲットはあらゆるテーブルの全てのチェーンで使用できる。ただし、nat テーブルはコネクションの最初のパケットしか通らないため、2番目以降のパケットに対して CONNMARK ターゲットを掛けようとしても何の効果もないという点に注意してほしい。 CONNMARK ターゲットには以下に述べる 4つのオプションが指定できる。
Table 11-3. CONNMARKターゲットオプション
| オプション | --set-mark |
| 例 | iptables -t nat -A PREROUTING -p tcp --dport 80 -j CONNMARK --set-mark 4 |
| 説明 | コネクションにマークを付ける。マークは unsigned long int (符号なし長整数型) で、つまり有効な値は 0 から 4294967295l となる。 --set-mark 12/8 のようにして特定のビットをマスクすることもできる。この方法を使えば、マークの中の全ビットのうち、マスクで指定したビットだけをセットする [1にする] ことが可能となる。この例では、第4ビット (第3ではない) だけがセットされる。12を 2進数にすると 1100、8 は 1000 であり、マスクに指定されているビットだけがセットを許可されるので、実際にマークされるのは第4ビットだけ (つまり8) となる。 |
| オプション | --save-mark |
| 例 | iptables -t mangle -A PREROUTING --dport 80 -j CONNMARK --save-mark |
| 説明 | --save-mark ターゲットを使うと、パケットマークをコネクションマークに記録することができる。例えば、既に MARK ターゲットでマークを付けてあるパケットがあった場合、 --save-mark を使用すればそのマークをコネクション単位のマークへと移動できるわけだ。また、マークは後述の --mask オプションでマスクすることも可能だ。 |
| オプション | --restore-mark |
| 例 | iptables -t mangle -A PREROUTING --dport 80 -j CONNMARK --restore-mark |
| 説明 | このターゲットオプションは、 CONNMARK で定義されているコネクションマークに基づいてパケットのマークを再設定 (restore) する。下に述べる --mask オプションでマスクを指定することもできる。マスクを指定した場合、マスク後のオプションだけが設定される。このターゲットは mangle テーブルでのみ使用できるという点に注意。 |
| オプション | --mask |
| 例 | iptables -t mangle -A PREROUTING --dport 80 -j CONNMARK --restore-mark --mask 12 |
| 説明 | --mask オプションは必ず --save-mark か --restore-mark オプションと組み合わせて使用しなければならない。これは、ふたつのオプションの指定するマーク値に対して適用する、論理積マスク (and-mask) を定義する。例えば、上記で restore の対象としているマークが 15 だったとすれば、マークは 2進数で 1111、マスクは 1100。1111 と 1100 の論理積は 1100 となる。 |
| Linux カーネル 2.6 で機能する。 |
11.5. CONNSECMARKターゲット
CONNSECMARK ターゲットは、 SELinux セキュリティ・コンテキスト (SELinux security context マークを、パケットに付けたり、パケットから取得したりする。 SELinux についての詳しいことは Security-Enhanced Linux のホームページを読んでいただきたい。このターゲットは mangle テーブルでのみ有効であり、 SECMARK ターゲットと併用しなければならない。 SECMARK ターゲットでまずマークを付けておき、それから CONNSECMARK でコネクションにマークを付けるのだ。
SELinux は当ドキュメントでの扱いを超えるが、簡単に言うと、Linux への 強制アクセス制御 (Mandatory Access Control) の実装であり、Linux/Unix の備える元来のセキュリティ制御よりもよく出来ている。オブジェクトにはそれぞれセキュリティ属性 (セキュリティ・コンテキスト と呼ぶ) が関連付けられ、特定のタスクの実行の許可や拒否を判断するためにこれらの属性が照会される。このターゲットを使用すると、コネクションに対して セキュリティ・コンテキスト をセットすることができる。
Table 11-4. CONNSECMARKターゲットオプション
| オプション | --save |
| 例 | iptables -t mangle -A PREROUTING -p tcp --dport 80 -j CONNSECMARK --save |
| 説明 | まだそのコネクションがマークされていなかった場合に、パケットの セキュリティ・コンテキスト マークを取得してコネクションにそのマークを与える。 |
| オプション | --restore |
| 例 | iptables -t mangle -A PREROUTING -p tcp --dport 80 -j CONNSECMARK --restore |
| 説明 | --restore オプションは、そのパケットに セキュリティ・コンテキスト マークが付いていなかった場合に、コネクションに関連づけられている セキュリティ・コンテキスト マークをそのパケットに付ける。 |
11.6. DNATターゲット
DNAT ターゲットは宛先ネットワークアドレス変換 (Destination Network Address Translation)、つまり、パケットの宛先 IPアドレスを書き換えるために用いる。パケットがマッチした時、ルールにこのターゲットが指定されていると、当該のパケットとその同じストリームに乗っている後続パケットは変換され、しかるべきデバイスあるいはホスト、ネットワークへルーティングされる。このターゲットは非常に便利だ。例えば、 WEB サーバを走らせているホストが LAN 内にあるが、インターネットで有効な本物の IPアドレスを与えられていない場合だ。その時、ファイヤーウォールに対して、 HTTP ポート宛てに送られてきたパケットを LAN 内の WEB サーバへ転送するよう指示しておけばいいのだ。また、 IPアドレスの範囲を指定することも可能で、そうすると、 DNAT メカニズムはその中から IPアドレスをランダムに選ぶ。これによって、一種の負荷分散 (load balancing) が可能となる。
以下、注意点だが、 DNAT ターゲットは nat テーブルの PREROUTING と OUTPUT チェーンおよび、それらのチェーンから呼ばれたチェーンでのみ有効だ。また、 DNAT ターゲットを含むチェーンは、 POSTROUTING をはじめとする他のチェーンから呼ばれて使われることはない。
Table 11-5. DNATターゲットオプション
| オプション | --to-destination |
| 例 | iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10 |
| 説明 | --to-destination オプションは、 DNAT メカニズムに対して、 IP ヘッダに設定したい宛先 IP と、マッチしたパケットの行き先を指示する。上記の例は、 IPアドレス 15.45.23.67 に宛てられたすべてのパケットを、LAN の IP 192.168.1.1 から 10 の範囲へ送る。既に述べたように、ひとつのストリーム中では常に同じホストが使用されるが、ストリームが異なれば、各ストリームが使うべき宛先 IPアドレスはランダムに選択される。また、単一の IPアドレスを指定することも可能で、そうすれば、接続は常にそのホストへ導かれる。さらに、トラフィックをリダイレクトする宛先ポートまたはポート範囲を追加指定することも可能だ。これは、パケットの DNAT 先 IPアドレスに、例えば :80 の記述を加えることによって指定できる。その場合の記述は --to-destination 192.168.1.1:80 のようになるし、ポートを範囲で指定した場合なら --to-destination 192.168.1.1:80-100 のようになる。お気づきの方もおられようが、行う事柄は決定的に異なっていながら、 SNAT ターゲットは DNAT ターゲットとほとんど同じ書式を採る。ポート指定は、 --protocol オプションで TCP か UDP を指定したルールでしか有効でないという点に注意しよう。 |
DNAT を適正に動作させるためには、かなりいろいろな準備をしなければならない。そこで僕は、 DNAT への取り組み方について、詳しい説明を加えることにした。通常行うことになる事柄を、簡略な例で見てみることにしよう。我々は今、 WEB サイトを、インターネット接続を利用して公開しようとしているとする。持っている IPアドレスはひとつだけで、 HTTP サーバはローカルネットワーク内にある。ファイヤーウォールの外部 IPアドレスを $INET_IP、 HTTP サーバの持つ内部向け IPアドレスを $HTTP_IP、ファイヤーウォールの内部向け IPアドレスを $LAN_IP とする。最初にやらなければならないのは、 nat テーブルの PREROUTING チェーンに下記のシンプルなルールを追加することだ。
iptables -t nat -A PREROUTING --dst $INET_IP -p tcp --dport 80 -j DNAT \
--to-destination $HTTP_IP
これで、ファイヤーウォールの 80番ポートに宛てて送られてきたパケットは全部、内部の HTTP サーバへリダイレクト (つまり DNAT) されるようになった。インターネット側からテストしたら、完璧に動作するはずだ。では、 HTTP サーバと同じローカルネットワーク内にいるホストが接続してこようとしたらどうなるか。ずばり、動作しない。ここがまさに、ルーティングの難しいところだ。では、ことの成り行きを、まず、通常の場合から見てみよう。混乱を避けるために、外界のマシンが持っている IPアドレスを $EXT_BOX としておこう。
パケットが外部ホストを離れ
$INET_IPへ向かう。送信元は$EXT_BOX。パケットがファイヤーウォールに到着。
ファイヤーウォールがパケットを DNAT し、その他のチェーンへ流す、など。
パケットはファイヤーウォールを離れ
$HTTP_IPへ向かう。パケットが HTTP サーバに到着。
$EXT_BOXへのデフォルトゲートウェイとしてファイヤーウォールの内部用 IP がルーティングデータベースに記録されていれば、 HTTP サーバは、ファイヤーウォールを介して返事をよこす。普通なら、ファイヤーウォールの内部用 IP は HTTP サーバのデフォルトゲートウェイになっているだろう。ファイヤーウォールはパケットを 逆DNAT する。これによって、このパケットはあたかもファイヤーウォール自体が発した返答のように見える。
返答パケットは平常通りにクライアント
$EXT_BOXへ戻る。
次に、パケットが、 HTTP サーバと同じネットワーク内にいるホストが発行したものだった場合の成り行きを考えてみよう。クライアントの IPアドレスは $LAN_BOX、その他のマシンの条件は上記と同じとする。
パケットが
$LAN_BOXを離れ$INET_IPへ向かう。パケットがファイヤーウォールに到着。
パケットは DNAT され、その他様々な処理を施される。ただし、SNAT はされず、故にパケットの送信元アドレスは変わらない。
パケットはファイヤーウォールを離れ HTTP サーバに到着する。
HTTP サーバはパケットに返答しようと、ルーティングデータベースを照合する。それによると、このパケットは同じネットワークのローカルマシンから来たことが判明する。よって、 HTTP サーバはパケットをそのままずばりの IPアドレス (この時は宛先 IPアドレスとして) に直接送ろうとする。
パケットがクライアントに届く。だがここで、返答のパケットが元々自分の指定したリクエスト先とは違うところから来ているので、クライアントは困惑する。結果、クライアントはこのパケットを破棄し、"本物" の返事を待ち続ける。
この問題の手っ取り早い解決策は、ファイヤーウォールへ入ってきたパケットの行き先が、これから DNAT で振り向けようと目論んでいるホストや IP になっていた場合には、それらのパケットにもれなく SNAT を掛けることだ。上記のルールを考察してみよう。ファイヤーウォールに入ってくる、宛先が $HTTP_IP の 80番ポートであるパケットには、それらが $LAN_IP から来たように見せるために SNAT を掛ける。すると、 HTTP サーバに対して、パケットをファイヤーウォールへと返信するよう強制でき、ファイヤーウォールはそのパケットを 逆DNAT するので、パケットは最初のクライアントへ送られることとなる。ルールはこういったものになるだろう:
iptables -t nat -A POSTROUTING -p tcp --dst $HTTP_IP --dport 80 -j SNAT \
--to-source $LAN_IP
POSTROUTING チェーンが処理されるのは、すべてのチェーンのうちで最後だということを頭に入れておこう。つまり、当該のチェーンに入ってくる時には、パケットは既に DNAT されている。内部向けアドレスでパケットをマッチさせているのは、そのためだ。
| 最後に挙げたルールはロギングに多大な悪影響を与えるため、この方法を用いるのは決してお勧めできない。とはいえ、上の例全体は働かないわけではない。影響とは以下のようなものだ: パケットがインターネット側からやってくると、 SNAT および DNAT を受け、 HTTP サーバ (例えば) に到達する。今や、 HTTP サーバはこのパケットはファイヤーウォールから来たと思い込んでいるので、インターネットから入ってきたリクエストを、どれもこれも、すべてファイヤーウォールから来たものとしてログしてしまうのだ。 これには更にもうひとつ、重大な副作用がある。LAN 内に SMTP サーバがあり、ローカルネットワーク内からのリクエストは受け入れるように設定してあるとする。そして、 SMTP トラフィックを SMTP サーバへ転送するよう、ファイヤーウォールを設定する。すると、見事なオープンリレーが出来上がってしまうのだ。しかも、ログは身の毛もよだつような代物となる。 ひとつの解決策は、早い話が上記の SNAT ルールをもっと限定的にして、内側の LAN インターフェイスから入ってくるパケットにだけ作用するようにすることだ。つまり、どのコマンドにも --src $LAN_IP_RANGE を加えるわけだ。こうすれば、ルールは LAN からやってくるストリームだけに作用するようになり、よって、送信元IPアドレスに影響を与えることは無くなる。その結果、ログは正しく書かれる、ただし LAN 内からのストリームは別だ。 言い換えれば、LAN のための専用 DNS サーバを置くか、本格的に DMZ を設けて切り離すほうが、解決策としては遙かに上だ。お金に余裕があるなら、後者のほうがいい。 |
取り敢えずこれで充分だと思っているだろう。確かにそうだ。ただし、このシナリオを仕上げるには、まだひとつ視点が抜けている。もし、ファイヤーウォール自体が HTTP サーバにアクセスしようとしたら? 今の状態では残念ながら、ファイヤーウォール自身の HTTP サーバに接続しようとするばかりで、 $HTTP_IP である本当のサーバへ向かおうとはしない。この問題を切り抜けるには、さらに、 OUTPUT チェーンに DNAT ルールを加える必要がある。上記の例に従えば、ルールはこのようなものになる:
iptables -t nat -A OUTPUT --dst $INET_IP -p tcp --dport 80 -j DNAT \
--to-destination $HTTP_IP
このルールの追加で、すべての体制は整った。 HTTP サーバの含まれるネットワーク以外のネットは何の滞りもなく動作する。 HTTP サーバと同じネットワークにいるホストも接続できる。そして、ファイヤーウォールも正常な接続が行える。すべてはうまくいき、問題はなにもない。
| 上に挙げたルールには、パケットを適切に DNAT と SNAT するという作用だけしかないという点を認識しておいていただきたい。実際には、パケットにこれらのチェーンを巡回させるために、上記のルール以外にも、 filter テーブル (FORWARD チェーン) に幾つかのルールが必要となるだろう。その際には、パケットは既に PREROUTING を通過済みであり、 DNAT によって宛先アドレスが書き換えられているということを忘れないようにしよう。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.7. DROPターゲット
DROP ターゲットは文字通りのことを行う。パケットを黙殺し、そこから後の処理は一切行わない。マッチ条件に完全に合致し DROP を受けたパケットはブロックされる。このアクションは、時に望まざる結果をもたらすことに注意しなければならない。"死んだ" ソケットが双方に放置されてしまうのだ。そういった事態が頻発する場合には REJECT ターゲットを使ったほうがいい。その代表的なケースが、フィルタを掛けているポートなどへ向けられたポートスキャナに情報をなるべく渡さないようにしたい場合だ。もうひとつの注意点は、サブチェーンでパケットが DROP されると、そのパケットはもう、親チェーンばかりでなく、他のテーブルに存在するどのチェーンも一切通らないということ。つまり、パケットは完全に死ぬのだ。前述したが、このターゲットは、どちらの方向にも、ルータをはじめとする中継機にさえも、いかなる種類の通知も送らない。
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.8. DSCPターゲット
これはパケット内部の DSCP のマーキング (Differentiated Services フィールド) を変更するターゲットだ。 DSCP ターゲットは TCP パケットにどんな DSCP 値でも与えることができる。 DSCP 値は、ルータにそのパケットの優先度を指示するひとつの手段だ。 DSCP の詳細については RFC ドキュメント RFC 2474 - Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers を参照して頂きたい。
簡単に言うと、 DSCP はサービスを格付けしてカテゴリー分類するための手段だ。このカテゴリーに基づいて、ルータにそれらの扱いの優劣をつけさせることができる。そうすると、ひとかたまりのバルク転送には適さない対話型の TCP コネクション (例えば telnet や SSH, POP3 など) に高速なコネクションを優先的に与えられる。また反対に、重要度の低いコネクション (SMTP にせよ何にせよ、あなたが優先度が低いと認めるサービス) に関しては、使うにはもったいない高速で低遅延のコネクションではなく、比較的遅延の大きい溜め出し状態のネットワークで送るようすることができる。
Table 11-6. DSCPターゲットオプション
| オプション | --set-dscp |
| 例 | iptables -t mangle -A FORWARD -p tcp --dport 80 -j DSCP --set-dscp 1 |
| 説明 | これは DSCP を任意の値に設定するものだ。値は、下記で述べるようにクラスで与えることもできるし、 --set-dscp を使って 10進または 16進数の値を設定することもできる。 |
| オプション | --set-dscp-class |
| 例 | iptables -t mangle -A FORWARD -p tcp --dport 80 -j DSCP --set-dscp-class EF |
| 説明 | DSCP フィールドを、定義済みの DiffServ クラスで指定する。指定可能な値としては EF, BE, CSxx, AFxx などがある。詳しくは Implementing Quality of Service Policies with DSCP のサイトで知ることができる。注意しなくてはならないのは、 --set-dscp-class と --set-dscp は排他、つまり、ひとつのコマンドの中ではどちらか一方しか使用できないということだ。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.9. ECNターゲット
正しく使えば非常に有益なターゲットだ。簡単に言えば、これを使用すると IPv4 ヘッダの ECN ビットをリセットできる。もう少し正確に言うと、少なくとも ECN ビットを 0 へとリセットすることができる。 ECN はネットの世界では比較的新しい規格であるため、問題を生じさせることがあるのだ。そのひとつは、 ECN が、旧来の TCP プロトコルの RFC では 0 になっていなければならないとされているふたつのビットを使用するという点。ルータやアプライアンスによっては、それらのビットが 1 になっているパケットを中継しないものがある。管理するネットワーク内で ECN 機構の何か一部分でも利用する場合、 ECN のせいで到達できないことが分かっているネットワークに対しては、そこへ向かうパケットの ECN ビットを 0 に戻す、といった使い方ができる。
| ひとつのストリームの中で途中から ECN をオンにすることはできないということを憶えておいていただきたい。 RFC に反しているし、そもそもやろうとしても不可能だ。 ECN はコネクションの両端でネゴシエートされなければならない。 ECN をオンにしたとしても、もう一方のホストはその事実を知らないので、 ECN 通知に応えることはできないのだ。 |
Table 11-7. ECNターゲットオプション
| オプション | --ecn-tcp-remove |
| 例 | iptables -t mangle -A FORWARD -p tcp --dport 80 -j ECN --ecn-tcp-remove |
| 説明 | ECN ターゲットの採る引数は --ecn-tcp-remove ひとつだけ。このオプションは TCP ヘッダ内の ECN ビットを取り除くよう ECN ターゲットに指示する。詳しくは上記。 |
| Linux カーネル 2.5, 2.6 で機能する。 |
11.10. LOGターゲット
LOG ターゲットはパケットに関する詳細な情報をログするという特別な用途のために設計されている。考えようによっては違法行為と言えなくもない。言い換えれば、ロギングが使用できるのは、純粋なバグ狩りとエラー検出を目的とする場合だけだ。 LOG ターゲットはパケットに関する固有の情報を返してくる。大部分の IP ヘッダの他、およそ興味深いと思われる情報のほとんどだ。ログの出力はカーネルのロギング機能 (通常は syslogd) を介して行われる。それらの情報は、 dmesg で直接読んだり、syslogd のログを通じて、あるいはその他のプログラムやアプリケーションを使って読むことができる。パケット毎の行き先や、どんなパケットにどんなルールが適用されているのかが分かるので、ルールセットをデバグする用途には非常に優れたターゲットとなる。また、すでに運用中のファイヤーウォールで 100% 確信の持てないルールをテストする際に、 DROP の代わりに LOG ターゲットを使ってみるというのも名案だ。というのも、 DROP にした場合、ルールセットに 1カ所でも文法エラーがあると、接続障害など深刻な影響をユーザに与えてしまうからだ。また、極めて詳細なロギングを行いたい向きには ULOG ターゲットが面白いだろう。 ULOG ターゲットなら MySQL などへのダイレクトロギングをサポートしている。
| 無用なログがコンソールに直接吐き出されるという現象が見られる場合、それは iptables あるいは Netfilter の問題ではない。専ら、 syslogd の設定 (たいていは /etc/syslog.conf) によって引き起こされる問題だ。この種の問題に関しては、 man syslog.conf を読み直すといいだろう。 また、 dmesg の設定を変更する必要もあるかもしれない。 dmesg はカーネルからのエラーメッセージを選択的に表示させるコマンド。 dmesg -n 1 とすれば panic メッセージのみをプリントさせることができる。 dmesg でいうレベルは syslogd のレベルと同じものだが、 dmesg では kernel ファシリティに属するログメッセージのみが対象となる。詳しくは man dmesg を参照のこと。 |
現在のところ、LOG ターゲットには、収集したい情報の種類や、設定したいオプション値の種類に応じて、皆の興味を惹くであろう 5つのオプションが設定可能となっている。下記にそのすべてを挙げた。
Table 11-8. LOGターゲットオプション
| オプション | --log-level |
| 例 | iptables -A FORWARD -p tcp -j LOG --log-level debug |
| 説明 | iptables と syslog に、どのログレベルを使うかを指示する。ログレベルの全リストを知りたければ、syslog.conf のマニュアルを読むこと。通常、以下のログレベル (プライオリティとも呼ばれる) がある: debug, info, notice, warning, warn, err, error, crit, alert, emerg, panic。 error キーワードは err と同義、 warn は warning と、 panic は emerg と同義だ。これら 3 つは時代遅れで使われなくなっている (deprecated)。言い換えれば、err, warn, panic は使うべきでないということだ。プライオリティ (priority) はログされるメッセージの重篤度 (severity) を指定する。メッセージはすべて kernel ファシリティ (facility) でログされる。つまり、 syslog.conf ファイルで kern.=info /var/log/iptables を定義し、 iptables にログレベル info を使わせれば、 /var/log/iptables ファイルにログが集まる。ただし、このファイルには、カーネル関連で info プライオリティを使っている他のサービスのログも書き込まれることになるので注意。ロギングの詳細については、 syslog、 syslog.conf の man ページや、その他の HOWTO などを読むことをお勧めする。 |
| オプション | --log-prefix |
| 例 | iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets" |
| 説明 | このオプションは、ログメッセージに特定の接頭辞 (prefix) を付けるよう iptables に指示する。これを使えば、 grep などのツールと併用して、特定の問題やルールが楽に調べられる。接頭辞は 29文字までで、スペースと記号も使用できる。 |
| オプション | --log-tcp-sequence |
| 例 | iptables -A INPUT -p tcp -j LOG --log-tcp-sequence |
| 説明 | このオプションは、ログメッセージに加えて、TCPシーケンスナンバー をログする。TCPシーケンスナンバー とはパケットの識別に使用される特別なナンバーで、各パケットの識別と、そのパケットがどの TCPシーケンス に該当するかを特定するため、そしてもちろん、ストリームを組み立て直すためにも利用されている。このオプションは、ログが権限のないユーザに読み込み可能な場合や誰にでも読める場合にはセキュリティリスクになるという点に注意しなければならない。これは iptables からの出力を含むログすべてに言えることだ。 |
| オプション | --log-tcp-options |
| 例 | iptables -A FORWARD -p tcp -j LOG --log-tcp-options |
| 説明 | --log-tcp-options オプションは TCP パケットのヘッダから読み取った様々なオプションをログする。どういった不具合が起こりうるか、あるいは既に起こっているかをデバグしたい時、何物にも代え難い武器となる。ほとんどの LOG オプションがそうであるように、このオプションも変数フィールドに類するものは何も採らない。 |
| オプション | --log-ip-options |
| 例 | iptables -A FORWARD -p tcp -j LOG --log-ip-options |
| 説明 | --log-ip-options オプションは IP パケットヘッダにあるほとんどのオプションをログする。これは --log-tcp-options とまったく同様に働き、違いは、対象が IP のオプションであるという点だけだ。これによるログメッセージは、特定の障害の切り分けやトレースを行いたい時に便利だ。もちろん、前記オプションと同様にデバグに活用することもできる。 |
| Linux カーネル 2.3, 2.4, 2,5, 2.6 で機能する。 |
11.11. MARKターゲット
MARK ターゲットは、特定のパケットに関連付けされる Netfilter マークを設定するために用いられる。このターゲットは mangle テーブルのでのみ有効で、それ以外の場所では使えない。 MARK の値は、 Linux の高度ルーティング機能と組み合わせて、パケットの種別によって経由先ルータを換えたり、キューイング規則 (qdisc = queue disciplines) を切り替える、といった使い方が考えられる。高度ルーティングについてのより詳しい情報は、 Linux Advanced Routing and Traffic Control HOW-TO を見てみてほしい。留意点だが、マークは、パケットに関連付けされた値であって、パケットそのものにくっつくわけではなく、カーネル内に保持される。つまり、パケットに MARK を付けておいて、そのパケットが他のホストに到着してもまだ MARK が付いていると考えるのは間違いだ。そういったことを行いたいのなら、 IP ヘッダの中の TOS の値を改変できる TOS ターゲットのほうを使うべきだ。
Table 11-9. MARKターゲットオプション
| オプション | --set-mark |
| 例 | iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2 |
| 説明 | --set-mark オプションはマーク を付けるのに必要となる。 --set-mark の引数は整数。例えば、特定のストリームのパケット、あるいは特定のホストからのパケットにマーク 2 を与えておき、ホストに応じた高度ルーティングを行ってネットワークの帯域幅を規制する (あるいは確保する) といった利用法が想定できる。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.12. MASQUERADEターゲット
MASQUERADE ターゲットは、基本的には SNAT ターゲットと同じだ。ただし、 --to-source オプションは必要でない。なぜかといえば、 MASQUERADE ターゲットは、ダイヤルアップ接続、DHCP など、つまり、目的のネットワークへの接続に動的な IPアドレスを使用する接続で機能するようにできているからだ。即ち、 MASQUERADE ターゲットは、動的に割り当てられる IPコネクション、つまり、実際のアドレスが変化するためそのアドレスが分からないようなコネクションでのみ、使うようにしなければならない。固定的な IP 接続なら、代わりに SNAT ターゲットを使用すべきだ。
接続を MASQUERADE することは、 --to-source オプションの代わりに特定のネットワークインターフェースの IPアドレスを指定しているのと同じだ。その IPアドレスは、特定のインターフェースに関する情報から自動的に捕捉される。 MASQUERADE ターゲットにはもうひとつ、或るインターフェースが無効になるとコネクションも忘れ去られるという特性がある。これは、例えば特定のインターフェースを殺したい場合に非常に有効な特性だ。もし SNAT ターゲットを使っていたら、コネクション追跡データが残ったままになり、それらは時には何日間も放置されることもあるので、せっかくのコネクション追跡メモリが食いつぶされてしまう。 MASQUERADE ターゲットのこの仕組みは、一般的に、ダイアルアップ接続に対して妥当とされる。接続が確立される度に異なった IP が割り当てられる確率が高いからだ。割り当て IP が変われば今までのコネクションはどのみち無効になるので、エントリを持ち続けるのも間抜けな話ではなかろうか。
IP が固定の場合でも、SNAT の代わりに MASQUERADE ターゲットを使うこともできなくはない。あまりお勧めでないのは、余計なオーバーヘッドがあることと、運用しているうちに矛盾を生じ、既存のスクリプトを駄目にして "使用不能" にしてしまう可能性があるからだ。
MASQUERADE ターゲットは、 SNAT ターゲットと同様に、 nat テーブルの POSTROUTING チェーンでのみ有効だという点に気を付けなくてはならない。 MASQUERADE ターゲットは、省略可能な下記のオプションを採ることもできる。
Table 11-10. MASQUERADEターゲットオプション
| オプション | --to-ports |
| 例 | iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000 |
| 説明 | --to-ports オプションは、出ていくパケットに使用させる送信元ポート (複数可) を指定するために用いる。 --to-ports 1025 のように単一のポートも指定できるし、ポート範囲で --to-ports 1024-3000 のような指定も可能だ。つまり、範囲の上下ポートはハイフンで区切る。これは、SNATターゲット のセクションで述べている SNAT の規定動作による選択ポートを、変更していることになる。 --to-ports オプションは、ルールのマッチ条件部で --protocol マッチを使って TCP か UDP を指定している場合にのみ使用することができる。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.13. MIRRORターゲット
| あらかじめ警告しておく。 MIRROR は危険なターゲットであり、 conntrack と NAT が登場した際にひとつのコード例として書かれたものにすぎない。非常に危険な状況を招き、使用を誤ると深刻な DDoS/DoS に陥る可能性がある。他のいかなる手段を用いてでも MIRROR の使用は避けるべきだ。セキュリティ上の不備を理由に、このターゲットはカーネル 2.5 及び 2.6 からは削除されたのだ! |
MIRROR ターゲットは、あくまでも実験的な、デモンストレーション用のターゲットで、使用は慎むべきだということを警告しておく。というのも、これは酷いループを引き起こし、最悪、サービス不能 (Denial of Service) に陥ることもあるからだ。 MIRROR ターゲットは、 IP ヘッダの送信元と宛先を入れ替えてパケットを送り出すためのもの。大変おかしな効果をもたらすが、このターゲットのせいで自分のマシンをクラックする羽目になり真っ赤になって怒るクラッカーがいたなんて話は、賭けてもいいが、今まで一度も耳にしたことがない。このターゲットで成し得る効果は、控えめに言っても狂気の沙汰だ。例えばここに、80番ポートに対して MIRROR ターゲットを設定してある A というコンピュータがあったとしよう。ホスト B が yahoo.com からやってきて、ホスト A の HTTP サーバにアクセスを試みたとすると、 MIRROR ターゲットは yahoo ホスト自身の WEB ページ (そこがリクエストの出どころだから) を返す結果となる。
注意は、 MIRROR ターゲットは INPUT、FORWARD、PREROUTING チェーンおよび、それらから呼ばれたユーザ定義チェーンでしか有効でないこと。また、 MIRROR ターゲットの結果として出ていくパケットは、filter、nat、mangle のどの通常テーブルからも見えない。見えたとしたら、ループをはじめとして様々なトラブルの原因となってしまう。ここが、このターゲットが頭痛の種と成り得る理由であり、しかも何が起こるかは皆目見当がつかない。例を挙げよう。あるホストが MIRROR ターゲットを使用している別のホストへ、成りすまし (spoof) を掛けたパケットを TTL 255 で送ったとする。なお且つ、そのパケット自体、やはり MIRROR ターゲットを使っている第3 のホストから来たように偽装している。するとパケットは、所定のホップ数が完結するまで、ひっきりなしに往き来を繰り返し始める。仮にホップが 1 だったとしても、パケットの往き来は 240 から 255回に達する。クラッカーにとっては悪くない話だ。つまり、1500バイトのデータを送りつければ、コネクションの 380k バイトを食い尽くすことができる。クラッカー、悪戯者、といった類の輩にとって、こんなおいしい話はない。
| Linux カーネル 2.3, 2.4 で機能する。安全面での根本的欠陥のため、カーネル 2.5 及び 2.6 からは削除された。このターゲットは使ってはならない。 |
11.14. NETMAPターゲット
SNAT や DNAT では IPアドレスのホスト部分は変わらないが、 NETMAP は、そこに新しい機能を装備したものだ。 NETMAP はこれまでの SNAT, DNAT にはない、ネットワーク単位の 1:1 NAT 機能を提供する。例を示そう。ここに、プライベート IPアドレスを持つ 254台のホスト (/24 のネットワーク) と、パブリック IP で成るまっさらの /24 のネットワークがあるとしよう。従来ならば各ホストに対して逐一 IP を変換をするところだが、 NETMAP ターゲットを -j NETMAP -to 10.5.6.0/24 といった具合に使うと、あ〜ら不思議、ファイヤーウォールを出る時には、ホストのどれもが 10.5.6.x として見えるのだ。 192.168.0.26 なら 10.5.6.26 になるといった具合だ。
Table 11-11. NETMAPターゲットオプション
| オプション | --to |
| 例 | iptables -t mangle -A PREROUTING -s 192.168.1.0/24 -j NETMAP --to 10.5.6.0/24 |
| 説明 | これが NETMAP ターゲット唯一のオプション。上記の例だと、 192.168.1.x のホスト群が根こそぎ 10.5.6.x へと変換される。 |
| Linux カーネル 2.5 と 2.6 で機能する。 |
11.15. NFQUEUEターゲット
NFQUEUE ターゲットの使い方はほぼ QUEUE ターゲットと同じで、その拡張版といったところ。 NFQUEUE ターゲットを使うとパケットを別々のキューに入れることができる。キューは 16ビットの ID で指定/区別する。
このターゲットを動作させるにはカーネルが nfnetlink_queue をサポートしている必要がある。この NFQUEUE ターゲットでどういったことができるかは、 QUEUEターゲット を参照してほしい。
Table 11-12. NFQUEUEターゲットオプション
| オプション | --queue-num |
| 例 | iptables -t nat -A PREROUTING -p tcp --dport 80 -j NFQUEUE --queue-num 30 |
| 説明 | --queue-num オプションは、キューイングされるデータを送るためのキューを指定する。このオプションを省略した時にはキューID 0 が使用される。キューナンバーは 16ビット unsigned integer なので、0 から 65535 までの値が使用できることになる。0 番キューは QUEUE ターゲットでも使用される。 |
| Linux カーネル 2.6.14 以降で機能する。 |
11.16. NOTRACKターゲット
このターゲットを使うと、そのルールにマッチした全パケットに対してコネクション追跡を無効にすることができる。当ターゲットについてはチャプター ステート機構 の 追跡除外コネクションとrawテーブル セクションで幾らか詳しく述べている。
NOTRACK ターゲットにオプションはなく、使い方は簡単。追跡させたくないパケットをマッチさせて、マッチさせたルールで NOTRACK ターゲットを仕掛けるだけだ。
| このターゲットが使えるのは raw テーブルの中だけだ。 |
| Linux カーネル 2.6 (後期) で機能する。 |
11.17. QUEUEターゲット
QUEUE ターゲットは、パケットをユーザ空間のプログラムやアプリケーションへキューイングするために用いられる。これは、 iptables とはゆかりのないプログラムやユーティリティと組み合わせて使い、例えば、ネットワークアカウンティングや、パケットのプロキシやフィルタリングなどを行う特殊且つ高度なアプリケーションへの使用が考えられる。そのようなアプリケーションのプログラミングはチュートリアルの守備範囲を外れるので、このターゲットについてこれ以上踏み込むのはやめておく。まず第一に、説明に時間がかかりすぎるし、第二に、内容も Netfilter や iptables のプログラミングとは無関係なものとなってしまうからだ。そうした事柄はすべて Netfilter Hacking HOW-TO にかなり詳細に網羅されている。
| カーネル 2.6.14 の時点で、netfilter の動作が変更になった。 QUEUE との遣り取りの仕組みが再開発され、nfnetlink_queue というものになったのだ。最近のものでは、 QUEUE ターゲットはそもそも NFQUEUE 0 へのポインタとなっている。プログラミング上の疑問点があれば、先ほど挙げたリンクがやはり役に立つだろう。このターゲットの動作には nfnetlink_queue.ko モジュールが必要だ。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.18. REDIRECTターゲット
REDIRECT ターゲットは、パケットやストリームをそのマシン自体へリダイレクトするために使用する。これにより、例えば HTTP ポート宛のパケットをすべて、自機上の Squid などのプロキシへリダイレクトすることができる。ローカルで作られたパケットがアドレス 127.0.0.1 へマッピングされるわけだ。言い方を変えれば、フォワードされるパケットの宛先アドレスを自分へと書き換えるようなものだ。 REDIRECT ターゲットは、 LAN 上のホストにプロキシの存在を明示しない 透過プロキシ を行う場合などに打ってつけの選択といえるだろう。
REDIRECT ターゲットは nat テーブルの PREROUTING、OUTPUT チェーンおよび、それらのチェーンから呼ばれるユーザ定義チェーンでのみ有効である点に注意しなければならない。その他では機能しない。 REDIRECT ターゲットは、下記に示すひとつのオプションしか採らない。
Table 11-13. REDIRECTターゲットオプション
| オプション | --to-ports |
| 例 | iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080 |
| 説明 | --to-ports オプションは、使用すべき宛先ポートあるいは宛先ポートの範囲を指定する。 --to-ports オプションがない場合、宛先ポートは変化しない。指定は上記のようにし、単一ポートを指定したい時には --to-ports 8080 のようになる。ポートを範囲で指定したい場合には --to-ports 8080-8090 のようになり、これは REDIRECT ターゲットに対して、そのパケットを 8080 から 8090 までのポートへリダイレクトするよう指示する。このオプションは --protocol オプションで TCP か UDP プロトコルを指定しているルールでのみ有効だという点に気を付けなくてはならない。さもなければこのターゲットにはまったく無意味だからだ。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.19. REJECTターゲット
REJECT ターゲットは、基本的には DROP ターゲットと同じ動作をする。ただし、パケットのブロックされたホストに対してエラーメッセージを送り返す点が異なる。 REJECT ターゲットは現在のところ、 INPUT、FORWARD、OUTPUT チェーンおよびそれらのサブチェーンでしか有効でない。とはいえ、そもそもこれらのチェーンでしか、このターゲットは意味を成さない。 REJECT ターゲットを使用しているチェーンは、 INPUT、FORWARD、OUTPUT チェーンからのみ呼ぶことができ、その他のチェーンからでは機能しない点に注意していただきたい。このターゲットの振る舞いを制御するオプションは、今のところ ひとつだけ。とはいえ、このオプションが採れる引数は膨大な種類に上る。 TCP/IP の基本的知識さえあれば、大方すぐに察しがつくものばかりだ。
Table 11-14. REJECTターゲットオプション
| オプション | --reject-with |
| 例 | iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset |
| 説明 | このオプションは REJECT ターゲットに対して、こちらが拒絶 (reject) するパケットの送り主ホストにどのような返答を送るかを指示する。このターゲットを指定しているルールにパケットがマッチすると、こちらのホストはまず設定された返答を送り、それから、 DROP ターゲットが破棄するのとまったく同様にパケットを黙殺する。利用可能な拒否のタイプには、現在のところ以下のものがある: icmp-net-unreachable, icmp-host-unreachable, icmp-port-unreachable, icmp-proto-unreachable, icmp-net-prohibited, icmp-host-prohibited。ホストに送られるメッセージのデフォルトは port-unreachable だ。上記はすべて ICMP エラーメッセージであり、お好み次第で指定できる。これらタイプの様々な役割については、付録 ICMPタイプ で詳しく知ることができる。さらに echo-reply オプションもあるが、これは ICMP の ping パケットをマッチさせるルールとの組み合わせでしか利用できない。そして最後の残りが、 TCP プロトコルとの組み合わせでのみ使える tcp-reset オプションだ。 tcp-reset オプションは、パケットを送ってきたホストへの返答として TCP の RST パケットを送れと REJECT ターゲットに指示をする。 TCP RST パケットは、開いている TCP コネクションを礼儀正しく (gracefully) 閉じるためのもの。 TCP RST についてもっと詳しく知りたいのなら、 RFC 793 - Transmission Control Protocol を読んでいただきたい。 iptables の man ページで述べられている通り、主に、挙動のおかしいメールホストにメールを送信する時に起こる身元情報探り (ident probe) をブロックしたい時に役に立つターゲットだ。そうしたホストはこうでもしないとメールを受け入れてくれない。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.20. RETURNターゲット
RETURN ターゲットは、このルールにヒットした時点で、パケットに、今辿っているチェーンの進行をやめさせる。現在のチェーンが他のチェーンのサブチェーンであった場合には、パケットは、まるで何事もなかったかのように親チェーンの続きを進む。チェーンがメインチェーン (例えば INPUT チェーン) だった場合は、パケットには、チェーンに採用されているデフォルトポリシーが適用される。通常、デフォルトポリシーに設定されているのは ACCEPT、DROP といった類である。
例を挙げよう。あるパケットが INPUT チェーンに入り、マッチするルールに行き当たり、そこに書いてある指示が --jump EXAMPLE_CHAIN だったとする。次にパケットは EXAMPLE_CHAIN を巡り始めるわけだが、そこで不意に --jump RETURN ターゲットの指定されたルールにマッチする。すると、パケットは INPUT チェーンへ取って返す。もう一方の例は、パケットが INPUT チェーンの中で --jump RETURN ルールにヒットした場合だ。その場合には、パケットは、前述したようにデフォルトポリシーへと突き落とされ、このチェーンの中での行動はそこでやめになる。
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.21. SAMEターゲット
SAME ターゲットの働きはほぼ SNAT ターゲットに近いが、少々違いがある。 SAME ターゲットは、固有のホストの開始したコネクションに対して、常に決まった外部 IPアドレスを使おうとするのだ。例えば、ここに /24 のネットワーク (192.168.1.0) と 3つの IPアドレス (10.5.6.7-9) があるとしよう。そこで 192.168.1.20 が当初、 .7 というアドレスを使って外へ出たならば、ファイヤーウォールは以後このマシンには同じ IPアドレスを使って出て行かせようとするのだ。
Table 11-15. SAMEターゲットオプション
| オプション | --to |
| 例 | iptables -t mangle -A PREROUTING -s 192.168.1.0/24 -j SAME --to 10.5.6.7-10.5.6.9 |
| 説明 | ご覧のように、 --to ステートメントは "-" で結んだふたつの IPアドレスを引数に採る。これらの IPアドレス及びその間に挟まれた全てのアドレスが、 SAME のアルゴリズムによって NAT で振り向ける IPアドレスとなる。 |
| オプション | --nodst |
| 例 | iptables -t mangle -A PREROUTING -s 192.168.1.0/24 -j SAME --to 10.5.6.7-10.5.6.9 --nodst |
| 説明 | SAME ターゲットの通常の動作では、関連する後続のコネクションは宛先 IP と送信元 IP の両方を基にして割り出される。 --nodst を使用することによって、 NAT の際に件の IP を使うべきかどうかは、送信元 IPアドレスだけで判断するようになる。このステートメントを使わない場合には、判断は宛先 IP と送信元 IP の組み合わせを基に行われる。 |
| Linux カーネル 2.5, 2.6 で機能する。 |
11.22. SECMARKターゲット
SECMARK ターゲットは、対象とする 1個のパケットに SELinux およびセキュリティ機構の定義するところの セキュリティコンテキスト マークをセットするために使用する。この機能は Linux においてはまだ駆け出しだが、将来もっと充実していくことだろう。SELinux は当ドキュメントの守備範囲ではないので、Security-Enhanced Linux で詳しく見ていただくことをお勧めするだけに留めておこう。
SELinux は、簡潔に言うと、強制アクセス制御 (Mandatory Access Control = MAC) を Linux に装備する先進的なセキュリティ機構で、NSA によって臨床試験的な実装が行われた。基本的には、様々なオブジェクトにセキュリティ属性を付与しておき、その セキュリティ・コンテキスト の中身でそれらを区別しようというものだ。SECMARK ターゲットを使用するとパケットに セキュリティ・コンテキスト をセットすることができ、それを基準にしてセキュリティサブシステムにそのパケットを区別させることができる。
| SECMARK ターゲットは mangle テーブルでのみ使用できる。 |
11.23. SNATターゲット
SNAT ターゲットは送信元ネットワークアドレス変換 (Source Network Address Translation ) を行うのに用いる。つまりこのターゲットは、パケットの IP ヘッダに書かれている送信元の IPアドレスを書き換える。こうしたことが必要となるのは、例えば、ひとつのインターネット接続を複数のホストで共用しなければならない場合だ。その際には、カーネルのフォワード機能をオンにして、ローカルネットワークから出ていくパケットの送信元 IP を、インターネットコネクションそのものの IP へと書き換えるような SNAT ルールを書けばいいわけだ。我々のローカルネットワークは通常、 IANA の定めるところの LAN 内でのみ許される IPアドレスを使用しているため、このようにしないと、外の世界では、返答のパケットをどこへ送ればいいのか知る由もない。もしも、これらのパケットをそのままフォワードなどしたら、その出所が我々であるということは、インターネット上の誰一人として分からないのだ。 SNAT ターゲットは、こちらの LAN を離れるパケットを唯一のホストつまりファイヤーウォールから来たように見せかけることによって、この種の動作に必要な変換をすべて世話してくれる。
SNAT ターゲットは nat テーブルの POSTROUTING チェーンでしか有効でない。言い換えれば、このチェーンが、SNAT を使用できる唯一のチェーンとなる。 SNAT による改変を受けるのはコネクションの先頭パケットだけで 、同じコネクションに乗ることとなる後続パケットには、すべて [: 自動的に] SNAT が掛かる。ひいては、最初に適用された POSTROUTING チェーンのそのルールが、同じストリーム上を流れるすべてのパケットに適用されることとなる。
Table 11-17. SNATターゲットオプション
| オプション | --to-source |
| 例 | iptables -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000 |
| 説明 | --to-source オプションは、パケットにどんな送信元を使わせるかの指定に用いる。一番単純な使い方としては、このオプションは IP ヘッダ内の送信元 IPアドレスにしたい単一の IPアドレスを引数に採る。いくつかの IPアドレスに分散させたい場合には、ハイフン区切りで IPアドレスを範囲指定することもできる。その時の --to-source の IP 指定は、例えば上記の例: 194.236.50.155-194.236.50.160 のようなものになる。こうすると、新しいストリームが開く度に、送信元 IP が範囲の中からランダムに割り振られる。ただし、同一ストリームの中では、どのパケットも常に同じ IPアドレスを使用する。また、 SNAT に使用させるポートの範囲も指定可能だ。そのようにすると、送信元ポートを、指定した範囲内に絞ることができる。この場合のルールのポートビット部は、上記の例の :1024-32000 のようなものとなる。これは、当該のルールのマッチセクションのどこかで -p tcp か -p udp が指定されている時にだけ使用が可能だ。 iptables は常に、ポートの入れ替えは可能な限り避けようとするが、ふたつのホストが重複するポートを使いそうになった場合には、どちらか一方のポートを変更する。ポート範囲が指定されていない場合に、変換の必要なケースが発生すると、送信元ポートが 512番より下だった場合には 512番より下の別のポートにマッピングされ、512番から 1023番までの場合には 1024 より下のいずれかにマッピングされる。それ以外のポートの場合には 1024番以上のポートへマッピングが行われる。前述したように、 iptables は常に、コネクションを開いたワークステーションの元々使っていた送信元ポートを維持しようと努める。これらの動作は、宛先ポートには一切影響を与えないという点に気を付けよう。クライアントがファイヤーウォール外の HTTP サーバにコンタクトを試みた際に、それが FTPコントロール ポートにマップされるというわけではない。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.24. TCPMSSターゲット
TCPMSS ターゲットを使うと、ファイヤーウォールに接触する TCP SYN パケットの MSS (Maximum Segment Size) 値を変更することができる。 MSS 値は、各々のコネクションの中で使用するパケットの最大サイズをコントロールするために用いられる。通常この値は、 MTU から 40バイトを引いた値だ。このターゲットは、パケットのフラグメンテーションが必要だということを伝える ICMP をブロックしてしまう ISP やサーバへの対策として利用することが多い。そうした状態でよく見られるのは、ファイヤーウォールやルータは完璧に機能しているはずなのに、大きなパケットになるとファイヤーウォール内側のローカルマシンは遣り取りができない、といった奇妙な現象だ。具体的に言えば、メールサーバが、小さなメールなら送れるがサイズの大きなメールが送れない、あるいは WEB ブラウザで、接続自体は成立しているのにデータを何も受信しないまま固まる、 ssh 接続はできるが scp だと最初のハンドシェークの後ハングする、などの現象だ。つまり、大きなパケットを扱うものが全てうまくいかないわけだ。
TCPMSS ターゲットは、コネクションを介して出て行くパケットのサイズを変更することによって、そうした問題を解決してくれる。憶えておいてほしいのは、 MSS は SYN パケットについてだけ設定すればよいということ。それ以降の MSS は各ホストが自分で面倒を見るからだ。 TCPMSS ターゲットには 2種類のオプションがある。
Table 11-18. TCPMSSターゲットオプション
| オプション | --set-mss |
| 例 | iptables -t mangle -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN -o eth0 -j TCPMSS --set-mss 1460 |
| 説明 | --set-mss オプションは、全送出パケットに MSS を具体的にセットする。上記の例は、インターフェイス eth0 から出ていく全パケットの MSS を 1460バイトにセットしている (イーサネットでの MTU は通常 1500バイトであり、そこから 40バイトを引くと 1460バイト)。 MSS は SYN パケットでのみ調整すればよく、後は末端のホストが勝手に面倒を見る。 |
| オプション | --clamp-mss-to-pmtu |
| 例 | iptables -t mangle -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN -o eth0 -j TCPMSS --clamp-mss-to-pmtu |
| 説明 | --clamp-mss-to-pmtu では MSS が自動的に適切な値に設定される。よって、具体的な値を与える必要がない。その際の MSS は PMTU (Path Maximum Transfer Unit = 経路上での最大転送可能サイズ) から 40バイトを引いた値が自動的に選定される。それはほとんどの場合に妥当な値だ。 |
| Linux カーネル 2.5, 2.6 で機能する。 |
11.25. TOSターゲット
TOS ターゲットは IP ヘッダ中の Type Of Service フィールドを設定するのに用いる。 TOS フィールドは 8ビットから成り、パケットのルーティングを補助するために使われる。このフィールドは、 iproute2 またはそのサブシステムから直接利用することが可能で、ルーティングポリシーの決定に活用できる。複数のファイヤーウォールやルータを備えている場合には、注目に値するターゲットだ。というのも、 TOS ターゲットはパケットそのものに実際に情報を付加できる唯一の手段だからだ。前述したように、 MARK ターゲット (特定のパケットに MARK を関連づけする) はカーネル内でのみ利用可能なものであり、パケットに何かをくっつけるわけではない。特定のパケットやストリームにルーティング情報を付加したい時には、まさにそのために設けられた、この TOS フィールドを使用すべきだ。
今日のインターネット上では、 TOS フィールドに対してろくな扱いをしないルータが多い。そのため、パケットをインターネットに送り出す直前に TOS をいじっても、現状ではほとんど役に立たないはずだ。 TOS フィールドがルータに無視されるだけならまだましだが、最悪の場合、 TOS フィールドを見て見当違いの処理が行われてしまう。それでも、前述の通り、複数のルータを利用する大きな WAN や LAN を扱っているのなら、有効な利用法があることは火を見るより明らかだ。これを使えば、パケットの TOS フィールドに基づいてルータや優先度を切り替える能力が獲得できる。たとえそれが自分のネットワーク内に限定されるとしてもだ。
| TOS ターゲットでパケットに対して指定可能なのは、特定の、名前の付いている値に限られている。規定済みの TOS 値はカーネルのインクルードファイル、正確に言うと Linux/ip.h ファイルを見れば分かる。理由はいろいろとあるが、ともかく、それ以外の値を設定する必要はまずありえないだろう。しかし、この制限を出し抜く手はある。名前のある値しか指定できないという制限を乗り越えるには、Matthew G. Marsh の管理しているサイト Paksecured Linux Kernel patches で入手可能な FTOS パッチを使えばいい。ただし、このパッチを使うには注意が必要! 何か極端なケースでもなければ、規定の値以外を使う必要はないはずだ。 |
| このターゲットは mangle テーブルでのみ有効で、それ以外では使うことができない |
| もうひとつ注意がある。古いバージョン (1.2.2 以前) の iptables に付属する TOS ターゲットは実装に不具合があり、パケットの改変時にパケットのチェックサムを補正しない。そのため、パケットが駄目になり、再送が必要になってしまう。結果として、さらに上乗せで改変 (mangle) しなければならなくなり、コネクションが正常に成り立たない事態に陥ることも多い。 |
TOS ターゲットが採るオプションは下記の 1種類のみだ。
Table 11-19. TOSターゲットオプション
| オプション | --set-tos |
| 例 | iptables -t mangle -A PREROUTING -p TCP --dport 22 -j TOS --set-tos 0x10 |
| 説明 | --set-tos オプションは、マッチしたパケットに設定すべき TOS の値を TOS 改変機構に指示する。引数は数字で、16進または 10進の数値が使用できる。 TOS 値は 8ビットから成るので、値は 0-255、16進なら 0x00-0xFF となる。標準の TOS ターゲットでは、前述したように、名前を持つ値 (事実上の標準化された値) しか採ることができないという点に注意。具体的には、 Minimize-Delay (10進値 16, 16進値 0x10), Maximize-Throughput (10進値 8, 16進値 0x08), Maximize-Reliability (10進値 4, 16進値 0x04), Minimize-Cost (10進値 2, 16進値 0x02), Normal-Service (10進値 0, 16進値 0x00) のいずれかとなる。ほとんどのパケットのデフォルト値は Normal-Service つまり 0 になっている。もちろん、16進数などで指定する代わりに、 TOS 値を名前で指定することも可能であり、むしろ、そうしたほうがよいとされている。というのも、 TOS 名に結びつけられた数値は、将来変更される可能性があるからだ。 TOS名の全リストが見たければ、 iptables -j TOS -h すればよい。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.26. TTLターゲット
| このターゲットを使用するには http://www.netfilter.org/ から patch-o-matic を手に入れて、そのツリーの base ディレクトリにある TTL パッチを適用する必要がある。 |
TTL ターゲットは IP ヘッダの Time To Live フィールドを変更するのに用いる。便利な活用法としては、すべての送出パケットの Time To Live 値の統一がある。これを行うのは、あなたの ISP が意地悪で、ひとつのインターネット接続には 1台しかマシンをつながせたがらず、しかも、それを強制してくる場合だ。 TTL 値を揃えれば、多少ではあるが、うまい具合に検知を邪魔できる。その際には、全送出パケットの TTL を、 Linux カーネルの標準である 64 など、しかるべき値に統一してやればいい。
Linux のデフォルト値を変更する方法について詳しく知りたければ、付録 その他の資料とリンク にある ip-sysctl.txt を読むといいだろう。
TTL ターゲットは mangle テーブルでのみ有効で、それ以外では使えない。採れるオプションは、執筆時点では 3つ。下の表で述べているのがそのすべてだ。
Table 11-20. TTLターゲットオプション
| オプション | --ttl-set |
| 例 | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-set 64 |
| 説明 | --ttl-set オプションは、 TTL ターゲットに対して、当該のパケットに設定すべき TTL 値を指示する。妥当な値は 64 前後。これなら長からず短からずといったところだ。ネットワークに悪影響を与えるので、あまり高い値を設定してはいけない。また、この値を高くすることは、モラルを犯す面もある。そうしたパケットは設定のいい加減なふたつのルータの間を行ったり来たりするからで、 TTL が高ければ高いほど、多くの帯域幅が無用に食いつぶされる。このターゲットは、関わりを持つクライアントとの距離を制限するという使い方が想定できる。あまり遠くにクライアントを持ちたくない典型といえば DNS サーバが挙げられる。 |
| オプション | --ttl-dec |
| 例 | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-dec 1 |
| 説明 | --ttl-dec オプションは、 TTL ターゲットに対して、Time To Live の値を --ttl-dec オプションに指定した分だけ減らすよう指示する。つまり、入ってくるパケットの TTL が 53 である時、 --ttl-dec 3 を指定していると、そのパケットはこちらのホストを 49 という TTL 値をまとって出ていく。なぜそうなるのかといえば、ネットワーキングコードが常に自動的に TTL を 1 ずつ減らすからで、結果として 4ステップ減ることととなり、パケットの TTL は 53 から 49 へと変わるのだ。このオプションは、例えば、どこまで離れた人々にサーバのサービスを提供するか制限したい時に利用される。例えば、ユーザは一番近くにある DNS を使用するのが当たり前なので、こちらの DNS サーバから出ていこうとするすべてのパケットをマッチさせて、数ステップ分減少させるという使い方ができる。もちろん、この用途なら --set-ttl を使うほうがベターかもしれない。 |
| オプション | --ttl-inc |
| 例 | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-inc 1 |
| 説明 | --ttl-inc オプションは、 TTL ターゲットに対して、Time To Live の値を --ttl-inc オプションで指定した分だけ増加させるよう指示する。つまり、 --ttl-inc オプションに指定した数だけ TTL を増やす効果が得られるわけで、もし --ttl-inc 4 を指定すれば、TTL 53 で入ってきたパケットはこのホストを TTL 56 で離脱する。 --ttl-dec オプションと同じことが起こっているのはお気づきだろう。ネットワークコードがいつものように TTL を自動的にひとつ減らしているのだ。とりわけ面白いのは、ファイヤーウォールを trace-route に対して少しだけステルスにできることだ。入ってくるパケットの TTL をもれなく 1つ上げてやることによって、ファイヤーウォールを trace-route から効果的に隠すことができる。trace-route は両刃の剣だ。コネクションの問題点やその発生箇所などの有効な情報を与えてくれる一方、ハッカー/クラッカーの手でそれがあなたに向けられれば、こちらの上流に関するおいしい情報を与えてしまうのだ。典型的な用例が Ttl-inc.txt スクリプトにあるので見ていただきたい。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.27. ULOGターゲット
ULOG ターゲットは、マッチしたパケットについて、ユーザ空間でのロギングを提供してくれる。パケットがマッチした時、ULOG ターゲットがセットされていると、パケットの情報がパケットそのものと一緒にネットリンクソケットを通じてマルチキャストされる。ユーザ空間のプロセスをいくつでも、いずれかのマルチキャストグループに参加させておけば、それらのパケットを受け取ることができるわけだ。言うなれば、これは iptables と Netfilter だからこそ可能な、より完全で洗練されたロギング機能であり、パケットのログを採ることに関して遙かに優れた機能を備えている。このターゲットを利用すれば、 MySQL をはじめとする様々なデータベースに情報をログすることも可能で、特定のパケットについての検索や、ログのグループ化も朝飯前となる。 ULOGD project page に行けば、 ULOG のユーザ空間アプリケーションも用意されている。
Table 11-21. ULOGターゲットオプション
| オプション | --ulog-nlgroup |
| 例 | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-nlgroup 2 |
| 説明 | --ulog-nlgroup オプションは、パケットをどのネットリンクグループに送るかを ULOG ターゲットに指示する。ネットリンクグループは 32 あり、単純に 1 から 32 で指定する。ネットリンクグループ 32 へ伝達したいとすれば、単純に --ulog-nlgroup 32 と書けばよい。デフォルトで使われるネットリンクグループは 1 である。 |
| オプション | --ulog-prefix |
| 例 | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-prefix "SSH connection attempt: " |
| 説明 | --ulog-prefix オプションは、ちょうど通常の LOG ターゲットの接頭辞と同じように働く。このオプションにより、すべてのログエントリに、指定したログ接頭辞が付加される。接頭辞の長さは 32文字までで、内容や出所によってログを見分けるのに大変役に立つ。 |
| オプション | --ulog-cprange |
| 例 | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-cprange 100 |
| 説明 | --ulog-cprange は ULOG ターゲットに対して、パケットのうち何バイトをユーザ空間の ULOG デーモンに送るかを決める。上記のように 100 を指定すると、パケット全体のうちから 100バイトがユーザ空間にコピーされる。そこには、うまくすればヘッダのすべてと、実際のパケットの冒頭のいくらかが含まれているだろう。 0 を指定した場合には、パケットのサイズに関わらず、パケットの頭から終わりまで全部がユーザ空間にコピーされる。デフォルト値は 0 つまりパケット全部だ。 |
| オプション | --ulog-qthreshold |
| 例 | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-qthreshold 10 |
| 説明 | --ulog-qthreshold は ULOG ターゲットに対して、実際にユーザ空間へデータを送るまでに、いくつのパケットをカーネル内でキューイングするかを指示する。例えば上記のように、しきい値 (threshold) を 10 にすると、カーネルは 10個のパケットを蓄積してから、それらをひとつのネットリンク・マルチパートメッセージとしてユーザ空間へ送る。下位互換性の理由からデフォルト値は 1 となっている。以前のユーザ空間のデーモンはマルチパートメッセージが扱えなかった。 |
| Linux カーネル 2.3, 2.4, 2.5, 2.6 で機能する。 |
11.28. まとめ
このチャプターでは、現在 Linux で利用可能な全てのターゲットを個別具体的に詳しく見てきた。iptables/Netfilter 用の新たなターゲットが開発者達によって次々と書かれているので種類は今も増え続けているが、見ていただいた通り、現状だけでも既にかなりの数に登る。またこのチャプターでは、各ターゲットで利用可能な様々なオプションについても述べてきた。
次章では、ファイヤウォールスクリプトをデバグすることについてと、その際に使えるテクニックについてあれこれと模索する。 bash と echo の活用といった比較的ありふれた手法の他に、 nmap や nessus といった高度なツールも紹介する。
Chapter 12. スクリプトのデバグ
ルールセットを書き上げる上で、面倒でつい手を抜いてしまいがちなのが、いかにして自分のルールセットをデバグするか、間違った箇所をいかにして見つけるかということだ。このチャプターでは、スクリプトをデバグしたりどこが悪いのか調べる際の基本的なステップを示すとともに、頼みの綱となる周到な手段や、間違ったルールセットを走らせたせいでファイヤーウォールに接続できなくなってしまうのを防ぐ方法について説明する。
これからご教授する方法は、ルールセットが bash シェルスクリプトとして書いてあることを前提としているが、そうでない場合にも応用は利くはずだ。残念ながら、 iptables-save で保存されたルールセットはコード的には全くの別物なので、これから述べるデバグ手法はほとんど助けにならない。しかし一方、 iptables-save によるファイルはシェルスクリプトよりもずっとシンプルで、特定のルールを動的に作り出すようなスクリプトコードも内包できないため、デバグの手間があまりかからないというのも事実だ。
12.1. デバグ、それは必要欠くべからざるもの
デバグを行うことは、 iptables 及び netfilter や、とにかくファイヤーウォールというものに関する限り必須事項だ。ファイヤーウォールの障害の 99% は、突き詰めれば人為的なものであり、ポリシーの設計や、ルールセットを作成する行程に原因がある。賭けてもいいが、ルールセット作成にミスはつきものと言っていい。時として、そうした誤りや、それによってファイヤーウォールに空いた節穴は、肉眼では捉えにくい。あなたが存在に気づいていなかったり、スクリプトの中で意図せずできてしまった穴は、ネットワークの急所となり、アタッカーに易々と進入口を差し出してしまう。このような穴のほとんどは、幾つかの便利なツールを使えば容易く見つけ出すことができる。
また、スクリプト自体にバグを紛れ込ませたのが原因で、ファイヤーウォールにログインできないなど、先ほどとは違った問題を引き起こす場合もある。しかしこれもまた、そもそもスクリプトを走らせる前にちょっと工夫をすることによって解決が可能だ。スクリプト言語とシステム環境双方の能力を最大限に利用すると、驚くべき能力が発揮できる。経験豊富な Unix 管理者ならそれは百も承知だろう。そして、スクリプトのデバグにおいても、双方の最大活用、それこそが全てなのだ。
12.2. Bashデバグテクニック
ルールセットの書かれたスクリプトをデバグする際に bash でできることはあまり多くはない。バグを見つける段でまず越えなければならない課題は、どの行で問題が発生するのかを知ることだ。これには、 bash の -x フラグを使うか、単純に echo ステートメントを挿入して問題の発生する箇所を見つけるという、ふたつの方法がある。理想的には、 echo ステートメントを利用して、コード中へ一定間隔で以下のような echo 命令を入れることになるだろう:
...
echo "Debugging message 1."
...
echo "Debugging message 2."
...
僕はよく、 grep したりスクリプトファイルを検索したりして該当するメッセージを見つけられる程度に、固有の文字列を含む、甚だ意味のないメッセージを使う。今、エラーメッセージは "Debugging message 1." の後で現れ、 "Debugging message 2." より前だったとすれば、問題のある行はそれらふたつのデバグメッセージの間のどこかにあると分かる。ご存じのように、 bash には、途中のコマンドにエラーがあっても最後まで全てのコマンドを実行し続けるという、悪いとは言わないまでもかなりヘンテコな設計思想がある。 netfilter で使うと、これが元で非常に面白い問題に遭遇することがある。上記のように単純に echo ステートメントでエラーを見つけるという方法は、非常に単純でありながら、極めて有効な手段となる。それによってトラブルをコードの 1 行にまで絞り込み、問題の正体を知ることができるからだ。
エラーを探る第二の方法は、前にも述べたように bash に -x オプションを与える方法だ。もちろんこれには少々の問題がある。特に、スクリプトが長く、コンソールバッファが足りない場合だ。 -x オプションの意味するところは非常に単純で、スクリプトコードの各行を、シェルの標準出力 (standard output) (通常はコンソール) へ逐一エコーさせる。やるべきことは、スクリプトの最初の行:
#!/bin/bash
を下記のように書き換えること。
#!/bin/bash -x
やってみれば分かると思うが、元の行数がそれほど多くないとしても大量のデータが出力される。コマンドの一行一行が変数の値などとともに全て現れるわけで、各コードが何をやっているのかまでいちいち読み取ろうとする必要はない。簡単に言うと、各行が実行と当時にスクリーンにも出力されるのだ。そこでありがたいのが、 bash が出力している行には頭に + 記号が付くという点。おかげで、何の目印もない大量の羅列を読むよりは幾分か、エラーや警告メッセージが識別しやすくなる。
-x オプションは、もう少し複雑なルールセットを書く時にありがちな幾つかのトラブルをデバグするのにも、非常に役に立つ。第一に挙げられるのが、 for, if, while といった基本的 (だとあなたが思いこんでいる) ループの中で実際に行われていることがつぶさに分かることだ。例えば、下の例を見てみよう。
#!/bin/bash
iptables="/sbin/iptables"
$iptables -N output_int_iface
cat /etc/configs/machines | while read host; do
$iptables -N output-$host
$iptables -A output_int_iface -p tcp -d $host -j output-$host
cat /etc/configs/${host}/ports | while read row2; do
$iptables -A output-$host -p tcp --dport $row2 -d $host -j ACCEPT
done
done
ごく単純なルールセットに見えるが、何度試してもエラーになってしまう。単純に echo を使ったデバグ方法を試した結果、上記のコードからは以下のエラーメッセージが出ることが分かっている。
work3:~# ./test.sh
Bad argument `output-'
Try `iptables -h' or 'iptables --help' for more information.
cat: /etc/configs//ports: No such file or directory
そこで、 bash の -x オプションをオンにして出力を眺めてみる。そのアウトプットが下記だが、ご覧のようにかなり奇妙なことが起こっている。幾つかのコマンドで変数 $host と $row2 がヌル (空文字) に置き換えられているのだ。よく見ると、問題が発生しているのはコード繰り返しの最終回だけだということが分かる。プログラミング上の間違いか、データにおかしなところがあるかのいずれかだと考えられる。この場合はデータ側の単純な問題であり、データファイルの最後に余分な改行がひとつ紛れ込んでいることが原因だ。そのため、ループの最後で本来起こるべきでない余分な繰り返しが起こっていたわけだ。ファイル末尾の改行を削除すれば問題はあっさりと解決だ。あまりエレガントな解決策とはいえないかもしれないが、個人レベルならそれで充分。もちろん、変数 $host と $row2 にデータが含まれているかどうかを検証するコードを加えるという手もある。
work3:~# ./test.sh
+ iptables=/sbin/iptables
+ /sbin/iptables -N output_int_iface
+ cat /etc/configs/machines
+ read host
+ /sbin/iptables -N output-sto-as-101
+ /sbin/iptables -A output_int_iface -p tcp -d sto-as-101 -j output-sto-as-101
+ cat /etc/configs/sto-as-101/ports
+ read row2
+ /sbin/iptables -A output-sto-as-101 -p tcp --dport 21 -d sto-as-101 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-101 -p tcp --dport 22 -d sto-as-101 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-101 -p tcp --dport 23 -d sto-as-101 -j ACCEPT
+ read row2
+ read host
+ /sbin/iptables -N output-sto-as-102
+ /sbin/iptables -A output_int_iface -p tcp -d sto-as-102 -j output-sto-as-102
+ cat /etc/configs/sto-as-102/ports
+ read row2
+ /sbin/iptables -A output-sto-as-102 -p tcp --dport 21 -d sto-as-102 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-102 -p tcp --dport 22 -d sto-as-102 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-102 -p tcp --dport 23 -d sto-as-102 -j ACCEPT
+ read row2
+ read host
+ /sbin/iptables -N output-sto-as-103
+ /sbin/iptables -A output_int_iface -p tcp -d sto-as-103 -j output-sto-as-103
+ cat /etc/configs/sto-as-103/ports
+ read row2
+ /sbin/iptables -A output-sto-as-103 -p tcp --dport 21 -d sto-as-103 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-103 -p tcp --dport 22 -d sto-as-103 -j ACCEPT
+ read row2
+ /sbin/iptables -A output-sto-as-103 -p tcp --dport 23 -d sto-as-103 -j ACCEPT
+ read row2
+ read host
+ /sbin/iptables -N output-
+ /sbin/iptables -A output_int_iface -p tcp -d -j output-
Bad argument `output-'
Try `iptables -h' or 'iptables --help' for more information.
+ cat /etc/configs//ports
cat: /etc/configs//ports: No such file or directory
+ read row2
+ read host
最後に挙げるのは、 -x オプションが、完璧ではないにしろ手助けとなるタイプのトラブルだ。それは、ファイヤーウォールスクリプトを SSH 経由で実行していて、スクリプトの実効途中でコンソールがハングしたまま戻らず、再度 SSH で接続することもできなくなるという問題だ。そうしたケースの 99.9% は、スクリプト内部に何箇所か問題があるのが原因と思われる。 -x オプションを有効にすれば、少なくとも、スクリプトがどの行で無応答になるかというところまでは突き止められる。ただし、残念ながら例外もある。例えば、スクリプトが、受信トラフィックをブロックするような何らかのルールを作り上げるものだったとしよう。しかし、 ssh や telnet サーバは送出トラフィックの初めに echo を送信するので、その時点で netfilter はコネクションを記憶することができる。そのため、コネクションステータスを司るようなルールがブロックルール構築よりも前にある場合には、受け取り方向のトラフィックはなんとか通してもらえるのだ。
ご覧いただいたように、結局のところ、書き上げたルールセットを完璧にデバグするのはかなり込み入った作業だ。とはいえ、やってできないことではない。 SSH を通じてファイヤーウォールを遠隔で設定しなければならない場合に、出来損ないのルールセットをロードすれば、ファイヤーウォールが無応答になってしまったりするケースがあることも分かったはずだ。そんな場合に時間を浪費しないための奥の手がある。無駄な時間を節約してくれる素晴らしい手段となるのは cron だ。仮に、50km 離れた場所にあるファイヤーウォールに取り組んでいるとしよう。ルールを幾つか足したり、削除したり、削除して新しいルールセットに差し替えたりする。と、ファイヤーウォールが無応答に。もう何も届かない。付けるものを付けておかないと、物理的にファイヤーウォールのある所まで馳せ参じ、現地で直接直すしかなくなってしまう!
12.3. デバグに役立つシステムツール
ファイヤーウォールのロックダウンへの備えとして最も使える予防策のひとつが、ファイヤーウォールのリセットを行うスクリプトがおよそ 5分毎に実行されるように cron を設定しておく方法だ。ファイヤーウォールが完璧に機能することが確認できたら、その cron ジョブはすかさず削除する。ジョブは下記のようなものになるだろう。コマンド cron -e で入力できる。
*/5 * * * * /etc/init.d/rc.flush-iptables.sh stop
作業対象サーバが固まる恐れのちょっとでもある作業を開始する前に、その cron ジョブが間違いなく動作して予定通りの作用をしてくれることを必ず確認しておかなければならない。
syslog 機構もまた、スクリプトのデバグで常用するツールのひとつだ。 syslog は、八百よろずのプログラムの吐き出すログメッセージをログするための機構だ。実際のところ、カーネルも含め、大きなプログラムの大多数は syslog によるロギングをサポートしている。 syslog へ送られるメッセージは必ず、ふたつの基本的な変数を保持している。 ファシリティ (facility) と、レベルまたはプライオリティ (level/priority) だ。このことは覚えておいて損はない。
ファシリティは syslog に対して、そのログエントリが何者からのものでどこに記録されるべきかを伝える。定義済みのファシリティは何種類もあるが、今対象となるのは kern ファシリティ。またの名を kernel ファシリティという。 netfilter から生成されるメッセージは全て、このファシリティを使って送られる。
ログレベルは syslog に、そのログメッセージの重篤度を伝える。利用可能なプライオリティには以下のものがある。
debug
info
notice
warning
err
crit
alert
emerg
syslog.conf の設定により、これらプライオリティに応じて異なったファイルへログを送ることができる。例えば warning プライオリティを持った kern ファシリティのメッセージを全て /var/log/kernelwarnings というファイルへ送るには、下記のように命令する。これは /etc/syslog.conf に書く文言だ。
kern.warning /var/log/kernwarnings
ご覧の通り、極めて単純。うまくいけば (syslog サーバをリスタートするか HUP を送った後) netfilter のログが /var/log/kernelwarnings に書かれているのを確認できるはずだ。もちろん、これは netfilter のロギングルールでどのログレベルを指定しているかにもよる。ログレベルは --log-level オプションで指定できる。
ルールセット中でしかるべき log ルールの与えてある行を通ったパケットならば、このファイルから必ず情報が得られるはずだ。この方法を使えば、おかしな徴候を具体的に知ることができる。例えば、どのチェーンにも末尾に log ルールを設定しておけば、各チェーンを過ぎて持ち越されるパケットがあるかどうかを調べることができる。ログに現れるエントリは下記に類するものになるだろう。見ての通り様々な情報を含んでいる。
Oct 23 17:09:34 localhost kernel: IPT INPUT packet died: IN=eth1 OUT=
MAC=08:00:09:cd:f2:27:00:20:1a:11:3d:73:08:00 SRC=200.81.8.14 DST=217.215.68.146
LEN=78 TOS=0x00 PREC=0x00 TTL=110 ID=12818 PROTO=UDP SPT=1027 DPT=137 LEN=58
このように、 syslog はルールセットのデバグに非常に役に立つ。採取したログを調べれば、開けたいポートが開かない理由を知る糸口がつかめるだろう。
12.4. iptablesのデバグ
iptables のデバグはなかなか骨が折れる。というのも iptables がいつも分かりやすいエラーメッセージばかり出すとは限らないからだ。そこで、 iptables でよくあるエラーメッセージと、それが出る理由をおさらいしておこう。
まず最初が "Unknown arg" エラー。出る原因はいろいろとある。例えば下のようなメッセージだ。
work3:~# iptables -A INPUT --dport 67 -j ACCEPT
iptables v1.2.9: Unknown arg `--dport'
Try `iptables -h' or 'iptables --help' for more information.
この例なら、使用している引数がひとつだけなので解決はあまりにも容易い。このエラーメッセージにお目にかかるのは、普通、長い長いコマンドを使った時だ。上のケースでの問題は、 --protocol マッチを入れ忘れていること。そのために、 --dport マッチが利用可能になっていないのだ。 --protocol マッチを加えればこのマッチの問題は解決する。或るマッチを使うには前提条件として特定の別マッチが必要な場合があり、それを指定し忘れていないか、よく確認しておく必要がある。
また、命令の中でダッシュ (-) が足りないためのエラーというのもよくある。下の例だ。解決策の正解はダッシュを足すだけ。それでコマンドはうまくいく。
work3:~# iptables -A INPUT --protocol tcp -dport 67 -j ACCEPT
Bad argument `67'
Try `iptables -h' or 'iptables --help' for more information.
もうひとつが、単純なミススペリングで、これもよくある。下記の例だ。お気づきのように、表示されるエラーメッセージの内容は、前提マッチを忘れた場合と全く同じなので、注意して見ないと分からない。
work3:~# iptables -A INPUT --protocol tcp --destination-ports 67 -j ACCEPT
iptables v1.2.9: Unknown arg `--destination-ports'
Try `iptables -h' or 'iptables --help' for more information.
上に述べた "Unknown arg" エラーメッセージの出る原因がもうひとつある。引数に問題が無く、前提条件のミスも考えられないという時には、ターゲット、マッチ、テーブルのいずれかがカーネルにコンパイルされていない可能性がある。例えば filter テーブルのサポートをカーネルにコンパイルし損ねた場合のメッセージは、このようなものになるだろう:
work3:~# iptables -A INPUT -j ACCEPT
iptables v1.2.9: can't initialize iptables table `filter': Table does not exist
(do you need to insmod?)
Perhaps iptables or your kernel needs to be upgraded.
通常、カーネルに内蔵済みでないモジュールがあると iptables は自動的に modprobe する能力を持っているので、こうしたエラーの出た原因はふた通り考えられる。カーネルをコンパイルしなおしてから depmod を適切に行わなかったか、あなたがそのモジュールのことをはなから忘れていたかのどちらかだ。ところが一方、問題のモジュールがマッチに関するものだった場合、エラーメッセージはもっと暗号じみて、理解が困難となる。例としてこのエラーメッセージを見ていただこう。
work3:~# iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
iptables: No chain/target/match by that name
この場合、我々はステートモジュールをコンパイルし忘れているのだが、エラーメッセージは理解しやすい親切なものとは言い難い。とはいえ、少なくとも、問題のヒントは与えてくれる。最後にもうひとつ、同じエラーメッセージを示そう。しかし今回欠如していたのはターゲットだ。ご覧の通り、ことは混迷を極める。 (不足しているのがマッチなのかターゲットなのか両方なのか不明の) 全く同一のエラーメッセージとなるからだ。
work3:~# iptables -A INPUT -m state --state ESTABLISHED -j REJECT
iptables: No chain/target/match by that name
depmod のし忘れなのかモジュールそのものが欠如しているのかを知る一番手っ取り早い方法は、モジュールが存在するはずのディレクトリを確認してみることだ。その場所は /lib/modules/2.6.4/kernel/net/ipv4/netfilter ディレクトリ。 ipt_* ファイルのうち、大文字で記されているのはターゲット、小文字で書かれているのがマッチとなる。例えば ipt_REJECT.ko はターゲット、 ipt_state.ko はマッチだ。
| 2.4 以前のカーネルではカーネルモジュールの拡張子は .o だったが、 2.6 からは .ko に変わった。 |
他に、 iptables 自体に助けを求める方法もある。ひとつのチェーンを丸ごとコメントアウトしてみて、問題が解消するかどうか試す方法だ。これは最終兵器とも言うべきもので、いったいどのチェーンが問題を起こしているのかも分からない時に威力を発揮する。或るチェーンを取り除いて、デフォルトポリシーも ACCEPT に設定し、試してみる。それで改善すれば原因はそのチェーンにある。改善しない場合は、次のチェーン、次のチェーンと試し、問題箇所を絞り込んでいけばいい。
12.5. その他のデバグツール
言うまでもなく、ファイヤーウォールスクリプトのデバグに非常に役立つツールが他にもある。このセクションでは、あなたのファイヤーウォールが様々な方向から (内側から、外側からなど) 見てどのように見えるかを調べられる、主立ったツールを、簡単に紹介する。僕が取り上げることにしたのは nmap と nessus だ。
12.5.1. Nmap
nmap は、ファイヤーウォールのありのままの姿を観察し、開いているポートや、もっとローレベルの様々な情報が調べられる、優れたツールだ。 OS特定機能 (OS fingerprinting) や、多岐に渡るポートスキャン方式をサポートしており、 IPv6 にも IPv4 にも対応。ネットワークスキャン機能も備えている。
スキャン時のコマンドライン書式は基本的には非常に簡潔だ。 -p 1-1024 のように、スキャンするポートを指定するのを忘れずに。例として下記を見ていただこう。
blueflux@work3:~$ nmap -p 1-1024 192.168.0.1
Starting nmap 3.50 ( http://www.insecure.org/nmap/ ) at 2004-03-18 17:19 CET
Interesting ports on firewall (192.168.0.1):
(The 1021 ports scanned but not shown below are in state: closed)
PORT STATE SERVICE
22/tcp open ssh
25/tcp open smtp
587/tcp open submission
Nmap run completed -- 1 IP address (1 host up) scanned in 3.877 seconds
OS特定 (フィンガープリント) 機能を使えばスキャン先システムの OS を推察することもできる。フィンガープリント機能は root 権限を必要とするが、そのホストが常々周りからどのように認識されているかが分かって面白い。 OSフィンガープリント を使うと、下の例のような結果が得られる。
work3:/home/blueflux# nmap -O -p 1-1024 192.168.0.1
Starting nmap 3.50 ( http://www.insecure.org/nmap/ ) at 2004-03-18 17:38 CET
Interesting ports on firewall (192.168.0.1):
(The 1021 ports scanned but not shown below are in state: closed)
PORT STATE SERVICE
22/tcp open ssh
25/tcp open smtp
587/tcp open submission
Device type: general purpose
Running: Linux 2.4.X|2.5.X
OS details: Linux Kernel 2.4.0 - 2.5.20
Uptime 6.201 days (since Fri Mar 12 12:49:18 2004)
Nmap run completed -- 1 IP address (1 host up) scanned in 14.303 seconds
見て分かるように、 OSフィンガープリントとて完璧ではない。しかし、幾つかに絞り込めるだけでもありがたい。あなたにとっても、アタッカーにとっても。ひいては、あなたにとって有益だということになる。肝心なのは、アタッカーに的確な OS 特定をさせないよう、与える情報をなるべく少なくすること。 nmap で解析した情報を見れば、あなたの OS がアタッカーにどう見えているのかが、あなたにも分かるというわけだ。
nmap には nmapfe (Nmap Front End) というグラフィカルユーザインターフェイスも添付されている。これは良くできた nmap フロントエンドで、もう少し複雑な検索がしたい時に使うと便利だろう。参考までに、スクリーンショットを下に示しておく。
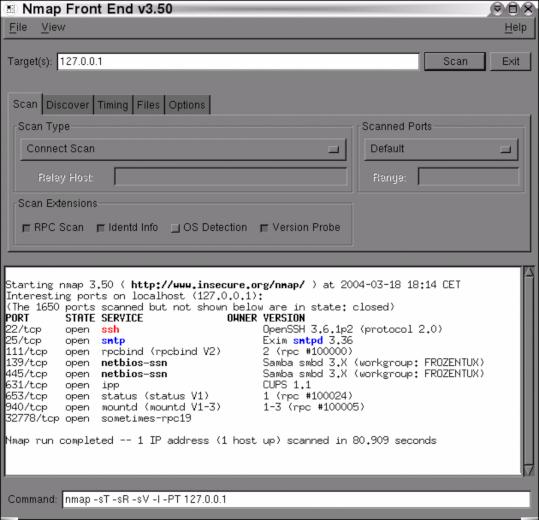
もちろん nmap には他にもいろいろな使い方がある。 nmap のホームページで様々なことが発見できるだろう。詳しくは Nmap の資料 をご覧いただきたい。
ご理解いただけたと思うが、 nmap は自分のホストを試験するのに優れたツールであり、どのポートが開いていてどのポートが開いていないかを知ることができる。例えば、設定か完了した後に nmap を使えば、意図した通りのことが達成できているかどうかが分かる。適切なポートから適切な反応が返ってくるか、といったような事柄だ。
12.5.2. Nessus
nmap が開放ポートなどを表示するいわゆるローレベル域のスキャナだとすれば、 nessus プログラムは本当の意味でのセキュリティスキャナだといえる。 nmap はいろいろなポートに接続してスキャンを行うが、分かるのは、どう頑張っても動作しているサーバのバージョンくらいまでだ。 nessus はもう一歩踏み込んで、開放ポートを全て挙げ、それぞれのポートでどんなプログラムのどのバージョンが動いているかを調べ、それらプログラムに対して様々な欠陥試験 (security threats) を行って、最終的に、そのサーバで見つかった脆弱性をリストアップしてくれる。
これが自分のホストをよりよく知るのに非常に有効なツールであることは、もう理解いただけただろう。 nessus プログラムはサーバ-クライアント型になっており、 nessus デーモンを活用すればマシンの内外どちらからでもファイヤーウォールの状態が簡単に、しかもかなり詳しく調べられる。クライアントはグラフィカルユーザインターフェイスになっており、それを使って nessus デーモンへログインし、幾つか設定を行い、脆弱性のスキャンを行う対象ホストを指定すればOKだ。作成されるレポートは例えば下のようなものとなる。
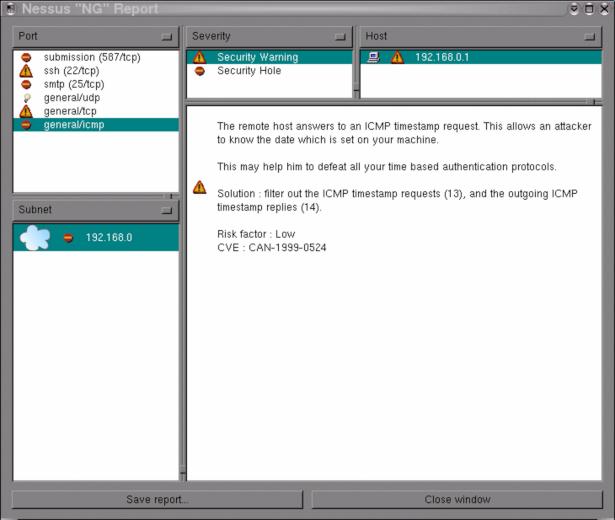
| ただし nessus はアタック先のマシンあるいはサービスをクラッシュさせる可能性もあるので注意が必要だ。幸い、そうしたクラッシュの危険性のあるアタックはデフォルトでは無効になっている。 |
12.6. まとめ
このチャプターではファイヤーウォールスクリプトをデバグする時に役立つ様々なテクニックを詳しく見てきた。ファイヤーウォールスクリプトのデバグは退屈な作業で時間もかかるが、省くわけにはいかない。幾つかのステップに小分けしてやっていけば、最終的にはそれほど大変だとは感じないだろう。述べてきた主な事柄は以下。
bash をデバグに活用
デバグに役立つシステムツール
iptables のデバグ
その他のデバグツール
Chapter 13. rc.firewallファイル
このチャプターでは、ひとつのファイヤーウォール設定例を取り上げ、そのスクリプトファイルがどんな感じになるかを見る。取り上げるのはごく基本的な設定で、それがどう働くか、何を行っているのかを掘り下げていく。これを通じて、各種の課題への対処法と、実際にスクリプトを稼働させる前に考慮すべきポイントについて基本的な考え方が呑み込めるだろう。スクリプトは、いくつか変数を変えるだけでそのまま使うこともできそうだが、あまりお勧めはしない。というのは、あなたのネットワークセッティングとの絡みで必ずしもうまく動作するとは限らないからだ。とはいえ、ごく一般的な設定のマシンならば、多少手を加えるだけですんなりと動くのではないだろうか。
| ルールセットの作りとしては、もっと効率的なやりかたがあるかもしれない。しかし、敢えてそうしたやり方をしているのは、 BASH スクリプティングに精通していなくても、誰もが理解しやすいようにするためだ。 |
13.1. 例 rc.firewall
というわけで、あなたは準備万端、いよいよ設定スクリプト例に目を通す用意ができたわけだ。ここまで読み進んできたのなら、曲がりなりにも準備はできているはずだ。例 rc.firewall.txt (付録 スクリプト例コードベース にもある) はかなり長大だが、コメントはそれほど多いとは言えない。僕がお勧めするのは、コメントを探すよりも、まずスクリプトファイルをざっと眺めてどんな感じのものかフ〜ンと納得してから、ここに戻ってきてスクリプト全体をくまなく見ていくという方法だ。
13.2. rc.firewallの解説
13.2.1. 設定オプション
例 rc.firewall.txt で一番最初に目に付くのが設定 (Configuration) セクションだ。ここは各自の設定にとってネックとなる情報を含んでいるため、必ず手を加える必要がある。例えば IPアドレスは各人違うだろうから、ここから有効な値が取れるようにしておかなくてはならない。 $INET_IP は、もし持っているのなら、間違いなく有効な IPアドレスでなければならない。 (IPを持っていないというなら、rc.DHCP.firewall.txt に目を通してみるのもいい。しかしとりあえず先へ進もう。このスクリプトを読めば、とにかく興味深い事柄がたくさん分かるはずだ)。また、変数 $INET_IFACE は、実際にインターネットにつながることになるデバイスを指していなければならない。変数名を与えるのは、eth0 か eth1, ppp0, tr0 といったところ。選択肢はそう多くはないはずだ。
このスクリプトは DHCP や PPPoE などに対応する設定オプションは特に含んでいないため、それらのセクションは空白になっている。他の空白セクションも同様に、他のスクリプトとの違いがよく分かるようにするため、敢えてそのまま残してある。それらの部分が必要になったら、いつでも他のスクリプトと混合もできるし、自分で (頑張って) 一から書いてみるのもいいだろう。
LAN に不可欠な設定オプションは、そのほぼ全部が、ローカルエリアネットワーク (ocal Area Network) セクションに含まれている。例えば、LAN につながっている物理インターフェースの IPアドレス、それにもちろん、LAN で用いる IP範囲、マシンと LAN との接点になっているインターフェースも指定しなければならない。
さらに、ローカルホスト (Localhost) の設定セクションがあるのにも気づいたはずだ。お仕着せながら、 99%の確率で、まず値を変える必要はないだろう。 IPアドレスはほぼ常に 127.0.0.1 であろうし、名前もほぼ lo に違いないからだ。また、ローカルホスト設定のすぐ下には、 iptables に関する簡潔なセクションがある。このセクションの主旨は $IPTABLES だけで、この変数は iptables アプリケーションそのものずばりの位置を指し示している。これは多少変わるかもしれない。 iptables パッケージを手動でコンパイルしたのなら、その位置は /usr/local/sbin/iptables となる。しかし、アプリケーションの実体を /usr/sbin/iptables など、違った場所に置いているディストリビューションもたくさんある。
13.2.2. 追加モジュールの初期ロード
最初の部分で、 /sbin/depmod -a コマンドを使って依存関係 (dependency) ファイルを最新状態に更新しているのが分かるだろう。その後に、このスクリプトで必要となるモジュールをロードする。不必要なモジュールはロードしないよう、いつも心がけておくべきだ。また、もう使うはずのなくなったモジュールをロードしたまま放っておくのも極力控えなければいけない。それに対応した追加ルールを書かなくてはならない羽目になり、セキュリティ上好ましくないからだ。では、例を挙げていくとしよう。 LOG、REJECT、MASQUERADE ターゲットを利用可能にしたいとして、それらがカーネルにスタティックにコンパイルされてない場合には、以下のようにしてモジュールをロードする:
/sbin/insmod ipt_LOG
/sbin/insmod ipt_REJECT
/sbin/insmod ipt_MASQUERADE
| ここで扱うスクリプトではモジュールを強制的にロードしているが、これは、ロードの失敗という結果を招くこともある。モジュールロードの失敗には様々な原因が考えられるが、その際にはエラーメッセージが出力されるだろう。ごく基本的なモジュールでロードの失敗が起こる場合、一番ありがちなのは、モジュールや機能がカーネルにスタティックにコンパイルされているケースだ。これに関する詳細なら、付録 よくある問題と質問 の モジュールロードのトラブル を読んでいただきたい。 |
次にあるのが ipt_owner モジュールをロードするためのオプションで、例えば、限られたユーザだけに特定のコネクションを許可するなどの用途に用いる。当例題では使用していないが、基本的な使用法としては、root にだけ redhat.com への FTP 接続と HTTP 接続を許可し、それ以外は DROP する、といった使い方ができる。また、あなた自身のユーザと root 以外、マシンからインターネットへの接続を禁止することもできる。他のユーザはうんざりするだろうが、こうすれば、ハッカーのアタックや、あなたのホストを単なる踏み台に使おうとするアタックを跳ね返し、セキュリティをさらに固められる。 ipt_owner マッチの詳細は、チャプター ルールの作り方 の Ownerマッチ セクションに書いてある。
ここでは、ステート (state) マッチングに関係する追加モジュールもロードしている。ステートマッチとコネクション追跡 (connection tracking) コードを拡張するモジュールはすべて、 ip_conntrack_*, ip_nat_* といった名前が付いている。コネクション追跡ヘルパーは、特殊な接続を間違いなく追跡する方法をカーネルに教えるための特別なモジュールだ。カーネルは、ヘルパーと称するこれらのものなしには、特殊なコネクションを追跡しようとした際に手掛かりの見当が付けられない。これに対して、 NAT ヘルパーは、特殊なパケットのどこを見ればいいのか、コネクションをきちんと機能させるためにはどのような変換 (translation) を行えばいいのかをカーネルに伝えるコネクション追跡拡張ヘルパーだ。例えば、 FTP は規格上複雑なプロトコルで、コネクションに関する情報をパケットのペイロードそのものの中でやりとりする。つまり、あなたのネットワークの中のマシンがインターネット上の FTP サーバに接続する場合を考えると、そのマシンはパケットのペイロードに自分のローカルネットワーク IPアドレスを乗せて送信し、「この IPアドレスに接続するように」と FTP サーバに要求する。ところが、ここで指定されたローカルネットワークアドレスは自分のネットワークを一歩でも出れば無効な種類のものなので、 FTP サーバは手も足も出ず、コネクションは断絶してしまう。 FTP NAT ヘルパーはこれらコネクションに必要な変換をすべて世話してくれるので、 FTP サーバは本当の接続先を知ることが可能となる。これと同様なことは DCC ファイル転送 (送信) とチャットにも言える。この種のコネクションを成立させるには、 IPアドレスとポートを IRC プロトコルの内部で送らなければならない。よって、何らかの変換が必要となるのだ。ヘルパーがないと、 FTP や IRC といった類は、平気で機能する部分もあるし、駄目な部分も出てくる。例えば、 DCC に乗せてファイルを受け取ることはできるとする。ところが送ることはできない。これは DCC がコネクションを開始する際の仕組みに起因している。まず初めに、あなたの側から、ファイルをこれから送る旨と、受信側がどこへ接続すればよいかが、受信者へ通知される。しかしヘルパーがないと、この DCC コネクションは受信者に、受信者のローカルネットワーク上にいる或るホストにつないでくれ、と言っているようにしか見えない。即ちコネクションが成り立たない。しかし、反対方向なら、送信側は (十中八九は) 正しい接続先アドレスを通知してくるので、滞りなく働くのだ。
| mIRC DCC でファイヤーウォールを越えられないのだが IRC クライアントでは問題なし、というトラブルに見舞われている場合は、付録 よくある問題と質問 にある mIRC DCCのトラブル を読んでみるといい。 |
執筆の時点では、 FTP および IRC プロトコルのサポートを追加するためのモジュールをロードする手段としては、これ以外の選択肢はない。これらの conntrack および nat モジュールについて詳しい説明が必要なら、付録 よくある問題と質問 を読んでいただきたい。また、 patch-o-matic には、H.323 conntrack ヘルパーをはじめ、他にも様々な NAT ヘルパーがある。それらを利用するには、 patch-o-matic を使用した後、カーネルをコンパイルしなおす必要がある。やり方については、チャプター 準備 で丁寧に説明してある。
| FTP と IRC プロトコルに対するネットワークアドレス変換 (Network Address Translation) をどういう形であれ正常に機能させたいのであれば、 ip_nat_irc と ip_nat_ftp をロードしなければならない。また、 NAT モジュールをロードする以前に ip_conntrack_irc と ip_conntrack_ftp モジュールもロードしておく必要がある。使い方は conntrack モジュールと同様だが、これらがそのコンピュータにもたらしてくれるのは、 FTP と IRC プロトコルを NAT する能力だ。 |
13.2.3. procの設定
この段階で、/proc/sys/net/ipv4/ip_forward に 1 を echo して、IPフォワーディング を有効にする。こんな具合だ:
echo "1" > /proc/sys/net/ipv4/ip_forward
| IPフォワーディング をいつ、どのタイミングでオンにするかは、考慮に値する問題だ。このスクリプトおよび、当チュートリアルで取り上げるすべてのスクリプトでは、具体的な IP フィルタ (つまり iptablesルールセット) を作る前にオンにしている。このやり方では、ルールセットの内容とマシンの性能にもよるが、1 ミリ秒から 1分 の間、あらゆる種類のトラフィックをどこへだろうと転送できる瞬間が生じる。これは悪質な連中にファイヤーウォールへ侵入する間隙を与えてしまうかもしれない。つまりは、本来なら、このオプションはすべてのファイヤーウォールルールが構築されてからオンにするべきだ。しかし僕は、全スクリプトで一貫した処理の流れを採るために、敢えて、ルールのロード前にオンにするほうを選択することにした。 |
動的 IP のサポートが必要な場合、例えば SLIP, PPP, DHCP を利用している人は、必要ならば、もうひとつのオプション ip_dynaddr を以下のやり方で有効にする:
echo "1" > /proc/sys/net/ipv4/ip_dynaddr
他にもオンにする必要のあるオプションがある場合は、同様の手順で行う。こういったことのやり方に関しては他にドキュメントがあるし、このドキュメントの主旨からは外れてしまう。proc システムについては、カーネルの付属文書の中にも、やや簡略すぎる嫌いもあるが優れたドキュメントが配布されており、同じものを付録 その他の資料とリンク にも用意しておいた。付録 その他の資料とリンク は、このチュートリアルにない、何か特定のジャンルについて調べたくなった際に、拠り所となる場所だ。
| このチュートリアルに含まれるその他すべてのスクリプトもそうだが、 rc.firewall.txt には、必要でないproc設定 (non-requred proc settings) という小さなセクションが含まれている。それら設定は、何かが思った通りに動いてくれない時に、発想のヒントになるだろう。しかし、それらの意味するところをはっきり知らないまま値を変えるのは御法度だ。 |
13.2.4. 各種チェーンへのルール配置
このセクションでは、このチュートリアルにおいて、ユーザ定義チェーンに関して僕が採用したいくつかの事柄と、 rc.firewall.txt に特有な手法を、簡単に説明する。僕が選択した方針のいくつかは、一部の見方によっては正しくないかもしれない。そうした観点や危惧される問題に関しては、随時、指摘してゆく。このセクションはまた、チャプター テーブルとチェーンの道のり のちょっとした復習にもなっている。これを通じて、実際の生きたサンプルでテーブルとチェーンをパケットがどのように巡ってゆくか、少しでも呑み込んでもらえればと願っている。
僕は各種ユーザチェーンを、できるだけ CPU パワーをセーブしながらも、セキュリティに最重点を置くやり方で配置した。例えば TCP パケットに TCP、UDP、TCP ルールを全部廻らせるのではなく、単純に TCP パケット全部をマッチさせて、それを 1つのユーザ定義チェーンに通すようにした。こうすれば、総体としてのオーバーヘッドを比較的低く抑えることができる。下の図で僕は、入ってきたパケットが Netfilter をどのようにくぐって行くかを説明しているつもりだ。こうした図と、説明文を用いて、当スクリプトの目的を説明し明らかにしていこうと思う。ここではまだ、特定の物事の子細には踏み込まない。それは後のチャプターに取っておこう。この図は、チェーンとテーブルの全行程を詳細に論述したチャプター テーブルとチェーンの道のり にあるものに比べれば、ちゃちななものだ。
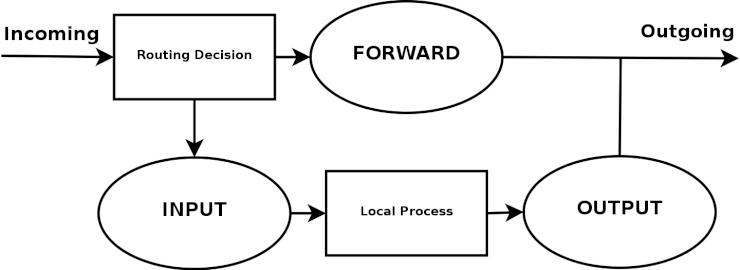
この図を見ながら、我々の目的がどういったことなのか、はっきりさせていこう。このスクリプトは終始一貫して、ひとつのローカルネットワーク と、1台のファイヤーウォール 、ファイヤーウォールにつながったひとつのインターネット接続、というシナリオの上に立っている。また、インターネットに対しては 1個の固定 IP を持っている (DHCP, PPP, SLIP などではないということ) という想定だ。ここでは、ファイヤーウォールはインターネット向けにいくつかのサービスを提供するサーバとしても働かせたい。また、ローカルネットワーク は完全に信頼し、よって、ローカルネットワークからのトラフィックは一切ブロックしないようにする。なお且つ、このスクリプトでは、はっきりと許可したいトラフィックだけを通すことを最重点項目に据える。そのために、各チェーンのデフォルトポリシーは DROP にしたい。これによって、こちらのネットワークつまりファイヤーウォールの内側に対して明示的に許可していないパケットやコネクションを、効果的に殺すことができる。
このシナリオでは、ローカルネットワークからのインターネット接続もできるようにしたい。ローカルネットワークは完全に信頼しているので、ローカルネットワーク からインターネットへのトラフィックは、どんな類でも許可するようにしたい。一方、インターネットは信頼の置けるネットワークとはほど遠いものなので、外の連中からローカルネットワークへのアクセスはブロックしたい。これらの想定を踏まえた上で、我々がやるべきこと、やらなくていいこと、そして、やろうと思っていることを考えていこう。
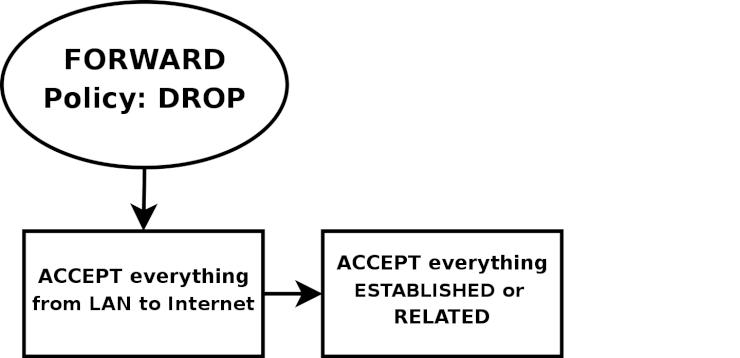
まず第一に、当然ながら、ローカルネットワーク からインターネット に接続できるようにしたい。どのローカルコンピュータも正規の IPアドレスは持っていないので、そのためには、パケットに漏れなく SNAT を掛ける必要がある。これはすべて、 POSTROUTING チェーンで行う。スクリプトで最後に作っているチェーンだ。これに伴って、何も処理をしなければ外界からローカルネットワークにフルアクセスできてしまうので、 FORWARD チェーンで何らかのフィルタリングを行わなければならない。我々はローカルネットワークは完全に信頼し、それ故に、ローカルネットワークからインターネットへのトラフィックは、取り立てて全部許可するようにする。インターネット側からローカルネットワークのコンピュータに触れられては困るので、インターネットからこちらのネットワークへのトラフィックはすべてブロックしたい。ただし、確立済み (established) のコネクションと、関連性 (related) のコネクションは、ローカルネットワークがインターネットから返答を受け取るのに必要なので、許してやる必要がある。
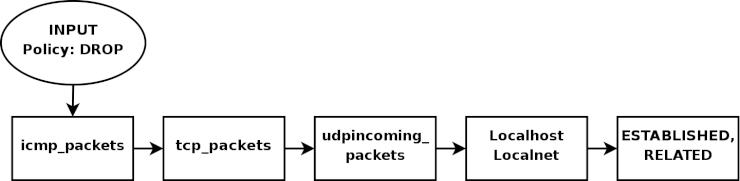
このファイヤーウォールを作るに当たっては、少々予算が厳しいことにしよう。つまり、ほんのいくつかでも、インターネット上の人々へサービスを提供しようと思う。そこで、 HTTP, FTP, SSH, IDENTD へのアクセスをインターネット側から許すことにした。これらのプロトコルはファイヤーウォールそのものの上で提供する。従って、 INPUT チェーンで許可される必要があると同時に、返答のトラフィックを OUTPUT チェーンで許可してやらなくてはならない。またその一方、我々はローカルネットワークについても完全に信頼し、ループバックデバイスとその IPアドレスにも信頼を置いている。そのため、ローカルネットワークおよびループバックネットワークインターフェースからのトラフィックをすべて許可する特別なルールを加えようと思う。また、或る特定の組み合わせによっては許可したくないパケットやパケットヘッダもあるし、インターネット側から侵入を許したくないIP範囲もある。例えば 10.0.0.0/8 というアドレス域は、ローカルネットワーク専用に規定されているものなので、通常、そんなアドレス域からのパケットを許可したいとは思わないはずだ。それらが成りすましパケットであることは 9割がた確実だからだ。だが、この設定を取り入れる前に、心に留めておかなくてはならないことがある。一部のインターネットサービスプロバイダは、こうしたアドレス域をネットワークに利用しているという事実だ。その点についての詳細な論議は、チャプター よくある問題と質問 に書いてある。
我々のサーバでは FTP サーバが動いているので、通るルールを可能な限り少なくするという前提も踏まえて、確立済み (established) および関連性 (related) のトラフィックを許可するルールを INPUT チェーンの一番先頭に組み込む。同様の理由から、ルールはいくつかのサブチェーンに分割しようと思う。こうすることによって、我々の扱うパケットは、可能な限り少数のルールを通るだけですむはずだ。巡るルールが少なければ、ルールセットがパケットひとつひとつに費やさせる時間が短縮でき、ネットワーク上での遅延を小さく抑えることにつながる。
このスクリプトではプロトコルの種別によってパケットを別々のチェーンへ振り分ける方針を決めた。種別とは、具体的には TCP、UDP、ICMP だ。 TCP パケットはどれも、許可したい TCPポートおよびプロトコルを指定したルールから成る tcp_packets という名のチェーンを通る。また、 TCP パケットはさらに追加審査にも掛けたい。そのため、ファイヤーウォールにとって妥当なポートナンバーを使っていると認められたすべてのパケットに対して、もうひとつサブチェーンを作ろうと思う。このチェーンを allowed チェーンと呼ぶことにするが、そこには、パケットの最終受け入れの前に行う少数のチェックを設ける。 ICMP パケットはどうかというと、icmp_packets というチェーンを通る。このチェーンの性質を考えると、 ICMP パケットのタイプとコードさえまともであれば、受け入れ前にそれ以外のチェックを行うこれといった必要性は考えにくい。従って、 ICMP パケットはいきなり受け入れることにする。取り組むべき最後のパケットが、 UDP パケットだ。 UDP パケットは、すべての進入 UDP パケットを扱う udp_packets というチェーンへ送り込む。ファイヤーウォールへやってくる UDP パケットは全部、このチェーンに送られ、許可された種類であれば、それ以上の検査なしにいきなり承認する。
我々が運営しているのは比較的小規模なネットワークなので、このマシンは補助的なワークステーションとして使われることもある。ファイヤーウォールにもう少し仕事をさせるためにも、 speak freely, ICQ といったいくつかの特殊なプロトコルを、当のファイヤーウォールとの間で取り交わせるようにしようと思う。
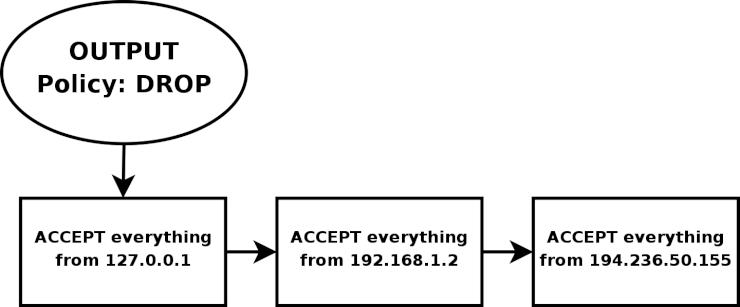
ファイヤーウォールの最後には OUTPUT チェーンがある。ファイヤーウォールを充分に信頼しているのだから、ファイヤーウォールから出るトラフィックはほぼ手放しで許可する。特定のユーザに対するブロッキングもしないし、プロトコルによるブロックも行わない。ただし、どこかの連中にファイヤーウォールを偽装パケットの発信源にされたくはないので、ファイヤーウォール自体に割り当てられた IPアドレスを発信元とするトラフィックだけを許可するようにしたい。これを実装するとすれば、最も順当な手段は、ファイヤーウォールに振られている IPアドレスのどれかから来たパケットであれば離脱を ACCEPT し、そうでなければ OUTPUT チェーンのデフォルトポリシーで DROP するようなルールを組み込むことだ。
13.2.5. デフォルトポリシーの設定
ルールセットの冒頭辺りで、デフォルトポリシーを設定している。各種チェーンでデフォルトポリシーを設定するには、下記のような、極めてシンプルなコマンドを使う:
iptables [-P {chain} {policy}]
デフォルトポリシーは、そのチェーンのどのルールにもマッチしないパケットに、もれなく適用される。例を挙げる。ここに、全ルールセットのルールにどれひとつとしてマッチしないパケットがあるとしよう。こうしたことが起こったら、我々は問題のパケットをどう処置するか決めなくてはならない。そこで登場するのがデフォルトポリシーだ。ルールセットでこれ以外のルールにマッチしないパケットに適用されるのが、デフォルトポリシーなのだ。
| 他 [訳者註: filter テーブル以外] のテーブルのチェーンにデフォルトポリシーを設定する場合には、注意が必要だ。それらのテーブルはそもそもフィルタリングのために作られたものではないため、奇妙な動作を招いてしまうからだ。 |
13.2.6. filterテーブルにユーザ定義チェーンを作る
ここまでで、我々がこのファイヤーウォールで何を達成したいのか全体像がつかめたはずなので、具体的なルールセットの構築に取りかかることにしよう。我々の作りたい、そして使いたいルールとチェーンを設定し、チェーン内のすべてのルールセットを構築するその時が、いよいよがやってきた。
ここから、 -N コマンドを使って、我々の必要とする各種の特別なチェーンを作成する。新しいチェーンは、何のルールも内包しない状態で作成される。
前述の通り、我々が使用するのは、 icmp_packets,
tcp_packets,
udp_packets,
allowed というチェーンであり、
allowed チェーンは
tcp_packets チェーン経由で使われる。
$INET_IFACE から進入するパケットのうち、
ICMP タイプのパケットは
icmp_packets チェーンへリダイレクトされる。
TCP タイプのパケットは
tcp_packets チェーンへリダイレクトされ、
$INET_IFACE からの UDP タイプのパケットは udp_packets チェーンへ行く。これについては、後ろの INPUTチェーン セクションで、より詳細な説明をしている。チェーンの作成は至ってシンプルで、下記のようなチェーンの宣言があるだけだ:
iptables [-N chain]
これからの数セクションで、ここで作られたはずのユーザ定義チェーンそれぞれを、子細に眺めていく。どんな姿をしているのか、どんなルールでできているのか、その中で何を達成しようとしているのか、詳しく見ていくことにしよう。
13.2.6.1. bad_tcp_packetsチェーン
bad_tcp_packets チェーンは、ヘッダの異常など、問題のある進入パケットの審査を目的としたルールを組み込むための専用チェーンだ。実際のところ、このチェーンには、進入する TCP パケットすべてを検査して、 NEW でありながら SYN ビットが立っていないもの、 NEW でありながら SYN/ACK の立っているものをブロックするパケットフィルタだけを組み込んでいる。このチェーンによって、上記のような異常や、XMAS ポートスキャンなど、想定しうるあらゆる矛盾をチェックすることができる。さらに INVALID ステートを検出するルールを追加してもいいだろう。
NEW でありながら SYN でない、ということについてもっとよく理解したいなら、付録 よくある問題と質問 にある NEWステートでありながらSYNビットの立っていないパケット セクションを読んでみるといい。そこでは、ステートが NEW でありながら SYN でないパケットが他のルールを素通りしてしまうという現象を取り上げている。ある種の特殊な環境では、これらのパケットを許可したほうがいい場合もあるが、99%、通す意味はない。従って、このスクリプトでは、ログを取って DROP している。
なぜ NEW と判定された SYN/ACK パケットを REJECT するかは、理由を考えてみれば非常に単純だ。それについては付録 よくある問題と質問 の SYN/ACKでNEWなパケット セクションで事細かに述べている。この処置は、基本的に、他のホストに対する配慮だ。これによって、他のホストを シーケンスナンバー予測アタック (sequence number prediction attack) から守ることになるからである。
13.2.6.2. allowedチェーン
パケットが $INET_IFACE から入ってきて、そのタイプが TCP ならば、パケットは tcp_packets チェーンを巡る。そこでもし、このコネクションが我々の許可したいポートであったなら、それが本当に望むべきものかどうか最終的なチェックに掛けるようにしたい。この最終チェックを行うのが、allowed チェーンだ。
まず最初に、そのパケットが SYN パケットかどうかを調べる。SYN パケットであるとすれば、それは十中八九、新しいコネクションの最初のパケットだろうから、当然これは許可する。次には、パケットが ESTABLISHED または RELATED なコネクションに属するものかどうかを調べる。そうであれば、当然これもまた許す。ESTABLISHED なコネクションとは、既に双方向にトラフィックがやりとりされたコネクションのことだが、この時点で SYN パケットは既に検出済みであることから、ステート機構の見地から見る限り、そのコネクションは紛れもない ESTABLISHED ステートに違いない。このチェーンで最後のルールは、上記以外のパケットをすべて DROP する。これに当てはまるものとは、つまり、双方向のトラフィックがまだ観察されていないその他すべて、とほぼ同義だ。例えば、SYN パケットに対してこちらが返答しなかった、あるいは SYN パケット以外でコネクションを開始しようとしたやつがいる、などの場合だ。コネクションの開始に SYN パケットを使わないなどということには、まったくもって実用性がない。あるとすれば、ほぼ間違いなく、ポートスキャンをする時だけだ。現在のところ TCP/IP には、SYN 以外のパケットによる TCP コネクション開始に対応した実装など、僕の知る限りひとつもない。よって、99% はポートスキャンに違いないので DROP してしまおう。
| このスクリプトでは ESTABLISHED,RELATED パケットに関するルールが二重に定義されていることになり、こちらのルールが実際に使われることはない。しかし、要素を全て網羅するために敢えてここに記述した。使用されるほうのルールは INPUT チェーンの冒頭にあり、そこでも ESTABLISHED,RELATED が定義されている |
13.2.6.3. TCPチェーン
tcp_packets チェーンは、インターネット側からファイヤーウォールのどのポートを利用可能にするかを決定する。だが、それだけでのチェックでは心許ない。そこで行うのが、前述した、各々のパケットの allowed チェーンへの送致である。
-A tcp_packets は iptables に対して、新しいルールの追加先チェーンを指示し、そのルールはチェーンの最後尾に追加される。-p TCP は TCP パケットをマッチさせるよう指示し、-s 0/0 は、ネットマスク 0.0.0.0 の送信元アドレス 0.0.0.0、つまり送信元アドレスすべてにマッチさせるよう、iptables に指示を与える。実を言えばこれはデフォルトの動作なのだが、物事をできるだけ明確にするために敢えて記述している。--dport 21 は宛先ポート 21 を表す。別の言い方をすれば、パケットが 21番ポート宛ならばマッチするということだ。すべての評価基準が満たされれば、パケットは allowed チェーン行きとなる。そこでどのルールにも当てはまらなければ、そのパケットは、自身を tcp_packets チェーンへ送り込んだ大元のチェーンへ差し戻される。
これまでのところ、TCP ポート 21 つまり FTP コントロールポート (FTP コネクションを制御するポート) は許可しているわけだが、この先で、RELATED コネクションにも許可を与える。ip_conntrack_ftp モジュールがロードされているはずなので、そうすることによって、PASSIVE、ACTIVE 両方のコネクションが許可できる。FTP をまったく許可しないつもりなら、ip_conntrack_ftp モジュールをアンロードした上で rc.firewall.txt から $IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 21 -j allowed の行を削除すればよい。
ポート 22 は SSH だが、SSH は、外からあなたのマシン上のシェルを使えるようにしたい場合には、23番ポートの telnet を使わせるよりずっとマシなものだ。しかし、肝に銘じてほしい。あなたが今取り組んでいるのはファイヤーウォール である。常識的に、ファイヤーウォールマシンをあなた以外の人が触れるようにするというのは間違った考えだ。ファイヤーウォールには、最小限のものしか持たせない、加えない、というのが鉄則だ。
ポート 80 は HTTP つまり WEBサーバ。ファイヤーウォール上で直に WEBサーバを動かす予定がないのなら、削除していただきたい。
そして最後に許可しているのがポート 113、つまり IDENTD で、IRC など一部のプロトコルが正常に機能するために必要となる。ローカルネットワーク上のたくさんのホストを NAT するつもりなら、是非憶えておきたいのが、oidentd パッケージだ。oidentd には、ローカルネットワーク内で IDENTD リクエストを正しいマシンへ中継できるようにする機能がある。
もし、スクリプトの中で開けておきたいポートが他にもあるというのなら、それもいいだろう。やり方はもう充分に分かっているはずだ。ただ tcp_packets チェーンの行をどれかカット & ペーストして、お好みのポートへと書き換えてやれば終わりだ。
13.2.6.4. UDPチェーン
INPUT チェーンで捕捉したのが UDP パケットなら、udp_packets チェーンへ送り込まれる。そこでは、再度 -p udp によってマッチを行い、送信元アドレス 0.0.0.0 ネットマスク 0.0.0.0 で全部をマッチさせる。言い換えれば、すべてを振り出しから検査し直すわけだ。ただし今度は、インターネットに対して開け放ちたい特定の UDP ポートを受け入れる。ステート機構が面倒を見てくれるので、送信してくるホストのポートに合わせてファイヤーウォールに穴を開ける必要はない。ポートを開放する必要があるのは、例えば DNS のように、UDP ポートを使用するサーバを走らせるつもりがある場合だけだ。ファイヤーウォールへ入ってくるパケットのうち、既に (こちらのローカルネットワークによって) 確立済み (established) のコネクションに属するものは、INPUT チェーンの先頭の --state ESTABLISHED,RELATED というルールによって、これ以前に自ずと認可されているのだ。
実際のスクリプトでは、DNS 検索に使用される 53番ポートを送信元とする進入パケットは ACCEPT していない。そのためのルールは書いてあるが、デフォルトではコメントアウトしてある。ファイヤーウォールを DNS サーバとして動作させたい場合には、その行のコメント記号を外してしていだたきたい。
僕の個人的都合で、 123番ポートつまり NTP (network time protocol) にも許可を与えている。このプロトコルは、非常に正確なクロックを備えたタイムサーバを参照して、自分のマシンのクロックを合わせるためのもの。大概の人には必要ないと思ったので、デフォルトでは許可していない。しかし、他の項目と同じで、ルールは一応書いてあり、コメントを外せば働くようになっている。
スクリプトでは現状、許可していないが、 2074番ポートはある種のリアルタイムマルチメディアアプリケーションで使用されるポートだ。その例が speak freely で、スピーカーとマイク、欲を言えばヘッドセットを使って、他の人々とリアルタイムで話すことができる。もし使いたければ、ただコメント記号を取り除くだけですぐに使用できる。
4000番ポートは ICQ プロトコル。 Mirabilis の ICQ と呼ばれるアプリケーションで使用するプロトコルとして広く知られている。 Linux 用にも、少なくとも 2,3種類の ICQ クローンがあり、世界中で最も広く使われているチャットプログラムのひとつとなっている。これについてこれ以上詳しく説明する必要はないのではなかろうか。
ここで、大量のログに悩まされる場合に、それぞれ違った状況に対応するふたつのルールが書かれている。最初のルールは、宛先ポートが 135 から 139 のブロードキャストパケットをブロックする。これらは、マイクロソフトユーザがたいてい装備する NetBIOS つまり SMB が使うポートだ。このルールは、ファイヤーウォール外のマイクロソフトネットワークの活動を一切 iptables にロギングさせない働きを持つ。 2番目のルールも余計なログを抑えるためのものだが、こちらは、外からの DHCP クエリを処置する。これは、あなたの外部ネットワークがノンスイッチングタイプのイーサネットで組まれていて、クライアントが DHCP によって IPアドレスを獲得している場合に特有の現象だ。上記のような環境に置かれている場合には、多量のログに悩まされる可能性がある。
| 最後のふたつのルールは、もしかするとそうした種類のログに興味がある人もいるかもしれないので、敢えて採用を見合わせている。神経質すぎるログに苛まれているのなら、ここでそれらのパケットを破棄してみてほしい。この種のルールは、INPUT チェーンの、ログに関するルールのすぐ上にもある。 |
13.2.6.5. ICMPチェーン
ここは、どんな ICMP の型を承認するか判断するところだ。 INPUT チェーンで eth0 から ICMP タイプのパケットが入ってくると、前述したように icmp_packets チェーンへリダイレクトされる。そこでは、どんな ICMPタイプ を承認するかを判定する。今のところ僕が許可することにしているのは、ICMP echo request と、 TTL equals 0 during transmit、 TTL equals 0 during reassembly の 3種類だけだ。その他の種類の ICMP を許可してないのは、それらほとんどの ICMPタイプ が RELATED ステートのルールでカバーできてしまうからである。
| 或る ICMP パケットが、すでに存在するパケットかストリームへの返答として送られた時には、そのパケットは元のストリームに対して RELATED であると判定される。ステートに関して詳しく知るには、チャプター ステート機構 を読んでいただきたい。 |
これらの ICMP パケットを承認するのには、以下のような理由がある。 Echo Request は echo応答 (echo reply) を要求するために用いられるもので、このことから、主に、或るホストがどこであれネットワーク上で利用可能かどうか調べたい時に、他ホストへの ping に利用される。このルールがないと、どこのネットワークからも、我々のホストが利用可能かどうか確かめることができなくなってしまう。よく、べつにインターネットから存在が見えなくたって構わないという理由で、このルールを削除したがる人もいる。このルールを削除すれば、インターネット側からファイヤーウォールへ打たれる無意味な ping を無効化するには、効果てきめんだ。ファイヤーウォールは、兎にも角にもそれらに返答しなくなるのだから。
Time Exceeded (つまり TTL equals 0 during transit と TTL equals 0 during reassembly) は、どこかのホストを trace-route したい時の備えと、パケットの Time To Live がゼロになった際にその旨の返答を受け取る時のために許可している。実際にどこかへ trace-route する場合を考察してみよう。まず最初は TTL = 1 から始める。すると 1つ目のホップで 0 に減らされるので、 trace-route の最終目的であるホストへの途上にある最初のゲートウェイから、 Time Exceeded が送り返されてくる。次は TTL = 2 にして、2番目のゲートウェイが Time Exceeded を返してくる。これが、最終到達目的のホストから返答を受け取れるまで繰り返される。このようにして、本当に到達したいホストまでの途上にあるすべてのホストから返答を受け取り、経由するホストを知ることができ、どのホストに障害があるのか分かるのだ。
ICMP タイプすべてのリストについては、付録 ICMPタイプ を見ていただきたい。 ICMP タイプとそれらの用途をさらに詳しく知りたい向きには、下記のドキュメントとリポートを読むことをお勧めする。
RFC 792 - Internet Control Message Protocol by J. Postel.
| ちなみに、僕がブロックしている ICMP タイプのうちいくつかは、あなたにとっては適当ではないかもしれない。ただ、僕のところに関する限り、ここで不許可にした ICMP タイプをすべてブロックしても、何の問題もなく完璧に動作している。 |
13.2.7. INPUTチェーン
前にも書いたように、 INPUT チェーンはほとんどの重労働を他のチェーンに任せている。こうすることによって、 iptables に余計な負荷を発生させず、そうでなければ高負荷時にパケットを破棄してしまうような遅いマシンでも、ずっとうまく動作するだろう。これを可能にしているのが、多くのパケットで重複するような細かいチェックを共通化して行い、それが終わったパケットを特定のユーザ定義チェーンへ送るという手法だ。これにより、パケットが巡らなければならないルールセットを極力切り詰め、結果として、ファイヤーウォールはパケットフィルタリングによるオーバーヘッドを被らずにすむのだ。
まず初めに、不良パケットでないか、いくつかの検査をする。これは、すべての TCP パケットを bad_tcp_packets チェーンへ送ることによって行う。このチェーンは、造りのおかしいパケットや、受け入れに適さない異常を検査する少々のルールから成っている。詳細に渡る説明は、当チャプターの bad_tcp_packetsチェーン セクションに書いた。
この段階で、前提的に信頼しているネットワークからのトラフィックを探す。信頼するネットワークには、ローカルネットワークアダプタとそこから入ってくるトラフィック、こちらのループバックインターフェースから出入りする全トラフィック、それに、現状で割り当てられているすべての IPアドレス (インターネットIPアドレスも含め、そうしたアドレスの一切) が含まれる。実際のスクリプトでは、LAN からファイヤーウォールへ向けての活動を許可するためのルールを、一番先頭に配置することにした。というのは、ローカルネットワークが発生させるトラフィックのほうが、インターネットコネクションよりも多いからだ。このようにすれば、ルールを一個一個当たっていくのに消費される負荷を、可能な限り抑えることができる。ファイヤーウォールを通るトラフィックにはどんなものが最も多いのか、常に検討を心がけるのは良いことだ。そうやって、なるべく最適に近づけようとルールを並べ替えているうちに、ファイヤーウォールの負荷を下げ、ネットワーク内での混雑を低減できるところへ行き着けるのだ。
インターネットインターフェースからの進入の可否を決める "実効的" なルールに取りかかる前に、オーバーヘッドを抑える目的で RELATED ルールを設定している。このルールは、インターネットIPアドレスへの ESTABLISHED か RELATED なストリームに属するパケットをすべて承認するステートルールだ。同様のルールは allowed チェーンにもあり、このルールと重複する感もあるが、こちらのほうが allowed にあるものより先に評価される。それにも拘わらす allowed チェーンの --state ESTABLISHED,RELATED ルールを捨てないのには、命令句をカット & ペーストしたい際の便など、いくつか理由がある。
INPUT チェーンでは次に、$INET_IFACE インターフェースから進入した TCP パケットをマッチさせ、前述した tcp_packets チェーンへ送る。それから、同様にして $INET_IFACE の UDP パケットをマッチさせて udp_packets チェーンへ送り、最後に、ICMP パケットを icmp_packets チェーンに送る。ファイヤーウォールというものは、一般的に、扱う機会が最も多いのが TCP パケットで、次に UDP、最後が ICMP パケットとなる。ただし、これはあくまでも一般的な話であり、あなたのところでは違うかもしれない。先ほどのネットワークベースのルールと同じように、ここでも、まったく同様のことを遵守すべきである。一番トラフィックが多いのはどれだろうか? ルール同士はオーバーヘッドを最も小さくするように組まれているだろうか? これは、データを大量に送り出すようなネットワークでは、避けては通れない考察となる。下手なルールセットを書けば、ペンティアム III 相当のマシンがルール 100個のシンプルなルールセットで音を上げてしまうこともあるし、100M ビットのイーサネットカードがキャパシティいっぱいでフル稼働ということにもなりうる。自分のローカルネットワークのルールセットを書く際には、重要な意味を持つ工程となる。
デフォルトでは無効にしてあるが、ここでもうひとつルールがあり、Linux ファイヤーウォールの外側にマイクロソフトネットワークがある場合に余計なロギングを抑える働きがある。マイクロソフトクライアントには、224.0.0.0/8 のアドレス範囲へマルチキャストパケットをごまんと送信する悪い癖がある。そこで、機会のあるうちにこれらのパケットをブロックして、ログがそれらで溢れないようにするのだ。その他にも、udp_packets で行っているのと同様なふたつのルール (UDPチェーン 参照) がある。
デフォルトポリシーに行き着く手前で、問題やバグが起こった時に発見できるよう、ログを取っている。これらは我々が許したくないパケットのことかもしれないし、誰かが我々に対して何か良くないことをしようとした仕業かもしれないし、あるいは最後の可能性として、許可すべきトラフィックをファイヤーウォールで不許可にしていることから生じた問題かもしれない。いずれにしても、対処の助けとなるよう、知っておく必要がある。ただし、ログがゴミで溢れかえってログパーティションがはちきれるのはご免なので、最大でも 1分間に 3パケットしか記録しない。また、各ログの出所が分かるよう、すべてのログエントリに接頭辞 (prefix) が付くよう設定している。
ここまで来てまだ捕獲されていないものは、INPUT チェーンのデフォルトポリシーによってすべて DROP される。デフォルトポリシーは、かなり以前、当チャプターの デフォルトポリシーの設定 セクションで設定している。
13.2.8. FORWARDチェーン
現在のシナリオでは、FORWARD チェーンが持つルールはかなり少しで済んでしまう。まず bad_tcp_packets チェーンへパケットを送る 1行のルールがある。前述の INPUT チェーンでも使っているルールだ。 bad_tcp_packets チェーンは、パケットの種類に関わらず、いろいろなルールから再利用できるように作られているのだ。
この最初の不良パケット検出が終わったところから、FORWARD チェーンの本格的なルールが始まる。最初のルールは、 $LAN_IFACE から進入するトラフィックを、他のどのインターフェースへでも、まったく規制することなしに承認する。言い換えると、このルールは LAN からインターネットへのすべてのトラフィックを許可していることになる。 2番目のルールは、 ESTABLISHED と RELATED なトラフィックがファイヤーウォールを抜けて帰ってくるのを許可する。これも別の言い方をすると、パケットのうち、内部ネットワークから開始されたコネクションに属するものを、ローカルネットワークへ自由に帰ってこられるようにしている。 FORWARD チェーンのデフォルトポリシーは既に DROP に設定してあるので、ローカルネットワークがインターネットにアクセスするためには、これらのルールが必要なのだ。これはかなり狡猾な働きをしてくれる。つまり、ローカルネットワーク上のホストはインターネット上のホストへ接続できる一方で、インターネット上のホストから我々の内部ネットワークのホストへの接続はブロックしてくれるのだ。
最後に、何らかの理由で FORWARD チェーンで中継を許されなかったパケットを記録するロギングルールも用意している。ここで見られる出来事は、造りのおかしいパケットとその他の問題もろもろ、といった辺りになるだろう。原因はハッカーのアタックということもあるし、パケットが壊れていたという場合もある。これは、ログ接頭辞が "IPT FORWARD packet died: " であることを除けば、INPUT チェーンで使っているルールとまったく同じものだ。ログ接頭辞の主たる活用法はログエントリを区別することで、パケットがどこでログされたかや、ヘッダオプションを調べたい時に、ログエントリの判別基準として活用することができる。
13.2.9. OUTPUTチェーン
このマシンは現在のところファイヤーウォールとワークステーションの二足のわらじを履いているわけだが、前提として、このマシンを使うのは自分だけに限られているので、送信元アドレスが $LO_IP か $LAN_IP または $INET_IP であれば、ここから出ていくものはほとんど全部許可することにしている。僕のマシンで内輪の誰かがやったのだと疑うことになってしまうが、上記以外は全部、何らかの成りすましをしている可能性が高い。一番最後には、破棄されるパケット全部のログを採る。パケットが破棄される際には、問題への対処がしやすいよう、パケットの情報をログに採っておこうと思うのが当然だ。ここで捕まるのは、厄介なエラーのログか、偽装を受けたいかがわしいパケットのログのどちらかだろう。それらのパケットは、最終的にはデフォルトポリシーによって DROP される。
13.2.10. natテーブルのPREROUTINGチェーン
PREROUTING チェーンは、その名前が示す通り、パケットを filter テーブルの INPUT チェーンへ送るか FORWARD チェーンへ送るかを決定するルーティング判断が下される前の段階で、パケットにネットワークアドレス変換 (network address translation) を施す。このスクリプトに関する限り、なぜ PREROUTING チェーンについて触れるかと言えば、ここではいかなるフィルタリングも行ってはならないという点を改めて確認しておきたい気持ちに迫られたからだ。PREROUTING チェーンはストリームの先頭パケットが通るだけ、つまり、後続のパケットはこのチェーンによる評価をまったく受けることなく素通りしてしまう。このスクリプトにおいては PREROUTING チェーンを一切使用していないが、特定のパケットに DNAT を掛けたいとすれば、ちょうど今頃、我々はこのチェーンに取り組んでいるはずだ。例えば、ローカルネットワークのいずれかのマシンで WEBサーバなどを運営しようとする場合がこれに当たる。 PREROUTING チェーンについての詳しい説明は、チャプター テーブルとチェーンの道のり で読むことができる。
| PREROUTING チェーンはいかなるフィルタリングにも使用してはならない。理由はいくつかあるが、中でも重要なのは、このチェーンを通るのはストリームの最初のパケットだけだという点だ。確固たる理由がない限りは、 PREROUTING チェーンは ネットワークアドレス変換 専門に使用するべきである。 |
13.2.11. SNATの開始とPOSTROUTINGチェーン
ここまで来れば、残る仕事はネットワークアドレス変換を稼働させることだけだ。僕はそうだと思うんだが、違うだろうか? まず第一に、インターネットに接続している外部インターフェースから出ていくパケット全部に NAT を掛けるべく、ルールを nat テーブルの POSTROUTING チェーンに追加する。外部インターフェースは、僕の場合は eth0 だ。ただし、これらは固有であり、その設定を自動化するための変数が、すべてのスクリプト例に備え付けてある。 -t オプションは、どのテーブルにルールを挿入するかを iptables に指示するもので、今回の場合は nat テーブルとなる。-A コマンドは POSTROUTING という名の既存チェーンに新たなルールを追加 (Append) することを表し、-o $INET_IFACE は、インターフェース $INET_IFACE (スクリプトでのデフォルトで言えば eth0) から出ていこうとする全送出パケットをマッチさせることを意味している。そして最後に、パケットを SNAT せよというターゲットを与えている。結果として、このルールにマッチするすべてのパケットは、SNAT され、あたかも我々のインターネット用インターフェースから来たかのように化ける。送出パケットに付ける IPアドレスを --to-source オプションで SNAT ターゲットに与えるのも忘れないでほしい。
当スクリプトでは、MASQUERADE ではなく SNAT ターゲットを使うことにした。これにはふたつの理由があり、ひとつは、このファイヤーウォールが固定IPアドレスを前提としているから。ひとつ目に付随して理由を挙げるとすれば、可能ならば SNAT ターゲットを使ったほうが、動作が速く、効率がよいという点がある。そしてもちろん、実際の生きたサンプルで SNAT がどう働き、どう使われるのかを示すという目的もある。もし、あなたのところが固定IPでないのなら、是非とも MASQUERADE ターゲットの使用を検討してほしい。 MASQUERADE ターゲットは、 NAT を行ってくれるのはもちろんだが、使用すべき IPアドレスを自動的に把握してくれるので、簡単な使い方で単刀直入に便利な機能を提供してくれる。マシンパワーを少々余計に消費するとはいえ、DHCP を利用している場合などには、充分それに見合う価値がある。 MASQUERADE ターゲットがどのようなものかよく見てみたいと思うなら、rc.DHCP.firewall.txt スクリプトを覗いてみるといいだろう。
13.3. まとめ
このチャプターでは、様々なスクリプトの基本的なレイアウトを解説した。中でも rc.firewall.txt スクリプトには特に重点を置いて説明した。ここで紹介したスクリプトの内部構造やレイアウトは、よそであなたが目にするものとは全然違うかもしれない。コーディングスタイルは十人十色。ここで紹介したのはあくまでも僕のスタイルだ。
次のチャプターでは、このドキュメントに付属しているいろいろなスクリプトを手短に紹介する。それを読めば、それぞれのスクリプトがどういったシナリオを想定して書かれたものかといった基本的な事柄が分かるだろう。概略さえ掴んでしまえば、あとは自分の力でスクリプト全部を理解できるのではなかろうか。それらのスクリプトは、このドキュメントのメインサイトからダウンロードすることもできる。
Chapter 14. スクリプト例
このチャプターの目的は、このチュートリアルに付属する各スクリプトの解説と概要、それに、それらが提供する機能を、非常に簡略にではあるが説明することだ。これらのスクリプトは決して完璧とはいえないし、あなたの目的にぴったり合うとも限らない。言い換えれば、あなたのニーズにふさわしいスクリプトにするのは、あなたの腕にかかっているのだ。そうした難業の中で、チュートリアルのここからの部分はきっと役に立つはずだ。まず最初のセクションでは、スクリプトの中に糸口を見つけるのが楽になるよう、各スクリプトに盛り込んだ構造について取り上げる。
14.1. rc.firewall.txtスクリプトの構造
このチュートリアルのために書いたすべてのスクリプトは、ひとつの統一的な構造をもって書かれている。全てのスクリプトの骨格を共通にして、相違点を見つけやすくするためだ。そうした構造については、このチャプターで、簡略ながら、それなりに分かりやすく解説しているつもりだ。このチャプターを通じて、スクリプトがそのように書かれたわけと、こうした構造に統一している理由を、ざっと理解してもらえればと思う。
| 僕はこの構造を用いているが、これがあなたのスクリプトにとっても最適な構造だとは限らない。ただ、僕なりに最も読みやすく理解しやすいものにしたいという要件にかなっていたため、僕はこの構造を選んだに過ぎない。 |
14.1.1. 構造
以下が、このチュートリアルのすべてのスクリプトが踏襲する構造だ。もし、構造に背く理由を特記することなしに何か違うやり方をしているところがあったら、それはたぶん僕のミスだ。
Configuration - 一番初めには、続くスクリプト全体で使用する設定オプションが記述されている。設定オプションはどんなシェルスクリプトでもたいてい最初にあるものだ。
Internet - ここはインターネット接続に関連する設定オプションのセクションだ。インターネット接続がない場合には、このセクションは飛ばされている。ここに列挙したよりもたくさんのサブセクションがある場合もあるが、少なくともインターネット接続に関わるものであることに違いはない。
DHCP - そのスクリプトに特有の DHCP 要件がある場合には、ここに DHCP 特有の設定オプションが来る。
PPPoE - そのスクリプトを使うユーザあるいは環境が、PPPoE 接続を使用する可能性がある場合には、ここにそのオプションが書かれる。
LAN - ファイヤーウォールの背後に LAN があり、それが利用可能な場合、関連するオプションをこのセクションで追加する。たいていは LAN があるので、ほとんどの場合この設定がある。
DMZ - その必要性があれば、ここで DMZ ゾーンの設定を加える。ほとんどのスクリプトにはない。通常のホームネットワークや小規模な企業ネットワークには DMZ は滅多にないからだ。
Localhost - これらのオプションは我々のローカルホスト に関するものだ。ここの変数は滅多に変わることはないのだが、とりあえず、ほとんどを変数に入れることにしている。おそらくは、これらの変数を変更する必然性はまったくないだろう。
iptables - このセクションは iptables に関わる設定だ。ほとんどのスクリプト、ほとんどのシチュエーションでは、 iptables バイナリの在処を示す変数ひとつだけで終わりだ。
Other - その他の特異なオプションや変数があれば、まずは真っ先に妥当な項目のサブセクションに収められる (インターネット接続に関するものならインターネットのサブセクションに入るといった具合)。もしどの項目にも当てはまらなければ、それらは Configuration 自体のサブセクションとして置かれる。
Module loading - スクリプトのこのセクションはモジュールのリストを管理する。最初の部分には必要なモジュールが、次に、必要でないモジュールが並んでいる。
セキュリティを高めたり、何かのサービスや機能を追加するようなモジュールは、特に必須でなくても追加している場合がある。そうした際には、たいてい、それぞれのスクリプトに覚え書きがあるはずだ。
iptables のバージョンが上がるにつれて、たいていのモジュールは自動的にロードされるようになってきており、敢えてロードをかけなければならないモジュールはほとんどない。しかし、コントロール性という意味では、モジュール類は明示的にロードたほうがいい。例えば conntrack ヘルパーは決して自動ではロードされない。
Required modules> - このセクションには、必要なモジュールが並んでいる。セキュリティに貢献する特殊なモジュールや、管理者やクライアントに特別なサービスを与えるモジュールである場合もある。
Non-required modules - このセクションには通常の動作には必要のないモジュールが並んでいる。ここのモジュールはデフォルトではすべてコメントアウトされているはずだ。いずれかのモジュールの提供する機能が必要ならば、適宜アンコメントしていただきたい。
proc configuration - このセクションは、proc ファイルシステムに対して施すべき特別な設定を取り扱う。必要なものがあればしかるべくリストアップされているだろうし、必要のないものは、デフォルトではコメントアウトされた状態で Non-required proc configuration の下に並んでいるはずだ。有用な proc 設定はほとんどこの中でリストアップされているが、それとて全部というにはほど遠い。
Required proc configuration - このセクションには、そのスクリプトが機能するために必要とされる proc の全設定項目が並んでいる。セキュリティを高めるためのものや、またある時は、管理者やクライアントに対して特別なサービスや機能を与えるものである場合もある。
Non-required proc configuration - このセクションには、使ってみれば役に立つ、しかし特に必須ではない proc の設定項目が並んでいる。そのスクリプトが動作するのに必要というわけではないため、すべてコメントアウトされているはずだ。ここにリストされるのは、proc の設定やノードの中のほんの一握りに過ぎない。
rules set up - これより上の部分で、まず間違いなく、ルールセット を挿入するための準備は整っているはずだ。ルールが見つけやすく読みやすいようにするため、僕はまずルールをテーブル毎にまとめ、その下位はチェーン名毎にまとめることにした。いつも、ユーザ定義チェーンはシステム組み込みチェーンを云々する前に作っている。また、チェーンとその中のルール定義は、iptables -L コマンドで出力されるのと同じ順番で配置することにしている。
Filter table - まず最初に filter テーブルとその中身を仕上げる。最初にやるべきは、このテーブルの中のすべてのポリシーの設定だ。
Set policies - システムチェーンすべてのデフォルトポリシーをセットアップする。僕が通常 filter テーブルで採るのは、各チェーンのポリシーは DROP に設定しておき、受け入れるサービスやストリームは各々のチェーンの中で具体的に ACCEPT していくというやり方だ。こうすれば、使わせたくないポートをひとつ残らず排除することができる。
Create user specified chains - この段階で、当テーブル内で以後使っていくことになるユーザ定義チェーンを作成する。ユーザ定義チェーンが作られていないことには、システムチェーンからそれらを使うことは不可能なので、なるべく早い段階で着手することにしている。
Create content in user specified chains - ユーザ定義チェーンを作ったら、それらのチェーンの中のルールも全部組み立ててしまう。ここで早くもこのデータを入れてしまうのは、当のユーザ定義チェーンを作成したのと近い場所にデータを並べたいからでもある。べつに後で入れることにしても構わない。まったく各自の自由だ。
INPUT chain - もうここまで来たら filter テーブルでやるべきこともほぼ出尽くしたので、INPUT チェーンに乗り移る。この段階で、INPUT チェーンのルールを全部入れてしまう。
察しはつくだろうが、ここから先で、iptables -L の出力に従ってゆく。この構造に固執してもらう必要などまったくないのだが、異なったテーブルやチェーンのデータをごちゃ混ぜにするのだけはなるべく避けよう。そのようなルールセットは非常に読みにくく、問題が起こったときに修正するのが大変だからだ。
FORWARD chain - ここで FORWARD チェーンのルール作成に取りかかる。これといった理由はない。
OUTPUT chain - filter テーブルの最後に、OUTPUT チェーンに関わるルールに取り組む。おそらく、ここでやるべきことはそう多くはないだろう。
nat table - filter テーブルの次には、nat テーブルを処理する。filter テーブルの次に行うのには、これらのスクリプトとの兼ね合いで、いくつかの理由がある。まず第一に、あまり早い段階でフォワードメカニズムそのものと NAT 機能を有効にしたくないからだ。そうしてしまうと、好ましくないタイミング (NAT がオンであるにも拘わらず filter ルールが未整備という意味) で、パケットがファイヤーウォールを通り抜けてしまう可能性が高い。僕は nat テーブルを、filter テーブルのすぐ外側を取り囲む感じで存在する一種の膜のように捉えている。つまり filter テーブルが核で、nat テーブルは filter テーブルを包み込む層のように働く。そしてさらに mangle テーブルが第2 の層として nat テーブルをくるんでいるのだ。この捉え方は、見方によっては間違っているかもしれないが、当たらずとも遠からずといったところだと思う。
Set policies - 一番最初に、nat テーブルの中のデフォルトポリシーをすべてセットアップする。僕は通常、最初から設定されているポリシー、具体的には ACCEPT のままでいいと考えている。そもそもこのテーブルはフィルタリングに使うべきではなく、ここでパケットを破棄させてはならない。推測するところでは、そのようなことを行うと、ある種非常に厄介な問題が発生するおそれがあるからだ。ACCEPT にしない理由は見あたらないので、僕はこのチェーンを ACCEPT に設定する。
Create user specified chains - この時点で、nat テーブル内に置きたいユーザ定義チェーンを作成する。普通、僕はここにチェーンをひとつも作らないが、もしもということもあるのでこのセクションが設けてある。ユーザ定義チェーンは、それがシステムチェーンから使用される以前に作成されていなくてはならないということを忘れずに。
Create content in user specified chains - ここで、ユーザ定義チェーンにルールを構築する潮時となる。filter テーブルと同様なわけだ。この項目をこの場所に設けているのは、そうしてはいけない理由が見あたらないから。
PREROUTING chain - PREROUTING チェーンは、必要に応じて DNAT を行うところだ。ほとんどのスクリプトでは、使われていないか、少なくともコメントアウトされている。知らず知らずのうちにローカルネットワークに大穴を開けてしまうのは嫌だからだ。一部のスクリプトでは、この種の機能の提供こそが主眼であるため、敢えて DNAT を有効にしている場合もある。
POSTROUTING chain - 僕の書いたスクリプトの大半は、ファイヤーウォールの内側にローカルネットワークがひとつ以上あってそれをファイヤーウォールでインターネットから隔てることを前提としているため、POSTROUTING チェーンは多用している。使用するのは SNAT ターゲットが主だが、特定のケースでは MASQUERADE ターゲットを使う必要性に迫られる。
OUTPUT chain - OUTPUT チェーンはどのスクリプトでも、ほぼまったく使われていない。現状で見る感じでは、OUTPUT チェーンに不具合があるというわけではないにしろ、このチェーンを使うこれといった理由が今のところ見つからない。もし、このチェーンを使う必然性を見つけたら、僕にその定義行を送ってほしい。このチュートリアルに盛り込めるかもしれない。
mangle table - 最後に云々するのは mangle テーブルだ。僕は通常、このテーブルをまったく使わない。このテーブルは、全マシンで TTL を統一するだとか、TOS フィールドを変えるといった特殊な要件でもない限り、滅多に使うものではない。こうした理由から、ほとんどのスクリプトでは、ほぼ何も入れないことにした。ただし、 mangle テーブルの利用法を示すこと自体を目的としたスクリプトだけは別だ。
Set policies - このチェーンの中のデフォルトポリシーを設定する。ここでも nat テーブルとほぼ同じことが言える。このテーブルはフィルタリングのためのものではないので、そうしたことは一切行ってはならない。僕はどのスクリプトでも、mangle テーブルではいかなる意味でも一切ポリシーを設定していないし、あなたもしないようにすべきだ。
Create user specified chains - ユーザ定義チェーンを全部作る。僕はどのスクリプトでも mangle テーブルをまったく使っていないので、チェーンもひとつも作成していない。扱うデータがないのだから、作っても意味がない。それにも拘わらずこのセクションを置いているのは、将来、使う必要性が生じた時への備えだ。
Create content in user specified chains - このテーブルにユーザ定義チェーンがある時には、ここでそのルールを作るとよい。
PREROUTING chain - 現在のところ、当チュートリアルのスクリプトには、この部分のルールを含む内容はほぼ皆無。パケット単位あるいはコネクション単位で、netfilter マークやルーティングマーク、 SEC マークを付けるというのが PREROUTING チェーンの基本的な活用法だ。
INPUT chain - 現在のところ、当チュートリアルのスクリプトには、この部分のルールを含む内容はほぼ皆無。使うとすれば、マークのハンドリングなどに使用することができる。
FORWARD chain - mangle テーブルの FORWARD チェーンは、マークのハンドリングや、このファイヤーウォールを通っていくパケットのパケットヘッダを改変する時に活用する。例えば TTL や TOS の変更などだ。
OUTPUT chain - OUTPUT チェーンは、ファイヤーウォール (言い換えればこのホスト) から出て行こうとしているパケットに変更を加える際に利用する。例えば、 TTL や TOS を設定するなど、種々のマークを付ける場合だ。どのスクリプトでもほとんど行っていないが、セクションだけは置いてある。
POSTROUTING chain - 現在のところ、当チュートリアルのスクリプトでは基本的にこのチェーンは使用していない。使うとすれば、このホスト (つまりファイヤーウォール) を離れようとする時かこのホストの中を通過中の全パケットに、某かの値を設定する時だ。例えば、パケットの MTU の再設定、 TTL や TOS の設定などがこれにあたる。
この説明で、各スクリプトの構造と、そのような構造を採っている理由がよくわかってもらえたとしたらありがたい。
| お断りしておくが、上記の説明は相当はしょっている。スクリプトがどんな項目から出来ていて、なぜそのように分けたかという駆け足の説明であり、それ以上の何物でもない。決して、これが唯一最良の方法だと言っているわけではない。 |
14.2. rc.firewall.txt
rc.firewall.txt は、これ以外のスクリプトの土台にもなっているスクリプトだ。このスクリプトについては、rc.firewallファイル チャプターで細部に至るまで解説している。まず大前提として、これはふたつのネットワークから成るホームネットワークのために書かれている。例えば、ひとつの LAN と、ひとつのインターネット接続がある場合だ。このスクリプトはまた、インターネット用の固定IPを持っていることを想定しており、DHCP、PPP、SLIP などのプロトコルによって IP を自動割り当てされている場合には当てはまらない。そのような条件で動作するスクリプトを探しているのなら、rc.DHCP.firewall.txt を検討してみてほしい。
rc.firewall.txt スクリプトの動作には、以下のオプションが、カーネルにスタティックにコンパイルしてあるか、モジュールとしてコンパイルしてあることが必要だ。ひとつでも欠けていると、その機能を必要とする部分が使用不能となるため、スクリプト全体として何らかの機能不全を起こすことになる。実用に際してスクリプトを書き換える場合には、使おうとする機能によっては、これ以外のモジュールもカーネルにコンパイルする必要が出てくるかもしれない。
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_TARGET_LOG
14.3. rc.DMZ.firewall.txt
rc.DMZ.firewall.txt スクリプトは、構成ネットワークとして、ひとつの信頼できる内部ネットワーク と、ひとつの非武装地帯 (DMZ = De-Militalized Zone)、ひとつのインターネット接続 を持つ人たちのために書いたスクリプトだ。この例では、DMZ に対して 1 対 1 の NAT を行っているため、ファイヤーウォールに何らかのIPエイリアス (IP aliasing) 、つまり、複数の IPアドレスでパケットを聞けるよう処置を施しておく必要がある。これを実現する方法はいくつかあり、ひとつは 1 対 1 の NAT を設定するやり方、もうひとつは、もしサブネットをひとつ丸ごと自由にできるなら、サブネットワークを作り、ファイヤーウォールに内部/外部用となるひとつの IP を与えることだ。こうしておけば、あとは DMZ のマシンに好きなように IP を割り振ることができる。認識しておかなくてはならないのは、これによってふたつの IP が「盗み取られる」ということだ。ひとつはブロードキャスト用、もうひとつはネットワークアドレスだ。どちらを選択して実装するかはあなた自身にお任せするしかあるまい。このチュートリアルは、ファイヤーウォール部分と NAT 部分を完成させるための道具までは提供できる。しかし、やるべきことの具体的な説明については、当チュートリアルの守備範囲を超えてしまうので助けになれない。
rc.DMZ.firewall.txt が動作するには、以下のオプションが、スタティックに、あるいはモジュールとしてカーネルにコンパイルしてあることが必要だ。最小限でもこれらのオプションがカーネルで利用可能になっていなければ、このスクリプトを有効に機能させることはできない。言い換えると、モジュールやターゲット/ジャンプに関するエラーや、マッチが見つからないというエラーが、ごまんと吐き出されることとなる。トラフィック制御やそれに類する何かをしようと考えている場合は、これ以外の必要なオプションもすべてコンパイルしておく必要がある。
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_TARGET_LOG
図を見て分かるように、内側にはふたつのネットワークが必要となる。一方は、 IP範囲 192.168.0.0/24 を使用し、信頼する内部ネットワーク (Trusted Internal Network) がそこに属する。もう一方は IP範囲 192.168.1.0/24 を使用する 非武装地帯 であり、この DMZ 内の各ホストに対しては 1 対 1 の NAT を施す。例を挙げよう。もしインターネットから誰かが $DNS_IP へパケットを送ってくると、我々はそのパケットに DNAT を掛け、 DMZ にある我々の DNS サーバへ送る。当の DNS サーバがこのパケットと出会う時には、パケットの宛先は外部向けの DNS の IP ではなく、実際の DNS の内部用ネットワーク IP になっている。仮に、パケットの変換が行われていなかったとしたら、 DNS サーバはそのパケットに返答しないだろう。 DNAT のコードがどんなものになるか、ちょっと例を挙げておこう:
$IPTABLES -t nat -A PREROUTING -p TCP -i $INET_IFACE -d $DNS_IP \
--dport 53 -j DNAT --to-destination $DMZ_DNS_IP
大前提としてまず、 DNAT は nat テーブルの PREROUTING チェーンでしか行えない。そして、TCP プロトコルのうち、 $INET_IFACE から進入するパケットで、宛先IP が我々の $DNS_IP で、宛先ポートが 53 つまりネームサーバとの間でゾーン転送に使用される TCP ポートになっているパケットを網に掛けている。もしそのようなパケットを見つけたら、DNAT ターゲットを与える。その後ろで、 --to-destination オプションを使用して、パケットに行ってもらいたい場所として $DMZ_DNS_IP つまり DMZ にある DNS サーバの IP を与えている。これが基本的な DNAT の働きだ。 DNAT されたパケットに対する返答がファイヤーウォールへ送信された時には、自動的に 逆DNAT される。
これで、頭を抱えずにこのスクリプトを読み解ける程度には、動作の仕組みが理解してもらえたはずだ。もし不明な点があり、それが最後までどこでも触れられていなかったとしたら、それは僕の落ち度だからメールをいただきたい。
14.4. rc.DHCP.firewall.txt
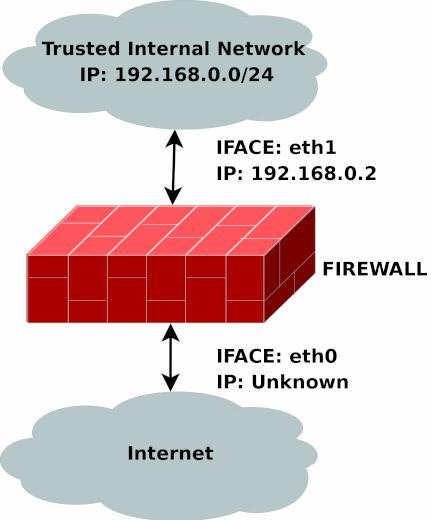
rc.DHCP.firewall.txt は、ほぼ rc.firewall.txtの原型そのままだ。ただし、こちらのスクリプトでは変数 $INET_IP は使っておらず、そこが元の rc.firewall.txt との大きな違いだ。動的IP での接続 (dynamic IP connection) との組み合わせだと、それでは機能してくれないからだ。とはいえ、原型からの変更点は最小限に留めている。こうしたケースでの問題をメールで質問されたことが何度かあるので、このスクリプトはきっと良い解決策になるだろう。このスクリプトでは、インターネット接続に DHCP、PPP、SLIP を使うことが
できるのだ。
rc.DHCP.firewall.txt スクリプトを満足に働かせるには、最低限でも以下のオプションが、スタティックに、あるいはモジュールとして、カーネルにコンパイルされている必要がある。
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_TARGET_MASQUERADE
CONFIG_IP_NF_TARGET_LOG
原型からの変更点の主なものは、先にも述べた $INET_IP 変数の除去と、それを参照する記述の削除だ。この変数を使用する代わりに、このスクリプトでは主要なフィルタリングを変数 $INET_IFACE に基づいて行っている。言い換えれば、-d $INET_IP が -i $INET_IFACE へ変わったわけだ。これがほぼ唯一の変更と言っても過言ではなく、実際、どうしても必要だったのはこれだけなのだ。
ただし、考察しておくべき点がまだ少しばかり残っている。我々はもう、INPUT チェーンでのフィルタリングを --in-interface $LAN_IFACE --dst $INET_IP のような評価基準で行うことはできない。その結果、内側のマシンがインターネット上で有効な種類の IP にアクセスしなければならなくなった際には、インターフェースに基づいてフィルタリングするしかなくなってしまう。その典型となるのが、我々がファイヤーウォール内で HTTP を運営している場合だ。内側のマシンでメインページ (例えば http://192.168.0.1/) を開き、そこに、同じホストへ戻る絶対指定のリンク (例えば http://foobar.dyndns.net/fuubar.html。これはダイナミックDNSに対応するためのひとつの方策) があったとすると、ちょっとした問題が起こる。この NAT されたマシンは HTTP サーバの IP を DNS に問い合わせ、その IP にアクセスしようとする。インターフェースと IP に基づくフィルタリングを行っている場合、INPUT チェーンはそのパケットを床に叩きつけて DROP してしまうので、NAT されたマシンは HTTP に辿り着けない。これは或る意味、固定IP を使っている際にも当てはまるのだが、その場合には、LANインターフェース で $INET_IP 宛のパケットかどうか調べて合致すれば ACCEPT する、というルールを加えることで切り抜けられるのだ。
前のほうから読み進んできた人なら見当がついたと思うが、動的IP をもうちょっとマシに処理できるスクリプトをどこかから入手するか、自分で書き上げるというのは名案だ。例えば、インターネット接続が立ち上がったと同時に ifconfig の出力から IP を取り出して変数にセットするようなスクリプトを書けばいいのだ。一案としては、例えば pppd などのプログラムと一緒に提供されている ip-up スクリプトを利用する手がある。役に立つサイトを探すなら、linuxguruz.org の iptables サイトを見てみるといいだろう。そこでは、膨大な数のスクリプトがダウンロードできるようになっている。linuxguruz.org へのリンクは付録 その他の資料とリンク にある。
| このスクリプトは rc.firewall.txt スクリプトに比べるとセキュリティにやや不安がある。外からのアタックに対して防御が甘くなっているので、上記のようなスクリプトが利用可能ならば、迷うことなくそれを使うことを強くお勧めする。 |
または、ファイヤーウォールスクリプト自体の中に、こうしたものを追加するという手もある:
INET_IP=`ifconfig $INET_IFACE | grep inet | cut -d : -f 2 | \
cut -d ' ' -f 1`
上記は、変数 $INET_IFACE を自動的に調べ、 IPアドレスを含む目的の行を grep し、そのまま使える IPアドレスへと cut で切り詰めている。もっときちんとやりたい人は retreiveip.txt の中からコードを切り出して使うといいだろう。そのスクリプトを走らせれば、インターネットIPアドレスを自動的に検出してくれるはずだ。ただし、これは若干の妙な挙動を引き起こしかねないという点を心していただきたい。ファイヤーウォールの内側で、ファイヤーウォールへの往来が息付きを起こすなどといった現象だ。以下に、妙な挙動のうち、ありがちなものをリストアップしておく。
例えば PPP デーモンなどが何らかのスクリプトを実行し、その中でこのスクリプトが実行された場合、"NEW でありながら SYN でない" ルールの働きによって、現在活動中のコネクションがハングする (NEWステートでありながらSYNビットの立っていないパケット セクションを参照のこと)。ひとつの手段として、"NEW でありながら SYN でない" ルールを取り除けばこの問題から逃げられなくもないが、はなはだ疑問の残るやり方だ。
既に定常化したルールがいくつかあり、それらを常に稼働させておきたい場合、既存のルールを破壊することなくルールを足したり消したりするのはなかなか厄介だ。例えば、LAN のマシンをファイヤーウォールに接続させないようにしていて、且つ PPP デーモンから何らかのスクリプトを実行したい場合、いかにして、LAN をブロックするルールを生かしたままルールを更新するか。
スクリプトが必要以上に複雑になり、既に述べたようなセキュリティの妥協を招く。スクリプトがシンプルであるほど、問題点も発見しやすく、コードに矛盾や混乱が生じにくい。
14.5. rc.UTIN.firewall.txt
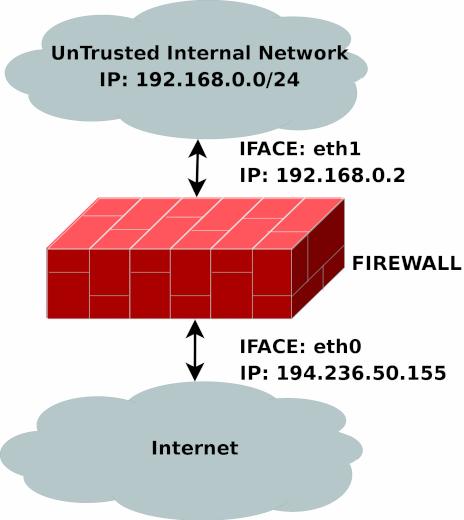
rc.UTIN.firewall.txt は、他のスクリプトとは対照的に、背後にある LAN をブロックする。つまり、ファイヤーウォールに接したどのネットワークの誰であろうと信用しない。また、LAN の構成員に対しては、インターネット上の特定のサービスしか利用させない。インターネットへのアクセスで許可するのは、POP3、HTTP、FTP だけだ。さらに、インターネット上のユーザを信頼していないばかりでなく、内部のユーザがファイヤーウォールにアクセスするのも快くしない。
rc.UTIN.firewall.txt スクリプトの動作には、以下のオプションが、カーネルにスタティックにコンパイルしてあるか、モジュールとしてコンパイルしてあることが必要だ。ひとつでも欠けていると、スクリプトによって必要とされる機能の一部が使用不能となるため、スクリプト全体として何らかの機能不全を起こすこととなる。実用に際してスクリプトを書き換える場合には、使おうとする機能によっては、これ以外のモジュールもカーネルにコンパイルする必要が出てくるかもしれない。
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_TARGET_LOG
このスクリプトは、何者をも信用しないことを鉄則とし、内輪の人間であろうとそれは同じだ。悲しいかな、企業を襲うハッキングやクラッキングのうち、内部のスタッフが絡んでいるケースが割合の多くを占めているのが実状だ。ファイヤーウォールを絞り上げようとした際にどういったことができるかと考える時に、このスクリプトは何かの手掛かりとなるだろう。元の rc.firewall.txt スクリプトとの違いはそれほど多くはないが、通常どういったものを通過できるようにしておけばよいか、など、参考になる点がいくつかあるはずだ。
14.6. rc.test-iptables.txt
rc.test-iptables.txt スクリプトを使うと、各種チェーンの実験ができる。ただし、使う人の設定によっては、ip_fowarding をオンにしたり、マスカレード (masquerading) を設定するなどといった、多少のチューニングが必要となる場合もある。しかし、基本的な設定がきちんとしてあって、基本チェーンがカーネルにロードされていれば、たいてい誰のところでも動くだろう。このスクリプトが実際にやっているのは、ping の要求と応答をログに書き出す LOG ターゲットをいくつか設定しているだけだ。それによって、どのチェーンがどういう順番で巡回されるかが見られる。例えば、このスクリプト実行してから、下記を発行する:
ping -c 1 host.on.the.internet
このコマンドを打つとともに、tail -n 0 -f /var/log/messages する。このようにすれば、各種のチェーンが使われる様子と、その順序が見られる。ただし、訳あってログエントリの順番は多少前後する。
| このスクリプトはテスト専用だ。言い換えると、1種類のパケットについてこのように多重的に何もかもログするようなルールを書くのは間違いだ。ログに使用しているパーティションはあっという間に満杯になってしまうだろう。まるで、効果抜群の DoS (Denial of Service) 攻撃だ。パーティションを使い切れば、ログを残すことなく DoS アタックができるので、本物の攻撃を招くおそれもある。 |
14.7. rc.flush-iptables.txt
rc.flush-iptables.txt スクリプトは、その性格上、本当の意味でのスクリプトとは言えない。rc.flush-iptables.txt スクリプトは、すべてのテーブルとチェーンのリセットとフラッシングを行う。このスクリプトでは、まず最初に、filter テーブルの INPUT、OUTPUT、FORWARD チェーンのポリシーを ACCEPT にする。次に、nat テーブルの PREROUTING、POSTROUTING、OUTPUT のデフォルトポリシーをリセットする。なぜこれらを最初に行うかといえば、そうすれば、コネクションが閉じてしまってパケットが立ち往生する心配をしなくてすむからだ。このスクリプトを作ったのは、実際のファイヤーウォール構築中にトラブルシュートに使ってもらえると思ったから。その意味から、このスクリプトはすべてを開放してデフォルトポリシーへとリセットすることだけに徹している。
その後、filter テーブル、nat テーブルの順で、そこに含まれるすべてのチェーンをフラッシングする。こうした過程を経て、邪魔くさいルールが綺麗さっぱりなくなっているという確信が持てる状態になる。それが完了したら、今度は nat テーブルと filter テーブルにあるユーザ定義チェーンを消し去る段階に突入する。これも終われば、即ちスクリプトは完了だ。mangle テーブルを使っている人は、そこをフラッシングするルールを加えてみてもいい。
| 最後に、このコードについて一言。このスクリプトを、 rc.firewall start とコマンドすればスクリプトがスタートする Red Hat Linux 流を用いて、元の rc.firewall.txt に組み込んでみてはどうか、と、ある人たちから提案を受けたことがある。しかし、この文書はチュートリアルであって、発想の源にしてもらうこと目指しているので、やたらとシェルスクリプトだらけになったり込み入った文法が満載になるのは好ましくない。だから、この提案は、今後も盛り込むことはないだろう。スクリプトに文法やら何やらが絡んでくると読解が難しくなる、というのが僕の考えだ。このチュートリアルは読みやすさ、分かりやすさをモットーとしており、これからもその方針は崩さないつもりだ。 |
14.8. Limit-match.txt
limit-match.txt スクリプトは、limit マッチの働きを見るための小さな実験用スクリプトだ。スクリプトをロードした上で、インターバルを変えながら ping を送ると、どれがどういった頻度で通るかを見ることができる。バーストリミット (burst limit) が一定のしきい値へと回復するまで echo応答 はブロックされる。
14.9. Pid-owner.txt
pid-owner.txt は、PID owner マッチの利用例を示したスクリプト。このスクリプトは大したことは何もしていない。ただ、スクリプトを実行し、iptables -L -v すれば、確かにルールにマッチしていることが分かる。
14.10. Recent-match.txt
recent-match.txt スクリプトは recent マッチの使い方を示す小さなサンプルスクリプトだ。このスクリプトのことを詳しく知るには iptablesのマッチ チャプターにある Recentマッチ セクションを読んでいただきたい。
14.11. Sid-owner.txt
sid-owner.txt は、SID owner マッチの利用例を示したスクリプト。このスクリプトは大したことは何もしていない。ただ、スクリプトを走らせて、iptables -L -v すれば、確かにルールにマッチしていることが分かる。
14.12. Ttl-inc.txt
小さな ttl-inc.txt スクリプト例。このスクリプトは、アタッカーに使われると多くの情報を与えてしまう traceroute から、ファイヤーウォール/ルータを隠す手法を示している。
14.13. Iptables-save ruleset
iptables-save の使い方を示すためにチャプター 大きなルールセットの保存とリストア で使用しているサンプルスクリプト。このスクリプトは動作しない。参考として見るだけで、決して実用してはならない。
14.14. まとめ
このチャプターでは、当チュートリアルに付属する様々なスクリプトの概要と、それぞれのスクリプトの伝えようとしていることを簡単に見ていただいた。少々でも理解してもらえたなら幸いだ。
次のチャプターでは、iptables 及び netfilter に利用可能な幾つかのグラフィカルユーザインターフェイスについて述べる。紹介しているのは世に出ているインターフェイスのごく一部に過ぎないが、それでも、見ていただくと分かるようにかなりの数に上る。これらのインターフェイスは主に、 iptables スクリプトの作成を容易にしようというもので、通常必要とされるシンプルな設定が相手なら充分過ぎるほどの機能を持っている。ただし、通常でない高度で複雑なものとなると、スクリプトは自分でせっせと書かなくてはならないかもしれない。
Chapter 15. iptables/netfilter用グラフィカルユーザインターフェイス
ここまでほとんど触れてこなかったものに、iptables/netfilter に利用可能なグラフィカルインターフェイスの話題がある。グラフィカルインターフェイスにとって大きな問題となるのは、 netfilter が非常に複雑かつフレキシブルであることと、行う作業の特殊性だ。それ故に、 netfilter 用 GUI の作成は困難を極める。
幾つかの個人や団体が netfilter/iptables の GUI 作成に取り組んできた。よそよりも多少うまくやれているところもあるが、暫くして開発を断念したところもあった。設計思想も千差万別で、とても全部を紹介することはできない。このチャプターでは、そのほんの一握りではあるが、見る価値のある幾つかの iptables 用 GUI を集めてみた。こんなものも加えてほしい、という提案はいつでも歓迎する。
15.1. fwbuilder
Firewall Builder、または単に fwbuilder と呼ばれるこの GUI は、もの凄く多機能でパワフルなツールで、ファイヤーウォールを構築したり、幾つものファイヤーウォールを管理したりできる。ポリシーを作成できる対応ファイヤーウォールはひとつではなく、 iptables (Linux 2.4, 2.6), ipfilter (freegsd, netbsdなど), openbsd pf、さらに、モジュールを購入すれば Cisco PIX にも対応する。
既にご存じかもしれないが、 fwbuilder には大勢が注目しており、維持、開発も継続的に行われている。 fwbuilder は独立したホストシステムの上で稼働し、そこでポリシーファイルを管理。そして目的のシステムへそれらをコピーして実行する。扱えるルールセットの規模は、単純なものから大規模でかなり込み入ったものまで幅広い。また、異なったバージョンの iptables を、各々別のターゲットやマッチで複数管理する能力も備えるなど、守備範囲も広い。完成した設定は xml ファイルとして保存されるが、システムで直接パース可能な設定ファイル (そのまま実行できるファイヤーウォールスクリプトなど) の形で保存することも可能だ。
上の例に示したのが fwbuilder の "firewall" 設定パネルとメインメニューだ。 fwbuilder は http://www.fwbuilder.org で入手できる。
15.2. Turtle Firewall プロジェクト
Turtle Firewall は、良くできた、しかしシンプルが旨の iptables ユーザインターフェイス。 webmin (web administration interface) と呼ばれるものに統合して使用する。 基本的なことだけができるように作られており、 fwbuilder パッケージほど複雑ではないし複雑な設定もできないが、大多数のシンプルなファイヤーウォールなら充分以上に扱えるし、多少の高等技術を使ったファイヤーウォールも操作できる。
Turtle Firewall 最大の強みは、 WEB ベースのプログラムだという点であり、そのため fwbuilder など他のツールとは全く違ったやり方でリモートからコントロールができるという点だ。もちろん、webmin もファイヤーウォール上で動く一個のサービスなので、ひとつのセキュリティリスクに成り得るのも確かだ。
上のスクリーンショットは Turtle Firewall の item ページを示したもので、ここからネットワークインターフェイスやネットワークなどの設定ができる。
次に挙げたスクリーンショットは、 Turtle Firewall のメインスクリーンを、下部に全ルールセットを展開した状態で示したもの。ルールセットは途中で切れているが、 Turtle Firewall 上でどのような見え方になるかは分かってもらえるだろう。
Turtle Firewall プロジェクトとその詳しい情報は http://www.turtlefirewall.com/ で見られる。
15.3. Integrated Secure Communications System
Integrated Secure Communications System、略して ISCS は、まだ開発の途中で、パブリックバージョンはリリースされていない。しかし、完成すれば非常にありがたいツールになりそうだ。開発陣は非常に高い目標を掲げており、リリースが遅れているのもそのためだ。 ISCS は幾つもの機能をひとつの管理/設定ユーザインターフェイス・スィートに統合する。つまり、大ざっぱに言えば、プロジェクトがリリースされた暁には、管理下の全てのファイヤーウォールはもちろん、 VPN、 VLAN、 トネリング、 sysctl などが、単一の GUI を通じて集中管理できることになる。
ISCS の開発陣が念頭に置いているのは、管理を簡素化してシステム管理者たちの無駄な労力を軽減し、ひいては、システム管理者の労働時間を短縮することだ。そのひとつの手段が、幾つものポリシーを放り込めばそれらをルールセットの形に仕上げて実行ポイント (enforcements points) へ送り込んで ("push") くれるようなプログラムを創り上げることなのだ。システム管理者はただポリシーを放り込むだけで、ちまちまと書いたりクリックしてつなぎ合わせたりする必要はなく、実装はすべて ISCS がやってくれるというわけだ。
このツールは本稿の執筆時点ではまだ完成していない。しかし僕はその開発リーダーと密に連絡を取っている。これは正直遠大なプロジェクトだ。完成すれば、間違いなく今日のマーケットでも最も優れたツールのひとつになる。結果は待つしかないが、ここで触れておくだけの価値はある。 ISCS プロジェクトのことは http://iscs.sourceforge.net/ で分かる。
| 僕は ISCS の開発リーダー John Sullivan に、開発に参加してくれる人を探してくれと頼まれた。非常に巨大なプロジェクトなので、手伝ってくれる人がいれば幾らでもほしいとのこと。もしあなたが手を貸してもいいと思っているのなら大歓迎だ。 |
15.4. IPMenu
IPMenu はとても賢いプログラムで、反面、操作は簡単でリソースや帯域幅もあまり喰わない。コンソールベースのプログラムであるため、例えば SSH 接続経由でも完璧に動作する。また、簡素で旧式のモデムでつながっているマシンでも充分に動作してくれる。
スクリーンショットから分かるように、 IPMenu は filter, mangle, nat を含めた iptables の全機能を扱える。また、ルーティングテーブルや帯域調整 (bandwidth shaping)、ルールセットのセーブやリストアも取り扱うことができる。これを使えば稼働中の iptables スクリプトにルールを直接追加することも簡単。どのテーブルでも操作対象となり、カスタムチェーンの追加や削除も可能だ。
スクリーンショットを見て分かるとおり、プログラムは簡素だが、ほとんどどんな状況にも対応できる。特筆すべきは、非常にシンプルなプログラムであり、リモートでの管理にも充分使えるという点だ。また、 ssh を介した純粋なコンソールで動くので、セキュリティ面でも太鼓判が押せる。 IPMenu のホームページは http://users.pandora.be/stes/ipmenu.html。
15.5. Easy Firewall Generator
Easy Firewall Generator も、完成の待ち遠しい開発途上のプログラムだ。概略としては、 Easy Firewall Generator は PHP で書かれた WEB ページであり、そこを通じてファイヤーウォールのオプションや性状を指定し、設定完了後にボタンを押せば、 WEB ページ上に iptables のルールセットが吐き出される仕組み。あとはそのルールセットを土台にして煮詰めていけばいい。
出力されるスクリプトには、基本的なルールの他、パケットの特徴に特化した、より個別的なルールも含まれている。また、必要に応じて IP sysctl による設定変更を含めたり、モジュールのロードを含めたりすることもできる。さらに、ルールセット全体を RedHat の init.d 形式で出力することも可能だ。
このスクリーンショットは操作の最終工程で、これから書き出すファイヤーウォールスクリプトを設定する画面だ。より詳しい情報と開発中の Easy Firewall Generator を入手するには http://easyfwgen.morizot.net/ へ行けばいい。
15.6. まとめ
このチャプターでは幾つかのグラフィカルユーザインターフェイスを取り上げ、それぞれに何ができるかなどを説明した。巷にはこの他にも幾つかのユーザインターフェイスが存在するということも知っておいていただきたい。このチャプターで述べたのは、世の中にある数種のファイヤーウォール管理インターフェイスの概容だ。紹介したプログラムの大部分はオープンソースであり無料で使用できるが、一部は、サポートやフル機能を活用するには少々の金額を支払う必要がある。
Chapter 16. Linux, iptables及びnetfilterをベースとした製品
このセクションは、企業の申し出によってその製品のテストを行い、その結果を掲載できるようにと設けたものだ。読者の中に企業の方がおられ、このセクションでテストしレビューてもらいたい製品があれば、いつでも大歓迎する。(通常通り、このチュートリアルの冒頭にある連絡先で著者にコンタクトしていただきたい)。承知しておいてもらわなければならないのは、このセクションは製品テスト情報を探す場所ではないということ。どちらかといえば、Linux ベースの製品の開発者や GNU/Linux ソフトウェアの開発に力を貸している人たち一般に、某かの情報を提供しようというコーナーだ。
自社の製品が不当に酷評されていると感じた方がおられたら、問題点の詳細な内容を知りたいという要望や、ファームウェアの更新等によって改訂した製品で再レビューをしてほしいという要望にも喜んで応じる。このポリシーは変わるかもしれない。というのも、このセクションがどれほど有名になるのか、筆者にはまだ分からないからだ。
16.1. Ingate Firewall 1200
一言で言えば、InGate Firewall 1200 は商用ファイヤーウォール製品だ。ざっくばらんに申し上げて、この製品は高価な部類に入り、ホームユーザ向けとはいえない。しかしながら、価格に見合うだけの価値はある。つまり、優れた製品である。詳細に入り込む前に、Ingate ファイヤーウォールがハードウェアとソフトウェアによるソリューションだということを言っておかなくてはならない。基本的には、特製の Linux カーネルで動作する非常に小さなコンピュータである。もちろん、Linux で動いているということを (インターフェイスの命名法などを除いては) 使用中に意識させることはない 。
ファイヤーウォールの設定や管理に使用する WEBインターフェイスの作成には、かなり力が入っている。InGate 1200 firewall は 2つの 10/100 Mbps イーサネットコネクタを備え、上位機種は更に多くのコネクタ (最大 6つの 10/100/1000 Mbps イーサネットコネクタと 2つのミニGbicポート) を装備している。
SIP の捜査と SIP によるインターネットフォンにも対応しており、TLS にもビルトインで対応している。モデル 1200 だと 2つの SIP ユーザライセンスが付属し、ライセンス数は購入する firewall/SIParator によって異なる。SIP の操作インターフェイスはよくできており、直感的で使いやすいが、高度な技術用語が山盛りだ。つまり、マニュアルは常に手元に置いておいた方がよく、殊に、この機器に何かしようという時には手放すわけにはいかない。マニュアルはよく書かれており、なお且つ、彼らの採用した極めてテクニカルな言葉遣いに慣れるまで、操作インターフェイスの理解には苦労する。マニュアルは 250ページ以上あり、現時点では英語とスウェーデン語が用意されており、そして、繰り返しになるが、内容はよく書かれている。
更に、InGate ファイヤーウォールは ipsec ベースの VPN と QoS にも対応している。ipsec ベースの VPN は、 "Road Warrior" ローミングなど他の機器の実装する ipsec とも互換性があるはずだ。
この機器はまた、非常に簡単に設定できるログ機能も持っている。ローカル上にログすることも、syslog や mail によるログ送信も可能だ。特に、ローカルロギングに見るログ検索機能はよく練り込まれていて秀逸だ。ローカルロギングにおいて僕の意識した唯一の問題は、検索エンジンが少々遅すぎること。このファイヤーウォール全体について気になった重要かつ唯一の点がこれで、ユーザインターフェイスが全体的に重く、編集後にメインページへジャンプしたりすることもあった。ただし、この問題は新しいバージョンで改善されるだろう。総合的に見ると、これは決してたちの悪いエラーではない。ことがユーザインターフェイスの遅さや妙なリンク程度で留まっているのだから。
入手したマシンを最初にテストしようとした時には、設定をかなり滅茶苦茶に壊してしまった (インターフェイスを入れ違えたり諸々)。そのため初回のセットアップでは、インターネットに接続できるまでに 4〜5時間かかった。当初の失敗を犯さなければ初回でも 1時間程度で完了できただろう。もちろん、初対面のユーザインターフェイスでなければこんな失敗は起きないと思われる。
デフォルトの値はよく考えられている。別の言い方をすれば、ごく基本的なオプション以外は、存在を忘れていいということだ。最初にやるべきことは "magic ping" (IPアドレスに対してデバイスの macアドレスをセットして、その IPアドレスに ping を飛ばす - これはローカル上でしかできない) によってデバイスの IPアドレスを設定すること。もう一方のイーサネットポートはデフォルトではオフにされており、敢えてオンにしない限り機能しないようになっている。基本的な設定以外 (ロググループなど) は InGate の開発陣によって設定済みだ。
結論として、これは僕の知る市販ファイヤーウォール製品のうちでベストに挙げていい製品のひとつだといえる。欠点は、ユーザインターフェイスがちょっとばかり遅いのと、値段が高いことだけだ。このデバイスの美点は、企業にありがちなコストの問題をカバーして余りあるもので、自力で一からシステムをインストールしなくてすむという簡便さは、ほとんどの企業にとって安上がりな選択となるだろう。特に、構成するファイヤーウォールの台数が多い場合だ。管理者が他の InGate 製品で扱いに慣れていればなおさらだ。まあこれは常にいえることだが。
16.2. まとめ
このチャプターでは、iptables や netfilter 及び Linux をベースにした幾つかの商用ファイヤーウォール製品について述べた。実は、リストにはここのチャプターで読んでもらったよりももっとたくさんのものがある。しかし、テストに取りかかるにあたって、兎も角、手始めの何かが必要だった。このセクションで取り上げた方がいいと思う製品があったら、それへのアクセスを数日間許可してくれるか、メーカーに連絡をして、僕にサンプルかデモマシンを送る気はないか訊いてみていただきたい。
さて、ここが最後のチャプターだ。残りは付録の数々。かなり興味深い情報ながらどのチャプターにも類別できなかったものや、表組みなどだ。この話題にまだまだ興味が尽きないなら、読むべきマテリアルはまだまだ五万とある。netfilter の WEBサイトへ行ってメーリングリストに参加しよう。iptables と netfilter の開発に参加するというのはどうだろう? このドキュメントを楽しんでくれただろうか。幾つかでも実際の設定をして試してもらえたとしたら嬉しく思う。
Appendix A. 特別なコマンドの詳細解説
A.1. 稼働中のルールセットのリストアップ
現在アクティブなルールセットをリストアップするには、iptables コマンドに特別なオプションを付けて実行する。詳しくはチャプター ルールの作り方 で述べた。コマンドは以下のようになる:
iptables -L
このコマンドを実行すると、現在動作しているルールセットが可能な限り読みやすい形に整形されてリストアップされるはずだ。整形とは、各種ポートは /etc/services ファイルに基づいてポート名へ、IPアドレスは DNS レコードを参照して名前に解決される、などといった事柄だ。ただし、後者は問題につながることもある。例えば 192.168.1.1 といった LAN IPアドレスも解決しようとするのだ。192.168.0.0/16 はプライベートアドレス域なのでリゾルブされるべきものではなく、解決しようと試みる間ハングしたようになる。この問題を避けるには、下記のようにする:
iptables -L -n
もうひとつ役に立つと思われるのは、ポリシー、ルール、チェーンそれぞれの統計情報を見ることだろう。これを行うには、冗長 (verbose) フラグを追加する。その時のコマンドは以下のようになる:
iptables -L -n -v
もちろん、nat テーブルや mangle テーブルをリストアップすることも可能だ。これは -t スイッチでできる。こんな具合だ:
iptables -L -t nat
また、/proc ファイルシステムにもいくつか興味を惹くファイルがある。例えば、今現在 conntrack テーブルにどんなコネクションが記録されているか調べると、役に立つことがある。このテーブルは現在捕捉されている各種のコネクション情報を保有しており、特定のコネクションがどのステート にあるかを知るための基準テーブルとして機能している。このテーブルに手を加えるのは不可で、もし変更できたとしても、ろくなことはない。テーブルを見るには下記のコマンドが使える:
cat /proc/net/ip_conntrack | less
上記コマンドを実行すれば、読み解くには多少の苦労が伴うにしろ、ともかく現在追跡されているコネクションのすべてが見られる。
A.2. テーブルのアップデートとフラッシュ
どこかで iptables がぐちゃぐちゃになってしまったとしても、フラッシングする手段が用意されているので、再起動する必要はない。この質問は何度も受けているので、ここで回答しておこうと思った次第だ。追加した時にルールを間違ってしまった場合は、ただ単に、その間違った行の中の -A パラメータを -D に変えればいいだけだ。そうすれば iptables はその行を見つけて削除してくれる。まったく同一内容の行が複数あった時には、指定した記述に合致する事例のうち最初に見つかったものだけが削除される。それでは困る場合には、-D オプションを iptables -D INPUT 10 のように使えば、INPUT チェーンの 10番目のルールを削除してくれる。
時には、あるチェーンをまるごとフラッシングしたいこともある。その場合は -F オプションの出番だ。例えば iptables -F INPUT は INPUT チェーンの内容をすべて消去する。ただし、これはデフォルトポリシーまでは変更してくれないので、もしもデフォルトポリシーが DROP に設定してあると、上記のやり方では INPUT チェーン全体を丸ごとブロックしてしまうことになる。チェーンのポリシーをリセットするには、DROP に設定した時と同様に、iptables -P INPUT ACCEPT といった具合にコマンドすればいい。
rc.firewall.txt ファイルを適切にセットアップしようとしている最中に iptables をフラッシング、リセットしたくなった時のことを考慮して、 rc.flush-iptables.txt (付録としても置いている) も用意しておいた。ただしひとつ留意点があって、もしあなたが mangle テーブルをいじくっている場合、そこはこのスクリプトでは消去されない。mangle テーブルも消去するには多少の行を追加するだけで、決して難しい話ではないのだが、rc.firewall.txt スクリプトはどこを見ても一切 mangle テーブルを使っていないので、盛り込まないことにした。
Appendix B. よくある問題と質問
B.1. モジュールロードのトラブル
モジュールのロードで問題にぶつかることがあるかもしれない。例えば、そのような名前のモジュールはないという旨のエラーなどだ。このエラーは下記のような表示となるだろう:
insmod: iptable_filter: no module by that name found
だが、そんなに心配することはない。そのモジュールはカーネルにスタティックにコンパイルされているのかもしれない。この問題を解決しようとする時に真っ先に検討すべきはこの点だ。そのモジュールが既にロード済みかどうか、あるいはカーネルにスタティックにコンパイルされているかどうかは、そのモジュールの機能を使用するようなコマンドを発行してみれば一目瞭然だ。上記の例ならば、filter テーブルをロードしようとしてもできないはずだ。当該の機能が存在しなければ、filter テーブルは、はなから使えないはずである。filter テーブルが存在するかどうか調べるには以下のようにする:
iptables -t filter -L
結果は、filter テーブル内のすべてのチェーンが出力されるか、もしくはエラーになるかのどちらかだ。もし問題がなければ、既にルールを入れてあるかどうかにもよるが、出力は下記のようなものになるはずだ:
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
一方、filter テーブルがロードできていない場合には下記の ようなエラーとなる:
iptables v1.2.5: can't initialize iptables table `filter': Table \
does not exist (do you need to insmod?)
Perhaps iptables or your kernel needs to be upgraded.
こうなると事態は少々深刻だ。第一の可能性としては、その機能がカーネルにコンパイルされていない、第二に、そのモジュールが通常のパス上に見つからない、ということを示しているからだ。こうなる原因として考えられるのは、モジュールをインストールするのを忘れたか、モジュールデータベースを更新する depmod -a をやり忘れたか、その機能がスタティックにもモジュールとしてもコンパイルされていないかだ。モジュールがロードされない原因はもちろんこの他にも考えられるが、主なものはこれらだ。これらの問題は簡単に解決できる。最初の原因なら、カーネルのソースディレクトリで make modules_install を実行すればよい (ただしソースがコンパイル済みでモジュールがビルド済みの場合)。 2番目である場合は、depmod -a を 1回実行してから、動くかどうか確かめてみることだ。3番目の問題はここで扱うには少々手に余るので、自分で頭をひねっていただくしかなさそうだ。この件についての詳しい情報は、Linux Documentation Project で見つかるだろう。
iptables 実行時に遭遇するかもしれないもうひとつのエラーは下記 のものだ。
iptables: No chain/target/match by that name
このエラーは、そのようなチェーンはない、あるいは、ターゲットまたはマッチがない と告げている。これには膨大な数のファクターが絡んでくるが、一番ありがちなのは、チェーン、ターゲット、マッチのスペルを打ち間違えていることだ。また、利用不可能なマッチを使用しようとした場合にも、このエラーが出る。適切なモジュールがロードされていないか、カーネルにコンパイルされていない、あるいは、iptables がモジュールの自動ロードに失敗したかのいずれかが原因だろう。おしなべて言えば上記の解決策を全部検討してみるべきだが、ルールの中に某かの誤字がないかも見直してみたほうがいい。
B.2. NEWステートでありながらSYNビットの立っていないパケット
iptables の仕様のうち、充分な説明がなく、多くの人 (正直、僕もそのひとりだった) が見落としている部分がひとつある。 NEW ステートを使用した時、SYN ビットの立っていないパケットでもファイヤーウォールを通過してしまうのだ。この仕様が存在するのは、場合によっては、あるパケットが、別のファイヤーウォールなどで ESTABLISHED 状態であるコネクションに、属している可能性を検討したいことがあるからだ。これのおかげで、複数のファイヤーウォールの併設が可能となり、うち 1つのファイヤーウォールではデータを一切損失することなく受けるということが可能となる。こうすれば、副ファイヤーウォールにサブネットのファイヤーウォール処理を引き継がせることができる。とはいえ、この仕様が、NEW ステートを用いると、それが接続開始時の 3 ウェイハンドシェークであろうとなかろうと、あらゆる種類の TCP コネクションを許してしまう結果をもたらしているのは事実だ。この問題に対処するには、以下のルールを INPUT、OUTPUT、FORWARD チェーンに追加する:
$IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j LOG \
--log-prefix "New not syn:"
$IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j DROP
| 上記のルールはこの問題を処置してくれる。この動作は Netfilter/iptables プロジェクトでろくに説明されていない。本来ならば絶対に特記されてしかるべき事柄だ。言い換えれば、ファイヤーウォールの構築時には、こうした動作に対して厳重な注意を払っていなくてはならないということだ。 |
認識しておかなくてはならないのは、このルールが、マイクロソフトによる間違った TCP/IP 実装との間で少々問題を起こすという点だ。上記のルールでは、時として、マイクロソフト製品が発したパケットが NEW ステートと見なされ、故にログおよび破棄されることがある。とはいえ、僕の知る限りでは、それでコネクションが絶たれてしまうことはないようだ。これが発生するのはコネクションがクローズされる時で、最後の FIN/ACK が送られ、Netfilter のステート機構がコネクションを閉じ、この接続が conntrack テーブルから消された際に起こる。マイクロソフトの異常な実装は、この時期になって、さらにパケットを送ってくるのだ。そのパケットは、NEW ステートと判断されるが、SYN ビットを欠いているので上記のルールにマッチしてしまう。つまるところ、このルールについてあれこれ悩む必要はない。どうしても気になるなら、このルールに --log-tcp-options オプションを付けてヘッダもログするようにすれば、パケットの中身がもう少し詳しく調べられるだろう。
このルールにはもうひとつ問題がある。PPP 接続時に起動されるよう仕組んであるスクリプトがあり、その時、例えば LAN 内から、誰かが既にファイヤーウォールへコネクションを張っていた場合だ。この場合、PPP 接続が開始すると、LAN からの既存のコネクションは事実上抹殺される。この現象が起こるのは、スクリプトコード上で conntrack と nat をモジュールとして扱っており、そのスクリプトが走る度にモジュールのロード/アンロードが行われる場合に限られる。また、ファイヤーウォール以外のホストから telnet 経由で rc.firewall.txt スクリプトを走らせた場合にも発現する。話を単純化するため、今あなたは telnet などのストリームコネクションでファイヤーウォールに接続するとしよう。あなたはコネクション追跡モジュールをロードし、それから "NEW であるが SYN でない " ルールをロードする。そこで、telnet クライアントあるいはデーモンが何か送ろうとする。しかしこの時、コネクション追跡コードにとって、現コネクション上では双方向のパケットは未検出で、しかも、そのパケットはコネクションにおける最初のパケットではないので SYN ビットは立っていない。そのため、コネクション追跡機構はこれを正規のコネクションとは認めない。その結果、そのパケットは例のルールに合致してログされ、床に投げ捨てられてしまうのだ。
B.3. SYN/ACKでNEWなパケット
ある種の TCP 成りすまし アタックでは、シーケンスナンバー予測 (Sequence Number Prediction) が使われることがある。この種のアタックでは、アタックに際して他のホストの IPアドレスに偽装した上で、目的のホストが使用するシーケンスナンバー を予測しようとする。
シーケンスナンバー予測による典型的な TCP 成りすまし攻撃の例を見てみよう。登場人物: "アタッカー" [A] が、"被害者" [V] に対しての攻撃を、"他ホスト" [O] であるかのように見せかけて行う。
[A] が SYN を [V] へ送る。送信元IPは [O] のものを使っている。
[V] が [O] に SYN/ACK を回答する。
この時点で [O] が未知の SYN/ACK に対して RST を送り返せば、アタックは失敗に終わる。しかし、[O] は落ちている (フラッドさせられたか、電源を落としてあるか、そうしたパケットを破棄するようなファイヤーウォールの内側にある) と仮定しよう。
アタックが [O] によって台無しにされなかった場合、[A] は、シーケンスナンバー さえ正しく予測できれば、[O] に成りすましたまま [V] と通信できる状態となる。
我々が 3 の段階で未知の SYN/ACK に対して RST を送るようにしていなければ、[V] が攻撃されるのを容認したことになり、我々は共犯者となってしまう。よって、[V] に対しては適切に RST を送るようにしておくのが常識的な配慮である。ルールセット内で "NEW だが SYN でない " ルールを用いていれば、SYN/ACK パケットは破棄される。以上のことから、下記のルールを bad_tcp_packets チェーンの "NEW だが SYN でない " ルールの直前に組み込んでいるのだ:
iptables -A bad_tcp_packets -p tcp --tcp-flags SYN,ACK SYN,ACK \ -m state --state NEW -j REJECT --reject-with tcp-reset
当シナリオの [O] になってしまう可能性はかなり減らすことができ、しかもこのルールが障害になることは滅多にない。ただし、複数のファイヤーウォールで冗長化していて、それらファイヤーウォール間でパケットやストリームの引き継ぎが頻繁に行われる場合だと話は別だ。そのような場合、正規のコネクションであったとしてもブロックされてしまうケースが出てくるだろう。また、このルールはこちらのファイヤーウォールに対するポートスキャンを或る程度許してしまうが、それ以上の何かをされる心配はない。
B.4. 予約済みIPアドレスを使用するインターネットサービスプロバイダ
この項目を追加したのは、友人から、僕がすっかり見落としていた話題を耳にしたからだ。一部の間抜けなサービスプロバイダは、ユーザが接続する必要のある場所に、IANA によってローカルネットワーク用として予約されている IPアドレスを使っているのだ。例を挙げると、Swedish Internet Service Provider と 電話公社 Telia が DNS サーバなどにこうした手法を使っている。使用されているのは 10.x.x.x という IPアドレス域だ。これは iptables スクリプトを書く上で、容易に障壁となる。 10.x.x.x の IPアドレス範囲といえば、自分の方へ向かってくるコネクションは成りすましの危険性があるため、一切許可しないようにするのは普通であり、そのことと衝突してしまうのだ。まったく困ったことだが、この場合にはルールの敷居を少し低くしてやるしかない。そうした DNS サーバからのトラフィックを許可するには、成りすましセクションの手前に ACCEPT ルールを挿入するか、スクリプトの成りすましルール部をコメントアウトするかだ。ルールはこのような感じになる:
/usr/local/sbin/iptables -t nat -I PREROUTING -i eth1 -s \
10.0.0.1/32 -j ACCEPT
ちょっと、そんなプロバイダへ苦言を呈する暇をいただきたい。これらの IPアドレス域は、僕の知る限り、こんな使い方をしていいものでない。企業の巨大サイトか、あんたらのホームネットワークで使うなら大手を振ってやっていただいて構わないが、あんたがたの気まぐれでこっちが節穴を開けさせられるなど、言語道断だ。零細プロバイダでもなかろうに、 DNS 用のたかだか 3つや 4つの IPアドレスに費用が出せないとは理解に苦しむ。
B.5. iptablesにDHCPリクエストを通させる
これは、DHCP の仕組みさえ知っていれば至って単純な話だ。ただし、許すものと許さないものの区別に少し気を付けなくてはならない。まず第一の前提として、DHCP は UDP プロトコル上で働く。従って、それが第一の判定基準となる。第二に、リクエストの送受信をどのインターフェースを通して行うか検討する必要がある。例えば eth0 インターフェースが DHCP によって設定されるなら、eth1 は DHCP リクエストを通してはならない。DHCP が使う UDP ポート、つまり 67 と 68 を具体的に指定して、ルールをやや厳格なものにする。パケットのマッチと許可に際しての評価方針は以上だ。ルールは下記のようになる:
$IPTABLES -I INPUT -i $LAN_IFACE -p udp --dport 67:68 --sport \
67:68 -j ACCEPT
これで、送信元と宛先がともに UDP ポート 67 番か 68 番であるトラフィックは、すべて許可される。とはいっても、接続してくる相手のポートも 67 か 68 である場合しか要求を受け入れないので、大きな問題は生じないはずだ。もちろん、もっと厳格にすることも可能だが、最小限の開放で全ての DHCP リクエストと更新送受を受け入れるという意味ではこれで充分だ。こだわるのなら、もちろんもっと厳しくしても構わない。
B.6. mIRC DCCのトラブル
mIRC は、ファイヤーウォールが関知しなくても、ファイヤーウォール経由で接続して DCC コネクションを成り立たせる特殊な設定を、自前で備えている。このオプション設定が有効にしてあって、さらに ip_conntrack_irc と ip_nat_irc モジュールがわざわざロードされていた場合には、絶対にうまくいかない。問題なのは、mIRC 自体が自動的にパケットの中身を NAT しているので、それがファイヤーウォールに届いた時、どう処理したらいいのかファイヤーウォールに分からないという点だ。mIRC はファイヤーウォールがこれを処理できるほど賢いことは期待していない。その代わりに、IPアドレスは IRC サーバに直接問い合わせ、DCC リクエストはそこで知れたアドレスへ送信するのだ。
設定オプションの "私はファイヤーウォールの内側にいます (I am behind a firewall) " の項目がオンになっていて、ip_conntrack_irc と ip_nat_irc モジュールも使用していた場合、Netfilter は "偽造DCCパケットの送信 (Forged DCC send packet) " という旨のログを吐く。
最も単純明快な解決策は、 mIRC 側の設定オプションのチェックマークを外し、処理を iptables に任せること。つまり、ファイヤーウォールの内側にいるのではありません、と mIRC に指示すればいいわけだ。
Appendix C. ICMPタイプ
以下が ICMPタイプ の全リストだ。そのタイプ/コードの組み合わせを発表した RFC または人物も示しておいた。 ICMP タイプ/コードの最新版の完全なリストが見たいのならば Internet Assigned Numbers Authority の icmp-parameters をご覧いただきたい。
| Iptables 及び netfilter は内部的にタイプ 255 の ICMP を使用する。タイプ 255 は他のどこでも実用に供されされておらず、また、今後も使用される見込みもほぼないからだ。 iptables -A INPUT -p icmp --icmp-type 255 -j DROP というルールをセットしたとすれば、ICMP パケットは全て DROP される。つまり、このルールは全ての ICMP パケットをマッチさせたい時に利用できるわけだ。 |
[訳者註: 下表で "(廃)" としたものは obsolete の意、つまり古くなって廃止されたものを表す]
Table C-1. ICMPタイプ
| TYPE | CODE | 意味 | 問合せ | エラー | 参照先 |
|---|---|---|---|---|---|
| 0 | 0 | Echo Reply (エコー応答) | x | RFC792 | |
| 3 | 0 | Network Unreachable (ネットワーク到達不能) | x | RFC792 | |
| 3 | 1 | Host Unreachable (ホスト到達不能) | x | RFC792 | |
| 3 | 2 | Protocol Unreachable (プロトコル到達不能) | x | RFC792 | |
| 3 | 3 | Port Unreachable (ポート到達不能) | x | RFC792 | |
| 3 | 4 | Fragmentation needed but no frag. bit set (フラグメント必要だがフラグメント禁止ビットあり) | x | RFC792 | |
| 3 | 5 | Source routing failed (ソースルーティング失敗) | x | RFC792 | |
| 3 | 6 | Destination network unknown (宛先ネットワーク発見できず) | x | RFC792 | |
| 3 | 7 | Destination host unknown (宛先ホスト発見できず) | x | RFC792 | |
| 3 | 8 | Source host isolated (送信元ホストへのルートなし) (廃) | x | RFC792 | |
| 3 | 9 | Destination network administratively prohibited (宛先ネットワークは設定によりアクセス禁止) | x | RFC792 | |
| 3 | 10 | Destination host administratively prohibited (宛先ホストは設定によりアクセス禁止) | x | RFC792 | |
| 3 | 11 | Network unreachable for TOS (TOS種別によりネットワーク到達不能) | x | RFC792 | |
| 3 | 12 | Host unreachable for TOS (TOS種別によりホスト到達不能) | x | RFC792 | |
| 3 | 13 | Communication administratively prohibited by filtering (フィルタリング設定により通信禁止) | x | RFC1812 | |
| 3 | 14 | Host precedence violation (ホスト優先順位侵害) | x | RFC1812 | |
| 3 | 15 | Precedence cutoff in effect (優先順位により遮断発動) | x | RFC1812 | |
| 4 | 0 | Source quench (輻輳発生による発信抑制) | RFC792 | ||
| 5 | 0 | Redirect for network (指定ネットワークへのリダイレクト要求) | RFC792 | ||
| 5 | 1 | Redirect for host (指定ホストへのリダイレクト要求) | |||
| 5 | 2 | Redirect for TOS and network (TOSとネットワークのリダイレクト要求) | RFC792 | ||
| 5 | 3 | Redirect for TOS and host (TOSとホストのリダイレクト要求) | RFC792 | ||
| 8 | 0 | Echo request(エコー要求) | x | RFC792 | |
| 9 | 0 | Router advertisement - Normal router advertisement (ルータ広告 - 通常通知) | RFC1256 | ||
| 9 | 16 | Router advertisement - Does not route common traffic (ルータ広告 - 通常トラフィックはルーティング不可) | RFC2002 | ||
| 10 | 0 | Route selection (ルート選択) | RFC1256 | ||
| 11 | 0 | TTL equals 0 during transit (搬送中にTTLが0に) | x | RFC792 | |
| 11 | 1 | TTL equals 0 during reassembly (再構成時の欠損フラグメント待機中に時間超過) | x | RFC792 | |
| 12 | 0 | IP header bad (catchall error) (IPヘッダ異常) (あらゆるエラーに共通) | x | RFC792 | |
| 12 | 1 | Required options missing (必要なオプションが欠如) | x | RFC1108 | |
| 12 | 2 | IP Header bad length (IPヘッダ長の異常) | x | RFC792 | |
| 13 | 0 | Timestamp request (obsolete) (タイムスタンプ要求) (廃) | x | RFC792 | |
| 14 | Timestamp reply (obsolete) (タイムスタンプ応答) (廃) | x | RFC792 | ||
| 15 | 0 | Information request (obsolete) (情報要求) (廃) | x | RFC792 | |
| 16 | 0 | Information reply (obsolete) (情報応答) (廃) | x | RFC792 | |
| 17 | 0 | Address mask request (ネットマスク通知要求) | x | RFC950 | |
| 18 | 0 | Address mask reply (ネットマスク通知応答) | x | RFC950 | |
| 20-29 | Reserved for robustness experiment (信頼性試験のための予約域) | Zaw-Sing Su | |||
| 30 | 0 | Traceroute | x | RFC1393 | |
| 31 | 0 | Datagram Conversion Error (データグラム変換エラー) | x | RFC1475 | |
| 32 | 0 | Mobile Host Redirect (移動体ホストのリダイレクト) | David Johnson | ||
| 33 | 0 | IPv6 Where-Are-You (IPv6位置確認要求) | x | Bill Simpson | |
| 34 | 0 | IPv6 I-Am-Here (IPv6位置確認応答) | x | Bill Simpson | |
| 35 | 0 | Mobile Registration Request (移動体登録要求) | x | Bill Simpson | |
| 36 | 0 | Mobile Registration Reply (移動体登録応答) | x | Bill Simpson | |
| 39 | 0 | SKIP | Tom Markson | ||
| 40 | 0 | Photuris | RFC2521 |
Appendix D. TCPオプション
当付録は TCPオプション の簡潔な記述で、正式に認められているオプションの全てを網羅している。これらの参照先とナンバー規定は Internet Assigned Numbers Authority の WEB サイトからダウンロードできる。マスターファイルは ここ で見ることができる。無用なアクセスや連絡で迷惑を掛けないようにとの配慮から、リスト内の個人情報は削除した。
Table D-1. TCPオプション
| Copy | Class | Number | 値 | 名称 | 参照先 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | EOOL - End of Options List | [RFC791, JBP] |
| 0 | 0 | 1 | 1 | NOP - No Operation | [RFC791, JBP] |
| 1 | 0 | 2 | 130 | SEC - Security | [RFC1108] |
| 1 | 0 | 3 | 131 | LSR - Loose Source Route | [RFC791, JBP] |
| 0 | 2 | 4 | 68 | TS - Time Stamp | [RFC791, JBP] |
| 1 | 0 | 5 | 133 | E-SEC - Extended Security | [RFC1108] |
| 1 | 0 | 6 | 134 | CIPSO - Commercial Security | [???] |
| 0 | 0 | 7 | 7 | RR - Record Route | [RFC791, JBP] |
| 1 | 0 | 8 | 136 | SID - Stream ID | [RFC791, JBP] |
| 1 | 0 | 9 | 137 | SSR - Strict Source Route | [RFC791, JBP] |
| 0 | 0 | 10 | 10 | ZSU - Experimental Measurement | [ZSu] |
| 0 | 0 | 11 | 11 | MTUP - MTU Probe | [RFC1191]* |
| 0 | 0 | 12 | 12 | MTUR - MTU Reply | [RFC1191]* |
| 1 | 2 | 13 | 205 | FINN - Experimental Flow Control | [Finn] |
| 1 | 0 | 14 | 142 | VISA - Experimental Access Control | [Estrin] |
| 0 | 0 | 15 | 15 | ENCODE - ??? | [VerSteeg] |
| 1 | 0 | 16 | 144 | IMITD - IMI Traffic Descriptor | [Lee] |
| 1 | 0 | 17 | 145 | EIP - Extended Internet Protocol | [RFC1385] |
| 0 | 2 | 18 | 82 | TR - Traceroute | [RFC1393] |
| 1 | 0 | 19 | 147 | ADDEXT - Address Extension | [Ullmann IPv7] |
| 1 | 0 | 20 | 148 | RTRALT - Router Alert | [RFC2113] |
| 1 | 0 | 21 | 149 | SDB - Selective Directed Broadcast | [Graff] |
| 1 | 0 | 22 | 150 | NSAPA - NSAP Addresses | [Carpenter] |
| 1 | 0 | 23 | 151 | DPS - Dynamic Packet State | [Malis] |
| 1 | 0 | 24 | 152 | UMP - Upstream Multicast Pkt. | [Farinacci] |
Appendix E. その他の資料とリンク
以下は、各種資料と、僕が情報収集に利用したサイトなどへのリンク:
ip-sysctl.txt - 2.4.14 カーネル付属文書より。少々簡略ではあるが役に立つ、 IP ネットワーク制御値と、それら各々のカーネルに対する役割の手引き書。
InGate - InGate は Linuxベースの商用ファイヤーウォール製品を作っているメーカー。プロダクトレンジは、ごく基本的なファイヤーウォールから SIPゲートウェイや QoSマシンまでと幅広い。
RFC 768 - User Datagram Protocol - UDP プロトコルの使用法とヘッダ全てを記述した正式な RFC 文書。
RFC 791 - 機能の追加や変更が加えられながら現在のインターネットでも使用されている IP についての仕様書。 基本部分は IPv4 でも変わっていない。
RFC 792 - Internet Control Message Protocol - ICMP パケットに関する情報を何か調べたい時、最も信頼の置ける資料。 ICMP プロトコルについて技術的な情報が必要になった時、必ず最初に見てみるべきはここ。 J. Postel 著。
RFC 793 - Transmission Control Protocol - あらゆるホストにおける TCP の動作の仕方に関して、大元となる資料がこれ。1981年以来、このドキュメントは TCP の動作仕様の規範となっている。極めて専門的だが、TCP を子細に渡って学びたい人なら必読だ。この資料は、J. Postel によって書かれた米国防総省の規格書に基づいている。
RFC 1122 - Requirements for Internet Hosts - Communication Layers - この RFC はインターネットホスト上で動作するソフトウェアの満たすべき諸元を、特に、コミュニケーション関係の層について規定している。
RFC 1349 - Type of Service in the Internet Protocol Suite - IPヘッダ の TOSフィールド に関する既定の変更と諸元の整理を行った RFC。
RFC 1812 - Requirements for IP Version 4 Routers -この RFC は、インターネット上のルータがどう振る舞うべきかや、様々な状況に際しての然るべき挙動について規定している。興味深い読み物だ。
RFC 2401 - Security Architecture for the Internet Protocol - IPSEC の実装と標準化について記述した RFC。 IPSEC と関わり合うつもりなら一読に値する。
RFC 2474 - Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers - この文書からは、 DiffServ の動作理論と、 DiffServ プロトコルを動作させる上で TCP/IP プロトコルに加える必要のある拡張や変更について、多くの情報が得られる。
RFC 2638 - A Two-bit Differentiated Services Architecture for the Internet - 異なったふたつの DS (Differentiated Service) アーキテクチャを組み合わせて実装する方法を解説している RFC。これらは共に、 IETH ミーティング 1997 で D.Clark と van Jacobsen によって書かれたものを起源としている。
RFC 2960 - Stream Control Transmission Protocol - 数社の通信系大企業によって開発された比較的新しいプロトコル。 UDP と TCP を補強するレイヤー3 のプロトコルで、高い信頼性とエラー回復性能を備えている。
RFC 3168 - The Addition of Explicit Congestion Notification (ECN) to IP - この RFC は、ECN の技術レベルにおける利用法と、 TCP/IP プロトコル上での実装方法を規定している。著者は K. Ramakrishnan, S. Floyd, D. Black。
RFC 3260 - New Terminology and Clarifications for Diffserv - このメモは Diffserv ワーキンググループで合意に至った新たな改良点をまとめるとともに、技術面での明確化や整理を幾つか行っている。
RFC 3286 - An Introduction to the Stream Control Transmission Protocol - Stream Control Transmission Protocol を紹介する RFC。SCTP は TCPスタックの中では比較的新しい部類に入るプロトコルで、数社の通信系大企業によって開発された。
ip_dynaddr.txt - カーネル 2.4.14 付属文書より。sysctl および proc ファイルシステムを利用した ip_dynaddr 設定に関する、非常に短い手引き書。
iptables.8 - iptables 1.3.1 の man ページ。これは、iptables ルールセットを読み書きするに当たって非常にためになるその man ページを HTML化したもの。いつも手元に置いておきたい。
Ipsysctl tutorial - 僕の書いたもうひとつのチュートリアルで、 Linux の備える IP System Control について解説している。 Linux の稼働中でも設定変更のできる IP 関連変数を全てリストアップしようとした、ひとつの試みだ。
Policy Routing Using Linux - 遂にインターネット上でも読めるようになった、 Linux におけるポリシールーティングについての優れた文書。とてもよく書かれていて、 1冊買ってみて損はない。 Matthew G. Marsh 著。
Security-Enhanced Linux - 米・国家安全保障局 (NSA) によってそのコンセプトが策定された Security-Enhanced Linux (SELinux) システムのオフィシャルサイト。SELinux は緻密に設計された強制アクセス制御機構で、誰に何ができ、どのプロセスがどんな権限を持つか、といったきめ細かな制御を可能とする
Firewall rules table - 当プロジェクトのために Stuart Clark が寄稿してくれた PDF 書類。設定値の書き込みフォームになっており、自分のファイヤーウォールを構築する際に必要となる情報を分かりやすく整理することができる。
http://l7-filter.sourceforge.net/ - l7-filter プロジェクトは、iptables 及び netfilter でレイヤー7 フィルタリングを可能にしようというもので、主にパッチとファイルから成る。主な用途は QoS とトラフィック課金。ただし、トラフィックが実際にブロックされるまでに数個のパケットが通ってしまうため、フィルタリング用途においては信頼性に欠ける。
http://www.netfilter.org/ - Netfilter iptables のオフィシャルサイト。Linux で iptables および Netfilter をセットアップしようとするすべての人にとって必見。
http://www.insecure.org/nmap/ - Nmap は、現在入手可能なものの中でも最も優れた、名のあるポートスキャナのひとつ。ファイヤーウォールスクリプトのデバグの際に非常に役に立つ。手に入れて実際に試してみよう。
http://www.netfilter.org/documentation/index.html#FAQ - Netfilter のオフィシャルFAQ。iptables、 Netfilter とは何か知りたくなった時の事始めとしてもおすすめ。
http://www.netfilter.org/unreliable-guides/packet-filtering-HOWTO/index.html - "Rusty Russells の頼りないガイド (Rusty Russells Unreliable Guide)" パケットフィルタリング編。 iptables, Netfilter 開発の中核メンバーのひとりが書いた、 iptables による基本的フィルタリングについての素晴らしいドキュメント。
http://www.netfilter.org/unreliable-guides/NAT-HOWTO/index.html - "Rusty Russells の頼りないガイド (Rusty Russells Unreliable Guide)" ネットワークアドレス変換編。iptables, Netfilter 開発の中核メンバーのひとり Rusty Russells が書いた、 iptables, Netfilter におけるネットワークアドレス変換 に関する素晴らしいドキュメント。
http://www.netfilter.org/unreliable-guides/netfilter-hacking-HOWTO/index.html - "Rusty Russells の頼りないガイド (Rusty Russells Unreliable Guide)" の Netfilter ハッキング HOW-TO。Netfilter, iptables のユーザ空間でのコードの書き方と、カーネル空間でのコードベースを扱った数少ないドキュメント。これも Rusty Russell によって書かれた。
http://www.linuxguruz.org/iptables/ - iptables および Netfilter 関連のインターネット上のページをほとんど網羅した素晴らしいリンク集。各種用途の iptables スクリプト集も用意されている。
Policy Routing using Linux - Linux でのポリシールーティングに関して、これに勝る本は見たことがない。Linux でのルーティングに手を染めて以来、僕のマストアイテムとなっている。Matthew G. Marsh 著.
Implementing Quality of Service Policies with DSCP - Cisco での DSCP の実装に関するリンク。 DSCP で使われるクラスなどが分かる。
IETF SIP Working Group - SIP はどうやら「次の大きな波」となりそうだ。SIP は今日のインターネット・テレフォニーのデファクトスタンダードとなっている。ワーキンググループのホームページに見られるドキュメントの量からも分かるように、SIP は極めて複雑で、将来登場するほとんどあらゆるセッションベースの通信に対応できるのではないだろうか。SIP は既知のユーザ間でのピアtoピア・コネクションの締結、例えば、user@example.org に接続して電話接続を成り立たせるような時に使われる。この IETF ワーキンググループは SIP に関する全ての作業を執り行っている。
IETF TLS Working Group - TLS はトランスポート層でのセキュリティモデルであり、ホスト-サーバ ベースのセキュリティメカニズムとしては最も一般的なもののひとつ。本稿執筆時点では 1.1 だが、より効果の高い新しい暗号化への対応に扉を開く 1.2 へのバージョンアップが進められている。これは、サーバの公開鍵を送受したり、信頼済みの証明書エージェントと遣り取りする方法などを決めた共通規格だ。詳しくは上記ページにある RFC を読んでいただきたい。
IPSEC Howto - Linux カーネル 2.6 を対象にした IPSEC のオフィシャル HOWTO。カーネル 2.6 以降での IPSEC の動作は解説されているが、カーネル 2.2 や 2.4 でどのように機能していたかは、ここには明白な情報がない。それが知りたい場合は FreeS/WAN のサイトへ行ってみよう。
FreeS/WAN - ここは Linux カーネル 2.2, 2.4 での IPSEC 実装である FreeS/WAN のオフィシャルサイト。ドキュメントの他、 IPSEC を実装するときに必要となるあらゆるものがダウンロードできる。サイトに書かれている幾つかの理由で活動は停止状態にあるが、バグフィクスとドキュメント、フォーラムには今も力が注がれている。 カーネル 2.6 での IPSEC 実装に関しては IPSEC Howto を見るといいだろう。
http://www.islandsoft.net/veerapen.html - iptables の自動強化と、iptables 内の特別な拒否リストに攻撃サイトを自動的に登録できるようにするための小改造について素晴らしい議論を展開している。
/etc/protocols - Slackware から例として引用した protocols ファイル。IP、ICMP、TCP などのプロトコルに関して、プロトコルごとにどんなプロトコルナンバーがあるか調べるのに役立つ。
/etc/services - Slackware から例として引用した services ファイル。折に触れて眺めていると、絶対に役に立つ。特に、どのプロトコルがどういったポートで働くのか概要を知りたい時には打ってつけ。
Internet Assigned Numbers Authority - IANA は各プロトコルの全数字規格を整理統括する役割を担う団体。プロトコルに特別な機能を追加 (例えば新たな TCP オプションの追加) しようとする者は、 IANA にコンタクトをとらなくてはならない。そうすると IANA が必要なナンバーを割り当ててくれる。つまりは、目を離すことのできない極めて重要なサイトということだ。
RFC-editor.org - RFC 文書を素早く見つけることができる素晴らしいサイト。 RFC 文書の検索機能、 RFC 全般に関する情報 (errata, ニュースなど)。
Internet Engineering Task Force - ここは、インターネット標準規格の設定と維持における、最も大きなグループのひとつだ。RFC 書庫を維持管理しているのもここで、膨大な数に上る企業や個人が協力し合ってインターネットの相互接続技術の安定に努めている。
Linux Advanced Routing and Traffic Control HOW-TO - このサイトは "Linux における高度ルーティングとトラフィック制御 HOWTO" を公開している。Linux の高度ルーティングの領域で、最も詳しく最も優れたドキュメントのひとつだ。 Bert Hubert が管理運営している。
Paksecured Linux Kernel patches - Matthew G. Marsh が書いたすべてのカーネルパッチを掲載したサイト。様々なパッチがあるが、FTOS パッチが入手できるのはここだ。
ULOGD project page - ULOGD のホームページ。
Linux Documentation Project はドキュメントの殿堂だ。ほとんどの大物ドキュメントはここにあり、 TLDP になければネットで検索してもかなり手こずるというほどだ。何かさらに詳しく調べたい事柄が出てきたら、このサイトを隈なく見てみよう。
Snort - オープンソースの素晴らしいネットワーク侵入検知システム (network intrusion detection system = NIDS)。触れたパケットのシグネチャを検査しており、アタックや侵入の印となるシグナチャを見つけると、設定によってカスタマイズ可能な特定のアクション (管理者への報告や何らかの処置、あるいはロギング) を実行する。
Tripwire - ホストへの侵入の検知に使える優れたセキュリティツール。 Tripwire は設定ファイルで指定されているファイル全てについてチェックサムを作成する。そして実行される度に、不正書き換えのされた疑いのあるファイルを管理者に知らせる。
Squid - 現在入手可能なものの中でも最も有名な WEB プロキシのひとつ。オープンソースで、無料で利用できる。 WEB キャッシングはもちろんだが、トラフィックが WEB サーバに到達する以前のフィルタリングに利用できる幾つかの機能も持つ。
http://kalamazoolinux.org/presentations/20010417/conntrack.html - このドキュメントには、各種 conntrack モジュールの紹介と、それらが Netfilter 上で担う役割についての素晴らしい解説が含まれている。conntrack についてより詳しく知りたい時には、ここは必読。
http://www.docum.org - Linux における CBQ, tc, ip コマンドに関する優れた情報源。そもそも、これらのプログラムについて扱っているサイトは数えるほどしかない。Stef Coene によって管理運営されている。
http://lists.samba.org/mailman/listinfo/netfilter - Netfilter のオフィシャルメーリングリスト。当ドキュメントでもリンクでも触れられていない事柄で疑問が湧いた時、強力に役に立つ。
それにもちろん、iptables のソース、ドキュメントも参考になったし、いろいろな人にもお世話になった。
Appendix F. 謝辞
I would like to thank the following people for their help on this document:
Fabrice Marie, For major updates to my horrible grammar and spelling. Also a huge thanks for updating the tutorial to DocBook format with make files etc.
Marc Boucher, For helping me out on some aspects on using the state matching code.
Frode E. Nyboe, For greatly improving the rc.firewall rules and giving great inspiration while i was to rewrite the rule-set and being the one who introduced the multiple table traversing into the same file.
Chapman Brad, Alexander W. Janssen, Both for making me realize I was thinking wrong about how packets traverse the basic NAT and filters tables and in which order they show up.
Michiel Brandenburg, Myles Uyema, For helping me out with some of the state matching code and getting it to work.
Kent `Artech' Stahre, For helping me out with the graphics. I know I suck at graphics, and you're better than most I know who do graphics;). Also thanks for checking the tutorial for errors etc.
Anders 'DeZENT' Johansson, For hinting me about strange ISPs and so on that uses reserved networks on the Internet, or at least on the Internet for you.
Jeremy `Spliffy' Smith, For giving me hints at stuff that might screw up for people and for trying it out and checking for errors in what I've written.
Appendix G. History
Version 1.2.2 (19 Nov 2006) http://iptables-tutorial.frozentux.net By Oskar Andreasson Contributors: Jens Larsson and G. W. Haywood. Version 1.2.1 (29 Sep 2006) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Ortwin Glueck, Mao, Marcos Roberto Greiner, Christian Font, Tatiana, Andrius, Alexey Dushechkin, Tatsuya Nonogaki and Fred. Version 1.2.0 (20 July 2005) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Corey Becker, Neil Perrins, Watz and Spanish translation team. Version 1.1.19 (21 May 2003) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Peter van Kampen, Xavier Bartol, Jon Anderson, Thorsten Bremer and Spanish Translation Team. Version 1.1.18 (24 Apr 2003) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Stuart Clark, Robert P. J. Day, Mark Orenstein and Edmond Shwayri. Version 1.1.17 (6 Apr 2003) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Geraldo Amaral Filho, Ondrej Suchy, Dino Conti, Robert P. J. Day, Velev Dimo, Spencer Rouser, Daveonos, Amanda Hickman, Olle Jonsson and Bengt Aspvall. Version 1.1.16 (16 Dec 2002) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Clemens Schwaighower, Uwe Dippel and Dave Wreski. Version 1.1.15 (13 Nov 2002) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Mark Sonarte, A. Lester Buck, Robert P. J. Day, Togan Muftuoglu, Antony Stone, Matthew F. Barnes and Otto Matejka. Version 1.1.14 (14 Oct 2002) http://iptables-tutorial.frozentux.net By: Oskar Andreasson Contributors: Carol Anne, Manuel Minzoni, Yves Soun, Miernik, Uwe Dippel, Dave Klipec and Eddy L O Jansson. Version 1.1.13 (22 Aug 2002) http://iptables-tutorial.haringstad.com By: Oskar Andreasson Contributors: Tons of people reporting bad HTML version. Version 1.1.12 (19 Aug 2002) http://www.netfilter.org/tutorial/ By: Oskar Andreasson Contributors: Peter Schubnell, Stephen J. Lawrence, Uwe Dippel, Bradley Dilger, Vegard Engen, Clifford Kite, Alessandro Oliveira, Tony Earnshaw, Harald Welte, Nick Andrew and Stepan Kasal. Version 1.1.11 (27 May 2002) http://www.netfilter.org/tutorial/ By: Oskar Andreasson Contributors: Steve Hnizdur, Lonni Friedman, Jelle Kalf, Harald Welte, Valentina Barrios and Tony Earnshaw. Version 1.1.10 (12 April 2002) http://www.boingworld.com/workshops/linux/iptables-tutorial/ By: Oskar Andreasson Contributors: Jelle Kalf, Theodore Alexandrov, Paul Corbett, Rodrigo Rubira Branco, Alistair Tonner, Matthew G. Marsh, Uwe Dippel, Evan Nemerson and Marcel J.E. Mol. Version 1.1.9 (21 March 2002) http://www.boingworld.com/workshops/linux/iptables-tutorial/ By: Oskar Andreasson Contributors: Vince Herried, Togan Muftuoglu, Galen Johnson, Kelly Ashe, Janne Johansson, Thomas Smets, Peter Horst, Mitch Landers, Neil Jolly, Jelle Kalf, Jason Lam and Evan Nemerson. Version 1.1.8 (5 March 2002) http://www.boingworld.com/workshops/linux/iptables-tutorial/ By: Oskar Andreasson Version 1.1.7 (4 February 2002) http://www.boingworld.com/workshops/linux/iptables-tutorial/ By: Oskar Andreasson Contributors: Parimi Ravi, Phil Schultz, Steven McClintoc, Bill Dossett, Dave Wreski, Erik Sj・und, Adam Mansbridge, Vasoo Veerapen, Aladdin and Rusty Russell. Version 1.1.6 (7 December 2001) http://people.unix-fu.org/andreasson/ By: Oskar Andreasson Contributors: Jim Ramsey, Phil Schultz, G・an B・e, Doug Monroe, Jasper Aikema, Kurt Lieber, Chris Tallon, Chris Martin, Jonas Pasche, Jan Labanowski, Rodrigo R. Branco, Jacco van Koll and Dave Wreski. Version 1.1.5 (14 November 2001) http://people.unix-fu.org/andreasson/ By: Oskar Andreasson Contributors: Fabrice Marie, Merijn Schering and Kurt Lieber. Version 1.1.4 (6 November 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Contributors: Stig W. Jensen, Steve Hnizdur, Chris Pluta and Kurt Lieber. Version 1.1.3 (9 October 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Contributors: Joni Chu, N.Emile Akabi-Davis and Jelle Kalf. Version 1.1.2 (29 September 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Version 1.1.1 (26 September 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Contributors: Dave Richardson. Version 1.1.0 (15 September 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Version 1.0.9 (9 September 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Version 1.0.8 (7 September 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Version 1.0.7 (23 August 2001) http://people.unix-fu.org/andreasson By: Oskar Andreasson Contributors: Fabrice Marie. Version 1.0.6 http://people.unix-fu.org/andreasson By: Oskar Andreasson Version 1.0.5 http://people.unix-fu.org/andreasson By: Oskar Andreasson Contributors: Fabrice Marie.
Appendix H. GNU Free Documentation License
Version 1.1, March 2000
Copyright (C) 2000 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or other written document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you".
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (For example, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, whose contents can be viewed and edited directly and straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup has been designed to thwart or discourage subsequent modification by readers is not Transparent. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML designed for human modification. Opaque formats include PostScript, PDF, proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY
If you publish printed copies of the Document numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a publicly-accessible computer-network location containing a complete Transparent copy of the Document, free of added material, which the general network-using public has access to download anonymously at no charge using public-standard network protocols. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has less than five).
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section entitled "History", and its title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
In any section entitled "Acknowledgements" or "Dedications", preserve the section's title, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section as "Endorsements" or to conflict in title with any Invariant Section.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections entitled "History" in the various original documents, forming one section entitled "History"; likewise combine any sections entitled "Acknowledgements", and any sections entitled "Dedications". You must delete all sections entitled "Endorsements."
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, does not as a whole count as a Modified Version of the Document, provided no compilation copyright is claimed for the compilation. Such a compilation is called an "aggregate", and this License does not apply to the other self-contained works thus compiled with the Document, on account of their being thus compiled, if they are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one quarter of the entire aggregate, the Document's Cover Texts may be placed on covers that surround only the Document within the aggregate. Otherwise they must appear on covers around the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License provided that you also include the original English version of this License. In case of a disagreement between the translation and the original English version of this License, the original English version will prevail.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST. A copy of the license is included in the section entitled "GNU Free Documentation License".
If you have no Invariant Sections, write "with no Invariant Sections" instead of saying which ones are invariant. If you have no Front-Cover Texts, write "no Front-Cover Texts" instead of "Front-Cover Texts being LIST"; likewise for Back-Cover Texts.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Appendix I. GNU General Public License
Version 2, June 1991
Copyright (C) 1989, 1991 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. Preamble
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users. This General Public License applies to most of the Free Software Foundation's software and to any other program whose authors commit to using it. (Some other Free Software Foundation software is covered by the GNU Library General Public License instead.) You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights. These restrictions translate to certain responsibilities for you if you distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must give the recipients all the rights that you have. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
We protect your rights with two steps: (1) copyright the software, and (2) offer you this license which gives you legal permission to copy, distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain that everyone understands that there is no warranty for this free software. If the software is modified by someone else and passed on, we want its recipients to know that what they have is not the original, so that any problems introduced by others will not reflect on the original authors' reputations.
Finally, any free program is threatened constantly by software patents. We wish to avoid the danger that redistributors of a free program will individually obtain patent licenses, in effect making the program proprietary. To prevent this, we have made it clear that any patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and modification follow.
1. TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
This License applies to any program or other work which contains a notice placed by the copyright holder saying it may be distributed under the terms of this General Public License. The "Program", below, refers to any such program or work, and a "work based on the Program" means either the Program or any derivative work under copyright law: that is to say, a work containing the Program or a portion of it, either verbatim or with modifications and/or translated into another language. (Hereinafter, translation is included without limitation in the term "modification".) Each licensee is addressed as "you".
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running the Program is not restricted, and the output from the Program is covered only if its contents constitute a work based on the Program (independent of having been made by running the Program). Whether that is true depends on what the Program does.
You may copy and distribute verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and give any other recipients of the Program a copy of this License along with the Program.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
You may modify your copy or copies of the Program or any portion of it, thus forming a work based on the Program, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
You must cause the modified files to carry prominent notices stating that you changed the files and the date of any change.
You must cause any work that you distribute or publish, that in whole or in part contains or is derived from the Program or any part thereof, to be licensed as a whole at no charge to all third parties under the terms of this License.
If the modified program normally reads commands interactively when run, you must cause it, when started running for such interactive use in the most ordinary way, to print or display an announcement including an appropriate copyright notice and a notice that there is no warranty (or else, saying that you provide a warranty) and that users may redistribute the program under these conditions, and telling the user how to view a copy of this License. (Exception: if the Program itself is interactive but does not normally print such an announcement, your work based on the Program is not required to print an announcement.)
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Program, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Program, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Program.
In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
You may copy and distribute the Program (or a work based on it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you also do one of the following:
Accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
Accompany it with a written offer, valid for at least three years, to give any third party, for a charge no more than your cost of physically performing source distribution, a complete machine-readable copy of the corresponding source code, to be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
Accompany it with the information you received as to the offer to distribute corresponding source code. (This alternative is allowed only for noncommercial distribution and only if you received the program in object code or executable form with such an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.
You may not copy, modify, sublicense, or distribute the Program except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense or distribute the Program is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Program or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Program (or any work based on the Program), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Program or works based on it.
Each time you redistribute the Program (or any work based on the Program), the recipient automatically receives a license from the original licensor to copy, distribute or modify the Program subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties to this License.
If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Program at all. For example, if a patent license would not permit royalty-free redistribution of the Program by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system, which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
If the distribution and/or use of the Program is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Program under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
The Free Software Foundation may publish revised and/or new versions of the General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation.
If you wish to incorporate parts of the Program into other free programs whose distribution conditions are different, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally.
NO WARRANTY
BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
2. How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively convey the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this when it starts in an interactive mode:
Gnomovision version 69, Copyright (C) year name of author Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'. This is free software, and you are welcome to redistribute it under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate parts of the General Public License. Of course, the commands you use may be called something other than `show w' and `show c'; they could even be mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your school, if any, to sign a "copyright disclaimer" for the program, if necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program
`Gnomovision' (which makes passes at compilers) written by James Hacker.
<signature of Ty Coon>, 1 April 1989
Ty Coon, President of Vice
This General Public License does not permit incorporating your program into proprietary programs. If your program is a subroutine library, you may consider it more useful to permit linking proprietary applications with the library. If this is what you want to do, use the GNU Library General Public License instead of this License.
Appendix J. スクリプト例コードベース
J.1. Example rc.firewall script
#!/bin/sh
#
# rc.firewall - Initial SIMPLE IP Firewall script for Linux 2.4.x and iptables
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
###########################################################################
#
# 1. Configuration options.
#
#
# 1.1 Internet Configuration.
#
INET_IP="194.236.50.155"
INET_IFACE="eth0"
INET_BROADCAST="194.236.50.255"
#
# 1.1.1 DHCP
#
#
# 1.1.2 PPPoE
#
#
# 1.2 Local Area Network configuration.
#
# your LAN's IP range and localhost IP. /24 means to only use the first 24
# bits of the 32 bit IP address. the same as netmask 255.255.255.0
#
LAN_IP="192.168.0.2"
LAN_IP_RANGE="192.168.0.0/16"
LAN_IFACE="eth1"
#
# 1.3 DMZ Configuration.
#
#
# 1.4 Localhost Configuration.
#
LO_IFACE="lo"
LO_IP="127.0.0.1"
#
# 1.5 IPTables Configuration.
#
IPTABLES="/usr/sbin/iptables"
#
# 1.6 Other Configuration.
#
###########################################################################
#
# 2. Module loading.
#
#
# Needed to initially load modules
#
/sbin/depmod -a
#
# 2.1 Required modules
#
/sbin/modprobe ip_tables
/sbin/modprobe ip_conntrack
/sbin/modprobe iptable_filter
/sbin/modprobe iptable_mangle
/sbin/modprobe iptable_nat
/sbin/modprobe ipt_LOG
/sbin/modprobe ipt_limit
/sbin/modprobe ipt_state
#
# 2.2 Non-Required modules
#
#/sbin/modprobe ipt_owner
#/sbin/modprobe ipt_REJECT
#/sbin/modprobe ipt_MASQUERADE
#/sbin/modprobe ip_conntrack_ftp
#/sbin/modprobe ip_conntrack_irc
#/sbin/modprobe ip_nat_ftp
#/sbin/modprobe ip_nat_irc
###########################################################################
#
# 3. /proc set up.
#
#
# 3.1 Required proc configuration
#
echo "1" > /proc/sys/net/ipv4/ip_forward
#
# 3.2 Non-Required proc configuration
#
#echo "1" > /proc/sys/net/ipv4/conf/all/rp_filter
#echo "1" > /proc/sys/net/ipv4/conf/all/proxy_arp
#echo "1" > /proc/sys/net/ipv4/ip_dynaddr
###########################################################################
#
# 4. rules set up.
#
######
# 4.1 Filter table
#
#
# 4.1.1 Set policies
#
$IPTABLES -P INPUT DROP
$IPTABLES -P OUTPUT DROP
$IPTABLES -P FORWARD DROP
#
# 4.1.2 Create userspecified chains
#
#
# Create chain for bad tcp packets
#
$IPTABLES -N bad_tcp_packets
#
# Create separate chains for ICMP, TCP and UDP to traverse
#
$IPTABLES -N allowed
$IPTABLES -N tcp_packets
$IPTABLES -N udp_packets
$IPTABLES -N icmp_packets
#
# 4.1.3 Create content in userspecified chains
#
#
# bad_tcp_packets chain
#
$IPTABLES -A bad_tcp_packets -p tcp --tcp-flags SYN,ACK SYN,ACK \
-m state --state NEW -j REJECT --reject-with tcp-reset
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j LOG \
--log-prefix "New not syn:"
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j DROP
#
# allowed chain
#
$IPTABLES -A allowed -p TCP --syn -j ACCEPT
$IPTABLES -A allowed -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A allowed -p TCP -j DROP
#
# TCP rules
#
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 21 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 22 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 80 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 113 -j allowed
#
# UDP ports
#
#$IPTABLES -A udp_packets -p UDP -s 0/0 --destination-port 53 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --destination-port 123 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --destination-port 2074 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --destination-port 4000 -j ACCEPT
#
# In Microsoft Networks you will be swamped by broadcasts. These lines
# will prevent them from showing up in the logs.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE -d $INET_BROADCAST \
#--destination-port 135:139 -j DROP
#
# If we get DHCP requests from the Outside of our network, our logs will
# be swamped as well. This rule will block them from getting logged.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE -d 255.255.255.255 \
#--destination-port 67:68 -j DROP
#
# ICMP rules
#
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 8 -j ACCEPT
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 11 -j ACCEPT
#
# 4.1.4 INPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A INPUT -p tcp -j bad_tcp_packets
#
# Rules for special networks not part of the Internet
#
$IPTABLES -A INPUT -p ALL -i $LAN_IFACE -s $LAN_IP_RANGE -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LO_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LAN_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $INET_IP -j ACCEPT
#
# Special rule for DHCP requests from LAN, which are not caught properly
# otherwise.
#
$IPTABLES -A INPUT -p UDP -i $LAN_IFACE --dport 67 --sport 68 -j ACCEPT
#
# Rules for incoming packets from the internet.
#
$IPTABLES -A INPUT -p ALL -d $INET_IP -m state --state ESTABLISHED,RELATED \
-j ACCEPT
$IPTABLES -A INPUT -p TCP -i $INET_IFACE -j tcp_packets
$IPTABLES -A INPUT -p UDP -i $INET_IFACE -j udp_packets
$IPTABLES -A INPUT -p ICMP -i $INET_IFACE -j icmp_packets
#
# If you have a Microsoft Network on the outside of your firewall, you may
# also get flooded by Multicasts. We drop them so we do not get flooded by
# logs
#
#$IPTABLES -A INPUT -i $INET_IFACE -d 224.0.0.0/8 -j DROP
#
# Log weird packets that don't match the above.
#
$IPTABLES -A INPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT INPUT packet died: "
#
# 4.1.5 FORWARD chain
#
#
# Bad TCP packets we don't want
#
$IPTABLES -A FORWARD -p tcp -j bad_tcp_packets
#
# Accept the packets we actually want to forward
#
$IPTABLES -A FORWARD -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A FORWARD -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT FORWARD packet died: "
#
# 4.1.6 OUTPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A OUTPUT -p tcp -j bad_tcp_packets
#
# Special OUTPUT rules to decide which IP's to allow.
#
$IPTABLES -A OUTPUT -p ALL -s $LO_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $LAN_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $INET_IP -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A OUTPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT OUTPUT packet died: "
######
# 4.2 nat table
#
#
# 4.2.1 Set policies
#
#
# 4.2.2 Create user specified chains
#
#
# 4.2.3 Create content in user specified chains
#
#
# 4.2.4 PREROUTING chain
#
#
# 4.2.5 POSTROUTING chain
#
#
# Enable simple IP Forwarding and Network Address Translation
#
$IPTABLES -t nat -A POSTROUTING -o $INET_IFACE -j SNAT --to-source $INET_IP
#
# 4.2.6 OUTPUT chain
#
######
# 4.3 mangle table
#
#
# 4.3.1 Set policies
#
#
# 4.3.2 Create user specified chains
#
#
# 4.3.3 Create content in user specified chains
#
#
# 4.3.4 PREROUTING chain
#
#
# 4.3.5 INPUT chain
#
#
# 4.3.6 FORWARD chain
#
#
# 4.3.7 OUTPUT chain
#
#
# 4.3.8 POSTROUTING chain
#
J.2. Example rc.DMZ.firewall script
#!/bin/sh
#
# rc.DMZ.firewall - DMZ IP Firewall script for Linux 2.4.x and iptables
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
###########################################################################
#
# 1. Configuration options.
#
#
# 1.1 Internet Configuration.
#
INET_IP="194.236.50.152"
HTTP_IP="194.236.50.153"
DNS_IP="194.236.50.154"
INET_IFACE="eth0"
#
# 1.1.1 DHCP
#
#
# 1.1.2 PPPoE
#
#
# 1.2 Local Area Network configuration.
#
# your LAN's IP range and localhost IP. /24 means to only use the first 24
# bits of the 32 bit IP address. the same as netmask 255.255.255.0
#
LAN_IP="192.168.0.1"
LAN_IFACE="eth1"
#
# 1.3 DMZ Configuration.
#
DMZ_HTTP_IP="192.168.1.2"
DMZ_DNS_IP="192.168.1.3"
DMZ_IP="192.168.1.1"
DMZ_IFACE="eth2"
#
# 1.4 Localhost Configuration.
#
LO_IFACE="lo"
LO_IP="127.0.0.1"
#
# 1.5 IPTables Configuration.
#
IPTABLES="/usr/sbin/iptables"
#
# 1.6 Other Configuration.
#
###########################################################################
#
# 2. Module loading.
#
#
# Needed to initially load modules
#
/sbin/depmod -a
#
# 2.1 Required modules
#
/sbin/modprobe ip_tables
/sbin/modprobe ip_conntrack
/sbin/modprobe iptable_filter
/sbin/modprobe iptable_mangle
/sbin/modprobe iptable_nat
/sbin/modprobe ipt_LOG
/sbin/modprobe ipt_limit
/sbin/modprobe ipt_state
#
# 2.2 Non-Required modules
#
#/sbin/modprobe ipt_owner
#/sbin/modprobe ipt_REJECT
#/sbin/modprobe ipt_MASQUERADE
#/sbin/modprobe ip_conntrack_ftp
#/sbin/modprobe ip_conntrack_irc
#/sbin/modprobe ip_nat_ftp
#/sbin/modprobe ip_nat_irc
###########################################################################
#
# 3. /proc set up.
#
#
# 3.1 Required proc configuration
#
echo "1" > /proc/sys/net/ipv4/ip_forward
#
# 3.2 Non-Required proc configuration
#
#echo "1" > /proc/sys/net/ipv4/conf/all/rp_filter
#echo "1" > /proc/sys/net/ipv4/conf/all/proxy_arp
#echo "1" > /proc/sys/net/ipv4/ip_dynaddr
###########################################################################
#
# 4. rules set up.
#
######
# 4.1 Filter table
#
#
# 4.1.1 Set policies
#
$IPTABLES -P INPUT DROP
$IPTABLES -P OUTPUT DROP
$IPTABLES -P FORWARD DROP
#
# 4.1.2 Create userspecified chains
#
#
# Create chain for bad tcp packets
#
$IPTABLES -N bad_tcp_packets
#
# Create separate chains for ICMP, TCP and UDP to traverse
#
$IPTABLES -N allowed
$IPTABLES -N icmp_packets
#
# 4.1.3 Create content in userspecified chains
#
#
# bad_tcp_packets chain
#
$IPTABLES -A bad_tcp_packets -p tcp --tcp-flags SYN,ACK SYN,ACK \
-m state --state NEW -j REJECT --reject-with tcp-reset
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j LOG \
--log-prefix "New not syn:"
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j DROP
#
# allowed chain
#
$IPTABLES -A allowed -p TCP --syn -j ACCEPT
$IPTABLES -A allowed -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A allowed -p TCP -j DROP
#
# ICMP rules
#
# Changed rules totally
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 8 -j ACCEPT
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 11 -j ACCEPT
#
# 4.1.4 INPUT chain
#
#
# Bad TCP packets we don't want
#
$IPTABLES -A INPUT -p tcp -j bad_tcp_packets
#
# Packets from the Internet to this box
#
$IPTABLES -A INPUT -p ICMP -i $INET_IFACE -j icmp_packets
#
# Packets from LAN, DMZ or LOCALHOST
#
#
# From DMZ Interface to DMZ firewall IP
#
$IPTABLES -A INPUT -p ALL -i $DMZ_IFACE -d $DMZ_IP -j ACCEPT
#
# From LAN Interface to LAN firewall IP
#
$IPTABLES -A INPUT -p ALL -i $LAN_IFACE -d $LAN_IP -j ACCEPT
#
# From Localhost interface to Localhost IP's
#
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LO_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LAN_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $INET_IP -j ACCEPT
#
# Special rule for DHCP requests from LAN, which are not caught properly
# otherwise.
#
$IPTABLES -A INPUT -p UDP -i $LAN_IFACE --dport 67 --sport 68 -j ACCEPT
#
# All established and related packets incoming from the internet to the
# firewall
#
$IPTABLES -A INPUT -p ALL -d $INET_IP -m state --state ESTABLISHED,RELATED \
-j ACCEPT
#
# In Microsoft Networks you will be swamped by broadcasts. These lines
# will prevent them from showing up in the logs.
#
#$IPTABLES -A INPUT -p UDP -i $INET_IFACE -d $INET_BROADCAST \
#--destination-port 135:139 -j DROP
#
# If we get DHCP requests from the Outside of our network, our logs will
# be swamped as well. This rule will block them from getting logged.
#
#$IPTABLES -A INPUT -p UDP -i $INET_IFACE -d 255.255.255.255 \
#--destination-port 67:68 -j DROP
#
# If you have a Microsoft Network on the outside of your firewall, you may
# also get flooded by Multicasts. We drop them so we do not get flooded by
# logs
#
#$IPTABLES -A INPUT -i $INET_IFACE -d 224.0.0.0/8 -j DROP
#
# Log weird packets that don't match the above.
#
$IPTABLES -A INPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT INPUT packet died: "
#
# 4.1.5 FORWARD chain
#
#
# Bad TCP packets we don't want
#
$IPTABLES -A FORWARD -p tcp -j bad_tcp_packets
#
# DMZ section
#
# General rules
#
$IPTABLES -A FORWARD -i $DMZ_IFACE -o $INET_IFACE -j ACCEPT
$IPTABLES -A FORWARD -i $INET_IFACE -o $DMZ_IFACE -m state \
--state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A FORWARD -i $LAN_IFACE -o $DMZ_IFACE -j ACCEPT
$IPTABLES -A FORWARD -i $DMZ_IFACE -o $LAN_IFACE -m state \
--state ESTABLISHED,RELATED -j ACCEPT
#
# HTTP server
#
$IPTABLES -A FORWARD -p TCP -i $INET_IFACE -o $DMZ_IFACE -d $DMZ_HTTP_IP \
--dport 80 -j allowed
$IPTABLES -A FORWARD -p ICMP -i $INET_IFACE -o $DMZ_IFACE -d $DMZ_HTTP_IP \
-j icmp_packets
#
# DNS server
#
$IPTABLES -A FORWARD -p TCP -i $INET_IFACE -o $DMZ_IFACE -d $DMZ_DNS_IP \
--dport 53 -j allowed
$IPTABLES -A FORWARD -p UDP -i $INET_IFACE -o $DMZ_IFACE -d $DMZ_DNS_IP \
--dport 53 -j ACCEPT
$IPTABLES -A FORWARD -p ICMP -i $INET_IFACE -o $DMZ_IFACE -d $DMZ_DNS_IP \
-j icmp_packets
#
# LAN section
#
$IPTABLES -A FORWARD -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A FORWARD -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT FORWARD packet died: "
#
# 4.1.6 OUTPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A OUTPUT -p tcp -j bad_tcp_packets
#
# Special OUTPUT rules to decide which IP's to allow.
#
$IPTABLES -A OUTPUT -p ALL -s $LO_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $LAN_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $INET_IP -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A OUTPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT OUTPUT packet died: "
######
# 4.2 nat table
#
#
# 4.2.1 Set policies
#
#
# 4.2.2 Create user specified chains
#
#
# 4.2.3 Create content in user specified chains
#
#
# 4.2.4 PREROUTING chain
#
$IPTABLES -t nat -A PREROUTING -p TCP -i $INET_IFACE -d $HTTP_IP --dport 80 \
-j DNAT --to-destination $DMZ_HTTP_IP
$IPTABLES -t nat -A PREROUTING -p TCP -i $INET_IFACE -d $DNS_IP --dport 53 \
-j DNAT --to-destination $DMZ_DNS_IP
$IPTABLES -t nat -A PREROUTING -p UDP -i $INET_IFACE -d $DNS_IP --dport 53 \
-j DNAT --to-destination $DMZ_DNS_IP
#
# 4.2.5 POSTROUTING chain
#
#
# Enable simple IP Forwarding and Network Address Translation
#
$IPTABLES -t nat -A POSTROUTING -o $INET_IFACE -j SNAT --to-source $INET_IP
#
# 4.2.6 OUTPUT chain
#
######
# 4.3 mangle table
#
#
# 4.3.1 Set policies
#
#
# 4.3.2 Create user specified chains
#
#
# 4.3.3 Create content in user specified chains
#
#
# 4.3.4 PREROUTING chain
#
#
# 4.3.5 INPUT chain
#
#
# 4.3.6 FORWARD chain
#
#
# 4.3.7 OUTPUT chain
#
#
# 4.3.8 POSTROUTING chain
#
J.3. Example rc.UTIN.firewall script
#!/bin/sh
#
# rc.UTIN.firewall - UTIN Firewall script for Linux 2.4.x and iptables
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
###########################################################################
#
# 1. Configuration options.
#
#
# 1.1 Internet Configuration.
#
INET_IP="194.236.50.155"
INET_IFACE="eth0"
INET_BROADCAST="194.236.50.255"
#
# 1.1.1 DHCP
#
#
# 1.1.2 PPPoE
#
#
# 1.2 Local Area Network configuration.
#
# your LAN's IP range and localhost IP. /24 means to only use the first 24
# bits of the 32 bit IP address. the same as netmask 255.255.255.0
#
LAN_IP="192.168.0.2"
LAN_IP_RANGE="192.168.0.0/16"
LAN_IFACE="eth1"
#
# 1.3 DMZ Configuration.
#
#
# 1.4 Localhost Configuration.
#
LO_IFACE="lo"
LO_IP="127.0.0.1"
#
# 1.5 IPTables Configuration.
#
IPTABLES="/usr/sbin/iptables"
#
# 1.6 Other Configuration.
#
###########################################################################
#
# 2. Module loading.
#
#
# Needed to initially load modules
#
/sbin/depmod -a
#
# 2.1 Required modules
#
/sbin/modprobe ip_tables
/sbin/modprobe ip_conntrack
/sbin/modprobe iptable_filter
/sbin/modprobe iptable_mangle
/sbin/modprobe iptable_nat
/sbin/modprobe ipt_LOG
/sbin/modprobe ipt_limit
/sbin/modprobe ipt_state
#
# 2.2 Non-Required modules
#
#/sbin/modprobe ipt_owner
#/sbin/modprobe ipt_REJECT
#/sbin/modprobe ipt_MASQUERADE
#/sbin/modprobe ip_conntrack_ftp
#/sbin/modprobe ip_conntrack_irc
#/sbin/modprobe ip_nat_ftp
#/sbin/modprobe ip_nat_irc
###########################################################################
#
# 3. /proc set up.
#
#
# 3.1 Required proc configuration
#
echo "1" > /proc/sys/net/ipv4/ip_forward
#
# 3.2 Non-Required proc configuration
#
#echo "1" > /proc/sys/net/ipv4/conf/all/rp_filter
#echo "1" > /proc/sys/net/ipv4/conf/all/proxy_arp
#echo "1" > /proc/sys/net/ipv4/ip_dynaddr
###########################################################################
#
# 4. rules set up.
#
######
# 4.1 Filter table
#
#
# 4.1.1 Set policies
#
$IPTABLES -P INPUT DROP
$IPTABLES -P OUTPUT DROP
$IPTABLES -P FORWARD DROP
#
# 4.1.2 Create userspecified chains
#
#
# Create chain for bad tcp packets
#
$IPTABLES -N bad_tcp_packets
#
# Create separate chains for ICMP, TCP and UDP to traverse
#
$IPTABLES -N allowed
$IPTABLES -N tcp_packets
$IPTABLES -N udp_packets
$IPTABLES -N icmp_packets
#
# 4.1.3 Create content in userspecified chains
#
#
# bad_tcp_packets chain
#
$IPTABLES -A bad_tcp_packets -p tcp --tcp-flags SYN,ACK SYN,ACK \
-m state --state NEW -j REJECT --reject-with tcp-reset
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j LOG \
--log-prefix "New not syn:"
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j DROP
#
# allowed chain
#
$IPTABLES -A allowed -p TCP --syn -j ACCEPT
$IPTABLES -A allowed -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A allowed -p TCP -j DROP
#
# TCP rules
#
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 21 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 22 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 80 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 113 -j allowed
#
# UDP ports
#
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 53 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 123 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 2074 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 4000 -j ACCEPT
#
# In Microsoft Networks you will be swamped by broadcasts. These lines
# will prevent them from showing up in the logs.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE -d $INET_BROADCAST \
#--destination-port 135:139 -j DROP
#
# If we get DHCP requests from the Outside of our network, our logs will
# be swamped as well. This rule will block them from getting logged.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE -d 255.255.255.255 \
#--destination-port 67:68 -j DROP
#
# ICMP rules
#
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 8 -j ACCEPT
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 11 -j ACCEPT
#
# 4.1.4 INPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A INPUT -p tcp -j bad_tcp_packets
#
# Rules for special networks not part of the Internet
#
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LO_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $LAN_IP -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -s $INET_IP -j ACCEPT
#
# Rules for incoming packets from anywhere.
#
$IPTABLES -A INPUT -p ALL -d $INET_IP -m state --state ESTABLISHED,RELATED \
-j ACCEPT
$IPTABLES -A INPUT -p TCP -j tcp_packets
$IPTABLES -A INPUT -p UDP -j udp_packets
$IPTABLES -A INPUT -p ICMP -j icmp_packets
#
# If you have a Microsoft Network on the outside of your firewall, you may
# also get flooded by Multicasts. We drop them so we do not get flooded by
# logs
#
#$IPTABLES -A INPUT -i $INET_IFACE -d 224.0.0.0/8 -j DROP
#
# Log weird packets that don't match the above.
#
$IPTABLES -A INPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT INPUT packet died: "
#
# 4.1.5 FORWARD chain
#
#
# Bad TCP packets we don't want
#
$IPTABLES -A FORWARD -p tcp -j bad_tcp_packets
#
# Accept the packets we actually want to forward
#
$IPTABLES -A FORWARD -p tcp --dport 21 -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -p tcp --dport 80 -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -p tcp --dport 110 -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A FORWARD -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT FORWARD packet died: "
#
# 4.1.6 OUTPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A OUTPUT -p tcp -j bad_tcp_packets
#
# Special OUTPUT rules to decide which IP's to allow.
#
$IPTABLES -A OUTPUT -p ALL -s $LO_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $LAN_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $INET_IP -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A OUTPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT OUTPUT packet died: "
######
# 4.2 nat table
#
#
# 4.2.1 Set policies
#
#
# 4.2.2 Create user specified chains
#
#
# 4.2.3 Create content in user specified chains
#
#
# 4.2.4 PREROUTING chain
#
#
# 4.2.5 POSTROUTING chain
#
#
# Enable simple IP Forwarding and Network Address Translation
#
$IPTABLES -t nat -A POSTROUTING -o $INET_IFACE -j SNAT --to-source $INET_IP
#
# 4.2.6 OUTPUT chain
#
######
# 4.3 mangle table
#
#
# 4.3.1 Set policies
#
#
# 4.3.2 Create user specified chains
#
#
# 4.3.3 Create content in user specified chains
#
#
# 4.3.4 PREROUTING chain
#
#
# 4.3.5 INPUT chain
#
#
# 4.3.6 FORWARD chain
#
#
# 4.3.7 OUTPUT chain
#
#
# 4.3.8 POSTROUTING chain
#
J.4. Example rc.DHCP.firewall script
#!/bin/sh
#
# rc.DHCP.firewall - DHCP IP Firewall script for Linux 2.4.x and iptables
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
###########################################################################
#
# 1. Configuration options.
#
#
# 1.1 Internet Configuration.
#
INET_IFACE="eth0"
#
# 1.1.1 DHCP
#
#
# Information pertaining to DHCP over the Internet, if needed.
#
# Set DHCP variable to no if you don't get IP from DHCP. If you get DHCP
# over the Internet set this variable to yes, and set up the proper IP
# address for the DHCP server in the DHCP_SERVER variable.
#
DHCP="no"
DHCP_SERVER="195.22.90.65"
#
# 1.1.2 PPPoE
#
# Configuration options pertaining to PPPoE.
#
# If you have problem with your PPPoE connection, such as large mails not
# getting through while small mail get through properly etc, you may set
# this option to "yes" which may fix the problem. This option will set a
# rule in the PREROUTING chain of the mangle table which will clamp
# (resize) all routed packets to PMTU (Path Maximum Transmit Unit).
#
# Note that it is better to set this up in the PPPoE package itself, since
# the PPPoE configuration option will give less overhead.
#
PPPOE_PMTU="no"
#
# 1.2 Local Area Network configuration.
#
# your LAN's IP range and localhost IP. /24 means to only use the first 24
# bits of the 32 bit IP address. the same as netmask 255.255.255.0
#
LAN_IP="192.168.0.2"
LAN_IP_RANGE="192.168.0.0/16"
LAN_IFACE="eth1"
#
# 1.3 DMZ Configuration.
#
#
# 1.4 Localhost Configuration.
#
LO_IFACE="lo"
LO_IP="127.0.0.1"
#
# 1.5 IPTables Configuration.
#
IPTABLES="/usr/sbin/iptables"
#
# 1.6 Other Configuration.
#
###########################################################################
#
# 2. Module loading.
#
#
# Needed to initially load modules
#
/sbin/depmod -a
#
# 2.1 Required modules
#
/sbin/modprobe ip_conntrack
/sbin/modprobe ip_tables
/sbin/modprobe iptable_filter
/sbin/modprobe iptable_mangle
/sbin/modprobe iptable_nat
/sbin/modprobe ipt_LOG
/sbin/modprobe ipt_limit
/sbin/modprobe ipt_MASQUERADE
#
# 2.2 Non-Required modules
#
#/sbin/modprobe ipt_owner
#/sbin/modprobe ipt_REJECT
#/sbin/modprobe ip_conntrack_ftp
#/sbin/modprobe ip_conntrack_irc
#/sbin/modprobe ip_nat_ftp
#/sbin/modprobe ip_nat_irc
###########################################################################
#
# 3. /proc set up.
#
#
# 3.1 Required proc configuration
#
echo "1" > /proc/sys/net/ipv4/ip_forward
#
# 3.2 Non-Required proc configuration
#
#echo "1" > /proc/sys/net/ipv4/conf/all/rp_filter
#echo "1" > /proc/sys/net/ipv4/conf/all/proxy_arp
#echo "1" > /proc/sys/net/ipv4/ip_dynaddr
###########################################################################
#
# 4. rules set up.
#
######
# 4.1 Filter table
#
#
# 4.1.1 Set policies
#
$IPTABLES -P INPUT DROP
$IPTABLES -P OUTPUT DROP
$IPTABLES -P FORWARD DROP
#
# 4.1.2 Create userspecified chains
#
#
# Create chain for bad tcp packets
#
$IPTABLES -N bad_tcp_packets
#
# Create separate chains for ICMP, TCP and UDP to traverse
#
$IPTABLES -N allowed
$IPTABLES -N tcp_packets
$IPTABLES -N udp_packets
$IPTABLES -N icmp_packets
#
# 4.1.3 Create content in userspecified chains
#
#
# bad_tcp_packets chain
#
$IPTABLES -A bad_tcp_packets -p tcp --tcp-flags SYN,ACK SYN,ACK \
-m state --state NEW -j REJECT --reject-with tcp-reset
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j LOG \
--log-prefix "New not syn:"
$IPTABLES -A bad_tcp_packets -p tcp ! --syn -m state --state NEW -j DROP
#
# allowed chain
#
$IPTABLES -A allowed -p TCP --syn -j ACCEPT
$IPTABLES -A allowed -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A allowed -p TCP -j DROP
#
# TCP rules
#
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 21 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 22 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 80 -j allowed
$IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 113 -j allowed
#
# UDP ports
#
$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 53 -j ACCEPT
if [ $DHCP == "yes" ] ; then
$IPTABLES -A udp_packets -p UDP -s $DHCP_SERVER --sport 67 \
--dport 68 -j ACCEPT
fi
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 53 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 123 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 2074 -j ACCEPT
#$IPTABLES -A udp_packets -p UDP -s 0/0 --source-port 4000 -j ACCEPT
#
# In Microsoft Networks you will be swamped by broadcasts. These lines
# will prevent them from showing up in the logs.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE \
#--destination-port 135:139 -j DROP
#
# If we get DHCP requests from the Outside of our network, our logs will
# be swamped as well. This rule will block them from getting logged.
#
#$IPTABLES -A udp_packets -p UDP -i $INET_IFACE -d 255.255.255.255 \
#--destination-port 67:68 -j DROP
#
# ICMP rules
#
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 8 -j ACCEPT
$IPTABLES -A icmp_packets -p ICMP -s 0/0 --icmp-type 11 -j ACCEPT
#
# 4.1.4 INPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A INPUT -p tcp -j bad_tcp_packets
#
# Rules for special networks not part of the Internet
#
$IPTABLES -A INPUT -p ALL -i $LAN_IFACE -s $LAN_IP_RANGE -j ACCEPT
$IPTABLES -A INPUT -p ALL -i $LO_IFACE -j ACCEPT
#
# Special rule for DHCP requests from LAN, which are not caught properly
# otherwise.
#
$IPTABLES -A INPUT -p UDP -i $LAN_IFACE --dport 67 --sport 68 -j ACCEPT
#
# Rules for incoming packets from the internet.
#
$IPTABLES -A INPUT -p ALL -i $INET_IFACE -m state --state ESTABLISHED,RELATED \
-j ACCEPT
$IPTABLES -A INPUT -p TCP -i $INET_IFACE -j tcp_packets
$IPTABLES -A INPUT -p UDP -i $INET_IFACE -j udp_packets
$IPTABLES -A INPUT -p ICMP -i $INET_IFACE -j icmp_packets
#
# If you have a Microsoft Network on the outside of your firewall, you may
# also get flooded by Multicasts. We drop them so we do not get flooded by
# logs
#
#$IPTABLES -A INPUT -i $INET_IFACE -d 224.0.0.0/8 -j DROP
#
# Log weird packets that don't match the above.
#
$IPTABLES -A INPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT INPUT packet died: "
#
# 4.1.5 FORWARD chain
#
#
# Bad TCP packets we don't want
#
$IPTABLES -A FORWARD -p tcp -j bad_tcp_packets
#
# Accept the packets we actually want to forward
#
$IPTABLES -A FORWARD -i $LAN_IFACE -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A FORWARD -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT FORWARD packet died: "
#
# 4.1.6 OUTPUT chain
#
#
# Bad TCP packets we don't want.
#
$IPTABLES -A OUTPUT -p tcp -j bad_tcp_packets
#
# Special OUTPUT rules to decide which IP's to allow.
#
$IPTABLES -A OUTPUT -p ALL -s $LO_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -s $LAN_IP -j ACCEPT
$IPTABLES -A OUTPUT -p ALL -o $INET_IFACE -j ACCEPT
#
# Log weird packets that don't match the above.
#
$IPTABLES -A OUTPUT -m limit --limit 3/minute --limit-burst 3 -j LOG \
--log-level DEBUG --log-prefix "IPT OUTPUT packet died: "
######
# 4.2 nat table
#
#
# 4.2.1 Set policies
#
#
# 4.2.2 Create user specified chains
#
#
# 4.2.3 Create content in user specified chains
#
#
# 4.2.4 PREROUTING chain
#
#
# 4.2.5 POSTROUTING chain
#
if [ $PPPOE_PMTU == "yes" ] ; then
$IPTABLES -t nat -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN \
-j TCPMSS --clamp-mss-to-pmtu
fi
$IPTABLES -t nat -A POSTROUTING -o $INET_IFACE -j MASQUERADE
#
# 4.2.6 OUTPUT chain
#
######
# 4.3 mangle table
#
#
# 4.3.1 Set policies
#
#
# 4.3.2 Create user specified chains
#
#
# 4.3.3 Create content in user specified chains
#
#
# 4.3.4 PREROUTING chain
#
#
# 4.3.5 INPUT chain
#
#
# 4.3.6 FORWARD chain
#
#
# 4.3.7 OUTPUT chain
#
#
# 4.3.8 POSTROUTING chain
#
J.5. Example rc.flush-iptables script
#!/bin/sh
#
# rc.flush-iptables - Resets iptables to default values.
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
# Configurations
#
IPTABLES="/usr/sbin/iptables"
#
# reset the default policies in the filter table.
#
$IPTABLES -P INPUT ACCEPT
$IPTABLES -P FORWARD ACCEPT
$IPTABLES -P OUTPUT ACCEPT
#
# reset the default policies in the nat table.
#
$IPTABLES -t nat -P PREROUTING ACCEPT
$IPTABLES -t nat -P POSTROUTING ACCEPT
$IPTABLES -t nat -P OUTPUT ACCEPT
#
# reset the default policies in the mangle table.
#
$IPTABLES -t mangle -P PREROUTING ACCEPT
$IPTABLES -t mangle -P POSTROUTING ACCEPT
$IPTABLES -t mangle -P INPUT ACCEPT
$IPTABLES -t mangle -P OUTPUT ACCEPT
$IPTABLES -t mangle -P FORWARD ACCEPT
#
# flush all the rules in the filter and nat tables.
#
$IPTABLES -F
$IPTABLES -t nat -F
$IPTABLES -t mangle -F
#
# erase all chains that's not default in filter and nat table.
#
$IPTABLES -X
$IPTABLES -t nat -X
$IPTABLES -t mangle -X
J.6. Example rc.test-iptables script
#!/bin/bash
#
# rc.test-iptables - test script for iptables chains and tables.
#
# Copyright (C) 2001 Oskar Andreasson <bluefluxATkoffeinDOTnet>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; version 2 of the License.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program or from the site that you downloaded it
# from; if not, write to the Free Software Foundation, Inc., 59 Temple
# Place, Suite 330, Boston, MA 02111-1307 USA
#
#
# Filter table, all chains
#
iptables -t filter -A INPUT -p icmp --icmp-type echo-request \
-j LOG --log-prefix="filter INPUT:"
iptables -t filter -A INPUT -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="filter INPUT:"
iptables -t filter -A OUTPUT -p icmp --icmp-type echo-request \
-j LOG --log-prefix="filter OUTPUT:"
iptables -t filter -A OUTPUT -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="filter OUTPUT:"
iptables -t filter -A FORWARD -p icmp --icmp-type echo-request \
-j LOG --log-prefix="filter FORWARD:"
iptables -t filter -A FORWARD -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="filter FORWARD:"
#
# NAT table, all chains except OUTPUT which don't work.
#
iptables -t nat -A PREROUTING -p icmp --icmp-type echo-request \
-j LOG --log-prefix="nat PREROUTING:"
iptables -t nat -A PREROUTING -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="nat PREROUTING:"
iptables -t nat -A POSTROUTING -p icmp --icmp-type echo-request \
-j LOG --log-prefix="nat POSTROUTING:"
iptables -t nat -A POSTROUTING -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="nat POSTROUTING:"
iptables -t nat -A OUTPUT -p icmp --icmp-type echo-request \
-j LOG --log-prefix="nat OUTPUT:"
iptables -t nat -A OUTPUT -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="nat OUTPUT:"
#
# Mangle table, all chains
#
iptables -t mangle -A PREROUTING -p icmp --icmp-type echo-request \
-j LOG --log-prefix="mangle PREROUTING:"
iptables -t mangle -A PREROUTING -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="mangle PREROUTING:"
iptables -t mangle -I FORWARD 1 -p icmp --icmp-type echo-request \
-j LOG --log-prefix="mangle FORWARD:"
iptables -t mangle -I FORWARD 1 -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="mangle FORWARD:"
iptables -t mangle -I INPUT 1 -p icmp --icmp-type echo-request \
-j LOG --log-prefix="mangle INPUT:"
iptables -t mangle -I INPUT 1 -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="mangle INPUT:"
iptables -t mangle -A OUTPUT -p icmp --icmp-type echo-request \
-j LOG --log-prefix="mangle OUTPUT:"
iptables -t mangle -A OUTPUT -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="mangle OUTPUT:"
iptables -t mangle -I POSTROUTING 1 -p icmp --icmp-type echo-request \
-j LOG --log-prefix="mangle POSTROUTING:"
iptables -t mangle -I POSTROUTING 1 -p icmp --icmp-type echo-reply \
-j LOG --log-prefix="mangle POSTROUTING:"
Index
Symbols
- $INET_IP, 設定オプション
- $LAN_IFACE, FORWARDチェーン
- $LAN_IP, OUTPUTチェーン
- $LOCALHOST_IP, OUTPUTチェーン
- $STATIC_IP, OUTPUTチェーン
- --ahspi, AH/ESPマッチ
- --chunk-types, SCTPマッチ
- --clamp-mss-to-pmtu, TCPMSSターゲット
- --clustermac, CLUSTERIPターゲット
- --cmd-owner, Ownerマッチ
- --comment, Commentマッチ
- --ctexpire, Conntrackマッチ
- --ctorigdst, Conntrackマッチ
- --ctorigsrc, Conntrackマッチ
- --ctproto, Conntrackマッチ
- --ctrepldst, Conntrackマッチ
- --ctreplsrc, Conntrackマッチ
- --ctstate, Conntrackマッチ
- --ctstatus, Conntrackマッチ
- --destination, 汎用的なマッチ
- --destination-port, TCPマッチ, UDPマッチ, SCTPマッチ, Multiportマッチ
- --dscp, DSCPマッチ
- --dscp-class, DSCPマッチ
- --dst-range, IP rangeマッチ
- --dst-type, Addrtypeマッチ
- --ecn, ECNマッチ
- --ecn-ip-ect, ECNマッチ
- --ecn-tcp-ece, ECNマッチ
- --ecn-tcp-remove, ECNターゲット
- --espspi, AH/ESPマッチ
- --fragment, 汎用的なマッチ
- --gid-owner, Ownerマッチ
- --hash-init, CLUSTERIPターゲット
- --hashlimit, Hashlimitマッチ
- --hashlimit-burst, Hashlimitマッチ
- --hashlimit-htable-expire, Hashlimitマッチ
- --hashlimit-htable-expireマッチ, Hashlimitマッチ
- --hashlimit-htable-gcinterval, Hashlimitマッチ
- --hashlimit-htable-max, Hashlimitマッチ
- --hashlimit-htable-size, Hashlimitマッチ
- --hashlimit-mode, Hashlimitマッチ
- --hashlimit-name, Hashlimitマッチ
- --hashmode, CLUSTERIPターゲット
- --helper, Helperマッチ
- --hitcount, Recentマッチ
- --icmp-type, ICMPマッチ
- --in-interface, 汎用的なマッチ
- --length, Lengthマッチ
- --limit, Limitマッチ
- --limit-burst, Limitマッチ
- --local-node, CLUSTERIPターゲット
- --log-ip-options, LOGターゲット
- --log-level, LOGターゲット
- --log-prefix, LOGターゲット
- --log-tcp-options, LOGターゲット
- --log-tcp-sequence, LOGターゲット
- --mac-source, MACマッチ
- --mark, Connmarkマッチ, Markマッチ
- --mask, CONNMARKターゲット
- --match, 暗黙的なマッチ
- --mss, TCPMSSマッチ
- --name, Recentマッチ
- --new, CLUSTERIPターゲット
- --nodst, SAMEターゲット
- --out-interface, 汎用的なマッチ
- --pid-owner, Ownerマッチ
- --pkt-type, Packet type マッチ
- --pkt-typeマッチ, Packet type マッチ
- --port, Multiportマッチ
- --protocol, 汎用的なマッチ
- --queue-num, NFQUEUEターゲット
- --rcheck, Recentマッチ
- --rdest, Recentマッチ
- --realm, Realmマッチ
- --reject-with, REJECTターゲット
- --remove, Recentマッチ
- --restore, CONNSECMARKターゲット
- --restore-mark, CONNMARKターゲット
- --rsource, Recentマッチ
- --rttl, Recentマッチ
- --save, CONNSECMARKターゲット
- --save-mark, CONNMARKターゲット
- --seconds, Recentマッチ
- --selctx, SECMARKターゲット
- --set, Recentマッチ
- --set-class, CLASSIFYターゲット
- --set-dscp, DSCPターゲット
- --set-dscp-class, DSCPターゲット
- --set-mark, CONNMARKターゲット, MARKターゲット
- --set-mss, TCPMSSターゲット
- --set-tos, TOSターゲット
- --sid-owner, Ownerマッチ
- --source, 汎用的なマッチ
- --source-port, TCPマッチ, UDPマッチ, SCTPマッチ, Multiportマッチ
- --src-range, IP rangeマッチ
- --src-type, Addrtypeマッチ
- --state, Stateマッチ
- --syn, TCPマッチ
- --tcp-flags, TCPマッチ
- --tcp-option, TCPマッチ
- --to, NETMAPターゲット, SAMEターゲット
- --to-destination, DNATターゲット
- --to-destinationターゲット, DNATターゲット
- --to-ports, MASQUERADEターゲット, REDIRECTターゲット
- --to-source, SNATターゲット
- --tos, TOSマッチ
- --total-nodes, CLUSTERIPターゲット
- --ttl-dec, TTLターゲット
- --ttl-eq, TTLマッチ
- --ttl-gt, TTLマッチ
- --ttl-inc, TTLターゲット
- --ttl-lt, TTLマッチ
- --ttl-set, TTLターゲット
- --uid-owner, Ownerマッチ
- --ulog-cprange, ULOGターゲット
- --ulog-nlgroup, ULOGターゲット
- --ulog-prefix, ULOGターゲット
- --ulog-qthreshold, ULOGターゲット
- --update, Recentマッチ
- [ASSURED], TCPコネクション
- [UNREPLIED], TCPコネクション
- その他の資料, その他の資料とリンク
- よくある問題, よくある問題と質問
- DHCP, iptablesにDHCPリクエストを通させる
- IRC DCC, mIRC DCCのトラブル
- NEW not SYN, NEWステートでありながらSYNビットの立っていないパケット
- アップデートとフラッシュ, テーブルのアップデートとフラッシュ
- プライベートIPを使用するISP, 予約済みIPアドレスを使用するインターネットサービスプロバイダ
- モジュール, モジュールロードのトラブル
- ルールセットのリストアップ, 稼働中のルールセットのリストアップ
- アプリケーション層, TCP/IPのレイヤー
- インターネットヘッダ長, ICMPヘッダ
- インターネット層, TCP/IPのレイヤー, IPの特徴
- インターフェイス, 設定オプション
- インフォメーション要求, インフォメーション要求/応答
- ウィンドウ, TCPヘッダ
- エコー要求/応答, ICMPエコー要求/応答
- エラー
- Table does not exist, iptablesのデバグ
- オプション, IPヘッダ, TCPヘッダ, カーネルのセットアップ
- カーネルのセットアップ, カーネルのセットアップ
- カーネル空間, このドキュメントで使う用語
- グラフィカルユーザインターフェイス, iptables/netfilter用グラフィカルユーザインターフェイス
- Easy Firewall Generator, Easy Firewall Generator
- fwbuilder, fwbuilder
- Integrated Secure Communications System, Integrated Secure Communications System
- IPmenu, IPMenu
- Turtle Firewall プロジェクト, Turtle Firewall プロジェクト
- コード, ICMPヘッダ
- コネクション, このドキュメントで使う用語
- コネクション指向, IPの特徴
- コネクション追跡, IPフィルタリングの用語と表現
- コマンド, コマンド
- サービスタイプ, ICMPヘッダ
- シーケンスナンバー, ICMPエコー要求/応答
- システムツール, スクリプトのデバグ
- ジャンプ, IPフィルタリングの用語と表現
- スクリプトの構造, 構造
- スクリプト例, スクリプトのデバグ, スクリプト例コードベース
- Configuration, 構造
- DHCP, 構造
- DMZ, 構造
- Filter table, 構造
- Internet, 構造
- iptables, 構造
- Iptables-save ruleset, Iptables-save ruleset
- iptsave-ruleset.txt, iptables-save
- LAN, 構造
- Limit-match.txt, Limit-match.txt
- Localhost, 構造
- Module loading, 構造
- NAT, 概念を理解するためのNATマシン構築例
- Non-required modules, 構造
- Non-required proc configuration, 構造
- Other, 構造
- Pid-owner.txt, Pid-owner.txt
- PPPoE, 構造
- proc configuration, 構造
- rc.DHCP.firewall.txt, rc.DHCP.firewall.txt, Example rc.DHCP.firewall script
- rc.DMZ.firewall.txt, rc.DMZ.firewall.txt, Example rc.DMZ.firewall script
- rc.firewall.txt, rc.firewallファイル, rc.firewall.txtスクリプトの構造, rc.firewall.txt, Example rc.firewall script
- rc.flush-iptables.txt, rc.flush-iptables.txt, Example rc.flush-iptables script
- rc.test-iptables.txt, rc.test-iptables.txt, Example rc.test-iptables script
- rc.UTIN.firewall.txt, rc.UTIN.firewall.txt, Example rc.UTIN.firewall script
- Recent-match.txt, Recent-match.txt
- Required modules, 構造
- Required proc configuration, 構造
- Rules set up, 構造
- Set policies, 構造
- Sid-owner.txt, Sid-owner.txt
- TTL-inc.txt, Ttl-inc.txt
- User specified chains, 構造
- User specified chains content, 構造
- 構造, 例 rc.firewall, 構造, 例 rc.firewall
- see also スクリプト例の構造
- スクリプト例の構造
- 設定, 設定オプション
- ステート機構, ステート機構
- デフォルトのコネクション, デフォルトのコネクション
- ストリーム, このドキュメントで使う用語
- スプーフィング, SYN/ACKでNEWなパケット
- セグメント, このドキュメントで使う用語
- セッション層, TCP/IPのレイヤー
- ソースクエンチ, ソースクエンチ (Source Quench)
- ターゲット, IPフィルタリングの用語と表現, iptablesのターゲットとジャンプ
- ACCEPT, ACCEPTターゲット
- CLASSIFY, CLASSIFYターゲット
- see also CLASSIFYターゲット
- CLUSTERIP, CLUSTERIPターゲット
- see also CLUSTERIPターゲット
- CONNMARK, CONNMARKターゲット
- see also CONNMARKターゲット
- CONNSECMARK, CONNSECMARKターゲット
- see also CONNSECMARKターゲット
- DNAT, DNATターゲット
- see also DNATターゲット
- DROP, DROPターゲット
- see also DROPターゲット
- DSCP, DSCPターゲット
- see also DSCPターゲット
- ECN, ECNターゲット
- see also ECNターゲット
- LOG, LOGターゲット
- see also LOGターゲット
- MARK, MARKターゲット
- see also MARKターゲット
- MASQUERADE, MASQUERADEターゲット
- see also MASQUERADEターゲット
- MIRROR, MIRRORターゲット
- see also MIRRORターゲット
- NETMAP, NETMAPターゲット
- see also NETMAPターゲット
- NFQUEUE, NFQUEUEターゲット
- see also NFQUEUEターゲット
- NOTRACK, NOTRACKターゲット
- see also NOTRACKターゲット
- QUEUE, QUEUEターゲット
- see also QUEUEターゲット
- REDIRECT, REDIRECTターゲット
- see also REDIRECTターゲット
- REJECT, REJECTターゲット
- see also REJECTターゲット
- RETURN, RETURNターゲット
- see also RETURNターゲット
- SAME, SAMEターゲット
- see also SAMEターゲット
- SECMARK, SECMARKターゲット
- see also SECMARKターゲット
- SNAT, SNATターゲット
- see also SNATターゲット
- TCPMSS, TCPMSSターゲット
- see also TCPMSSターゲット
- TOS, TOSターゲット
- see also TOSターゲット
- TTL, TTLターゲット
- see also TTLターゲット
- ULOG, ULOGターゲット
- see also ULOGターゲット
- 基礎, iptablesのコマンドの基本
- タイプ, ICMPヘッダ
- タイムスタンプ, リダイレクト (Redirect)
- チェーン, IPフィルタリングの用語と表現
- FORWARD, 全般, 各種チェーンへのルール配置, FORWARDチェーン, natテーブルのPREROUTINGチェーン, 構造
- INPUT, 全般, 各種チェーンへのルール配置, ICMPチェーン, INPUTチェーン, 構造, 構造
- OUTPUT, 全般, Rawテーブル, 各種チェーンへのルール配置, OUTPUTチェーン, 構造, 構造, 構造
- POSTROUTING, 全般, SNATの開始とPOSTROUTINGチェーン, 構造, 構造
- PREROUTING, 全般, Rawテーブル, natテーブルのPREROUTINGチェーン, 構造, 構造
- ユーザ定義, ユーザ定義チェーン
- 道のり, テーブルとチェーンの道のり
- チェックサム, TCPヘッダ, UDPヘッダ, ICMPヘッダ
- チャンクタイプ(SCTP), SCTPマッチ
- チャンクフラグ(SCTP), SCTPマッチ
- テーブル, IPフィルタリングの用語と表現, テーブル
- Filter, 全般, filterテーブル
- Mangle, 全般, mangleテーブル, 構造
- Nat, 全般, natテーブル, 構造
- Raw, 全般, Rawテーブル
- 道のり, テーブルとチェーンの道のり
- テーブルとチェーンの道のり, テーブルとチェーンの道のり
- 全般, 全般
- データオフセット, TCPヘッダ
- データリンク層, TCP/IPのレイヤー
- デバグ, スクリプトのデバグ
- Bash, Bashデバグテクニック
- DHCP, iptablesにDHCPリクエストを通させる
- Iptables, iptablesのデバグ
- IRC DCC, mIRC DCCのトラブル
- Nessus, スクリプトのデバグ
- NEW not SYN, NEWステートでありながらSYNビットの立っていないパケット
- Nmap, スクリプトのデバグ
- SYN/ACKでNEWなパケット, SYN/ACKでNEWなパケット
- その他のツール, スクリプトのデバグ
- よくある問題, よくある問題と質問
- アップデートとフラッシュ, テーブルのアップデートとフラッシュ
- システムツール, デバグに役立つシステムツール
- プライベートIPを使用するISP, 予約済みIPアドレスを使用するインターネットサービスプロバイダ
- モジュール, モジュールロードのトラブル
- ルールセットのリストアップ, 稼働中のルールセットのリストアップ
- トランスポート層, TCP/IPのレイヤー
- ネゴシエートされたポート, IPフィルタの計画の仕方
- ネットワークアクセス層, TCP/IPのレイヤー
- ネットワーク侵入検出システム
- ネットワーク, IPフィルタの計画の仕方
- ネットワーク層, TCP/IPのレイヤー
- ハードウェア
- マシンの配備位置, NATマシンの配備位置
- 配備位置, プロキシの配置の仕方
- 必要条件, NATマシン構築に必要なもの
- ハードウェ和
- 構造, プロキシの配置の仕方
- ハンドシェイク, IPの特徴
- バージョン, ICMPヘッダ
- パケット, このドキュメントで使う用語
- パディング, IPヘッダ, TCPヘッダ
- パラメータ障害, パラメータ障害
- ファイル
- ip_conntrack, conntrackエントリ
- ip_conntrack_max, conntrackエントリ
- ip_conntrack_tcp_loose, TCPコネクション
- ip_ct_generic_timeout, 追跡除外コネクションとrawテーブル
- Ip_dynaddr, procの設定
- Ip_forward, procの設定
- フィルタリング, TCP/IPのレイヤー
- レイヤー7, IPフィルタとは何か
- 序章, IPフィルタリングとは
- フラグ, IPヘッダ
- フラグメント, IPヘッダ
- フラグメントオフセット, IPヘッダ
- プレゼンテーション層, TCP/IPのレイヤー
- プロキシ, TCP/IPのレイヤー, IPフィルタとは何か, IPフィルタの計画の仕方
- 配備位置, プロキシの配置の仕方
- プロトコル, IPヘッダ, ICMPヘッダ
- ヘッダチェックサム, IPヘッダ, ICMPヘッダ
- ポート
- ネゴシエーション, IPフィルタの計画の仕方
- ポリシー, IPフィルタリングの用語と表現, IPフィルタの計画の仕方, デフォルトポリシーの設定, FORWARDチェーン
- マッチ, IPフィルタリングの用語と表現, iptablesのマッチ
- --destination, 汎用的なマッチ
- --fragment, 汎用的なマッチ
- --in-interface, 汎用的なマッチ
- --match, 暗黙的なマッチ, 明示的なマッチ
- --out-interface, 汎用的なマッチ
- --protocol, 汎用的なマッチ
- --source, 汎用的なマッチ
- Addrtype, Addrtypeマッチ
- see also Addrtypeマッチ
- AH/ESP, AH/ESPマッチ
- see also AH/ESPマッチ
- Comment, Commentマッチ
- see also Commentマッチ
- Connmark, Connmarkマッチ
- see also Connmarkマッチ
- Conntrack, Conntrackマッチ
- see also Conntrackマッチ
- Dscp, DSCPマッチ
- see also Dscpマッチ
- Ecn, ECNマッチ
- see also Ecnマッチ
- Hashlimit, Hashlimitマッチ
- see also Hashlimitマッチ
- Helper, Helperマッチ
- see also Helperマッチ
- ICMP, ICMPマッチ
- see also ICMPマッチ
- IP range, IP rangeマッチ
- see also IP rangeマッチ
- Length, Lengthマッチ
- see also Lengthマッチ
- Limit, Limitマッチ
- see also Limitマッチ
- Mac, MACマッチ
- see also Macマッチ
- Mark, Markマッチ
- see also Markマッチ
- Multiport, Multiportマッチ
- see also Multiportマッチ
- Owner, Ownerマッチ
- see also Ownerマッチ
- Packet type, Packet type マッチ
- see also Packet typeマッチ
- Realm, Realmマッチ
- see also Realmマッチ
- Recent, Recentマッチ
- see also Recentマッチ
- SCTP, SCTPマッチ
- see also SCTPマッチ
- TCP, TCPマッチ
- see also TCPマッチ
- Tcpmss, TCPMSSマッチ
- see also Tcpmssマッチ
- Tos, TOSマッチ
- see also Tosマッチ
- Ttl, TTLマッチ
- see also Ttlマッチ
- UDP, UDPマッチ
- see also UDPマッチ
- Unclean, Uncleanマッチ
- see also Uncleanマッチ
- ステート, Stateマッチ
- see also Stateマッチ
- 暗黙的, 暗黙的なマッチ
- 基礎, iptablesのコマンドの基本
- 汎用的, 汎用的なマッチ
- 明示的, 明示的なマッチ
- see also 明示的なマッチ
- モジュール, 追加モジュールの初期ロード
- FTP, 追加モジュールの初期ロード
- H.323, 追加モジュールの初期ロード
- IRC, 追加モジュールの初期ロード
- Patch-o-matic, 追加モジュールの初期ロード
- ユーザインターフェイス, iptables/netfilter用グラフィカルユーザインターフェイス
- グラフィカル, iptables/netfilter用グラフィカルユーザインターフェイス
- see also グラフィカルユーザインターフェイス
- ユーザランド, このドキュメントで使う用語
- ユーザ空間, このドキュメントで使う用語
- ユーザ空間でのステート, ユーザ空間でのステート
- ユーザ空間のセットアップ, ユーザ空間のセットアップ
- ユーザ定義チェーン, ユーザ定義チェーン, filterテーブルにユーザ定義チェーンを作る
- リダイレクト, リダイレクト (Redirect)
- Redirect for host, リダイレクト (Redirect)
- Redirect for network, リダイレクト (Redirect)
- Redirect for TOS and host, リダイレクト (Redirect)
- Redirect for TOS and network, リダイレクト (Redirect)
- ルーティング, TCP/IP宛先誘導型ルーティング, MARKターゲット
- ANYCAST, Addrtypeマッチ
- BLACKHOLE, Addrtypeマッチ
- BROADCAST, Addrtypeマッチ
- LOCAL, Addrtypeマッチ
- MULTICAST, Addrtypeマッチ
- NAT, Addrtypeマッチ
- PROHIBIT, Addrtypeマッチ
- THROW, Addrtypeマッチ
- UNICAST, Addrtypeマッチ
- UNREACHABLE, Addrtypeマッチ
- UNSPEC, Addrtypeマッチ
- XRESOLVE, Addrtypeマッチ
- ルーティング・レルム, Realmマッチ
- ルール, IPフィルタリングの用語と表現, ルールの作り方
- 基礎, iptablesのコマンドの基本
- ルールの作り方, ルールの作り方
- ルールセット, IPフィルタリングの用語と表現
- ルールセットのリストア, 大きなルールセットの保存とリストア
- ルールセットの保存, 大きなルールセットの保存とリストア
- 宛先アドレス, IPヘッダ, ICMPヘッダ
- 宛先ポート, TCPヘッダ, UDPヘッダ
- 暗黙的なマッチ, 暗黙的なマッチ
- 確認応答ナンバー, TCPヘッダ
- 基礎, iptablesの入手先
- Filterテーブル, テーブル
- iptables-restore, 大きなルールセットの保存とリストア, iptables-restore
- iptables-save, 大きなルールセットの保存とリストア
- iptablesのコンパイル, ユーザ空間アプリケーションのコンパイル
- Mangleテーブル, テーブル
- Natテーブル, テーブル
- procの設定, procの設定
- Rawテーブル, テーブル
- Red Hat 7.1 でのインストール, Red Hat 7.1 でのインストール
- restoreの欠点, restoreの欠点
- テーブル, テーブル
- ポリシー, デフォルトポリシーの設定
- モジュール, 追加モジュールの初期ロード
- see also モジュール
- ユーザ空間のセットアップ, ユーザ空間のセットアップ
- ユーザ定義チェーン, filterテーブルにユーザ定義チェーンを作る
- 準備, 準備
- 速度に関する考察, 速度に関する考察
- 配置, 各種チェーンへのルール配置
- 緊急ポインタ, TCPヘッダ
- 計画
- IPフィルタ, IPフィルタの計画の仕方
- 語句, このドキュメントで使う用語
- 高度ルーティング, TCP/IP宛先誘導型ルーティング
- 識別子, IPヘッダ, ICMPヘッダ, ICMPエコー要求/応答
- 準備, 準備
- 入手先, iptablesの入手先
- 序章, 序章
- 詳細説明, 特別なコマンドの詳細解説
- アップデートとフラッシュ, テーブルのアップデートとフラッシュ
- ルールセットのリストアップ, 稼働中のルールセットのリストアップ
- 侵入検知システム
- ホストベース, IPフィルタの計画の仕方
- 全長, IPヘッダ, UDPヘッダ, ICMPヘッダ
- 送信元アドレス, IPヘッダ, ICMPヘッダ
- 送信元ポート, TCPヘッダ, UDPヘッダ
- 速度に関する考察, 速度に関する考察
- 多重セキュリティ戦略, IPフィルタの計画の仕方
- 低信頼性のプロトコル, IPの特徴
- 到達不能メッセージ, ICMP到達不能メッセージ (Destination Unreachable)
- Communicationadministratively prohibited by filtering, ICMP到達不能メッセージ (Destination Unreachable)
- Destination host administrativelyprohibited, ICMP到達不能メッセージ (Destination Unreachable)
- Destination hostunknown, ICMP到達不能メッセージ (Destination Unreachable)
- Destination network administrativelyprohibited, ICMP到達不能メッセージ (Destination Unreachable)
- Destination networkunknown, ICMP到達不能メッセージ (Destination Unreachable)
- Fragmentation needed and DFset, ICMP到達不能メッセージ (Destination Unreachable)
- Host precedenceviolation, ICMP到達不能メッセージ (Destination Unreachable)
- Host unreachable, ICMP到達不能メッセージ (Destination Unreachable)
- Host unreachable forTOS, ICMP到達不能メッセージ (Destination Unreachable)
- Network unreachable, ICMP到達不能メッセージ (Destination Unreachable)
- Network unreachable forTOS, ICMP到達不能メッセージ (Destination Unreachable)
- Port unreachable, ICMP到達不能メッセージ (Destination Unreachable)
- Precedence cutoff ineffect, ICMP到達不能メッセージ (Destination Unreachable)
- Protocol unreachable, ICMP到達不能メッセージ (Destination Unreachable)
- Source host isolated, ICMP到達不能メッセージ (Destination Unreachable)
- Source route failed, ICMP到達不能メッセージ (Destination Unreachable)
- 配置t, 各種チェーンへのルール配置
- 汎用的なマッチ, 汎用的なマッチ
- 非標準化技術, IPフィルタの計画の仕方
- 標準化, IPフィルタの計画の仕方
- 複雑なプロトコル
- Amanda, 複雑なプロトコルとコネクション追跡
- FTP, 複雑なプロトコルとコネクション追跡
- IRC, 複雑なプロトコルとコネクション追跡
- TFTP, 複雑なプロトコルとコネクション追跡
- 物理層, TCP/IPのレイヤー
- 明示的なマッチ, 明示的なマッチ
- 予約域, TCPヘッダ
- 用語, このドキュメントで使う用語
- NAT, NATの利用目的と用語解説
- 例
- ハードウェアの必要条件, NATマシン構築に必要なもの
- マシンの配備位置, NATマシンの配備位置
A
- Accept, IPフィルタリングの用語と表現
- ACCEPTターゲット, ACCEPTターゲット, 各種チェーンへのルール配置, UDPチェーン
- ACK, TCPヘッダ
- Addrtypeマッチ, Addrtypeマッチ
- --dst-type, Addrtypeマッチ
- --src-type, Addrtypeマッチ
- ANYCAST, Addrtypeマッチ
- BLACKHOLE, Addrtypeマッチ
- BROADCAST, Addrtypeマッチ
- LOCAL, Addrtypeマッチ
- MULTICAST, Addrtypeマッチ
- NAT, Addrtypeマッチ
- PROHIBIT, Addrtypeマッチ
- THROW, Addrtypeマッチ
- UNICAST, Addrtypeマッチ
- UNREACHABLE, Addrtypeマッチ
- UNSPEC, Addrtypeマッチ
- XRESOLVE, Addrtypeマッチ
- AH/ESPマッチ, AH/ESPマッチ
- --ahspi, AH/ESPマッチ
- Ahspiマッチ, AH/ESPマッチ
- Amanda, 複雑なプロトコルとコネクション追跡
- ANYCAST, Addrtypeマッチ
- ASSURED, conntrackエントリ, TCPコネクション
B
- Bad_tcp_packets, bad_tcp_packetsチェーン, INPUTチェーン
- Bash, Bashデバグテクニック
- +-sign, Bashデバグテクニック
- -x, Bashデバグテクニック
- Basics
- BLACKHOLE, Addrtypeマッチ
- BROADCAST, Addrtypeマッチ
C
- Chain
- FORWARD, 構造
- Chkconfig, Red Hat 7.1 でのインストール
- Chunk-typesマッチ, SCTPマッチ
- Cisco PIX, IPフィルタの計画の仕方
- Clamp-mss-to-pmtuターゲット, TCPMSSターゲット
- CLASSIFYターゲット, CLASSIFYターゲット
- --set-class, CLASSIFYターゲット
- CLUSTERIPターゲット, CLUSTERIPターゲット
- --clustermac, CLUSTERIPターゲット
- --hash-init, CLUSTERIPターゲット
- --hashmode, CLUSTERIPターゲット
- --local-node, CLUSTERIPターゲット
- --new, CLUSTERIPターゲット
- --total-nodes, CLUSTERIPターゲット
- Clustermacターゲット, CLUSTERIPターゲット
- Cmd-ownerマッチ, Ownerマッチ
- cmd.exe, IPフィルタとは何か
- Commentマッチ, Commentマッチ
- --comment, Commentマッチ
- Commercial products, Linux, iptables及びnetfilterをベースとした製品
- Ingate Firewall 1200, Ingate Firewall 1200
- Common problems
- SYN/ACKでNEWなパケット, SYN/ACKでNEWなパケット
- CONNMARKターゲット, CONNMARKターゲット
- --mask, CONNMARKターゲット
- --restore-mark, CONNMARKターゲット
- --save-mark, CONNMARKターゲット
- --set-mark, CONNMARKターゲット
- Connmarkマッチ, Connmarkマッチ
- --mark, Connmarkマッチ
- CONNSECMARK ターゲット, mangleテーブル
- CONNSECMARKターゲット, CONNSECMARKターゲット
- --restore, CONNSECMARKターゲット
- --save, CONNSECMARKターゲット
- Conntrack, ステート機構
- ip_conntrack, conntrackエントリ
- エントリ, conntrackエントリ
- ヘルパー, 複雑なプロトコルとコネクション追跡
- Conntrackマッチ, Conntrackマッチ
- --ctexpire, Conntrackマッチ
- --ctorigdst, Conntrackマッチ
- --ctorigsrc, Conntrackマッチ
- --ctproto, Conntrackマッチ
- --ctrepldst, Conntrackマッチ
- --ctreplsrc, Conntrackマッチ
- --ctstate, Conntrackマッチ
- --ctstatus, Conntrackマッチ
- console, Bashデバグテクニック
- cron, IPフィルタの計画の仕方, Bashデバグテクニック
- crontab, デバグに役立つシステムツール
- Ctexpireマッチ, Conntrackマッチ
- Ctorigdstマッチ, Conntrackマッチ
- Ctorigsrcマッチ, Conntrackマッチ
- Ctprotoマッチ, Conntrackマッチ
- Ctrepldstマッチ, Conntrackマッチ
- Ctreplsrcマッチ, Conntrackマッチ
- Ctstateマッチ, Conntrackマッチ
- Ctstatusマッチ, Conntrackマッチ
- CWR, TCPヘッダ
D
- De-Militarized Zone (DMZ), rc.DMZ.firewall.txt
- Debugging
- Echo, Bashデバグテクニック
- Deny, IPフィルタリングの用語と表現
- Destination-portマッチ, TCPマッチ, UDPマッチ, SCTPマッチ, Multiportマッチ
- Destinationマッチ, 汎用的なマッチ
- DHCP, MASQUERADEターゲット, 設定オプション, 各種チェーンへのルール配置
- Differentiated Services, IPヘッダ
- DiffServ, IPヘッダ
- Dmesg, LOGターゲット
- DMZ, IPフィルタの計画の仕方
- DNAT, このドキュメントで使う用語, IPフィルタとは何か, NATの利用目的と用語解説
- DNAT ターゲット, 全般, natテーブル
- DNATターゲット, DNATターゲット, natテーブルのPREROUTINGチェーン
- --to-destination, DNATターゲット
- DNATターゲットの例, DNATターゲット
- DNS, IPの特徴, UDPチェーン
- Drop, IPフィルタリングの用語と表現
- DROPターゲット, DROPターゲット, UDPチェーン, FORWARDチェーン, OUTPUTチェーン
- DSCP, IPヘッダ
- Dscp-classマッチ, DSCPマッチ
- DSCPターゲット, DSCPターゲット
- Dscpマッチ, DSCPマッチ
- Dst-rangeマッチ, IP rangeマッチ
- Dst-typeマッチ, Addrtypeマッチ
- Dynamic Host Configuration Protocol (DHCP), rc.DHCP.firewall.txt
E
- Easy Firewall Generator, Easy Firewall Generator
- ECE, TCPヘッダ
- Echo, Bashデバグテクニック
- ECN, IPヘッダ
- ECN IPフィールド, ECNマッチ
- Ecn-ip-ectマッチ, ECNマッチ
- Ecn-tcp-eceマッチ, ECNマッチ
- Ecn-tcp-removeターゲット, ECNターゲット
- ECNターゲット, ECNターゲット
- --ecn-tcp-remove, ECNターゲット
- Ecnマッチ, ECNマッチ
- Espspiマッチ, AH/ESPマッチ
- ESPマッチ
- --espspi, AH/ESPマッチ
- Explicit Congestion Notification, IPヘッダ
- eメール, IPフィルタの計画の仕方
F
- Fast-NAT, NATの利用目的と用語解説
- Filterテーブル, テーブル
- FIN, TCPの特徴, TCPヘッダ
- FIN/ACK, TCPの特徴
- Firewall Builder, fwbuilder
- Fragmentマッチ, 汎用的なマッチ
- FreeSWAN, AH/ESPマッチ
- FTP, 複雑なプロトコルとコネクション追跡
- fwbuilder, fwbuilder
H
- Hash-initターゲット, CLUSTERIPターゲット
- Hashlimit-burstマッチ, Hashlimitマッチ
- Hashlimit-htable-gcintervalマッチ, Hashlimitマッチ
- Hashlimit-htable-maxマッチ, Hashlimitマッチ
- Hashlimit-htable-sizeマッチ, Hashlimitマッチ
- Hashlimit-modeマッチ, Hashlimitマッチ
- Hashlimit-nameマッチ, Hashlimitマッチ
- Hashlimitマッチ, Hashlimitマッチ
- --hashlimit, Hashlimitマッチ
- --hashlimit-burst, Hashlimitマッチ
- --hashlimit-htable-expire, Hashlimitマッチ
- --hashlimit-htable-gcinterval, Hashlimitマッチ
- --hashlimit-htable-max, Hashlimitマッチ
- --hashlimit-htable-size, Hashlimitマッチ
- --hashlimit-mode, Hashlimitマッチ
- --hashlimit-name, Hashlimitマッチ
- Hashmodeターゲット, CLUSTERIPターゲット
- Helperマッチ, Helperマッチ
- --helper, Helperマッチ
- Hitcountマッチ, Recentマッチ
- Http, 各種チェーンへのルール配置
I
- ICMP, TCP/IPのおさらい, ICMPの特徴, ICMPコネクション, ICMPチェーン
- Time To Live, ICMPヘッダ
- TTL equals zero, TTL equals 0
- see also TTL equals zero
- Types, 稼働中のルールセットのリストアップ
- インターネットヘッダ長, ICMPヘッダ
- インフォメーション要求, インフォメーション要求/応答
- see also インフォメーション要求
- エコー要求/応答, ICMPエコー要求/応答
- see also エコー要求/応答
- コード, ICMPヘッダ
- サービスタイプ, ICMPヘッダ
- シーケンスナンバー, ICMPエコー要求/応答
- ソースクエンチ, ソースクエンチ (Source Quench)
- see also ソースクエンチ
- タイプ, ICMPヘッダ
- タイムスタンプ, タイムスタンプ要求/応答
- see also タイムスタンプ
- チェックサム, ICMPヘッダ
- バージョン, ICMPヘッダ
- パラメータ障害, パラメータ障害
- see also パラメータ障害
- プロトコル, ICMPヘッダ
- ヘッダ, ICMPヘッダ
- ヘッダチェックサム, ICMPヘッダ
- リダイレクト, リダイレクト (Redirect)
- see also リダイレクト
- 宛先アドレス, ICMPヘッダ
- 識別子, ICMPヘッダ, ICMPエコー要求/応答
- 全長, ICMPヘッダ
- 送信元アドレス, ICMPヘッダ
- 到達不能メッセージ, ICMP到達不能メッセージ (Destination Unreachable)
- see also 到達不能メッセージ
- 特徴, ICMPの特徴
- Icmp-typeマッチ, ICMPマッチ
- icmp_packets, ICMPチェーン
- ICMPマッチ, ICMPマッチ, ICMPチェーン
- --icmp-type, ICMPマッチ
- ICQ, IPフィルタの計画の仕方
- Identd, 各種チェーンへのルール配置
- IHL, IPヘッダ
- In-interfaceマッチ, 汎用的なマッチ
- Ingate, Ingate Firewall 1200
- Ingate Firewall 1200, Ingate Firewall 1200
- Integrated Secure Communications System, Integrated Secure Communications System
- IP, TCP/IPのおさらい
- IP rangeマッチ, IP rangeマッチ
- --dst-range, IP rangeマッチ
- --src-range, IP rangeマッチ
- Ipchains, Red Hat 7.1 でのインストール
- IPmenu, IPMenu
- IPSEC, このドキュメントで使う用語, AH/ESPマッチ
- Iptables
- 基礎, iptablesのコマンドの基本
- iptables-restore, 大きなルールセットの保存とリストア, iptables-restore
- 欠点, restoreの欠点
- 速度に関する考察, 速度に関する考察
- iptables-restoreの欠点, restoreの欠点
- iptables-save, 大きなルールセットの保存とリストア, iptables-save, スクリプトのデバグ
- 欠点, restoreの欠点
- 速度に関する考察, 速度に関する考察
- Iptables-save ruleset, Iptables-save ruleset
- Iptablesのターゲット, iptablesのターゲットとジャンプ
- see also ターゲット
- iptablesのデバグ, スクリプトのデバグ
- iptablesのフラッシュ, rc.flush-iptables.txt
- iptablesのマッチ, iptablesのマッチ
- see also マッチ
- ipt_*, iptablesのデバグ
- ipt_REJECT.ko, iptablesのデバグ
- ipt_state.ko, iptablesのデバグ
- Ip_conntrack, conntrackエントリ
- ip_conntrack_max, conntrackエントリ
- ip_conntrack_tcp_loose, TCPコネクション
- IPフィルタリング, IPフィルタリングとは
- 計画, IPフィルタの計画の仕方
- IRC, 複雑なプロトコルとコネクション追跡
L
- LAN, IPフィルタの計画の仕方, 設定オプション, FORWARDチェーン
- Lengthマッチ, Lengthマッチ
- --length, Lengthマッチ
- Limit-burstマッチ, Limitマッチ
- Limit-match.txt, Limit-match.txt
- Limitマッチ, Limitマッチ, Limit-match.txt
- LOCAL, Addrtypeマッチ
- Local-nodeターゲット, CLUSTERIPターゲット
- Log-ip-optionsターゲット, LOGターゲット
- Log-levelターゲット, LOGターゲット
- Log-prefixターゲット, LOGターゲット
- Log-tcp-optionsターゲット, LOGターゲット
- Log-tcp-sequenceターゲット, LOGターゲット
- LOGターゲット, LOGターゲット, UDPチェーン, FORWARDチェーン
M
- Mac-sourceマッチ, MACマッチ
- Macマッチ, MACマッチ
- --mac-source, MACマッチ
- Mangleテーブル, テーブル
- MARK ターゲット, mangleテーブル
- MARKターゲット, MARKターゲット
- --set-mark, MARKターゲット
- Markマッチ, Connmarkマッチ, Markマッチ
- --mark, Markマッチ
- Maskターゲット, CONNMARKターゲット
- MASQUERADE ターゲット, natテーブル
- MASQUERADEターゲット, MASQUERADEターゲット, SNATの開始とPOSTROUTINGチェーン
- --to-ports, MASQUERADEターゲット
- MIRRORターゲット, MIRRORターゲット
- Mssマッチ, TCPMSSマッチ
- MTU, SCTP共通ヘッダフォーマット
- MULTICAST, Addrtypeマッチ
- Multiportマッチ, Multiportマッチ
- --destination-port, Multiportマッチ
- --port, Multiportマッチ
- --source-port, Multiportマッチ
N
- Nameマッチ, Recentマッチ
- NAT, IPフィルタの計画の仕方, Addrtypeマッチ, MASQUERADEターゲット, SNATの開始とPOSTROUTINGチェーン
- ハードウェア, NATマシン構築に必要なもの
- 注意点, NAT使用時の注意点
- 配備位置, NATマシンの配備位置
- 例, 概念を理解するためのNATマシン構築例
- Natテーブル, テーブル
- Nessus, スクリプトのデバグ
- Netfilter-NAT, NATの利用目的と用語解説
- NETMAPターゲット, NETMAPターゲット
- --to, NETMAPターゲット
- Network address translation (NAT), テーブル
- Newターゲット, CLUSTERIPターゲット
- NFQUEUEターゲット, NFQUEUEターゲット
- --queue-num, NFQUEUEターゲット
- NIDS, IPフィルタの計画の仕方
- Nmap, スクリプトのデバグ
- Nmapfe, Nmap
- Nodstターゲット, SAMEターゲット
- NOTRACK ターゲット, Rawテーブル
- NOTRACKターゲット, 追跡除外コネクションとrawテーブル, NOTRACKターゲット
- NTP, UDPチェーン
O
- OSI
- アプリケーション層, TCP/IPのレイヤー
- セッション層, TCP/IPのレイヤー
- データリンク層, TCP/IPのレイヤー
- トランスポート層, TCP/IPのレイヤー
- ネットワーク層, TCP/IPのレイヤー
- プレゼンテーション層, TCP/IPのレイヤー
- 参照モデル, TCP/IPのレイヤー
- 物理層, TCP/IPのレイヤー
- Out-interfaceマッチ, 汎用的なマッチ
- Owner match
- Pidマッチ, Pid-owner.txt
- Sidマッチ, Sid-owner.txt
- Ownerマッチ, Ownerマッチ, Pid-owner.txt, Sid-owner.txt
P
- Packet typeマッチ, Packet type マッチ
- --pkt-type, Packet type マッチ
- Pid-owner.txt, Pid-owner.txt
- Pid-ownerマッチ, Ownerマッチ
- PNAT, NATの利用目的と用語解説
- Portマッチ, Multiportマッチ
- POSTROUTING, SNATターゲット, 各種チェーンへのルール配置
- PPP, 各種チェーンへのルール配置
- PPPoE, 設定オプション
- precautions, Bashデバグテクニック
- PREROUTING, DNATターゲット
- procの設定, procの設定
- PROHIBIT, Addrtypeマッチ
- Protocolマッチ, 汎用的なマッチ
- PSH, TCPヘッダ
- PUSH, TCPヘッダ
R
- Rawテーブル, テーブル
- rc.DHCP.firewall.txt, rc.DHCP.firewall.txt
- rc.DMZ.firewall.txt, rc.DMZ.firewall.txt
- rc.firewall.txt, rc.firewall.txtスクリプトの構造, rc.firewall.txt
- rc.firewallの解説, rc.firewallファイル
- rc.flush-iptables.txt, rc.flush-iptables.txt
- rc.test-iptables.txt, rc.test-iptables.txt
- rc.UTIN.firewall.txt, rc.UTIN.firewall.txt
- Rcheckマッチ, Recentマッチ
- Rdestマッチ, Recentマッチ
- Realmマッチ, Realmマッチ
- --realm, Realmマッチ
- Recent-match.txt, Recent-match.txt
- Recentマッチ, Recentマッチ, Recent-match.txt
- REDIRECTターゲット, REDIRECTターゲット
- --to-ports, REDIRECTターゲット
- Reject, IPフィルタリングの用語と表現
- Reject-withターゲット, REJECTターゲット
- REJECTターゲット, REJECTターゲット, bad_tcp_packetsチェーン
- --reject-with, REJECTターゲット
- Removeマッチ, Recentマッチ
- Restore-markターゲット, CONNMARKターゲット
- Restoreターゲット, CONNSECMARKターゲット
- RETURNターゲット, RETURNターゲット
- RFC, IPヘッダ
- 1122, TCPMSSマッチ
- 1349, IPヘッダ
- 1812, CLUSTERIPターゲット
- 2401, AH/ESPマッチ
- 2474, IPヘッダ, IPヘッダ, DSCPターゲット
- 2638, DSCPマッチ
- 2960, SCTPの特徴
- 3168, IPヘッダ, IPヘッダ, ECNマッチ
- 3260, IPヘッダ, IPヘッダ
- 3268, TCPヘッダ, TCPヘッダ
- 3286, SCTPの特徴
- 768, UDPの特徴
- 791, IPヘッダ, IPヘッダ
- 792, ICMPヘッダ, ICMPチェーン
- 793, このドキュメントで使う用語, TCPコネクション, TCPMSSマッチ, REJECTターゲット
- Rsourceマッチ, Recentマッチ
- RST, TCPヘッダ
- Rttlマッチ, Recentマッチ
S
- SACK, IPヘッダ
- SAMEターゲット, SAMEターゲット
- Save-markターゲット, CONNMARKターゲット
- Saveターゲット, CONNSECMARKターゲット
- SCTP, SCTPの特徴
- ABORT, シャットダウンと中止, SCTPの一般ヘッダと共通ヘッダ, SCTP ABORTチャンク
- Advertised Receiver Window Credit, SCTP INITチャンク
- B-bit, SCTP DATAチャンク
- Checksum, SCTPの一般ヘッダと共通ヘッダ
- Cookie, SCTP COOKIE ECHOチャンク
- COOKIE ACK, イニシャライズとアソシエーション, SCTP COOKIE ACKチャンク
- COOKIE ECHO, イニシャライズとアソシエーション, SCTP COOKIE ECHOチャンク
- DATA, データの送信とコントロールセッション, SCTP共通ヘッダフォーマット, SCTP DATAチャンク
- E-bit, SCTP DATAチャンク
- ECN, SCTPの特徴
- ERROR, データの送信とコントロールセッション, SCTP ERRORチャンク
- Cookie Received While Shutting Down, SCTP ERRORチャンク
- Invalid Mandatory Parameter, SCTP ERRORチャンク
- Invalid Stream Identifier, SCTP ERRORチャンク
- Missing Mandatory Parameter, SCTP ERRORチャンク
- No User Data, SCTP ERRORチャンク
- Out of Resource, SCTP ERRORチャンク
- Stale Cookie Error, SCTP ERRORチャンク
- Unrecognized Chunk Type, SCTP ERRORチャンク
- Unrecognized Parameters, SCTP ERRORチャンク
- Unresolvable Address, SCTP ERRORチャンク
- HEARTBEAT, データの送信とコントロールセッション, SCTP HEARTBEATチャンク
- HEARTBEAT ACK, データの送信とコントロールセッション, SCTP HEARTBEAT ACKチャンク
- INIT, イニシャライズとアソシエーション, SCTP共通ヘッダフォーマット, SCTPの一般ヘッダと共通ヘッダ, SCTP INITチャンク
- 可変長パラメータ, SCTP INITチャンク
- INIT ACK, イニシャライズとアソシエーション, SCTP共通ヘッダフォーマット, SCTP INIT ACKチャンク
- 可変長パラメータ, SCTP INIT ACKチャンク
- Length, SCTP ABORTチャンク, SCTP COOKIE ACKチャンク
- MTU, SCTP共通ヘッダフォーマット
- SACK, SCTPの特徴, データの送信とコントロールセッション, SCTP SACKチャンク
- SHUTDOWN, シャットダウンと中止, SCTP SHUTDOWNチャンク
- SHUTDOWN ACK, シャットダウンと中止, SCTP SHUTDOWN ACKチャンク
- SHUTDOWN COMPLETE, シャットダウンと中止, SCTP共通ヘッダフォーマット, SCTPの一般ヘッダと共通ヘッダ, SCTP SHUTDOWN COMPLETEチャンク
- T-bit, SCTP ABORTチャンク, SCTP SHUTDOWN COMPLETEチャンク
- TCB, SCTP ABORTチャンク
- TSN, SCTP DATAチャンク
- U-bit, SCTP DATAチャンク
- イニシエートタグ, SCTP INITチャンク, SCTP INIT ACKチャンク
- イニシャライズ, イニシャライズとアソシエーション
- エラー原因, SCTP ERRORチャンク
- ギャップ Ack ブロック #1 開始点, SCTP SACKチャンク
- ギャップ Ack ブロック #1 終点, SCTP SACKチャンク
- ギャップ Ack ブロック #N 開始点, SCTP SACKチャンク
- ギャップ Ack ブロック #N 終点, SCTP SACKチャンク
- ギャップ Ack ブロック数, SCTP SACKチャンク
- シャットダウンと中止, シャットダウンと中止
- ストリームシーケンスナンバー, SCTP DATAチャンク
- ストリーム識別子, SCTP DATAチャンク
- タイプ, SCTP ABORTチャンク
- チャンクタイプ, SCTPマッチ
- チャンクフラグ, SCTPの一般ヘッダと共通ヘッダ, SCTP COOKIE ECHOチャンク, SCTP ERRORチャンク, SCTP HEARTBEATチャンク, SCTP INITチャンク, SCTP INIT ACKチャンク, SCTP SACKチャンク, SCTP SHUTDOWNチャンク, SCTP SHUTDOWN ACKチャンク, SCTPマッチ
- チャンク値, SCTPの一般ヘッダと共通ヘッダ
- チャンク長, SCTPの一般ヘッダと共通ヘッダ, SCTP HEARTBEAT ACKチャンク, SCTP INITチャンク, SCTP INIT ACKチャンク, SCTP SACKチャンク, SCTP SHUTDOWNチャンク, SCTP SHUTDOWN ACKチャンク
- データの送信とコントロールセッション, データの送信とコントロールセッション
- ハートビートインフォメーション TLV, SCTP HEARTBEATチャンク, SCTP HEARTBEAT ACKチャンク
- ヘッダ, SCTPヘッダ
- ペイロードプロトコル識別子, SCTP DATAチャンク
- マルチキャスト, SCTPの特徴
- メッセージ指向, SCTPの特徴
- ユーザデータ, SCTP DATAチャンク
- ユニキャスト, SCTPの特徴
- レート対応, SCTPの特徴
- 宛先ポート, SCTPの一般ヘッダと共通ヘッダ
- 共通ヘッダフォーマット, SCTP共通ヘッダフォーマット
- 検証タグ, SCTPの一般ヘッダと共通ヘッダ
- 受信ウィンドウ保証量広告, SCTP INIT ACKチャンク, SCTP SACKチャンク
- 重複 TSN #1, SCTP SACKチャンク
- 重複 TSN #X, SCTP SACKチャンク
- 重複 TSN 数, SCTP SACKチャンク
- 初期 TSN, SCTP INIT ACKチャンク
- 初期TSN, SCTP INITチャンク
- 全長, SCTP COOKIE ECHOチャンク, SCTP DATAチャンク, SCTP ERRORチャンク, SCTP HEARTBEATチャンク, SCTP SHUTDOWN COMPLETEチャンク
- 送出ストリーム数, SCTP INITチャンク, SCTP INIT ACKチャンク
- 送信元ポート, SCTPの一般ヘッダと共通ヘッダ
- 特徴, SCTPの特徴
- 流入ストリーム数, SCTP INITチャンク, SCTP INIT ACKチャンク
- 累積 TSN Ack, SCTP SACKチャンク, SCTP SHUTDOWNチャンク
- SCTPマッチ, SCTPマッチ
- SECMARK ターゲット, mangleテーブル
- SECMARKターゲット, SECMARKターゲット
- --selctx, SECMARKターゲット
- Secondsマッチ, Recentマッチ
- Selctxターゲット, SECMARKターゲット
- SELinux, CONNSECMARKターゲット, SECMARKターゲット
- Sequence Number, TCPヘッダ
- Set-classターゲット, CLASSIFYターゲット
- Set-dscp-classターゲット, DSCPターゲット
- Set-dscpターゲット, DSCPターゲット
- Set-markターゲット, CONNMARKターゲット, MARKターゲット
- Set-mssターゲット, TCPMSSターゲット
- Set-tosターゲット, TOSターゲット
- Setマッチ, Recentマッチ
- Sid-owner.txt, Sid-owner.txt
- Sid-ownerマッチ, Ownerマッチ
- SLIP, 各種チェーンへのルール配置
- SNAT, このドキュメントで使う用語, IPフィルタとは何か, NATの利用目的と用語解説
- SNAT ターゲット, natテーブル
- SNATターゲット, SNATターゲット, 各種チェーンへのルール配置, SNATの開始とPOSTROUTINGチェーン
- --to-source, SNATターゲット
- Snort, IPフィルタの計画の仕方
- Source-portマッチ, TCPマッチ, UDPマッチ, SCTPマッチ, Multiportマッチ
- Sourceマッチ, 汎用的なマッチ
- Squid, IPフィルタとは何か, IPフィルタの計画の仕方, REDIRECTターゲット
- Src-rangeマッチ, IP rangeマッチ
- Src-typeマッチ, Addrtypeマッチ
- SSH, Bashデバグテクニック, 各種チェーンへのルール配置
- State
- Conntrackマッチ, Conntrackマッチ
- see also Conntrackマッチ
- Stateマッチ, このドキュメントで使う用語, IPフィルタリングの用語と表現, ステート機構, Stateマッチ
- --state, Stateマッチ
- CLOSED, TCPヘッダ
- ESTABLISHED, はじめに, ユーザ空間でのステート, ICMPコネクション, TCPチェーン, INPUTチェーン
- ICMP, ICMPコネクション
- INVALID, はじめに, ユーザ空間でのステート, bad_tcp_packetsチェーン
- NEW, はじめに, ユーザ空間でのステート, ICMPコネクション, bad_tcp_packetsチェーン
- NOTRACK, 追跡除外コネクションとrawテーブル
- see also NOTRACKターゲット
- RELATED, はじめに, ユーザ空間でのステート, TCPコネクション, TCPチェーン, ICMPチェーン, INPUTチェーン
- TCP, TCPコネクション
- UDP, UDPコネクション
- UNTRACKED, ユーザ空間でのステート
- [ASSURED], UDPコネクション
- [UNREPLIED], UDPコネクション
- 追跡除外コネクション, 追跡除外コネクションとrawテーブル
- 複雑なプロトコル, 複雑なプロトコルとコネクション追跡
- see also 複雑なプロトコル
- SYN, TCPヘッダ, bad_tcp_packetsチェーン, SYN/ACKでNEWなパケット
- SYN_RECV, TCPコネクション
- SYN_SENT, conntrackエントリ
- Synマッチ, TCPマッチ
- Syslog, LOGターゲット, デバグに役立つシステムツール
- alert, デバグに役立つシステムツール
- crit, デバグに役立つシステムツール
- emerg, デバグに役立つシステムツール
- err, デバグに役立つシステムツール
- info, デバグに役立つシステムツール
- notice, デバグに役立つシステムツール
- warning, デバグに役立つシステムツール
- デバグ, デバグに役立つシステムツール
- syslog.conf, デバグに役立つシステムツール
T
- Table does not exist エラー, iptablesのデバグ
- TCP, TCP/IPのおさらい, TCPコネクション, bad_tcp_packetsチェーン, TCPチェーン
- ACK, TCPヘッダ
- CWR, TCPヘッダ
- ECE, TCPヘッダ
- FIN, TCPの特徴, TCPヘッダ
- FIN/ACK, TCPの特徴
- PSH, TCPヘッダ
- PUSH, TCPヘッダ
- RST, TCPヘッダ
- SYN, TCPの特徴, TCPヘッダ
- URG, TCPヘッダ, TCPヘッダ
- ウィンドウ, TCPヘッダ
- オプション, TCPヘッダ, TCPオプション
- シーケンスナンバー, TCPヘッダ
- チェックサム, TCPヘッダ
- データオフセット, TCPヘッダ
- ハンドシェイク, TCPの特徴
- パディング, TCPヘッダ
- ヘッダ, TCPヘッダ
- 宛先ポート, TCPヘッダ
- 開始, TCPコネクション
- 確認応答ナンバー, TCPヘッダ
- 緊急ポインタ, TCPヘッダ
- 送信元ポート, TCPヘッダ
- 特徴, TCPの特徴
- 予約域, TCPヘッダ
- Tcp-flagsマッチ, TCPマッチ
- Tcp-optionマッチ, TCPマッチ
- TCP/IP, TCP/IPのおさらい
- アプリケーション層, TCP/IPのレイヤー
- インターネット層, TCP/IPのレイヤー
- スタック, TCP/IPのレイヤー
- トランスポート層, TCP/IPのレイヤー
- ネットワークアクセス層, TCP/IPのレイヤー
- レイヤー, TCP/IPのレイヤー
- TCP/IP ルーティング, TCP/IP宛先誘導型ルーティング
- TCPMSSターゲット, TCPMSSターゲット
- --clamp-mss-to-pmtu, TCPMSSターゲット
- --set-mss, TCPMSSターゲット
- Tcpmssマッチ, TCPMSSマッチ
- --mss, TCPMSSマッチ
- tcp_chain, TCPチェーン
- TCPマッチ, TCPマッチ
- TFTP, 複雑なプロトコルとコネクション追跡
- THROW, Addrtypeマッチ
- Time Exceededメッセージ, TTL equals 0
- Time to live, IPヘッダ, ICMPヘッダ
- To-portsターゲット, MASQUERADEターゲット, REDIRECTターゲット
- To-sourceターゲット, SNATターゲット
- TOS, mangleテーブル
- TOSターゲット, TOSターゲット
- --set-tos, TOSターゲット
- Tosマッチ, TOSマッチ
- --tos, TOSマッチ
- Total-nodesターゲット, CLUSTERIPターゲット
- Toターゲット, NETMAPターゲット, SAMEターゲット
- Tripwire, IPフィルタの計画の仕方
- TTL, ICMPチェーン
- TTL equals zero, TTL equals 0
- TTL equals 0 during reassembly, TTL equals 0
- TTL equals 0 during transit, TTL equals 0
- TTL ターゲット, mangleテーブル
- Ttl-decターゲット, TTLターゲット
- Ttl-eqマッチ, TTLマッチ
- Ttl-gtマッチ, TTLマッチ
- TTL-inc.txt, Ttl-inc.txt
- Ttl-incターゲット, TTLターゲット
- Ttl-ltマッチ, TTLマッチ
- Ttl-setターゲット, TTLターゲット
- TTLターゲット, TTLターゲット, Ttl-inc.txt
- Ttlマッチ, TTLマッチ
- Turtle Firewall プロジェクト, Turtle Firewall プロジェクト
- Type of Service, IPヘッダ
U
- UDP, TCP/IPのおさらい, UDPの特徴, UDPコネクション, UDPチェーン
- udp_packets, UDPチェーン
- UDPマッチ, UDPマッチ, UDPチェーン
- Uid-ownerマッチ, Ownerマッチ
- Ulog-cprangeターゲット, ULOGターゲット
- Ulog-nlgroupターゲット, ULOGターゲット
- Ulog-prefixターゲット, ULOGターゲット
- Ulog-qthresholdターゲット, ULOGターゲット
- ULOGターゲット, ULOGターゲット
- Uncleanマッチ, Uncleanマッチ
- UNICAST, Addrtypeマッチ
- Unknown arg, iptablesのデバグ
- UNREACHABLE, Addrtypeマッチ
- UNREPLIED, TCPコネクション
- UNSPEC, Addrtypeマッチ
- Updateマッチ, Recentマッチ
- URG, TCPヘッダ, TCPヘッダ