ハフマンツリーから記号に対応するコードを求める関数は、再帰的な関数の典型例だった。Cなどの言語で許される再帰的な関数の記述は、Gの場合はおもてだって使うことができない。Gでは再帰的な処理はあきらめなければならないのだろうか? 今回はGにおける再帰処理の扱い方を考えてみよう。
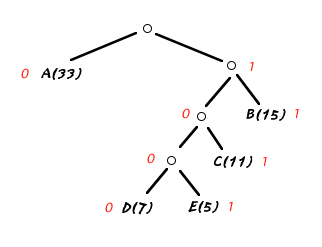
例えば、このツリーでは"E"には"1001"というコードが与えられている。人間が作業する場合はツリー全体が見渡せるので簡単なことなのだが、プログラムで実行させる場合は洞窟の中を探検したり、巨大迷路の中を歩くようなもので多少やっかいな作業になる。
全ての記号とコードを対応させたいときは、ツリーの根(図の一番上の部分)から出発してノードを順番にたどっていくのが簡単だ。
「あるノードのコードが分かっているものとして、」そのノードから分岐する一方にはコードに"1"を追加し、他方には"0"を追加することにしよう。分岐したものが記号であるときにはそのコードが記号のコードになる。
「ノードだった場合は、」そのノードから分岐する一方にはコードに"1"を追加し、他方には"0"を追加することにしよう。分岐したものが記号であるときにはそのコードが記号のコードになる。
「ノードだった場合は、」そのノードから分岐する一方にはコードに"1"を追加し、他方には"0"を追加することにしよう。分岐したものが記号であるときにはそのコードが記号のコードになる。
<<続く>>
無限ループに入りそうな文章だが、全ての枝葉には記号がぶら下がっているため、全てを回り尽くすと自然に終了する仕組みになっている。
実際のCプログラムでは、上の手順を実行する関数の定義の中でその関数自身を使って簡単に表現している。出典は前回同様「データ圧縮ハンドブック」(ISBN4-8101-8605-9)だ。
他の関数から呼び出すときには
convert_tree_to_code( nodes, codes, 0, 0, root_node );
という具合に行われる。
ツリーのあたま ( root_node ) からスタートして、END_OF_STREAM (256) より大きい場合(中間ノードに対応している)、一回ごとにcode_so_far を左シフトして、child_0 の方はcode_so_far そのままで、child_1 の方は最下位ビットに1を立てて、convert_tree_to_code を(再帰的に)呼び出している。END_OF_STREAM (256) 以下になったときには、その時点のcode_so_far がその記号に対するコードとなっている。
プログラムコードは簡潔で動作は分かりやすいが、全体を通して漏れなくツリー全体をたどっているかどうか考え出すと、頭がついていかなくなってしまう。
Gでは関数の中に同じ関数を呼び出すことはできない。ちゃんと、回帰的な使用はできませんとメッセージが出てくる。だから、回帰的なアルゴリズムを使うことができないかというと、そうではない。スタックを自前で準備すればいいだけだ。C でも実際はコンパイラが見えないところでスタックを用意してくれているらしい。
前置きが長くなってしまったが、一番下のシフトレジスターがスタックになっている。convert_tree_to_code( nodes, codes, code_so_far, bits, node ) は5個の入力を持っているが、code_so_far、bits、nodeの3個をクラスターにして、二股に別れたchild_1の方をスタックに収めることにした。
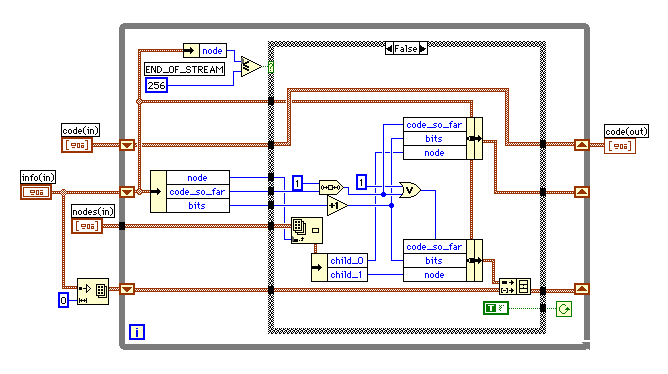
ケースがtrueになったときにはスタックから取り出して計算を続け、全てのスタックが無くなったときにループが終了する。
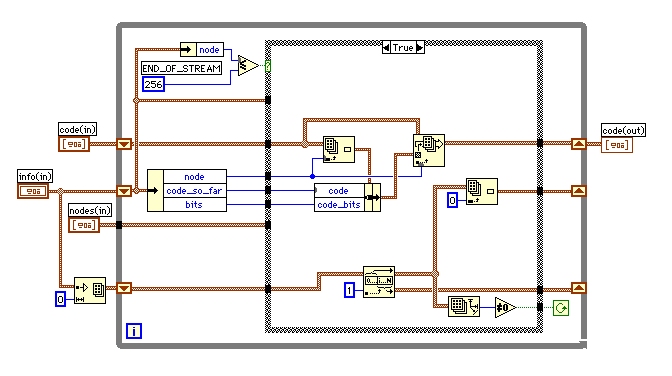
スタックの配列のサイズが変動することで動作速度が遅くなることを気にする場合は、スタックのサイズをあらかじめ決めて、スタックカウンターでスタック量を管理すれば良いだろう。