gccの日本語文字コード (1999/12/12 初版)
GNUの gcc/g++ は、日本語シフトJISコードに完全に対応していません。そのために、
Windows 95/98 などのシフトJISコード・ベースの環境では、特定の文字で問題を起こし
ます。ここでは、その対処法を示します。
日本語の文字コードは2バイトで表されますが、問題を起こすのはその2バイト目が
「円記号」'\' (5C)になる文字です。例えば次のような標準出力
cout << "ベクトルの表示" << endl;
のコードを含むプログラムをコンパイルすると
unknown escape sequence: `\' followed by char code 0x8e
|
となって、うまくゆきません。この場合、問題となるのは「表」です。この文字は、2
バイト目が「円記号」'\'になっています。
Windows 95/98 の場合は、付属のソフト文字コード表([スタート] -> [プログラム]
-> [アクセサリ])を使って、文字コードの値を簡単に調べることができます。
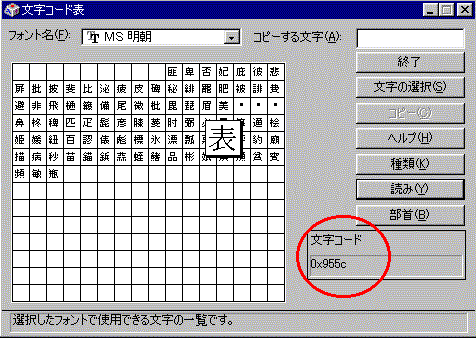 「表」の文字コードは、'x955C' (16進) です。これは1バイト目が 'x95' で、2バイ
ト目が '5C' つまり「円記号」 '\' です。
問題を回避するには、1バイト目を16進数 '\x95' で、2バイト目をエスケープ文
字を使って '\\'で表します("表" → "\x95\\")。
cout << "ベクトルの\x95\\示" << endl;
この様に、2バイト目が「円記号」となる文字をいくつか示します。
'ソ'(x835c) → '\x83\\'
'欺'(x8b5c) → '\x8b\\'
'圭'(x8c5c) → '\x8c\\'
'構'(x8d5c) → '\x8d\\'
'蚕'(x8e5c) → '\x8e\\'
'十'(x8f5c) → '\x8f\\'
'申'(x905c) → '\x90\\'
'貼'(x935c) → '\x93\\'
'能'(x945c) → '\x94\\'
'表'(x955c) → '\x95\\'
'暴'(x965c) → '\x96\\'
'予'(x975c) → '\x97\\'
'禄'(x985c) → '\x98\\'
「表」の文字コードは、'x955C' (16進) です。これは1バイト目が 'x95' で、2バイ
ト目が '5C' つまり「円記号」 '\' です。
問題を回避するには、1バイト目を16進数 '\x95' で、2バイト目をエスケープ文
字を使って '\\'で表します("表" → "\x95\\")。
cout << "ベクトルの\x95\\示" << endl;
この様に、2バイト目が「円記号」となる文字をいくつか示します。
'ソ'(x835c) → '\x83\\'
'欺'(x8b5c) → '\x8b\\'
'圭'(x8c5c) → '\x8c\\'
'構'(x8d5c) → '\x8d\\'
'蚕'(x8e5c) → '\x8e\\'
'十'(x8f5c) → '\x8f\\'
'申'(x905c) → '\x90\\'
'貼'(x935c) → '\x93\\'
'能'(x945c) → '\x94\\'
'表'(x955c) → '\x95\\'
'暴'(x965c) → '\x96\\'
'予'(x975c) → '\x97\\'
'禄'(x985c) → '\x98\\'
| 目次 |
戻る |
Copyright(c) 1999 Yamada, K