埲壓偼丄Gemini偺塸岅儀乕僞斉偑偱偨偙傠偵峴偭偨娙扨側幚尡偺寢壥偱偡丅擔杮岅僥僉僗僩偺拪弌偑丄巗斕偺嵟怴斉偱偳偆側偭偰偄傞偐偼奺帺偱偛妋擣偔偩偝偄丅擔杮岅拪弌偑姰慡偵偱偒傞傕偺偐偳偆偐嵟怴斉傪巊偭偰偼偍傝傑偣傫偨傔晄柧偱偡丅偍婥偯偒偺揰偑偁傟偽丄忣曬傪偍婑偣偄偨偩偗傟偽丄岾偄偱偡丅
乮2002/2/11婰乯
Iceni幮偺PDF僨乕僞拪弌僜僼僩丄Gemini偺棙梡椺傪愢柧偡傞傕偺偱偡丅
Gemini偼丄帠幚忋偺暥彂攝晍丄岞奐梡昗弨僜僼僩偲偟偰桳柤側丄Adobe幮偺Acrobat偺僾儔僌僀儞偱偡丅
Acrobat 4.0J偲丄Gemini1.2偺儀乕僞斉傪巊偭偨幚尡偱偡丅
Gemini傪巊偭偰丄PDF偐傜丄HTML丄RTF丄plain text偱僥僉僗僩僨乕僞傪庢傝弌偡偙偲偑壜擻偱偡丅
Gemini偺摫擖曽朄偼徣棯偟傑偡丅
僨乕僞乕拪弌偡傞慺嵽偺PDF偼丄Mac偺忋偱丄PageMaker偵傛偭偰丄擔杮岅偲儘僔傾岅傪暲婰偟偨傕偺偱偡丅
尰暔偼偙偙偐傜sfpdfm.pdf傪僟僂儞儘乕僪偱偒傑偡丅
乮Netscape偱偼丄僼傽僀儖亅>暿柤偱曐懚乯
奩摉偺PDF僼傽僀儖sfpdfm.pdf偼丄壓婰偺傛偆側儗僀傾僂僩偵側偭偰偄傑偡丅乮壓晹偼徣棯乯

傑偢丄偳偺傛偆側弌椡偵偡傞偐傪愝掕偟傑偡丅
僥僉僗僩偼壓婰偺弌椡偑慖戰偱偒傑偡丅
1. Acrobat 4.0偱丄僼傽僀儖->娐嫬愝掕->Gemini傪慖傃傑偡丅

2. 偡傞偲丄僥僉僗僩偲夋憸偺弌椡庬椶慖戰梡儃僢僋僗偑偁傜傢傟傑偡丅

3. 僥僉僗僩偲丄夋憸偺弌椡宍幃偺庬椶傪丄偦傟偧傟慖戰偟傑偡丅
僥僉僗僩偱偼丄儁乕僕枅偵偔偓傞偐丄夵峴僐乕僪傪偦偺傑傑巆偡偐摍偺慖戰傕壜擻偱偡丅


4. Acrobat 4.0偱丄僾儔僌僀儞->Gemini Export傪慖戰偟傑偡丅
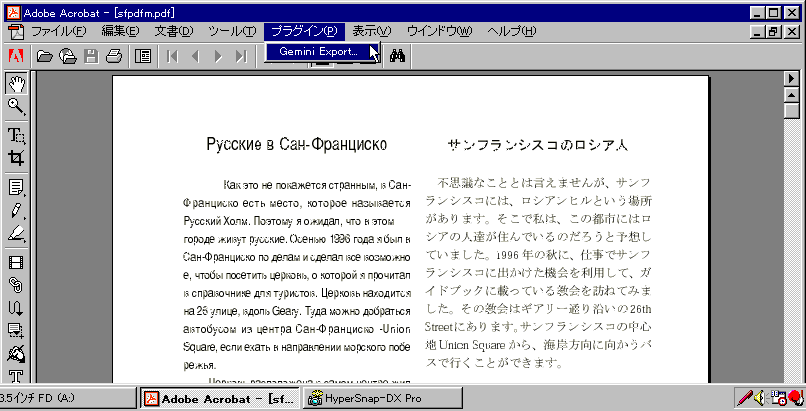
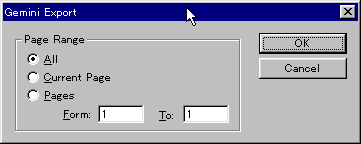
5. 偦偙偱丄奩摉偺PDF僼傽僀儖偺丄
拪弌偺懳徾偲偡傞晹暘傪慖戰偟傑偡丅
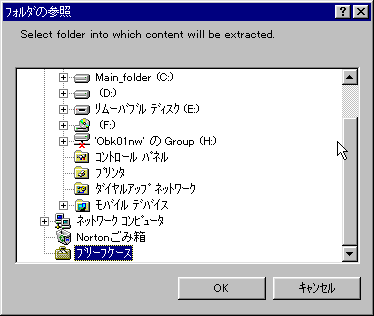
拪弌偟偨僼傽僀儖偺抲偒応偺慖戰
6. 弌椡僨乕僞乮僥僉僗僩乯偼埲壓偺傛偆偵側傝傑偟偨丅
忋偺曽偺暥帤偑偽偗偰偄傑偡偑丄偙偙偑儘僔傾岅偺晹暘偱偡丅

7. 暥帤傪惓偟偔愝掕偡傞偲丄傕偲偺忬懺偵栠傝傑偡丅
壓婰偼Mac梡偺僄僨傿僞乕YooEdit偱暥帤愝掕傪曄峏偡傞椺偱偡丅

偙偙偱Pryamoi傪慖戰偟偰傒傑偡丅

偙傟偱丄撉傔傞忬懺偵側傝傑偡丅

傕偪傠傫丄擔杮岅晹暘傕拪弌偝傟偰偄傑偡丅埲壓偼夋柺偺堦晹偱偡丅
