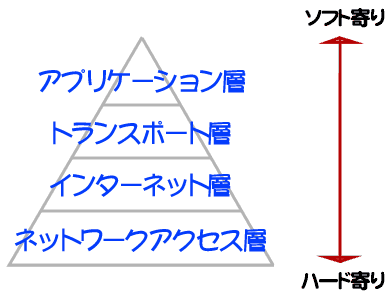
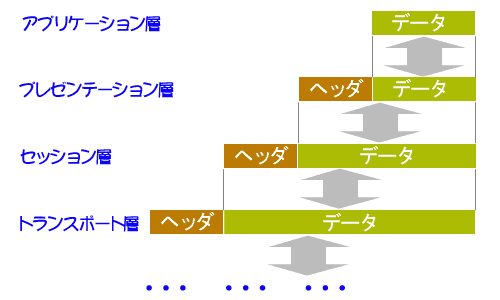
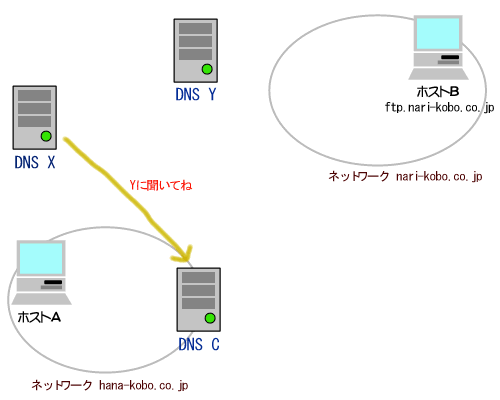
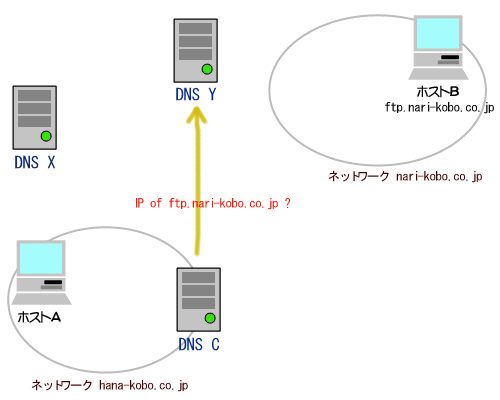
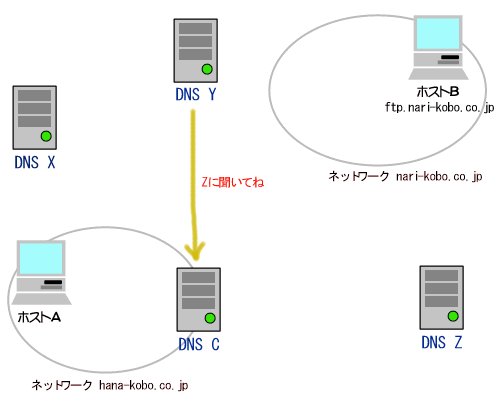
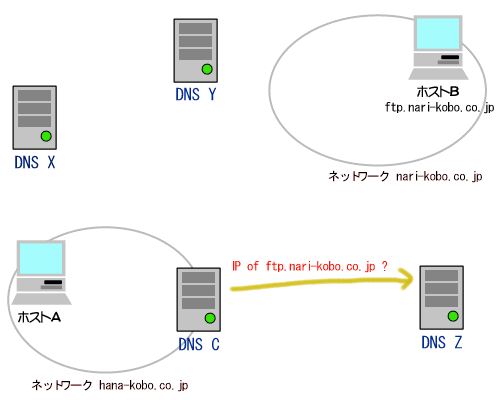
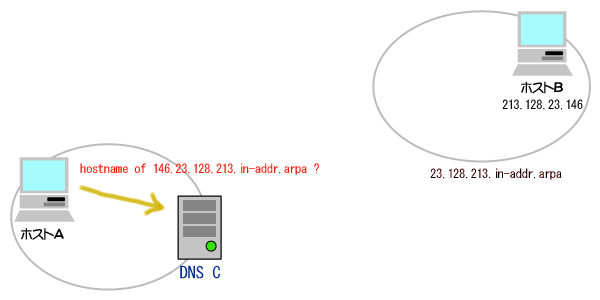
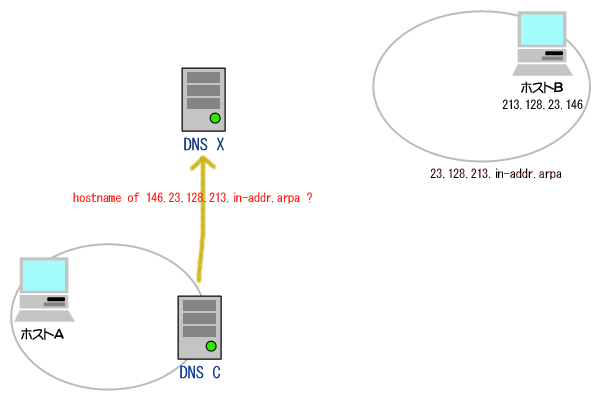
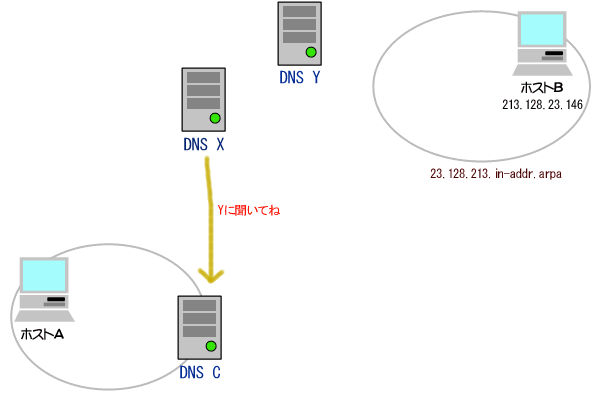
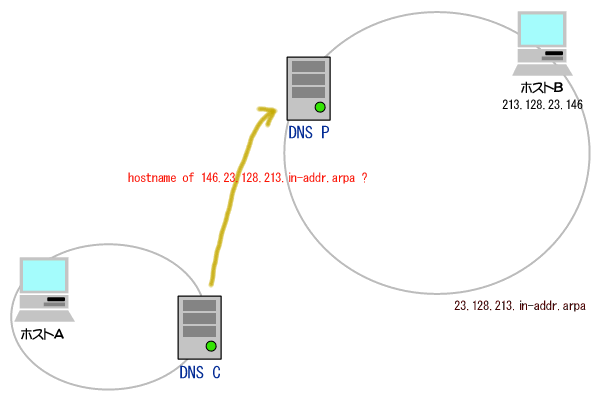
(1)論理アドレス(IPアドレス)
IPアドレスとはTCP/IPネットワークでの住所を指す32ビット(4バイト)の数値で、IPプロトコルによって定義されています。一般に、192.168.24.6というような1バイトづつの数値を4つ並べる方法で表現されます。
IPアドレスはネットワーク上での住所だと書きましたが、しかし、IPアドレスは単にネットワーク上の端末を区別するだけの値ではありません。それは、対象となる端末がどのネットワークに属しているかという情報も持っているのです。郵便の住所で「大阪府寝屋川市なんちゃら町?丁目?番地」と書けば、それが大阪府に属していることも表わしているのと同じようなことです。
複数のネットワーク間でパケットを交換し合うために最も重要な機能である「ルーティング」も、IPアドレスに含まれているこのネットワーク情報を基に処理されています。
ただし、ここでIPアドレス(ただし非ネットワークのもの)に関して勘違いしやすい非常に重要な注意点を指摘しておきます。
それは「IPアドレスが特定しているものは何か」ということに関してです。
上でも使用した、郵便での住所の比喩から、IPアドレスは特定の端末に1つだけ割当てられるものと理解されがちです。しかし実際はそうではありません。IPアドレスは特定の端末に複数割当てられることが多々あるのです。(プライベートアドレスと呼ばれる自由に使用できる同一のIPアドレスも存在しますが、これについては後で解説します。)
これは一体どういうことでしょうか?
実は、IPアドレスはネットワークと端末とのインターフェイス(接点)に割当てられるものなのです。端末そのものに割当てられるものではないのです。
例えば、会社のパソコンが社内LANにつながっていて、かつ同パソコンからプロバイダ経由(つまりはダイアルアップ接続)でインターネットにも接続できるような場合、その端末には2つのIPアドレスが割当てられることになります。なぜなら、そのパソコンにはLANというネットワークとの接点と、モデムを経由したプロバイダのネットワークとの接点が存在するからです。
しかしながら、「え? 自分のコンピュータはそういう形で利用しているけど、IPアドレスは1つしか設定したことないですよ」という方も多いのではないでしょうか。
実は、それはもう1つのIPアドレスが自動的に割当/設定されるため、わざわざユーザが自ら設定する必要が無いのでしていない、というだけのことなのです。
具体的にそれを確かめて見ましょう。
ただし、ここで解説に当たっては以下の環境を想定します。これらはLAN接続していてかつダイアルアップ接続が可能な端末では一般的な設定だと思われます。
・LANカードによりLANに繋がっている
・モデムを使用してダイアルアップ接続できる
・LANではDHCPを使用しないで固定IPアドレスを設定している
・ダイアルアップ接続ではDHCPを使用している
・OSは Microsoft Windows9X
|
ミニ解説: DHCP
DHCPというのは「動的IP設定プロトコル」のことで、簡単にいうと「IPアドレスをDHCPサーバと端末の間で接続の度に勝手に取り決めて設定してくれる機能」のことです。
これを使用すると、ユーザは自分でIPアドレス等を設定する必要がなくなります。
大規模なネットワークで各端末に人手を介してIPアドレスを設定するのは大変な労力が必要となるため、DHCPはそのような大規模ネットワークで特に威力を発揮します。
例えばISP(インターネットプロバイダ)のネットワークではこのDHCPを使用することがほとんどです。ISPにダイアルアップ接続してくるユーザは非常に多く、またその数も不定だからです。
それに対して、LANの場合はDHCPを使用せず各ユーザがIPアドレスを設定(といっても1度だけですが..)する場合がまだまだ多いようです。たいていの場合ユーザ数がそれほど多くないという事情もあるためのようです。
DHCPの設定等について詳しくは、また後日どこかで解説する機会を持ちたいと思います。
|
ここではOSとして Microsoft Windows9X が載っているものを前提としていますが、他のOSが乗っているパソコンでも似た様な方法で確かめることができます。MS Windows に固有の現象ではないのでその点を誤解しないで下さい。
まず、ダイアルアップ接続していない状態で「MS-DOSプロンプト」を起動させて以下のコマンドを実行して下さい。
|
C:\WINDOWS>ipconfig /All /Batch C:\IP1.TXT
|
|
ミニ解説: ipconfigコマンド
ipconfigコマンドは、端末のIPアドレスの現在の設定状況を表示してくれるコマンドです。/All オプションは「詳細を表示する」という指定で、/Batch *** オプションは「結果をディスプレイではなく***ファイルに書きこみなさい」という指定です。
したがって、上のコマンドの意味は全体として「現在のIP設定詳細情報を C:\IP1.TXTファイルに書出しなさい」という意味になります。
|
すると、C:\IP1.TXT に以下のような記述があるのを見て取れるはずです。
#### IP1.TXT ####
... ... ... ...
... ... ... ...
0 Ethernet アダプタ :
説明 . . . . . . . . : PPP Adapter.
物理アドレス. . . . . . : 44-45-53-54-00-00
DHCP 有効. . . . . . . . : はい
IP アドレス. . . . . . . . . : 0.0.0.0
サブネット マスク . . . . . . . . : 0.0.0.0
デフォルト ゲートウェイ . . . . . . :
DHCP サーバー . . . . . . . . : 255.255.255.255
... ... ... ...
... ... ... ...
1 Ethernet アダプタ :
説明 . . . . . . . . : Fast Ethernet PCI Adapter
物理アドレス. . . . . . : 00-00-F4-5A-39-F9
DHCP 有効. . . . . . . . : いいえ
IP アドレス. . . . . . . . . : 192.168.10.2
サブネット マスク . . . . . . . . : 255.255.255.0
デフォルト ゲートウェイ . . . . . . : 192.168.10.254
... ... ... ...
... ... ... ...
|
これを見ると、この端末にはネットワークへのインターフェイスが「PPP Adapter」と「Fast Ethernet PCI Adapter」の2つあることが分かります。
しかし、PPP Adapter(ダイアルアップアダプターのこと)にはこの段階ではIPアドレスが割当てられていません。今はダイアルアップ接続をしていないためこのようになっているのです。
これに対して、Fast Ethernet PCI Adapter(LANカードのこと)にはIPアドレスが既に割当てられています。しかもそれは以前自分(あるいは前の持ち主)で設定したIPアドレスになっているはずです。
これらの点を確認できたら、今度はダイアルアップ接続をした状態で「MS-DOSプロンプト」を起動させて先と同様のコマンドを実行して下さい。
C:\WINDOWS>ipconfig /All /Batch C:\IP2.TXT
|
すると今度は、C:\IP2.TXT が以下のような記述に変わったのを見て取れるはずです。
#### IP2.TXT ####
... ... ... ...
... ... ... ...
0 Ethernet アダプタ :
説明 . . . . . . . . : PPP Adapter.
物理アドレス. . . . . . : 44-45-53-54-00-00
DHCP 有効. . . . . . . . : はい
IP アドレス. . . . . . . . . : 202.213.147.52
サブネット マスク . . . . . . . . : 255.255.255.0
デフォルト ゲートウェイ . . . . . . : 202.213.147.52
DHCP サーバー . . . . . . . . : 255.255.255.255
... ... ... ...
... ... ... ...
1 Ethernet アダプタ :
説明 . . . . . . . . : Fast Ethernet PCI Adapter
物理アドレス. . . . . . : 00-00-F4-5A-39-F9
DHCP 有効. . . . . . . . : いいえ
IP アドレス. . . . . . . . . : 192.168.10.2
サブネット マスク . . . . . . . . : 255.255.255.0
デフォルト ゲートウェイ . . . . . . : 192.168.10.254
... ... ... ...
... ... ... ...
|
まず、この端末に存在するネットワークインターフェイスは「PPP Adapter」と「Fast Ethernet PCI Adapter」の2つでIP1.TXTから変化がないことが分かります。
Fast Ethernet PCI Adapterの各情報はIP1.TXTと変化がありません。しかし先程と違って、PPP AdapterにはIPアドレス等に身に覚えのない各種情報が割当てられています。今はダイアルアップ接続をしている最中のためこのようになっているのです。IPアドレス等が身に覚えのない値に設定されていたのは、ダイアルアップ接続をした際にDHCPによりIPアドレスが自動設定されたためです。
このように、たとえ自分で設定したIPアドレスの数とネットワークインターフェイスの数が一致しなくても、それは単にDHCPなどにより自動的に設定されているだけで、「IPアドレスはネットワークインターフェイス毎に割り当てられる」という原理に反しているわけではありません。
さて、先に「IPアドレスにはそれがどのネットワークに属しているのかを表す情報も含まれている」と書きました。
では次に、その「ネットワーク情報」がIPアドレスの中にどのように組み込まれているのかを見ていくことにします。
郵便の住所の場合は、住所自身に「都道府県、市町村、丁、番地」というような情報を直接含めることで地域情報(通信でのネットワーク情報に相当)を住所に組み込んでいます。この方式の場合、地域情報がそのエリアの複雑さにしたがって階層化(都道府県レベルや市町村レベル等)されるため、どんなにややこしい場所でも地域情報の階層を追っていくことでたやすくその場所を特定できるという利点があります。
インターネット黎明期のIPアドレスでは、以下に示すアドレスクラスを用いてそれぞれのネットワークを区別していました。
これによると、IPアドレスはネットワーク部とホスト部という2つの部分に分離でき、ネットワーク部の長さは1バイト、2バイト、3バイトのいずれかであることが分かります。
なお、ネットワーク部とは「ネットワークを識別する数値」を意味し、ホスト部とは「同ネットワーク内での端末を識別する数値」のことを意味します。
①クラスA
10進法表記
A.B.C.D ただし、A<128
2進法表記
0??? ???? . ???? ???? . ???? ???? . ???? ????
赤字 --- ネットワーク部 緑字 --- ホスト部
|
1バイト目が127以下のもの(先頭ビットが0)で、先頭バイトがネットワーク部、後ろ3バイトがホスト部となる。したがって、このクラスに属するネットワーク数は2^7(=127)個で、各ネットワークには2^24(=16,777,216)個ものIPアドレスが割当てられる。
②クラスB
10進法表記
A.B.C.D ただし、127 < A< 192
2進法表記
10?? ???? . ???? ???? . ???? ???? . ???? ????
赤字 --- ネットワーク部 緑字 --- ホスト部
|
1バイト目が128以上191以下のもの(先頭2ビットが10)で、先頭2バイトがネットワーク部、後ろ2バイトがホスト部となる。したがって、このクラスに属するネットワーク数は2^14(=16,384)個で、各ネットワークには2^16(=65,536)個ものIPアドレスが割当てられる。
③クラスC
10進法表記
A.B.C.D ただし、191 < A< 224
2進法表記
110? ???? . ???? ???? . ???? ???? . ???? ????
赤字 --- ネットワーク部 緑字 --- ホスト部
|
1バイト目が192以上223以下のもの(先頭3ビットが110)で、先頭3バイトがネットワーク部、後ろ1バイトがホスト部となる。したがって、このクラスに属するネットワーク数は2^21(=2,097,152)個で、各ネットワークには2^8(=256)個のIPアドレスが割当てられる。
④クラスD
1バイト目が224以上239以下のもの(先頭4ビットが1110)で、マルチキャストアドレスと呼ばれる。これは特定の端末を指すのではなく、特定のアプリケーションを共有するコンピュータのグループを指す。
このクラスにはネットワーク部という概念がない。
⑤クラスE
1バイト目が240以上のもの(先頭4ビットが1111)で、これは将来のために予約されている。したがって、インターネットで使用することはできない。
このクラスにはネットワーク部という概念がない。
この方式ではネットワークは階層化されて理解されず、全てのネットワークはお互いに対等な関係にありました。例えば、ネットワークAがネットワークBの中に完全に含まれていたとしても、その階層関係はIPアドレスからは分からなかったのです。
インターネットが形成され始めた頃は接続されるネットワークの数も少なくこれで特に問題はなかったのですが、その後のインターネットの急速な拡大に伴って「ルータの負荷が無視できないほどに増大する」という現象が起き始めました。これは、IPアドレスにネットワークの階層情報が無いため、ルータが使用する「ルーティングテーブル」がインターネットに接続されるネットワーク数の増加に伴ってどんどん肥大していかざるを得ないために起こったものでした。(ルーティングテーブルについては4章で詳しく解説します。とりあえずここではそういうものだと思って読み進めて下さい。)
また、この方式では各ネットワークに割当てられるIPアドレス数が、そのネットワークが実際に使用するIPアドレス数に依らず上述のとおりアドレスクラスによって決定されてしまうため、インターネットに接続される中小規模のネットワークが増加するにしたがって「IPアドレスの枯渇」という別の問題も引き起こし始めました。
これは、一番小さなクラスCのネットワークですらIPアドレスが256個も割り当てられてしまうため、そのネットワークの規模によっては使われないIPアドレスが大量に発生してしまうためです。IPアドレスは4バイトとその大きさが決まっているため、「使われないIPアドレスの発生」はすなわち全体として「IPアドレスの枯渇」を引き起こすというわけです。
そこで、IPアドレスのネットワーク部を調節して割当てIPアドレス数を節約し、かつネットワークの階層関係をも表現することができる新しい技術が開発されました。この新しい技術は、基本的にはアドレスクラスの代わりに「ネットマスク」というビット単位のマスクを用いることでネットワーク部の長さを調節できるようにするという技術です。(下図)
IPアドレス
213.128.23.53
ネットマスク
255.255.240.0
2進法表記
11111111 11111111 11110000 00000000 <--- ネットマスクは 255.255.240.0
11010101 10000000 00010111 00110101 <--- IPアドレスは 213.128.23.53
<----- ネットワーク部 -----><--- ホスト部 -->
ネットマスクを2進表記にした場合に1が立っている部分をネットワーク部
0が立っている部分をホスト部とする
|
そのため、この新しい方法ではネットワーク及び端末の登録時に使用するIP情報を若干拡張する必要がでてきました。なぜなら、従来のアドレスクラスによる方法では、IPアドレスの先頭バイトからネットワーク部の長さが確定できたのですが、この新たな技術ではIPアドレスだけではネットワーク部の長さが確定できないため、IPアドレスそのものと共にそのネットワーク部を特定するネットマスクの情報も指定しなければならなくなったためです。
そこで、最近では端末やネットワークのIP情報を登録する際に、必ずIPアドレスと共にネットマスクも登録するようになっています。この辺りのことは、最近パソコンのネットワーク設定を自力でしたほとんどの方が経験しているのではないでしょうか。
ちなみに、前述のIP1.TXTやIP2.TXTにも「サブネットマスク」という形でこれを見てとれます。
このように登録IP情報が拡張されたため、自身のIPアドレス表記法も以下のような形に拡張されました。
例)ネットマスクが28ビット長の場合
IP...213.128.23.148/28
あるいは
IP...213.128.23.248 ネットマスク...255.255.255.240
|
では次に、このネットマスクを用いたネットワークの階層化の例を見てみることにします。
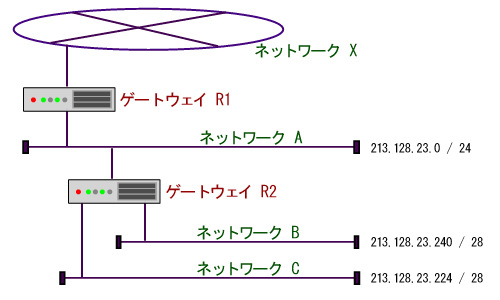
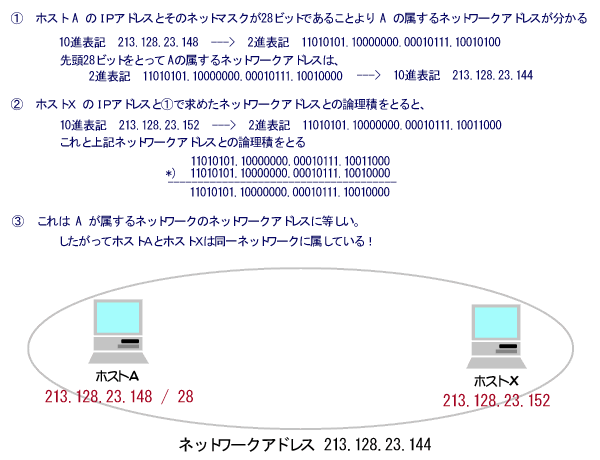
この図では、まず外部ネットワークとしてネットワークXがあり、そこにネットマスク長が24ビットのネットワークAが接続されていて、そのネットワークAには更にネットマスク長が28ビットのネットワークB、Cが接続されている、という様子が表わされています。
この場合、図から「ネットワークAは、ネットワークBとCを内部に含んでいる」という階層構造を確かめられますが、実はIP情報からもその階層構造を確認できます。以下でこれを確かめてみます。
例えば、ネットワークBに含まれるIPアドレス「213.128.23.248」はネットワークAのネットマスク「255.255.255.0」と論理積をとると「213.128.23.0」となりネットワークAのIPアドレスに等しくなります。また同様に、ネットワークCに含まれるIPアドレス「213.128.23.230」もネットワークAのネットマスク「255.255.255.0」と論理積をとると「213.128.23.0」となりネットワークAのIPアドレスに等しくなります。
そしてこれは、ネットワークB、Cに属するどのアドレスを用いても同じ結果となります。
あるネットワークのネットマスクと論理積をとったものがそのネットワーク部と等しくなるアドレスはそのネットワークに属していると判断できるため、結局ネットワークB、CはネットワークAに属していることが分かります。
逆に、ネットワークAに含まれているIPアドレスの中には、ネットワークB、Cのネットマスクと論理積をとってもネットワークB、CのIPアドレスに等しくならないものが存在します(例えば「213.128.23.126」)。これは、とりもなおさずネットワークAがネットワークBやCには属していない、ということを表しています。
以上より、「ネットワークAはネットワークB及びネットワークCを内部に含んでいる」という階層構造を確認することができました。
4章でルーティングに関して解説をしますが、そこではネットマスクのこの機能によりルータの負荷が減ることを解説します。
最後に、従来のアドレスマスクによる方式では、上記のようなネットワークの階層化ができなかった、という点に注意して下さい。
|
ミニ解説: プライベートアドレス
基本的にIPアドレスは世界中で重複してはならないため、NIC(Network Information Center)と呼ばれる機関がその割当てを管理しています。したがって、自分のネットワーク及びその端末に、勝手にIPアドレスを割当てることは許されず、必ずNICから割当てられたIPアドレスのみを使用しなくてはなりません。
ところが、条件付ながら「勝手に」割当てることが許されているIPアドレス群があります。それらは「プライベートアドレス」と呼ばれ、以下の条件の下で自由に使用することができます。
使用の条件
ローカルに閉じたネットワーク内でのみ流通するアドレスとしてならば自由に使用して良い。つまり、インターネットにそのアドレス情報(プライベートアドレス)が流れるような位置のネットワークで使用してはならない。
|
この条件を満たすネットワークであれば、以下に示すプライベートアドレスを自由に使用して構わないのですが、この条件を満たすネットワークとは具体的にはどのようなネットワークでしょうか。
プライベートアドレス:
10.0.0.0 ~ 10.255.255.255
172.16.0.0 ~ 172.31.255.255
192.168.0.0 ~ 192.168.255.255
|
外部のネットワークから完全に独立した(物理的に独立した)ネットワークは勿論上記条件を満たしていますが、インターネットと物理的に繋がっているネットワークではどうでしょうか?
インターネットに繋がっている端末同士が通信する場合、必ずお互いのIPアドレスをパケットに含めなくてはならないことを前章で解説しましたが、これから考えるとインターネットと物理的に接続されたネットワークは上記条件を満たせないように思えます。
確かにほとんどの場合そうなのですが、実はあるテクニックを使用すればインターネットと物理的に繋がっているネットワークでも上記条件をクリアすることが可能となります。
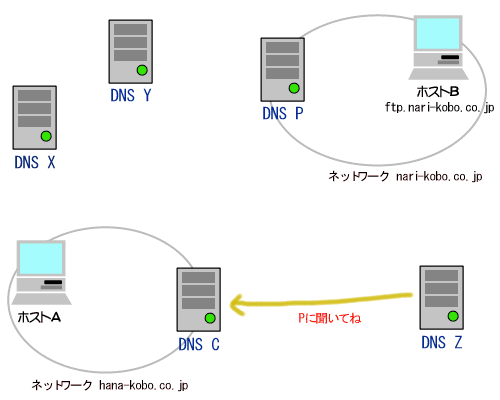
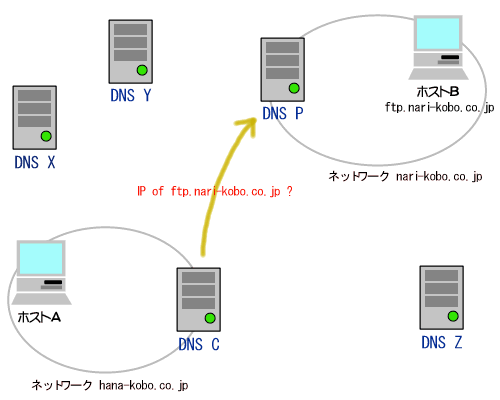
それは、一言でいってしまうと「代理のテクニック」です。以下の図を見てください。
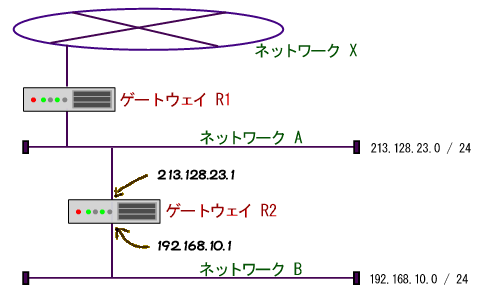
ネットワークXはインターネットに繋がっているとします。この場合、ネットワークBはインターネットに物理的に繋がっている位置関係にあります。
したがって、もしネットワークBの端末がインターネットのどこかの端末に直接アクセスした場合、必ずネットワークBの端末のIPアドレスがインターネット側に漏れてしまうので、ネットワークBではプライベートアドレスを使用することはできません。
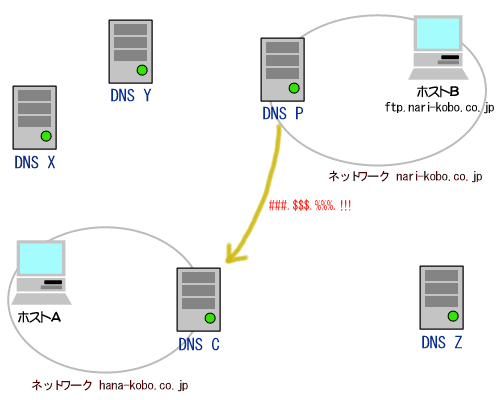
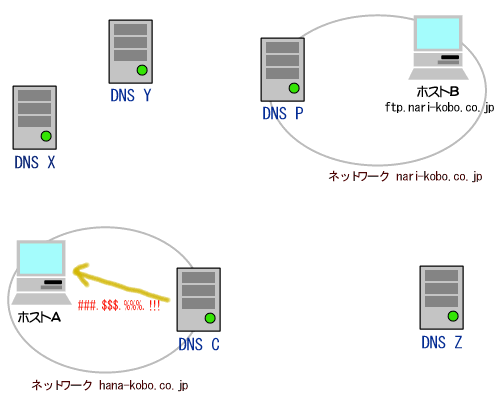
ところが、もし、ルータR2がネットワークBの端末の代理を常にしてくれるとしたらどうでしょうか。つまり、ネットワークBの端末Pがインターネットのある端末Qにアクセスしたい場合に、P自身ではなくてR2がQにアクセスし、その通信内容をR2がPに転送するようにした場合はどうかということです。
実はこの場合、ネットワークBはプライベートアドレスを使用できることになります。なぜなら、インターネット側にはPのIPアドレスが一切流れないからです。Qと通信しているのはPではなく、あくまでもR2だからです。インターネット側にはR2のIPアドレス(213.128.23.1)しか流れないのです。勿論、Q自身にも通信相手が実はPであるとは分かりません。Qから見た場合、自分はR2と通信しているとしか認識できないためです。
このテクニックは「IPマスカレード」あるいは「NAT」と呼ばれます。このテクニックを用いれば、プライベートアドレスをインターネットと物理的に接続されれているネットワークでも使用できるようになります。
また、これにより1つのIPアドレス(非プライベートアドレス)を仮想的に複数の端末に割当てたような効果を与えることができます。
|
|
ミニ解説: ネットワークアドレスとブロードキャストアドレス
NICから割当てられたIPアドレスであろうとプライベートアドレスであろうと、それらのIPアドレスのうち「ホスト部のビットが全て1となるIPアドレス」と「ホスト部のビットが全て0となるIPアドレス」はその用途が以下のとおり予約されています。
・ホスト部のビットが全て1となるIPアドレス
ブロードキャストアドレスと呼ばれる。そのネットワークに含まれる全ての端末を指定したことになるアドレス。
・ホスト部のビットが全て0となるIPアドレス
ネットワークアドレスと呼ばれる。そのネットワーク自身を指すアドレス。特定の端末を指すことはできない。
|
|
|