 |
 |
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
|
|
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
Ultra Monkey 解説のはじめに「RedHat Enterprise Linux 4 と Fedora Core 5 で検証した」と書いた。しかし残念ながら heartbeat については実験に供する 2台目の Fedora Core 5 マシンの持ちあわせがないため、ここからの内容は RHEL4 でのみ検証したものであることをお断りしておかなければならない。よって、heartbeat のバージョンも 1.x が話題の中心となる (Fedora Core 5 でインストールされるのはバージョン 2.x)。
Linux-HA プロジェクトのオフィシャルドキュメントサイトに、"Getting Started with Linux-HA (Heartbeat)" をはじめ、優れた HOWTO がたくさんある。そちらも読むべし。
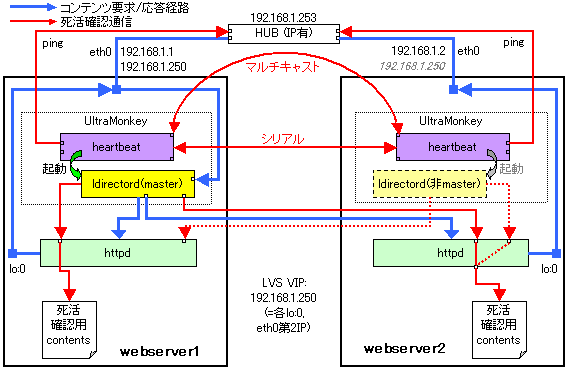
いよいよ ldirectord の二重化と httpd の負荷分散を組み合わせる仕上げの行程だ。一方の ldirectorサーバ (当例では実サーバマシンに取り込んでしまっている) に障害が起こってももう一台が LVS管理業務を肩代わりしてくれるように、その時アクティブであるべきサーバ上でのみ heartbeat が ldirectord を起動するようにする。クラスタのマスタメンバーは webserver1 の方とする。
前ページで、webserver1 には ldirectord を配備した。ここから先へ読み進む前に、webserver2 にも配備しておいてほしい。その際、今度は ldirectord が webserver2 でも動くわけなので、 ARP応答仕様の修正で述べた「IPフォワードの設定」は webserver2 にも施さなくてはいけない。
また、ホスト名がリゾルブできること (この例で言うと webserver1 => 192.168.1.1, webserver2 => 192.168.1.2) が動作の大前提となるので、この 2台の他に内部 DNSサーバも立てておく必要がある。djbdns を使えば至って簡単で占有リソースも少ない。
heartbeat どうしが互いの状態を通信し合う経路は、必ず 2本以上用意しなければならない。図のシリアルと LAN のように、種類の異なるものを併用すれば確実性が高まる。また、LAN ハートビートは、ネットワークカードが余分に用意できるなら、クロスケーブルでマシンどうしを直結したハートビート専用経路も仕掛けておくとさらに確実だ。
heartbeat の設定に関わるファイルは 3つで、いずれも /etc/ha.d/ にある。
| ファイル | 説明 |
| ha.cf | heartbeatどうしの通信や異常検出に使用する経路 (イーサネットかシリアルか等) と方法、クラスタメンバサーバの指定など、heartbeatの動作の基本を定義するファイル。 |
| haresources | クラスタの提供するサービスや、そのサービスのデフォルトオーナーはどのサーバなのかを定義するファイル。ここでいうサービスとは、障害/復帰を検知した時に何を停止/起動するのかという定義で、当例においては ldirectord (だけではないが) の起動/停止を指すことになる。 |
| authkeys | heartbeatどうしが情報を遣り取りする際にパケットに署名を行うための秘密キーを定義。 |
logfacility local0 debug 0 keepalive 2 deadtime 10 warntime 5 initdead 120 mcast eth0 225.0.0.1 694 1 0 serial /dev/ttyS1 auto_failback off node webserver1 node webserver2 ping 192.168.1.253 respawn hacluster /usr/lib/heartbeat/ipfail
| ディレクティブ | 説明 |
| logfile, debugfile, logfacility |
logfacility だけを指定すると、通常ログメッセージ, デバグメッセージとも syslog に送られる。 logfacility を指定しないと、logfile で定義したファイルと debugfile で定義したファイルに heartbeat が自らログを出力する。後者の場合で、 logfile, debugfile のうち定義されていない方 (両方未定義なら両方) は、デフォルトのファイルへ出力される。デフォルトのログファイルパスは、標準ログが /var/log/ha-log, デバグログは /var/log/ha-debug らしい。 logfacility を指定したら syslogd の設定を。 |
| debug | デバグレベル。デフォルトでも 0 (最小) らしいが、念のため設定しておく。 |
| keepalive | 死活監視の間隔。上記のように数字だけで指定した場合は単位は秒。 1500ms のようにミリ秒で指定することもできる。 |
| deadtime | 「ホストが死んでいる」と判定を下すまでの猶予時間。単位に関しては keepalive 同様。非常に重要。後述の「deadtimeチューニング」参照。 |
| warntime | ログに "late heartbeat" (ノードからの死活の返事が遅い) との警告を書くまでのしきい値。deadtime の調整に活用できる。単位に関しては keepalive 同様。 |
| initdead | heartbeat の起動直後だけは、deadtime の代わりにこの値が使用される。ネットワークの立ち上がりの遅い OS やマシンのための猶予期間だ。少なくとも deadtime の 2倍以上するのがセオリー。単位に関しては keepalive 同様。 |
| udpport | (例には不記載) 後述の bcast および ucast で heartbeat通信に使用する UDPポート。省略時はデフォルトの 694 となる。 |
| bcast | heartbeat通信にブロードキャストを用いる場合に使用。値にはネットワークインターフェイスを指定する。`bcast eth0 eth1' のように複数のインターフェイスを指定することも可能。 |
| mcast | heartbeat通信にマルチキャストを使用する場合に指定。書式は; mcast {DEV} {MCAST_ADDR} {PORT} {TTL} {LOOP_FLAG} MCAST_ADDR部: 224.0.0.0~239.255.255.255 のうち他の用途に使用されていないもの。うまくいかない時は推奨値である 239.X.X.X を指定してみるといいかもしれない。全てのノードで同一にすること。 PORT部: udpportディレクティブで指定したポート (または省略時の 694) を指定。 TTL部: マルチキャストパケットが必要以上に遠くへ流れないよう最大ホップ数を指定。heartbeatどうしは普通同じセグメントにあるので通常は 1。 LOOP_FLAG部: 0 (無効) または 1 (有効)。有効にすると「投げたマルチキャストパケットをそれと同じインターフェイスで再び受け取る」と説明されているがどういう活用法があるのか未知。通常は 0 (無効)。 |
| ucast | heatbeat通信にユニキャストを使用する場合に指定。書式は; ucast {DEV} {PEER_IP_ADDR} |
| baud | serialハートビート通信時のボーレート。省略時のデフォルトは 19200 のようだ。 |
| serial | heartbeat通信にシリアル(ヌルモデム) を使用する場合に指定。書式は; serial {DEV} 先に挙げた例では、ひとつ目のシリアルポートは UPS で占有されていると仮定して、ふたつ目のシリアルポートを指定している。シリアル通信のテスト方法を後述する。 |
| auto_failback | 図のように webserver1 がマスターメンバだとすると、値が on (有効) ならば、webserver1 に障害が起きて webserver2 がアクティブになった後、もしも webserver1 が復活したら webserver2 はサービスを webserver1 に再び明け渡す。ipfailプラグインを機能させるためには、on にせよ off にせよ、とにかくこのディレクティブは書いておく必要がある。 |
| node | heartbeatクラスタメンバ (自分も含めて)。例では webserver1 などとしたが、ホスト名は `uname -n` で出力されるものと一致していなければならず、普通は webserver1.hoge.local のような名前を指定することになるだろう。 |
| ping | 自身およびネットワーク経路の健常性を確認するために定期的に ping を行う。これは ipfail プラグインの提供する機能だ。ふたつ以上のノードへ pingテストを行うには書き方がふたつあり; ping node1 node2 でもいいし、 ping node1 ping node2 と別々に書いても同義で、いずれかひとつの ping先が不通になると失敗となり ipfail プラグインが主副ノードの交代をトリガーする。ping試験を使用する場合には、マシンと物理的に直結つながっているネットワークデバイス (L2スイッチなど) のアドレスを指定するのが最も堅実。アドレスの持てないハブなどを介している場合にはゲートウェイのアドレスを指定してもいい。下記 ping_group も参照。 |
| ping_group | (例では不使用) ping node1 node2 ... のように指定し、複数のノードへ ping試験を行う。ping ディレクティブとの違いは、いずれかひとつのノードへでも ping が成功している限り失敗とはみなされないこと。上記同様これも ipfail プラグインによってもたらされる機能。 |
| respawn ... | heartbeatデーモンとともに開始/停止するプログラム。第1引数はそのプログラムの実行ユーザ。プログラムが ipfail の場合は、heartbeat をインストールした時に作られるhacluster というUNIXユーザを使用することが推奨されている。ipfail は、ping 試験に基づいてのノード切り替え機能を提供するプラグイン。CRM (次項目参照) を利用して 3台以上のノードによる heartbeatクラスタを構築する場合には、ipfail の代わりに pingd プラグインを使うべきらしい。なお、指定したプログラムがコード 100 で EXIT した場合には、そのプログラムは respawn されず終息したままとなる。 |
| crm | 例では使用していないが How to install Ultra Monkey LVS in a 2-Node HA/LB Setup on CentOS/RHEL4 の例で記述されているので触れておく。 CRM とは ClusterResourceManager のことだそうで、heartbeat 2.0 から盛り込まれた、 3台以上のマシンによる heartbeatクラスタ構成を可能にするための集中管理型設定方式を、使う (yes) か使わない (no) か。heartbeat 1.x はこのディレクティブを知らないので 1.x で使うとエラーになる。 |
下記は heartbeat のソースに付属している doc/faqntips.html に挙げられている FAQ "How to tune heartbeat on heavily loaded system to avoid split-brain" (高負荷なシステムでスプリットブレインを防止するためのチューニング方法) を訳したもの。同ドキュメントは、heartbeat を RPM でインストールした場合には /usr/share/doc/heartbeat-X.X.X/ 下にコピーされているはずだ。スプリットブレインおよびネットワークパーティションとは、クラスタメンバーの中の複数のマシンが死活確認方法を失い、互いの状態が分からなくなってリソースを同時に活性化させてしまったり同時に止めてしまう現象を言う。
負荷の高い時に "No local heartbeat" (ローカルハートビート消失) または "Cluster node returning after patition" (ネットワークパーティション現象から復帰) というログメッセージが出力されることがある。これは deadtime の設定値が小さすぎることに起因している場合が多い。deadtime のチューニング方法を紹介しておこう:
一般論として、マシンにメモリを足すのも解決策のひとつとなる。また、マシンの動作負荷を減らすのもひとつの方策だ。この種の現象は、1.0 系の古い heartbeat よりも、新しいバージョンの heartbeat のほうが発生しにくくなっている。
このファイルの内容はクラスタの全ノードで同一でなければならない。
webserver1 \
ldirectord::ldirectord.cf \
LVSSyncDaemonSwap::master \
IPaddr2::192.168.1.250/24/eth0/192.168.1.255
各行末にバックスラッシュがあることから分かるように、文言は 1行から成っている。(ワープロ的な意味での) 2行目以降はインデントしてあるが、そうしなければならないという規則は特にない。
| 書式または記述例 | 説明 |
| webserver1 | クラスタのマスターノード。このサーバ名は、マスターノード上での `uname -n` で得られるホスト名と一致しなくてはならない。つまり、ha.cf で定義した node のいずれかひとつと一致しているはずだ。 |
| [リソースの一般論] PROG::ARG::ARG... |
マスターノードの後に続くものは、スペースで区切られたひとつひとつがクラスタのリソースであり、全リソース (論理上の 1行) をまとめてリソースグループと呼ぶ。リソースとは、ノード上で heartbeat が活性化した時に一緒に起動され、非活性になった時に他のノードに引き渡されるプログラムや資源のこと。 リソースの起動順序は左から右の順 (例のようにバックスラッシュエスケープした状態で言うと上から下)、停止順序は右から左 (下から上) の順となる。複数のリソースグループを定義した場合には、ノードが切り替わる際は一番上に書かれたリソースグループから順次引き継ぎが行われるが、リソースグループどうしは関連性や依存関係のあるものとして扱われるわけではないので、起動時も停止時も上から下となる。 左記のように書式を普遍化して PROG::ARG... で表したとすると、プログラム PROG が、活性化時には `PROG ARG ARG start' で呼ばれ、非活性化時には `PROG ARG ARG stop' という具合に呼ばれることになる。 PROG はまず /etc/ha.d/resource.d/ で探され、次に /etc/init.d/ で探される。 |
| ldirectord::ldirectord.cf | /etc/ha.d/resource.d/ldirectord を引数 ldirectord.cf を付けて起動することを表す。ldirectord は/usr/sbin/ldirectord つまり ldirectord デーモン実行ファイルへのシンボリックリンク。 |
| LVSSyncDaemonSwap::master | /etc/ha.d/resource.d/LVSSyncDaemonSwap は、リソースの引き渡し時に、既にセッション開始済みのクライアントコネクションを、切断せずにノード譲渡するための LVSデータ同期デーモンのコントロールスクリプト。引数 `master start' でコールすると、マスターとして定義されている LVS ホストを活性化し非マスターのほうを停止する。 `master stop' でコールすると、マスターを停止して非マスターを活性化する。LVSSyncDaemonSwap は Ultra Monkey として使用する上においては今のところ必要だが、ipvsadm を直に使用する場合は、本来、カーネル 2.4.27 以降ならば不要だそうで、代わりに master役と backup役の LVSデータ同期デーモンを各ノードで両方とも立ち上げておけばいいのだという (ipvsadm --start-daemon master; ipvsadm --start-daemon backup)。カーネル 2.4.26以前の LVSフレームワークでは master役と backup役を同時に立ち上げることができなかった。 |
| IPaddr2::192.168... | /etc/ha.d/resource.d/IPaddr2 は、仮想IPアドレスを発生させるスクリプト。IPaddr2 の引数書式は; IPaddr2 ip_addr[/netmask[/iface[:label][/bcast]]] ネットマスク以降は省略も可能だが、その場合、heartbeat はルーティングテーブルを参照して最も妥当と思われるインターフェイスに副IPアドレスを付与しようとする。やや不確実だ。 当然ながら、最後に start を付けて呼ぶと ip_addr を起こし、 stop では削除する。古いドキュメントでは IPaddr2 でなく IPaddr が使われている例を目にするが、今や、特段の事情でもない限り IPaddr のほうを使う理由はない。双方の大きな違いは次の点だ; ・IPaddrは仮想IPの発生にifconfigを使い、ネットワークエイリアスとして生成する。 ・IPaddr2はiproute2を使い、副IPアドレスをifaceに直接付加する。(※) |
※ この点により、IPaddr2 で発生された仮想IPアドレスは ifconfig コマンドでは表示されないことがある。確実に表示させるには iproute2 のコマンドを使用して、
root# ip addr show
とする。
発信する heatbeat通信パケットにサインするための秘密キーを定義するファイル。内容は、クラスタに属する全ノードで同じでなくてはならない。ファイルパーミションは必ず root:root 600 とすること。
auth 1 1 sha1 thisIsMySecret
普遍化すると;
auth {key_number} {key_number} {auth_method} {key}
前ページでテスト用に公開用VIP を手動作成した場合は、それをを削除しておく;
root# ip addr del 192.168.1.250/32 dev eth0
また、前ページで ifcfg-eth0:0 を作ったままの人はそれも無効にしなくてはいけない;
root# ifdown eth0\:0 root# rm /etc/sysconfig/network-scripts/ifcfg-eth0\:0
当ページの実装法では、ldirectord は heartbeat によって適宜起動されるのでスタートアップ起動されてはいけない。両 webserver とも;
root# chkconfig --del ldirectord root# chkconfig --add heartbeat root# chkconfig heartbeat on (念のため)
実際に稼働させる。これも両ノードで。
root# service ldirectord stop (両ノードでやってから下行へ) root# service heartbeat start (先に webserver1, 次に webserver2 で行う)
いろいろな状態確認コマンドとその出力の抜粋を以下に示す。
root# ip addr show (webserver1上にて) <現在マスターなので、VIP 192.168.1.250 が eth0 の副IP になっている> 2: eth0: <BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast qlen 100 link/ether 00:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0 inet 192.168.1.250/24 brd 192.168.1.255 scope global secondary eth0 root# ip addr show (webserver2上にて) <現在マスターではないので、VIP 192.168.1.250 がループバックのエイリアスになっている> 1: lo: <LOOPBACK,UP> mtu 16436 qdisc noqueue link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 brd 127.255.255.255 scope host lo inet 192.168.1.250/32 brd 192.168.1.255 scope global lo:0
root# ldirectord /etc/ha.d/ldirectord.cf status (webserver1上にて) ldirectord for /etc/ha.d/ldirectord.cf is running with pid: xxx root# ldirectord /etc/ha.d/ldirectord.cf status (webserver2上にて) ldirectord is stopped for /etc/ha.d/ldirectord.cf
root# ipvsadm -L -n (webserver1上にて) <ldirectord が活性化され管理ノードになっているのでロードバランステーブルが表示される> IP Virtual Server version 1.x.x (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.1.250:80 wrr persistent 600 -> 192.168.1.2:80 Route 1 0 0 -> 192.168.1.1:80 Local 1 0 0 root# ipvsadm -L -n (webserver2上にて) <ldirectord が非活性であり管理ノードではないのでロードバランステーブルは空> IP Virtual Server version 1.x.x (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn
root# /etc/ha.d/resource.d/LVSSyncDaemonSwap master status (webserver1上にて) master running (ipvs_syncmaster pid: xxxx) root# /etc/ha.d/resource.d/LVSSyncDaemonSwap master status (webserver2上にて) master stopped
運用しだしたら、通常の確認は ipvsadm -L -n だけでいいだろう。また、前ページで紹介した cluster スクリプトも、heartbeat を実装した今なら満足に働いてくれる。ただし、cluster スクリプトは、
という点に注意して使って頂きたい。