文字列全体を変換する関数は用途によっていろいろあります。代表的なものは次のサンプルを見て下さい。
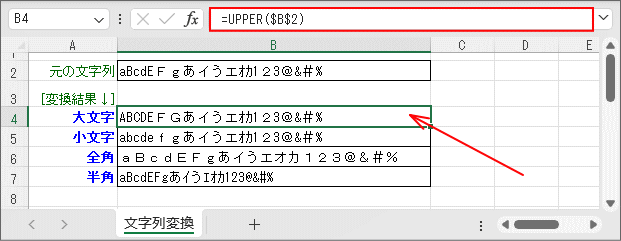
- 文字列を「大文字」に変換します。(4行目)
-
(画像をクリックすると、このページのサンプルがダウンロードできます)
大文字変換は「UPPER関数」です。作用対象は「英字」であり、カナ・かな、数字、記号は影響を受けません。
なお、「g⇒G」のように全角の英字は全角のまま大文字になります。
関数 概略説明 UPPER関数 文字列を大文字に変換します。 引数は変換元の文字列です。
- 文字列を「小文字」に変換します。(5行目)
-
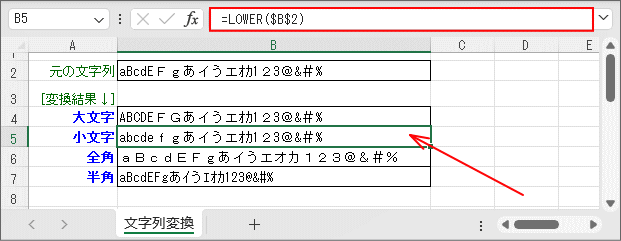
小文字変換は「LOWER関数」です。作用対象は「英字」であり、カナ・かな、数字、記号は影響を受けません。
なお、「F⇒f」のように全角の英字は全角のまま小文字になります。
関数 概略説明 LOWER関数 文字列を小文字に変換します。 引数は変換元の文字列です。
- 文字列を「全角」に変換します。(6行目)
-
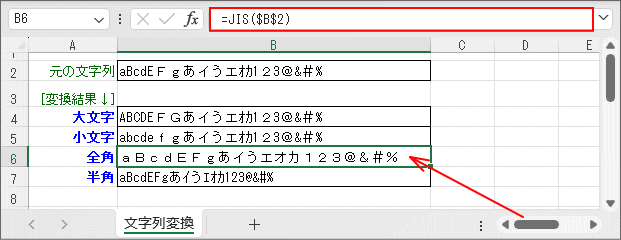
全角変換は「JIS関数」です。作用対象は「半角文字」であり、既に全角になっている文字は影響を受けません。
半角/全角混在の文字列は全て全角で統一されることになります。
関数 概略説明 JIS関数 文字列内の半角(1バイト)の英数カナ文字を全角(2バイト)の文字に変換します。 引数は変換元の文字列です。
- 文字列を「半角」に変換します。(7行目)
-
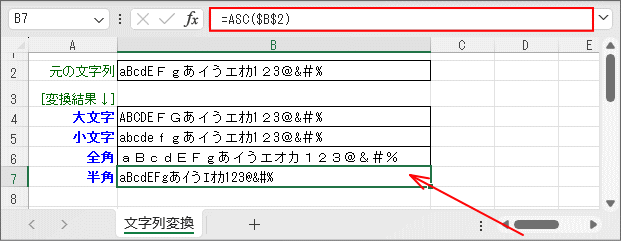
半角変換は「ASC関数」です。作用対象は「半角に変換できる全角文字」であり、既に半角になっている文字は影響を受けません。
全角文字でも「漢字」「ひらがな」は半角に変換できないので変換されません。このため、結果が半角に統一されない場合があります。
関数 概略説明 ASC関数 全角(2バイト)文字を半角(1バイト)文字に変更します。 引数は変換元の文字列です。
文字列から特定文字を見つけて、何文字目か判断したり、他の文字に置き換えるサンプルです。
- 特定文字を指定して別の文字に全て置き換えます。(4行目)
-
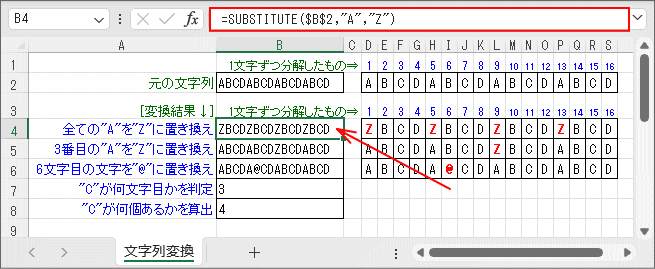
「元の文字列」は16文字ありますが、どの文字が置き換わったか見にくいので、右側に1文字ずつ分解したものを用意して、 置き換わった桁位置の文字は赤太字にしてあります。
探し出しでの文字の置き換えには「SUBSTITUTE関数」を使います。 このサンプルでは「元の文字列」から全ての「A」を探し出して「Z」に置き換えています。 「置換対象(第4引数)」を省略しているので、「全て」が対象になります。
関数 概略説明 SUBSTITUTE関数 対象文字列内の検索文字(文字列)を置換文字(文字列)に置き換えます。
引数は以下の通りです。
① 対象文字列
② 検索文字(文字列)
③ 置換文字(文字列)
④ 置換対象(省略可、省略した場合はすべての文字列が対象になります)
- n番目に見つかった指定文字を別の文字に置き換えます。(5行目)
-
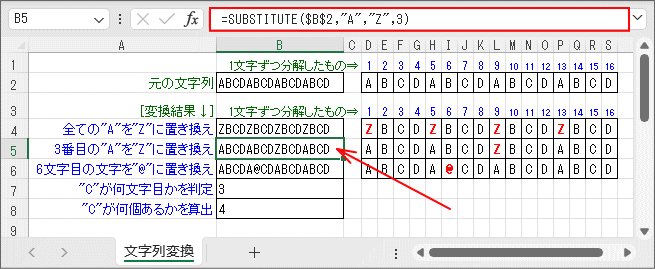
探し出しでの文字の置き換えには「SUBSTITUTE関数」を使います。 このサンプルでは「元の文字列」から「3番目」の「A」を探し出して「Z」に置き換えています。 「置換対象(第4引数)」で「3」を指定しています。
- n文字目(直接位置)の文字を別の文字に置き換えます。(6行目)
-
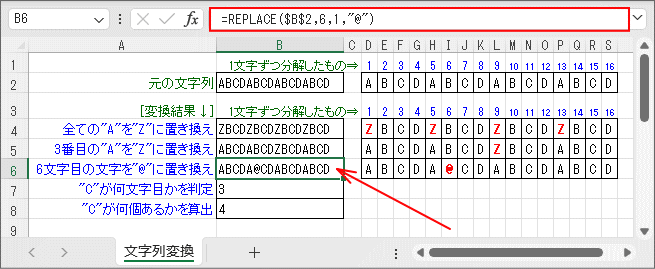
直接位置での文字の置き換えには「REPLACE関数」を使います。 このサンプルでは「元の文字列」から「6文字目」の「1文字」を「@」に置き換えています。
関数 概略説明 REPLACE関数 文字列に含まれる、指定された文字位置・文字数の文字を別の文字に置き換えます。
引数は以下の通りです。
① 対象文字列
② 開始位置
③ 文字数
- 指定文字が何文字目にあるかを判定します。(7行目)
-
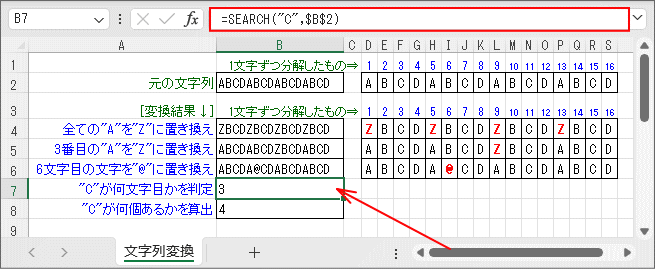
検索文字の文字位置判定は「SEARCH関数」を使います。 このサンプルでは「元の文字列」から「C」が最初に見つかる文字位置を判定しています。
関数 概略説明 SEARCH関数 指定された検索文字(文字列)を対象文字数から検索して見つかった文字位置を返します。
引数は以下の通りです。
① 検索文字(文字列)
② 対象文字列
③ 開始位置(省略可、省略した場合は先頭から検索します)
※SEARCH関数では大文字と小文字は区別されません。 大文字と小文字を区別する場合はFIND関数を使います。
FIND関数 指定された検索文字(文字列)を対象文字数から検索して見つかった文字位置を返します。
引数は以下の通りです。
① 検索文字(文字列)
② 対象文字列
③ 開始位置(省略可、省略した場合は先頭から検索します)
※FIND関数では大文字と小文字が区別されます。 大文字と小文字を区別しない場合はSEARCH関数を使います。
- 指定文字が何個あるかを算出します。(8行目)
-
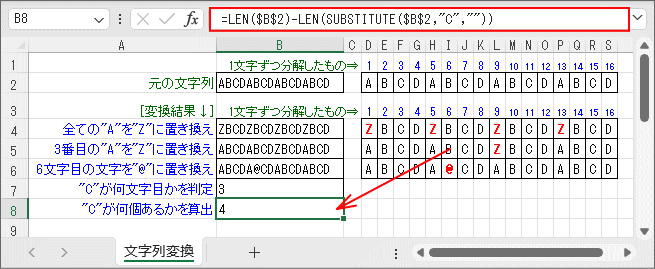
文字列中に「指定文字が何個あるか」を簡単に算出できる関数はありません。 近年では新しい関数もかなり追加されていますが、未だにないようです。 但し、方法が無いわけではありません。
算出方法は、
となります。このサンプルでは、= [元の文字列]の文字数 - [指定文字を取り除いた文字列]の文字数
となります。=LEN($B$2)-LEN(SUBSTITUTE($B$2,"C",""))
「LEN関数」が2つ使われていますが、左の方は単に「元の文字列」の文字数を算出しており、 右の方が「指定文字を取り除いた文字列」の文字数(残りの文字数)を算出しています。
「指定文字を取り除いた文字列」というのは「SUBSTITUTE関数」で「元の文字列」の中から「C」を探して「空文字("")」に置き換えています。 「空文字("")」というのはその文字を消去したのと同じで文字数のカウントに加算されなくなるということです。
関数 概略説明 LEN関数 文字列の文字数を算出します。引数は対象となる文字列です。