![]()
【注意】 このドキュメントは、W3CのRDF Primer W3C Recommendation 10 February 2004の和訳です。
このドキュメントの正式版はW3Cのサイト上にある英語版であり、このドキュメントには翻訳に起因する誤りがありえます。誤訳、誤植などのご指摘は、訳者までお願い致します。
First Update: 2005年9月27日
このドキュメントに対する正誤表を参照してください。いくつかの規範的な修正が含まれているかもしれません。
翻訳版も参照してください。
Copyright © 2004 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply.
RDF(Resource Description Framework)は、WWW上で資源に関する情報を表現するための言語です。この入門書は、RDFを効果的に利用するために必要な基礎知識を読者に提供するために考案されました。RDFの基本概念を紹介し、XML構文について記述しています。RDF語彙記述言語を用いてRDF語彙を定義する方法を記述し、一部の導入済みRDFアプリケーションの概要を提供します。また、他のRDF仕様ドキュメントの内容と目的について説明します。
このドキュメントは、W3Cメンバーおよび他の利害関係者によりレビューされ、W3C勧告として管理者の協賛を得ました。勧告の作成におけるW3Cの役割は、仕様に注意を引き付け、広範囲な開発を促進することです。これによってウェブの機能性および相互運用性が増強されます。
本ドキュメントは、以前のRDF仕様、RDFモデルおよび構文(1999年勧告)、RDFスキーマ(2000年勧告候補)を同時に置き換えることを目的とする一連の6つ(入門、概念、構文、セマンティクス、語彙、およびテストケース)のうちの1つです。これは、2004年2月10日の公開に向けてW3Cセマンティック・ウェブ・アクティビティ(アクティビティ声明、グループ憲章)の一部としてRDFコア・ワーキンググループによって開発されてきたものです。
勧告案草案以後のこのドキュメントに対する変更の詳細は、変更履歴に記述されています。
一般の方々はコメントをwww-rdf-comments@w3.org(アーカイブ)に送り、www-rdf-interest@w3.org(アーカイブ)における関連技術の一般的な議論に参加してください。
実装のリストが利用可能です。
W3Cは、この事業に関するあらゆる特許の開示のリストを維持します。
この項は、このドキュメントの公開時のステータスについて記述しています。他のドキュメントがこのドキュメントに取って代わることがありえます。現行のW3Cの刊行物および技術報告の最新の改訂版のリストは、http://www.w3.org/TR/のW3C技術報告インデックスにあります。
1. はじめに
2. 資源に関するステートメントの作成
2.1 基本概念
2.2 RDFモデル
2.3 構造化されたプロパティー値と空白ノード
2.4 型付きリテラル
2.5 概念の要約
3. RDFのXML構文: RDF/XML
3.1 基本原理
3.2 RDF URIrefの省略と組織化
3.3 RDF/XMLの要約
4. その他のRDFの性能
4.1 RDFコンテナ
4.2 RDFコレクション
4.3 RDFの具体化
4.4 構造化された値: rdf:valueに関する詳細
4.5 XMLリテラル
5. RDF語彙の定義: RDFスキーマ
5.1 クラスの記述
5.2 プロパティーの記述
5.3 RDFスキーマ宣言の解釈
5.4 その他のスキーマ情報
5.5 より豊かなスキーマ言語
6. RDFアプリケーションの一部: 現在のRDF
6.1 ダブリン・コア・メタデータ・イニシアティブ
6.2 PRISM
6.3 XPackage
6.4 RSS 1.0: RDFサイト・サマリー
6.5 CIM/XML
6.6 遺伝子オントロジー・コンソーシアム
6.7 機器性能とユーザ嗜好の記述
7. RDF仕様のその他の部分
7.1 RDFセマンティクス
7.2 テストケース
8. 参考文献
8.1 規範的な参考文献
8.2 参考情報の参考文献
9. 謝辞
A. URI(Uniform Resource Identifier)に関する詳細
B. XML(Extensible Markup Language)に関する詳細
C. 変更
RDF(Resource Description Framework)は、WWW上で資源に関する情報を表わすための言語です。タイトル、著者、ウェブ・ページの更新日、ウェブ・ドキュメントの著作権およびライセンス情報、ある共有資源に対する利用可能スケジュールなどのような、ウェブ資源に関するメタデータの表現を特に目的としています。しかし、RDFは、「ウェブ資源」の概念を一般化することにより、ウェブでは直接検索できないけれどもウェブで識別できる事物に関する情報を表わすために使用できます。例には、オンライン・ショッピング機能で入手できるアイテムに関する情報(例えば、仕様、価格、および入手可能性に関する情報)や、情報発信に対するウェブ・ユーザの嗜好に関する記述が含まれています。
RDFは、人間に表示するだけではなく、アプリケーションが情報を処理する必要のある状況を目的としています。RDFは、この情報を表現するための共通の枠組みを提供するため、意味を損なわずにアプリケーション間で情報交換が行えます。共通の枠組みであるため、アプリケーションの設計者は共通のRDFパーサや処理ツールを有効利用できます。異なるアプリケーション間で情報交換できるということは、情報が元々作成された以外のアプリケーションでその情報を利用できることを意味します。
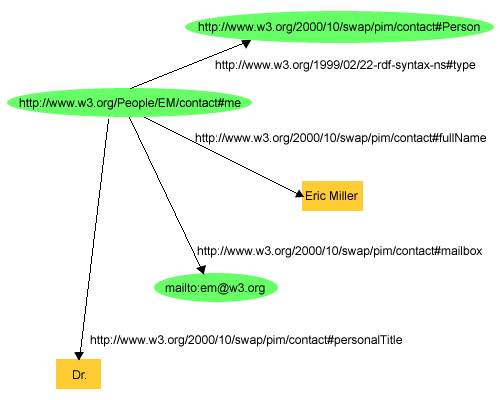
RDFは、ウェブ識別子(Uniform Resource Identifier(URI)と呼ばれる)を使用して事物を識別し、シンプルなプロパティーとプロパティー値で資源を記述するという考えに基づいています。これによって、資源を表わすノードとアークのグラフや、そのプロパティーと値として、資源に関するシンプルなステートメントを提供できるようになります。できる限り早くこの議論をより具体的にするために、「名前がEric Millerであり、Eメール・アドレスがem@w3.orgであり、博士の称号を持つ、http://www.w3.org/People/EM/contact#meで識別される人物」というステートメントのグループは、図1のRDFグラフのように表わすことができます。
図1では、以下を識別するためにRDFがURIを使用していることを示しています。
http://www.w3.org/People/EM/contact#meで識別されるEric Millerhttp://www.w3.org/2000/10/swap/pim/contact#Personで識別される人物http://www.w3.org/2000/10/swap/pim/contact#mailboxで識別されるメールボックスmailto:em@w3.org(RDFは、プロパティーの値として、「Eric Miller」などの文字列や、整数や日付などのその他のデータ型の値を使用する)RDFは、これらのグラフを記録し、交換するためのXMLベースの構文(RDF/XMLと呼ぶ)も提供します。 例1は、図1のグラフに対応するRDF/XMLのRDFの小さな一部分です。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#">
<contact:Person rdf:about="http://www.w3.org/People/EM/contact#me">
<contact:fullName>Eric Miller</contact:fullName>
<contact:mailbox rdf:resource="mailto:em@w3.org"/>
<contact:personalTitle>Dr.</contact:personalTitle>
</contact:Person>
</rdf:RDF>
mailboxとfullName(省略形の)、そのそれぞれの値em@w3.org、およびEric Millerのようなプロパティーと同様に、このRDF/XMLもURIを含むことに注意してください。
HTMLと同様に、このRDF/XMLは、機械が処理でき、URIを利用してウェブ中の情報をリンクできます。しかし、従来のハイパーテキストとは異なり、RDFのURIは、ウェブで直接検索できない事物(Eric Millerという人物など)を含む、あらゆる識別可能な事物を参照できます。その結果として、RDFは、ウェブ・ページのような事物の記述に加え、車、ビジネス、人、ニュースなども記述できます。 さらに、RDFプロパティー自体がURIを持っていて、リンク付けされているアイテム間に存在する関係を正確に識別します。
以下のドキュメントがRDFの仕様を提供しています。
この入門書は、情報システムの設計者とアプリケーション開発者がRDFの機能とその使用法を理解するのに役立つように、RDFへの手引きを提供し、いくつかの既存のRDFアプリケーションについて記述することを目的としています。特に、この入門書は以下のような質問に答えることを目的としています。
この入門書は非規範ドキュメントです。つまり、RDFの最終的な仕様ではありません。この入門書の例やその他の説明資料は、RDFの理解に役立つように提供されていますが、常に最終的または完全な答えを提供するとは限りません。このような場合には、RDF仕様の関連する規範部分を参考にすべきです。これが容易になるように、この入門書では、議論の適切な場所で、これらの他のドキュメントがRDFの完全な仕様で果たす役割を記述し、規範仕様の関連部分を指し示すリンクを提供しています。
また、これらのRDFドキュメントが、以前に公開されたRDF仕様である、RDFモデルおよび構文仕様[RDF-MS]、およびRDFスキーマ仕様1.0[RDF-S]を更新し、明確化していることにも注意するべきです。その結果、用語、構文、および概念にいくつかの変更がありました。この入門書は、上記で引用したRDFドキュメントの黒丸付きリストで提供されている、より新しいRDF仕様を反映します。したがって、旧仕様およびそれに基づく以前のチュートリアルや紹介記事に慣れ親しんでいた読者は、現行仕様とこれらの旧ドキュメントの間に違いがありえることを承知しているべきです。旧RDF仕様に関して提起された問題のリスト、および現行仕様でのその解決策に関しては、RDF問題追跡ドキュメント[RDFISSUE]を参考にすることができます。
RDFは、ウェブ・ページなどの、ウェブ資源に関するステートメントを作成する簡単な方法を提供することを目的としてます。この項では、RDFがこれらの性能を提供する方法の背景となる基本的な考え方について記述します(これらの概念を記述する規範仕様は、RDF概念および抽象構文[RDF-CONCEPTS]です)。
John Smithという名前の誰かが特定のウェブ・ページを作成したと述べようとしていると想像してみてください。英語などの自然言語でこれを簡単に述べると、以下のようなシンプルなステートメントの形式になるでしょう。
http://www.example.org/index.html
has a creator whose value is John Smith
事物のプロパティーを記述するためには、以下のようないくつかの事物を命名または識別する方法が必要であることを示すために、ステートメントの一部を強調しています。
このステートメントでは、ウェブ・ページを識別するためにURL(Uniform Resource Locator)を使用しています。さらに、プロパティーを識別するために「creator」という単語を、事物(人)を識別するために「John Smith」という2つの単語を使用しています。
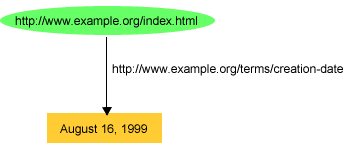
このウェブ・ページの他のプロパティーは、ページを識別するためにはURLを、プロパティーとその値を識別するためには単語(または、他の表現)を使用し、同じ一般形式の英語のステートメントを追記することによって記述できます。例えば、ページが作成された日付(creation-date)とページが書かれた言語(language)は、ステートメントを追加して以下のように記述できます。
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
RDFは、記述されている事物には値を持つプロパティーがあり、上記と同様に、これらのプロパティーと値を指定するステートメントを作成することによって資源を記述できるという考えに基づいています。RDFでは、ステートメントの様々な部分に関して述べるために特別な用語を使用します。特に、ステートメントが述べている事物を識別する部分(この例では、ウェブ・ページ)を主語と呼びます。ステートメントが指定する主語(これらの例では、作者や作成日、言語)のプロパティーや特性を識別する部分を述語と呼び、そのプロパティーの値を識別する部分を目的語と呼びます。したがって、英語のステートメントは以下のようになります。
http://www.example.org/index.html
has a creator whose value is John Smith
このステートメントの各部分のRDF用語は以下の通りです。
http://www.example.org/index.htmlというURLしかし、英語は(英語を話す)人の間でコミュニケーションをとるのには有効ですが、RDFは機械が処理できるステートメントを作成しようとしているのです。この種のステートメントを機械が処理するのに適したものにするためには、以下の2つが必要です。
幸い、既存のウェブ・アーキテクチャは、これらの必要な機能を両方とも提供してくれます。
先に示したように、ウェブは、既にURL(Uniform Resource Locator)という、識別子の1つの形式を提供しています。最初の例では、John Smithが作成したウェブ・ページを識別するためにURLを使用しました。URLは、主要なアクセスのメカニズム(基本的に、そのネットワーク上の「位置」)を表現することによってウェブ資源を識別する文字列です。しかし、ウェブ・ページとは異なる、ネットワーク上の位置やURLを持たない様々な事物に関する情報を記録できるということも重要です。
これらの目的のために、ウェブは、URI(Uniform Resource Identifier)と呼ばれるより一般的な形式の識別子を提供します。URLは、URIの特定の1つの種類です。すべてのURIは、異なる人や組織が事物を識別するために別個に作成し使用できるプロパティーを共有します。しかし、URIは、ネットワーク上の位置を持っていたり、他のコンピュータのアクセス・メカニズムを使用したりする事物を識別することにのみ制限されてはいません。実際、URIは、ステートメントで参照する必要があるあらゆるものを参照するために作成できます。これには以下が含まれます。
この一般性のために、RDFは、ステートメント内の主語、述語、および目的語を識別するためのメカニズムの基礎としてURIを使用します。より正確に言うと、RDFはURI参照[URIS]を使用します。末尾にオプションで付くフラグメント識別子と合わせて、URI参照(URIref)はURIです。例えば、http://www.example.org/index.html#section2というURI参照は、http://www.example.org/index.htmlというURIと、Section2という(「#」という文字で区切られた)フラグメント識別子で構成されています。RDFのURIrefは、ユニコード[UNICODE]の文字を含むことができ([RDF-CONCEPTS]を参照)、これによって多くの言語をURIrefに反映できます。RDFは資源をURI参照で識別できるものと定義しているため、URIrefを使用するとRDFは実際に何でも記述でき、そのような事物の間の関係を述べることができます。URIrefとフラグメント別子に関しては、付録Aと[RDF-CONCEPTS]で、より詳細に論じます。
機械が処理できる方法でRDFステートメントを表現するために、RDFはXML(Extensible Markup Language)[XML]を使用します。XMLは、誰もが自身のドキュメント形式を設計し、その形式でドキュメントを書くことができるようにするために設計されました。RDF情報を表現する際に使用し、それを機械間で交換するために、RDFは、RDF/XMLと呼ばれる特定のXMLマークアップ言語を定義しています。RDF/XMLの例は、第1項で示しました。その例(例1)では、それぞれEric MillerやDr.というテキスト・コンテンツを区切るために、<contact:fullName>や<contact:personalTitle>などのタグを使用しました。このようなタグによって、タグの意味を理解して書かれたプログラムがそのコンテンツを適切に解釈できるようになります。XMLコンテンツと(いくらかの例外があるが)タグの両方は、ユニコード[UNICODE]の文字を含むことができ、これによって多くの言語による情報を直接表現できるようになります。付録Bでは、一般的なXMLの背景の詳細を提供しています。RDFに使用される特定のRDF/XML構文の詳細は第3項で記述されており、[RDF-SYNTAX]で規範的に定義されています。
2.1項では、RDFのステートメントの基本概念、RDFステートメントで参照された事物を識別するためにURI参照を使用するという考え、および、RDFステートメントを表現するために機械が処理できる方法としてのRDF/XMLを紹介しました。このような背景のもと、この項では、RDFがどのようにURIを使用して資源に関するステートメントを作成するかを述べます。「はじめに」では、RDFは資源に関するシンプルなステートメントを表現するという考えに基づいており、各ステートメントは主語、述語、目的語で構成される、と述べました。RDFでは、以下の英語のステートメント
http://www.example.org/index.html
has a creator whose value is John Smith
は、以下を有するRDFステートメントで表わすことができます。
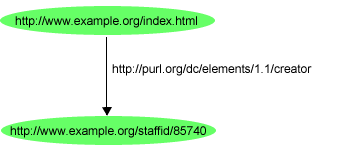
http://www.example.org/index.htmlhttp://purl.org/dc/elements/1.1/creatorhttp://www.example.org/staffid/85740最初のステートメントの主語だけではなく述語や目的語を識別するために、それぞれ「creator」や「John Smith」という語を使用する代わりに、どのようにURIrefを使用するかに注意してください(この方法でURIrefを使用した場合の効果の一部に関しては、この項の後部で論じます)。
RDFは、ステートメントをグラフ内のノードとアークとしてモデル化します。RDFのグラフのモデルは、[RDF-CONCEPTS]で定義されています。その表記では、ステートメントは以下のもので表現されます。
したがって、上記のRDFステートメントは、図2で示すグラフで表されます。
ステートメントのグループは、対応するノードとアークのグループによって表現されます。そのため、以下の英語ステートメントをさらにRDFグラフに反映させるには、
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
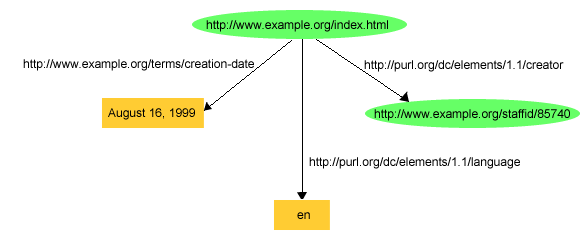
図3で示されたグラフを使用できます(適切なURIrefを使用して「creation-date」(作成日)や「language」(言語)のプロパティーを命名)。
図3では、ある種のプロパティー値を表現するためには、RDFステートメント内の目的語が、URIrefか、文字列によって表現される定数値(リテラルと呼ばれる)かのどちらかでありえることを示しています。(http://purl.org/dc/elements/1.1/languageという述語の場合、リテラルは2文字の英語の国際標準コードです。)RDFステートメントでは、リテラルを主語や述語として使用できません。RDFグラフを描く時には、URIrefであるノードは楕円で表示され、リテラルであるノードは四角で表示されます。(これらの例で使用されているシンプルな文字列のリテラルは、2.4項で紹介する型付きリテラルと区別するために、プレーン・リテラルと呼びます。RDFステートメントで使用できる様々な種類のリテラルは[RDF-CONCEPTS]で定義されています。プレーン・リテラルと型付きリテラルは両方ともユニコード[UNICODE]の文字を含むことができ、これによって多くの言語による情報を直接表現できるようになります。)
これらを議論する際にグラフを描くのが便利でないことがあるため、トリプルと呼ばれる、ステートメントを記述する別の方法も使用されます。トリプルの表記では、グラフの各ステートメントは、主語、述語、目的語の順序のシンプルなトリプルで記述されます。例えば、図3で示されている3つのステートメントは、以下のようなトリプルの表記で記述されます。
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> <http://www.example.org/staffid/85740> . <http://www.example.org/index.html> <http://www.example.org/terms/creation-date> "August 16, 1999" . <http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/language> "en" .
各トリプルは、グラフ内の1つのアークに対応し、アークの最初と最後のノード(ステートメント内の主語と目的語)を完備しています。描かれたグラフとは異なり(しかし、最初のステートメントと同様に)、トリプルの表記では、ノードは、それが表示されるステートメントごとに別々に識別される必要があります。そのため、例えば、http://www.example.org/index.htmlは、グラフのトリプル表現では3度(各トリプルで1度)表示されますが、描かれたグラフでは1度しか表示されません。しかし、トリプルは、描かれたグラフと同じ情報を表します。この点が重要で、RDFの基本は、ステートメントのグラフ・モデルであり、グラフを表したり描いたりするために使用される表記は、二次的なものです。
完全なトリプル表記では、URI参照をアングルブラケット内に完て書き出す必要があり、上例が示すように、非常に長い行になりえます。便宜上、この入門書ではトリプルの記述に省略形を使用します(他のRDF仕様でも同じ省略形が使用される)。この省略形では、アングルブラケットなしのXMLの修飾名(または、QName)を完全なURI参照の省略形として代用します(QNameに関する詳細は、付録Bで論じます)。QNameには、名前空間URIに割り当てられた接頭辞が含まれ、その後にコロン、そしてローカル名が続きます。完全なURIrefは、接頭辞に割り当てられた名前空間URIにローカル名を加えたQNameで形成されます。そのため、例えば、QNameの接頭辞fooが名前空間URI http://example.org/somewhere/に割り当てられている場合、QName foo:barがURIref http://example.org/somewhere/barの省略形ということになります。入門書の例では、以下に定める、いくつかの「よく知られている」(well-known)QName接頭辞も(毎回、明示的に指定せずに)使用されます。
接頭辞 rdf:、名前空間 URI:
http://www.w3.org/1999/02/22-rdf-syntax-ns#
接頭辞 rdfs:、名前空間 URI:
http://www.w3.org/2000/01/rdf-schema#
接頭辞 dc:、名前空間 URI:
http://purl.org/dc/elements/1.1/
接頭辞 owl:、名前空間 URI:
http://www.w3.org/2002/07/owl#
接頭辞 ex:、名前空間 URI:
http://www.example.org/(または、
http://www.example.com/)
接頭辞 xsd:、名前空間 URI:
http://www.w3.org/2001/XMLSchema#
必要に応じて、「例」の接頭辞ex:を明らかに変形したものを、例で使用します。例えば、
接頭辞 exterms:、名前空間 URI:
http://www.example.org/terms/(例示した組織が使用している用語用)、
接頭辞 exstaff:、名前空間 URI:
http://www.example.org/staffid/(例示した組織のスタッフの識別子用)、
接頭辞 ex2:、名前空間 URI:
http://www.domain2.example.org/(二番目に例示した組織用)、など。
前述のトリプルの集合は、この新しい省略形を使用して以下のように書くこともできます。
ex:index.html dc:creator exstaff:85740 . ex:index.html exterms:creation-date "August 16, 1999" . ex:index.html dc:language "en" .
RDFは、ステートメントで事物を命名するための単語の代わりにURIrefを使用するため、RDFでは1組のURIref(特に、特定の目的用の1組)を語彙と呼びます。しばしば、このような語彙のURIrefは、共通の接頭辞を使用する1組のQNameとして表現できるように組織化されています。すなわち、語彙のすべての用語に対して1つの共通の名前空間URIrefが選択されます(通常は、語彙を定義している人の管理下にあるURIref)。語彙に含まれているURIrefは、個々のローカル名を共通のURIrefの末端に追加することによって形成されます。このように、共通の接頭辞を持つ1組のURIrefを形成します。例えば、前の例で示したように、example.orgなどの組織は、「creation-date」や「product」(製品)などの、事業で使用する用語に対して接頭辞http://www.example.org/terms/で始まるURIrefで構成される語彙を定義できますし、従業員を識別するために接頭辞http://www.example.org/staffid/で始まるURIrefの別の語彙を定義できます。RDFは、これと同じアプローチを使用して、RDFで特別な意味を持つ独自の用語を定義します。このRDF語彙内のURIrefは、すべてhttp://www.w3.org/1999/02/22-rdf-syntax-ns#で始まります(慣習的にQName接頭辞rdf:に関連づけられている)。RDF語彙記述言語(5項で述べる)は、http://www.w3.org/2000/01/rdf-schema#で始まるURIrefを持つ1組の用語を追加定義します(慣習的にQName接頭辞rdfs:に関連づけられている)。(ここでは、特定のQName接頭辞は、このような方法で、ある1組の用語と関連して共通的に使用され、時にはQName接頭辞自体が語彙の名前として使用されることがあります。例えば、誰かが「rdfs:語彙」を参照できます。
共通のURI接頭辞を使用すると、関連する一連の用語に対してURIrefを便利に組織化できます。しかし、これは単なる慣習にすぎません。RDFモデルは、完全なURIrefを認識するだけで、URIrefの「内部を見たり」、構造に関する知識を使用したりはしません。特にRDFでは、URIrefの先頭に共通の接頭辞があるというだけでは、URIref間に関係があるとは仮定しません(さらなる議論に関しては付録Aを参照)。さらに、先頭の接頭辞が異なっているURIrefは同じ語彙の一部であると見なせないとも言えません。特定の組織、プロセス、ツールなどでは、他の語彙のURIrefを自身の語彙の一部として好きなだけ使用して、自身にとって有効な語彙を定義できます。
さらに、ある組織では、その語彙に関する追加情報を提供してくれるウェブ資源のURLとして語彙の名前空間URIrefを使用することもあるでしょう。例えば、以前に指摘したように、QName接頭辞dc:は、入門書の例では、名前空間URIhttp://purl.org/dc/elements/1.1/に関連づけられて使用されるでしょう。実際には、これは6.1項で述べるダブリン・コアの語彙を指します。ウェブ・ブラウザでこの名前空間URIrefにアクセスすると、ダブリン・コアの語彙に関する追加情報が検索されるでしょう(具体的には、RDFスキーマ)。しかし、これも単なる慣習にすぎません。RDFでは、名前空間URIが検索可能なウェブ資源を識別することを前提としていません(さらなる議論に関しては付録Bを参照)。
入門書の残りの部分では、RDF自体で使用するために定義された一連のURIrefや、従業員を識別するためにexample.orgが定義した一連のURIrefなどのような、ある特定の目的のために定義された一連のURIrefを参照する時に、語彙(vocabulary)という用語を使用します。名前空間(namespace)という用語は、XML名前空間の構文上の概念を特別に参照する時にのみ(あるいは、QNameの接頭辞に割り当てられたURIを記述する時に)、使用します。
RDFグラフには、様々な語彙のURIrefを自由に混ぜ入れることができます。例えば、図3のグラフでは、exterms:や、exstaff:、dc:語彙のURIrefを使用しています。また、RDFでは、同じ資源を記述するために、あるURIrefを述語として使用したステートメントをグラフにいくつ出現させることができるかに全く制限がありません。例えば、ex:index.htmlという資源が、John Smithと数人のスタッフの協力で作成されている場合、example.orgは以下のステートメントを作成するでしょう。
ex:index.html dc:creator exstaff:85740 . ex:index.html dc:creator exstaff:27354 . ex:index.html dc:creator exstaff:00816 .
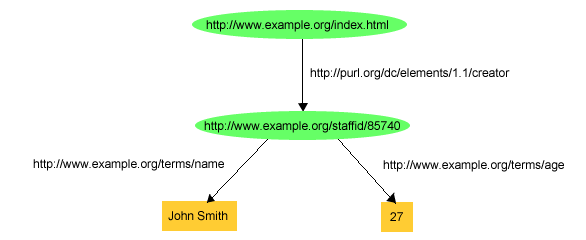
RDFステートメントに関するこれらの例では、RDFが事物を識別する基本的な手段としてURIrefを使用するいくつかの利点を示しています。例えば、最初のステートメントの場合、「John Smith」という文字列でウェブ・ページの作者を識別する代わりに、(彼の従業員番号に基づくURIrefを使用して)http://www.example.org/staffid/85740というURIrefを彼に割り当てていまあう。この場合のURIrefを使用する利点は、ステートメントの主語をより正確に識別できるということです。すなわち、ページの作者は、「John Smith」という文字列でも、何千人もいるJohn Smithという名前の誰かでもなく、そのURIrefに関連づけられている特定のJohn Smithだということです(URIrefを作成した人は誰でもこの関係を定義する)。そのうえ、John Smithを参照するURIrefがあるため、彼は完全な資源であり、JohnのURIrefを主語として持つRDFステートメントを追加するだけで、彼に関する追加情報を記録できます。例えば、図4では、Johnの名前と年令を示すいくつかの追加ステートメントを示しています。
この例では、RDFステートメントにおいてRDFがURIrefを述語(predicates)として使用するということも示しています。 すなわち、プロパティーを識別するために、RDFでは「creator」や「name」(名前)などの文字列(または、単語)を使用するのではなく、URIrefを使用します。プロパティーを識別するためにURIrefを使用することは、様々な理由で重要です。第一に、自分が使用するプロパティーと、URIrefを使用しなければ同じ文字列で識別されてしまう他の誰かが使用するプロパティーとを区別できす。例えば、図4の例では、example.orgは、文字列リテラルとしてすべて書き出した誰かのフルネーム(例えば、「John Smith」)を意味するために「name」を使用していますが、他の誰かが何か別のもの(例えば、プログラム・テキストの断片の変数名)を意味するために「name」を使用することもできます。プロパティー識別子としての「name」にウェブ上で遭遇した(あるいは、複数の情報源のデータを統合した)プログラムは、必ずしもこれらの用途を区別できるわけではないでしょう。しかし、example.orgが「name」プロパティーにhttp://www.example.org/terms/nameを使用し、他の人が自分の「name」プロパティーにhttp://www.domain2.example.org/genealogy/terms/nameを使用した場合、(プログラムが自動的に別々の意味であると判断できなくても)別々のプロパティーが関係していることは明らかです。また、プロパティーを識別するためにURIrefを使用することにより、プロパティーを資源自体として扱うことができるようになります。プロパティーは資源であるため、プロパティーのURIrefを主語として持ったRDFステートメントを追加するだけで、そのプロパティーに関する追加情報を記録できます(例えば、example.orgでは「name」が何を意味するかの英語の記述)。
RDFステートメントでURIrefを主語や述語、目的語として使用すれば、ウェブ上の共通語彙を開発し使用できます。なぜならば、他の人が既に使用している語彙を発見して使用することで、その概念の共通認識を反映した事物を記述できるからです。例えば、以下のトリプル
ex:index.html dc:creator exstaff:85740 .
では、dc:creatorという述語は、URIrefとして完全に展開すれば、ダブリン・コア・メタデータ属性セット(詳細は6.1項で論じる)内の「creator」属性を一意に参照します。ダブリン・コア・メタデータ属性セットとは、あらゆる種類の情報を記述するために広く用いられている属性(プロパティー)の集合のことです。このトリプルの作者は、ウェブ・ページ(http://www.example.org/index.htmlで識別される)とページの作者(http://www.example.org/staffid/85740で識別される別個の人物)との関係は、まさにhttp://purl.org/dc/elements/1.1/creatorで識別される概念であるということを効果的に述べています。ダブリン・コアの語彙をよく知っている人や、dc:creatorが何を意味するかを見つけた人は(例えば、ウェブ上でその定義を調べることによって)、この関係が何を意味するかが分かるでしょう。さらに、この理解に基づいて、dc:creatorという述語を含むトリプルを処理する際には、その意味に従って動作するようにプログラムを書くことができます。
もちろん、そのためには、リテラルを使用するのではなく、もっとURIrefを一般的に使用して事物を参照する必要があります。例えば、John Smithやcreatorのような文字列リテラルではなく、exstaff:85740やdc:creatorのようにURIrefを使用します。そのような場合でも、RDFがURIrefを使用すれば識別の問題がすべて解決されるわけではありません。なぜならば、例えば、同じ事物を参照するのに別のURIrefを使用することが依然として可能であるからです。このような理由で、他の語彙と重複するかもしれない新しい用語を作るよりも、可能であれば、既存の語彙(ダブリン・コアのような)の用語を使用する方が良いでしょう。6項で述べるアプリケーションで示しているように、特定のアプリケーション領域での使用に適した語彙が絶えず開発されています。しかし、同義語が作成されても、これらの別々のURIrefは共通にアクセスできる「ウェブ・スペース」で使用されるため、これらの別々の参照間の同等性を識別するだけでなく、共通の参照を使用する方向に移行することも可能です。
さらに、RDF自体がRDFステートメントで使用される用語(前例のdc:creatorのような)に関連づけている意味と、人(または、これらの人が書いたプログラム)がそれらの用語に関連づけているかもしれない付加的な、外部で定義された意味とを区別することが重要です。RDFは、言語として、主語、述語、目的語のトリプルのグラフ構文、rdf:語彙内のURIrefに関連づけられた特定の意味、および後述する特定のその他の概念、のみを直接定義します。これらは、[RDF-CONCEPTS]および[RDF-SEMANTICS]で規範的に定義されています。しかし、RDFでは、dc:creatorのような、RDFステートメントで使用できる他の語彙の用語の意味は定義していません。特定の語彙は、その語彙内で定義されているURIrefに特定の意味を割り当てて、RDFの外部で作成されるでしょう。この語彙のURIrefを使用したRDFステートメントは、これらの用語に関連づけられている特定の意味を、その語彙を処理するように特別に書かれていない任意のRDFアプリケーションには伝えずに、この語彙に慣れている人々や、この語彙を処理するように書かれているRDFアプリケーションに伝えることができます。
例えば、人は意味を以下のようなトリプルと関連付けることができます。
ex:index.html dc:creator exstaff:85740 .
これは、人がURIref dc:creatorの一部として「creator」という単語の出現と関連づけた意味に基くか、ダブリン・コア語彙のdc:creatorの特定の定義に関する人の理解に基いています。しかし、任意のRDFアプリケーションに関する限り、また、組み込み済みの意味に関する限り、トリプルは以下のようになる方が良いでしょう。
fy:joefy.iunm ed:dsfbups fytubgg:85740 .
同様に、ウェブ上にあるdc:creatorの意味を記述した自然言語テキストは、任意のRDFアプリケーションが直接使用できる付加的な意味を全く提供しません。
もちろん、特定のアプリケーションが特別な意味を少しもURIrefに関連付けることができなくても、RDFステートメントでは特定の語彙のURIrefを使用できます。例えば、一般的なRDFソフトウェアは、上記の表現がRDFステートメントであり、ed:dsfbupsは述語であるといったことを認識するでしょう。このRDFソフトウェアは、語彙の開発者がed:dsfbupsのようなURIrefに関連付けることができたかもしれない特別な意味を全くトリプルに関連づけないでしょう。そのうえ、たとえそのように書かれていないRDFアプリケーションではその意味にアクセスしづらいとしても、人は、特定の語彙に関する理解に基づいて、その語彙のURIrefに割り当てられた特別な意味に従って動作するようにRDFにアプリケーションを書くことができます。
以上をまとめると、RDFは、アプリケーションをより簡単に処理できるステートメントを作成する方法を提供するということです。既に指摘したように、SELECT NAME FROM EMPLOYEE WHERE SALARY > 35000(3万5千ドル以上の給与の従業員の中から名前を選択せよ)のようなクエリーを処理する際に「従業員」や「給料」のような用語をデータベース・システムが「理解」できないのと同じように、アプリケーションはこのようなステートメントを実際には「理解」できません。しかし、アプリケーションが適切に作成されていれば、データベース・システムとそのアプリケーションが「従業員」と「給料」を理解せずに従業員と給料の情報を処理しても効果的に作業ができるのとちょうど同じように、これらを理解しているかのような方法でRDFステートメントを処理できます。例えば、あるユーザがすべての書評をウェブで検索し、それぞれの本に対する平均格付けを作成できれば、そのユーザは、その情報をまたウェブに掲載できます。別のウェブサイトでは、この本の格付け平均のリストを取って来て、「トップ10にランクインした本」のページを作成できます。ここでは、格付けに関する共通語彙の有用性と利用方法、そして格付けを適用する本を識別するURIrefの共有グループにより、各個人が相互理解を持ち、ますます強力な(さらなる貢献がなされるため)、本に関するウェブ上の「情報ベース」を構築できるようになります。何千もの主題に関してウェブ上で日々作成されている膨大な情報に対しても同じ原理を適用できます。
RDFステートメントは、以下のような、情報を記録するための他の多くの形式に似ています。
そして、これらの形式の情報をRDFステートメントとして扱うことができ、これによって、多くの情報源のデータをRDFを使用して統合できるようになります。
記録すべき事物に関する情報の種類が、今までに示したシンプルなRDFステートメント形式でしかありえないのならば、話はとても簡単でしょう。しかし、実際の世界では、少なくとも表面的には、ほとんどのデータがそれより複雑な構造を伴っています。例えば、最初の例では、ウェブ・ページが作成された日付は、その値としてプレーン・リテラルを持つ、1つのexterms:creation-dateプロパティーとして記録されています。しかし、exterms:creation-dateプロパティーの値の月や日、年を別々の情報として記録する必要があると仮定してください。あるいは、John Smithの個人情報の事例に、Johnの住所が記述されていたと仮定してください。この場合、以下のトリプルのように、住所全体をプレーン・リテラルとしてすべて書き出すことができます。
exstaff:85740 exterms:address "1501 Grant Avenue, Bedford, Massachusetts 01730" .
しかし、Johnの住所を、通りや市、州、郵便番号という別々の値から成る構造体として記録する必要があると仮定してください。RDFでは、これをどのように行えれば良いでしょうか?
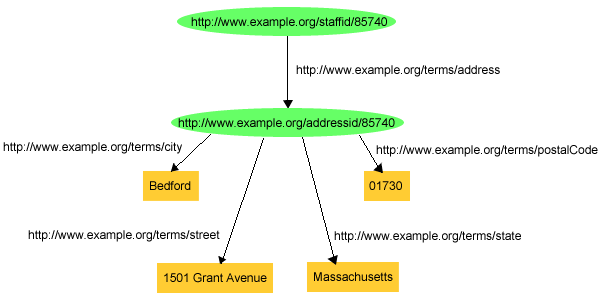
RDFでは、このような構造化された情報を、記述する事物の集合を資源と見なして(John Smithの住所のように)、この新しい資源に関するステートメントを作成することによって表現します。そのため、RDFグラフでは、John Smithの住所を構成要素に分解するために、新しいノードを作成してJohn Smithの住所の概念を表現し、例えばhttp://www.example.org/addressid/85740(exaddressid:85740と略される)のように、この概念を新しいURIrefで識別します。その後、このノードを主語にしたRDFステートメント(追加アークおよびノード)を作成して追加情報を表現でき、図5で示すグラフを作成します。
あるいは、トリプルでは以下のようになります。
exstaff:85740 exterms:address exaddressid:85740 . exaddressid:85740 exterms:street "1501 Grant Avenue" . exaddressid:85740 exterms:city "Bedford" . exaddressid:85740 exterms:state "Massachusetts" . exaddressid:85740 exterms:postalCode "01730" .
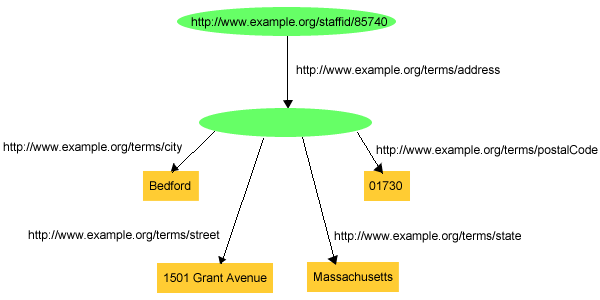
このような方法で、構造化された情報をRDFで表現すると、Johnの住所などの集合概念を表現するために、exaddressid:85740などの多数の「中間の」URIrefが発生します。このような概念を特定のグラフ外から直接参照する必要はなく、したがって、「ユニバーサルな」識別子は必要ないかもしれません。さらに、図5のステートメント群を表現するグラフを描く時には、図6のグラフのように簡単に描くことができるため、「John Smithの住所」を識別するために割り当てたURIrefは、実際には必要ではありません。
完璧なRDFグラフである図6では、「John Smithの住所」の概念を表わすためにURIrefがないノードを使用しています。ノード自体がグラフの別々の部分の間に必要な接続性を提供するため、この空白ノードは、URIrefを使用せずに描くという目的を果たします。([RDF-MS]では空白ノードを匿名資源(anonymous resource)と呼びます。) しかし、このグラフをトリプルとして表現するためには、このノードに対する明示的な識別子の形式が必要です。これを理解するために、図6で示した内容に対応したトリプルを書いてみると、以下のようになるでしょう。
exstaff:85740 exterms:address ??? . ??? exterms:street "1501 Grant Avenue" . ??? exterms:city "Bedford" . ??? exterms:state "Massachusetts" . ??? exterms:postalCode "01730" .
ここでは、???は空白ノードの存在を意味します。複雑なグラフには1つ以上の空白ノードを含むことができるため、グラフのトリプル表現では、これらの異なる空白ノードを区別する方法も必要になります。その結果、トリプルでは、_:nameの形式を持つ空白ノード識別子を使用して空白ノードの存在を示します。例えば、この例では_:johnaddressという空白ノード識別子を使用して空白ノードを参照でき、その結果、トリプルは以下の通りになります。
exstaff:85740 exterms:address _:johnaddress . _:johnaddress exterms:street "1501 Grant Avenue" . _:johnaddress exterms:city "Bedford" . _:johnaddress exterms:state "Massachusetts" . _:johnaddress exterms:postalCode "01730" .
グラフのトリプル表現では、グラフ中のそれぞれ別個の空白ノードには別個の空白ノード識別子が与えられます。URIrefやリテラルとは異なり、空白ノード識別子はRDFグラフの実際の部分とは考えられません(これは、図6のグラフを見たり、空白ノードには空白ノード識別子がないということに注意すれば理解できます)。 空白ノード識別子は、グラフがトリプル形式で書かれている場合は、グラフで空白ノードを表現する(そして、1つの空白ノードを別の空白ノードと区別する)方法の1つにすぎません。また、空白ノード識別子は、1つのグラフを表現しているトリプル内でのみ意味を持ちます(同じ数の空白ノードを持つ2つの別個のグラフでは、独自に同じ空白ノード識別子を使用して区別し、同じ空白ノード識別子を持つ別々のグラフに属する空白ノードが同じであると見なすのは間違いでしょう)。グラフ外からグラフのノードを参照する必要がありえる場合には、グラフを識別するためにURIrefを割り当てるべきです。最後に、空白ノード識別子は、RDFグラフのトリプル形式は、アークではなく(空白)ノードを表現するので、空白ノード識別子はトリプルでは主語または目的語としてのみ現れます。つまり、トリプルでは、空白ノード識別子を述語として使用してはなりません。
この項の冒頭では、John Smithの住所のように、記述する事物の集合を1つの別個の資源と見なし、この新しい資源に関するステートメントを作成することによって、集合構造を表現すことができると指摘しました。この例では、RDFの重要な側面を示します。それは、RDFは、例えばJohn Smithと彼の住所を表現しているリテラルとの関係などの、2項関係のみを直接表現するということです。Johnとこの住所の別々の構成要素のグループとの関係を表現する場合には、Johnと通りや市、州、郵便番号の構成要素とのn項(n方向)関係(この場合、n=5)を扱う必要があります。このような構造をRDFで直接表現するためには(例えば、住所が、通り、市、州、郵便番号の構成要素のグループであると見なして)、このn方向関係を別々の2項関係のグループに分解しなければなりません。空白ノードは、これを行う方法を提供します。それぞれのn項関係に対して、関係しているものの1つをその関係の主語として選び(この場合、John)、空白ノードを作成して残りの関係(この場合、Johnの住所)を表現します。そして、関係の残り(この例では、都市など)を、空白ノードで表現されている新しい資源の別々のプロパティーとして表現します。
空白ノードは、URIを持たない資源に関するステートメントをより正確に作成する方法も提供しますが、これはURIを持つ他の資源との関係で記述されます。例えば、人に関するステートメントを作成する場合(例えばJane Smith)、この人の電子メール・アドレスに基づくURI(例えば、mailto:jane@example.org)を彼女のURIとして使用するのが自然でしょう。しかし、この方法は問題を引き起こしかねません。例えば、Janeジェーン自身に関する情報(例えば、彼女の物理的な現住所)だけでなく、Janeのメールボックス(例えば、それが置かれているサーバ)に関する情報も記録する必要があって、彼女の電子メール・アドレスに基づいてJaneにURIrefを使用すると、それがJaneなのか記述されている彼女のメールボックスなのかを区別するのが難しくなります。会社のウェブ・ページのURL(例えば、http://www.example.com/)を会社自体のURIとして使用している場合にも、同じ問題が存在しています。この場合も、会社に関する情報だけでなく、ウェブ・ページ自体に関する情報(例えば、誰がいつ作成した)も記録する必要があって、この両者に対する識別子としてhttp://www.example.com/を使用すると、これらのどちらが実際の主語であるかを区別するのが難しくなります。
根本的な問題は、Janeの代わりにJaneのメールボックスを使用するのはあまり正確でないということです。つまり、Janeと彼女のメールボックスは同じものではないため、別々に識別されるべきです。Jane自身がURIを持っていない場合には、空白ノードを使ってこの状況をより正確にモデル化できます。Janeを空白ノードで表現し、値としてURIref mailto:jane@example.orgを持っているexterms:mailboxプロパティーを持つステートメントの主語としてその空白ノードを使用できます。以下のトリプルで示しているように、空白ノードは、exterms:Personという値を持つrdf:typeプロパティー(型の詳細については、次項で論じる)や、「Jane Smith」という値を持つexterms:nameプロパティー、その他の有用な記述情報を用いても記述できます。
_:jane exterms:mailbox <mailto:jane@example.org> . _:jane rdf:type exterms:Person . _:jane exterms:name "Jane Smith" . _:jane exterms:empID "23748" . _:jane exterms:age "26" .
(最初のトリプルではmailto:jane@example.orgがアングルブラケット内に記述されていることに注意してください。これは、mailto:jane@example.orgが、QNameの省略形ではなく、mailto URLスキームにおける完全なURIrefであり、完全なURIrefはトリプル表記法ではアングルブラケットで囲み込まなければならないからです。)
これは、実際には、「型exterms:Personの資源があり、その電子メールボックスがmailto:jane@example.orgで、その名前がJane Smithで識別される、など」ということを示しています。つまり、この空白ノードは「資源がある」と読むことができます。その空白ノードを主語として持つステートメントは、その資源の特性に関する情報を提供します。
実際には、これらの事例でURIrefではなく空白ノードを使用したとしても、この種の情報を処理する方法はあまり変わりません。例えば、ある電子メールアドレスがexample.orgに属している人物を一意に識別すると分かっている場合(特に、アドレスが再利用される可能性がない場合)、その電子メールアドレスがその人のURIでなかったとしても、複数の情報源からその人に関する情報を関連付けるためにこの事実を使用できます。この場合、ある本について記述したRDFがウェブ上にあり、その著者の問い合わせ先をmailto:jane@example.orgとして提供している場合、この新しい情報を前のトリプルの集合と組み合わせて、その著者の名前はJane Smithであると結論づけることは合理的でしょう。ポイントは、「本の著者は、mailto:jane@example.orgです」のように述べることは、通常、「本の著者は、メールボックスがmailto:jane@example.orgである人物です」の省略形であるということです。空白ノードを使用してこの「人物」を表現することは、現実世界の状況をより正確に表現する方法です。(偶然にも、いくつかのRDFベースのスキーマ言語によって、あるプロパティーはそのプロパティーが記述する資源の一意の識別子であると指定できます。これに関する詳細は、5.5項で論じます。)
このような方法で空白ノードを使用すれば、不適切な状況でリテラルを使用することを避けることもできます。例えば、Janeの本について記述する際に、著者を識別するURIrefがなければ、出版社は以下のように書くことができます(出版社自身のex2tex2terms:語彙を使用して)。
ex2terms:book78354 rdf:type ex2terms:Book . ex2terms:book78354 ex2terms:author "Jane Smith" .
しかし、この本の著者は、実際には「Jane Smith」という文字列ではなく、名前がJane Smithである人物です。出版社は、以下のように、これと同じ情報を空白ノードを使用してより正確に示すことができます。
ex2terms:book78354 rdf:type ex2terms:Book . ex2terms:book78354 ex2terms:author _:author78354 . _:author78354 rdf:type ex2terms:Person . _:author78354 ex2terms:name "Jane Smith" .
これは、本質的に「資源ex2terms:book78354は、型ex2terms:Bookに関するものであり、その著者は型ex2terms:Personの資源で、その名前はJane Smithです。」と述べています。もちろん、このような特殊な事例では、出版社は、その著者を外部で参照してもらえるように、空白ノードを使用して著者を識別する代わりに、出版社自身のURIrefを著者に割り当てることができます。
最後に、Janeの年齢を26としている上の例では、プロパティーの値はシンプルに見えることがあるけれども、実際にはより複雑であるという事実を示しています。この場合、Janeの年令は実際に26歳ですが、単位情報(歳)が明示されていません。このような情報は、プロパティーの値にアクセスする誰もが使用されている単位を理解していると確実に見なせる状況では、しばしば省略されます。しかし、ウェブというより幅広い環境においては、このように想定することは概して安全ではありません。例えば、米国のサイトでは、重さの値をポンドで示しますが、米国以外からそのデータにアクセスする人は、重さがキログラムで示されていると思うかもしれません。一般的に、単位やこれと類似した情報を明確に表現するには、慎重な検討が必要です。この問題の詳細は、構造化された値のような情報を表現するための他のいくつかのテクニックに加えて、そのような情報を表現するためのRDFの機能を記述している4.4項で議論じます。
前の項では、プレーン・リテラルで表現されたプロパティーの値を、それらのリテラルの個々の部分を表現するために、構造化された値に分解しなくてはならない状況を扱う方法について述べました。例えば、ウェブ・ページを作成した日付を、値として1つのプレーン・リテラルを持つ1つのexterms:creation-dateプロパティーとして記録するのではなく、この方法を使用して、同じ値を表現するために別々のプレーン・リテラルを使用して、月、日、年という別々の部分の情報から成る構造体としてその値を表現します。しかし、プロパティーの値を数(例えば、yearやageプロパティーの値)やその他の種類の特殊な値などにするつもりであっても、今までは、RDFステートメントで目的語としての役割を果たすすべての定数を、これらのプレーンな(型付きでない)リテラルで表現してきました。
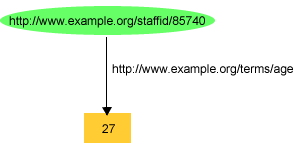
例えば、図4では、John Smithに関する情報を記録しているRDFグラフを示しました。このグラフは、図7で示しているように、John Smithのexterms:ageプロパティーの値をプレーン・リテラル「27」として記録しました。
この場合、仮想の組織、example.orgは、「27」が、「2」とそれに続く「7」の文字から構成される文字列としてではなく、恐らく1つの数字として解釈されることを意図しています(このリテラルが「age」プロパティーの値を表わすため)。しかし、図7のグラフには、「27」が数として解釈されるべきであると明示している情報は全くありません。同様に、example.orgは、「27」が、例えば8進数の数、つまりtwenty three(23)という値としてではなく、10進数の数、つまりtwenty seven(27)という値として解釈されることも恐らく意図しています。しかし、繰り返しになりますが、図7のグラフにはこれを明示する情報が全くありません。特定のアプリケーションは、exterms:ageプロパティーの値を10進数として解釈するはずだという理解のもとに書かれているかもしれませんが、これは、このRDFの適切な解釈はRDFグラフでは明らかに示されていない情報に依存しており、したがって、このRDFを解釈する必要がある他のアプリケーションで必ずしも利用できるわけではない情報に依存しているということを意味するでしょう。
プログラミング言語やデータベース・システムに共通する習慣は、データ型とリテラルを関連付けることによって、リテラルを解釈する方法に関するこの追加情報を提供することです(この事例ではdecimal(十進数)やinteger(整数)のようなデータ型)。例えば、データ型を理解するアプリケーションは、指定されたデータ型がinteger(整数)なのか、binary(2進数)なのか、string(文字列)なのかによって、例えば、リテラル「10」が数字ten(10)を表わすつもりなのか、数字two(2)なのか、「1」の後に「0」が続く文字で構成される文字列なのかを知るようになります。(2.3項の末尾で言及した単位情報を含むために、例えば、データ型integerYearsのような、より特化したデータ型を使用することもできます。しかし、この入門書ではこの概念について詳述していません。)RDFでは、型付きリテラルを使用してこの種の情報を提供します。
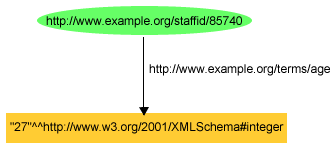
RDFの型付きリテラルは、文字列と特定のデータ型を識別するURIrefとを対にすることによって作られます。これによって、対になったリテラルを持つ1つのリテラルのノードがRDFグラフで作られます。型付きリテラルで表現された値は、指定されたデータ型を指定された文字列に関連づけている値です。例えば、型付きトリプルを使用すれば、以下のトリプルを使用して、John Smithの年齢が整数27であると記述できます。
<http://www.example.org/staffid/85740> <http://www.example.org/terms/age> "27"^^<http://www.w3.org/2001/XMLSchema#integer> .
または、長いURIを書く代わりにQNameの簡略化を使用すると以下のようになります。
exstaff:85740 exterms:age "27"^^xsd:integer .
または、図8で示しているようになります。
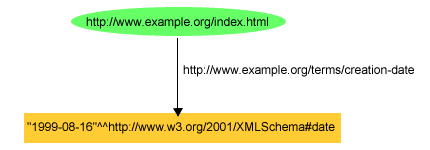
同様に、ウェブ・ページに関する情報を記述している図3で示したグラフでは、こそのページのexterms:creation-dateプロパティーの値は、「August 16, 1999」(1999年8月16日)というプレーン・リテラルとして書かれていました。しかし、型付きリテラルを使用すれば、ウェブ・ページの作成日は、以下のトリプルを使用して、August 16, 1999という日付であると明確に記述できます。
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
または、図9で示しているようになります。
一般的なプログラミング言語やデータベース・システムとは異なり、RDFには、整数や実数、文字列、日付に対するデータ型のような、自身のデータ型の集合が全く組み込まれていません。その代わりに、RDFの型付きリテラルは、解釈するためにどのようなデータ型を使用すべきかを特定のリテラルに対して明示する方法を提供するだけです。型付きリテラルで使用されるデータ型は、RDFの外部で定義され、それらのデータ型URIで識別されます。(例外が1つあります。RDFは、XMLコンテンツをリテラルの値として表現するために、rdf:XMLLiteralというURIrefを使用して組み込みデータ型を定義します。このデータ型は、[RDF-CONCEPTS]で定義されており、使用法は4.5項で記述されています。)例えば、図8と図9の例では、XMLスキーマ パート2:データ型 [XML-SCHEMA2]で定義されているXMLスキーマ・データ型に属するデータ型、integerとdateを使用します。この方法の利点は、これによって、異なる情報源からの情報を、その情報源と元々のRDFデータ型の集合の間で型の変換を行わずに、直接表現する柔軟性をRDFが得るということです。(型の変換は、異なるデータ型を持つシステム間で情報を移動させる際に必要ですが、RDFでは、元のRDFデータ型の集合に変換を加える必要はありません。)
RDFデータ型の概念は、RDF概念および抽象構文 [RDF-CONCEPTS]で記述しているように、XMLスキーマ・データ型[XML-SCHEMA2]の概念の枠組みに基づいています。この概念の枠組みは、データ型が以下から構成されていると定義しています。
xsd:dateの場合、この値の集合は一連の日付です。xsd:dateは、1999-08-16をこの種のリテラルを書く正当な方法であると定義しています(例えば、August 16, 1999ではなく)。[RDF-CONCEPTS]で定義されているように、データ型の字句空間は、ユニコード[UNICODE]の文字列セットで、これによって多くの言語による情報を直接表現できるようになります。xsd:dateに対する字句-値マッピングは、このデータ型では、1999-08-16という文字列は1999年8月16日という日付を表現するということを決定します。同じ文字列が異なるデータ型に対し異なる値を表現できるため、字句-値マッピングは因数です。すべてのデータ型がRDFでの使用に適しているわけではありません。データ型をRDFで適切に使用するためには、今しがた記述した概念の枠組みに従わなければなりません。これが基本的に意味するのは、文字列が与えられれば、データ型は、その文字列が字句空間にあるかどうかと、その文字列が値空間でどのような値を表現するかを、明確に定義しなければならないということです。例えば、xsd:string、xsd:boolean、xsd:dateなどのような基本的なXMLスキーマ・データ型は、RDFでの使用に適しています。しかし、組み込みXMLスキーマ・データ型の一部かは、RDFでの使用に適していません。例えば、xsd:durationは明確に定義された(well-defined)値空間を持っておらず、xsd:QNameはXMLドキュメントのコンテキストを含んでいる必要があります。RDFでの使用に適当/不適当であると現在考えられているXMLスキーマ・データ型のリストを[RDF-SEMANTICS]で提供しています。
特定の型付きリテラルが意味する値は型付きリテラルのデータ型で定義されており、rdf:XMLLiteralを除き、RDFはいかなるデータ型も定義しないため、RDFグラフで表示されている型付きリテラルの実際の解釈(例えば、それが意味する値を決定する)は、RDFだけでなく型付きリテラルのデータ型も正しく処理するように書かれたソフトウェアで行わなければなりません。事実上、このソフトウェアは、RDFだけではなくデータ型も含んだ拡張言語を組み込み語彙の一部として処理するように書かれていなければなりません。これは、どのデータ型をRDFソフトウェアで一般的に使用できるのかという問題を引き起こします。一般的に、RDFでの使用に適していると[RDF-SEMANTICS]に記載されているXMLスキーマ・データ型は、RDFでは「最優先」(first among equals)というステータスを持っています。既に指摘したように、図8と図9の例では、これらのXMLスキーマ・データ型の一部を使用しました。そして、この入門書でも、他の大部分の型付きリテラルの例でこれらのデータ型を使用します(一例をあげると、XMLスキーマ・データ型では、データ型を参照するために使用できるURIrefを既に割り当てています。この仕様は[XML-SCHEMA2]で定めています)。これらのXMLスキーマ・データ型は、他のデータ型式と全く同じように処理されますが、最も広く使用されることが予期されており、したがって、異なるソフトウェア間で相互利用される可能性が最もあります。その結果、多くのRDFソフトウェアがこれらのデータ型も処理するように書かれるでしょう。しかし、既に記述したように、RDFでの使用に適していると判断されたという前提で、他の一連のデータ型を処理するためにもRDFソフトウェアを書くことができます。
一般的に、RDFソフトウェアは、ソフトウェアが処理するように書かれていないデータ型に対する参照を含んでいるRDFデータの処理を要求されることがあり、その場合、ソフトウェアが処理できないこともあります。一例をあげると、rdf:XMLLiteralを除いて、RDF自体は、データ型を識別するURIrefを定義していません。その結果、特定のURIrefを認識するように書かれていなければ、RDFソフトウェアは、型付きリテラルで書かれているURIrefが実際にデータ型を識別するかどうかを判断できないでしょう。そのうえ、URIrefがデータ型を識別したとしても、RDF自体はそのデータ型と特定のリテラルとを対にすることの妥当性を定義しません。この妥当性は、その特定のデータ型を正しく処理するように書かれたソフトウェアのみが決定できます。
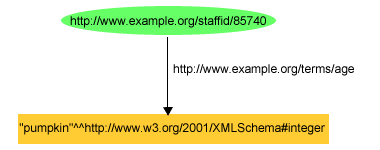
例えば、型付きリテラルは、トリプルで以下のように書くことができます。
exstaff:85740 exterms:age "pumpkin"^^xsd:integer .
または、図10で示すグラフは以下のようになります。
これは、正当なRDFですが、"pumpkin"(かぼちゃ)はxsd:integerの字句空間に存在すると定義されていないため、xsd:integerのデータ型に関する限り、明らかに誤りです。xsd:integerデータ型を処理するように書かれていないRDFソフトウェアは、この誤りを認識できないでしょう。
しかし、RDFの型付きリテラルを適切に使用すれば、リテラルの値が意図する解釈に関する情報をより多く得ることができ、ゆえに、RDFステートメントはアプリケーション間の情報交換により適した手段になります。
全体として見ると、RDFは基本的にシンプルです。つまり、URIrefで識別された事物に関するステートメントとして解釈されたノードとアークの図式です。この項では、これらの概念に関する概論を提供しています。以前に指摘したように、これらの概念を記述している規範的な(すなわち、最終的な)RDFの仕様は、RDF概念および抽象構文 [RDF-CONCEPTS]であり、詳細はこれを参考にするべきです。これらの概念の形式意味論(意味)は、RDFセマンティクス(規範) [RDF-SEMANTICS]ドキュメントで定義されています。
しかし、これまで論じてきた、RDFステートメントを使用して事物を記述するための基本技術に加え、人や組織は、これらのステートメントで使用しようとする語彙(用語)を記述する方法も必要であることは明らかです。特に、以下のような語彙が必要です。
exterms:Person)。exterms:ageやexterms:creation-date)。そして、exterms:ageプロパティーの値が、常にxsd:integerであるように指定するなど)。RDFでこのような語彙を記述するための基礎はRDF語彙記述言語1.0 [RDF-VOCABULARY]であり、これは5項で記述しています。
RDFの基礎をなす基本概念に関する別の背景と、ウェブ情報を記述するための一般言語を提供する上でのその役割に関しては[WEBDATA]で参照できます。RDFは、概念グラフや論理ベースの知識表現、フレーム、リレーショナル・データベースを含む、知識表現や人工知能、データ管理の概念を利用します。これらの主題に関する背景情報になりうる情報源には、[SOWA]や[CG]、[KIF]、[HAYES]、[LUGER]、[GRAY]が含まれています。
2項で記述したように、RDFの概念モデルはグラフです。RDFは、RDF/XMLと呼ばれるRDFグラフを作成し、交換するためのXML構文を提供します。省略表記用のトリプルとは異なり、RDF/XMLは、RDFを書くための規範構文です。RDF/XMLは、RDF/XML構文仕様 [RDF-SYNTAX]で定義されてます。この項では、このRDF/XML構文について記述しています。
既に提示したいくつかの例を使用してRDF/XML構文の背景にある基本概念を示すことができます。例として、以下の英語のステートメントを見てください。
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
URIrefをcreation-dateプロパティーに割り当てた後の、この1つのステートメントのRDFグラフを図11で示します。
トリプル表現では以下のようになります。
ex:index.html exterms:creation-date "August 16, 1999" .
(この例では、日付の値に型付きリテラルが使用されていないことに注意してください。RDF/XMLでの型付きリテラルの表現に関しては、この項の後半で記述します。)
例2では、図11のグラフに対応するRDF/XML構文を示しています。
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:exterms="http://www.example.org/terms/"> 4. <rdf:Description rdf:about="http://www.example.org/index.html"> 5. <exterms:creation-date>August 16, 1999</exterms:creation-date> 6. </rdf:Description> 7. </rdf:RDF>
(例の説明に役立つように行番号を付記しています。)
これは、非常に手間がかかるように見えます。このXMLの各部分を順に検討すれば、何が起こっているかを理解することはずっと簡単です(XMLは付録Bで簡潔に紹介しています)。
1行目の<?xml version="1.0"?>は、XML宣言で、以下のコンテンツがXMLであることと、どのバージョンのXMLなのかを示しています。
2行目では、rdf:RDF要素を開始しています。これは、以下のXMLコンテンツ(ここから始まり、7行目の</rdf:RDF>で終わる)がRDFを表現しようとしていることを示しています。同じ行のrdf:RDFの後に、XML名前空間宣言がrdf:RDF開始タグのxmlns属性として表現されます。この宣言では、このコンテンツ内の接頭辞rdf:が付いているタグはすべてURIref http://www.w3.org/1999/02/22-rdf-syntax-ns#によって識別される名前空間の一部であると明記しています。文字列http://www.w3.org/1999/02/22-rdf-syntax-ns#で始まるURIrefは、RDF語彙の用語に対して使用されています。
3行目では、別のXML名前空間宣言を明記しており、今回は接頭辞exterms:です。これは、rdf:RDF要素の別のxmlns属性として表され、名前空間URIref http://www.example.org/terms/がexterms:接頭辞と関連づけられることを明記しています。文字列http://www.example.org/terms/で始まるURIrefは、例としてあげた組織、example.orgが定義している語彙の用語に対して使用されます。3行目の末尾の「>」は、rdf:RDF開始タグの終わりを示しています。1~3行目は、これがRDF/XMLコンテンツであることを示し、RDF/XMLコンテンツ内で使用される名前空間を識別するために必要な一般的な「管埋」情報です。
4~6行目では、図11で示した特定のステートメントのRDF/XMLを提供しています。RDFステートメントについて述べる明確な方法は、これが記述であり、ステートメントの主題に関するものであり(この場合、http://www.example.org/index.htmlに関するもの)、これはRDF/XMLがステートメントを表現する方法であると述べることです。 4行目のrdf:Description開始タグは資源の記述の始まりを示し、続いてrdf:about属性を使用して主語資源のURIrefを指定し、ステートメントが何に関する資源なのか(ステートメントの主語)を識別するようになります。5行目では、QName exterms:creation-dateをタグとして使用してプロパティー要素を提供し、ステートメントの述語と目的語を表現しています。QName exterms:creation-dateを選択しているので、exterms:接頭辞のURIrefにローカール名creation-dateを追加すると、ステートメントの述語http://www.example.org/terms/creation-dateが得られます。このプロパティー要素のコンテンツは、ステートメントの目的語であるAugust 19, 1999というプレーン・リテラル(主語資源の作成日プロパティーの値)です。プロパティーの要素は、これを包含するrdf:Description要素内に入れ子にされ、このプロパティーが、rdf:Description要素のrdf:about属性で指定されている資源に適用されていることを示します。6行目は、この特定のrdf:Description要素の終わりを示しています。
最後に、7行目は、2行目で開始したrdf:RDF要素の終わりを示しています。rdf:RDF要素を使用してRDF/XMLコンテンツを含むことは、XMLがコンテキストによってRDF/XMLとして識別できるような状況におけるオプションです。これに関する詳細は、[RDF-SYNTAX]で論じます。しかし、どのような場合でも、rdf:RDF要素を提供しても問題はなく、入門書の例では、通常は(常にではないが)提供しています。
例2では、RDFグラフをXMLの要素、属性、要素コンテンツ、属性値としてコード化するためにRDF/XMLで使用されている基本概念を示しています。付録Bで述べているように、述語のURIref(一部のノードも同様に)は、名前空間修飾付き(namespace-qualified)要素や属性を示すローカル名と共に、名前空間URIを示す短い接頭辞で構成されているXML QNameとして書かれています。対(名前空間URIref、ローカル名)が選択されるので、これらを連結すると最初のノードや述語のURIrefを作成できます。主語ノードのURIrefは、XML属性値として書かれます(目的語ノードのURIrefが属性値として書かれることもある)。リテラルのノード(常に目的語ノードである)は、要素テキスト・コンテンツや属性値になります。(これらのオプションの多くは、この入門書の後半で記述しており、これらのオプションはすべて[RDF-SYNTAX]で記述されています。)
例2の4~6行目と同じRDF/XMLを使用して各ステートメントを別々に表現することによって、複数のステートメントで構成されたRDFグラフをRDF/XMLで表現できます。例えば、以下の2つのステートメントを書く場合、
ex:index.html exterms:creation-date "August 16, 1999" . ex:index.html dc:language "en" .
例3のRDF/XMLを使用できます。
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:dc="http://purl.org/dc/elements/1.1/" 4. xmlns:exterms="http://www.example.org/terms/"> 5. <rdf:Description rdf:about="http://www.example.org/index.html"> 6. <exterms:creation-date>August 16, 1999</exterms:creation-date> 7. </rdf:Description> 8. <rdf:Description rdf:about="http://www.example.org/index.html"> 9. <dc:language>en</dc:language> 10. </rdf:Description> 11. </rdf:RDF>
例3は、2番目のステートメントを表現するために2番目のrdf:Description要素(8~10行目に)を追加しただけで、あとは例2と同じです。(また、このステートメントで追加されている名前空間を識別するために、3行目に名前空間宣言を追加しています。)追加した各ステートメントに対して別々のrdf:Description要素を使用して、追加した任意の数のステートメントを同じ方法で書くことができます。例3で示しているように、いったんXMLと名前空間宣言を書く手間に対処すると、RDF/XMLでそれぞれのRDFステートメントを追記することは容易かつそれほど複雑ではありません。
RDF/XML構文では、多くの略語を提供し、共通した用法をより簡単に記述できるようにしています。例えば、例3のように、普通は同じ資源を複数のプロパティーや値で同時に記述します。この事例では、資源ex:index.htmlは、複数のステートメントの主語です。このような事例に対処するため、RDF/XMLでは、これらのプロパティーを表現する複数のプロパティー要素を主語資源を識別するrdf:Description要素内で入れ子にできます。例えば、http://www.example.org/index.htmlに関する以下のステートメントのグループを表現する場合、
ex:index.html dc:creator exstaff:85740 . ex:index.html exterms:creation-date "August 16, 1999" . ex:index.html dc:language "en" .
例4で示しているようにRDF/XMLを書くことができます。
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:dc="http://purl.org/dc/elements/1.1/" 4. xmlns:exterms="http://www.example.org/terms/"> 5. <rdf:Description rdf:about="http://www.example.org/index.html"> 6. <exterms:creation-date>August 16, 1999</exterms:creation-date> 7. <dc:language>en</dc:language> 8. <dc:creator rdf:resource="http://www.example.org/staffid/85740"/> 9. </rdf:Description> 10. </rdf:RDF>
以前の2つの例と比べて、例4では、dc:creatorプロパティー要素を(8行目に)追加しています。さらに、主語がhttp://www.example.org/index.htmlである3つのプロパティーに対するプロパティー要素を、各ステートメントに対して別々のrdf:Description要素を書くのではなく、その主語を識別する1つのrdf:Description要素内に入れ子にしています。
8行目では、新しい形式のプロパティー要素も導入しています。7行目のdc:language要素は、例2で使用しているexterms:creation-date要素に似ています。これら2つの要素は、プレーン・リテラルを用いてプロパティーをプロパティー値として表現し、プロパティー名に対応する開始タグと終了タグでリテラルを囲み込んで書いています。しかし、8行目のdc:creator要素は、リテラルではなく別の資源を値を持つプロパティーを表現しています。他の要素のリテラルの値と同じ方法で、この資源のURIrefを開始タグと終了タグ内にプレーン・リテラルで書いた場合、dc:creator要素の値は、URIrefとして解釈されているリテラルで識別された資源ではなく、文字列http://www.example.org/staffid/85740であるということを述べていることになります。この違いを示すために、XMLで空要素タグ(別個の終了タグを持たない)と呼んでいるものを使用してdc:creator要素を書き、この空要素内でrdf:resource属性を使用してプロパティー値を書いています。rdf:resource属性は、プロパティー要素の値が別の資源であり、そのURIrefで識別されるということを示します。URIrefは属性値として使用されるため、RDF/XMLでは、要素や属性名を書く際に行ったようにQNameで省略するのではなく、URIrefをすべて書き出す(絶対URIrefや相対URIrefとして)必要があります(絶対URIrefと相対URIrefに関しては付録Aで論じます)。
例4のRDF/XMLが略語形であるということを理解していることが重要です。各ステートメントが別々に書かれている例5のRDF/XMLは、全く同じRDFグラフ(図12のグラフ)を記述しています。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.org/index.html">
<exterms:creation-date>August 16, 1999</exterms:creation-date>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<dc:language>en</dc:language>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<dc:creator rdf:resource="http://www.example.org/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
以下の項では、いくつかのRDF/XML省略形を追記しています。利用できる省略形に関する詳細は、[RDF-SYNTAX]で記述しています。
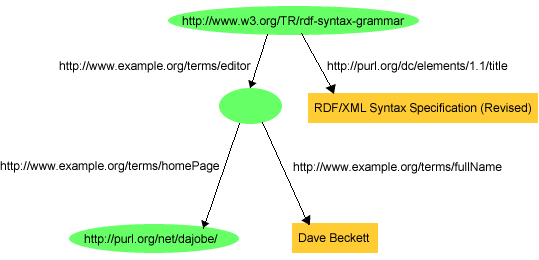
RDF/XMLでは、URIrefがないノード、すなわち、2.3項で記述した空白ノードを含んでいるグラフも表現できます。例えば、図13([RDF-SYNTAX]に掲載)は、「ドキュメント'http://www.w3.org/TR/rdf-syntax-grammar'のタイトルは'RDF/XML Syntax Specification (Revised)'で、編集者が存在し、その編集者の名前は'Dave Beckett'で、'http://purl.org/net/dajobe/'というホームページを持っている」と述べているグラフを示します。
これは、2.3項で論じた概念を示しています。つまり、URIrefがなくても他の情報に関して記述できるものを表現するために空白ノードを使用します。この場合、空白ノードは、ドキュメントの編集者である、人を表現しており、その人を彼の名前とホームページによって記述しています。
RDF/XMLでは、空白ノードを含む、グラフを表現する方法をいくつか提供します。これらは、すべて[RDF-SYNTAX]で記述されています。ここで示しているのは最も直接的な方法で、各空白ノードに空白ノード識別子を割り当てるというものです。空白ノード識別子は、特定のRDF/XMLドキュメント内の空白ノードを識別する役割を果たしますが、URIrefと異なり、割り当てられているドキュメントの外部では不明です。空白ノードは、空白ノード識別子を値として持つrdf:nodeID属性を、本来ならば資源のURIrefが表示される場所に使用することでRDF/XMLで参照できます。特に、rdf:about属性ではなくrdf:nodeID属性を持つrdf:Description要素を使用して、空白ノードを主語として持つステートメントをRDF/XMLで書くことができます。同様に、rdf:resource属性ではなくrdf:nodeID属性を持つプロパティー要素を使用して、空白のノードを目的語として持つステートメント書くことができます。rdf:nodeIDを使用して、例6では、図13に対応するRDF/XMLを示しています。
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:dc="http://purl.org/dc/elements/1.1/" 4. xmlns:exterms="http://example.org/stuff/1.0/"> 5. <rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"> 6. <dc:title>RDF/XML Syntax Specification (Revised)</dc:title> 7. <exterms:editor rdf:nodeID="abc"/> 8. </rdf:Description> 9. <rdf:Description rdf:nodeID="abc"> 10. <exterms:fullName>Dave Beckett</exterms:fullName> 11. <exterms:homePage rdf:resource="http://purl.org/net/dajobe/"/> 12. </rdf:Description> 13. </rdf:RDF>
例6の9行目では、空白ノード識別子abcがいくつかのステートメントの主語として空白ノードを識別するために使用され、7行目では、空白ノードが資源のexterms:editorプロパティーの値であると示すために使用されています。[RDF-SYNTAX]で記述されている他のいくつかの方法と比べて、空白ノード識別子を使用することの利点は、空白ノード識別子を使用すると、同じRDF/XMLドキュメントの複数の場所で同じ空白ノードを参照できるということです。
最後に、2.4項で記述した型付きリテラルは、これまでの例で使用したプレーン・リテラルの代りに、プロパティー値として使用できます。型付きリテラルは、そのリテラルを含んでいるプロパティー要素にデータ型URIrefを指定しているrdf:datatype属性を加えることにより、RDF/XMLで表現されます。
例えば、例2のステートメントを変更して、exterms:creation-dateプロパティーに対するプレーン・リテラルではなく型付きリテラルを使用すると、トリプル表現は以下のようになります。
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
これに対応するRDF/XML構文は、例7で示しているようになります。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date rdf:datatype=
"http://www.w3.org/2001/XMLSchema#date">1999-08-16
</exterms:creation-date>
6. </rdf:Description>
7. </rdf:RDF>
例7の5行目では、rdf:datatype属性を要素の開始タグに加えてデータ型を指定することにより、型付きリテラルがexterms:creation-dateプロパティー要素の値として提供されています。この属性の値は、データ型のURIrefで、この事例ではXMLスキーマのdateデータ型のURIrefです。これが属性値であるため、トリプルで使用されるQNameの省略形xsd:dateを使用するのではなく、URIrefをすべて書き出さなければなりません。その後、このデータ型に適したリテラルが要素のコンテンツとして書かれ(この事例では、1999-08-16というリテラル)、これはXMLスキーマのdateデータ型の1999年8月16日をリテラルで表現したものです。
この入門書の残りの例では、リテラルの値が意図する解釈に関してより多い情報を伝える際に型付きリテラルの値を強調するために、プレーンな(型付きでない)リテラルではなく適切なデータ型の型付きリテラルを使用するでしょう。(例外は、型付きリテラルを現在使用していない実際のアプリケーションの例では、これらのアプリケーションの用法を正確に反映するために、プレーン・リテラルが使用され続けるということでしょう。)RDF/XMLでは、プレーン・リテラルと型付きリテラルの両方(そして、若干の例外があるが、タグ)は、ユニコード[UNICODE]の文字を含むことができ、これによって多くの言語による情報を直接表現できます。
例7は、型付きリテラルを使用するためには、型付きリテラルを値として持つ要素ごとにデータ型を識別するURIrefを持つrdf:datatype属性を書く必要があるということを示しています。以前に指摘したように、RDF/XMLでは、QNameとして省略するのではなく、属性値として使用されるURIrefをすべて書き出す必要があります。このような場合には、RDF/XMLでは、URIrefに省略機能を追加提供することによって、XMLエンティティーを使用して読み易さを改善できます。本質的に、XMLエンティティー宣言は、名前を文字列に関連づけます。エンティティー名がXMLドキュメント内の他の場所で参照されていれば、XMLプロセッサはその参照を対応する文字列に置き換えます。例えば、以下のようなENTITY宣言(RDF/XMLドキュメントの冒頭でDOCTYPE宣言の一部として指定される)
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
は、エンティティーxsdが、XMLスキーマ・データ型に対する名前空間URIrefを表現している文字列であると定義しています。この宣言によって、XMLドキュメントの他の場所で完全な名前空間URIrefをエンティティー参照 &xsd;で省略形にできます。この省略形を使用すれば、例7は例8で示されているように書くことができます。
1. <?xml version="1.0"?>2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.org/terms/">
5. <rdf:Description rdf:about="http://www.example.org/index.html">
6. <exterms:creation-date rdf:datatype="&xsd;date">1999-08-16
</exterms:creation-date>
7. </rdf:Description>
8. </rdf:RDF>
2行目のDOCTYPE宣言では、6行目で使用されているエンティティーxsdを定義しています。
RDF/XMLでは、省略の手段としてXMLエンティティーを使用することはオプションであり、したがって、XMLのDOCTYPE宣言の使用もRDF/XMLではオプションです。(XMLに慣れている読者にとっては、RDF/XMLは「整形式の」XMLである必要があるだけです。RDF/XMLは、XML検証プロセッサによってDTDに対する妥当性を検証するように設計されていません。これに関しては、付録Bでより全面的に論じ、XMLに関する追加情報を提供します。
読み易さを考慮して、入門書の残りの例では、今しがた記述したようにXMLエンティティーxsdを使用します。XMLエンティティーに関する詳細は、付録Bで論じます。付録Bで示しているように、他のURIref(そして、より一般的に言えば、他の文字列)もXMLエンティティーを使用して省略できます。しかし、この入門書の例の中でこの方法で省略されるのは、XMLスキーマ・データ型に対するURIrefのみです。
RDF/XMLを省略形で書く方法は他にもありますが、今までに示した機能は、RDF/XMLでグラフを表現するための簡単だが一般的な方法を提供します。これらの機能を使用して、RDFグラフを以下のようなRDF/XMLで書くことができます。
rdf:Description要素の主語として順にリストアップされ、ノードがURIrefを持つ場合にはrdf:about属性を、ノードが空白である場合にはrdf:nodeIDを使用します。rdf:resource属性(目的語ノードにURIrefがある場合)か、トリプルの目的語を指定するrdf:nodeID属性(目的語ノードが空白である場合)のいずれかを使用して適切なプロパティー要素が作成されます。[RDF-SYNTAX]で記述した一部のさらに省略化した方法に比べ、このシンプルなアプローチは、実際のグラフ構造を最も直接的に表現し、出力されたRDF/XMLを以後のRDF処理に使用するアプリケーションに対して特に推奨されます。
今までの例では、既に記述した資源にはURIrefが付与されていると見なしてきました。例えば、最初の例では、URIrefがhttp://www.example.org/index.htmlであるexample.orgのウェブ・ページに関する記述情報を提供しました。完全なURIrefを引用しているrdf:about属性を使用してこの資源をRDF/XMLで識別しました。RDFは、URIrefを資源に割り当てる方法を指定したり制御したりしませんが、組織化された資源のグループの一部にURIrefを割り当てて効果を得るのが望ましい時もあります。例えば、スポーツ用品の会社(example.com)が、テントやハイキング用ブーツなどの自社製品のRDFベースのカタログを、http://www.example.com/2002/04/productsで識別されるRDF/XMLドキュメントとして提供したいと思っていると仮定します。この資源では、各製品には別々のRDF記述が与えられます。この記述の1つと一緒に、このカタログ(「Overnighter」という型のテントのカタログの項目)は、例9で示しているようにRDF/XMLで書くことができます。
1. <?xml version="1.0"?> 2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:exterms="http://www.example.com/terms/"> 5. <rdf:Description rdf:ID="item10245"> 6. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model> 7. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps> 8. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight> 9. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize> 10. </rdf:Description> ...other product descriptions... 11. </rdf:RDF>
例9では、記述されている資源(テント)のプロパティー(型(model)、収容人数(sleeping capacity)、重さ(weight))を表現する方法が、前の例と似ています。(これらを取り囲んで、xml、DOCTYPE、RDF、および名前空間情報が、1行目から4行目と11行目に含まれていますが、この情報はカタログ全体に対して1度提示すれば良く、カタログの項目ごとに繰り返す必要はありません。様々なプロパティー値に関連しているデータ型が明示されていても、これらのプロパティー値の一部に関連している単位は、その値を適切に解釈するためにはこの情報が必要であるにもかかわらず、示されていないということにも注意してください。プロパティーの値に関連している単位やこれに類似した情報の表現に関しては、4.4項で論じます。この例では、exterms:sleepsの値は、テントで寝ることができる人数で、exterms:weightの値はキログラムで示され、バックパックに占めるテントの面積であるexterms:packedSizeの値は平方センチメートルで示されています。)
前例との大きな違いは、5行目のrdf:Description要素が、rdf:about属性ではなくrdf:ID属性を持っているという点です。rdf:IDを使用すると、rdf:ID属性の値で示されたフラグメント識別子を、記述されている資源の完全なURIrefの省略形として指定できます(この事例では、item10245で、example.comが割り当てているカタログ番号です)。フラグメント識別子item10245は、基底URI(この事例では、含んでいるカタログ・ドキュメントのURI)と関連して解釈されます。テントに対する完全なURIrefは、(カタログの)基底URIに文字「#」を追加し(フラグメント識別子が後続することを示すために)、その後にitem10245を追加して作成されます(絶対URIref http://www.example.com/2002/04/products#item10245になる)。
rdf:ID属性は、現在の基底URI(この例では、カタログの)に対して一意でなければならない名前を定義するという点において、XMLやHTMLのID属性に多少似ています。この事例では、rdf:ID属性は、名前(item10245)をこの特定の種類のテントに割り当てているように見えます。このカタログ内の他のRDF/XMLでは、絶対URIref http://www.example.com/2002/04/products#item10245か相対URIref #item10245のどちらかを使用して、このテントを参照できます。この相対URIrefは、カタログの基底URIrefと関連して定義されたURIrefであると認識されます。同じ省略形を使用して、カタログの項目にrdf:ID="item10245"ではなくrdf:about="#item10245"を指定することにより(すなわち、相対URIrefを直接指定して)、テントのURIrefを示すこともできます。短縮の方法としては、この2つの形式は基本的に同義です。つまり、RDF/XMLによって作成される完全なURIrefは、どちらの場合でも同じhttp://www.example.com/2002/04/products#item10245です。しかし、rdf:ID属性の特定の値は同じ基底URI(この事例では、カタログ・ドキュメント)に対して一度だけしか出現できないため、rdf:IDを使用すると、一連の別々の名前を割り当てる際に追加確認できます。どちらの形式を使用しても、example.comは、2段階の過程でテントに対するURIrefを付与することになります。最初にカタログ全体にURIrefを割り当て、次に、カタログ内のテントの記述に相対URIrefを使用して、この特定の種類のテントに割り当てられたURIrefを示します。そのうえ、この相対URIrefの使用法は、RDFから独立してテントに割り当てられた完全なURIrefの省略形か、カタログ内のテントへのURIrefの割り当てかのどちらかであると考えられます。
カタログの外部にあるRDFは、完全なURIrefを使用することによって、すなわち、カタログの基底URIにテントの相対URIref #item10245を連結することによって(絶対URIref http://www.example.com/2002/04/products#item10245になる)、このテントを参照できます。例えば、exampleRatings.comというアウトドア・スポーツのウェブサイトでは、RDFを使用して様々なテントの格付けを提供できます。したがって、例9で記述したテントに対する(5つ星の)格付けは、exampleRatings.comのウェブサイトでは、例10のように表わすことができます。
1. <?xml version="1.0"?> 2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:sportex="http://www.exampleRatings.com/terms/"> 5. <rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245"> 6. <sportex:ratingBy rdf:datatype="&xsd;string">Richard Roe</sportex:ratingBy> 7. <sportex:numberStars rdf:datatype="&xsd;integer">5</sportex:numberStars> 8. </rdf:Description> 9. </rdf:RDF>
例10の5行目では、rdf:Description要素と、テントの完全なURIrefを値として持つrdf:about属性とを一緒に使用しています。このURIrefの使用すると、格付けで参照するテントを正確に識別できます。
これらの例では、いくつかのポイントを示しています。まず最初に、RDFは、URIrefを資源(この場合、カタログの様々なテントやその他の項目)に割り当てる方法を指定したり制御したりしなくても、1つのドキュメント(この場合、カタログ)をこれらの資源の記述の情報源として識別するプロセス(RDFの外部での)と、そのドキュメント内のこれらの資源の記述における相対URIrefの使用とを組み合わせることによって、RDFでURIrefの資源に割り当てるという効果を得ることができます。例えば、example.comは、このカタログを、製品の商品番号がこのカタログの項目になければexample.comが知らないものであるという理解のもとに、自社製品を記述している主要な情報源として使用できます。(RDFでは、2つの資源のURIrefが同じベースを持っているとか似ているとかいう理由だけでは、これらの資源の間に特殊な関係が存在すると仮定しないことに注意してください。example.comがこの関係について知っているかもしれませんが、RDFでは直接定義されません。)
これらの例では、ウェブの基本構造原理の1つも示しています。これは、だれでもが好きな語彙を使用して既存の資源に関する情報を自由に加えることができるというものです[BERNERS-LEE98]。さらに、これらの例では、特定の資源を記述しているRDFをすべて1か所に置く必要はなく、ウェブ全体に分散できることを示しています。これは、ある組織が、別の組織が定義した資源を格付けしたりコメントしたりするような状況にのみ当てはまるのではなく、資源を最初に定義した人(または、他の誰か)が、その資源に関する情報を追加して資源の記述を拡充したい状況にも当てはまります。これは、資源を最初に記述したRDFドキュメントを変更し、情報を追記するために必要なプロパティーと値を追加することで行えます。あるいは、この例で示しているように、別のドキュメントを作成し、rdf:aboutを使用してURIrefを通じて最初の資源を参照するrdf:Description要素にプロパティーと値を追加することもできます。
上の議論では、#item10245のような相対URIrefが基底URIと関連して解釈されるということを示しました。デフォルトでは、この基底URIは、相対URIrefが使用されている資源のURIです。しかし、この基底URIを明示的に指定できる方が良い場合もあります。例えば、example.orgがhttp://www.example.com/2002/04/productsにあるカタログに加え、ミラーサイト、例えばhttp://mirror.example.com/2002/04/productsでカタログの複製を提供したいと考えていると仮定してください。これは問題を引き起こします。なぜならば、ミラーサイトからカタログにアクセスした場合、例であげたテントに対するURIrefは、掲載されているドキュメントのURIから作成されるため、http://www.example.com/2002/04/products#item10245ではなくhttp://mirror.example.com/2002/04/products#item10245が作成され、したがって、明らかに意図した資源とは異なる資源を示すことになるからです。そうではなく、example.orgは、そのロケーションが基底を定義する1つのソース・ドキュメントを作成せずに、製品のURIrefの集合に基底URIrefを割り当てたい考えるかもしれませんと。
このようなケースに対応するために、RDF/XMLでは、XMLドキュメントが自身のURI以外の基底URIを指定できるXMLベース [XML-BASE]をサポートしています。例11では、XMLベースを使用してカタログを記述する方法を示しています。
1. <?xml version="1.0"?> 2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:exterms="http://www.example.com/terms/" 5. xml:base="http://www.example.com/2002/04/products"> 6. <rdf:Description rdf:ID="item10245"> 7. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model> 8. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps> 9. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight> 10. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize> 11. </rdf:Description> ...other product descriptions... 12. </rdf:RDF>
例11の5行目のxml:base宣言では、rdf:RDF要素内のコンテンツに対する基底URIがhttp://www.example.com/2002/04/productsであり(別のxml:base属性が指定されるまでは)、このコンテンツ内で引用されているすべての相対URIrefが、含んでいるドキュメントのURIがどのようなものであっても、そのベースに関連していると解釈されるということを明示しています。その結果、テントの相対URIrefである#item10245は、カタログ・ドキュメントの実際のURIがどのようなものであっても、または、基底URIrefが実際に特定のドキュメントを識別してもしなくても、同じ絶対URIref http://www.example.com/2002/04/products#item10245として解釈されます。
今までの例では、example.comのカタログのテントの特定の型という1つの製品の記述を使用してきました。しかし、example.comでは、恐らくいくつかの異なる型のテントを提供するでしょうし、それに加えて、バックパックやハイキング・ブーツなどのような他の製品カテゴリーの複数のインスタンスも提供するでしょう。事物を異なる種類やカテゴリーに分類するというこの考えは、オブジェクトが異る型やクラスを持つというプログラミング言語の概念に似ています。RDFでは、rdf:typeという定義済みプロパティーを提供することによってこの概念をサポートします。RDF資源をrdf:typeプロパティーで記述すると、そのプロパティーの値は事物のカテゴリーやクラスを表現する資源であると見なされ、そのプロパティーの主語はそのカテゴリーやクラスのインスタンスであると考えられます。例12では、製品の記述がテントに関するものであることを、example.comがrdf:typeを使用してどのように示せるのかを表しています。
1. <?xml version="1.0"?> 2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:exterms="http://www.example.com/terms/" 5. xml:base="http://www.example.com/2002/04/products"> 6. <rdf:Description rdf:ID="item10245"> 7. <rdf:type rdf:resource="http://www.example.com/terms/Tent"/> 8. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model> 9. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps> 10. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight> 11. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize> 12. </rdf:Description> ...other product descriptions... 13. </rdf:RDF>
例12では、7行目のrdf:typeのプロパティーは、記述されている資源がURIref http://www.example.com/terms/Tentで識別されるクラスのインスタンスであることを示しています。ここでは、example.comは、自社の他の用語(プロパティーexterms:weightのような)の記述に使用するのと同じ語彙の一部としてこのクラスを記述していたと仮定しており、そのため、このクラスの絶対URIrefを使用してこれを参照しています。example.comが製品カタログ自体の一部としてこれらのクラスを記述していたならば、相対URIref #Tentを使用してこれを参照できたでしょう。
RDF自身は、この例のTentのような事物や、そのプロパティーであるexterms:weightのような事物をアプリケーション固有のクラスで定義する機能を提供しません。その代りに、そのようなクラスは、5項で論じたRDFスキーマ言語を使用してRDFスキーマで記述します。5.5項で述べたDAML+OIL言語やOWL言語のような、クラスを記述するための他の機能も定義できます。
RDFでは、資源がその資源を特定の型やクラスのインスタンスとして記述するrdf:typeプロパティーを持っていることは、極めて普通のことです。このような資源を、グラフでは型付きノード(typed node)と呼び、一方、RDF/XMLでは型付きノード要素(typed node element)と呼びます。RDF/XMLでは、この型付きノードを記述するための特別な省略形を提供しています。この省略形では、rdf:typeプロパティーとその値が削除され、ノードに対するrdf:Description要素は、この削除されたrdf:typeプロパティー(クラスを命名するURIref)の値に対応するQNameという名前を持つ要素に置き換えられます。この省略形を使用すると、例12のexample.comのテントは例13で示しているように記述することも可能です。
1. <?xml version="1.0"?> 2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 4. xmlns:exterms="http://www.example.com/terms/" 5. xml:base="http://www.example.com/2002/04/products"> 6. <exterms:Tent rdf:ID="item10245"> 7. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model> 8. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps> 9. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight> 10. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize> 11. </exterms:Tent> ...other product descriptions... 12. </rdf:RDF>
資源は、複数のクラスのインスタンスとして記述できるため、複数のrdf:typeプロパティーを持つことができます。しかし、この方法ではこれらのrdf:typeプロパティーの1つしか省略形にできません。他のものは、例12のrdf:typeプロパティーで示した方法で、rdf:typeを使用してすべて書き出さなければなりません。
exterms:Tentなどのユーザ定義クラスのインスタンスを記述する際の使用に加え、4項で述べた組み込みRDFのクラス(rdf:Bagのような)や、5項で述べた組み込みRDFスキーマ・クラス(rdfs:Classのような)のインスタンスを記述する場合に、RDF/XMLでは型付きノード省略も一般的に使用されます。
例12と例13はどちらも、(RDFではなく)XMLで直接書くのと極めて似た方法で、RDF/XMLでRDFステートメントを記述できるということを示しています。これは、情報の構造化方法に大きな変更を要さずにアプリケーションでRDFを使用できるということを意味するため、あらゆる種類のアプリケーションでXMLの使用が増加していることを考慮すると、重要な検討材料となります。
上例では、RDF/XML構文の背景にある基本概念の一部について説明しました。これらの例では、有用なRDF/XMLを書き始めるのに十分な情報を提供しています。XMLでのRDFステートメントのモデリングの背景にある原理(ストライピングとして知られている)に関するさらに徹底的な議論は、利用可能なその他のRDF/XML省略形や、XMLによるRDFの記述に関する詳細や例とともに、RDF/XML構文仕様(規範)[RDF-SYNTAX]で提供します。
RDFでは、一連の資源やRDFステートメントを表現するための組み込み型やプロパティー、プロパティー値としてXMLフラグメント(XML fragment)を表現する性能のような、さらに多くの性能を提供しています。以下の項ではこれらの付加的な性能に関して記述しています。
事物のグループを記述する必要がしばしばあります。例えば、数人の作者がある本を書いたと述べたり、あるコースの受講生やパッケージ内のソフトウェア・モジュールをリストアップする場合がこれに当たります。RDFでは、このようなグループを記述するために使用できる、いくつかの定義済みの(組み込み)型とプロパティーを提供しています。
最初に、RDFでは、3つの定義済みの型(いくつかの定義済みプロパティーと一緒に)で構成されるコンテナ語彙を提供しています。コンテナは、事物を含んでいる資源です。含まれている事物をメンバーと呼びます。コンテナのメンバーは、資源(空白ノードを含む)あるいはリテラルであることができます。 RDFでは、以下の3種類のコンテナを定義しています。
rdf:Bagrdf:Seqrdf:AltBag(型rdf:Bagを持つ資源)は、資源やリテラルのグループを表し、複製のメンバーを恐らく含んでいますが、メンバーの順序は重要ではありません。例えば、Bagは、部品番号の項目の順序や処理が重要でない部品番号のグループを記述するために使用できます。
順序(Sequence)を意味するSeq(型rdf:Seqを持つ資源)は、資源やリテラルのグループを表し、複製のメンバーを恐らく含んでおり、メンバーの順序が重要です。例えば、Sequenceは、アルファベット順に維持しなければならないグループを記述するために使用できます。
代替(Alternative)を意味するAlt(型rdf:Altを持つ資源)は、(通常は、プロパティーの1つの値に対する)代替である資源やリテラルのグループを表します。例えば、Altは、本のタイトルの別言語訳を記述したり、資源が掲載されている代替インターネット・サイトのリストを記述するために使用できます。Altコンテナを値として持つプロパティーを使用するアプリケーションは、グループのメンバーのどれか1つを適切であるとして選択できるということを認識する必要があります。
これらのコンテナの型の1つとして資源を記述するために、資源には、定義済み資源であるrdf:Bag、rdf:Seq、rdf:Altのうちの1つ(適切なものであればどれでもよい)を値として持つrdf:typeプロパティーが付与されています。コンテナ資源(空白ノードまたはURIrefを持つ資源のどちらか)は、グループを全体として表します。コンテナのメンバーは、コンテナ資源を主語として、そして、そのメンバーを目的語として持つメンバーごとにコンテナ・メンバーシップ・プロパティーを定義することによって記述できます。これらのコンテナ・メンバーシップ・プロパティーは、rdf:_nという形式名を持っており、nは、rdf:_1、rdf:_2、rdf:_3などのような、0が先行しない0以上の10進整数であり、特別にコンテナのメンバーを記述するために使用されます。コンテナ・メンバーシップ・プロパティーとrdf:typeプロパティーに加え、コンテナ資源にはコンテナを記述するプロパティーは他にもあります。
これらのコンテナの型が定義済みのRDF型やプロパティーを使用して記述される一方で、Altコンテナのメンバーは代替値であるなどの、これらのコンテナに関連している特別な意味は、意図した意味のみであるということを理解していることが重要です。これらの特別なコンテナ型とその定義は、事物のグループを記述する必要がある人々の間に共有の慣習を定める目的で提供されています。RDFが行うのは、RDFグラフを作成するために使用できる型とプロパティーを提供し、各型のコンテナを記述することのみです。RDFは、(3.2項で論じた)型ex:Tentの資源が何であるかを理解しないのと同じように、型rdf:Bagの資源が何であるかを理解するように作られていません。その都度、各型に伴う特別な意味に従って動作するようにアプリケーションを書かなければなりません。この点に関しては、以下の例で詳しく述べます。
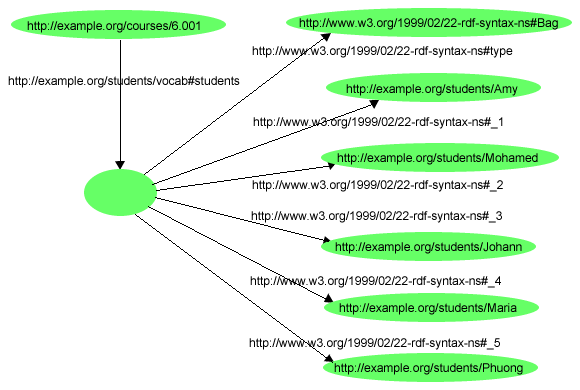
一般的に、プロパティーの値が事物のグループであるということを示すためにコンテナを使用します。例えば、「6.001のコースには、Amy、Mohamed、Johann、Maria、Phuongという生徒がいる」という文章を表現する場合、型rdf:Bagのコンテナを値として持つ(学生のグループを意味する)s:studentsプロパティーを(適切な語彙から)付与することによって記述できます。次に、コンテナ・メンバーシップ・プロパティーを使用しすれば、図14で示すRDFグラフのように、個々の学生がそのグループのメンバーであると識別できます。
この例のs:studentsプロパティーの値がBagと記述されているため、グラフのメンバーシップ・プロパティーの名前に整数が含まれていても、学生のURIrefに付与されている順序は重要ではありません。メンバーシップ・プロパティーの名前の(明らかな)順番を無視するかどうかは、rdf:Bagコンテナを含んだグラフを作成、処理するアプリケーション次第です。
RDF/XMLでは、このようなコンテナをより簡単に記述するために、いくつかの特別な構文と省略形を提供しています。例えば、例14では、図14で示したグラフを記述しています。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students>
<rdf:Bag>
<rdf:li rdf:resource="http://example.org/students/Amy"/>
<rdf:li rdf:resource="http://example.org/students/Mohamed"/>
<rdf:li rdf:resource="http://example.org/students/Johann"/>
<rdf:li rdf:resource="http://example.org/students/Maria"/>
<rdf:li rdf:resource="http://example.org/students/Phuong"/>
</rdf:Bag>
</s:students>
</rdf:Description>
</rdf:RDF>
例14では、RDF/XMLは各メンバーシップ・プロパティーを明示的に番号付けする必要性を避けるための便宜的な要素としてrdf:liを提供するということを示しています。rdf:_1、rdf:_2などの番号付けされたプロパティーは、対応するグラフを形成する時にこのrdf:li要素から生成されます。rdf:liという要素名は、HTMLの「リスト項目」(list item)という用語と調和するように選ばれました。また、<s:students>プロパティー要素内に入れ子にされている<rdf:Bag>要素の使用にも注意してください。<rdf:Bag>要素は、型のインスタンス(この場合、rdf:Bagのインスタンス)を記述する際に、rdf:Description要素とrdf:type要素の2つを1つの要素に置き換える、例13で使用した省略形の別の例です。URIrefが指定されていないため、Bagは空白ノードです。<s:students>プロパティー要素内にBagを入れ子にすることは、空白ノードがこのプロパティーの値であることを省略形で示すための方法です。これらの省略形の詳細については、[RDF-SYNTAX]で記述しています。
rdf:Seqコンテナのグラフ構造と、対応するRDF/XMLはrdf:Bagのものと似ています(唯一の違いは、rdf:Seqという型だけです)。繰り返しになりますが、rdf:Seqコンテナは順序を記述するためのものですが、整数値のプロパティー名の順序を適切に解釈するかどうかは、グラフを作成、処理するアプリケーション次第です。
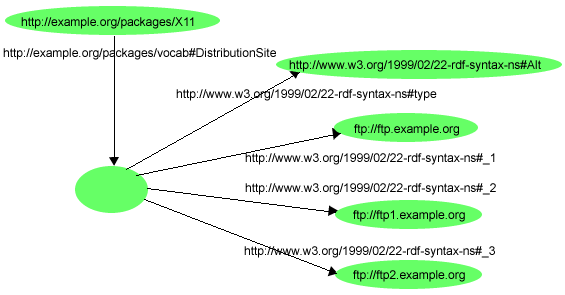
Altコンテナの例をあげると、「X11のソースコードは、ftp.example.orgや、ftp1.example.org、ftp2.example.orgに掲載されている」という文章は、図15のRDFグラフで表現できます。
例15は、図15のグラフをどのようにRDF/XMLで記述できるかを示しています。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/packages/vocab#">
<rdf:Description rdf:about="http://example.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:li rdf:resource="ftp://ftp.example.org"/>
<rdf:li rdf:resource="ftp://ftp1.example.org"/>
<rdf:li rdf:resource="ftp://ftp2.example.org"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Altコンテナは、プロパティーrdf:_1で識別される少なくとも1つのメンバーを持つように作られています。このメンバーは、デフォルト値、または優先値とみなされるようになっています。rdf:_1で識別されるメンバー以外の要素の順序は重要ではありません。
図15のRDFは、書いてあるとおり、s:DistributionSiteというサイト・プロパティーの値はAltコンテナ資源自身であると単に述べています。Altコンテナのメンバーの1つはs:DistributionSiteサイト・プロパティーの値とみなされるとか、ftp://ftp.example.orgはデフォルト値、または優先値であるといった、このグラフから読み取られる別の意味は、アプリケーションが理解できるAltコンテナの意味として組み込まれていなければならず、そして/または、特定のプロパティー(この場合、s:DistributionSite)に対して定義されている意味に組み込まれていなければならず、アプリケーションはこれも理解しなければなりません。
Altコンテナは言語のタグ付けとの連結で頻繁に使用されます。(RDF/XMLでは、[XML]で定義されているxml:lang属性を使用して、要素コンテンツが特定の言語であることを示すことができます。xml:langの使用に関しては、[RDF-SYNTAX]で説明し、6.2項で例示しています。)例えば、ある著作のタイトルが複数の言語に翻訳されている場合、各言語で表されたタイトルを表現するリテラルを持ったAltコンテナを指すtitleプロパティーを持つことができます。
BagとAltが意図する意味の違いに関しては、「ハックルベリー・フィンの冒険」という本の原作者を検討することによって詳細に示すことができます。この本の著者は1人だけですが、この著者は2つの名前(Mark TwainとSamuel Clemens)を持っています。この著者を指定するためには、どちらの名前でも十分です。したがって、著者名にAltコンテナを使用すると、Bagを使用するよりも(2人の別々の著者がいることを意味しうる)正確に関係を表現できます。
ユーザは、RDFコンテナ語彙を使用せずに、資源のグループを記述する方法を自由に選択できます。このRDFコンテナは、一般的に使用されている場合には、資源のグループを含むデータをより相互運用可能にしてくれる共通の定義として提供されているだけです。
このRDFコンテナ型を使用するよりも明確な代替手段が存在することもあります。例えば、特定の資源と他の資源のグループとの関係は、同じプロパティーを使用して最初の資源を複数のステートメントの主語にすることによって示すことができます。これは、複数のメンバーを含んだコンテナを目的語として持つ1つのステートメントの主語である資源とは構造的に異なります。これらの2つの構造は同じ意味を持っている場合もあれば、そうでない場合もあります。ある状況においてどちらを使用するかは、この点を念頭に置いて選択する必要があります。
一例として、以下の文章のような、作家とその出版物との関係を考えてみてください。
Sueは、「Anthology of Time」と「Zoological Reasoning」「Gravitational Reflections」を著しました。
この場合、同じ作家が別々に書いた3つの資源があります。これは、プロパティーを繰り返し使用して、以下のように表現できます。
exstaff:Sue exterms:publication ex:AnthologyOfTime . exstaff:Sue exterms:publication ex:ZoologicalReasoning . exstaff:Sue exterms:publication ex:GravitationalReflections .
この例では、同じ人物が書いたということ以外、これらの出版物間の関係は何も述べられていません。各ステートメントは独立した事実であるため、プロパティーを繰り返し使用することは合理的な選択といえます。しかし、これは、以下のように、Sueが書いた資源のグループのステートメントでも全く同じく合理的に表現できます。
exstaff:Sue exterms:publication _:z . _:z rdf:type rdf:Bag . _:z rdf:_1 ex:AnthologyOfTime . _:z rdf:_2 ex:ZoologicalReasoning . _:z rdf:_3 ex:GravitationalReflections .
その一方で、以下の文章
Fred、Wilma、Dinoというメンバーの議事運営委員会によって決議案が承認されました。
は、委員会が全体で決議案を承認したと述べていますが、各委員が個別に決議案に賛成票を投じたとは必ずしも述べていません。この場合、この文章を以下のように3つの別々のexterms:approvedBy(委員ごとに1つの)ステートメントとしてモデル化すると、誤解を招く恐れがあります。
ex:resolution exterms:approvedBy ex:Fred . ex:resolution exterms:approvedBy ex:Wilma . ex:resolution exterms:approvedBy ex:Dino .
なぜならば、これらのステートメントは、各委員が個別に決議案を承認したと述べているからです。
この場合、主語が決議案で、目的語が委員会自体である、1つのexterms:approvedByステートメントとして文章をモデル化する方が良いでしょう。以下のトリプルのように、委員会の委員をメンバーとするBagとして委員会の資源を記述できます。
ex:resolution exterms:approvedBy ex:rulesCommittee . ex:rulesCommittee rdf:type rdf:Bag . ex:rulesCommittee rdf:_1 ex:Fred . ex:rulesCommittee rdf:_2 ex:Wilma . ex:rulesCommittee rdf:_3 ex:Dino .
RDFコンテナを使用する際には、ステートメントは、プログラミング言語のデータ構造のように、コンテナを構築していないということを理解することが重要です。その代わりに、ステートメントは、存在していると推定されるコンテナ(事物のグループ)を記述しています。例えば、上記の議事運営委員会の例では、RDFでそのように記述しているか否かに関係なく、議事運営委員会は順不同のグループです。例えば、資源ex:rulesCommitteeは型rdf:Bagを持っていると述べることは、議事運営委員会がデータ構造であると述べているのでも、グループの委員を保持するための特定のデータ構造を構築しているのでもありません(委員を全く記述せずに議事運営委員会をBagとして記述できます)。そうではなく、議事運営委員会はBagコンテナに関連しているものに対応した特性を持っている、すなわち委員を持っており、その記述の順序は重要ではないと記述しています。同様に、コンテナ・メンバーシップ・プロパティーを使用すると、コンテナ資源は、ある事物をメンバーとして持つと単に記述していることになります。これは、メンバーとして記述されている事物のみが、存在しているメンバーであると必ずしも述べているわけではありません。例えば、議事運営委員会を記述するために上で示したトリプルは、Fred、Wilma、Dinoが委員会のメンバーであると述べているだけで、彼らのみが委員会のメンバーであるとは述べていません。
また、例14と例15では、関連するコンテナの型とは無関係に、コンテナを記述する際の共通の「パターン」を示しました(例えば、コンテナ自体を表現するために適切なrdf:typeプロパティーで空白ノードを使用したり、連番付けされたコンテナ・メンバーシップ・プロパティーを生成するためにrdf:liを使用した)。しかし、RDFでは、RDFコンテナ語彙を使用するこの特別な方法を強制しないため、この語彙を他の方法で使用できるということを理解することが重要です。例えば、空白ノードを使用するのではなく、URIrefを持っているコンテナ資源を使用する方が適切な場合もあります。さらに、前の例で示した「整形式」(well-formed)の構造を持つグラフを記述せずに、コンテナ語彙を使用できます。例えば、例16では、例15で示したAltコンテナに似たグラフのRDF/XMLを示していますが、rdf:liを使用してコンテナ・メンバーシップ・プロパティーを生成するのではなく、それを明示的に書きます。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/packages/vocab#">
<rdf:Description rdf:about="http://example.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_2 rdf:resource="ftp://ftp.example.org"/>
<rdf:_2 rdf:resource="ftp://ftp1.example.org"/>
<rdf:_5 rdf:resource="ftp://ftp2.example.org"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
[RDF-SEMANTICS]で指摘しているように、RDFではコンテナ語彙の使用に「整形式性」(well-formedness)の条件を課さないため、BagとAltの両方としてコンテナを記述しているにも関わらず、例16は完全に正当で、このコンテナには、rdf:_2プロパティーの2つの異なる値があり、rdf:_1、rdf:_3、rdf:_4プロパティーがないと記述されています。
その結果、コンテナが「整形式」であることを要するRDFアプリケーションが完全に強力であるためには、コンテナ語彙が適切に使用されていることを検証できるように書かれている必要があります。
4.1項で述べたコンテナの限界は、閉じる方法がない、すなわち「これらがコンテナのすべてのメンバーです」と述べる方法がないということです。4.1項で指摘したように、コンテナは、識別された特定の資源がメンバーであると述べるだけで、他のメンバーが存在しないとは述べません。また、1つのグラフはメンバの一部を記述できますが、別のメンバーを記述する別のグラフがどこかに存在する可能性を排除できません。RDFでは、指定されたメンバーのみを含むグループをRDFコレクションの形式で記述する方法をサポートしています。RDFコレクションは、RDFグラフでリスト構造として表現した事物のグループです。このリスト構造は、定義済み型rdf:List、定義済みプロパティーrdf:firstとrdf:rest、定義済み資源rdf:nilで構成される定義済みのコレクション語彙を使用して構成されています。
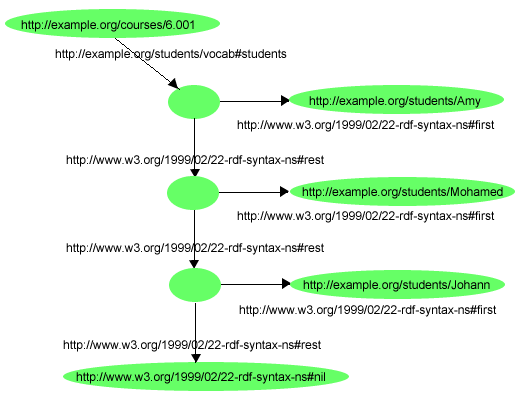
これを例示すると、図16で示したグラフを使用して「コース6.001の生徒は、Amy、Mohamed、Johannです」という文章は、表現できます。
このグラフでは、s:Amyなどのコレクションの各メンバーは、リストを表現する資源(この例では、空白ノード)を主語として持つrdf:firstプロパティーの目的語です。このリスト資源は、rdf:restプロパティーによってリストの残りにリンクされています。リストの終わりは、資源rdf:nilを目的語として持っているrdf:restプロパティーで示されます(資源rdf:nilは空のリストを表現し、型rdf:Listであると定義されています)。この構造は、Lispプログラミング言語を知っている人には馴染みがあるでしょう。Lispと同様に、rdf:firstプロパティーとrdf:restプロパティーによってアプリケーションが構造をトラバースできます。このリスト構造を形成する各空白ノードは、グラフには明示されませんが、暗黙的に型rdf:Listに属しています(すなわち、これらのノードはそれぞれ、定義済み型rdf:Listを値として持つrdf:typeプロパティーを暗黙的に持っています)。RDFスキーマ言語[RDF-VOCABULARY]は、プロパティーrdf:firstとrdf:restが型rdf:Listに属する主語を持っていると定義するため、対応するrdf:typeトリプルを何度も書き出さなくても、リストであるこれらのノードに関する情報は一般的に推論できます。
RDF/XMLでは、この形式のグラフを使用してコレクションの記述が簡単になる特別な表記法を提供しています。RDF/XMLでは、コレクションは属性rdf:parseType="Collection"を持ち、コレクションのメンバーを表現する入れ子になった要素のグループを含むプロパティー要素で記述できます。RDF/XMLでは、要素の内容が特別な方法で解釈されるということを示すためにrdf:parseType属性を提供しています。この場合、rdf:parseType="Collection"属性は、囲み込まれた要素を使用して、対応するリスト構造をRDFグラフで作成しているということを示しています(rdf:parseType属性のその他の値に関しては、この入門書の後の項で述べます)。
rdf:parseType="Collection"がどのように作用するかを例示すると、例17のRDF/XMLは、図16で示したRDFグラフになります。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.org/students/Amy"/>
<rdf:Description rdf:about="http://example.org/students/Mohamed"/>
<rdf:Description rdf:about="http://example.org/students/Johann"/>
</s:students>
</rdf:Description>
</rdf:RDF>
RDF/XMLでrdf:parseType="Collection"を使用すると、図16で示したようなリスト構造を常に定義します。すなわち、一定の長さがある固定された有限の項目リストで、rdf:nilで終了し、リスト構造自体に一意な「新しい」空白ノードを使用します。しかし、RDFは、RDFコレクション語彙を使用するこの特定の方法を強制しないため、他の方法でこの語彙を使用でき、その中には、リストや閉じたコレクションを記述しないものもあります。この理由を理解するためには、図16で示したグラフは、例18のようにコレクション語彙を使用して、同じトリプルを「通常の表記法で」(rdf:parseType="Collection"を使用せずに)書き出すことによって、RDF/XMLでも書くことができるということに注意する必要があります。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students rdf:nodeID="sch1"/>
</rdf:Description>
<rdf:Description rdf:nodeID="sch1">
<rdf:first rdf:resource="http://example.org/students/Amy"/>
<rdf:rest rdf:nodeID="sch2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="sch2">
<rdf:first rdf:resource="http://example.org/students/Mohamed"/>
<rdf:rest rdf:nodeID="sch3"/> </rdf:Description>
<rdf:Description rdf:nodeID="sch3">
<rdf:first rdf:resource="http://example.org/students/Johann"/>
<rdf:rest rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/>
</rdf:Description>
</rdf:RDF>
[RDF-SEMANTICS]で指摘したように(そして、4.1項で述べたコンテナ語彙の場合と同様に)、RDFはコレクション語彙の使用に「整形式性」の条件を課さないため、通常の表記法でトリプルを書く際に、rdf:parseType="Collection"を使用して自動的に生成される明確な構造の(well-structured)グラフ以外の構造を持つRDFグラフを定義できます。例えば、特定のノードが2つの異なるrdf:firstプロパティーの値を持つと言明したり、末尾が分岐したりリストではない構造を作成したり、単にコレクションの記述の一部を省略することは、不正ではありません。また、通常の表記法でコレクション語彙を使用して定義したグラフは、リスト構造に一意な空白ノードではなく、リストの構成要素を識別するためにURIrefを使用できます。その場合には、コレクションが閉じないように、効果的に要素をコレクションに追加した他のグラフでトリプルを作成できるでしょう。
その結果、コレクションが整形式であることを要するRDFアプリケーションが完全に強力であるためには、コレクション語彙が適切に使用されていることを検証できるように書かれている必要があります。さらに、RDFグラフの構造に制約を追加定義できるOWL [OWL]のような言語では、これらのケースの一部を除外できます。
RDFアプリケーションは、RDFを使用して他のRDFステートメントに関して記述する必要がある場合もあります。例えば、ステートメントをいつ作成したのかや、その他の類似の情報を記録する場合などです(これを「来歴」情報と呼ぶことがあります)。例えば、3.2項の例9では、example.comが販売用に提供している、URIref exproducts:item10245を持つ特定のテントを記述しました。この記述で示したトリプルの1つは、以下の通り、テントの重さを記述したものでした。
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
そして、誰がこの特定の情報を提供しているのかをexample.comが記録していると便利です。
RDFでは、RDFステートメントを記述するための組み込み語彙を提供しています。この語彙を使用したステートメントの記述を、ステートメントの具体化(reification)と呼びます。RDF具体化語彙は、型rdf:Statement、プロパティーrdf:subject、rdf:predicate、rdf:objectから成ります。しかし、RDFではこの具体化語彙を提供していますが、使用には注意が必要です。なぜならば、実際には定義されていない事物を語彙が定義していると推測しがちだからです。この点の詳細に関しては、この項の後半で論じます。
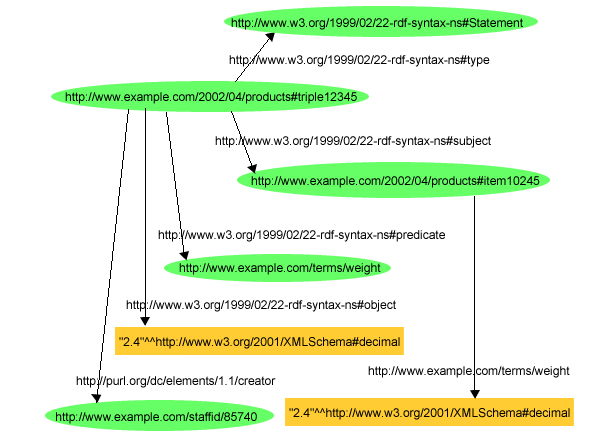
具体化語彙を使用して、exproducts:triple12345のようなURIrefをステートメントに割り当て(したがって、テントの重さを記述したステートメントを書くことができる)、以下のように、ステートメントを使用してステートメントを記述することによって、テントの重さに関するステートメントを具体化できます。
exproducts:triple12345 rdf:type rdf:Statement . exproducts:triple12345 rdf:subject exproducts:item10245 . exproducts:triple12345 rdf:predicate exterms:weight . exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
これらのステートメントでは、URIref exproducts:triple12345で識別される資源はRDFステートメントであり、ステートメントの主語はexproducts:item10245で識別される資源を示し、ステートメントの述語はexterms:weightで識別される資源を示し、ステートメントの目的語は型付きリテラル"2.4"^^xsd:decimalで識別される十進数の値を示すと述べています。最初のステートメントが実際にexproducts:triple12345で識別されていると仮定すると、この最初のステートメントと具体化を比較することで、具体化が本当にそれを記述していることが明らかにならなければなりません。RDF具体化語彙を使用すると、通常は、常にこのパターンの4つのステートメントを使用してステートメントを記述することになり、そのため、この4つのステートメントを「具体化の四つ組み(reification quad)」と呼ぶことがあります。
この規定に準じた具体化を使用して、example.comでは、まず、最初のステートメントをURIref(前と同じ、exproducts:triple12345など)に割り当てて先ほど説明した具体化を使用してステートメントを記述し、次に、John Smithがexproducts:triple12345を書いたという追加ステートメントを加えることによって(どのJohn Smithなのかを識別するためにURIrefを使用して)、John Smithがテントの重さに関する最初のステートメントを作成したという事実を記録できます。その結果、以下のようなステートメントになります。
exproducts:triple12345 rdf:type rdf:Statement . exproducts:triple12345 rdf:subject exproducts:item10245 . exproducts:triple12345 rdf:predicate exterms:weight . exproducts:triple12345 rdf:object "2.4"^^xsd:decimal . exproducts:triple12345 dc:creator exstaff:85740 .
最初のステートメントは、この具体化とJohn Smithに対するステートメントの属性と合わせると、図17で示すグラフになります。
このグラフは、例19で示しているようなRDF/XMLで書くことができます。
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.com/terms/"
xml:base="http://www.example.com/2002/04/products">
<rdf:Description rdf:ID="item10245">
<exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
</rdf:Description>
<rdf:Statement rdf:about="#triple12345">
<rdf:subject rdf:resource="http://www.example.com/2002/04/products#item10245"/>
<rdf:predicate rdf:resource="http://www.example.com/terms/weight"/>
<rdf:object rdf:datatype="&xsd;decimal">2.4</rdf:object>
<dc:creator rdf:resource="http://www.example.com/staffid/85740"/>
</rdf:Statement>
</rdf:RDF>
3.2項では、rdf:Description要素でRDF/XMLのrdf:ID属性を使用してステートメントの主語のURIrefを省略する方法を紹介しました。プロパティー要素でrdf:IDを使用して、プロパティー要素が生成するトリプルの具体化を自動的に作成することもできます。例20では、どのようにrdf:IDを使用して例19と同じグラフを作成できるかを示しています。
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.com/terms/"
xml:base="http://www.example.com/2002/04/products">
<rdf:Description rdf:ID="item10245">
<exterms:weight rdf:ID="triple12345" rdf:datatype="&xsd;decimal">2.4
</exterms:weight>
</rdf:Description>
<rdf:Description rdf:about="#triple12345">
<dc:creator rdf:resource="http://www.example.com/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
この事例では、exterms:weight要素で属性rdf:ID="triple12345"を指定すると、以下のようなテントの重さを記述した最初のトリプルになります。
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
さらに、以下のような具体化トリプルになります。
exproducts:triple12345 rdf:type rdf:Statement . exproducts:triple12345 rdf:subject exproducts:item10245 . exproducts:triple12345 rdf:predicate exterms:weight . exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
これらの具体化トリプルの主語は、ドキュメントの基底URI(xml:base宣言で示される)と、文字列「#」(これに続くものがフラグメント識別子であることを示すために)、そしてrdf:ID属性の値を連結して形成したURIrefです。すなわち、トリプルは、前の例と同じ主語exproducts:triple12345を持っています。
具体化を言明することは最初のステートメントを言明することと同じではなく、どちらももう一方を暗示しないことに注意してください。すなわち、Johnがテントの重さに関して何かを言ったと誰かが述べた場合、彼はテントの重さ自体に関するステートメントを作成しているのではなく、Johnが言ったことに関するステートメントを作成しているのです。逆に、誰かがテントの重さを記述する場合も、彼は、自作したステートメントに関するステートメントを作成しているのではありません(彼らには「ステートメント」と呼ばれるものに関して話す意図がないので)。
上記のテキストでは、意図的に多くの場所で「具体化の慣用的な使用法」を示しています。以前に指摘したように、実際には定義されていない事物を語彙が定義していると推測しがちであるため、RDF具体化語彙の使用には注意が必要です。具体化をうまく使用するアプリケーションもありますが、これは、RDFが具体化語彙に対して定義する実際の意味と、RDFがこの語彙をサポートするために提供する実際機能に加えて、いくつかの慣用法に従い、いくつかの仮定をすることによって実現しているのです。
一例をあげると、具体化の慣用的な使用法では、具体化トリプルの主語は、同じ主語、述語、目的語を持っているある任意のトリプルではなく、特定のRDFドキュメントのトリプルの特定のインスタンスを識別すると思われることに注意することが重要です。既に例示したように、具体化は、作成日や情報源のデータなどのプロパティーを表現するためのものであり、これらのプロパティーをトリプルの特定のインスタンスに適用する必要があるため、このような特定の慣用法が使用されます。1つのグラフが1組のトリプルとして定義されていたとしても、同じ主語、述語、目的語を持ったいくつかのトリプルが存在することは可能で、同じトリプルの構造を持ったいくつかのインスタンスが異なるドキュメントに出現しえます。したがって、この慣用法を完全にサポートするためには、具体化トリプルの主語をあるドキュメントの個体トリプルに関連付ける何らかの手段が必要です。しかし、RDFは、これを行う方法を提供していません。
例えば、上記の例では、テントの重さを記述している最初のステートメントは資源exproducts:triple12345で、この資源は4つの具体化ステートメントの主語であり、John Smithが作成したステートメントである、ということを実際に示している明示的な情報はトリプルにもRDF/XMLにもありません。これは、図17で示したグラフを見れば分かります。最初のステートメントは確かにこのグラフの一部ですが、グラフの情報に関する限り、exproducts:triple12345は別個の資源であり、グラフのその一部分を識別しているのではありません。RDFは、exproducts:triple12345のようなURIrefがどのように特定のステートメントやグラフと関連しているかを示す組み込み済みの手段を提供しないし、同じく、exproducts:item10245のようなURIrefがどのように実際のテントと関連しているかを示す組み込み済みの手段も提供しません。特定のURIrefを特定の資源(この場合は、ステートメント)に関連付けるには、RDFの以外のメカニズムを使用しなければなりません。
例20で示したようにrdf:IDを使用すれば、具体化が自動的に生成され、具体化におけるステートメントの主語としてURIrefが使用されていることを示す便利な方法が提供されます。さらに、rdf:ID属性の値triple12345が具体化トリプルの主語のURIrefを生成するために使用されるため、rdf:IDは、具体化におけるトリプルをそのトリプルを作成したRDF/XML構文の一部に関連付ける部分的な「フック」(hook)の機能を果たします。しかし、その結果生じるトリプルには最初のトリプルがURIref exproducts:triple12345を持っていたと明示的に述べるものが何もないため、この関係もまたRDF以外のものです(RDFは、使用されたり省略化されたURIrefとRDF/XMLとの間に関係があるとは見なしません)。
URIrefをステートメントに割り当てるための組み込み済みの手段がないということは、この種の「来歴」情報をRDFで表現できないということを意味しているのではなく、RDFが具体化語彙と関連している意味のみを使用しても表現できないということを意味しているだけです。例えば、RDFドキュメント(例えば、ウェブ・ページ)にURIがある場合、このURIで識別される資源に関するステートメントを作成でき、このステートメントをどのように解釈すべきかに関するあるアプリケーションに依存した理解に基づいて、それらのステートメントがドキュメントのすべてのステートメントにわたって「分散している」(等しく適用されている)かのようにアプリケーションは動作できます。また、個々のRDFステートメントにURIを割り当てるための何らかのメカニズムが(RDFの外部に)存在している場合、これらのステートメントを識別するためにこれらのURIを使用し、これらの個々のステートメントに関するステートメントを確実に作成できます。しかし、これらの場合にも、必ずしも慣用的な方法で具体化語彙を使用する必要はないでしょう。
これを理解するために、以下の最初のステートメント
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
が、URIref exproducts:triple12345を持っていると仮定すれば、具体化語彙を使用しなくても(exproducts:triple12345がrdf:type rdf:Statementを持っていると記述することは役立つかもしれないが)、以下のステートメントだけで、ステートメントがJohn Smithによるものであると考えることができます。
exproducts:triple12345 dc:creator exstaff:85740 .
さらに、上記で記述した慣用法に従って具体化語彙を直接使用でき、同様に、特定のトリプルをこの具体化に関連付ける方法に関してアプリケーションに依存した理解をすることもできます。しかし、このRDFを受け取る他のアプリケーションは、必ずしもこのアプリケーションに依存した理解を共有するわけではなく、したがって、必ずしも適切にグラフを解釈するわけではないでしょう。
ここで説明した具体化の解釈が、一部の言語で見られるような「引用」とは異なるものであることに注意することも重要です。そうではなく、具体化は、トリプルの特定のインスタンスとトリプルが示す資源との関係について記述します。具体化は、「このRDFトリプルは、この形式を持っている」と(引用のように)述べているのではなく、「このRDFトリプルは、これらの事物に関して述べている」と述べていると直観的に解することができます。例えば、この項で使用されている具体化の例では、最初のステートメントのrdf:subjectを記述している以下のトリプル
exproducts:triple12345 rdf:subject exproducts:item10245 .
は、ステートメントの主語がURIref exproducts:item10245で識別される資源(テント)であると述べています。これは、引用のように、ステートメントの主語がURIref自体(すなわち、特定の文字で始まる文字列)であるとは述べていません。
2.3項では、RDFモデルが本来、2項関係のみをサポートするということを指摘しました。すなわち、ステートメントは2つの資源間の関係を指定します。例えば、以下のステートメント
exstaff:85740 exterms:manager exstaff:62345 .
は、関係exterms:managerが2人の従業員の間(恐らく、1人がもう1人を管理する)で成立っていると述べています。
しかし、より多項な関係(3つ以上の資源間の関係)を含む情報をRDFで表現する必要がある場合もあります。これに関する1つの例を2.3項で論じました。そこでの問題は、John Smithと彼の住所情報との関係を表現することであり、John Smithの住所の値は、彼が住む通り、市、州、および郵便番号の構造化された値でした。これを関係として書くと、この住所は以下の形式の5項関係であることが分かります。
address(exstaff:85740, "1501 Grant
Avenue", "Bedford", "Massachusetts", "01730")
2.3項では、以下のトリプルのように、記述する集合物(ここでは、Johnの住所を表現する構成要素のグループ)を別個の資源として考え、以下のトリプルのように、その新しい資源に関する別々のステートメントを作成することによって、この種の構造化された情報をRDFで表現できることを指摘しました。
exstaff:85740 exterms:address _:johnaddress . _:johnaddress exterms:street "1501 Grant Avenue" . _:johnaddress exterms:city "Bedford" . _:johnaddress exterms:state "Massachusetts" . _:johnaddress exterms:postalCode "01730" .
(ここでは、_:johnaddressはJohnの住所を表現している空白ノードの空白ノード識別子です。)
これは、RDFのn項関係を表現する一般的な方法です。つまり、要素のうちの1つ(この場合、John)を選んで最初の関係の主語(この場合、address)として扱い、次に、中間の資源を指定して残りの関係を表現し(URLを割り当てたり、割り当てなかったりして)、その後に、その関係の残りの構成要素を表現するプロパティーをその新しい資源に付与します。
Johnの住所の場合、構造化された値の個々の部分は、どれもexterms:addressプロパティーの「主要な」値であるとは考えられず、住所のすべての部分は等しく値に寄与します。しかし、構造化された値の部分の1つが「主要な」値として考えられる場合もあり、その関係の他の部分は、主要な値を修飾する別のコンテキスト上の情報や他の情報を提供します。例えば、3.2項の例9では、特定のテントの重さを、型付きリテラルを使用して十進の値2.4として示しました。つまり、以下のとおりです。
exproduct:item10245 exterms:weight "2.4"^^xsd:decimal .
実際には、重さのより完全な記述は、単なる十進の値2.4ではなく、2.4キログラムでしょう。このように述べるためには、exterms:weightプロパティーの値は、十進の値に対する型付きリテラルと測定単位の表示(キログラム)という、2つの構成要素を持つ必要があります。このような状況では、この十進の値はexterms:weightプロパティーの「主要な」値であるとみなすことができます。なぜならば、述べられていない単位の情報を補うために、この値は、コンテキストの理解に依存してしばしば単に型付きリテラルとして記録される(上記のトリプルのように)からです。
RDFモデルでは、この種の修飾付きプロパティーの値は、単にもう1種類の構造化された値であるとみなすことができます。これを表現するために、別々の資源を使用して構造化された値(この場合、重さ)を全体として表現し、最初のステートメントの目的語として扱うことができます。次に、構造化された値の個々の部分を表現するプロパティーを、その資源に付与できます。この場合、十進数の値を表現する型付きリテラルに対するプロパティーと、単位に対するプロパティーがなければなりません。RDFは、定義済みrdf:valueプロパティーを提供し、構造化された値の主要な値(もし、あれば)を記述します。そのため、この場合、型付きリテラルをrdf:valueプロパティーの値として、資源exunits:kilogramsをexterms:unitsプロパティーの値として付与できます(資源exunits:kilogramsがexample.orgの語彙の一部として定義されていると仮定して)。結果として生じるトリプルは、以下のようになり、
exproduct:item10245 exterms:weight _:weight10245 . _:weight10245 rdf:value "2.4"^^xsd:decimal . _:weight10245 exterms:units exunits:kilograms .
例21で示すRDF/XMLを使用して表現できます。
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245">
<exterms:weight rdf:parseType="Resource">
<rdf:value rdf:datatype="&xsd;decimal">2.4</rdf:value>
<exterms:units rdf:resource="http://www.example.org/units/kilograms"/>
</exterms:weight>
</rdf:Description>
</rdf:RDF>
また、例21では、4.2項で紹介したrdf:parseType属性の2番目の使用も例示しており、この場合は、rdf:parseType="Resource"です。rdf:parseType="Resource"属性は、入れ子なったrdf:Descriptionを実際に書かなくても、要素のコンテンツが新しい(空白ノード)資源の記述として解釈されるということを示すために使用されます。この場合、exterms:weightプロパティー要素に使用されるrdf:parseType="Resource"は、空白ノードがexterms:weightプロパティーの値として作成され、囲み込まれている要素(rdf:valueとexterms:units)がその空白ノードのプロパティーを記述するということを示します。rdf:parseType="Resource"に関する詳細は、[RDF-SYNTAX]で示します。
rdf:valueプロパティーを使用して主要な値を付与し、プロパティーを追加使用してその値をより詳細に記述した分類体系やその他の情報を識別することによって、異なる分類体系やレイティング・システムからの値のみならず、どのような測定単位を使用した量でも同じアプローチを使用して表現できます。
このような目的のためにrdf:valueを使用する必要はなく(例えば、exterms:amountのようなユーザ定義のプロパティー名を、例21のrdf:valueの代わりに使用できる)、RDFではいかなる特別な意味もrdf:valueに関連づけません。このようなよく起こる状況では、rdf:valueは、単に使用の便宜上、提供されます。
しかし、データベースやウェブにある(そして入門書の後半の例の)大量の既存のデータが、重さ、コストなどのようなプロパティーに対してシンプルな値の形式をとっているにもかかわらず、このようなシンプルな値ではこれらの値を適切に記述するにはしばしば不十分であるという原則は重要です。ウェブのような世界規模の環境では、プロパティーの値にアクセスする誰かが、使用されている単位(または、関連があるかもしれない他のコンテキストに依存した情報)を理解すると仮定することは、一般に安全ではありません。例えば、米国のサイトでは重さの値をポンドで示しますが、米国以外からこのデータにアクセスする人は、重さがキログラムで示されていると思うかもしれません。ウェブ環境でデータを正しく解釈するには、追加情報(単位情報などの)を明示的に記録する必要があります。これは、個々のアイテムや製品の記述か、一連のデータ(例えば、カタログやサイトにおけるすべてのデータ)の記述か、スキーマか(5項を参照)のいずれかで、rdf:valueを使用したり、単位をプロパティー名に組み込んだり(例えば、exterms:weightInKg)、単位情報を含む特殊なデータ型を定義したり(例えば、extypes:kilograms)、他のユーザ定義のプロパティーを加えてこの情報を指定したり(例えば、exterms:unitOfWeight)といった、様々な方法で可能です。
プロパティーの値は、XMLのフラグメント、あるいはXMLマークアップを含んだテキストである必要がある場合があります。例えば、出版社が本や記事のタイトルを含んだRDFメタデータを維持していることがあります。このようなタイトルは、大抵はシンプルな文字列にすぎませんが、常にそうであるというわけではありません。例えば、数学の本のタイトルは、MathML [MATHML]を使用して表現できる数学の公式を含んでいることがあります。また、タイトルには、ルビ注釈 [RUBY]、または双方向レンダリングや特殊なグリフ異体字(例えば、[CHARMOD]を参照)のような、その他の理由でマークアップを含むことができます。
RDF/XMLでは、この種のリテラルを簡単に書くために特殊な表記法を提供しています。これは、rdf:parseTypeの3番目の値を使用して行います。要素に属性rdf:parseType="Literal"を付与することで、その要素のコンテンツがXMLフラグメントとして解釈されるということが示されます。例22は、rdf:parseType="Literal"の使用例を示しています。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:base="http://www.example.com/books">
<rdf:Description rdf:ID="book12345">
<dc:title rdf:parseType="Literal">
<span xml:lang="en">
The <em><br /></em> Element Considered Harmful.
</span>
</dc:title>
</rdf:Description>
</rdf:RDF>
例22のRDF/XMLでは、主語ex:book12345と述語dc:titleを持つ1つのトリプルを含むグラフを記述しています。RDF/XMLにおけるrdf:parseType="Literal"属性は、<dc:title>要素中のすべてのXMLが、dc:titleプロパティーの値であるXMLフラグメントであるということを示します。このグラフでは、この値は型付きリテラルであり、そのデータ型、rdf:XMLLiteralは、特にXMLのフラグメントを表現するために[RDF-CONCEPTS]で定義されています(XMLマークアップを含むことも含まないこともある文字シーケンスを含む)。XMLフラグメントは、XML排他的正規化勧告(XML Exclusive Canonicalization recommendation) [XML-XC14N]に従って正規化されています。これによって、使用された名前空間の宣言がフラグメントへの追加、統一した文字のエスケーピングまたはアンエスケーピング、空要素タグの展開、その他の変換が生じます。(これらの理由のために、そして、トリプル表記法自体がさらなるエスケーピングを要するという事実のために、実際の型付きリテラルはここでは示していません。RDF/XMLでは、RDFユーザがこれらの変換を直接処理しなくてもよいように、rdf:parseType="Literal"属性を提供しています。詳細に関心があれば、[RDF-CONCEPTS]と[RDF-SYNTAX]を参考にしてください。)xml:langやxml:baseのようなコンテキスト上の属性は、RDF/XMLドキュメントから引き継がれず、必要であれば、例で示したようにXMLフラグメントで明示的に指定しなければなりません。
この例では、RDFデータを設計する際に注意しなければならないことを示しています。一見したところでは、タイトルがプレーン・リテラルとして最もよく表現されたシンプルな文字列であるように見え、後になってはじめて、一部のタイトルにマークアップが含まれていることが分かるでしょう。属性の値がマークアップを含んだり含まなかったりすることがあるような場合には、rdf:parseType="Literal"を全体に使用するか、ソフトウェアがプレーン・リテラルと型rdf:XMLLiteralのリテラルの両方をプロパティーの値として処理するかのどちらかでなければなりません。
RDFは、名前付きプロパティーと値を使用して、資源に関するシンプルなステートメントを表現する方法を提供します。しかし、RDFユーザのコミュニティーには、これらのステートメントで使用するための語彙(用語)を定義する性能、特に、特定の種類やクラスの資源を記述していることを示す性能が必要で、これらの資源を記述する際に特定のプロパティー使用するでしょう。例えば、3.2項の例の会社、example.comは、exterms:Tentなどのクラスを記述したいと考え、exterms:modelやexterms:weightInKg、exterms:packedSizeなどのプロパティーを使用してこれを記述します(2.1項で論じたように、様々な「example」名前空間接頭辞を持つQNameは、これらの名前がRDFでは実際にURI参照であるということを気づかしてくれるものとして、ここではクラスやプロパティーの名前として使用されます)。同様に、書誌的な資源の記述に関心を持っている人々は、ex2:Bookやex2:MagazineArticleなどのクラスを記述したいと考え、ex2:authorやex2:title、ex2:subjectなどのプロパティーを使用してこれらを記述します。他のアプリケーションでは、ex3:Personやex3:Companyなどのクラス、そしてex3:ageやex3:jobTitle、ex3:stockSymbol、ex3:numberOfEmployeesなどのプロパティーを記述する必要があるかもしれません。RDF自体は、このようなアプリケーション固有のクラスとプロパティーを定義するための手段を提供しません。その代わりに、このようなクラスとプロパティーは、RDFスキーマと呼ばれる、RDF語彙記述言語1.0 [RDF-VOCABULARY]によって提供されるRDFの拡張を使用して、RDF語彙として記述されます。
RDFスキーマは、exterms:Tentやex2:Book、ex3:Personのようなアプリケーション固有のクラス、そしてexterms:weightInKgやex2:author、ex3:JobTitleのようなプロパティーの語彙を提供しません。その代わりに、このようなクラスとプロパティーを記述し、どのクラスとプロパティーが一緒に使用されると予期されるかを示すために必要な機能を提供します(例えば、ex3:Personを記述する際にプロパティーex3:jobTitleが使用されると述べる)。言い換えれば、RDFスキーマはRDFの型システムを提供します。RDFスキーマの型システムは、Javaなどのオブジェクト指向プログラミング言語の型システムに多少似ています。例えば、RDFスキーマでは、資源を1つ以上のクラスのインスタンスとして定義できます。さらに、クラスを階層的に組織化できます。例えば、クラスex:Dogは、ex:Animalのサブクラスであるex:Mammalのサブクラスとして定義できます。つまり、クラスex:Dogにある資源は、暗黙的にex:Animalにもあるということを意味します。しかし、RDFクラスとプロパティーは、プログラミング言語の型とはある点で非常に異なっています。RDFクラスとプロパティーの記述は、情報を強制しなければならないという拘束を作成せずに、それらが記述するRDF資源に関する追加情報を提供します。この情報は、様々な方法で使用でき、これに関しては5.3項で論じます。
RDFスキーマの機能自体は、RDF語彙の形式、つまり、自身の特別な意味を持つ特殊化した定義済みRDF資源として提供されます。RDFスキーマ語彙の資源には、接頭辞http://www.w3.org/2000/01/rdf-schema#(慣習上QName接頭辞rdfs:と関連する)を持つURIrefがあります。RDFスキーマ言語で書かれた語彙記述(スキーマ)は、正当なRDFグラフです。したがって、追加のRDFスキーマ語彙も処理するように書かれていないRDFソフトウェアは、スキーマを様々な資源とプロパティーから構成される正当なRDFグラフとして解釈できますが、RDFスキーマ用語の追加的な組み込み済みの意味は「理解」しないでしょう。これらの追加の意味を理解するためには、rdf:語彙だけでなく、それらの組み込み済みの意味と一緒に、rdfs:語彙も含んだ拡張言語を処理するようにRDFソフトウェアを書かなければなりません。この点に関しては、次の項で例示します。
以下の項では、RDFスキーマの基本的な資源とプロパティーを例示します。
どんな種類の記述プロセスであっても、基礎段階は記述する様々な種類の事物を識別することです。RDFスキーマでは、この「事物の種類」をクラスと呼びます。RDFスキーマのクラスは、型やカテゴリーの類概念に相当し、Javaなどのオブジェクト指向プログラミング言語のクラスの概念に多少似ています。RDFのクラスは、ウェブ・ページ、人、文書形式、データベース、抽象概念などのような、ほぼすべてのカテゴリーの事物を表現するために使用できます。クラスは、RDFスキーマ資源rdfs:Classやrdfs:Resource、そしてプロパティーrdf:typeやrdfs:subClassOfを使用して記述します。
例えば、example.orgという組織が、RDFを使用して様々な種類の自動車に関する情報を提供したいと考えているとします。RDFスキーマでは、example.orgは、まず最初に、自動車である事物のカテゴリーを表現するためにクラスが必要です。クラスに属する資源を、そのクラスのインスタンと呼びます。この場合、example.orgは、このクラスのインスタンスを自動車である資源にしようとします。
RDFスキーマでは、クラスは、値が資源rdfs:Classであるrdf:typeプロパティーを持つ資源です。そのため、自動車のクラスは、クラスにURIrefを割り当てることによって記述されます。例えばex:MotorVehicle(ex:を使用してURIref http://www.example.org/schemas/vehiclesを表し、これはexample.orgの語彙のURIrefに対する接頭辞として使用される)や、値が資源rdfs:Classであるrdf:typeプロパティーでその資源を記述する場合などです。つまり、example.orgは、以下のようなRDFステートメントを書きます。
ex:MotorVehicle rdf:type rdfs:Class .
3.2項で示したように、プロパティーrdf:typeは、資源がクラスのインスタンスであることを示すために使用されます。そのため、ex:MotorVehicleをクラスとして記述すると、資源exthings:companyCarは、以下のRDFステートメントによって自動車であると記述されるでしょう。
exthings:companyCar rdf:type ex:MotorVehicle .
(このステートメントでは、プロパティー名とインスタンス名の頭文字を小文字で書き、クラス名の頭文字は大文字で書くという一般的な慣習を採用しています。しかし、この慣習はRDFスキーマでは要求されません。また、このステートメントでは、example.orgが事物のクラスと事物のインスタンスに対して別々の語彙を定義することに決めたと仮定しています。)
資源rdfs:Class自体は、rdfs:Classのrdf:typeを持っています。資源は、複数のクラスのインスタンスでありえます。
クラスex:MotorVehicleを記述した後に、example.orgは、乗用車、バン、ミニバンなどの様々な特種用途の自動車を表現するクラスを追記したいと考えるかもしれません。これらのクラスは、新しいクラスごとにURIrefを割り当て、例えば以下の記述のように、これらの資源をクラスとして記述するRDFステートメントを書くことによって、クラスex:MotorVehicleと同じ方法で記述できます。
ex:Van rdf:type rdfs:Class . ex:Truck rdf:type rdfs:Class .
しかし、これらのステートメント自体は、個々のクラスを記述するだけです。example.orgは、クラスex:MotorVehicleとの特別な関係、すなわち、これらが特別な種類のMotorVehicle(自動車)であるということも示したいと考えるかもしれません。
2つのクラス間のこの種の特別な関係は、定義済みのrdfs:subClassOfプロパティーを使用して2つのクラスを関連づけて記述します。例えば、ex:Vanが特種なex:MotorVehicleであると述べるために、example.orgは以下のRDFステートメントを書くでしょう。
ex:Van rdfs:subClassOf ex:MotorVehicle .
このrdfs:subClassOf関係が意味するのは、クラスのex:Vanの任意のインスタンスはクラスex:MotorVehicleのインスタンスでもあるということです。そのため、資源exthings:companyVanがex:Vanのインスタンスである場合、宣言したrdfs:subClassOf関係に基づき、RDFスキーマ語彙を理解するように書かれたRDFソフトウェアは、exthings:companyVanがex:MotorVehicleのインスタンスでもあるという追加情報を推論できます。
このexthings:companyVanの例は、前に指摘した拡張言語を定義したRDFスキーマに関するポイントを示しています。RDF自体は、rdfs:subClassOfなどのRDFスキーマ語彙の用語に特別な意味を定義しません。そのため、RDFスキーマがex:Vanとex:MotorVehicleの間のこのrdfs:subClassOf関係を定義する場合、RDFスキーマ用語を理解するように書かれていないRDFソフトウェアは、これが述語rdfs:subClassOfを持ったトリプルであるとは認識するでしょうが、rdfs:subClassOfの特別な意味は理解せず、exthings:companyVanがex:MotorVehicleでもあるという追加の推論を導くことはできないでしょう。
rdfs:subClassOfプロパティーは推移的です。これは、例えば以下のRDFステートメントがある場合、
ex:Van rdfs:subClassOf ex:MotorVehicle . ex:MiniVan rdfs:subClassOf ex:Van .
RDFスキーマは、ex:MiniVanをex:MotorVehicleのサブクラスでもあると定義しているということを意味します。その結果、RDFスキーマは、クラスex:MiniVanのインスタンスである資源を、クラスex:MotorVehicleのインスタンスでもある(同様に、クラスex:Vanのインスタンスでもある)と定義します。クラスは、複数のクラスのサブクラスでありえます(例えば、ex:MiniVanはex:Vanとex:PassengerVehicleの両方のサブクラスでありえます)。RDFスキーマでは、すべてのクラスをクラスrdfs:Resourceのサブクラスとして定義します(すべてのクラスに属しているインスタンスは資源であるため)。
図18では、これらの例で論じているクラス階層の全体を示しています。
(図を簡略化するために、各クラスをrdfs:Classに関連付けるrdf:typeプロパティーは、図18では省略しています。実際には、RDFスキーマでは、rdfs:subClassOfプロパティーを型rdfs:Classの資源として使用するステートメントの主語と目的語の両方を定義するため、この情報を推論できます。しかし、実際にスキーマを書く際には、この情報を明示的に提供する方が望ましいです。)
このスキーマは、以下のトリプルでも記述できます。
ex:MotorVehicle rdf:type rdfs:Class . ex:PassengerVehicle rdf:type rdfs:Class . ex:Van rdf:type rdfs:Class . ex:Truck rdf:type rdfs:Class . ex:MiniVan rdf:type rdfs:Class . ex:PassengerVehicle rdfs:subClassOf ex:MotorVehicle . ex:Van rdfs:subClassOf ex:MotorVehicle . ex:Truck rdfs:subClassOf ex:MotorVehicle . ex:MiniVan rdfs:subClassOf ex:Van . ex:MiniVan rdfs:subClassOf ex:PassengerVehicle .
例23では、このスキーマをどのようにRDF/XMLで記述できるかを示しています。
<?xml version="1.0"?> <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xml:base="http://example.org/schemas/vehicles"> <rdf:Description rdf:ID="MotorVehicle"> <rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/> </rdf:Description> <rdf:Description rdf:ID="PassengerVehicle"> <rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdf:Description> <rdf:Description rdf:ID="Truck"> <rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdf:Description> <rdf:Description rdf:ID="Van"> <rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdf:Description> <rdf:Description rdf:ID="MiniVan"> <rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/> <rdfs:subClassOf rdf:resource="#Van"/> <rdfs:subClassOf rdf:resource="#PassengerVehicle"/> </rdf:Description> </rdf:RDF>
例13に関連して3.2で論じたように、RDF/XMLでは、rdf:typeプロパティー(型付きノード)持った資源を記述するための省略形を提供しています。RDFスキーマのクラスはRDF資源であるため、この省略形を適用してクラスを記述できます。この省略形を使用すれば、スキーマは例24のように記述することもできます。
<?xml version="1.0"?> <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xml:base="http://example.org/schemas/vehicles"> <rdfs:Class rdf:ID="MotorVehicle"/> <rdfs:Class rdf:ID="PassengerVehicle"> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdfs:Class> <rdfs:Class rdf:ID="Truck"> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdfs:Class> <rdfs:Class rdf:ID="Van"> <rdfs:subClassOf rdf:resource="#MotorVehicle"/> </rdfs:Class> <rdfs:Class rdf:ID="MiniVan"> <rdfs:subClassOf rdf:resource="#Van"/> <rdfs:subClassOf rdf:resource="#PassengerVehicle"/></rdfs:Class> </rdf:RDF>
この項の残りでは、同様の型付きノード省略を使用します。
例23と例24のRDF/XMLでは、3.2項で述べたように、スキーマ・ドキュメントに関連するURIrefを「割り当てる」効果を出すために、rdf:IDを使用して記述した資源(クラス)に対し、MotorVehicleなどの名前を導入しています。ここではrdf:IDは有用です。なぜならば、URIrefを省略するだけでなく、rdf:ID属性の値が現在の基底URI(通常、ドキュメントのURI)に対して一意であるということを追加確認できるからです。これは、RDFスキーマでクラス名とプロパティー名を定義する時に、繰り返されているrdf:IDの値を見つけ出すのに役立ちます。その結果、これらの名前に基づく相対URIrefを同じスキーマ中の他のクラス定義に使用できます(例えば、#MotorVehicleは、他のクラスの記述に使用される)。スキーマ自体が資源http://example.org/schemas/vehiclesであると仮定すると、このクラスの完全なURIrefは、http://example.org/schemas/vehicles#MotorVehicleになりますう(図18で示したように)。3.2項で述べたように、スキーマが移動したりコピーされたりしても、これらのスキーマのクラスへの参照が一貫して維持されることを保証するために(あるいは、スキーマ・クラスがすべて1か所で公開されているとは仮定しないで、ただ単にこれらのスキーマ・クラスに対して基底URIrefを割り当てるために)、クラス記述に明示的なxml:base="http://example.org/schemas/vehicles"宣言を含むこともできます。明示的なxml:base宣言の使用は、望ましいと考えられ、どちらの例でも提供しています。
他の場所にあるRDFインスタンス・データ(例えば、これらのクラスの個々の自動車を記述したデータ)でこれらのクラスを参照するためには、example.orgは、絶対URIrefを書くか、相対URIrefを適切なxml:base宣言と共に使用するか、QNameを適切なURIrefに展開してくれる適切な名前空間宣言と共にQNameを使用するかのいずれかの方法により、クラスを識別する必要があります。例えば、資源exthings:companyCarは、例25で示すRDF/XMLによって、例24のスキーマで記述したクラスex:MotorVehicleのインスタンスとして記述できます。
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/schemas/vehicles#" xml:base="http://example.org/things"> <ex:MotorVehicle rdf:ID="companyCar"/> </rdf:RDF>
QName ex:MotorVehicleは、名前空間宣xmlns:ex="http://example.org/schemas/vehicles#"を使用して展開すれば、完全なURIref http://example.org/schemas/vehicles#MotorVehicleになり、これは図18で示したようにMotorVehicleクラスに対する正しいURIrefであるということに注意してください。xml:base宣言xml:base="http://example.org/things"を提供して、rdf:ID="companyCar"を適切なexthings:companyCarに展開できます(QNameをrdf:ID属性の値として使用できないので)。
記述したい事物の特定のクラスの記述に加え、ユーザ・コミュニティーは事物(乗用車を記述するためのrearSeatLegRoomなど)のクラスを特徴づける特定のプロパティーを記述できなければなりません。RDFスキーマでは、プロパティーは、RDFのクラスrdf:Propertyと、RDFスキーマ・プロパティーrdfs:domain、rdfs:range、rdfs:subPropertyOfを使用して記述されます。
RDFのすべてのプロパティーは、クラスrdf:Propertyのインスタンスとして記述されます。そのため、exterms:weightInKgなどの新しいプロパティーは、プロパティーにURIrefを割り当て、資源rdf:Propertyを値として持つrdf:typeプロパティーでその資源を記述することによって、例えば以下のようなRDFステートメントを書くこによって記述されます。
exterms:weightInKg rdf:type rdf:Property .
RDFスキーマでは、RDFデータでプロパティーとクラスがどのような意図で一緒に使用されるかを記述するための語彙も提供します。この種の最も重要な情報は、RDFスキーマ・プロパティーrdfs:rangeとrdfs:domainを使用してアプリケーション固有のプロパティーを詳細に記述することによって供されます。
rdfs:rangeプロパティーは、特定のプロパティーの値が指定されたクラスのインスタンスであることを示すために使用されます。例えば、example.orgが、プロパティーex:authorがクラスex:Personのインスタンスである値を持っているということを示したい場合、以下のRDFステートメントを書くでしょう。
ex:Person rdf:type rdfs:Class . ex:author rdf:type rdf:Property . ex:author rdfs:range ex:Person .
これらのステートメントでは、ex:Personがクラスで、ex:authorがプロパティーであり、ex:authorプロパティーを使用しているRDFステートメントがex:Personのインスタンスを目的語として持っているということ示しています。
例えば、プロパティーex:hasMotherは、0や1、または複数の。定義域プロパティーを持つことができます。ex:hasMotherが定義域プロパティーを持っていない場合、ex:hasMotherプロパティーの値に関して何も述べることはあません。ex:hasMotherが、例えばex:Personを範囲として指定するものなどの、1つの定義域プロパティーを持っている場合、ex:hasMotherプロパティーの値がクラスex:Personのインスタンスであるということを示します。ex:hasMotherが、例えば1つがex:Personをその範囲として指定するもので、もう1つがex:Femaleをその範囲として指定するものであるなど、複数の定義域プロパティーを持っている場合、ex:hasMotherプロパティーの値が範囲として指定されたすべてのクラスのインスタンスである資源ということ、すなわち、ex:hasMotherのいずれの値もex:Femaleおよびex:Personの両方であるということを示します。
この最後の点は明白でないかもしれません。しかし、プロパティーex:hasMotherがex:Femaleとex:Personという2つの範囲を持つと述べることには、以下の2つの別々のステートメントを出すことが伴います。
ex:hasMother rdfs:range ex:Female .ex:hasMother rdfs:range ex:Person .
例えば、以下のような、このプロパティーを使用するあるステートメントに関して、
exstaff:frank ex:hasMother exstaff:frances .
両方のrdfs:rangeステートメントが正しいものであるためには、exstaff:francesがex:Femaleおよびex:Personの両方である場合でなけばなりません。
rdfs:rangeプロパティーは、2.4項で論じたように、プロパティーの値が型付きリテラルによって付与されたということを示すために使用できます。例えば、プロパティーex:ageはXMLスキーマ・データ型xsd:integerの値を持つということを、example.orgが示したい場合、以下のようなRDFステートメントを書くでしょう。
ex:age rdf:type rdf:Property . ex:age rdfs:range xsd:integer .
データ型xsd:integerは、自身のURIrefで識別されます(完全なURIrefは、http://www.w3.org/2001/XMLSchema#integerです)。このURIrefは、これがデータ型を識別するとスキーマで明示的に述べなくても使用できます。しかし、特定のURIrefがデータ型を識別すると明示的に述べることは多くの場合役立ちます。これは、RDFスキーマのクラスrdfs:Datatypeを使用することで行えます。example.orgは、xsd:integerがデータ型であると述べるために、以下のRDFステートメントを書くでしょう。
xsd:integer rdf:type rdfs:Datatype .
このステートメントでは、xsd:integerがデータ型のURIrefであると述べています([RDF-CONCEPTS]に記述されているRDFデータ型の要件に従っていると思われる)。このようなステートメントは、例えばexample.orgが新しいデータ型を定義しているという意味で、データ型の定義を制定しません。RDFスキーマでデータ型を定義する方法はありません。2.4項で指摘したように、データ型はRDF(および、RDFスキーマ)の外部で定義され、URIrefを通じてRDFステートメントで参照されます。このステートメントは、単にデータ型の存在を記録し、このデータ型がこのスキーマで使用されていることを明示する役割を果たします。
rdfs:domainプロパティーは、特定のプロパティーが指定されたクラスに適用されるということを示すために使用されます。例えば、example.orgが、プロパティーex:authorはクラスex:Bookのインスタンスに適用するということを示したい場合、以下のRDFステートメントを書くでしょう。
ex:Book rdf:type rdfs:Class . ex:author rdf:type rdf:Property . ex:author rdfs:domain ex:Book .
これらのステートメントは、ex:Bookがクラスで、ex:authorがプロパティーであり、ex:authorプロパティーを使用しているRDFステートメントがex:Bookのインスタンスを主語として持っているということを示しています。
例えば、exterms:weightなどの任意のプロパティーは、0や1、または複数の定義域プロパティーを持つことができます。exterms:weightが定義域プロパティーを持っていない場合、exterms:weightプロパティーが一緒に使用される資源に関して何も述べることはありません(どんな資源もexterms:weightを持つことができます)。exterms:weightが、例えばex:Bookをドメインとして指定するものなどの、1つの定義域プロパティーを持っている場合、exterms:weightプロパティーがクラスex:Bookのインスタンスに適用するということを述べています。exterms:weightが、例えば1つがex:Bookを範囲として指定するもので、もう1つがex:MotorVehicleを範囲として指定するものであるなど、複数の定義域プロパティーを持っている場合、exterms:weightプロパティーを持っているいずれの資源もドメインとして指定されたすべてのクラスのインスタンスであるということ、すなわち、exterms:weightプロパティーを持っているいずれの資源もex:Bookおよびex:MotorVehicleの両方であるということを述べています(定義域と値域を指定する際に注意が必要であるということを示す)。
rdfs:rangeの場合と同様に、この最後の点は明白でないかもしれません。しかし、プロパティーexterms:weightがex:Bookとex:MotorVehicleという2つの範囲を持つと述べることには、以下の2つの別々のステートメントを出すことが伴います。
exterms:weight rdfs:domain ex:Book . exterms:weight rdfs:domain ex:MotorVehicle .
例えば、以下のような、このプロパティーを使用するあるステートメントに関して、
exthings:companyCar exterms:weight "2500"^^xsd:integer .
両方のrdfs:domainステートメントが正しいものであるためには、exthings:companyCarがex:Bookおよびex:MotorVehicleの両方のインスタンスでなければなりません。
これらの値域と定義域の記述の使用は、自動車のスキーマを拡張し、2つのプロパティーex:registeredToとex:rearSeatLegRoomや、新しいクラスex:Person追加し、データ型xsd:integerをデータ型として明示的に記述することによって例示できます。ex:registeredToプロパティーは、任意のex:MotorVehicleにも適用し、その値はex:Personです。この例のために、ex:rearSeatLegRoomはクラスex:PassengerVehicleのインスタンスのみに適用します。値は、後部座席の足空間をセンチメートルによる数値で示したxsd:integerです。この記述は、例26で示しています。
<rdf:Property rdf:ID="registeredTo"> <rdfs:domain rdf:resource="#MotorVehicle"/> <rdfs:range rdf:resource="#Person"/> </rdf:Property> <rdf:Property rdf:ID="rearSeatLegRoom"> <rdfs:domain rdf:resource="#PassengerVehicle"/> <rdfs:range rdf:resource="&xsd;integer"/> </rdf:Property> <rdfs:Class rdf:ID="Person"/> <rdfs:Datatype rdf:about="&xsd;integer"/>
例24で述べた自動車のスキーマにこのRDF/XMLが追加されていると仮定しているため、<rdf:RDF>要素を例26では使用しないことに注意してください。また、これと同じ仮定によって、#MotorVehicleのような相対URIrefを使用してそのスキーマに属する他のクラスを参照できます。
RDFスキーマでは、クラスだけでなくプロパティーを特殊化する方法を提供しています。2つのプロパティー間のこの特殊化の関係は、定義済みのrdfs:subPropertyOfプロパティーを使用して記述されます。例えば、ex:primaryDriverとex:driverの両方がプロパティーである場合、example.orgは、以下のRDFステートメントを書くことにより、これらのプロパティーを記述し、ex:primaryDriverがex:driverを特殊化したものであるという事実を記述できます。
ex:driver rdf:type rdf:Property . ex:primaryDriver rdf:type rdf:Property . ex:primaryDriver rdfs:subPropertyOf ex:driver .
このrdfs:subPropertyOf関係が意味するのは、インスタンスexstaff:fredがインスタンスex:companyVanのex:primaryDriverである場合、RDFスキーマはexstaff:fredがex:companyVanのex:driverでもあると定義する、ということです。これらのプロパティーを記述しているRDF/XMLを(ここでも、これが例24で記述した自動車スキーマに追加されていると仮定している)例27で示しています。
<rdf:Property rdf:ID="driver"> <rdfs:domain rdf:resource="#MotorVehicle"/> </rdf:Property> <rdf:Property rdf:ID="primaryDriver"> <rdfs:subPropertyOf rdf:resource="#driver"/> </rdf:Property>
プロパティーは、0や1、または複数のプロパティーのサブプロパティーでありえます。RDFプロパティーに適用されるRDFスキーマであるrdfs:rangeとrdfs:domainプロパティーはすべて、それぞれのサブプロパティーにも適用されます。そのため、上記の例では、RDFスキーマは、ex:driverとのサブプロパティーの関係から、ex:primaryDriverがex:MotorVehicleのrdfs:domainも持っていると定義します。
例28では、今までに示したすべての記述を含めた、完全な自動車体系のRDF/XMLを示しています。
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://example.org/schemas/vehicles">
<rdfs:Class rdf:ID="MotorVehicle"/>
<rdfs:Class rdf:ID="PassengerVehicle">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Truck">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Van">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="MiniVan">
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Person"/>
<rdfs:Datatype rdf:about="&xsd;integer"/>
<rdf:Property rdf:ID="registeredTo">
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Property>
<rdf:Property rdf:ID="rearSeatLegRoom">
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="&xsd;integer"/>
</rdf:Property>
<rdf:Property rdf:ID="driver">
<rdfs:domain rdf:resource="#MotorVehicle"/></rdf:Property>
<rdf:Property rdf:ID="primaryDriver">
<rdfs:subPropertyOf rdf:resource="#driver"/>
</rdf:Property>
</rdf:RDF>
RDFスキーマを使用してどのようにクラスとプロパティーを記述するかを示してきたため、今ではこれらのクラスとプロパティーを使用するインスタンスを例示できます。例えば、例29では、プロパティーに対するいくつかの仮想の値と一緒に、例28で記述したex:PassengerVehicleクラスのインスタンスを記述しています。
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles#"
xml:base="http://example.org/things">
<ex:PassengerVehicle rdf:ID="johnSmithsCar">
<ex:registeredTo rdf:resource="http://www.example.org/staffid/85740"/>
<ex:rearSeatLegRoom
rdf:datatype="&xsd;integer">127</ex:rearSeatLegRoom>
<ex:primaryDriver rdf:resource="http://www.example.org/staffid/85740"/>
</ex:PassengerVehicle>
</rdf:RDF>
この例では、インスタンスがスキーマとは別個のドキュメントで記述されると仮定しています。スキーマがhttp://example.org/schemas/vehiclesのxml:baseを持っているため、名前空間宣言xmlns:ex="http://example.org/schemas/vehicles#"を提供して、インスタンスのデータにおけるex:registeredToなどのQNameをこのスキーマで記述されたクラスとプロパティーのURIrefに適切に展開できるようにします。xml:base宣言もこのインスタンスに対して提供され、これによって、rdf:ID="johnSmithsCar"は、実際のドキュメントの位置に関わらず、適切なURIrefに展開できるようになります。
ex:PassengerVehicleがex:MotorVehicleのサブクラスであるため、ex:PassengerVehicleのこのインスタンスを記述する際にex:registeredToプロパティーを使用できることに注意してください。このインスタンスでは、プレーン・リテラルではなく(つまり、<ex:rearSeatLegRoom>127</ex:rearSeatLegRoom>として値を述べるのではなく)、型付きリテラルがex:rearSetLegRoomプロパティーの値に使用されることにも注意してください。スキーマがこのプロパティーの地域をxsd:integerとして記述するため、プロパティーの値は、値域の記述に合わせるためにそのデータ型の型付きリテラルでなければなりません(すなわち、値域の宣言はプレーン・リテラルに自動的にデータ型を「割り当て」ないため、適切なデータ型の型付きリテラルを明示的に提供しなければなりません)。4.4項で論じたように、ex:rearSetLegRoomプロパティーの単位(センチメートル)を明示的に指定するために、スキーマあるいは追加のインスタンスのデータにおける追加情報も提供できます。
以前に指摘したように、RDFスキーマの型システムは、Javaなどのオブジェクト指向プログラミング言語の型システムに多少似ています。しかし、RDFはいくつかの重要な点において、ほとんどのプログラミング言語の型システムとは異なっています。
1つの重要な違いは、クラスが特定のプロパティーのコレクションを持っていると記述する代わりに、RDFスキーマは、定義域プロパティーと値域プロパティーを使用して、プロパティーが資源の特定のクラスに適用していると記述するということです。例えば、一般的なオブジェクト指向プログラミング言語では、型Personの値を持つauthorという属性でクラスBookを定義できます。対応するRDFスキーマでは、クラスex:Bookを記述し、別の記述ではex:Bookの定義域とex:Personの値域を持ったプロパティーex:authorを記述するでしょう。
これらの方法の違いは、構文的なものだけのように思えるかもしれませんが、実際には大きな違いがあります。プログラミング言語のクラス記述では、属性authorはクラスBookの記述の一部であり、クラスBookのインスタンスにのみ適用します。他のクラス(例えば、softwareModule)も、authorという属性を持つことができますが、これは異なる属性であると考えられます。言い換えれば、ほとんどのプログラミング言語における属性記述の範囲は、その属性が定義されているクラスまたは型に制限されています。一方で、RDFでは、プロパティー記述は、デフォルトでクラス定義から独立しており、デフォルトでグローバルな範囲を持っています(定義域の仕様を使用して、特定のクラスのみに適用すると宣言できる場合もありますが)。
その結果、RDFスキーマは、定義域を指定せずにexterms:weightプロパティーを記述できます。このプロパティーは、重さを持っていると考えられる任意のクラスのインスタンスを記述するために使用できます。RDFのプロパティーに基く方法の1つの利点は、最初の記述では予期されていなかった状況にまでプロパティー定義の使用をより簡単に拡張できるということです。同時に、この「利点」は、不適切な状況でプロパティーが誤適用されないようにするために、慎重に使用しなければいけません。
RDFのプロパティー記述がグローバルな範囲を持っていることの別の結果は、RDFスキーマでは、特定のプロパティーはそれを適用した資源のクラスに応じたローカルに異なる値域を持っていると定義できないということです。例えば、プロパティーex:hasParentを定義する際には、プロパティーを使用してクラスex:Tigerの資源を記述すれば、このプロパティーの値域はクラスex:Tigerの資源でもあると述べ、同時に、プロパティーを使用してクラスex:Humanの資源を記述すれば、このプロパティーの値域はクラスex:Humanの資源でもあると述べることができることが望ましいでしょう。この種の定義は、RDFスキーマでは不可能です。その代わりに、RDFのプロパティーに対して定義した値域は、そのプロパティーの使用のすべてに適用されるため、値域は慎重に定義するべきです。しかし、RDFスキーマでは、このようなローカルに異なる値域を定義できませんが、5.5項で論じた、より豊かなスキーマ言語の一部ではこれらを定義できます。
もうひとつの重要な違いは、RDFスキーマ記述は、必ずしも一般的なプログラミング言語の型宣言のように規範的である必要はないということです。例えば、プログラミング言語が、型Personの値を持っているauthor属性を持つクラスBookを宣言する場合、通常、これは一連の制約であると解釈されます。プログラミング言語では、author属性なしにBookのインスタンスを作成することは許されておらず、値としてPersonを持たないauthor属性を持つBookのインスタンスは許されていないでしょう。そのうえ、クラスBookに対して定義された唯一の属性がauthorがである場合、プログラミング言語では、その他の属性を持つBookのインスタンスは許されないでしょう。
一方、RDFスキーマではスキーマ情報を資源の追加記述として提供しますが、この記述をアプリケーションでどのように使用すべきかは規定していません。例えば、ex:authorプロパティーがクラスex:Personのrdfs:rangeを持っているとRDFスキーマが述べているとします。これは単に、ex:authorプロパティーを含むRDFステートメントがex:Personのインスタンスを目的語として持っているというRDFステートメントです。
このスキーマが提供する情報は、異なる方法で使用できます。あるアプリケーションでは、このステートメントは作成しているRDFデータ用のテンプレートの一部を指定していると解釈し、これを使用してex:authorプロパティーが指示された(ex:Person)クラスの値を持っていることを保証します。すなわち、このアプリケーションでは、プログラミング言語と同じ方法で制約としてスキーマ記述を解釈します。しかし、別のアプリケーションでは、このステートメントは受信しているデータに関する追加情報(最初のデータでは明示的に提供されない情報)を提供していると解釈するかもしれません。例えば、この2番目のアプリケーションでは、指定されていない資源を値として持つex:authorプロパティーを含む一部のRDFデータを受信し、このスキーマが提供するステートメントを使用して資源がクラスex:Personのインスタンスに間違いないと結論づけることができます。3番目のアプリケーションでは、クラスex:Corporationの資源を値として持つex:authorプロパティーを含む一部のRDFデータを受信し、このスキーマ情報を「ここには、矛盾がありえるが、ないこともありえる」という警告の根拠として使用するかもしれません。明白な矛盾を解決してくれる宣言が他のどこかにあるかもしれません(例えば、「法人は(法的な)人である」という趣旨の宣言)。
そのうえ、アプリケーションがプロパティーの記述を解釈する方法により、一部のスキーマに特化したプロパティーがない場合や(例えば、ex:authorがex:Bookの定義域を持っていると記述されていても、ex:authorプロパティーを持たないex:Bookのインスタンスはありえる)、追加プロパティーを持っている場合(例えば、クラスex:Bookを記述しているスキーマがそのようなプロパティーを記述しなくても、ex:technicalEditorプロパティーを持つex:Bookのインスタンスはありえる)でもインスタンスの記述が有効であると見なせます。
言い換えれば、RDFスキーマのステートメントは常に記述です。この記述は規範的でもありえますが(制約を導入する)、これはこのステートメントを解釈するアプリケーションがそのように処理したい場合に限ります。RDFスキーマが行うのは、この追加情報を述べる方法を提供することです。この情報が明示的に指定されたインスタンスのデータと相反するかどうかは、決定や動作を行うアプリケーション次第です。
RDFスキーマは、その他の多くの組み込みプロパティーを提供し、これらを使用してRDFスキーマやインスタンスに関するドキュメントやその他の情報を提供できます。例えば、rdfs:commentプロパティーを使用して人間が読める資源の記述を提供できます。rdfs:labelプロパティーを使用してより人間が読めるバージョンの資源名を提供できます。rdfs:seeAlsoプロパティーを使用して、主語である資源に関する追加情報を提供できる資源を示すことができます。rdfs:isDefinedByプロパティーは、rdfs:seeAlsoのサブプロパティーであり、これを使用して主語である資源を「定義する」(ある意味で、RDFで指定されない資源。例えば、資源はRDFスキーマになれない)資源を示すことができます。これらのプロパティーのより詳細な議論に関しては、RDF語彙記述言語1.0: RDFスキーマ [RDF-VOCABULARY]を参考にしてください。
rdf:valueのような多くの組み込みRDFプロパティーと同様に、これらのRDFスキーマ・プロパティーに対して記述した用法は、これらのプロパティーが意図する用法にすぎません。[RDF-SEMANTICS]ではこれらのプロパティーに対して特別な意味を定義せず、RDFスキーマではこれらの意図する用法に基づくいかなる制約も定義しません。例えば、rdfs:seeAlsoプロパティーの目的語はこの目的語が出現するステートメントの主語に関する追加情報を提供しなければならない、という指定のある制約はありません。
RDFスキーマには、RDF語彙を記述するための基本的な性能が備わっていますが、付加的な性能も可能であり、有益である場合があります。これらの性能は、RDFスキーマのさらなる開発を通じて提供したり、RDFに基づく他の言語で提供したりすることができます。有益であると認識されているより豊かなスキーマの性能(RDFスキーマでは提供されない)には、以下が含まれます。
ex:hasAncestorのような)が推移的であると指定すること。例えば、A ex:hasAncestor Bであり、B ex:hasAncestor Cである場合、A ex:hasAncestor Cであるなど。ex:hasPlayersプロパティーには11の値がある一方で、バスケットボール・チームでは同じプロパティーに5つの値しかない、と言うことができるなど。その他の性能に加え、上記で述べた追加性能は、DAML+OIL [DAML+OIL]やOWL [OWL]などのオントロジー言語の対象です。これらの言語は、両方ともRDFとRDFスキーマに基づいています(現在、両方ともが上記のすべての追加性能を備えている)。これらの言語の目的は、機械が処理できる資源のセマンティクスを追加提供すること、すなわち、資源の機械表現をこれらの言語が意図する実世界のものにより類似したものにすることです。このような性能は、RDFを使用した有用なアプリケーションを構築するためには必ずしも必要ではありませんが(多くの既存のRDFアプリケーションの記述に関しては、6項を参照)、このような言語の開発はセマンティック・ウェブの開発の一環として非常に活発な取り組みの対象になっています。
前項では、RDFとRDFスキーマの一般的な性能について述べました。これらの性能を例示するために前項では例を使用し、これらの例の一部では、RDFアプリケーションの可能性を提案しましたが、実際のアプリケーションについては少しも論じませんでした。この項では、多種多様な事物に関する情報を表現し操作するためにRDFがどのように様々な実世界の要件をサポートするかを示しながら、実際に開発されているRDFアプリケーションの一部について述べます。
メタデータは、データに関するデータです。具体的には、この用語は、資源が物理的であるか電子的であるかに関わらず、情報資源の識別、記述、検索を行うために使用されるデータを意味します。コンピュータで処理される構造化されたメタデータは比較的新しい概念ですが、メタデータの基本概念は、大規模な情報を管理し利用する際に長年使用されてきました。図書館のカード目録は、このようなメタデータの身近な例です。
ダブリン・コアは、ドキュメントを記述するための(したがって、メタデータを記録するための)1組の「要素」(プロパティー)です。この要素は元々、オハイオ州ダブリンで開かれた1995年3月のメタデータ・ワークショップで開発されました。その後、ダブリン・コアは、後のダブリン・コア・メタデータ・ワークショップに基づいて変更され、現在はダブリン・コア・メタデータ・イニシアティブによって維持されています。ダブリン・コアの目的は、図書館のカード目録に似た方法で、ドキュメントのようなネットワーク化されたオブジェクトの記述と自動索引を容易にする記述要素の最小セットを提供することです。ダブリン・コア・メタデータ・セットは、一般的なWWWの検索エンジンに採用されている「ウェブクローラー」などの、インターネット上の資源発見ツールで使用するのに適しているように作られています。さらに、ダブリン・コアは、インターネットに情報を提供する広範囲の著者や一般の情報公開者が容易に理解し使用できることを目指しています。ダブリン・コアの要素は、インターネット資源を記録する際に広く使用されるようになりました(ダブリン・コアのcreator要素は、既に前の例で使用しました)。ダブリン・コアの現行の要素は、ダブリン・コア・メタデータ要素セット、Version 1.1: 参照記述 [DC]で定義されており、以下のプロパティーに対する定義を含んでいます。
ダブリン・コア要素を使用した情報は、任意の適切な言語で(例えば、HTMLのmeta要素で)表現できます。しかし、ダブリン・コア情報の理想的な表現方法はRDFです。以下の例では、ダブリン・コア語彙を使用したRDFでの1組の資源の簡単な記述を示します。ここで示している特定のダブリン・コアRDF語彙は、正式なものであることを意図していないことに注意してください。ダブリン・コア参照記述 [DC]は、正式な参照です。
最初の例(例30)では、ダブリン・コアのプロパティーを使用してウェブサイトのホームページを記述しています。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.dlib.org">
<dc:title>D-Lib Program - Research in Digital Libraries</dc:title>
<dc:description>The D-Lib program supports the community of people
with research interests in digital libraries and electronic
publishing.</dc:description>
<dc:publisher>Corporation For National Research Initiatives</dc:publisher>
<dc:date>1995-01-07</dc:date>
<dc:subject>
<rdf:Bag>
<rdf:li>Research; statistical methods</rdf:li>
<rdf:li>Education, research, related topics</rdf:li>
<rdf:li>Library use Studies</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:type>World Wide Web Home Page</dc:type>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
</rdf:Description>
</rdf:RDF>
RDFとダブリン・コアの両方が「Description」という(XML)要素を定義することに注意してください(ダブリン・コアの要素名は小文字で書かれていますが)。最初の文字が等しく大文字であっても、XML名前空間メカニズムによってこれらの2つの要素を区別できます(1つはrdf:Descriptionで、もう1つはdc:descriptionです)。また、関心があって、ウェブ・ブラウザでhttp://purl.org/dc/elements/1.1/(この例では、この名前空間URIを使用してダブリン・コア語彙を識別した)にアクセスすると(執筆時点では)、[DC]のRDFスキーマ宣言が検索されるでしょう。
2番目の例(例31)では、発行された雑誌について記述しています。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://www.dlib.org/dlib/may98/05contents.html">
<dc:title>DLIB Magazine - The Magazine for Digital Library Research
- May 1998</dc:title>
<dc:description>D-LIB magazine is a monthly compilation of
contributed stories, commentary, and briefings.</dc:description>
<dc:contributor>Amy Friedlander</dc:contributor>
<dc:publisher>Corporation for National Research Initiatives</dc:publisher>
<dc:date>1998-01-05</dc:date>
<dc:type>electronic journal</dc:type>
<dc:subject>
<rdf:Bag>
<rdf:li>library use studies</rdf:li>
<rdf:li>magazines and newspapers</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:format>text/html</dc:format>
<dc:identifier rdf:resource="urn:issn:1082-9873"/>
<dcterms:isPartOf rdf:resource="http://www.dlib.org"/>
</rdf:Description>
</rdf:RDF>
例31では(最後から3行目で)、ダブリン・コア限定子isPartOf(別の語彙からの)を使用して、この雑誌が以前に述べたウェブ・サイトの「一部」であることを示しています。
3番目の例(例32)では、例31で記述した雑誌の特定記事を記述しています。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://www.dlib.org/dlib/may98/miller/05miller.html">
<dc:title>An Introduction to the Resource Description Framework</dc:title>
<dc:creator>Eric J. Miller</dc:creator>
<dc:description>The Resource Description Framework (RDF) is an
infrastructure that enables the encoding, exchange and reuse of
structured metadata. rdf is an application of xml that imposes needed
structural constraints to provide unambiguous methods of expressing
semantics. rdf additionally provides a means for publishing both
human-readable and machine-processable vocabularies designed to
encourage the reuse and extension of metadata semantics among
disparate information communities. the structural constraints rdf
imposes to support the consistent encoding and exchange of
standardized metadata provides for the interchangeability of separate
packages of metadata defined by different resource description
communities. </dc:description>
<dc:publisher>Corporation for National Research Initiatives</dc:publisher>
<dc:subject>
<rdf:Bag>
<rdf:li>machine-readable catalog record formats</rdf:li>
<rdf:li>applications of computer file organization and
access methods</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:rights>Copyright © 1998 Eric Miller</dc:rights>
<dc:type>Electronic Document</dc:type>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
<dcterms:isPartOf rdf:resource="http://www.dlib.org/dlib/may98/05contents.html"/>
</rdf:Description>
</rdf:RDF>
例32でも限定子isPartOfを使用しており、今回は、この記事が以前に記述した雑誌の「一部」であることを示しています。
コンピュータ言語とファイル形式は、メタデータを、このメタデータが記述するデータをともに組み込むための明確な規定を常に設けているわけではありません。多くの場合、メタデータは、別の資源として指定され、データと明示的にリンクされなければなりません(これは、この入門書を記述するRDFメタデータのために行われました。この入門書の末尾にこのメタデータへの明示的なリンクがあります)。しかし、メタデータをデータに直接組み込むための明確な規定を作成しているアプリケーションや言語も徐々に増えています。例えば、W3CのSVG言語(Scalable Vector Graphics)[SVG](別のXMLベースの言語)は、他のSVGデータと一緒にメタデータを記録するための明示的なmetadata要素を提供します。この要素の中では、あらゆるXMLベースのメタデータ言語を使用できます。[SVG]には、例33で示した、SVGドキュメント自体にSVGドキュメントを記述したメタデータを組み込む方法の例が含まれています。この例では、メタデータを記録するためにダブリン・コア語彙とRDF/XMLを使用しています。
<?xml version="1.0"?>
<svg width="4in" height="3in" version="1.1"
xmlns = 'http://www.w3.org/2000/svg'>
<desc xmlns:myfoo="http://example.org/myfoo">
<myfoo:title>This is a financial report</myfoo:title>
<myfoo:descr>The global description uses markup from the
<myfoo:emph>myfoo</myfoo:emph> namespace.</myfoo:descr>
<myfoo:scene><myfoo:what>widget $growth</myfoo:what>
<myfoo:contains>$three $graph-bar</myfoo:contains>
<myfoo:when>1998 $through 2000</myfoo:when> </myfoo:scene>
</desc>
<metadata>
<rdf:RDF
xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs = "http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc = "http://purl.org/dc/elements/1.1/" >
<rdf:Description rdf:about="http://example.org/myfoo"
dc:title="MyFoo Financial Report"
dc:description="$three $bar $thousands $dollars $from 1998 $through 2000"
dc:publisher="Example Organization"
dc:date="2000-04-11"
dc:format="image/svg+xml"
dc:language="en" > <dc:creator>
<rdf:Bag>
<rdf:li>Irving Bird</rdf:li>
<rdf:li>Mary Lambert</rdf:li>
</rdf:Bag>
</dc:creator>
</rdf:Description>
</rdf:RDF>
</metadata>
</svg>
Adobe社のXMP(Extensible Metadata Platform)は、ファイルに関するメタデータをファイル自体に組み込めるようにする技術に関する別の例です。XMPでは、メタデータ表現の基礎としてRDF/XMLを使用します。Adobe製品の多くが既にXMPをサポートしています。
PRISM: Publishing Requirements for Industry Standard Metadata [PRISM]は、出版業界で開発されたメタデータの仕様です。雑誌の出版社とその販売業者は、PRISMワーキンググループを結成して業界のメタデータに対するニーズを識別し、そのニーズを満たすように仕様を定義しました。出版社は、コンテンツの作成時に行った投資よりも大きな利益を得るために、様々な方法で既存のコンテンツを使用したいと考えています。雑誌記事をウェブに掲載するためにHTMLに変換するのは、その1つの例です。別の例としては、LexisNexisのようなアグリゲーター(訳注:aggregator。複数の出版社の雑誌記事を総合的に収集・提供する機関)にその雑誌記事をライセンス提供するものがあります。これらはすべてコンテンツの「初めての使用」であり、通常は、雑誌の発売時に稼動します。出版社は、そのコンテンツが「いつまでも新鮮」であって欲しいとも願います。このコンテンツは、回顧記事などの形で新刊号で使用できます。雑誌の写真やレシピなどを編集した本などの形で、その出版社内の別の部署でも使用できます。別の使用方法としては、製品レビューの再版や別の出版社による復刻版などの、外部に対して使用許可を与えるというのもあります。この全体的な目標には、発見(discovery)や権利追求(rights tracking)、エンド・ツー・エンド・メタデータ(end-to-end metadata)に重点を置いたメターデータのアプローチが必要です。
発見: 発見とは、検索やブラウジング、コンテンツ・ルーティング、その他の技術を包括する、コンテンツを見つけることに対する一般的な用語です。発見に関する議論は、消費者による一般のウェブサイト検索にしばしば重点が置かれます。しかし、コンテンツの発見は、それよりずっと広範囲です。対象者は、消費者で構成されることもあれば、研究者やデザイナー、写真編集者、ライセンシング・エージェントなどの内部利用者で構成されることもあります。PRISMでは、発見を支援するために、プロパティーを提供して資源の話題や形式、ジャンル、起源、コンテキストを記述します。PRISMでは、複数の主題記述分類法を使用して資源を分類する手段も提供しています。
権利追求: 雑誌には、他から使用許可を得た素材が頻繁に含まれています。ストック写真の代理店が提供する写真は、最も一般的な種類の使用許可済みの素材ですが、記事や補足記事、そして他のすべての種類のコンテンツの使用許可を得ることもできます。コンテンツが、1回のみの使用が許可されているのか、ロイヤリティの支払いを要するのか、出版社が完全に所有しているのかを単に知るだけでも大変です。PRISMでは、そのような権利の基本的な追跡のための要素を提供しています。PRISMの仕様で定義されている別の語彙は、コンテンツが使用できたりできなかったりする場所や時間、業界の記述をサポートしています。
エンド・ツー・エンド・メタデータ: 出版されたコンテンツのほとんどは、そのコンテンツ用に作成されたメタデータを既に持っています。残念ながら、コンテンツがシステム間で移動すると、しばしばそのメタデータは廃棄され、後の生産過程でかなりの費用をかけて再作成されます。PRISMは、コンテンツ作成過程の多くの段階で使用できる仕様を提供してこの問題を削減することを目指しています。PRISMの仕様の大きな特徴は、他の既存の仕様を使用するということです。PRISMのグループは、全く新しいものを作成するのではなく、できる限り既存の仕様を使用し、必要な場合にのみ新しい事柄を定義することに決めました。このような理由で、PRISMの仕様は、様々なISOの形式や語彙に加え、XML、RDF、ダブリン・コアを使用しています。PRISMの記述は、プレーン・リテラル値を持つ一部のダブリン・コアのプロパティーと同じくらい簡単かもしれません。例34では、タイトル、写真家、形式などに関する基本情報を提供して写真を記述しています。
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:lang="en-US">
<rdf:Description rdf:about="http://travel.example.com/2000/08/Corfu.jpg">
<dc:title>Walking on the Beach in Corfu</dc:title>
<dc:description>Photograph taken at 6:00 am on Corfu with two models
</dc:description>
<dc:creator>John Peterson</dc:creator>
<dc:contributor>Sally Smith, lighting</dc:contributor>
<dc:format>image/jpeg</dc:format> </rdf:Description>
</rdf:RDF>
PRISMは、ダブリン・コアを強化して、より詳細な記述も可能にします。この強化は、一般的に接頭辞prism:、pcv:、prl:を使用して引用される3つの新しい語彙として定義されています。
prism:: この接頭辞は、主要なPRISM語彙を参照し、その用語はURI接頭辞http://prismstandard.org/namespaces/basic/1.0/を使用します。この語彙のプロパティーの大部分は、ダブリン・コアに属するプロパティーの、より特定的なバージョンです。例えば、dc:dateのより特定的なバージョンは、prism:publicationTime、prism:releaseTime、prism:expirationTimeなどのようなプロパティーで提供されています。
pcv: この接頭辞は、PRISM統制語彙(PRISM Controlled Vocabulary、pcv)という語彙を参照し、その用語はURI接頭辞http://prismstandard.org/namespaces/pcv/1.0/を使用します。現在、記事の主題を記述するためには、記述的なキーワードを提供するという方法が一般的にとられています。残念ながら、人によって使用するキーワードが異なるため、簡単なキーワードでは検索性能に大きな違いは生じません[BATES96]。最も良い方法は、「統制語彙」の件名で記事をコード化することです。この語彙は、その語彙の用語に対してできる限り多くの同義語を提供する必要があります。このようにして、統制用語は、検索者と索引作成者が提供したキーワードが出会う場所を提供します。pcv語彙は、語彙の用語、用語間の関係、用語の別名を指定するためのプロパティーを提供します。
prl: この接頭辞は、PRISM権利言語語彙を参照し、その用語はURI接頭辞http://prismstandard.org/namespaces/prl/1.0/を使用します。デジタル権利管理は、かなりの激変を経験している分野です。権利管理言語に対する多くの提案がありますが、業界全体で明らかに好まれているものはありません。推奨すべきものも明確にはないため、暫定措置としてPRISM権利言語(PRL)が定義されています。これは、時間、地理、業界の条件によって、項目を「使用」できるかできないかを述べられるようにするプロパティーを提供します。これは、権利を追跡する時に出版社が費用を削減し始めるのに役立つ80/20のトレードオフであると信じられています。一般的な権利言語であることや、出版社が自動的に消費者のコンテンツの使用に制限を課すようにすることを意図したものではありません。
様々な複雑さの記述を処理する性能のために、PRISMはRDFを使用します。現在、メタデータの多くは、以下のようなシンプルな文字列(プレーン・リテラル)の値を使用しています。
<dc:coverage>Greece</dc:coverage>
PRISMの開発者は、簡単なリテラル値からより構造化された値へと移行し、PRISMの仕様の使用がやがて洗練されることを期待しています。実際、現在直面している状況はその範囲の値です。洗練された統制語彙を既に使用している出版社もあれば、手動で提供されるキーワードを辛うじて使用している出版社もあります。これを例示するために、dc:coverageプロパティーに提供できる異なる種類の値の例をいくつか以下に示します。
<dc:coverage>Greece</dc:coverage> <dc:coverage rdf:resource="http://prismstandard.org/vocabs/ISO-3166/GR"/>
(すなわち、プレーン・リテラルかURIrefのどちらかを使用して国を識別し、)
<dc:coverage>
<pcv:Descriptor rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grèce</pcv:label>
</pcv:Descriptor>
</dc:coverage>
(構造化された値を使用してURIrefと様々な言語による名前の両方を提供します。)
意味が似ているプロパティーや、他のプロパティーのサブセットであるプロパティーがあることにも注意してください。例えば、資源の地理的な主題は以下のように示されます。
<prism:subject>Greece</prism:subject> <dc:coverage>Greece</dc:coverage>
または、
<prism:location>Greece</prism:location>
これらのプロパティーはいずれも、シンプルなリテラルの値か、より複雑な構造化された値を使用できます。このような可能性は、DTDや新しいXMLスキーマでさえ適切に記述できません。扱うべき構文の変化が広範囲なものであっても、RDFのグラフ・モデルは、1組のトリプルというシンプルな構造を持っています。トリプルの定義域でメタデータを扱うと、古いソフトウェアは非常に簡単にコンテンツを新たな拡張に対応させることができます。
最後に、2つの例を示してこの項を終わります。例35は、この画像(.../Corfu.jpg)は、たばこ業界(SIC:標準産業分類のコード21)で使用できない(#none)と述べています。
<rdf:RDF xmlns:prism="http://prismstandard.org/namespaces/basic/1.0/"
xmlns:prl="http://prismstandard.org/namespaces/prl/1.0/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://travel.example.com/2000/08/Corfu.jpg">
<dc:rights rdf:parseType="Resource"
xml:base="http://prismstandard.org/vocabularies/1.0/usage.xml">
<prl:usage rdf:resource="#none"/>
<prl:industry rdf:resource="http://prismstandard.org/vocabs/SIC/21"/>
</dc:rights>
</rdf:Description>
</rdf:RDF>
例36は、コルフ(Corfu)という画像の写真家は、John Petersonとしてよりよく知られている従業員3845であることを示しています。また、写真の地理的範囲がギリシアであることも示しています。しかし、統制語彙のコードだけでなく、語彙の中のその用語に対する情報のキャッシュされたバージョンを提供することでこのように示しています。
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pcv="http://prismstandard.org/namespaces/pcv/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:base="http://travel.example.com/">
<rdf:Description rdf:about="/2000/08/Corfu.jpg">
<dc:identifier rdf:resource="/content/2357845" />
<dc:creator>
<pcv:Descriptor rdf:about="/emp3845">
<pcv:label>John Peterson</pcv:label>
</pcv:Descriptor>
</dc:creator>
<dc:coverage>
<pcv:Descriptor
rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grece</pcv:label>
</pcv:Descriptor>
</dc:coverage>
</rdf:Description>
</rdf:RDF>
多くの状況では、1つの単位として使用される、または、使用されうる資源の構造化されたグループ分けやその関連性に関する情報を保持する必要性が伴います。XMLパッケージ(XPackage)仕様[XPACKAGE]は、このようなグループ分けを定義するためのパッケージというフレームワークを提供します。XPackageは、そのようなパッケージに含まれる資源、その資源のプロパティー、その包含方法、互いの関係を記述するためのフレームワークを指定します。XPackageアプリケーションには、ドキュメントで使用するスタイルシートの指定や、複数のドキュメントで共有する画像の宣言、ドキュメントの著者やその他のメタデータの提示、XML資源で名前空間を使用する方法の記述、資源を1つのアーカイブ・ファイルにまとめるための明細リストの提供が含まれています。
XPackageフレームワークは、XML、RDF、XMLリンク付け言語 [XLINK]に基づいており、複数のRDF語彙を提供します。その1つは一般的なパッケージ記述のためのもので、他のいくつかの語彙はパッケージ・プロセッサに有用な補足的な資源情報を提供するためのものです。
XPackageの1つの応用は、XHTMLドキュメントとそれをサポートしている資源の記述です。ウェブサイトで検索されたXHTMLドキュメントは、同じく検索される必要があるスタイルシートや画像ファイルなどの他の資源に依存しています。しかし、これらのサポートしている資源の独自性は、全文書を処理しなければ明白でないこともありえます。著者の名前などのドキュメントに関する他の情報も、文書を処理しなければ利用できないかもしれません。XPackageでは、そのような記述情報を、RDFを含んでいるパッケージ記述ドキュメントに標準の方法で格納できます。そのようなXHTMLドキュメントを記述しているパッケージ記述ドキュメントの外的要素は、例37(簡単にするために名前空間宣言を省いている)のようになります。
<?xml version="1.0"?>
<xpackage:description>
<rdf:RDF>
(description of individual resources go here)
</rdf:RDF>
</xpackage:description>
資源(XHTMLドキュメント、スタイルシート、画像など)は、標準のRDF/XML構文を使用して、このパッケージ記述ドキュメントで記述されています。それぞれの資源記述要素には、様々な語彙のRDFプロパティーを含めるとができます(XPackageでは、RDFで「語彙」と呼ぶものに対し「オントロジー」という用語を使用します)。主要なパッケージング語彙以外に、XPackage自体は、以下を含むいくつかの補足語彙を指定しています。
file:sizeのようなプロパティーで)語彙(接頭辞file:を使用して)mime:contentTypeのようなプロパティーで)語彙(接頭辞mime:を使用して)unicode:scriptのようなプロパティーで)語彙(接頭辞unicode:を使用して)x:namespaceやx:styleのようなプロパティーで)語彙(接頭辞x:を使用して)例38では、ドキュメントのMIMEコンテンツ・タイプ(「application/xhtml+xml」)は、XPackage MIME語彙の標準XPackageプロパティーであるmime:contentTypeを使用して定義されています。別のプロパティーであるドキュメントの著者(この場合、「Garret Wilson」)は、XPackageの外部で定義されている、ダブリン・コア語彙のプロパティーを使用して記述され、dc:creatorプロパティーになります。
<?xml version="1.0"?>
<xpackage:description
xmlns:xpackage="http://xpackage.org/namespaces/2003/xpackage#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:mime="http://xpackage.org/namespaces/2003/mime#"
xmlns:x="http://xpackage.org/namespaces/2003/xml#"
xmlns:xlink="http://www.w3.org/1999/xlink">
<rdf:RDF>
<!--doc.html-->
<rdf:Description rdf:about="urn:example:xhtmldocument-doc">
<rdfs:comment>The XHTML document.</rdfs:comment>
<xpackage:location xlink:href="doc.html"/>
<mime:contentType>application/xhtml+xml</mime:contentType>
<x:namespace rdf:resource="http://www.w3.org/1999/xhtml"/>
<x:style rdf:resource="urn:example:xhtmldocument-stylesheet"/>
<dc:creator>Garret Wilson</dc:creator>
<xpackage:manifest rdf:parseType="Collection">
<rdf:Description rdf:about="urn:example:xhtmldocument-stylesheet"/>
<rdf:Description rdf:about="urn:example:xhtmldocument-image"/>
</xpackage:manifest>
</rdf:Description>
</rdf:RDF>
</xpackage:description>
xpackage:manifestプロパティーは、処理にスタイルシートと画像資源の両方が必要であることを示しており、これらの資源は、パッケージ記述ドキュメント内で別々に記述されています。例39のスタイルシート資源の記述例では、一般的なXPackage語彙xpackage:locationプロパティー(XLinkと互換性がある)を使用してパッケージ内の位置(「stylesheet.css」)を記載し、XPackageのMIME語彙mime:contentTypeプロパティーを使用して、それがCSSスタイルシート(「text/css」)であることを示します。
<?xml version="1.0"?>
<xpackage:description
xmlns:xpackage="http://xpackage.org/namespaces/2003/xpackage#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:mime="http://xpackage.org/namespaces/2003/mime#"
xmlns:x="http://xpackage.org/namespaces/2003/xml#"
xmlns:xlink="http://www.w3.org/1999/xlink">
<rdf:RDF>
<!--stylesheet.css-->
<rdf:Description rdf:about="urn:example:xhtmldocument-css">
<rdfs:comment>The document style sheet.</rdfs:comment>
<xpackage:location xlink:href="stylesheet.css"/>
<mime:contentType>text/css</mime:contentType>
</rdf:Description>
</rdf:RDF>
</xpackage:description>
この例の完全版は、[XPACKAGE]にあります。
スケジュール、やることリスト、ニュースの見出し、検索結果、「新着情報」などの、ウェブに上の様々な情報に日常的にアクセスすることが必要になることがあります。ウェブに上の情報の情報源や多様性が増すにつれ、この情報を管理し、全体として一貫したものに統合することはますます難しくなります。RSS1.0(「RDFサイト・サマリ」)は、タイムリーで大規模な発信と再利用を可能にする情報を記述する、軽量ながらも強力な方法を提供するRDF語彙です。RSS1.0は、恐らくウェブ上で最も広く使用されているRDFアプリケーションでもありす。
簡単な例をあげると、W3Cのホームページは、一般の人々との主要な接点であり、ある部分では、コンソーシアムの成果物に関する情報を広める役目も果たしています。ある日のW3Cのホームページの例を図19で示しています。中央のニュース記事のコラムは、頻繁に変わります。この情報のタイムリーな配布をサポートするために、W3Cチームでは、中央のコラムのコンテンツを他の人が再利用できるようにしてくれるRDFサイト・サマリー(RSS1.0)のニュース配信を実装しました。ニュース配信サイトではその日の最新ニュースの要約(サマリー)に見出しを結び付け、他のサイトでは読者へのサービスとしてその見出しをリンクで表示することで、個人がデスクトップ・アプリケーションでこの配信を購読できるようになります。このデスクトップRSSリーダーを使用すると、ブラウザで各サイトを訪問しなくても、何百ものサイトの動向を把握できます。
ウェブの多くのサイトがRSS 1.0配信を提供しています。例40は、(異なる日付の)W3C配信の例です。
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel rdf:about="http://www.w3.org/2000/08/w3c-synd/home.rss">
<title>The World Wide Web Consortium</title>
<description>Leading the Web to its Full Potential...</description>
<link>http://www.w3.org/</link>
<dc:date>2002-10-28T08:07:21Z</dc:date>
<items> <rdf:Seq>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item164"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item168"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item167"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.w3.org/News/2002#item164">
<title>User Agent Accessibility Guidelines Become a W3C
Proposed Recommendation</title>
<description>17 October 2002: W3C is pleased to announce the
advancement of User Agent Accessibility Guidelines 1.0 to
Proposed Recommendation. Comments are welcome through 14 November.
Written for developers of user agents, the guidelines lower
barriers to Web accessibility for people with disabilities
(visual, hearing, physical, cognitive, and neurological).
The companion Techniques Working Draft is updated. Read about
the Web Accessibility Initiative. (News archive)</description>
<link>http://www.w3.org/News/2002#item164</link>
<dc:date>2002-10-17</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item168">
<title>Working Draft of Authoring Challenges for Device
Independence Published</title>
<description>25 October 2002: The Device Independence
Working Group has released the first public Working Draft of
Authoring Challenges for Device Independence. The draft describes
the considerations that Web authors face in supporting access to
their sites from a variety of different devices. It is written
for authors, language developers, device experts and developers
of Web applications and authoring systems. Read about the Device
Independence Activity (News archive)</description>
<link>http://www.w3.org/News/2002#item168</link>
<dc:date>2002-10-25</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item167">
<title>CSS3 Last Call Working Drafts Published</title>
<description>24 October 2002: The CSS Working Group has
released two Last Call Working Drafts and welcomes comments
on them through 27 November. CSS3 module: text is a set of
text formatting properties and addresses international contexts.
CSS3 module: Ruby is properties for ruby, a short run of text
alongside base text typically used in East Asia. CSS3 module:
The box model for the layout of textual documents in visual
media is also updated. Cascading Style Sheets (CSS) is a
language used to render structured documents like HTML and
XML on screen, on paper, and in speech. Visit the CSS home
page. (News archive)</description>
<link>http://www.w3.org/News/2002#item167</link>
<dc:date>2002-10-24</dc:date>
</item>
</rdf:RDF>
例40で示しているように、この形式は容易に区別できる部分にまとめることができるコンテンツ用に設計されています。ニュース・サイト、ウェブログ、スポーツの得点、株価などは、すべてRSS 1.0の使用例です。
HTTPを「話す」ことができるアプリケーションでRSS配信を要求できます。しかし、最近では、RSS 1.0アプリケーションは以下の3つの異なるカテゴリーに分かれています。
<item>ごとに切り離し、再び1つの大きなグループにまとめます。そして、そのグループ全体が検索できるようになります。このような方法で、例えば「Java」に関する最新ニュースを、全てのサイトを検索しなくても、恐らく何千ものサイトから検索できます。RSS 1.0は拡張可能なように設計されています。別のRDF語彙(または、RSS開発コミュニティーではモジュールとして知られている)をインポートすることにより、RSS 1.0の著者は、大量のメタデータや取り扱い上の注意事項をファイルの受信者に提供できます。より一般的なRDF語彙と同様に、誰でもモジュールを書くことができます。現在、3つの公式モジュールと、コミュニティー全体がもうじき承認する19の提案モジュールがあります。これらのモジュールは、完全なダブリン・コアのモジュールから集約モジュールなどのより特化したRSS中心のモジュールにまで及びます。
RDFの範囲で「RSS」を論じる時には注意が必要です。現在、RSS仕様には2つの系統があります。1つ(RSS 0.91,0.92,0.93,0.94と2.0)はRDFを使用せず、もう1つ(RSS 0.9 and 1.0)は使用します。
電気事業は、多様な目的に電力システム・モデルを使用しています。例えば、計画とセキュリティー分析には、電力システムのシミュレーションが必要です。また、電力システム・モデルは、例えばエネルギー制御センターで使用するエネルギー管理システム(Energy Management Systems;EMS)などでの実際の運営にも使用されています。運営上の電力システム・モデルは、何千ものクラスの情報から構成されることがあります。これらのモデルを組織内で使用すること以外に、事業には、例えば送電の調整や信頼できる運営の確保のために、計画と運営の両方を目的としたシステム・モデリング情報の交換が必要です。しかし、個々の事業は、これらの目的に対して異なるソフトウェアを使用しており、その結果、システム・モデルが異なる形式で蓄えられるため、モデルの交換が難しくなっています。
電力システム・モデルの交換に対応するために、事業では、電力システムの事業体と関係性に関する共通定義に合意する必要がありました。これに対応するために、非営利のエネルギー研究コンソーシアムである電力研究所(Electric Power Research Institute;EPRI)が、共通情報モデル(Common Information Model;CIM)[CIM]を開発しました。CIMでは、電力システムの資源、その属性、関係に対する共通のセマンティックスを定めています。さらに、CIMモデルを電子的に交換する性能もサポートするために、電力業界は、XMLでCIMモデルを表現するための言語であるCIM/XMLを開発しました。CIM/XMLは、RDFとRDFスキーマを使用してXML構造を組織化するRDFアプリケーションです。北米電気信頼度協議会(North American Electric Reliability Council;NERC)(北米の電気供給の信頼性向上のために結成された業界が支援する組織)は、送電システムのオペレーターの間でモデルを交換するための標準としてCIM/XMLを採用しました。CIM/XMLフォーマットは、IECの国際標準化プロセスも踏んでいます。[DWZ01]には、CIM/XMLの素晴らしい議論が掲載されています。[注意: この電力業界のCIMを、分散型のソフトウェアやネットワーク、企業環境に関する管理情報を表現するための分散管理タスクフォース(Distributed Management Task Force)が開発したCIMと混同してはいけません。DMTFのCIMもXML表現を持っています。しかし、RDFを使用する方向に進行している独自の研究もあますが、現在のところは使用していません。]
CIMは、電気事業のすべての主要な客体を目的語のクラスや属性として、また、それらの関係を表現できます。CIMは、これらの目的語のクラスや属性を使用して、業者固有のEMSシステム間や、EMSシステムと発電管理や送電管理のような電力システム運営の様々な側面に関連する他のシステムとの間で独自に開発されたアプリケーションの統合をサポートします。
CIMは、統一モデリング言語(Unified Modeling Language;UML)を使用した1組のクラスの図表として指定されます。CIMの基底クラスはPowerSystemResourceクラスで、SubstationやSwitch、Breakerなどの他のより特化したクラスをサブクラスとして定義しています。CIM/XMLは、CIMをRDFスキーマ語彙として表現し、RDF/XMLを特定のシステム・モデルを交換するための言語として使用します。例41では、CIM/XMLのクラスとプロパティーの定義の例を示しています。
<rdfs:Class rdf:ID="PowerSystemResource">
<rdfs:label xml:lang="en">PowerSystemResource</rdfs:label>
<rdfs:comment>"A power system component that can be either an
individual element such as a switch or a set of elements
such as a substation. PowerSystemResources that are sets
could be members of other sets. For example a Switch is a
member of a Substation and a Substation could be a member
of a division of a Company"</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID="Breaker">
<rdfs:label xml:lang="en">Breaker</rdfs:label>
<rdfs:subClassOf rdf:resource="#Switch" />
<rdfs:comment>"A mechanical switching device capable of making,
carrying, and breaking currents under normal circuit conditions
and also making, carrying for a specified time, and breaking
currents under specified abnormal circuit conditions e.g. those
of short circuit. The typeName is the type of breaker, e.g.,
oil, air blast, vacuum, SF6."</rdfs:comment>
</rdfs:Class>
<rdf:Property rdf:ID="Breaker.ampRating">
<rdfs:label xml:lang="en">ampRating</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#CurrentFlow" />
<rdfs:comment>"Fault interrupting rating in amperes"</rdfs:comment>
</rdf:Property>
CIM/XMLは、モデルの表現を簡略化するために、完全なRDF/XML構文のサブセットのみを使用します。さらに、CIM/XMLはRDFスキーマ語彙への一部の拡張を実装します。この拡張は、逆の役割および、特定の資源に対していくつの特定のプロパティーのインスタンスが許されるのかを記述する多重度(カーディナリティー)制約をサポートします(多重性宣言に許されている値は、0か1、きっかり1、0以上、1以上です)。例42のプロパティーでは、この拡張(cims: QName接頭辞によって識別される)を例示しています。
<rdf:Property rdf:ID="Breaker.OperatedBy">
<rdfs:label xml:lang="en">OperatedBy</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#ProtectionEquipment" />
<cims:inverseRoleName rdf:resource="#ProtectionEquipment.Operates" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:ID="ProtectionEquipment.Operates">
<rdfs:label xml:lang="en">Operates</rdfs:label>
<rdfs:domain rdf:resource="#ProtectionEquipment" />
<rdfs:range rdf:resource="#Breaker" />
<cims:inverseRoleName rdf:resource="#Breaker.OperatedBy" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
EPRIでは、様々なベンダー製品間で実際の大規模なモデル(テストの1事例として、2000以上の変電所を記述したデータが含まれる)を交換するためにCIM/XMLを使用して相互運用性テストを成功裡に行い、このモデルが一般のユーティリティ・アプリケーションで正しく解釈されることを確認しました。CIMは元々、EMSシステムを目的としていましたが、送電やその他の用途にも対応するように拡張されています。
オブジェクト管理グループ(Object Management Group;OMG)は、オブジェクト・インターフェース標準を採用して、データ・アクセス設備(Data Access Facility)[DAF]というCIM電力ステム・モデルにアクセスしています。CIM/XML言語と同様に、DAFは、RDFモデルに基づいており、同じCIMスキーマを共有します。しかし、CIM/XMLはモデルがドキュメントとして交換できるようにしますが、DAFはアプリケーションが1組のオブジェクトとしてモデルにアクセスできるようにします。
CIM/XMLは、エンティティーの関係やオブジェクト指向クラス、属性、関係として必然的に表現される情報のXMLベースの交換をサポートする際に、RDFが果たすことのできる有益な役割を例示します(その情報が必ずしもウェブでアクセスできない場合でも)。この場合、RDFは、オブジェクトの識別と構造化された関係への使用をサポートする基本構造をXMLに提供します。この関係は、RDF(または、OWLなどのオントロジー言語)とUML(そして、そのXML表現)の関連性を調査する多くのプロジェクトのみならず、情報交換用にRDF/XMLを使用する多くのアプリケーションによって示されます。また、CIM/XMLがカーディナリティー制約と逆の関係をサポートするためにRDFスキーマを拡張する必要があるということから、5.5項で述べたDAML+OILやOWLなどのより強力なRDFベースのスキーマ/オントロジー言語の開発を導いた種々の要件も説明できます。このような言語は、多くの同様のモデル・アプリケーションを将来サポートする際に適しているかもしれません。
最後に、CIM/XMLは、「現在のRDF」の例をさらに求める人にとって重要な事実も示しています。つまり、言語が「XML」言語として記述されることがあるとか、システムが「XML」を使用していると記述されてるとか、そして、実際に使用している「XML」がRDF/XMLであるなどで、つまり、これらはRDFアプリケーションであるということです。これを見つけるために、言語やシステムの記述をかなり詳細に探す必要があることがあります。(RDFが全く明示的に述べられていない例も一部ありますが、サンプル・データではRDF/XMLであることが明確に分かります)。そのうえ、CIM/XMLなどのアプリケーションは、一般的なアクセスではなくソフトウェア・コンポーネント間での情報交換を目的としているため、生成されたRDFはウェブで容易に探せないでしょう(将来のシナリオでは、この種のRDFがより多くウェブでアクセス可能になると想像できますが)。
SNOMED RT(Systematized Nomenclature of Medicine Reference Terminology)やMeSH(Medical Subject Headings)などの統制語彙を使用した構造化されたメタデータは、より効率的な文献検索を可能にして医療知識[COWAN]の配信や交換をサポートし、医療で重要な役割を果たしています。同時に、医療の分野は急激に変化するため、語彙をさらに開発する必要性が生じます。
遺伝子オントロジー(GO)コンソーシアム(Gene Ontology (GO) Consortium) [GO]の目的は、統制語彙を提供して遺伝子産物の特定の側面を記述することです。データベースと連携すれば、注釈を裏付けるために参照を提供したりどのような証拠が利用できるかを示して、遺伝子産物(または、遺伝子)をGO用語で注釈します。これらのデータベースで共通のGO用語を使用すれば、統一的な横断検索が容易になります。GOオントロジーは、帰属と照会の両方を異なるレベルの粒度で実行できるように構造化されます。細胞内の遺伝子やタンパク質の役割に関する知識が蓄積され変化しているため、GO語彙は動的です。
GOの3つの組織化原理は、分子機能、生物学的過程、細胞成分です。遺伝子産物は、1つ以上の分子機能を持ち、1つ以上の生物学的過程で使用され、1つ以上の細胞成分であるか、関連しています。これらのすべて3つのオントロジー内の用語の定義は、1つの(テキスト形式の)定義ファイルに含まれています。3つすべてのオントロジーのファイルとすべての利用可能な定義を含んだXML形式のバージョンが毎月生成されます。
機能、過程、成分は、有向非巡回グラフ(DAG)またはネットワークとして表現されます。子用語はその親用語の「インスタンス」(isa関係)か、その親用語の構成要素(part-of関係)でありえます。子用語は、複数の親用語を持つことができ、異なる関係のクラスを異なる親と持つことができます。このオントロジーでは、同義語や外部のデータベースとの相互参照も表現されます。GOは、広範囲なツールをサポートし、グラフ構造の表現に柔軟性があるため、RDF/XML機能を使用して、XMLバージョンのオントロジーにおける用語間の関係を表現します。同時に、GOは現在、用語の記述内で非RDFの入れ子のXML構造を使用するため、使用される言語は純粋なRDF/XMLではありません。
例43は、GOドキュメントからのGO情報のサンプルの一部を示しています。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE go:go>
<go:go xmlns:go="http://www.geneontology.org/xml-dtd/go.dtd#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<go:version timestamp="Wed May 9 23:55:02 2001" />
<rdf:RDF>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003673">
<go:accession>GO:0003673</go:accession>
<go:name>Gene_Ontology</go:name>
<go:definition></go:definition>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003674">
<go:accession>GO:0003674</go:accession> <go:name>molecular_function</go:name>
<go:definition>The action characteristic of a gene product.</go:definition>
<go:part-of rdf:resource="http://www.geneontology.org/go#GO:0003673" />
<go:dbxref>
<go:database_symbol>go</go:database_symbol>
<go:reference>curators</go:reference>
</go:dbxref>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0016209">
<go:accession>GO:0016209</go:accession>
<go:name>antioxidant</go:name>
<go:definition></go:definition>
<go:isa rdf:resource="http://www.geneontology.org/go#GO:0003674" />
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>CG7217</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0038570</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>Jafrac1</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0040309</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
</go:term>
</rdf:RDF>
</go:go>
例43では、go:termが基本要素であることを示しています。場合によっては、GOはRDFスキーマを使用しないで、自身の用語を定義してきました。例えば、用語GO:0016209には、要素<go:isa rdf:resource="http://www.geneontology.org/go#GO:0003674" />があります。このタグは、「GO:0016209 isa GO:0003674」という関係、つまり、英語で言うと「Antioxidant is a molecular function.(酸化防止剤は分子機能です。)」を表現しています。別の特殊化した関係はgo:part-ofです。例えば、GO:0003674には要素<go:part-of rdf:resource="http://www.geneontology.org/go#GO:0003673" />があります。これは「分子機能は遺伝子オントロジーの一部です」という意味です。
すべての注釈は、文献参照や別のデータベース、コンピュータ解析のような、情報源に属していなければなりません。注釈は、引用された情報源でどのような証拠が発見されるのかを示して、遺伝子産物とGO用語との間の関連性を裏づけなければなりません。簡単な統制語彙を使用して証拠を記録します。例には以下のものが含まれます。
go:dbxref要素は外部データベースの用語を表し、go:associationは各用語の遺伝子の関連性を表します。go:associationは、関連性を裏付ける証拠へのgo:dbxrefを保持するgo:evidenceと、遺伝子記号とgo:dbxrefを含むgo:gene_productの両方を持つことができます。これらの要素は、これらの要素内に他の要素を入れ子にすることは[RDF-SYNTAX]の2.1項と2.2項で記述している別のノード/述語アークの「ストライプ」に準じていないため、GO XML構文が「純粋な」RDF/XMLでないことを示します。
GOは、多くの興味深い点を示しています。まず最初に、情報交換のためにXMLを使用する価値を、RDFを使用してそのXMLを構造化することによって高めることができることを示しています。これは、厳密な階層構造ではなく、全面的なグラフやネットワーク構造を持つデータに特に当てはまります。GOは、ウェブを直接使用した時に、RDFを使用したデータが必ずしも表示されない別の例でもあります(ファイルにはウェブでアクセスできますが)。また、一見すると「XML」で記述されているけれども、よく調べてみるとRDF/XML機能(「純粋な」RDF/XMLではないが)を使用しているという、データの別の例もあります。最後に、GOは、オントロジーを表現するための基礎としてRDFが果たすことができる役割を示しています。5.5項で論じたDAML+OILやOWL言語などの、オントロジーを指定するためのより豊かなRDFベースの言語がより広範囲に使用されるようになると、この役割はさらに高められます。実際に、次世代遺伝子オントロジー(Gene Ontology Next Generation)プロジェクトは現在、GOオントロジーの表現をこれらのより豊かな言語で開発しています。
近年、ウェブをブラウジングするための新しいモバイル機器が多く出現しました。これらの機器の多くは、広範囲な入出力性能や異なるレベルの言語のサポートを含む非常に多様な性能を持っています。モバイル機器は、非常に多様なネットワーク接続性能を持つこともできます。これらの新しい機器のユーザは、機器の性能や現在のネットワーク特性に関係なく、便利な表現を期待します。同様に、ユーザは、コンテンツやアプリケーションが表示される時に、自分達の動的に変わる嗜好(例えば、音声をオン・オフするなど)を考慮して欲しいと考えます。しかし、現実には、機器の異種性や、ユーザが自分達の嗜好をサーバに伝える標準的な方法が欠けていることにより、コンテンツを機器に保存できなかったり、コンテンツを表示できなかったり、コンテンツがユーザの望みに反するといった結果が生じます。さらに、結果的に生成されるコンテンツがネットワークを通じてクライアント機器に達するのに時間がかかり過ぎることもありえます。
これらの問題に対する解決策は、クライアントが配信コンテキスト―機器の性能、ユーザの嗜好、ネットワーク特性など―を、サーバがそのコンテキストを使用してコンテンツを機器やユーザ用にカスタマイズできるような方法でコード化することです(配信コンテキストの定義に関しては、[DIPRINC]を参照)。W3Cの複合性能/嗜好プロファイル(Composite Capabilities/Preferences Profile;CC/PP)の仕様[CC/PP]は、包括的なフレームワークを定義して配信コンテキストを記述することで、この問題に対処するのに役立ちます。
CC/PPフレームワークは、比較的簡単な構造―構成要素と属性/値の組み合わせによる2つのレベルの階層構造を定義します。構成要素を使用して、配信コンテキストの一部(例えば、ネットワーク特性、機器がサポートするソフトウェア、機器のハードウェア特性など)を収集できます。構成要素には、1つ以上の属性を含むことができます。例えば、ユーザの嗜好をコード化する構成要素には、音声出力(AudioOutput)が必要かどうかを指定する属性を含むことができます。
CC/PPは、RDFスキーマを使用して構造(上記の階層)を定義します(構造スキーマの詳細に関しては、[CC/PP]を参照してください)。CC/PP語彙は、特定の構成要素とその属性を定義します。しかし、[CC/PP]は、このような語彙を定義しません。その代わりに、語彙は他の機関やアプリケーションで定義されます(以下で述べるように)。[CC/PP]は、CC/PP語彙のインスタンスを送信するプロトコルも定義していません。
CC/PP語彙のインスタンスをプロファイルと呼びます。CC/PP属性は、プロファイルでRDFプロパティーとしてコード化されます。例44では、音声表現を好むユーザのためにユーザ嗜好のプロファイルのフラグメントを示しています。
<ccpp:component>
<rdf:Description rdf:ID="UserPreferences">
<rdf:type rdf:resource="http://www.example.org/profiles/prefs/v1_0#UserPreferences"/>
<ex:AudioOutput>Yes</ex:AudioOutput>
<ex:Graphics>No</ex:Graphics>
<ex:Languages>
<rdf:Seq>
<rdf:li>en-cockney</rdf:li>
<rdf:li>en</rdf:li>
</rdf:Seq>
</ex:Languages>
</rdf:Description>
</ccpp:component>
このアプリケーションでRDFを使用することには、いくつかの利点があります。まず最初に、CC/PPでコード化したプロファイルには、異なる機関が作成したスキーマで定義された属性を含むことができます。集約されたプロファイル・データに対する上位スキーマを1つの機関が作成することはないだろうと思われるため、RDFはこれらのプロファイルに正にと適しています。RDFの2番目の利点は、(グラフ・ベースのデータ・モデルのおかげで)任意の属性(RDFプロパティー)をプロファイルへ容易に挿入できるようになるということです。これは、ロケーション情報などの、頻繁に変更されるデータを含むプロファイルに特に有益です。
オープン・モバイル・アライアンス(Open Mobile Alliance)は、ユーザー・エージェント・プロファイル(User Agent Profile;UAProf)[UAPROF]―プロファイル送信のためのプロトコルのみならず、機器性能、ユーザ・エージェント性能、ネットワーク特性などを記述するための語彙を含むCC/PPベースのフレームワークを定義しました。UAProfは、HardwarePlatform、SoftwarePlatform、NetworkCharacteristics、BrowserUAを含む6つの構成要素を定義しています。構成要素の属性は確定されていませんが―補足されたり置換されうる―各コンポーネントに対してもいくつかの属性を定義しています。例45では、UAProfのHardwarePlatform構成要素のフラグメントを示しています。
<prf:component>
<rdf:Description rdf:ID="HardwarePlatform">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20021113#HardwarePlatform"/>
<prf:ScreenSizeChar>15x6</prf:ScreenSizeChar>
<prf:BitsPerPixel>2</prf:BitsPerPixel>
<prf:ColorCapable>No</prf:ColorCapable>
<prf:BluetoothProfile>
<rdf:Bag>
<rdf:li>headset</rdf:li>
<rdf:li>dialup</rdf:li>
<rdf:li>lanaccess</rdf:li>
</rdf:Bag>
</prf:BluetoothProfile>
</rdf:Description>
</prf:component>
UAProfプロトコルは、静的プロファイルと動的プロファイルの両方をサポートします。静的プロフィールには、URIでアクセスします。これにはいくつかの利点があります。それは、サーバへのクライアントの要求には冗長になりかねないXMLドキュメントではなくURIのみが含まれる(したがって、空中のトラフィックが最小になる)、クライアントはプロファイルを保存そして/または作成する必要がない、クライアントの実装負荷が比較的軽いということです。動的プロファイルはオン・ザ・フライで作成され、その結果、関連するURIを持ちません。動的プロファイルは、静的プロファイルとの相違点を含むプロファイル・フラグメントで構成することもできますが、クライアントの静的プロファイルに含まれていない一意のデータを含むこともできます。要求には、静的プロファイルと動的プロファイルをいくつでも含むことができます。しかし、要求では、古いプロファイルが新しいプロファイルに置換えられるため、プロファイルの順序は重要です。UAProfのプロトコルと、複数のプロファイルを処理するための規則に関する詳細情報に関しては[UAPROF]を参照してください。
他のいくつかのコミュニティー(3GPPのTS 26.234 [3GPP]やWAPフォーラムのマルチメディア・メッセージング・サービス・クライアント・トランザクション仕様(Multimedia Messaging Service Client Transactions Specification;MMS-CTR)など[MMS-CTR])がCC/PPに基づいた語彙を定義しました。その結果、プロファイルは、RDFの分散的な性質を利用して様々な語彙で定義された構成要素を含むことができます。例46では、このようなプロファイルを示しています。
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:prf="http://www.wapforum.org/profiles/UAPROF/ccppschema-20010330#"
xmlns:mms="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#"
xmlns:pss="http://www.3gpp.org/profiles/PSS/ccppschema-YYYYMMDD#">
<rdf:Description rdf:ID="SomeDevice">
<prf:component>
<rdf:Description rdf:ID="Streaming">
<rdf:type rdf:resource="http://www.3gpp.org/profiles/PSS/ccppschema-PSS5#Streaming"/>
<pss:AudioChannels>Stereo</pss:AudioChannels>
<pss:VideoPreDecoderBufferSize>30720</pss:VideoPreDecoderBufferSize>
<pss:VideoInitialPostDecoderBufferingPeriod>0</pss:VideoInitialPostDecoderBufferingPeriod>
<pss:VideoDecodingByteRate>16000</pss:VideoDecodingByteRate>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="MmsCharacteristics">
<rdf:type rdf:resource="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#Streaming"/>
<mms:MmsMaxMessageSize>2048</mms:MmsMaxMessageSize>
<mms:MmsMaxImageResolution>80x60</mms:MmsMaxImageResolution>
<mms:MmsVersion>2.0</mms:MmsVersion>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="PushCharacteristics">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20010330#PushCharacteristics"/>
<prf:Push-MsgSize>1024</prf:Push-MsgSize>
<prf:Push-MaxPushReq>5</prf:Push-MaxPushReq>
<prf:Push-Accept>
<rdf:Bag>
<rdf:li>text/html</rdf:li>
<rdf:li>text/plain</rdf:li>
<rdf:li>image/gif</rdf:li>
</rdf:Bag>
</prf:Push-Accept>
</rdf:Description>
</prf:component>
</rdf:Description>
</rdf:RDF>
配信コンテキストの定義とコンテキスト内のデータは絶えず進化します。その結果、RDFの本来の拡張性と、それ故に動的に変化する語彙に対するサポートによって、RDFは配信コンテキストのコード化に適したフレームワークになります。
1項では、RDFの仕様が(この入門書に加え)以下の多くのドキュメントで構成されることを示しました。
この入門書では、これらのドキュメントのいくつかのテーマ、つまり、RDFの基本概念(2項)、RDF/XML構文(3項)、RDFスキーマ(5項)について既に論じました。この項では、RDFの完全な仕様におけるこれらのドキュメントの役割について説明するために、残りのドキュメントについて簡潔に述べます([RDF-SEMANTICS]は既に何度も参照しましたが)。
前項で論じたように、RDFは、特定の語彙(資源、プロパティー、クラスなどの名前)を使用して、資源に関するステートメントをグラフの形式で表わすために使用することを目的としています。RDFは、5.5項で論じたような、より高度な言語の基盤になることも目的としています。これらの目的を果たすために、RDFグラフの「意味」は非常に正確な方法で定義されなければなりません。
非常に一般的な意味で、RDFグラフの「意味」が厳密に何で構成されているかは、ユーザが定義したRDFのクラスやプロパティーを特定の方法で解釈するユーザ・コミュニティー内の規定や、自然言語によるコメント、他のコンテンツを持つドキュメントへのリンクを含む、多くの要素に依存しています。2.2項で簡潔に指摘したように、この意味は、RDF情報の人間の翻訳者が使用したり、そのRDF情報で様々な種類の処理を実行するソフトウェアを書くプログラマが使用したりできますが、これらの形式で伝えられた意味の多くは、機械処理には直接利用できないでしょう。しかし、RDFステートメントには、機械が特定のRDFグラフから引き出せる結論(または、含意)を極めて正確に決定づける形式的な意味もあります。RDFセマンティクス [RDF-SEMANTICS]ドキュメントでは、形式言語のセマンティクスを指定するためのモデル理論と呼ばれる技術を使用してこの形式的な意味を定義しています。[RDF-SEMANTICS]は、RDFスキーマや個々のデータ型によって表現されたRDF言語へのセマンティックの拡張も定義しています。言い換えれば、RDFモデル理論は、すべてのRDF概念に対する形式的な基盤を提供しています。モデル理論で定義されているセマンティクスに基づいて、RDFグラフを基本的に同じ意味を持つ論理式に翻訳するのは簡単です。
RDFテストケース [RDF-TESTS]は、RDFコア・ワーキンググループが対処した特定の技術的な課題に対応するテストケース(例)でRDF仕様の原文を補います。テストケース・ドキュメントでは、これらの例の記述に役立つように、Nトリプルと呼ばれる表記法を導入し、これによって、この入門書を通じて使用しているトリプル表記法の根拠を提供しています。テストケースは、テストケース・ドキュメントで参照されているウェブ・ロケーションに機械可読形式で掲載されているため、開発者は、RDFソフトウェアの自動テストの根拠としてこれらを使用できます。
テストケースは、以下の多くのカテゴリーに分類されています。
このテストケースは、RDFの完全な仕様ではなく、他の仕様ドキュメントに優先するものでもありません。しかし、これは、RDFの設計に関するRDFコア・ワーキンググループの意図を示すことを目的としており、仕様のある詳細部分の表現が不明瞭である場合、このテストケースは開発者にとって役立つものとなるでしょう。
application/rdf+xmlへの登録は、http://www.w3.org/2001/sw/RDFCore/mediatype-registrationでアーカイブされています。
このドキュメントは、RDFコア・ワーキンググループの多くのメンバーからの情報提供の恩恵を受けています。特に、Art Barstow、Dave Beckett、Dan Brickley、Ron Daniel、Ben Hammersley、Martyn Horner、Graham Klyne、Sean Palmer、Patrick Stickler、Aaron Swartz、Ralph Swick、Garret Wilsonに感謝いたします。彼らは、入門書の以前のバージョンへコメントを寄せてくださった多くの人々と共に、このドキュメントに有益な貢献をしてくださいました。
さらに、このドキュメントには、RDF系の仕様で述べているRDFデータ型機能の開発を先導したPat Hayes、Sergey Melnik、Patrick Sticklerによる大きな貢献もありました。
Frank Manolaは、このドキュメントの準備のほとんどの期間中に彼が勤めていたMITRE社にも、MITRE主催の研究交付金を受けたRDFコア・ワーキンググループの活動への支援に対し感謝いたします。
注意: この項ではURIについて簡潔に紹介します。URIの最終的な仕様はRFC 2396 [URIS]であり、詳細に関してはこれを参考するべきです。また、URIに関するさらなる議論は、Naming and Addressing: URIs, URLs, ... [NAMEADDRESS]に掲載されています。
2.1項で論じたように、ウェブでは、ウェブに関する資源を識別する(命名する)ために、Uniform Resource Identifier(URI)と呼ばれる一般的な形式の識別子を提供しています。URLとは異なり、URIは、ネットワーク上にロケーションを持つ事物や、他のコンピュータ・アクセス機構を使用する事物の識別に制限されていません。数多くの多様なURIスキーム(URI形式)が様々な目的で既に開発され、使用されています。例えば以下のようなものが含まれます。
http:(ハイパーテキスト転送プロトコル、ウェブ・ページ用)mailto:(電子メール・アドレス)例えば、mailto:em@w3.orgftp:(ファイル転送プロトコル)urn:(URN、永続的でロケーションに依存しない資源識別子用)例えば、urn:isbn:0-520-02356-0(書籍用)既存のURIスキームのリストは、アドレシング・スキーム(Addressing Schemes)[ADDRESS-SCHEMES]にあります。新しいものを作り出そうとするのではなく、既存のスキームの1つを特定の識別の目的に適合させることを検討する方が良いでしょう。
個人や団体は、誰がURIを作り、どのように使用されるかを制御できません。URIスキームには、URLのhttp:のようにDNSなどの集中型システムに依存しているものもあれば、freenet:のような完全に分散型のスキームもあります。これは、他のあらゆる種類の名前と同じで、URIの作成には特別な権限や許可は必要ないということを意味します。また、自分が持っていない事物に対して日常の言語で好きな名前を使うことができるのと全く同じ様に、誰もが自分が持っていない事物を参照するためにURIを作成できます。
2.1項でも指摘したように、RDFでは、URI参照 [URIS]を使用してRDFステートメントで主語、述語、目的語を命名します。URI参照(または、URIref)はURIです(末尾にフラグメント識別子を伴うことがあります)。例えば、URI参照http://www.example.org/index.html#section2は、URI http://www.example.org/index.htmlと(「#」という文字で区切られた)フラグメント識別子Section2で構成されています。RDF URIrefには、ユニコード[UNICODE]の文字を含むことができ([RDF-CONCEPTS]を参照)、これによって多くの言語をURIrefに反映できます。
URIrefは、絶対あるいは相対のどちらかでありえます。絶対URIrefは、URIrefが出現するコンテキスト、例えばhttp://www.example.org/index.htmlとは無関係に資源を示します。相対URIrefは絶対URIrefの省略形であり、URIrefの一部の接頭辞が欠けており、この欠けた情報を埋めるためにURIrefが出現するコンテキストからの情報が必要です。例えば、相対URIref otherpage.htmlが資源http://www.example.org/index.htmlで出現する時には、絶対URIref http://www.example.org/otherpage.htmlと書き込まれるでしょう。URI部分がないURIrefは、現在のドキュメント(そのURIrefが現れるドキュメント)への参照であると見なされます。そのため、ドキュメント内の空のURIrefは、ドキュメント自体のURIrefと同じだと見なされます。フラグメント識別子のみで構成されるURIrefは、このURIrefが現れるドキュメントのURIrefにフラグメント識別子を追加したものと同じだと見なされます。例えば、http://www.example.org/index.html内で、#section2がURIrefとして出現する場合、これは絶対URIref http://www.example.org/index.html#section2と同じだと見なされます。
[RDF-CONCEPTS]では、RDFグラフ(抽象モデル)が相対URIrefを使用しないということを指摘しています。すなわち、RDFステートメントの主語、述語、目的語(そして、型付きリテラルのデータ型)は、常にコンテキストとは無関係に識別されなければなりません。しかし、RDF/XMLなどの特定の具象RDF構文では、ある状況においては、相対URIrefを絶対URIrefの省略形として使用できます。RDF/XMLでは、実際にそのような相対URIrefの使用が可能で、この入門書のRDF/XMLの例の一部でそのような使用法を示しています。詳細については、[RDF-SYNTAX]を参照してください。
RDFとウェブ・ブラウザの両方が、URIrefを使用して事物を識別します。しかし、RDFとブラウザは、少し違った方法でURIrefを解釈します。これは、RDFは事物を識別するためにだけURIrefを使用するけれども、ブラウザは事物を検索するためにもURIrefを使用するからです。大抵は実質的な違いはありませんが、違いが重要な場合もあります。1つの明白な違いは、ブラウザでURIrefを使用した場合には、実際に検索できる資源を識別すると予期される、すなわち、何かが実際にこのURIで識別されるロケーション「に」あると予期されます。しかし、RDFでは、URIrefは人などのウェブで検索できないものを識別するためにも使用できます。RDF資源を識別するためにURIrefを使用する場合、その資源に関する記述情報を含むページはウェブ上のそのURI「に」置かれるという慣習に従ってRDFを使用することがあります。そのため、URIrefをブラウザで使用してその情報を検索できます。オリジナル資源とそれを記述したウェブ・ページの区別が困難になりますが、状況によっては、この慣習は有益になりえます(2.3項で詳細に論じた問題です)。しかし、この慣習はRDFの定義に明示されている事項ではなく、RDF自体はURIrefが検索できるものを識別することを想定していません。
もう1つの違いは、フラグメント識別子を持つURIrefを扱う方法にあります。フラグメント識別子は、HTMLドキュメントを識別するURLでよく見られ、URLで識別されているドキュメント内の特定の場所を識別する働きをします。指示された資源を検索するためにURI参照を使用するという、通常のHTMLの使用法では、以下の2つのURIref
http://www.example.org/index.html
http://www.example.org/index.html#Section2
には、関連があります(これらは2つとも同じドキュメントを参照し、2番目のURIrefは1番目のURIref内のロケーションを識別しています)。しかし、既に指摘したように、RDFは資源を検索するのではなく、純粋に資源を識別するためにURI参照を使用し、RDFではこの2つのURIref間の特定の関係を想定しません。これらのURI参照は構文的に異なっているため、RDFに関する限り、関連がない事物を参照することがありえます。これは、HTMLで定義されている包含関係が存在しないということを意味しているのではなく、RDFではURI参照のURI部分が同じであるという事実だけに基づいて、関係が存在するとは想定しないということだけを意味しています。
この点をさらに説明すると、RDFでは、フラグメント識別子があるか否かに関係なく、共通の先行文字列を共有するURI参照の間に関係があるとは想定しません。例えば、RDFに関する限り、以下の2つのURIref
http://www.example.org/foo.html
http://www.example.org/bar.html
は、両方とも、文字列http://www.example.org/で始まりますが、特定の関係はありません。これらのURIrefは異なっているため、RDFでは、これらは単に異なる資源です。(これらは、実際に同じディレクトリに位置する2個のファイルであるかもしれませんが、RDFは、このような関係、または、いかなるその他の関係も存在すると想定しません。)
注意: この項は、XMLについて簡単に紹介することを目的としています。XMLの最終的な仕様は[XML]で、詳細についてはこれを参照してください。
XML(Extensible Markup Language) [XML]は、誰もが自身のドキュメント形式を設計し、その形式でドキュメントを書くことができるよyに設計されました。HTMLドキュメント(ウェブ・ページ)と同様に、XMLドキュメントにはテキストが含まれます。このテキストは、主にプレーン・テキストのコンテンツとタグ形式のマークアップで構成されています。このマークアップによって、処理プログラムが様々なコンテンツ(要素という)を解釈できるようになります。XMLコンテンツと(例外がある)タグの両方にユニコード[UNICODE]の文字を含むことができ、これによって多くの言語による情報を直接表現できるようになります。HTMLでは、許されている一連のタグとその解釈は、HTMLの仕様で定義されています。しかし、XMLでは、ユーザが自身の特定の要求に合わせた独自のマークアップ言語(表示できるタグと構造)を定義できます(3項で述べたRDF/XML言語は、このようなXMLマークアップ言語の1つです)。例えば、以下はXMLベースのマークアップ言語を使用してマークアップした簡単な一節です。
<sentence><person webid="http://example.com/#johnsmith">I</person> just got a new pet <animal>dog</animal>.</sentence>
タグ(<sentence>、<person>など)で区切られた要素は、この一節に関連する特定の構造を反映するために導入されています。この特定の要素やその構造化方法を理解して書かれたプログラムは、タグによって、この一節を適切に解釈できるようになります。例えば、この例にある要素の1つは<animal>dog</animal>です。これは開始タグの<animal>、要素コンテンツ、対応する終了タグの</animal>で構成されています。このanimal要素は、person要素と一緒に、sentence要素のコンテンツの一部として入れ子にされています。以下のような文章が書かれていれば、入れ子はより明確である(また、この入門書の残りの部分に含まれる、さらに「構造化」されたXMLの一部により近い)と思われます。
<sentence>
<person webid="http://example.com/#johnsmith">I</person>
just got a new pet
<animal>dog</animal>.
</sentence>
要素にコンテンツがない場合もあります。これは、<animal></animal>のように、1組の開始タグと終了タグ内にコンテンツを囲み込まないで書くか、<animal/>のように、空要素タグというタグの省略形を使用して書くことができます。
開始タグ(または、空の要素タグ)には、タグ名以外に修飾情報を属性の形式で含む場合もあります。例えば、<person>要素の開始タグは、属性webid="http://example.com/#johnsmith"(恐らく、参照される特定人物を識別する)を含んでいます。属性は、名前、等号、値(引用符で囲み込まれた)で構成されています。
この特定のマークアップ言語は、要素の意味の一部を伝えるために「sentence」「person」「animal」という単語をタグ名として使用し、それを読んでいる英語を話す人々や、この語彙を解釈するように特別に書かれたプログラムに意味を伝えるでしょう。しかし、ここには組み込み済みの意味はありません。例えば、英語を話さない人々や、このマークアップを理解するように書かれていないプログラムには、要素(<person>)は全く何も意味しないかもしれません。例えば、以下の一節の例をごらんください。
<dfgre><reghh bjhbw="http://example.com/#johnsmith">I</reghh> just got a new pet <yudis>dog</yudis>.</dfgre>
機械にとっては、この一節は、前の例と全く同じ構造を持っています。しかし、タグが英単語でなくなっているため、英語を話す人々には、何が述べられているかはもはや明確ではありません。さらに、別々の人々が、完全に異なる意図を持った意味で同じ単語を自分達のマークアップ言語にタグとして使用しているかもしれません。例えば、他のマークアップ言語の「sentence」は、犯罪者が刑務所に服役しなければならない期間を意味するかもしれません(訳注:「sentence」には、「文」以外に「刑期」という意味もある)。そのため、XML語彙の正確性を保つための仕組みを追加提供しなければなりません。
混乱を避けるため、マークアップ要素を一意に識別する必要があります。これは、XML名前空間XML-NS [XML-NS]をXMLで使用すれば行うことができます。名前空間は、単に、特定の名前の集合に対する限定子として機能する、ウェブ(空間)の一部を識別する方法です。名前空間は、その名前空間に対するURIを作成することにより、XMLマークアップ言語用に作成されます。この名前空間のURIでタグ名を修飾することにより、誰でもが独自のタグを作成し、他の人が作成した同じスペルのタグと適切に区別できます。慣習として、ウェブページを作成してマークアップ言語(および、タグが意図する意味)を記述し、そのウェブ・ページのURLをその名前空間のURIとして使用することもあります。しかし、これは慣習にすぎず、XMLとRDFのどちらも、名前空間URIが検索可能なウェブ資源を識別するとは想定しません。以下の例では、XML名前空間の使用法を示しています。
<user:sentence xmlns:user="http://example.com/xml/documents/"> <user:person user:webid="http://example.com/#johnsmith">I</user:person> just got a new pet <user:animal>dog</user:animal>. </user:sentence>
この例では、属性xmlns:user="http://example.com/xml/documents/"は、XMLのこの部分で使用するための名前空間を宣言しています。これは、接頭辞userを名前空間URI http://example.com/xml/documents/にマッピングします。次に、XMLコンテンツは、修飾名(または、QName)をタグとして使用できます。QNameには、名前空間を識別する接頭辞、その後にコロン、次にXMLタグや属性名のローカル名が含まれています。この例のように、名前空間URIを使用して名前の特定のグループを区別し、由来する名前空間のURIでタグを修飾することにより、タグ名が衝突する心配がなくなります。同じスペルの2つのタグは、それらが同じ名前空間URIを持つ場合にのみ、同じと見なされます。
全てのXMLドキュメントは整形式(well-formed)である必要があります。これは、XMLドキュメントは、例えば、全ての開始タグには対応する終了タグがなければならず、要素は他の要素内に適切に入れ子にされなければならない(要素は重複してはならない)などの、多くの構文上の条件を満たさなければならないということを意味します。[XML]では、整形式性(well-formedness)の一揃いの条件が定義されています。
さらに、XMLドキュメントでは、XML文書型宣言(document type declaration)をオプションで含んで、ドキュメントの構造に制約を追加定義し、ドキュメント内で定義済みの単位のテキストを使用できます。文書型宣言(DOCTYPEで始まる)は、ドキュメントの文法を定義する宣言を含んだり指し示したりします。この文法は、文書型定義(document type definition)、またはDTDとして知られています。DTDにおける宣言では、DTDに対応してどのXML要素と属性がXMLドキュメントに出現できるか、これらの要素と属性の関係(例えば、どの要素を他のどの要素内で入れ子にできるか、または、どの属性がどの要素と共に出現できるか)、要素や属性が必須なのかオプションなのか、などの事項を指定します。文書型宣言は、ドキュメントの外部に位置する1組の宣言を指し示すことができたり(外部サブセット(external subset)と呼ばれ、これを使用して共通の宣言を複数のドキュメントで共有できる)、宣言をドキュメントに直接含むことができたり(内部サブセット(internal subset)と呼ばれる)、内部および外部の両方のDTDサブセットを持つことができます。ドキュメントの完全なDTDは、両方のサブセットを併せて構成されます。文書型宣言を持つXMLドキュメントの簡単な例を、以下の例47で示しています。
<?xml version="1.0"?> <!DOCTYPE greeting SYSTEM "http://www.example.org/dtds/hello.dtd"> <greeting>Hello, world!</greeting>
この場合、ドキュメントには外部DTDサブセットしかなく、システム識別子(system identifier)http://www.example.org/dtds/hello.dtdがこのドキュメントの位置(URIref)を規定します。
XMLドキュメントは、関連する文書型宣言を持っていて、そのドキュメントが文書型宣言で定義されている制約に従っている場合、正当(valid)です。
RDF/XMLドキュメントでは、整形式のXMLであることのみを要し、XML DTD(または、XMLスキーマ)に対する妥当性の検証を目的としておらず、[RDF-SYNTAX]では、任意のRDF/XMLの妥当性を検証するために使用できる規範的なDTDを指定しません([RDF-SYNTAX]の付録では、RDF/XMLに対する規範的でないスキーマの例を提供しています)。その結果、XML DTD文法に関するより詳細な議論は、この入門書の範囲を超えています。XML DTDやXML妥当性検証に関する詳細は、[XML]やXMLに関する多くの本に掲載されています。
しかし、RDF/XMLに関連するXML文書型宣言の使用法が1つあり、それは、XMLエンティティーを定義する際の使用法です。XMLエンティティー宣言は、本質的に名前を文字列に関連づけます。エンティティー名がXMLドキュメント内の他のどこかで使用される場合、XMLプロセッサーはエンティティー名を対応する文字列に置き換えます。これによって、URIrefsなどの長い文字列を省略でき、このような文字列を含むXMLドキュメントがより読みやすくなります。文書型宣言を使用して単にXMLエンティティーを宣言することが可能で、(RDF/XMLと同様に)ドキュメントの妥当性の検証を目的としていない場合でも有用でありえます。
RDF/XMLドキュメントでは、実体は一般的にドキュメント自身の中で、つまり内部のDTDサブセットのみを使用して宣言されます(この理由の1つは、RDF/XMLは妥当性を検証するように作られておらず、妥当性の検証を行わないXMLプロセッサは外部のDTDサブセットを処理する必要がないということです)。例えば、例48で示した、RDF/XMLドキュメントの冒頭の文書型宣言を提供することで、rdf、rdfs、xsdの名前空間に対するそのドキュメントのURIrefを、例で示しているように、それぞれ&rdf;、&rdfs;、&xsd;に省略化することができます。
<?xml version='1.0'?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#">
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
]>
<rdf:RDF
xmlns:rdf = "&rdf;"
xmlns:rdfs = "&rdfs;"
xmlns:xsd = "&xsd;">
...RDF statements...
</rdf:RDF>